最近在针对某系统进行性能优化时,发现了一个hive on spark 模式下使用 HikariCP 数据库连接池造成的资源泄露问题,该问题具有普适性,故特地拿出来跟大家分享下。
1 问题描述
-
在微服务中,我们普遍会使用各种数据库连接池技术以加快获取数据库连接并执行数据查询的速度,这本质是一种空间换时间的有效的性能优化的思路。
-
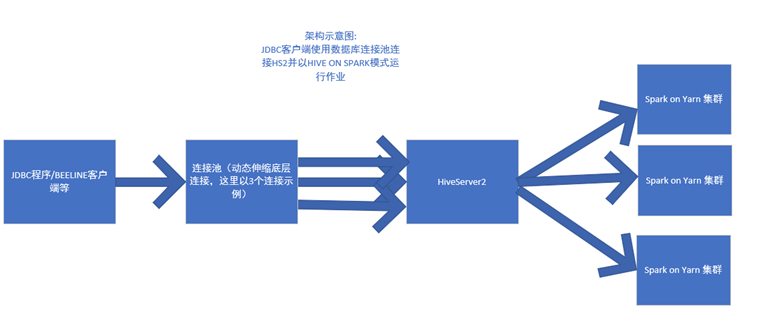
推而广之,在大数据场景下通过JDBC访问HiveServer2并提交数据查询SQL语句时,也很容易想到同样使用数据库连接池技术以加快作业速度。
-
但是相比普通的RDBMS,Hive的JDBC连接更重,以HIVE ON SPARK模式运行作业时更是如此,因为当连接底层需要执行SQL时,HS2会向YARN申请CONTAINER资源,然后启动分布式的SPARK ON YARN集群并分布式地执行编译好的SQL,当该SQL执行完毕后并不会立即释放SAPRK ON YANR资源,而是会等待一段时间以复用这些 SPARK ON YARN资源执行客户端通过该连接提交的新的SQL,只有当该JDBC连接关闭时,或者达到了配置的超时时间而客户端仍没有提交新的SQL时,才会彻底释放这些 SPARK ON YARN 资源。
-
当业务代码使用了数据库连接池技术时,由于其关闭JDBC连接时本质上只是将连接归还给了连接池而没有真是关闭底层的JDBC连接,所以连接背后的 SPARK ON YARN资源并不会被及时释放也就是造成了资源泄露,此时其它作业向YARN申请资源时就需要排队等待,从而影响了其它作业的执行。
-
本案列中该系统使用了HikariCP 数据库连接池,且没有配置数据库连接的空闲超时时长(idletimeout),真正生效的空闲超时时长是Hikari源码层面配置的默认值10分钟,所以每个连接底层的SQL作业执行完毕后都需要10分钟才真正释放了背后的SPARK ON YARN资源,从而造成了其它作业对YANR资源的排队和等待。(话说你占着资源却不使用,不就是站着那个啥不干那个啥么_)
2 问题解决方案
针对该问题进行分析,解决方案有多个,如下分别进行描述。
2.1 解决方案1
