引言
字符串处理是编程中最常见的任务之一,而在C++中,我们有多种处理字符串的方式。本文将详细介绍C++中的字符串操作,包括C风格字符串和C++的string类。无论你是C++新手还是想巩固基础的老手,这篇文章都能帮你梳理字符串处理的关键知识点。
目录
1. [C风格字符串](#c风格字符串)
2. [C++ string类基础](#c-string类基础)
3. [string类的常用操作](#string类的常用操作)
4. [string类的内存管理](#string类的内存管理)
5. [字符串操作性能优化](#字符串操作性能优化)
6. [实用案例分析](#实用案例分析)
1.C风格字符串
基本概念
C风格字符串本质上是以空字符(`\0`)结尾的字符数组。在C++中,我们仍然可以使用这种方式:
char str[] = "Hello"; // 相当于 {'H', 'e', 'l', 'l', 'o', '\0'}
char* p = "World"; // 字符串字面量,p指向常量区需要注意的是,在新的C++标准中,建议使用`const char*`来表示字符串字面量,因为它们不应被修改:
const char* p = "World"; // 更安全的做法C风格字符串在内存中的表示
为了便于理解,我们可以看看C风格字符串在内存中的表示:
字符串: "Hello"
内存表示:
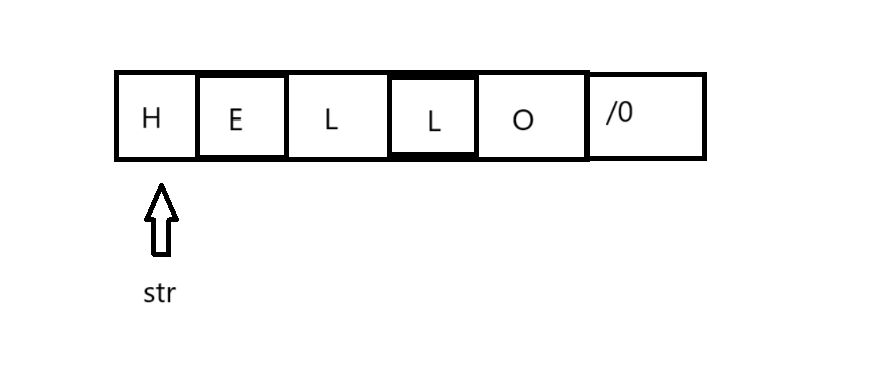
其中`\0`是ASCII值为0的空字符,标志字符串的结束。这就是为什么C风格字符串操作函数需要遍历整个字符串来确定长度 - 它们必须找到这个结束符。
常用函数实际应用
字符串长度计算 (strlen)
#include <cstring>
#include <iostream>
int main() {
char greeting[] = "Hello, C++ programmer!";
size_t length = strlen(greeting);
std::cout << "字符串: \"" << greeting << "\"" << std::endl;
std::cout << "长度: " << length << " 字符" << std::endl;
std::cout << "数组大小: " << sizeof(greeting) << " 字节" << std::endl;
// 输出:
// 字符串: "Hello, C++ programmer!"
// 长度: 22 字符
// 数组大小: 23 字节 (包括结尾的'\0')
return 0;
}字符串复制 (strcpy vs strncpy)
#include <cstring>
#include <iostream>
int main() {
char source[] = "Source string";
char dest1[20]; // 足够大的目标数组
char dest2[5]; // 故意设置小一些的数组
// 安全的复制 (目标足够大)
strcpy(dest1, source);
std::cout << "strcpy 结果: " << dest1 << std::endl;
// 不安全的复制 (可能导致缓冲区溢出)
// strcpy(dest2, source); // 危险!会导致未定义行为
// 安全的有限复制
strncpy(dest2, source, 4);
dest2[4] = '\0'; // 手动添加字符串结束符
std::cout << "strncpy 结果: " << dest2 << std::endl;
// 输出:
// strcpy 结果: Source string
// strncpy 结果: Sour
return 0;
}字符串拼接 (strcat)
#include <cstring>
#include <iostream>
int main() {
char result[50] = "Hello"; // 初始字符串
// 第一次拼接
strcat(result, ", ");
std::cout << "拼接后: " << result << std::endl;
// 第二次拼接
strcat(result, "World");
std::cout << "拼接后: " << result << std::endl;
// 使用strncat限制拼接长度
strncat(result, "! This is a very long string", 1);
std::cout << "限制拼接后: " << result << std::endl;
// 输出:
// 拼接后: Hello,
// 拼接后: Hello, World
// 限制拼接后: Hello, World!
