数据库索引的作用是做数据的快速检索,而快速检索实现的本质是数据结构。像二叉树、红黑树、AVL树、B树、B+树、哈希等数据结构都可以实现索引,但其中B+树效率最高。
MySQL数据库索引使用的是B+树。
二叉树:二叉树中,左子树比根节点小,右子树比根节点大,每次寻找目标值都是二分查找的方式,所以二叉树的时间复杂度为O(logn)。但当大量数据发生倾斜的时候,极端情况下,二叉树会形成链表一样的线性结构,其时间复杂度为O(n),降低了查询效率;而且每次从磁盘读取一个节点到内存就进行一次IO,当二叉树深度越深,IO次数就越多,所以综上两点,二叉树不利于做索引。
红黑树:红黑树是二叉树的进阶版,当二叉树处于不平衡的状态时,红黑树就会自动左旋右旋节点使二叉树保持基本的平衡状态,也保证了查询效率不会明显地降低。但当大量数据发生倾斜时,红黑树并没有从根本上解决数据倾斜的问题,只是不会像二叉树一样变成线性结构那么夸张。
比如数据库主键递增,主键一般都有上百上千万个,红黑树存在这种倾斜问题,那对查询性能而言也是巨大的消耗,数据库不可能忍受这种毫无意义的等待。

AVL树:AVL树是个绝对的平衡二叉树,所以AVL树不存在二叉树、红黑树的数据倾斜问题。大量的顺序插入不会导致查询性能的降低,这从根本上解决了二叉树、红黑树的数据倾斜问题。但数据库查询数据的瓶颈在于磁盘 IO, AVL 树是二叉树的一种,每一个树节点只存储了一个数据,随着插入的数据越多,树的深度也越深,意味着IO次数就越多,所以也影响读取的效率。
这就引入了B树、B+树,一个树节点上尽可能多地存储数据,这样一次磁盘 IO 就可以加载多个数据到内存中,提高查询效率。
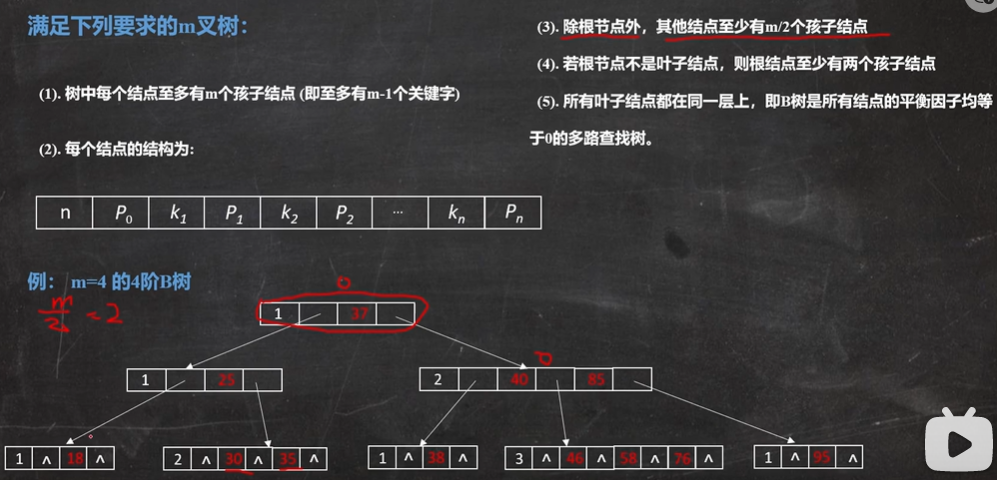
B树:B树又叫平衡多路查找树,一棵m阶的B树有如下性质:
(1)树中每个结点至多有m个孩子节点(即至多有m-1个关键字)
(2)每个结点中包括“n:记录结点中关键字的个数”、“p0....pn:孩子节点”以及“k1...kn:关键字”。
(3)除根节点外,其他节点至少有ceil(m/2)个孩子结点。(ceil函数:向上取整)
(4)若根节点不是叶子结点,则根节点至少有两个孩子结点。
(5)所有叶子结点都要在同一层上。
B树要求每个节点不仅包含数据的key值,还有data值。而每页的存储空间有限,如果data比较大的话,会导致每个节点的key存储的较少,当数据量大的时候,同样会导致B树很深,从而增加磁盘的IO次数,进而影响查询效率。
B+树是B树的进阶版,B+树与B树的区别:
(1)B树中每个根结点既有key又有data数据,而B+树中根节点只有key没有data数据。这样可以存储较多的key,降低B+树的高度,从而减少IO的次数。
(2)B树中叶子结点之间没有关联,而B+树中叶子结点的关键字从小到大排序,叶子结点相互之间有一个引用链路将叶子结点连接起来,像链表一样。
(3)B树查找数据可能不用找到叶子结点就找到数据,而B+树把所有的数据都放在叶子结点上,所以每次查找的次数都相同,B+树查询速度比B树更稳定。
(4)遍历全部结点时,B树要对每一层都进行遍历,而B+树只需要遍历所有的叶子结点即可,这有利于数据库做全表扫描。