深度学习领域技术的飞速发展,给人们的生活带来了很大改变。例如,智能语音助手能够与人类无障碍地沟通,甚至在视频通话时可以提供实时翻译;将手机摄像头聚焦在某个物体上,该物体的相关信息就会被迅速地反馈给使用者;在购物网站上浏览商品时,机器也在同时分析着用户的偏好,并及时个性化地推荐用户可能感兴趣的商品。原先以为只有人类才能做到的事,现在机器也能毫无差错地完成,甚至超越人类,这显然与深度学习的发展密不可分,技术正引领人类社会走向崭新的世界。
PyTorch是当前主流深度学习框架之一,其设计追求最少的封装、最直观的设计,其简洁优美的特性使得PyTorch代码更易理解,对新手非常友好。
本系列推文以深度学习为主题,覆盖基础篇到实战篇的知识点。本文主要介绍深度学习领域中计算机视觉部分。
1、计算机视觉-定义
计算机视觉是使用计算机及相关设备对生物视觉的一种模拟。它的主要任务是通过对采集的图片或视频进行处理以获得相应场景的三维信息。计算机视觉是一门关于如何运用照相机和计算机获取人们所需的、被拍摄对象的数据与信息的学问。形象地说,就是给计算机安装上眼睛(照相机)和大脑(算法),让计算机能够感知环境。
2、基本任务
计算机视觉的基本任务包括图像处理、模式识别或图像识别、景物分析、图像理解等。除了图像处理和模式识别之外,它还包括空间形状的描述、几何建模以及认识过程。实现图像理解是计算机视觉的终极目标。下面举例说明图像处理、模式识别和图像理解。
图像处理技术可以把输入图像转换成具有所希望特性的另一幅图像。例如,可通过处理使输出图像有较高的信噪比,或通过增强处理突出图像的细节,以便于操作员的检验。在计算机视觉研究中经常利用图像处理技术进行预处理和特征抽取。
模式识别技术根据从图像抽取的统计特性或结构信息,把图像分成预定的类别。例如,文字识别或指纹识别。在计算机视觉中,模式识别技术经常用于对图像中的某些部分(例如分割区域)的识别和分类。
图像理解技术是对图像内容信息的理解。给定一幅图像,图像理解程序不仅描述图像本身,而且描述和解释图像所代表的景物,以便对图像代表的内容做出决定。在人工智能研究的初期经常使用景物分析这个术语,以强调二维图像与三维景物之间的区别。图像理解除了需要复杂的图像处理以外,还需要具有关于景物成像的物理规律的知识以及与景物内容有关的知识。
3、现代深度学习
计算机视觉里经常使用的卷积神经网络,即CNN,是一种对人脑比较精准的模拟。
人脑在识别图片的过程中,并不是对整幅图同时进行识别,而是感知图片中的局部特征,之后再将局部特征综合起来得到整幅图的全局信息。卷积神经网络模拟了这一过程,其卷积层通常是堆叠的,低层的卷积层可以提取到图片的局部特征,例如角、边缘、线条等,高层的卷积层能够从低层的卷积层中学到更复杂的特征,从而实现对图片的分类和识别。
卷积就是两个函数之间的相互关系。在计算机视觉里面,可以把卷积当作一个抽象的过程,就是把小区域内的信息统计抽象出来。例如,对于一张爱因斯坦的照片,可以学习n个不同的卷积和函数,然后对这个区域进行统计。可以用不同的方法统计,比如可以着重统计中央,也可以着重统计周围,这就导致统计的函数的种类多种多样,以达到可以同时学习多个统计的累积和。
图1演示了如何从输入图像得到最后的卷积,生成相应的图。首先用学习好的卷积和对图像进行扫描,然后每个卷积和会生成一个扫描的响应图,称为响应图或者称为特征图(feature map)。如果有多个卷积和,就有多个特征图。也就是说,从一个最开始的输入图像(RGB三个通道)可以得到256个通道的feature map,因为有256个卷积和,每个卷积和代表一种统计抽象的方式。
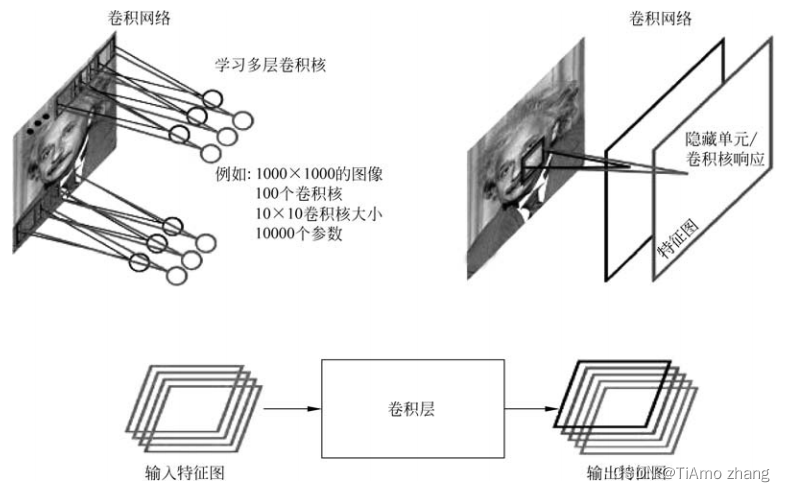
