文章目录
- 前言
- 1、创建第一个线程
- 2、线程对象的生命周期、等待和分离
- 3、线程创建的多种方式
- 4、互斥量
- 4.1 独占的互斥量std::mutex
- 4.2 递归独占互斥量recursive_mutex
- 4.3 带超时的互斥量std::timed_mutex和std::recursive_timed_mutex
- 4.4 std::lock_guard和std::unique_lock
- 5、call_once/once_flag的使用
- 6、条件变量
前言
C++11之前,C++语言没有对并发编程提供语言级别的支持,这使得我们在编程写可移植的并发程序时,存在诸多不便。现在C++11增加了线程以及线程相关的类,很方便地支持了并发编程,使得编写多线程程序的可移植性得到了很大的提高
1、创建第一个线程
//创建线程需要引入头文件thread
#include<thread>
#include<iostream>
void ThreadMain()
{
cout << "begin thread main" << endl;
}
int main()
{
//创建新线程t并启动
thread t(ThreadMain);
//主线程(main线程)等待t执行完毕
if (t.joinable()) //必不可少
{
//等待子线程退出
t.join(); //必不可少
}
return 0;
}
我们都知道,对于一个单线程来说,也就main线程或者叫做主线程,所有的工作都是由main线程去完成的。而在多线程环境下,子线程可以分担main线程的工作压力,在多个CPU下,实现真正的并行操作。
在上述代码中,可以看到main线程创建并启动了一个新线程t,由新线程t去执行ThreadMain()函数,jion函数将会把main线程阻塞住,知道新线程t执行结束,如果新线程t有返回值,返回值将会被忽略
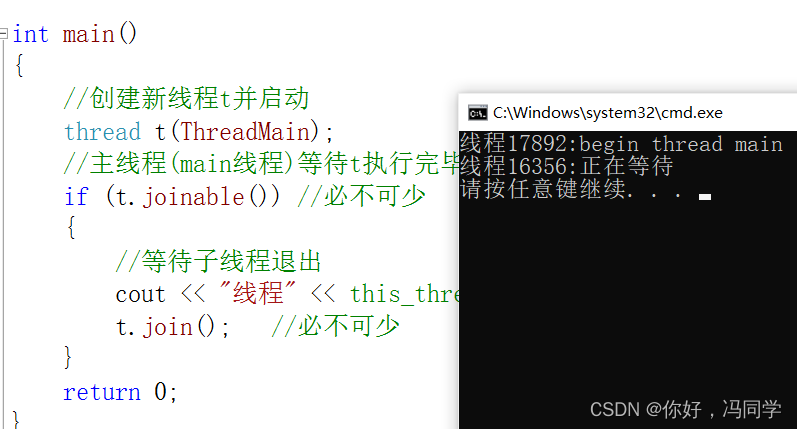
我们可以通过函数this_thread::get_id()来判断是t线程还是main线程执行任务
void ThreadMain()
{
cout << "线程" << this_thread::get_id()<< ":begin thread main" << endl;
}
int main()
{
//创建新线程t并启动
thread t(ThreadMain);
//主线程(main线程)等待t执行完毕
if (t.joinable()) //必不可少
{
//等待子线程退出
cout << "线程" << this_thread::get_id() << ":正在等待" << endl;
t.join(); //必不可少
}
return 0;
}
执行结果:
2、线程对象的生命周期、等待和分离
void func()
{
cout << "do func" << endl;
}
int main()
{
thread t(func);
return 0;
}
上诉代码运行可能会抛出异常,因为线程对象t可能先于线程函数func结束,应该保证线程对象的生命周期在线程函数func执行完时仍然存在
为了防止线程对象的生命周期早于线程函数fun结束,可以使用线程等待join
void func()
{
while (true)
{
cout << "do work" << endl;
this_thread::sleep_for(std::chrono::seconds(1));//当前线程睡眠1秒
}
}
int main()
{
thread t(func);
if (t.joinable())
{
t.join();//main线程阻塞
}
return 0;
}