该方案的思路是彻底摒弃数据库连接池,因为一般而言,大数据作业擅长的是大数据量和复杂逻辑的处理,其作业执行速大都在分钟级别以上,数据库连接池节省的1到2秒钟几乎微不足道,所以考虑到这些使用上的弊端干脆弃之不用。
2.2 解决方案2
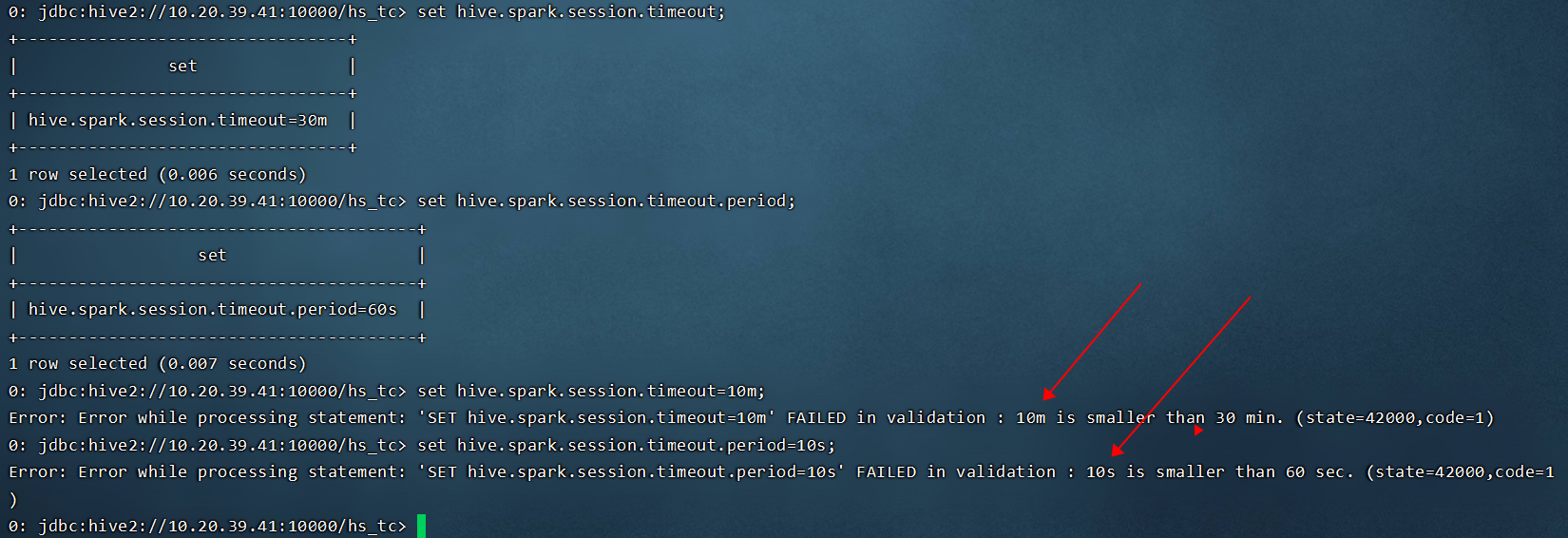
- 该方案的思路是配置HS2 背后SPARK ON YARN集群的SESSION超时时间,从而更快地释放 SPARK ON YARN 资源。
- 但是通过测试并查看源码发现该超时时间的最小值是30分钟不能设置更小值,所以起不了效果。
- 相关参数有:
- hive.spark.session.timeout:默认值30m最小值30m;
- hive.spark.session.timeout.period:默认值60s最小值60s;
2.3 解决方案3
- 该方案的思路是配置Spark on yarn的动态资源分配机制,从而使得spark on yarn集群在没有SQL作业需要执行时并不会占用太多YARN资源。
- 但是由于SPARK 集群至少需要1个CONTAINER以执行DRIVER,所以该方案只能缓解问题不能彻底解决问题。
- 相关参数有:
- spark.dynamicAllocation.enabled,需要配置为true;
- spark.dynamicAllocation.minExecutors:默认为1可以进一步调整为0;
2.4 解决方案4
- 该方案的思路是配置客户端和HS2 之间的SESSION超时时间,从而让HS2主动断开客户端的JDBC连接并释放背后的Spark ON YARN资源。
- 经测试该方案可行,但修改相关参数需要重启hs2服务进程且该参数的修改会影响所有用户作业,一般集群管理员可能会有异议;
- 相关参数有:
- hive.server2.session.check.interval:不同版本默认值不同,比如15m/6h;
- hive.server2.idle.session.timeout:不同版本默认值不同,比如4h/12h/7d;
- hive.server2.idle.operation.timeout:不同版本默认值不同,比如2h/6h;
