目录
一、springboot的常用注解?
二、springmvc常用注解?
三、mysql的内连接和外连接有什么区别?比如有两张表:A和B内连接只返回两个表A和B的交集部分
四、redis分布式锁的缺点有哪些?
五、如何使用reddssion解决redis分布式锁的缺点?
六、rabbitmq如何保证消息不丢失?
七、springmvc的执行流程?
八、springcloud有哪些常用的组件?
九、hashMap底层原理和扩容机制
十、三次握手
十一、四次挥手
一、springboot的常用注解?
@SpringBootApplication
@ComponentScan
@EnableAutoConfiguration
@Configuration
@Value
@Component
二、springmvc常用注解?
@ResponseBody
@PathVariable
@RequestBody
@RestController
@RequestMapping
三、mysql的内连接和外连接有什么区别?
比如有两张表:A和B
内连接只返回两个表A和B的交集部分
SELECT column1, column2, ... FROM table1 JOIN table2 ON table1.column = table2.column;
外连接包括左外连接和右外连接:
左外连接返回A表中所有的数据和B表中匹配的数据,右外连接和左外连接刚好相反。
左外连接:
SELECT column1, column2, ... FROM table1 LEFT JOIN table2 ON table1.column = table2.column;
右外连接:
SELECT column1, column2, ... FROM table1 RIGHT JOIN table2 ON table1.column = table2.column;
其中,column1、column2等为需要查询的列名,table1、table2为需要连接的表名,column为连接两个表的共有字段。
总之,内连接是A与B的交集,外连接是A或B的其中一个的所有的表的数据与另外一个表匹配上的结果返回的数据
四、redis分布式锁的缺点有哪些?
1.死锁问题:如果加锁的客户端在执行完业务逻辑后未能及时释放锁,就会导致死锁问题
2.锁竞争问题:如果加锁的客户比较多,就会导致锁竞争问题,降低系统的性能
3.误删问题:错误的把不该删除的key给删除了
4.时效性问题:如果加锁的时间过长,就会导致锁的时效性问题,影响系统的响应速度
5.单点故障问题:如果Redis节点宕机,就会导致锁失效,影响系统的可用性
针对以上问题如何解决?
1、针对死锁问题:可以设置锁的过期时间,避免加锁的客户端在执行完业务逻辑后未能及时释放锁
2、针对锁竞争问题:可以使用分布式锁算法,如Redlock算法,避免多个客户端同时加锁,降低锁竞争的概率
3、误删问题:可以使用lua脚本,将判断锁是否存在和删除锁的操作原子化,避免在业务逻辑执行期间锁被误删的问题
4.针对时效性问题,可以根据业务特点和系统负载情况,设置合理的锁过期时间,避免锁过期时间过长,影响系统的响应速度。
5.针对单点故障问题,可以采用redis集群或sentinel哨兵高可用方案,避免单点故障问题,
同时可以采用多副本机制,避免数据丢失和锁时效问题
总之:可以通过设置合理的锁过期时间、使用Redlock算法、使用lua脚本保证原子性、redis集群和哨兵高可用机制可以有效防止redis分布式锁的缺点。
五、如何使用reddssion解决redis分布式锁的缺点?
1.高可用性:Reddison使用Redis Sentinel或Cluster模式,保证了Redis的高可用性,避免了单点故障的问题。
2.锁失效处理:Reddison在获取锁时,会设置一个有效期,在锁过期时会自动释放锁,避免了死锁的风险。
3.避免竞争:Reddison使用Redis的Lua脚本机制,在获取锁时只需要一次网络请求,避免了大量竞争带来的性能瓶颈。
4.自动续期:Reddison提供了自动续期功能,可以避免因为任务执行时间过长导致锁失效的问题。
在获取锁时,可以指定一个超时时间,如果任务执行时间超过了这个时间,Reddison会自动为锁续期,直到任务执行完成。
六、rabbitmq如何保证消息不丢失?