虽然使用join能有效防止程序的崩溃,但是在某些情况下,我们并不希望main线程通过join被阻塞在原地,此时可以采用detach进行线程分离。但是需要注意:detach之后main线程就无法再和子线程发生联系了,比如detach之后就不能再通过join来等待子线程,子线程任何执行完我们也无法控制了
void func()
{
int count = 0;
while (count < 3)
{
cout << "do work" << endl;
count++;
this_thread::sleep_for(std::chrono::seconds(1));//当前线程睡眠1秒
}
}
int main()
{
thread t(func);
t.detach();
this_thread::sleep_for(std::chrono::seconds(1));//当前线程睡眠1秒
cout << "线程t分离成功" << endl;
return 0;
}
执行结果:

3、线程创建的多种方式
线程的创建和执行,无非是给线程指定一个入口函数嘛,例如main线程的入口函数就main()函数,前面编写的子线程的入口函数是一个全局函数。除了这些之外线程的入口函数还可以是函数指针、仿函数、类的成员函数、lambda表达式等,它们都有一个共同的特点:都是可调用对象。线程的入口函数指定,可以为任意一个可调用对象。
普通函数作为线程的入口函数
void func()
{
cout << "hello world" << endl;
}
int main()
{
thread t(func);
if (t.joinable())
{
t.join();
}
return 0;
}
类的成员函数作为线程的入口函数
class ThreadMain
{
public:
ThreadMain() {}
virtual ~ThreadMain(){}
void SayHello(std::string name)
{
cout << "hello " << name << endl;
}
};
int main()
{
ThreadMain obj;
thread t(&ThreadMain::SayHello, obj, "fl");
thread t1(&ThreadMain::SayHello, &obj, "fl");
t.join();
t1.join();
return 0;
}
t和t1在传递参数时存在不同:
- t是用对象obj调用线程函数的语句,即线程函数将在obj对象的上下文中运行。这里obj是通过值传递给线程构造函数的,因此在线程中使用的是对象obj的一个副本。这种方式适用于类定义在局部作用域中时,需要将其传递给线程的情况。
- t1是使用对象的指针&obj调用线程函数的语句,即线程函数将在对象obj的指针所指向的上下文中运行。这里使用的是对象obj的指针,因此在线程中使用的是原始的obj对象。这种方式适用于类定义在全局或静态作用域中时,需要将其传递给线程的情况。
如果需要在类的成员函数中,创建线程,以类中的另一个成员函数作为入口函数,再执行
class ThreadMain
{
public:
ThreadMain() {}
virtual ~ThreadMain(){}
void SayHello(std::string name)
{
cout << "hello " << name << endl;
}
void asycSayHello(std::string name)
{
thread t(&ThreadMain::SayHello, this, name);
if (t.joinable())
{
t.join();
}
}
};
int main()
{
ThreadMain obj;
obj.asycSayHello("fl");
return 0;
