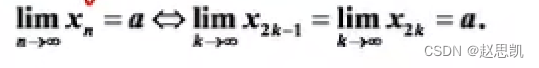一、概述
相较于传统目标检测,DETR是一种纯端到端的网络。它不再需要NMS(非极大值抑制,用于去除多余的预测框)和生成anchor。
DETR提出了一个新的目标函数(二分图匹配),这个函数可以强制网络输出一个独一无二的预测值(没有冗余的预测框)。
二、网络结构

DETR的前向流程如上图所示:①使用一个CNN抽取图片的特征;②将这个特征拉平;③将拉平后的特征送入Transformer的encoder-decoder单元;④由decoder输出预测框的信息(出框的信息是一个超参数,原文为100)⑤利用二分图匹配的方式将Ground Truth与预测结果进行匹配,对于匹配成功的框才会进一步计算loss(没有匹配成功的框将会被标记为no object<背景类>)
1.基于集合的目标函数
DETR的输出是一个固定集合(固定数目)。为了在这些集合中找到正确的预测框,DETR采用了一个二分图匹配的方法来解决这个问题。具体做法是:将n个预测框和x个Ground Turth构建成一个cost matrix(代价矩阵),通过算法在其中找出代价最小的排列。


矩阵中的内容为损失函数(分类Loss和框体Loss),公式即可写为:

这个公式的意义是:在二分图匹配的基础上计算两个loss(分类Loss和框体Loss),其中对于第一个loss,由于要与第二个loss取值范围一致,其log被去除且实验表明并不会影响结果;对于第二个loss,由于L1-Loss会对大物体敏感,所以采用generalized iou loss来计算(与物体大小无关)。
2.整体网络框架

①默认图片输入大小为1066x800x3,经过卷积网络提取特征,得到输出2048x25x34;然后经过一个1x1卷积进行通道调整(降维)得到256x25x34。
②将特征拉平(850*256),并为其叠加位置编码(256x25x34)
③将序列输入Encoder中,计算自注意力
④将结果输入Decoder,进行解码输出;这里引入一个object query(一个可学习,维度为100*256),在每个decoder会先做一次object query的自注意力操作用于移除冗余框(第一个decoder可以不做)
⑤将特征输入检测头(FFN-MLP),进行预测。
三、代码
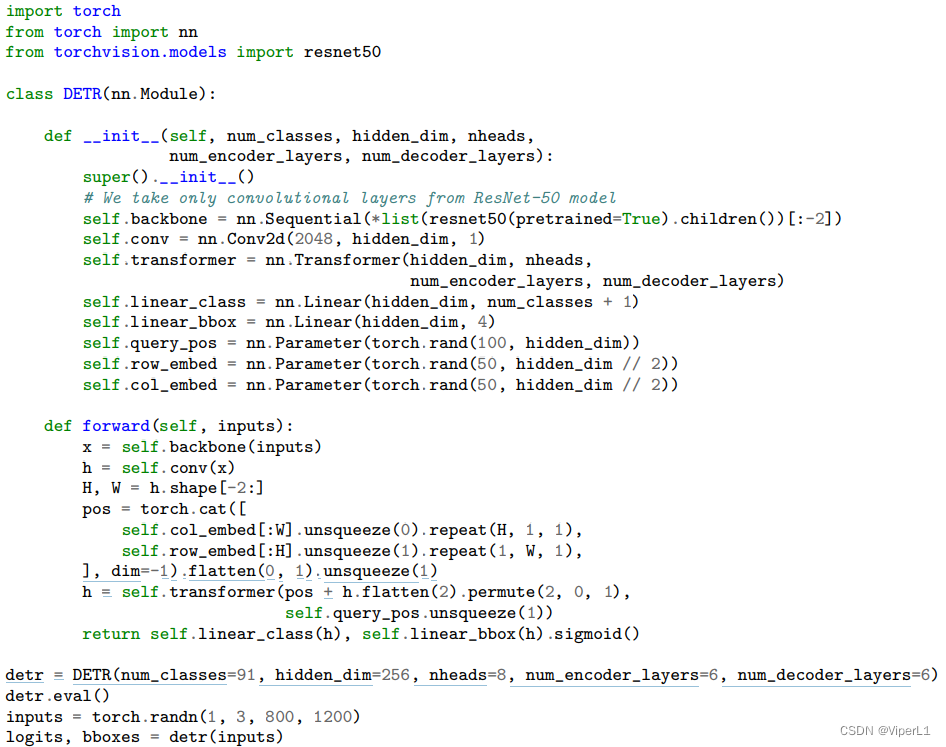
出自原文的DETR42最简结构

![[蓝桥杯] 枚举、模拟和排列问题](https://img-blog.csdnimg.cn/fafa6bb132e64a8b99b56704546601e7.png)