1、开启生产者和消费者确认机制
2、开启消息持久化机制,将消息持久化到磁盘
3、事务机制:在消息发送过程中,将发送消息和确认消息包装在一个事务中,
如果事务提交成功,消息就会被正确地发送到RabbitMQ,
否则事务回滚,消息不会发送到RabbitMQ,从而避免消息丢失。
4、镜像队列:镜像队列是指将队列的内容在多个节点上进行复制,保证队列的高可用性。
如果主节点出现故障,备用节点可以立即接管工作,避免消息丢失。
七、springmvc的执行流程?
1.客户端发送请求:客户端发送HTTP请求到服务器端,请求的URL与处理器映射器中的映射规则进行匹配。
2.处理器映射器匹配处理器:处理器映射器根据请求的URL匹配到对应的处理器,即Controller。
3.处理器适配器执行处理器:处理器适配器根据处理器的类型,调用对应的处理器方法,并将请求的参数传递给处理器方法。
4.处理器方法处理请求:处理器方法处理请求,生成ModelAndView对象,其中Model包含数据,View表示视图。
5.视图解析器解析视图:视图解析器根据视图名称解析出对应的视图对象。
6.视图渲染:视图渲染器将ModelAndView中的数据填充到视图中。
7.响应客户端:最终将渲染后的视图响应给客户端。
八、springcloud有哪些常用的组件?
1.Nacos:注册中心和配置中心
2.Ribbon:负载均衡策略,根据一种规则随机访问不同的微服务
3.Feign:rpc远程调用
4.Hystrix:服务容错组件,实现服务的容错和降级,避免服务出现故障时影响系统稳定
5.gateway:API网关组件,用于实现统一的API入口,提供路由、负载均衡、安全认证等功能。
6.Config:分布式配置管理组件,用于实现配置的集中管理和动态更新,避免在部署过程中修改配置文件的麻烦。
7.Stream:消息驱动组件,用于实现消息的生产和消费,支持多种消息中间件,如Kafka、RabbitMQ等。
8.Sleuth:分布式跟踪组件,用于实现分布式系统中的调用链跟踪和服务性能监控。
九、hashMap底层原理和扩容机制
1、hashMap的结构变化:
jdk1.8之前:数组+链表+链表头插法
jdk1.8之后:数组+链表+红黑数+链表尾插法
树化和反树化:链表长度大于8,树化为红黑树,链表长度小于6,反树化为链表,节约资源浪费
2、底层原理:
HashMap底层是一个哈希表数组,
每个数组元素是一个链表,链表中存储着哈希值相同的键值对。
当进行插入、删除、查找等操作时,首先需要根据键的哈希值计算出在数组中的位置,然后再在链表中进行操作。
3、扩容机制:
新建一个HashMap对象,没有元素,只有当首次Put的时候,会创建一个初始容量为16的数组