}
在asycSayHello的成员函数中,如果没有传递this指针,会导致编译不通过

原因就是参数列表不匹配,因此需要我们显示的传递this指针,表示以本对象的成员函数作为参数的入口函数
lambda表达式作为线程的入口函数
int main()
{
thread t([](int i){
cout << "test lambda i = " << i << endl;
}, 123);
if (t.joinable())
{
t.join();
}
return 0;
}
执行结果:

在类的成员函数中,以lambda表达式作为线程的入口函数
class TestLmadba
{
public:
void Start()
{
thread t([this](){
cout << "name is " << this->name << endl;
});
if (t.joinable())
{
t.join();
}
}
private:
std::string name = "fl";
};
int main()
{
TestLmadba test;
test.Start();
return 0;
}
在类的成员函数中,以lambda表达式作为线程的入口函数,如果需要访问兑现的成员变量,也需要传递this指针
仿函数作为线程的入口函数
class Mybusiness
{
public:
Mybusiness(){}
virtual ~Mybusiness(){}
void operator()(void)
{
cout << "Mybusiness thread id is " << this_thread::get_id() << endl;
}
void operator()(string name)
{
cout << "name is " << name << endl;
}
};
int main()
{
Mybusiness mb;
thread t(mb);
if (t.joinable())
{
t.join();
}
thread t1(mb, "fl");
if (t1.joinable())
{
t1.join();
}
return 0;
}
执行结果:

线程t以无参的仿函数作为函数入口,而线程t1以有参的仿函数作为函数入口
函数指针作为线程的入口函数
void func()
{
cout << "thread id is " << this_thread::get_id() << endl;
}
void add(int a, int b)
{
cout << a << "+" << b << "=" << a + b << endl;
}
int main()
{
//采用C++11扩展的using来定义函数指针类型
using FuncPtr = void(*)();
using FuncPtr1 = void(*)(int, int);
//使用FuncPtr来定义函数指针变量
FuncPtr ptr = &func;
thread t(ptr);
if (t.joinable())
{
t.join();
}
FuncPtr1 ptr1 = add;
thread t1(ptr1, 1, 10);
if (t1.joinable())
{
t1.join();
}
return 0;
}
执行结果:
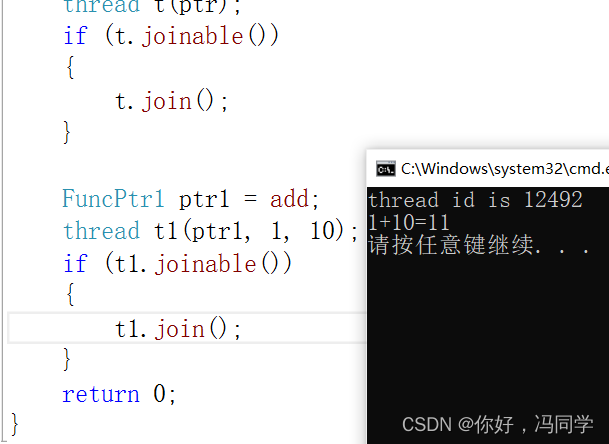
function和bind作为线程的入口函数
void func(string name)
{
cout << this_thread::get_id() << ":name is " << name << endl;
}
int main()
{
function<void(string)> f(func);