- hive.server2.idle.session.check.operation:true

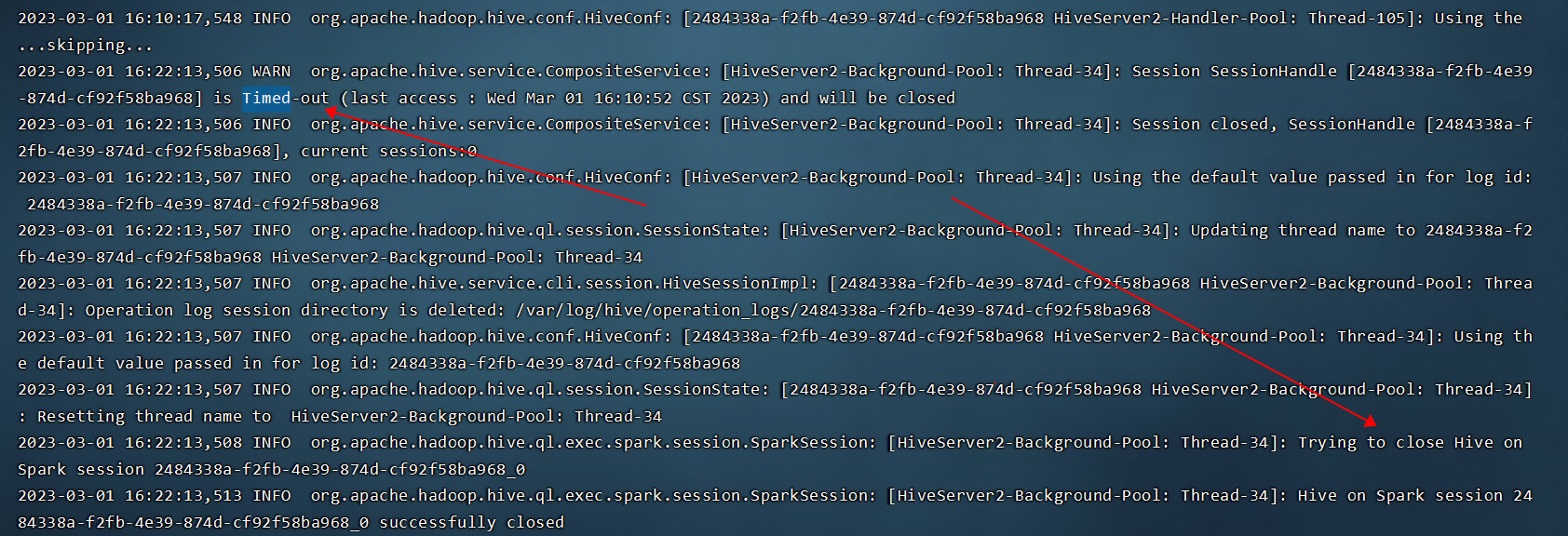
如下日志可见,session timeout 被关闭后,spark session 也别清理了:
2.5 解决方案5
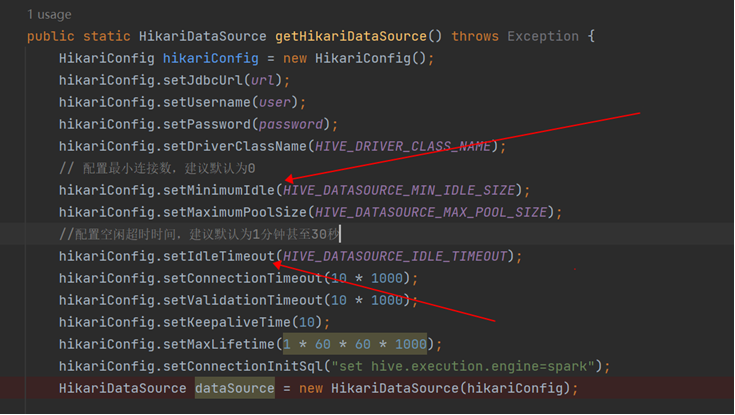
- 该方案的思路是调整数据库连接池的相关参数尤其是最小连接数和空闲超时时间,从而更快地更积极地主动关闭空闲的数据库连接,比如将IdleTimeout配置为30秒,将最小连接数MinimumIdle配置为0,则SQL作业运行完毕30秒后就会关闭所有连接,也就会释放所有SPARK ON YARN资源,从而解决了资源泄露问题;
- 相关hikariConfig参数有:
- MinimumIdle:最小连接数;
- MaximumPoolSize:最大连接数;
- IdleTimeout:空闲超时时间;
- ConnectionTimeout:获取连接超时时间;
- ValidationTimeout:连接有效行验证超时时间;
- KeepaliveTime:空闲连接保活间隔时间;
- MaxLifetime:连接最大时间;
- 示例代码如下:
3 知识点总结
- 大数据作业擅长的是大数据量和复杂逻辑的处理,其作业执行速大都在分钟级别以上,数据库连接池节省的1到2秒钟几乎微不足道,所以大数据作业一般不使用数据库连接池;
- 当使用数据库连接池时,由于相比普通的RDBMS,Hive的JDBC连接更重,以 HIVE ON SPARK 模式运行作业时更是如此,所以一定要及时释放JDBC连接从而及时释放背后的 YARN资源,从而避免资源泄露问题引起其它作业长时间等待YARN资源;
- 使用数据库连接池时,为及时释放JDBC连接从而及时释放背后的YARN资源,一般可以调整数据库连接池的相关参数,尤其是最小连接数和空闲超时时间,从而更快地更积极地主动关闭空闲的数据库连接,比如将IdleTimeout配置为30秒,将最小连接数MinimumIdle配置为0,则SQL作业运行完毕30秒后就会关闭所有连接,也就会释放所有SPARK ON YARN资源,从而解决了资源泄露问题。