■ 图1卷积
在卷积神经网络中,除了卷积层,还有一种叫池化的操作。池化操作在统计上的概念更明确,就是一种对一个小区域内求平均值或者求最大值的统计操作。
带来的结果是,池化操作会将输入的feature map的尺寸减小,让后面的卷积操作能够获得更大的视野,也降低了运算量,具有加速的作用。
在如图2所示这个例子里,池化层对每个大小为2×2px的区域求最大值,然后把最大值赋给生成的feature map的对应位置。如果输入图像的大小是100×100px,那输出图像的大小就会变成50×50px,feature map变成了原来的1/4。同时保留的信息是原来2×2区域里面最大的信息。
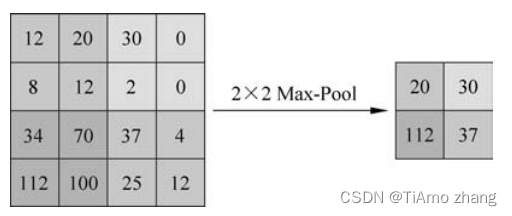
■ 图2池化
LeNet网络如图3所示。Le是人工智能领域先驱Lecun名字的简写。LeNet是许多深度学习网络的原型和基础。在LeNet之前,人工神经网络层数都相对较少,而LeNet 5层网络突破了这一限制。LeNet在1998年即被提出,Lecun用这一网络进行字母识别,达到了非常好的效果。

■ 图3LeNet
LeNet网络输入图像是大小为32×32px的灰度图,第一层经过了一组卷积和,生成了6个28×28px的feature map,然后经过一个池化层,得到6个14×14px的feature map,然后再经过一个卷积层,生成了16个10×10px的卷积层,再经过池化层生成16个5×5px的feature map。
这16个大小为5×5px的feature map再经过3个全连接层,即可得到最后的输出结果。输出就是标签空间的输出。由于设计的是只对0~9进行识别,所以输出空间是10,如果要对10个数字再加上52个大、小写字母进行识别的话,输出空间就是62。向量各维度的值代表“图像中元素等于该维度对应标签的概率”,即若该向量第一维度输出为0.6,即表示图像中元素是“0”的概率是0.6。那么该62维向量中值最大的那个维度对应的标签即为最后的预测结果。62维向量里,如果某一个维度上的值最大,它对应的那个字母和数字就是预测结果。
从1998年开始的15年间,深度学习领域在众多专家学者的带领下不断发展壮大。遗憾的是,在此过程中,深度学习领域没有产生足以轰动世人的成果,导致深度学习的研究一度被边缘化。直到2012年,深度学习算法在部分领域取得不错的成绩,而压在骆驼背上的最后一根稻草就是AlexNet。
AlexNet由多伦多大学提出,在ImageNet比赛中取得了非常好的效果。AlexNet识别效果超过了当时所有浅层的方法。经此一役,AlexNet在此后被不断地改进、应用。同时,学术界和工业界认识到了深度学习的无限可能。
AlexNet是基于LeNet的改进,它可以被看作LeNet的放大版,如图4所示。AlexNet的输入是一个大小为224×224px的图片,输入图像在经过若干个卷积层和若干个池化层后,最后经过两个全连接层泛化特征,得到最后的预测结果。
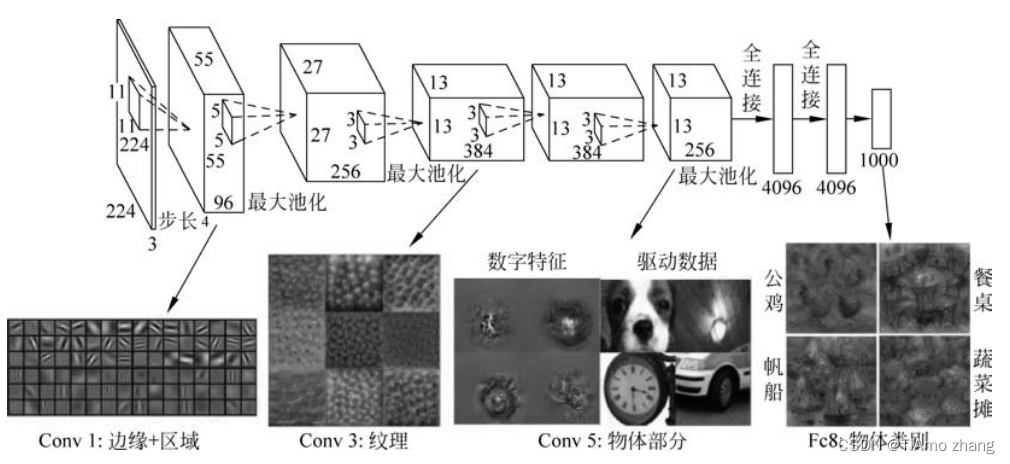
■ 图4AlexNet
2015年,特征可视化工具开始盛行。那么,AlexNet学习出的特征是什么样子的?在第一层,都是一些填充的块状物和边界等特征;中间层开始学习一些纹理特征;而在接近分类器的高层,则可以明显看到物体形状的特征;最后一层即分类层,不同物体的主要特征已经被完全提取出来。
无论对什么物体进行识别,特征提取器提取特征的过程都是渐进的。特征提取器最开始提取到的是物体的边缘特征,继而是物体的各部分信息,然后在更高层级上才能抽象到物体的整体特征。整个卷积神经网络实际上是在模拟人的抽象和迭代的过程。