thread t(f, "fl");
if (t.joinable())
{
t.join();
}
thread t1(bind(func, "fl"));
if (t1.joinable())
{
t1.join();
}
return 0;
}
执行结果:

线程不能拷贝和复制,但可以移动
//赋值操作
void func(string name)
{
cout << this_thread::get_id() << ":name is " << name << endl;
}
int main()
{
thread t1(func, "fl");
thread t2 = t1;
thread t3(t1);
return 0;
}
编译报错:

在线程内部,已经将线程的赋值和拷贝操作delete掉了,所以无法调用到

//移动操作
void func(string name)
{
cout << this_thread::get_id() << ":name is " << name << endl;
}
int main()
{
thread t1(func, "fl");
thread t2(std::move(t1));
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
return 0;
}
执行结果:
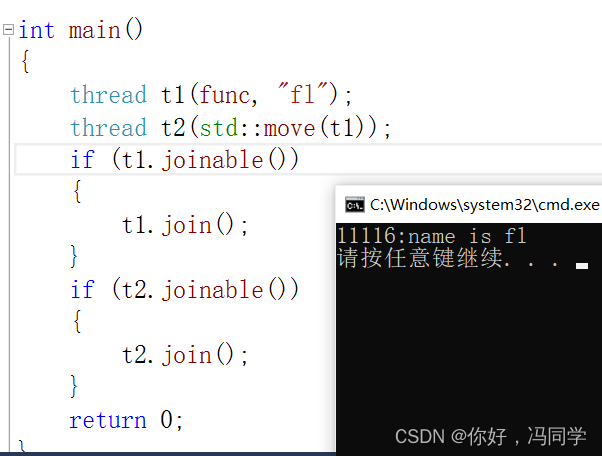
线程被移动之后,线程对象t1将不代表任何线程了,可以通过调试观察到

4、互斥量
当多个线程同时访问同一个共享资源时,如果不加以保护或者不做任何同步操作,可能出现数据竞争或不一致的状态,导致程序运行出现问题。
为了保证所有的线程都能够正确地、可预测地、不产生冲突地访问共享资源,C++11提供了互斥量。
互斥量是一种同步原语,是一种线程同步手段,用来保护多线程同时访问的共享数据。互斥量就是我们平常说的锁
C++11中提供了4种语义的互斥量
- std::mutex:独占的互斥量,不能递归
- std::timed_mutex:带超时的独占互斥量,不能递归使用
- std::recursive_mutex:递归互斥量,不能带超时功能
- std::recursive_timed_mutex:带超时的递归互斥量
4.1 独占的互斥量std::mutex
这些互斥量的接口基本类似,一般用法是通过lock()方法来阻塞线程,知道获得互斥量的所有权为止。在线程获得互斥量并完成任务之后,就必须使用unlock()来解除对互斥量的占用,lock()和unlock()必须成对出现。try_lock()尝试锁定互斥量,如果成功则返回true,失败则返回false,它是非阻塞的。
int num = 0;
std::mutex mtx;
void func()
{
for (int i = 0; i < 100; ++i)
{
mtx.lock();
num++;
mtx.unlock();
}
}
int main()
{
thread t1(func);
thread t2(func);
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
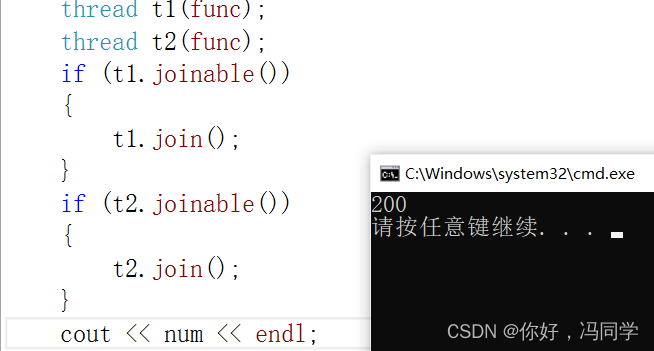
cout << num << endl;
return 0;
}
执行结果:
使用lock_guard可以简化lock/unlock的写法,同时也更安全,因为lock_guard在构造时会自动锁定互斥量,而在退出作用域后进行析构时自动解锁,从而保证了互斥量的正确操作,避免忘记unlock操作,因此,尽量用lock_guard。lock_guard用到了RALL技术,这种技术在类的构造函数中分配资源,在析构函数中释放资源,保证资源在出了作用域之后就释放。上面的例子使用lock_guard后会更简介,代码如下:
void func()
{
for (int i = 0; i < 100; ++i)
{
lock_guard<mutex> lock(mtx);
num++;
}
}
一般来说,当某个线程执行操作完毕后,释放锁,然后需要等待几十毫秒,让其他线程也去获取锁资源,也去执行操作。如果不进行等待的话,可能当前线程释放锁后,又立马获取了锁资源,会导致其他线程出现饥饿。
4.2 递归独占互斥量recursive_mutex
递归锁允许同一线程多次获得该互斥锁,可以用来解决同一线程需要多次获取互斥量时死锁的问题。在以下代码中,一个线程多次获取同一个互斥量时会发生死锁:
class Complex
{
public:
std::mutex mtx;
void SayHello()
{
lock_guard<mutex> lock(mtx);
cout << "Say Hello" << endl;
SayHi();
}
void SayHi()
{
lock_guard<mutex> lock(mtx);
cout << "say Hi" << endl;
}
};
int main()
{
Complex complex;
complex.SayHello();
return 0;
}
执行结果:

这个例子运行起来就发生了死锁,因为在调用SayHello时获取了互斥量,之后再调用SayHI又要获取相同的互斥量,但是这个互斥量已经被当前线程获取 ,无法释放,这时就会产生死锁,导致程序崩溃。
要解决这里的死锁问题,最简单的方法就是采用递归锁:std::recursive_mutex,它允许同一个线程多次获取互斥量
class Complex
{
public:
std::recursive_mutex mtx;//同一线程可以多次获取同一互斥量,不会发生死锁
void SayHello()
{
lock_guard<recursive_mutex> lock(mtx);
cout << "Say Hello" << endl;
SayHi();
}
void SayHi()
{
lock_guard<recursive_mutex> lock(mtx);
cout << "say Hi" << endl;
}
};
执行结果:
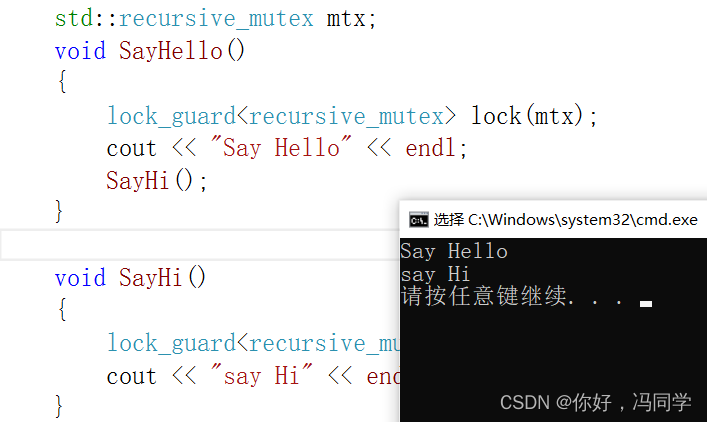
需要注意的是尽量不要使用递归锁比较好,主要原因如下:
1、需要用到递归锁定的多线程互斥量处理往往本身就是可以简化的,允许递归互斥量很容易放纵复杂逻辑的产生,而非导致一些多线程同步引起的晦涩问题
2、递归锁的效率比非递归锁的效率低
3、递归锁虽然允许同一个线程多次获得同一个互斥量,但可重复的最大次数并为具体说明,一旦超过一定次数,再对lock进行调用就会抛出std::system错误
4.3 带超时的互斥量std::timed_mutex和std::recursive_timed_mutex
std::timed_mutex是超时的独占锁,srd::recursive_timed_mutex是超时的递归锁,主要用在获取锁时增加超时锁等待功能,因为有时不知道获取锁需要多久,为了不至于一直在等待获互斥量,就设置一个等待超时时间,在超时时间后还可做其他事。
std::timed_mutex比std::mutex多了两个超时获取锁的接口:try_lock_for和try_lock_until,这两个接口是用来设置获取互斥量的超时时间,使用时可以用一个while循环去不断地获取互斥量。
std::timed_mutex mtx;
void work()
{
chrono::milliseconds timeout(100);
while (true)