return 0;
}字符串比较 (strcmp)
#include <cstring>
#include <iostream>
int main() {
char str1[] = "apple";
char str2[] = "banana";
char str3[] = "apple";
int result1 = strcmp(str1, str2);
int result2 = strcmp(str1, str3);
int result3 = strcmp(str2, str1);
std::cout << "比较 \"" << str1 << "\" 和 \"" << str2 << "\": ";
if (result1 < 0) std::cout << "str1 < str2" << std::endl;
else if (result1 > 0) std::cout << "str1 > str2" << std::endl;
else std::cout << "str1 == str2" << std::endl;
std::cout << "比较 \"" << str1 << "\" 和 \"" << str3 << "\": ";
if (result2 == 0) std::cout << "相等" << std::endl;
std::cout << "比较 \"" << str2 << "\" 和 \"" << str1 << "\": ";
if (result3 > 0) std::cout << "str2 > str1" << std::endl;
// 部分比较
int partial = strncmp(str1, str2, 1); // 只比较第一个字符
std::cout << "只比较第一个字符: ";
if (partial < 0) std::cout << "'a' < 'b'" << std::endl;
// 输出:
// 比较 "apple" 和 "banana": str1 < str2
// 比较 "apple" 和 "apple": 相等
// 比较 "banana" 和 "apple": str2 > str1
// 只比较第一个字符: 'a' < 'b'
return 0;
}常用函数
C风格字符串操作主要依赖`<cstring>`头文件中的函数:
| 函数 | 功能 | 示例 |
|---|---|---|
strlen(s) | 获取字符串长度(不包括结尾的\0) | size_t len = strlen(str); |
strcpy(dest, src) | 复制字符串 | strcpy(dest, src); |
strncpy(dest, src, n) | 复制指定长度的字符串 | strncpy(dest, src, 10); |
strcat(dest, src) | 字符串拼接 | strcat(dest, src); |
strncat(dest, src, n) | 拼接指定长度的字符串 | strncat(dest, src, 5); |
strcmp(s1, s2) | 字符串比较 | if (strcmp(s1, s2) == 0) {...} |
strncmp(s1, s2, n) | 比较指定长度的字符串 | if (strncmp(s1, s2, 3) == 0) {...} |
strchr(s, c) | 查找字符首次出现位置 | char* pos = strchr(str, 'a'); |
strrchr(s, c) | 查找字符最后出现位置 | char* pos = strrchr(str, 'a'); |
strstr(s1, s2) | 查找子串 | char* pos = strstr(str, "sub"); |
注意事项
1. **内存溢出风险**:
C风格字符串操作不会自动检查边界,容易导致缓冲区溢出。
char small[5];
strcpy(small, "This is too long"); // 危险!会导致缓冲区溢出 **安全的替代方案**:
char small[5];
strncpy(small, "This is too long", 4);
small[4] = '\0'; // 确保添加结束符2. **内存管理责任**:
使用C风格字符串时,程序员需要自己管理内存分配和释放。
char* dynamicStr = new char[100];
strcpy(dynamicStr, "Hello");
// 使用完毕后
delete[] dynamicStr; // 必须释放内存3. **潜在的内存泄漏**:
char* createGreeting(const char* name) {
char* greeting = new char[strlen(name) + 10];
strcpy(greeting, "Hello, ");
strcat(greeting, name);
return greeting;
}
// 使用
char* msg = createGreeting("John");
std::cout << msg << std::endl;
// 如果忘记这一步,会导致内存泄漏
delete[] msg;4. **常见Bug示例**:
// Bug 1: 没有考虑空终止符
char dest[5];
char source[] = "Hello";
strncpy(dest, source, 5); // 复制5个字符,但没有空间给'\0'
// 解决方法:
strncpy(dest, source, 4);
dest[4] = '\0';
// Bug 2: 字符串常量修改