当HashMap中元素的数量超过了扩容阈值(默认为当前容量的75%),就会触发将数组二倍扩容操作。
并重新计算每个元素的位置,将元素分配到新的数组中。
同时,为了避免哈希冲突,扩容操作会将链表中的元素重新分配到新的链表中,使得每个链表中的元素数量尽量均匀。
4、put底层实现原理(重点):
HashMap的put方法用于向HashMap中添加键值对
4.1首先,根据键的哈希值计算出在数组中的位置,如果该位置上没有元素,就直接插入键值对,并返回null。
4.2如果该位置上已经有元素,就需要遍历链表,查找是否存在相同的键。
如果存在相同的键,则用新的值替换旧的值,并返回旧的值。
如果不存在相同的键,则将新的键值对插入到链表的末尾,并返回null。
5、HashMap底层使用了两个函数:
hashCode():用于计算键的哈希值。
hashCode()方法定义在Object类中,可以被所有对象调用,返回一个int类型的哈希值。
在HashMap中,每个键值对的键都需要计算哈希值,以便确定它在哈希表数组中的位置。
equals():用于判断键是否相等。
equals()方法也定义在Object类中,可以被所有对象调用,用于比较两个对象是否相等。
在HashMap中,当两个键的哈希值相等时,还需要调用equals()方法比较它们的值是否相等,以避免哈希冲突。
注意:在HashMap中,hashCode()和equals()方法是非常重要的,它们决定了键值对的插入、删除和查找的效率。
如果两个键的哈希值相等,但是equals()方法返回false,就会导致键值对插入到错误的位置,
从而影响HashMap的性能。
因此,在实现自定义类型的键时,需要重写hashCode()和equals()方法,依赖hashCode方法和equals方法保证键的唯一以确保它们的正确性和一致性。
十、三次握手
第一次:客户端向服务器发出连接请求,等待服务器端确认
第二次:服务器端向客户端返回一个响应,告诉客户端收到了请求
第三次:客户端向服务器再次发送确认消息,建立连接。

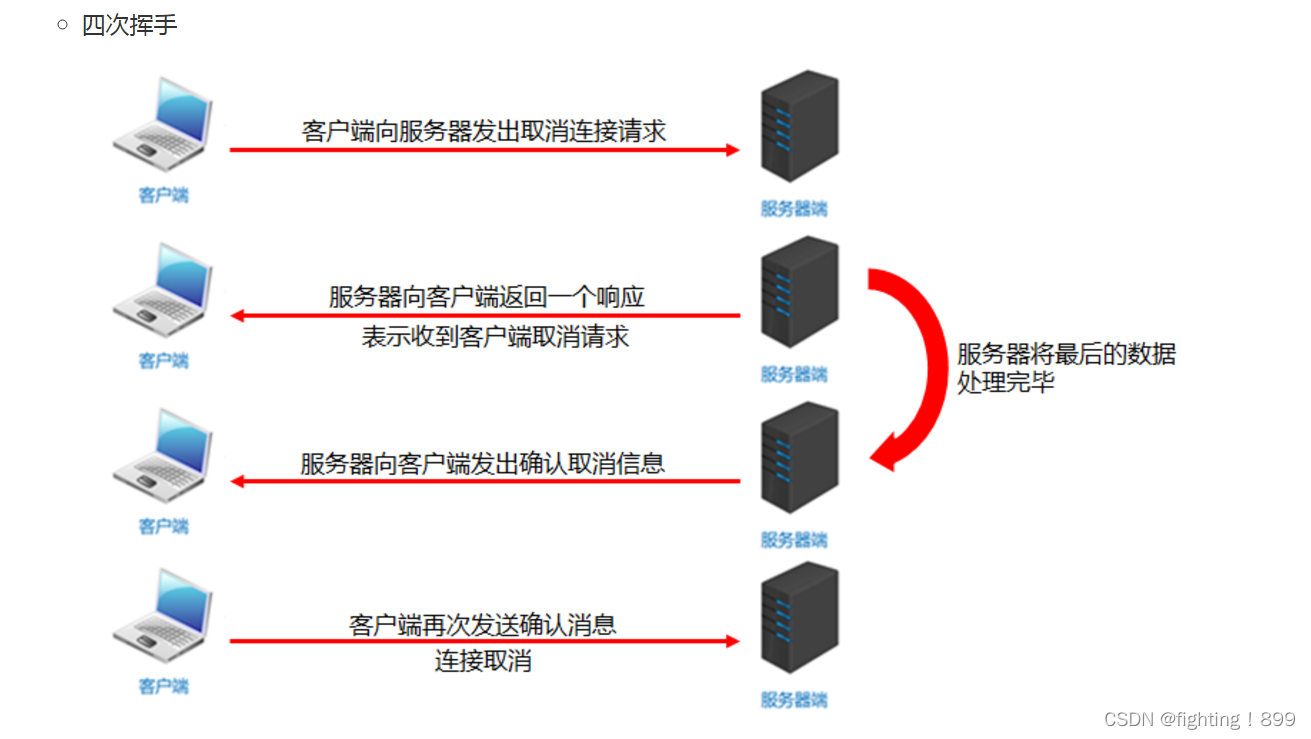
十一、四次挥手
第一次:客户端向服务器发出取消连接请求
第二次:服务器向客户端返回一个响应表示收到客户端取消申请
第三次:服务器向客户端发起确认取消信息
第四次:客户端再次发送确认信息,连接取消











![[JavaEE]----Spring03](https://img-blog.csdnimg.cn/abd888e6246e43fcb6a199e363d2300d.png)