{
if (mtx.try_lock_for(timeout))
{
cout << this_thread::get_id() << ": do work with the mutex" << endl;
this_thread::sleep_for(chrono::milliseconds(250));
mtx.unlock();
}
else
{
cout << this_thread::get_id() << ": do work without the mutex" << endl;
this_thread::sleep_for(chrono::milliseconds(100));
}
}
}
int main()
{
thread t1(work);
thread t2(work);
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
return 0;
}
执行结果:

在上面的例子中,通过一个while循环不断地去获取超时锁,如果超时还没有获取到锁时就休眠100毫秒,再继续获取锁。
相比std::timed_mutex,std::recursive_timed_mutex多了递归锁的功能,允许同一个线程多次获得互斥量。std::recursive_timed_mutex和std::recursive_mutex的用法类似,可以看作在std::recursive_mutex的基础上增加了超时功能
4.4 std::lock_guard和std::unique_lock
lock_guard和unique_lock的功能完全相同,主要差别在于unique_lock更加灵活,可以自由的释放mutex,而lock_guard需要等到生命周期结束后才能释放。
它们的构造函数中都有第二个参数
unique_lock:

lock_guard:

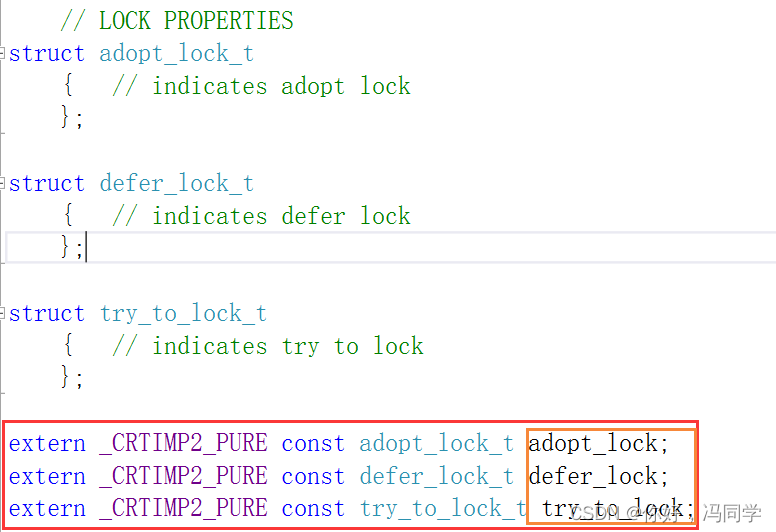
可以从源码中看到,unique_lock的构造函数中,第二个参数的种类有三种,分别是adopt_lock,defer_lock和try_to_lock。lock_guard的构造函数中,第二个参数的种类只有一种,adopt_lock
这些参数的含义分别是:
adopt_lock:互斥量已经被lock,构造函数中无需再lock(lock_ guard与unique_lock通用)
defer_lock:互斥量稍后我会自行lock,不需要在构造函数中lock,只初始化一个没有加锁的mutex
try_to_lock:主要作用是在不阻塞线程的情况下尝试获取锁,如果互斥量当前未被锁定,则返回std::unique_lock对象,该对象拥有互斥量并且已经被锁定。如果互斥量当前已经被另一个线程锁定,则返回一个空的std::unique_lock对象
mutex mtx;
void func()
{
//mtx.lock();//需要加锁,否则在lock的生命周期结束后,会自动解锁,则会导致程序崩溃
unique_lock<mutex> lock(mtx, std::adopt_lock);
cout << this_thread::get_id() << " do work" << endl;
}
int main()
{
thread t(func);
if (t.joinable())
{
t.join();
}
return 0;
}
执行结果:
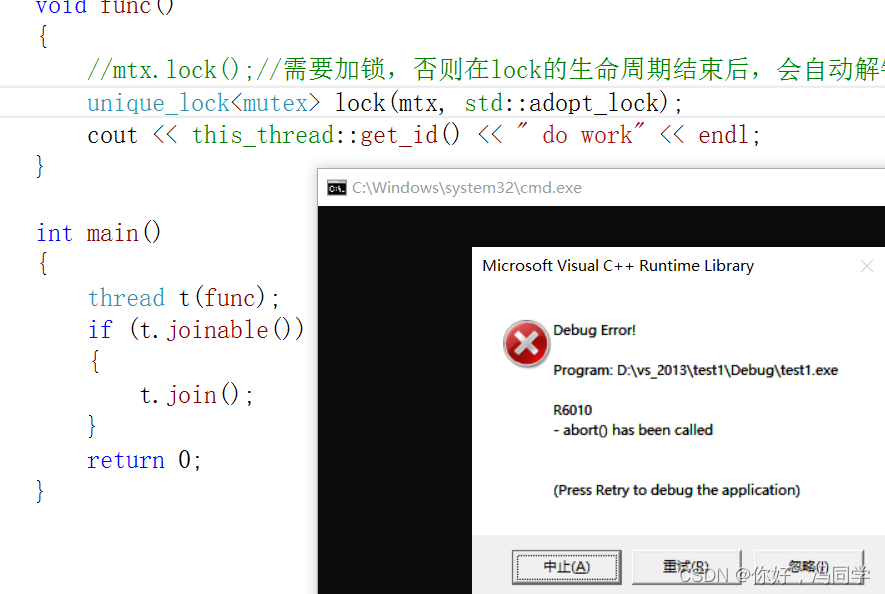
adopt_lock就表示构造unique_lock<mutex>时,认为mutex已经加过锁了,就不会再加锁了,它就把加锁的权限和时机交给了我们,由我们自己控制
mutex mtx;
void func()
{