char* str = "Hello";
str[0] = 'h'; // 错误!尝试修改只读内存
// 解决方法:
char str[] = "Hello"; // 创建可修改的副本
str[0] = 'h'; // 正确2.C++ string类基础
头文件与命名空间
#include <string>
using namespace std; // 或使用std::string创建和初始化
#include <string>
#include <iostream>
int main() {
// 1. 默认构造函数 - 空字符串
std::string s1;
std::cout << "s1 (空字符串): [" << s1 << "], 长度: " << s1.length() << std::endl;
// 2. 从C风格字符串初始化
std::string s2 = "Hello";
std::cout << "s2: " << s2 << std::endl;
// 3. 构造函数初始化
std::string s3("World");
std::cout << "s3: " << s3 << std::endl;
// 4. 使用多个相同字符初始化
std::string s4(5, 'a');
std::cout << "s4 (5个'a'): " << s4 << std::endl;
// 5. 拷贝初始化
std::string s5 = s2;
std::cout << "s5 (复制s2): " << s5 << std::endl;
// 6. 子串初始化
std::string s6(s2, 1, 3); // 从s2的位置1开始,3个字符
std::cout << "s6 (s2的子串): " << s6 << std::endl;
// 7. 移动构造 (C++11)
std::string s7 = std::move(s2);
std::cout << "s7 (移动自s2): " << s7 << std::endl;
std::cout << "s2 (移动后): [" << s2 << "]" << std::endl; // s2可能为空或未定义状态
// 8. 初始化列表 (C++11)
std::string s8 = {'H', 'e', 'l', 'l', 'o'};
std::cout << "s8 (初始化列表): " << s8 << std::endl;
// 输出:
// s1 (空字符串): [], 长度: 0
// s2: Hello
// s3: World
// s4 (5个'a'): aaaaa
// s5 (复制s2): Hello
// s6 (s2的子串): ell
// s7 (移动自s2): Hello
// s2 (移动后): []
// s8 (初始化列表): Hello
return 0;
}string与char*的转换
#include <string>
#include <iostream>
#include <cstring>
int main() {
// 1. string转为C风格字符串
std::string cpp_str = "Hello, C++ world!";
// 使用c_str()获取C风格字符串 (const char*)
const char* c_str1 = cpp_str.c_str();
std::cout << "使用c_str(): " << c_str1 << std::endl;
// 使用data()获取底层数据
const char* c_str2 = cpp_str.data();
std::cout << "使用data(): " << c_str2 << std::endl;
// 注意:c_str()和data()返回的指针在string被修改时可能失效
cpp_str += " Modified";
std::cout << "修改后的cpp_str: " << cpp_str << std::endl;
std::cout << "原c_str1可能已失效!" << std::endl;
// 如果需要持久保存,应该复制数据
char* persistent = new char[cpp_str.length() + 1];
strcpy(persistent, cpp_str.c_str());
std::cout << "持久复制: " << persistent << std::endl;
// 2. C风格字符串转为string
const char* name = "John Doe";
std::string cpp_name(name);
std::cout << "C风格转string: " << cpp_name << std::endl;
// 部分转换
std::string partial(name, 4); // 只取前4个字符
std::cout << "部分转换 (前4个字符): " << partial << std::endl;
// 从指定位置
std::string lastname(name + 5); // 跳过"John "
std::cout << "从第5个字符开始: " << lastname << std::endl;
// 清理
delete[] persistent;
// 输出:
// 使用c_str(): Hello, C++ world!
// 使用data(): Hello, C++ world!
// 修改后的cpp_str: Hello, C++ world! Modified
// 原c_str1可能已失效!
