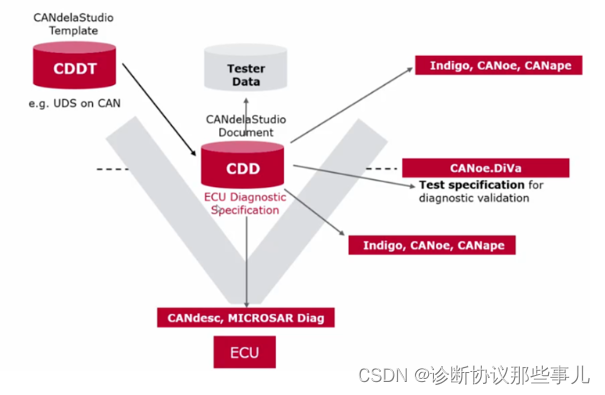
背景
现存的一些新视图合成的训练过程和渲染速度都比较慢,其原因是因为query point需要使用MLP编码,而且在一个采样空间中,存在很多无效的query point也要计算其density和color,从而出现很多冗余计算。
作者针对这个问题,提出了基于哈希的特征提取方式,通过反向求导更新哈希表中的特征向量。
作者陈述了非哈希式的优化方法的弊端,即便像八叉树等方法可以将训练缩短至几分钟,但仍有多余计算,可以进一步精简。

方法
作者提出了多分辨率哈希索引,每个分辨率有独立的哈希表,将索引出来的特征全部concat之后送入MLP,得到的重建效果和之前的方法无异,而且训练速度和渲染速度更快。将参数量最多降低至20倍。

该方法其实很简单。Nerf是将世界坐标和视线方向通过MLP编码得到特征,然后使用两个独立的MLP将特征映射为密度和颜色;hash encoding则直接根据世界坐标x去索引方格8个角落的特征,然后三线性插值得到x的特征。所谓的哈希表其实就是类似于nn.Embedding的东西,可以通过整数进行索引一个指定维度的特征。
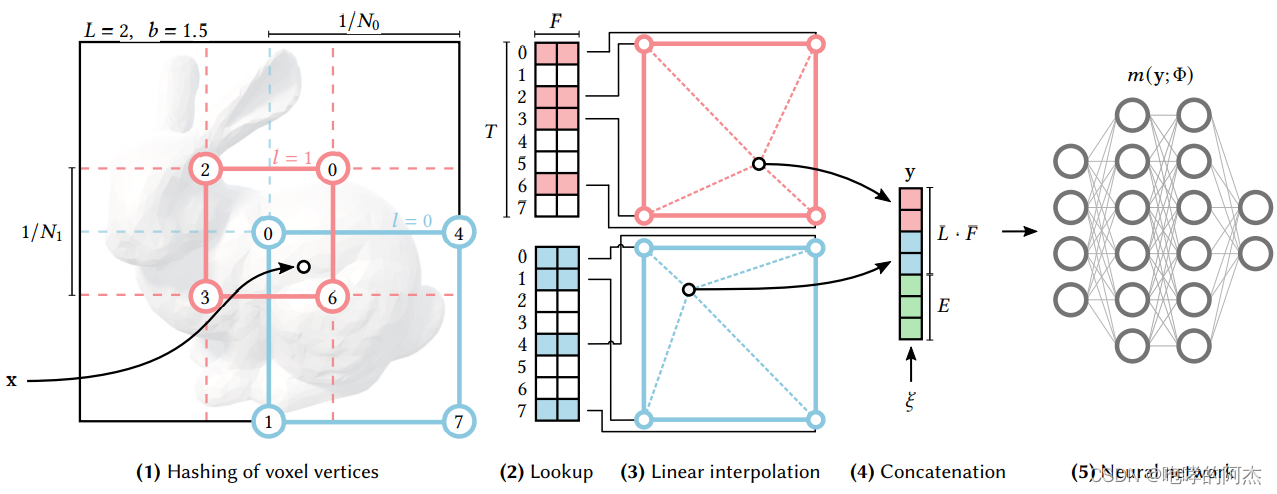 比较复杂的可能就是这是个多分辨率表结构,每个多分辨率都有独立的哈希表。分辨率的大小从一个coarse level到fine level,用一个b 作为scale。然后将多分辨率表中检索到特征concat到一起,得到所谓的哈希编码特征。
比较复杂的可能就是这是个多分辨率表结构,每个多分辨率都有独立的哈希表。分辨率的大小从一个coarse level到fine level,用一个b 作为scale。然后将多分辨率表中检索到特征concat到一起,得到所谓的哈希编码特征。
该特征可以用很多应用,比如论文列举了4个应用
- Gigapixel Image Approximation
- Signed Distance Functions
- Neural Radiance Caching
- Neural Radiance and Density Fields (NeRF)
源码浅析
论文地址
官方代码
hashNerf
torch-NGP
hash表的建立
self.embeddings = nn.ModuleList([nn.Embedding(2**self.log2_hashmap_size, \
self.n_features_per_level) for i in range(n_levels)])
三线性插值
def trilinear_interp(self, x, voxel_min_vertex, voxel_max_vertex, voxel_embedds):
'''
x: B x 3
voxel_min_vertex: B x 3
voxel_max_vertex: B x 3
voxel_embedds: B x 8 x 2
'''
# source: https://en.wikipedia.org/wiki/Trilinear_interpolation
weights = (x - voxel_min_vertex)/(voxel_max_vertex-voxel_min_vertex) # B x 3
# step 1
# 0->000, 1->001, 2->010, 3->011, 4->100, 5->101, 6->110, 7->111
c00 = voxel_embedds[:,0]*(1-weights[:,0][:,None]) + voxel_embedds[:,4]*weights[:,0][:,None]
c01 = voxel_embedds[:,1]*(1-weights[:,0][:,None]) + voxel_embedds[:,5]*weights[:,0][:,None]
c10 = voxel_embedds[:,2]*(1-weights[:,0][:,None]) + voxel_embedds[:,6]*weights[:,0][:,None]
c11 = voxel_embedds[:,3]*(1-weights[:,0][:,None]) + voxel_embedds[:,7]*weights[:,0][:,None]
# step 2
c0 = c00*(1-weights[:,1][:,None]) + c10*weights[:,1][:,None]
c1 = c01*(1-weights[:,1][:,None]) + c11*weights[:,1][:,None]
# step 3
c = c0*(1-weights[:,2][:,None]) + c1*weights[:,2][:,None]
return c