while (true)
{
unique_lock<mutex> lock(mtx, std::defer_lock);
cout << "func thread id is " << this_thread::get_id() << endl;
this_thread::sleep_for(chrono::milliseconds(500));
}
}
int main()
{
thread t1(func);
thread t2(func);
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
return 0;
}
执行结果:
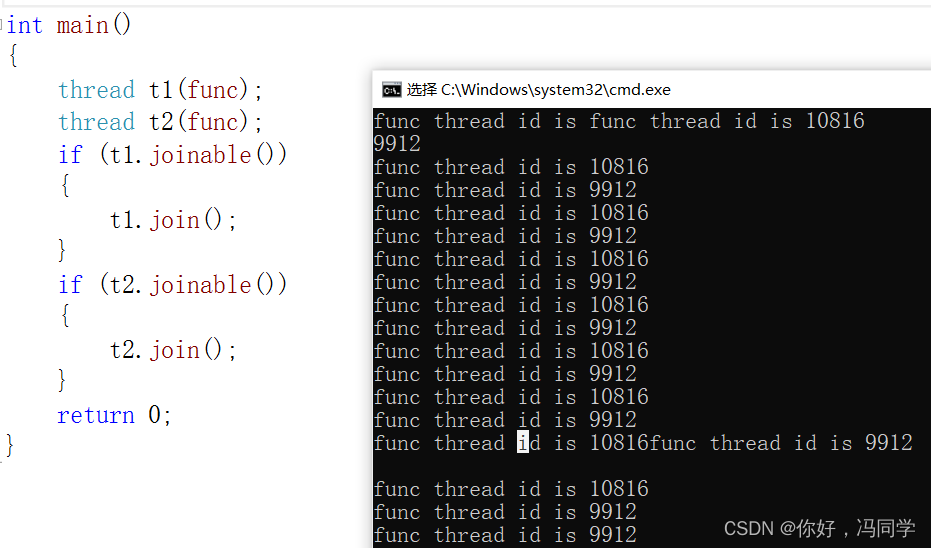
本来我们的意愿是t1和t2每个时刻只能有一个线程打印"func thread id is…",但是实际上却发生了竞争的关系,原因就在于defer_lock在构造unique_lock<mutex>时,认为mutex在后面会加锁,也就没有加锁,所以打印结果才发生混乱,因此需要我们手动改进一下
void func()
{
while (true)
{
unique_lock<mutex> lock(mtx, std::defer_lock);
lock.lock();
cout << "func thread id is " << this_thread::get_id() << endl;
this_thread::sleep_for(chrono::milliseconds(500));
//lock.unlock(); //可以加,也可以不加
//因为内部有一个标准为,如果我们自己手动解锁了,由于标志位的改变,在调用lock的析构函数时,就不会进行解锁操作
}
}
执行结果:
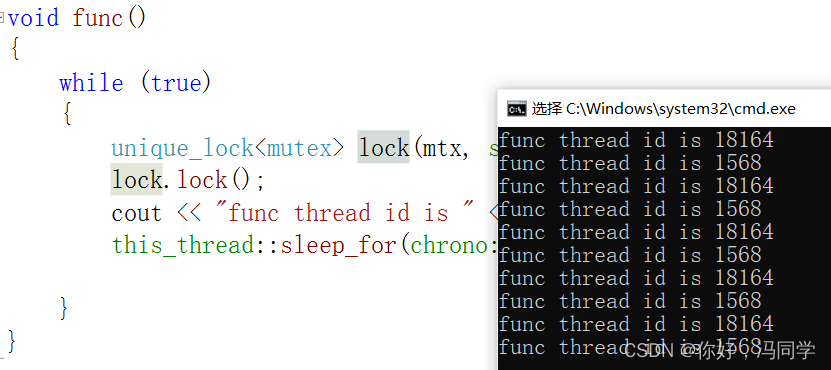
5、call_once/once_flag的使用
为了保证在多线程环境中某个函数仅被调用一次,比如,需要在初始化某个对象,而这个对象只能初始化一次时,就可以用std::call_once来保证函数在多线程环境中只能被调用一次。使用std::call_once时,需要一个once_flag作为call_once的入参,用法比较简单
call_once函数模板

在使用call_once时,第一个参数是类型为once_flag的标志位,第二个参数是一个可调用对象,第三个为可变参数,表示的可调用对象中的参数
std::once_flag flag;
void do_once()
{
std::call_once(flag, [](){
cout << "call once" << endl;
});
}
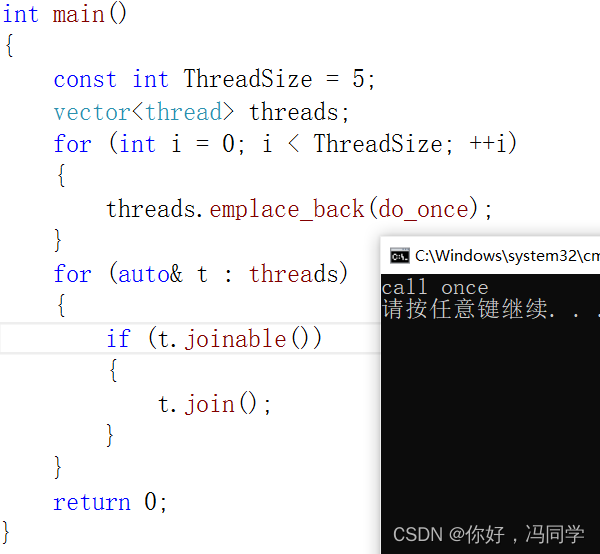
int main()
{
const int ThreadSize = 5;
vector<thread> threads;
for (int i = 0; i < ThreadSize; ++i)
{
threads.emplace_back(do_once);
}
for (auto& t : threads)
{
if (t.joinable())
{
t.join();
}
}
return 0;
}
执行结果:
6、条件变量
条件变量是C++11提供的另外一种用于等待的同步机制,它能够阻塞一个或者多个贤臣,直到收到另一个线程发出的通知或者超时,才会唤醒当前阻塞的线程。条件变量需要和互斥量配合起来使用。C++11提供了两种条件变量:
- condition_valuable,配合std::unique<mutex>进行wait操作
- condition_valuable_any,和任意带有lock,unlock语义的mutex搭配使用,比较灵活,但效率比condition_valuable差一些
