🌟hello,各位读者大大们你们好呀🌟
🍭🍭系列专栏:【C++学习与应用】
✒️✒️本篇内容:vector的基本概念、vector的使用(构造,迭代器,空间增长,增删查改)、vector迭代器失效问题、vector重要接口的模拟实现、模拟实现中使用memcpy的拷贝问题、vector的动态二维数组
🚢🚢作者简介:计算机海洋的新进船长一枚,请多多指教( •̀֊•́ ) ̖́-
目录
一、vector介绍及使用
1.vector介绍
2.vector的使用
2.1vector的构造
2.2vector iterator(迭代器)的使用
2.3vector 空间增长问题
2.4vector 增删查改
2.5vector 迭代器失效问题(重要)
二、vector深度剖析及模拟实现
1.模拟实现std::vector的核心框架接口
2.使用memcpy拷贝问题
3.动态二维数组理解
一、vector介绍及使用
1.vector介绍
vector文档链接![]() https://cplusplus.com/reference/vector/vector/
https://cplusplus.com/reference/vector/vector/
- vector是表示可变大小数组的序列容器。
- 就像数组一样,vector也采用的连续存储空间来存储元素。也就是意味着可以采用下标对vector的元素进行访问,和数组一样高效。但是又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自动处理。
- 本质讲,vector使用动态分配数组来存储它的元素。当新元素插入时候,这个数组需要被重新分配大小为了增加存储空间。其做法是,分配一个新的数组,然后将全部元素移到这个数组。就时间而言,这是一个相对代价高的任务,因为每当一个新的元素加入到容器的时候,vector并不会每次都重新分配大小。
- vector分配空间策略:vector会分配一些额外的空间以适应可能的增长,因为存储空间比实际需要的存储空间更大。不同的库采用不同的策略权衡空间的使用和重新分配。但是无论如何,重新分配都应该是对数增长的间隔大小,以至于在末尾插入一个元素的时候是在常数时间的复杂度完成的。
- 因此,vector占用了更多的存储空间,为了获得管理存储空间的能力,并且以一种有效的方式动态增长。
- 与其它动态序列容器相比(deque, list and forward_list), vector在访问元素的时候更加高效,在末尾添加和删除元素相对高效。对于其它不在末尾的删除和插入操作,效率更低。比起list和forward_list统一的迭代器和引用更好
2.vector的使用
2.1vector的构造
| (constructor)构造函数声明 | 接口说明 |
| vector()(重点) | 无参构造 |
| vector(size_type n, const value_type& val = value_type()) | 构造并初始化n个val |
| vector (const vector& x); (重点) | 拷贝构造 |
| vector (InputIterator first, InputIterator last); | 使用迭代器进行初始化构造 |
代码实例如下
vector<int> v1(10, 5); //创建int类型数组容器v1,里面有10个5;
vector<char> v1(5, 'a'); //创建char类型数组容器v2,里面有5个'a';
vector<double> v1(7, 2.3); //创建double类型数组容器v3,里面有7个2.3;
vector<int> v1(10, 5); //创建int类型数组容器v1,里面有10个5;
vector<char> v1(5, 'a'); //创建char类型数组容器v2,里面有5个'a';
vector<double> v1(7, 2.3); //创建double类型数组容器v3,里面有7个2.3;
vector<int> v1(10, 9); //创建int类型数组容器v1,里面有10个9;
vector<int> v2(v1.begin(), v1.begin() + 6); //创建int类型数组容器v2,里面有6个9;
vector<char> v1(10, 9); //通过前面的方法创建一个对象;
vector<char> v2(v1); //创建对象v2,其内容与v1一模一样.
