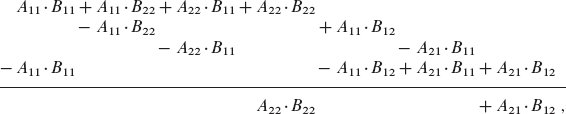什么是KMean算法?简要说明什么是KMean算法,以及KMean算法的应用场景。
KMeans是一种聚类算法,它将数据集分成K个不同的类别(簇),使得每个数据点都属于一个簇,并且每个簇的中心点(质心)代表了该簇的特征。其主要思想是通过不断迭代来最小化每个数据点到其所属簇的质心的距离平方和。
KMeans算法的步骤如下:
- 随机初始化K个质心。
- 对于每个数据点,计算其到每个质心的距离,将其分配到距离最近的质心所在的簇中。
- 对于每个簇,重新计算其质心。
- 重复执行第2和第3步,直到达到一定的迭代次数或簇的分配不再发生变化。

KMeans算法的应用场景很多,例如:
- 市场分析:通过分析消费者的购买行为来将其分组,以便针对不同群体采取不同的市场营销策略。
- 图像分割:将图像中的像素点根据其颜色或亮度等特征分为不同的区域,从而实现图像分割。
- 生物信息学:通过聚类来发现生物学实验数据中的模式和结构,例如发现蛋白质的结构、识别DNA序列中的基因等。
- 自然语言处理:对文本数据进行聚类,例如将新闻文章分成不同的主题类别。
利用KMean算法进行鸢尾花分类
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
# 加载鸢尾花数据
iris = load_iris()
# 构建数据框
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.Series(iris.target)
# 使用KMeans算法进行聚类
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X)
# 绘制聚类结果的散点图
plt.scatter(X.iloc[:, 0], X.iloc[:, 1], c=kmeans.labels_, cmap='viridis')
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.show()这段代码首先加载了鸢尾花数据,然后使用KMeans算法将数据聚成3个簇。最后,使用Matplotlib库绘制了聚类结果的散点图,其中不同颜色代表不同的簇。
效果:

KNN和KMean算法有哪些不同?
KNN和KMeans算法是两种不同的机器学习算法,它们的主要区别在于:
- 目标:KNN算法是一种监督学习算法,它的目标是预测一个新数据点的类别或数值属性。而KMeans算法是一种无监督学习算法,它的目标是将数据集分成K个簇,其中K是用户定义的参数。
- 输入数据:KNN算法使用已知类别的训练数据集来进行分类。KMeans算法使用未标记的数据集进行聚类,即只有特征向量,没有标签。
- 算法流程:KNN算法在训练时只是简单地将所有的训练数据保存下来,在分类时计算待分类数据与所有训练数据之间的距离,并找出距离最近的K个训练数据,然后根据这K个数据的类别进行分类。而KMeans算法在训练时需要先选择K个随机的中心点作为初始簇心,然后迭代地将每个数据点分配到最近的簇中,并重新计算簇心,直到收敛为止。
- 输出结果:KNN算法的输出是一个预测的类别或数值属性。KMeans算法的输出是K个簇,以及每个数据点所属的簇。
总之,KNN算法是一种分类算法,它将数据点分成不同的类别;而KMeans算法是一种聚类算法,它将数据点聚成不同的簇。