// 持久复制: Hello, C++ world! Modified
// C风格转string: John Doe
// 部分转换 (前4个字符): John
// 从第5个字符开始: Doe
return 0;
}创建和初始化
string s1; // 空字符串
string s2 = "Hello"; // 从C风格字符串初始化
string s3("World"); // 构造函数初始化
string s4(5, 'a'); // 创建含有5个'a'的字符串:"aaaaa"
string s5 = s2; // 拷贝初始化
string s6(s2, 1, 3); // 从s2的位置1开始,拷贝3个字符:"ell"string与char*的转换
// string转为C风格字符串
string s = "Hello";
const char* cstr = s.c_str(); // 获取C风格字符串,不能修改
const char* data = s.data(); // 类似c_str(),但在C++11之前可能不包含'\0'
// C风格字符串转为string
char* cstr = "World";
string s(cstr);3.string类的常用操作
访问与修改
#include <string>
#include <iostream>
#include <stdexcept>
int main() {
std::string s = "Hello";
// 访问单个字符 - 使用下标操作符
char first = s[0]; // 'H'
char last = s[4]; // 'o'
std::cout << "首字母: " << first << std::endl;
std::cout << "末字母: " << last << std::endl;
// 使用at()访问 - 带边界检查
try {
char safe = s.at(1); // 'e'
std::cout << "安全访问位置1: " << safe << std::endl;
// 下面这行会抛出std::out_of_range异常
char error = s.at(10);
}
catch (const std::out_of_range& e) {
std::cout << "捕获到边界检查异常: " << e.what() << std::endl;
}
// 修改字符
s[0] = 'h'; // 修改第一个字符
std::cout << "修改后: " << s << std::endl;
s.at(4) = 'O'; // 安全地修改最后一个字符
std::cout << "再次修改: " << s << std::endl;
// 直接访问首尾字符
char front_char = s.front(); // C++11, 等价于s[0]
char back_char = s.back(); // C++11, 等价于s[s.length()-1]
std::cout << "首字符: " << front_char << std::endl;
std::cout << "尾字符: " << back_char << std::endl;
// 输出:
// 首字母: H
// 末字母: o
// 安全访问位置1: e
// 捕获到边界检查异常: invalid string position
// 修改后: hello
// 再次修改: hellO
// 首字符: h
// 尾字符: O
return 0;
}访问与修改
string s = "Hello";
char first = s[0]; // 使用下标访问:'H'
char last = s.at(4); // 使用at()方法(带边界检查):'o'
s[0] = 'h'; // 修改为:"hello"
s.at(4) = 'O'; // 修改为:"hellO"拼接操作
#include <string>
#include <iostream>
int main() {
// 初始字符串
std::string s1 = "Hello";
std::string s2 = "World";
// 1. 使用+运算符拼接
std::string s3 = s1 + " " + s2;
std::cout << "s1 + ' ' + s2 = " << s3 << std::endl;
// 2. 混合拼接字符串和C风格字符串
std::string s4 = s1 + " beautiful " + s2 + "!";
std::cout << "混合拼接: " << s4 << std::endl;
// 3. 使用+=运算符
std::string s5 = "Hi";
s5 += ", ";
s5 += s2;
s5 += "!";
std::cout << "使用+=: " << s5 << std::endl;
// 4. append方法
std::string s6 = "Welcome";
s6.append(" to ");
s6.append(s2);
std::cout << "使用append: " << s6 << std::endl;
// 5. append部分字符串
std::string s7 = "C++";
s7.append(" Programming", 0, 7); // 只添加" Progra"
std::cout << "部分append: " << s7 << std::endl;
// 6. 拼接性能比较 - 推荐用法
std::string efficient;
efficient.reserve(50); // 预留足够空间
efficient += "Efficient ";
efficient += "string ";
efficient += "concatenation";
std::cout << "高效拼接: " << efficient << std::endl;
// 输出:
// s1 + ' ' + s2 = Hello World
// 混合拼接: Hello beautiful World!
// 使用+=: Hi, World!