2.2vector iterator(迭代器)的使用
| iterator的使用 | 接口说明 |
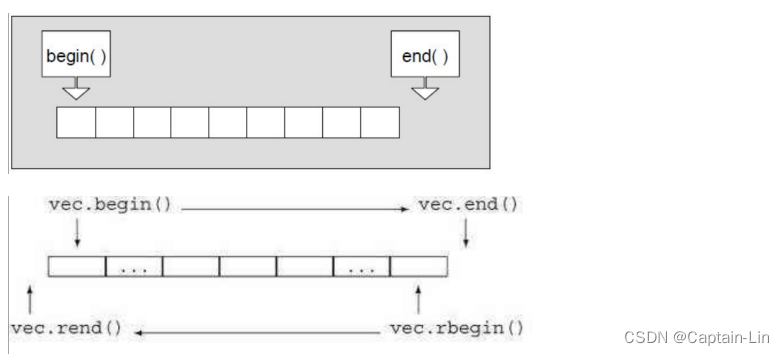
| begin + end(重点) | 获取第一个数据位置的iterator/const_iterator, 获取最后一个数据的下一个位置的iterator/const_iterator |
| rbegin + rend | 获取最后一个数据位置的reverse_iterator,获取第一个数据前一个位置的reverse_iterator |
代码实例如下
// vector的迭代器
void PrintVector(const vector<int>& v)
{
// const对象使用const迭代器进行遍历打印
vector<int>::const_iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
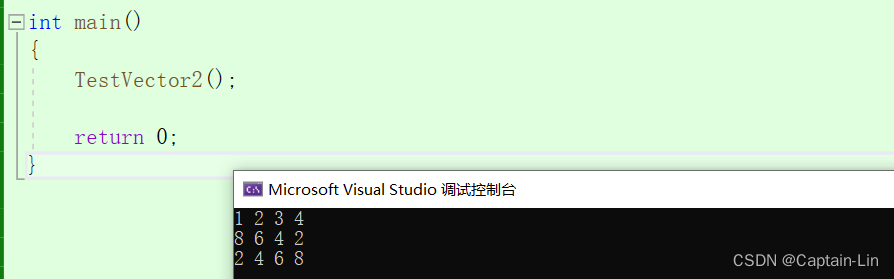
void TestVector2()
{
// 使用push_back插入4个数据
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
// 使用迭代器进行遍历打印
vector<int>::iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
// 使用迭代器进行修改(注意这里没有打印)
it = v.begin();
while (it != v.end())
{
*it *= 2;
++it;
}
// 使用反向迭代器进行遍历再打印(rbegin-数组反向开头第一个,rend-数组以反向开头的结尾,即数组第一个)
// vector<int>::reverse_iterator rit = v.rbegin();
auto rit = v.rbegin();
while (rit != v.rend())
{
cout << *rit << " ";
++rit;
}
cout << endl;
PrintVector(v);
}
2.3vector 空间增长问题
| 容量空间 | 接口说明 |
| size | 获取数据个数 |
| capacity | 获取容量大小 |
| empty | 判断是否为空 |
| resize(重点) | 改变vector的size |
| reserve (重点) | 改变vector的capacity |
- capacity的代码在vs和g++下分别运行会发现,vs下capacity是按1.5倍增长的,g++是按2倍增长的。这个问题经常会考察,不要固化的认为,vector增容都是2倍,具体增长多少是根据具体的需求定义的。vs是PJ版本STL,g++是SGI版本STL。
- reserve只负责开辟空间,如果确定知道需要用多少空间,reserve可以缓解vector增容的代价缺陷问题。
- resize在开空间的同时还会进行初始化,影响size。
代码示例
// vector的 resize
// reisze(size_t n, const T& data = T())
// 将有效元素个数设置为n个,如果时增多时,增多的元素使用data进行填充
// 注意:resize在增多元素个数时可能会扩容
void TestVector3()
{
vector<int> v;
// set some initial content:
for (int i = 1; i < 10; i++)
v.push_back(i);
v.resize(5);//size由10->5,6~10的size被释放
v.resize(8, 100);//size由5->8,6~8的size被初始化为100
v.resize(12);//size由8->12,9~12的size被默认初始化为0
cout << "v contains:";
for (size_t i = 0; i < v.size(); i++)
cout << ' ' << v[i];
cout << '\n';
}
测试vector的默认扩容机制
// 测试vector的默认扩容机制
void TestVectorExpand()
{
size_t sz;
vector<int> v;
sz = v.capacity();
cout << "making v grow:\n";
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
if (sz != v.capacity())
{
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}
//vs:运行结果:vs下使用的STL基本是按照1.5倍方式扩容
//making foo grow :
//capacity changed : 1
//capacity changed : 2
//capacity changed : 3
//capacity changed : 4
//capacity changed : 6
//capacity changed : 9
//capacity changed : 13
//capacity changed : 19
//capacity changed : 28
//capacity changed : 42
//capacity changed : 63
//capacity changed : 94
//capacity changed : 141
//g++运行结果:linux下使用的STL基本是按照2倍方式扩容
//making foo grow :
//capacity changed : 1
//capacity changed : 2
//capacity changed : 4
//capacity changed : 8
