目录
一,常用端口号
Hadoop3.x :
Hadoop2.x:
二,常用配置文件:
Hadoop3.x:
Hadoop2.x:
集群时间同步:
时间服务器配置(必须root用户):
(1)查看所有节点ntpd服务状态和开机自启动状态
(2)修改hadoop102的ntp.conf配置文件
(3)修改hadoop102的/etc/sysconfig/ntpd 文件
(4)重新启动ntpd服务
关闭所有节点上ntp服务和自启动
在其他机器配置1分钟与时间服务器同步一次
添加定时任务:
一,常用端口号
Hadoop3.x :
HDFS NameNode内部通信端口:8020 / 9000/9820
HDFS NameNode对用户查询端口:9870
Yarn MapReduce查看执行任务端口:8088
历史服务器端口:19888
Hadoop2.x:
HDFS NameNode内部通信端口:8020 / 9000
HDFS NameNode对用户查询端口:50070
Yarn MapReduce查看执行任务端口:8088
历史服务器端口:19888
二,常用配置文件:
Hadoop3.x:
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
workers
Hadoop2.x:
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
slaves
集群时间同步:
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行任务时间不同步。
找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,生产环境根据任务对时间的准确程度要求周期同步。测试环境为了尽快看到效果,采用1分钟同步一次。
时间服务器配置(必须root用户):
(1)查看所有节点ntpd服务状态和开机自启动状态
systemctl status ntpd ------检查时间服务器是否打开

systemctl start ntpd ------开启时间服务器
systemctl is-enabled ntpd ----设置开机是否启动ntpd服务
![]()
(2)修改hadoop102的ntp.conf配置文件
修改配置文件,设置那些服务器与这台服务器同步:
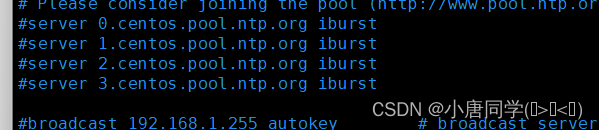
vim /etc/ntp.conf末尾添加:
server 127.127.1.0
fudge 127.127.1.0 stratum 10
下图去掉了注释,改了自己的IP区间:

restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
下边几行注释了起来
(3)修改hadoop102的/etc/sysconfig/ntpd 文件
vim /etc/sysconfig/ntpd增加内容如下(让硬件时间与系统时间一起同步---硬件时间更准确)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
systemctl start ntpd关闭所有节点上ntp服务和自启动
systemctl stop ntpd
systemctl disable ntpd在其他机器配置1分钟与时间服务器同步一次
crontab -e
添加定时任务:
*/1 * * * * /usr/sbin/ntpdate hadoop102Hadoop入门就此终结,下面跟我一起更新学习HDFS吧!