可以看到condition_valuable_any比condition_valuable更灵活,因为它通用,对所有的锁都适用,而condition_valuable的性能更好。我们应该根据具体的应用场景来选择合适的条件变量
条件变量的使用条件如下:
- 拥有条件变量的线程获取互斥量
- 循环检测某个条件,如果条件不满足,则阻塞直到条件满足;如果条件满足,则向下执行
- 某个线程满足条件执行完毕之后调用notify_onc或者notify_all唤醒一个或者所有等待的线程
一个简单的生产者消费者模型
mutex mtx;
condition_variable_any notEmpty;//没满的条件变量
condition_variable_any notFull;//不为空的条件变量
list<string> list_; //缓冲区
const int custom_threads_size = 3;//消费者的数量
const int produce_threads_size = 4;//生产者的数量
const int max_size = 10;
void produce(int i)
{
while (true)
{
lock_guard<mutex> lock(mtx);
notEmpty.wait(mtx, []{
return list_.size() != max_size;
});
stringstream ss;
ss << "生产者" << i << "生产的东西";
list_.push_back(ss.str());
notFull.notify_one();
}
}
void custome(int i)
{
while (true)
{
lock_guard<mutex> lock(mtx);
notFull.wait(mtx, []{
return !list_.empty();
});
cout << "消费者" << i << "消费了 " << list_.front() << endl;
list_.pop_front();
notEmpty.notify_one();
}
}
int main()
{
vector<std::thread> producer;
vector<std::thread> customer;
for (int i = 0; i < produce_threads_size; ++i)
{
producer.emplace_back(produce, i);
}
for (int i = 0; i < custom_threads_size; ++i)
{
customer.emplace_back(custome, i);
}
for (int i = 0; i < produce_threads_size; ++i)
{
producer[i].join();
}
for (int i = 0; i < custom_threads_size; ++i)
{
customer[i].join();
}
return 0;
}
在上述案例中,list<string> list_是一个临界资源,无论是生产者生产数据,还是消费者消费数据,都要往list_中插入数据或者删除数据,为了防止出现数据竞争或不一致的状态,导致程序运行出现问题,因为每次操作list_时都需要进行加锁操作。
当list_没有满的情况下,生产者可以生产数据,如果满了,则会阻塞在条件变量notFull下,需要消费者通过notify_one()随机唤醒一个生产者。
当list_不为空的情况下。消费者可以消费数据,如果空了,则会阻塞在条件变量notEmpty下,需要生产者通过notify_one()随机唤醒一个消费者。