//capacity changed : 16
//capacity changed : 32
//capacity changed : 64
//capacity changed : 128// 如果已经确定vector中要存储元素大概个数,可以提前将空间设置足够
// 就可以避免边插入边扩容导致效率低下的问题了
void TestVectorExpandOP()
{
vector<int> v;
size_t sz = v.capacity();
v.reserve(100); // 提前将容量设置好,可以避免一遍插入一遍扩容
cout << "making bar grow:\n";
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
if (sz != v.capacity())
{
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}2.4vector 增删查改
| vector增删查改 | 接口说明 |
| push_back(重点) | 尾插 |
| pop_back (重点) | 尾删 |
| find | 查找(注意这个是算法模块实现,不是vector的成员接口) |
| insert | 在position之前插入val |
| erase | 删除position位置的数据 |
| swap | 交换两个vector的数据空间 |
| operator[ ] (重点) | 像数组一样访问 |
代码示例
(1)尾插和尾删:push_back/pop_back
// 尾插和尾删:push_back/pop_back
void TestVector4()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
auto it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
v.pop_back();
v.pop_back();
it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
int main()
{
TestVector4();
return 0;
}

(2)insert 和 erase
// 任意位置插入:insert和erase,以及查找find
// 注意find不是vector自身提供的方法,是STL提供的算法
void TestVector5()
{
// 使用列表方式初始化,C++11新语法
vector<int> v{ 1, 2, 3, 4 };
// 在指定位置前插入值为val的元素,比如:3之前插入30,如果没有则不插入
// 1. 先使用find查找3所在位置
// 注意:vector没有提供find方法,如果要查找只能使用STL提供的全局find
auto pos = find(v.begin(), v.end(), 3);
if (pos != v.end())
{
// 2. 在pos位置之前插入30
v.insert(pos, 30);
}
vector<int>::iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
pos = find(v.begin(), v.end(), 3);
// 删除pos位置的数据
v.erase(pos);
it = v.begin();
while (it != v.end()) {
cout << *it << " ";
++it;
}
cout << endl;
}
int main()
{
TestVector5();
return 0;
}
(3)operator[ ] 使用
// operator[]+index 和 C++11中vector的新式for+auto的遍历
// vector使用这两种遍历方式是比较便捷的。
void TestVector6()
{
vector<int> v{ 1, 2, 3, 4 };
// 通过[]读写第0个位置。
v[0] = 10;
cout << v[0] << endl;
// 1. 使用for+[]小标方式遍历
for (size_t i = 0; i < v.size(); ++i)
cout << v[i] << " ";
cout << endl;
vector<int> swapv;
swapv.swap(v);
//通过上面的代码swapv.swap(v),已经将数组v的数据转移到swapv上了
cout << "v data:";
for (size_t i = 0; i < v.size(); ++i)
cout << v[i] << " ";
cout << endl;
// 2. 使用迭代器遍历
cout << "swapv data:";
auto it = swapv.begin();
while (it != swapv.end())
{
cout << *it << " ";
++it;
}
// 3. 使用范围for遍历
for (auto x : v)
cout << x << " ";
cout << endl;
}
int main()
{
TestVector6();
return 0;
}
2.5vector 迭代器失效问题(重要)
迭代器的主要作用就是让算法能够不用关心底层数据结构,其底层实际就是一个指针,或者是对指针进行了封装,比如:vector的迭代器就是原生态指针T* 。因此迭代器失效,实际就是迭代器底层对应指针所指向的空间被销毁了,而使用一块已经被释放的空间,造成的后果是程序崩溃(即如果继续使用已经失效的迭代器,程序可能会崩溃)。
对于vector可能会导致其迭代器失效的操作有:
(1)会引起其底层空间改变的操作,都有可能是迭代器失效,比如:resize、reserve、insert、assign、push_back等。