// 使用append: Welcome to World
// 部分append: C++ Progra
// 高效拼接: Efficient string concatenation
return 0;
}拼接操作
string s1 = "Hello";
string s2 = "World";
string s3 = s1 + " " + s2; // "Hello World"
s1 += " " + s2; // s1变为:"Hello World"子串与插入
#include <string>
#include <iostream>
int main() {
std::string original = "Hello World! How are you?";
// 1. 获取子串
std::string sub1 = original.substr(6, 5); // 从位置6开始,长度为5
std::cout << "substring(6, 5): " << sub1 << std::endl;
// 2. 获取到末尾的子串
std::string sub2 = original.substr(13); // 从位置13到结尾
std::cout << "substring(13): " << sub2 << std::endl;
// 3. 尝试获取超出范围的子串
try {
std::string sub_error = original.substr(100, 5);
}
catch (const std::out_of_range& e) {
std::cout << "子串越界: " << e.what() << std::endl;
}
// 4. 基本插入操作
std::string s = "Hello World";
s.insert(5, " Beautiful");
std::cout << "插入字符串: " << s << std::endl;
// 5. 在指定位置插入字符
s.insert(s.length(), '!');
std::cout << "插入字符: " << s << std::endl;
// 6. 在指定位置插入多个相同字符
s.insert(0, 3, '*');
std::cout << "插入3个星号: " << s << std::endl;
// 7. 插入C风格字符串的一部分
std::string target = "Example";
const char* source = "INSERTION";
target.insert(2, source, 5); // 在位置2插入source的前5个字符
std::cout << "插入C字符串的一部分: " << target << std::endl;
// 8. 使用迭代器插入
std::string iter_example = "135";
auto it = iter_example.begin() + 1; // 指向'3'前面的位置
iter_example.insert(it, '2');
it = iter_example.begin() + 3; // 现在指向'5'前面的位置
iter_example.insert(it, '4');
std::cout << "使用迭代器插入: " << iter_example << std::endl;
// 输出:
// substring(6, 5): World
// substring(13): How are you?
// 子串越界: basic_string::substr: __pos (which is 100) > this->size() (which is 24)
// 插入字符串: Hello Beautiful World
// 插入字符: Hello Beautiful World!
// 插入3个星号: ***Hello Beautiful World!
// 插入C字符串的一部分: ExINSERample
// 使用迭代器插入: 12345
return 0;
}子串与插入
string s = "Hello World";
string sub = s.substr(6, 5); // 从位置6开始,长度为5的子串:"World"
s.insert(5, " Beautiful"); // 在位置5插入:Hello Beautiful World删除操作
#include <string>
#include <iostream>
int main() {
// 基本删除操作
std::string s1 = "Hello World";
std::string original = s1;
// 1. 删除指定位置的指定数量字符
s1.erase(5, 1); // 删除位置5的1个字符(空格)
std::cout << "删除空格: [" << s1 << "]" << std::endl;
// 2. 删除指定位置到末尾的所有字符
s1 = original;
s1.erase(5); // 删除位置5及之后的所有字符
std::cout << "只保留Hello: [" << s1 << "]" << std::endl;
// 3. 使用迭代器删除单个字符
s1 = original;
auto it = s1.begin() + 5; // 指向空格
s1.erase(it);
std::cout << "使用迭代器删除空格: [" << s1 << "]" << std::endl;
// 4. 使用迭代器范围删除多个字符
s1 = original;
auto start = s1.begin() + 5; // 指向空格
auto end = s1.begin() + 11; // 指向末尾后一个位置
s1.erase(start, end);
std::cout << "删除范围: [" << s1 << "]" << std::endl;
// 5. 清空字符串
s1.clear();
std::cout << "清空后长度: " << s1.length()
<< ", 空字符串: [" << s1 << "]" << std::endl;
// 6. 删除特定字符 (如空白)
std::string text = " Remove extra spaces ";
// 去除前导空白
size_t start_pos = text.find_first_not_of(" \t\n\r");