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> v{ 1,2,3,4,5,6 };
auto it = v.begin();
// 将有效元素个数增加到100个,多出的位置使用8填充,操作期间底层会扩容
// v.resize(100, 8);
// reserve的作用就是改变扩容大小但不改变有效元素个数,操作期间可能会引起底层容量改变
// v.reserve(100);
// 插入元素期间,可能会引起扩容,而导致原空间被释放
// v.insert(v.begin(), 0);
// v.push_back(8);
// 给vector重新赋值,可能会引起底层容量改变
v.assign(100, 8);
/*
出错原因:以上操作,都有可能会导致vector扩容,也就是说vector底层原理旧空间被释放掉,
而在打印时,it还使用的是释放之间的旧空间,在对it迭代器操作时,实际操作的是一块已经被释放的
空间,而引起代码运行时崩溃。
解决方式:在以上操作完成之后,如果想要继续通过迭代器操作vector中的元素,只需给it重新
赋值即可。
*/
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}(2)指定位置元素的删除操作--erase
#include <iostream>
#include <vector>
using namespace std;
int main()
{
int a[] = { 1, 2, 3, 4 };
vector<int> v(a, a + sizeof(a) / sizeof(int));
// 使用find查找3所在位置的iterator
vector<int>::iterator pos = find(v.begin(), v.end(), 3);
// 删除pos位置的数据,导致pos迭代器失效。
v.erase(pos);
cout << *pos << endl; // 此处会导致非法访问
return 0;
}实际上,erase删除pos位置元素后,pos位置之后的元素会往前搬移,没有导致底层空间的改变,理论上讲迭代器不应该会失效,但是:如果pos刚好是最后一个元素,删完之后pos刚好是end的位置,而end位置是没有元素的,那么pos就失效了。但是删除vector中任意位置上元素时,vs(编译器)会统一认为该位置迭代器失效了,这与vs的机制有关,这里就不再多做赘述了。
(3)注意:Linux下,g++编译器对迭代器失效的检测并不是非常严格,处理也没有vs下极端
接下来让我们一起看下面的三个例子,这些例子会向我们说明:在SGI STL中,迭代器失效后,代码并不一定会崩溃,但是运行结果肯定不对,如果it不在begin和end范围内,肯定会崩溃
// 1. 扩容之后,迭代器已经失效了,程序虽然可以运行,但是运行结果已经不对了
int main()
{
vector<int> v{ 1,2,3,4,5 };
for (size_t i = 0; i < v.size(); ++i)
cout << v[i] << " ";
cout << endl;
auto it = v.begin();
cout << "扩容之前,vector的容量为: " << v.capacity() << endl;
// 通过reserve将底层空间设置为100,目的是为了让vector的迭代器失效
v.reserve(100);
cout << "扩容之后,vector的容量为: " << v.capacity() << endl;
// 经过上述reserve之后,it迭代器肯定会失效,在vs下程序就直接崩溃了,但是linux下不会
// 虽然可能运行,但是输出的结果是不对的
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}
程序输出:
1 2 3 4 5
扩容之前,vector的容量为: 5
扩容之后,vector的容量为 : 100
0 2 3 4 5 409 1 2 3 4 5
// 2. erase删除任意位置代码后,linux下迭代器并没有失效
// 因为空间还是原来的空间,后序元素往前搬移了,it的位置还是有效的
#include <vector>
#include <algorithm>
int main()
{
vector<int> v{ 1,2,3,4,5 };
vector<int>::iterator it = find(v.begin(), v.end(), 3);
v.erase(it);
cout << *it << endl;
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}
程序可以正常运行,并打印:
4
4 5
// 3: erase删除的迭代器如果是最后一个元素,删除之后it已经超过end
// 此时迭代器是无效的,++it导致程序崩溃
int main()
{
vector<int> v{ 1,2,3,4,5 };
// vector<int> v{1,2,3,4,5,6};
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
v.erase(it);
++it;
}
for (auto e : v)
cout << e << " ";
cout << endl;
return 0;
}
========================================================
// 使用第一组 erase 数据时,程序可以运行
[ldx@VM - 0 - 3 - centos 20220114]$ g++ testVector.cpp - std = c++11
[ldx@VM - 0 - 3 - centos 20220114]$ . / a.out
1 3 5
======================================================== =
// 使用第二组 erase 数据时,程序最终会崩溃
[ldx@VM - 0 - 3 - centos 20220114]$ vim testVector.cpp
[ldx@VM - 0 - 3 - centos 20220114]$ g++ testVector.cpp - std = c++11
[ldx@VM - 0 - 3 - centos 20220114]$ . / a.out
Segmentation fault(4)与vector类似,string在插入+扩容操作+erase之后,迭代器也会失效
#include <string>
void TestString()
{
string s("hello");
auto it = s.begin();
// 放开下面resize代码之后,代码会崩溃,因为resize到20会string会进行扩容
// 扩容之后,it指向之前旧空间已经被释放了,该迭代器就失效了
// 后序打印时,再访问it指向的空间程序就会崩溃
//s.resize(20, '!');
while (it != s.end())
{
cout << *it;
++it;
}
cout << endl;
it = s.begin();
while (it != s.end())
{
it = s.erase(it);
// 按照下面方式写,运行时程序会崩溃,因为erase(it)之后
// it位置的迭代器就失效了
// s.erase(it);
++it;
}
}【总结】迭代器失效解决办法:在使用前,对迭代器(重新)赋值即可
二、vector深度剖析及模拟实现
1.模拟实现std::vector的核心框架接口
#include <iostream>
using namespace std;
#include <assert.h>
namespace ldx
{
template<class T>
class vector
{
public:
// Vector的迭代器是一个原生指针
typedef T* iterator;
typedef const T* const_iterator;
///
// 构造和销毁
vector()
: _start(nullptr)
, _finish(nullptr)
, _endOfStorage(nullptr)
{}
vector(size_t n, const T& value = T())
: _start(nullptr)
, _finish(nullptr)
, _endOfStorage(nullptr)
{
reserve(n);
while (n--)
{
push_back(value);
}
}
/*
* 理论上,提供了vector(size_t n, const T& value = T())之后
* vector(int n, const T& value = T())就不需要提供了,但是对于:
* vector<int> v(10, 5);
* 编译器在编译时,认为T已经被实例化为int,而10和5编译器会默认其为int类型
* 就不会走vector(size_t n, const T& value = T())这个构造方法,
* 最终选择的是:vector(InputIterator first, InputIterator last)[InputIterator - 输入迭代器]
* 因为编译器觉得区间构造两个参数类型一致,因此编译器就会将InputIterator实例化为int
* 但是10和5代表的意义根本不是一个区间(而是构建一个顺序表,其中包括10个5),编译时就报错了
* 故需要增加该构造方法
*/
vector(int n, const T& value = T())
: _start(new T[n])
, _finish(_start + n)
, _endOfStorage(_finish)
{
for (int i = 0; i < n; ++i)
{
_start[i] = value;
}
}
// 若使用iterator做迭代器,会导致初始化的迭代器区间[first,last)只能是vector的迭代器
// 重新声明迭代器,迭代器区间[first,last)可以是任意容器的迭代器
template<class InputIterator>
vector(InputIterator first, InputIterator last)
{
while (first != last)
{
push_back(*first);
++first;
}
}
vector(const vector<T>& v)
: _start(nullptr)
, _finish(nullptr)
, _endOfStorage(nullptr)
{
reserve(v.capacity());
iterator it = begin();
const_iterator vit = v.cbegin();
while (vit != v.cend())
{
*it++ = *vit++;
}
_finish = it;
}
vector<T>& operator=(vector<T> v)
{
swap(v);
return *this;
}
~vector()
{
if (_start)
{
delete[] _start;
_start = _finish = _endOfStorage = nullptr;
}
}
/
// 迭代器相关
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator cbegin() const
{
return _start;
}
const_iterator cend() const
{
return _finish;