if (start_pos != std::string::npos) {
text.erase(0, start_pos);
}
std::cout << "去除前导空白: [" << text << "]" << std::endl;
// 去除尾部空白
size_t end_pos = text.find_last_not_of(" \t\n\r");
if (end_pos != std::string::npos) {
text.erase(end_pos + 1);
}
std::cout << "去除尾部空白: [" << text << "]" << std::endl;
// 输出:
// 删除空格: [HelloWorld]
// 只保留Hello: [Hello]
// 使用迭代器删除空格: [HelloWorld]
// 删除范围: [Hello]
// 清空后长度: 0, 空字符串: []
// 去除前导空白: [Remove extra spaces ]
// 去除尾部空白: [Remove extra spaces]
return 0;
}删除操作
string s = "Hello World";
s.erase(5, 1); // 删除位置5的空格:HelloWorld
s.erase(5); // 删除位置5及之后的所有字符:Hello查找操作
#include <string>
#include <iostream>
#include <iomanip> // 用于格式化输出
// 辅助函数:显示查找结果
void showPosition(const std::string& str, size_t pos) {
if (pos == std::string::npos) {
std::cout << "未找到" << std::endl;
return;
}
std::cout << "位置: " << pos << std::endl;
// 显示位置示意图
std::cout << str << std::endl;
std::cout << std::string(pos, ' ') << "^" << std::endl;
}
int main() {
std::string haystack = "Hello World! Welcome to the C++ programming world!";
// 1. 基本查找 - 查找子串
std::cout << "在字符串中查找 'World':" << std::endl;
size_t pos1 = haystack.find("World");
showPosition(haystack, pos1);
// 2. 查找单个字符
std::cout << "\n查找字符 'o':" << std::endl;
size_t pos2 = haystack.find('o');
showPosition(haystack, pos2);
// 3. 从指定位置开始查找
std::cout << "\n从位置8开始查找 'o':" << std::endl;
size_t pos3 = haystack.find('o', 8);
showPosition(haystack, pos3);
// 4. 查找不存在的字符串
std::cout << "\n查找不存在的字符串 'Python':" << std::endl;
size_t pos4 = haystack.find("Python");
if (pos4 == std::string::npos) {
std::cout << "未找到 'Python'" << std::endl;
}
// 5. 从后向前查找 (rfind)
std::cout << "\n从后向前查找 'o':" << std::endl;
size_t pos5 = haystack.rfind('o');
showPosition(haystack, pos5);
// 6. 查找任意一个字符首次出现 (find_first_of)
std::cout << "\n查找'aeiou'中任意一个字符首次出现:" << std::endl;
size_t pos6 = haystack.find_first_of("aeiou");
showPosition(haystack, pos6);
// 7. 查找不在指定字符集中的字符 (find_first_not_of)
std::cout << "\n查找首个不是字母或空格的字符:" << std::endl;
size_t pos7 = haystack.find_first_not_of("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ ");
showPosition(haystack, pos7);
// 8. 查找指定字符集中的字符最后一次出现 (find_last_of)
std::cout << "\n查找'aeiou'中任意一个字符最后一次出现:" << std::endl;
size_t pos8 = haystack.find_last_of("aeiou");
showPosition(haystack, pos8);
// 9. 使用find_first_of实现单词分割
std::string sentence = "Breaking,this,into,words";
std::cout << "\n分割字符串 '" << sentence << "':" << std::endl;
size_t start = 0;
size_t end = sentence.find_first_of(",");
while (end != std::string::npos) {
std::cout << " - " << sentence.substr(start, end - start) << std::endl;
start = end + 1;
end = sentence.find_first_of(",", start);
}
std::cout << " - " << sentence.substr(start) << std::endl;
// 输出类似:
// 在字符串中查找 'World':
// 位置: 6
// Hello World! Welcome to the C++ programming world!