}
//
// 容量相关
size_t size() const
{
return _finish - _start;
}
size_t capacity() const
{
return _endOfStorage - _start;
}
bool empty() const
{
return _start == _finish;
}
void reserve(size_t n)
{
if (n > capacity())
{
size_t oldSize = size();
// 1. 开辟新空间
T* tmp = new T[n];
// 2. 拷贝元素
// 这里直接使用memcpy会有问题吗?同学们思考下
//if (_start)
// memcpy(tmp, _start, sizeof(T)*size);
if (_start)
{
for (size_t i = 0; i < oldSize; ++i)
tmp[i] = _start[i];
// 3. 释放旧空间
delete[] _start;
}
_start = tmp;
_finish = _start + oldSize;
_endOfStorage = _start + n;
}
}
void resize(size_t n, const T& value = T())
{
// 1.如果n小于当前的size,则数据个数缩小到n
if (n <= size())
{
_finish = _start + n;
return;
}
// 2.空间不够则增容
if (n > capacity())
reserve(n);
// 3.将size扩大到n
iterator it = _finish;
_finish = _start + n;
while (it != _finish)
{
*it = value;
++it;
}
}
///
// 元素访问
T& operator[](size_t pos)
{
assert(pos < size());
return _start[pos];
}
const T& operator[](size_t pos)const
{
assert(pos < size());
return _start[pos];
}
T& front()
{
return *_start;
}
const T& front()const
{
return *_start;
}
T& back()
{
return *(_finish - 1);
}
const T& back()const
{
return *(_finish - 1);
}
/
// vector的修改操作
void push_back(const T& x)
{
insert(end(), x);
}
void pop_back()
{
erase(end() - 1);
}
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_endOfStorage, v._endOfStorage);
}
iterator insert(iterator pos, const T& x)
{
assert(pos <= _finish);
// 空间不够先进行增容
if (_finish == _endOfStorage)
{
//size_t size = size();
size_t newCapacity = (0 == capacity()) ? 1 : capacity() * 2;
reserve(newCapacity);
// 如果发生了增容,需要重置pos
pos = _start + size();
}
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = x;
++_finish;
return pos;
}
// 返回删除数据的下一个数据
// 方便解决:一边遍历一边删除的迭代器失效问题
iterator erase(iterator pos)
{
// 挪动数据进行删除
iterator begin = pos + 1;
while (begin != _finish) {
*(begin - 1) = *begin;
++begin;
}
--_finish;
return pos;
}
private:
iterator _start; // 指向数据块的开始
iterator _finish; // 指向有效数据的尾
iterator _endOfStorage; // 指向存储容量的尾
};
}//以下是测试用例
void TestldxVector2()
{
ldx::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
cout << v.size() << endl;
cout << v.capacity() << endl;
cout << v.front() << endl;
cout << v.back() << endl;
cout << v[0] << endl;
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
v.pop_back();
v.pop_back();
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
v.insert(v.begin(), 0);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
v.erase(v.begin() + 1);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}2.使用memcpy拷贝问题
假设模拟实现的vector中的reserve接口中,使用memcpy进行的拷贝,以下代码会发生什么问题?
int main()
{
ldx::vector<bite::string> v;
v.push_back("1111");
v.push_back("2222");
v.push_back("3333");
return 0;
}问题分析:
- memcpy是内存的二进制格式拷贝,将一段内存空间中内容原封不动的拷贝到另外一段内存空间中。
- 如果拷贝的是自定义类型的元素,memcpy既高效又不会出错,但如果拷贝的是自定义类型元素(这里要做好区分哦),并且自定义类型元素中涉及到资源管理时,就会出错,因为memcpy的拷贝实际是浅拷贝。


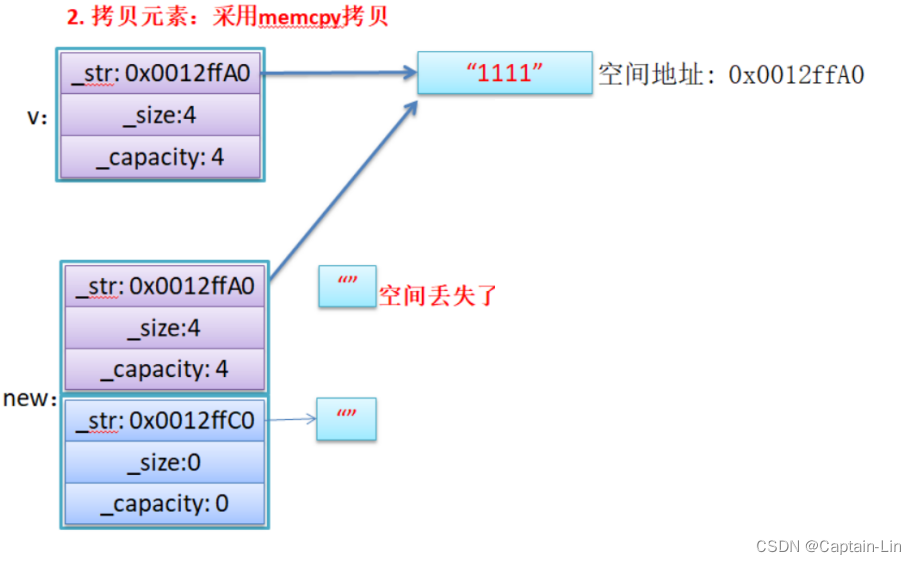
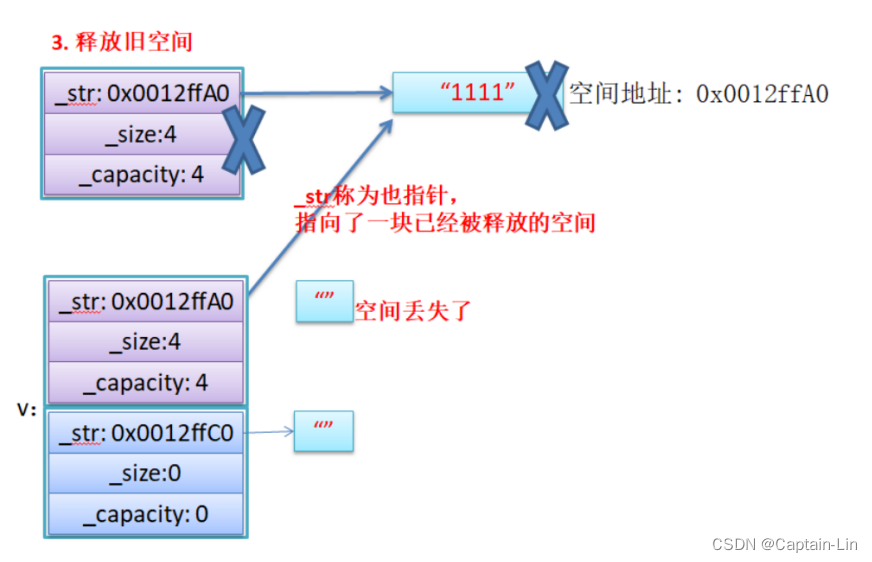
【总结】如果对象中涉及到资源管理时,千万不能使用memcpy进行对象之间的拷贝,因为memcpy是浅拷贝,否则可能会引起内存泄漏甚至程序崩溃。
不熟悉浅拷贝、深拷贝的朋友,可以查看这篇博客(内含相关内容)![]() https://blog.csdn.net/Captain_ldx/article/details/128425365
https://blog.csdn.net/Captain_ldx/article/details/128425365
3.动态二维数组理解
ldx为上文模拟实现的namespace
// 以杨辉三角的前n行为例:假设n为5
void test2vector(size_t n)
{
// 使用vector定义二维数组vv,vv中的每个元素都是vector<int>
ldx::vector<ldx::vector<int>> vv(n);
// 将二维数组每一行中的vecotr<int>中的元素全部设置为1
for (size_t i = 0; i < n; ++i)
vv[i].resize(i + 1, 1);
// 给杨慧三角出第一列和对角线的所有元素赋值
for (int i = 2; i < n; ++i)
{
for (int j = 1; j < i; ++j)
{
vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1];
}
}
}上述代码构造一个vv动态二维数组,vv中总共有n个元素,每个元素都是vector类型的,每行没有包含任何元素,如果n为5时如下所示:
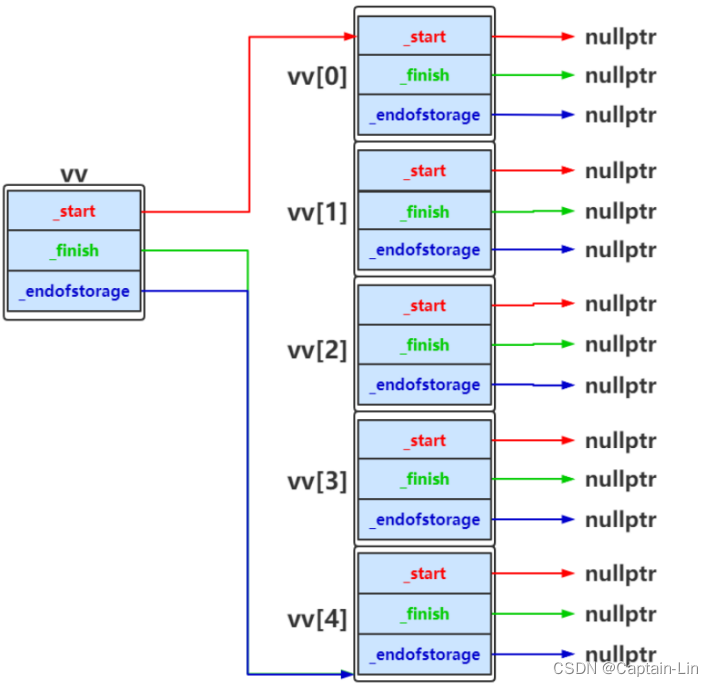
vv中元素填充完成之后,如下图所示:
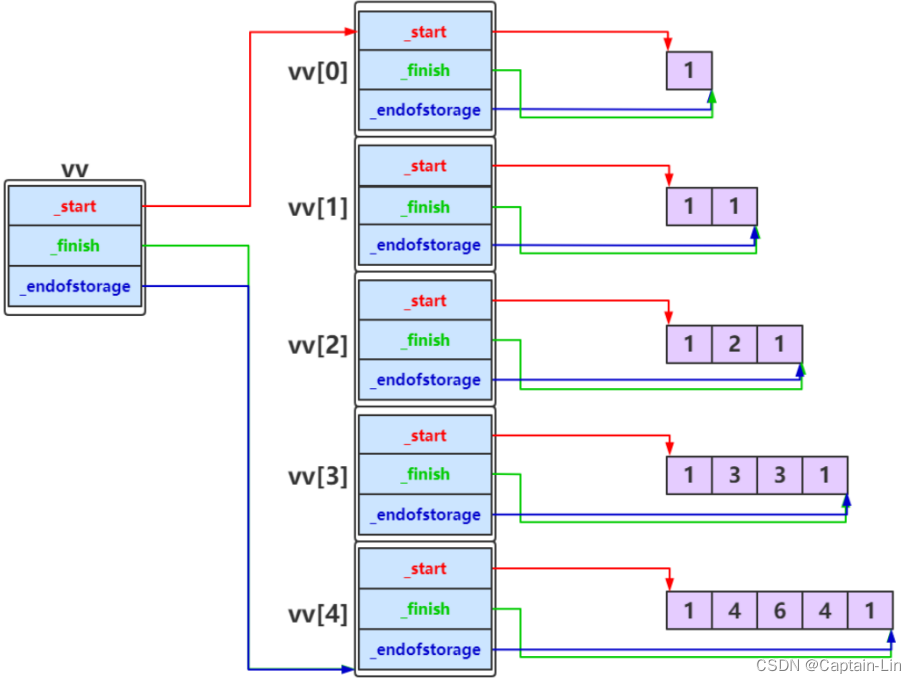
使用标准库中vector构建动态二维数组时与上图实际是一致的。
🌹🌹C/C++ vector的知识大概就讲到这里啦,博主后续会继续更新更多C++的相关知识,干货满满,如果觉得博主写的还不错的话,希望各位小伙伴不要吝啬手中的三连哦!你们的支持是博主坚持创作的动力!💪💪