// ^
// ... (其他输出)
return 0;
}查找操作
string s = "Hello World";
size_t pos = s.find("World"); // 查找子串,返回首次出现的位置:6
pos = s.find('o'); // 查找字符:4
// 如果未找到,返回string::npos
if (s.find("Bye") == string::npos) {
cout << "未找到子串" << endl;
}
// 从指定位置开始查找
pos = s.find('o', 5); // 从位置5开始查找'o':7
// 反向查找
pos = s.rfind('o'); // 从后向前查找'o',返回最后一次出现的位置:7替换操作
#include <string>
#include <iostream>
int main() {
// 基本替换操作
std::string s = "Hello World";
std::string original = s;
// 1. 替换指定位置和长度
s.replace(6, 5, "C++");
std::cout << "基本替换: " << s << std::endl;
// 2. 替换为重复字符
s = original;
s.replace(6, 5, 3, '*'); // 用3个*替换"World"
std::cout << "替换为重复字符: " << s << std::endl;
// 3. 使用C风格字符串替换
s = original;
const char* replacement = "Universe";
s.replace(6, 5, replacement);
std::cout << "使用C字符串替换: " << s << std::endl;
// 4. 使用部分C风格字符串替换
s = original;
s.replace(6, 5, replacement, 4); // 只使用"Univ"
std::cout << "部分C字符串替换: " << s << std::endl;
// 5. 使用另一个string对象的部分内容替换
s = original;
std::string other = "Beautiful Planet";
s.replace(6, 5, other, 0, 9); // 使用"Beautiful"
std::cout << "部分string替换: " << s << std::endl;
// 6. 使用迭代器范围替换
s = original;
std::string iter_repl = "C++ Language";
s.replace(s.begin() + 6, s.end(), iter_repl.begin(), iter_repl.begin() + 3);
std::cout << "迭代器范围替换: " << s << std::endl;
// 7. 全局替换所有出现的子串
std::string text = "The cat sat on the mat with another cat";
std::string from = "cat";
std::string to = "dog";
size_t pos = 0;
while ((pos = text.find(from, pos)) != std::string::npos) {
text.replace(pos, from.length(), to);
pos += to.length(); // 跳过刚刚替换的内容
}
std::cout << "全局替换: " << text << std::endl;
// 输出:
// 基本替换: Hello C++
// 替换为重复字符: Hello ***
// 使用C字符串替换: Hello Universe
// 部分C字符串替换: Hello Univ
// 部分string替换: Hello Beautiful
// 迭代器范围替换: Hello C++
// 全局替换: The dog sat on the mat with another dog
return 0;
}替换操作
string s = "Hello World";
s.replace(6, 5, "C++"); // 替换位置6开始的5个字符:Hello C++
比较操作
#include <string>
#include <iostream>
#include <iomanip> // 用于格式化输出
// 辅助函数:显示比较结果
void showCompareResult(const std::string& s1, const std::string& s2, int result) {
std::cout << "比较 \"" << s1 << "\" 和 \"" << s2 << "\": ";
if (result < 0)
std::cout << "s1 < s2" << std::endl;
else if (result > 0)
std::cout << "s1 > s2" << std::endl;
else
std::cout << "s1 == s2" << std::endl;
}
int main() {
// 准备测试字符串
std::string s1 = "apple";
std::string s2 = "banana";
std::string s3 = "apple";
std::string s4 = "applesauce";
std::string s5 = "APPLE";
// 1. 使用比较运算符
std::cout << "使用比较运算符:" << std::endl;
std::cout << std::boolalpha; // 使bool值显示为true/false而非1/0
std::cout << "s1 == s3: " << (s1 == s3) << std::endl; // true
std::cout << "s1 != s2: " << (s1 != s2) << std::endl; // true
std::cout << "s1 < s2: " << (s1 < s2) << std::endl; // true
std::cout << "s2 > s1: " << (s2 > s1) << std::endl; // true
std::cout << "s1 <= s3: " << (s1 <= s3) << std::endl; // true
std::cout << "s1 >= s3: " << (s1 >= s3) << std::endl; // true
// 2. 使用compare方法
std::cout << "\n使用compare方法:" << std::endl;
int result1 = s1.compare(s2);
showCompareResult(s1, s2, result1);
int result2 = s1.compare(s3);
showCompareResult(s1, s3, result2);
int result3 = s2.compare(s1);
showCompareResult(s2, s1, result3);
// 3. 比较部分字符串
std::cout << "\n比较部分字符串:" << std::endl;
// 比较s1从位置0开始的4个字符与s4从位置0开始的4个字符
int result4 = s1.compare(0, 4, s4, 0, 4);
std::cout << "比较 \"" << s1.substr(0, 4) << "\" 和 \"" << s4.substr(0, 4) << "\": "
<< (result4 == 0 ? "相等" : "不相等") << std::endl;
// 4. 大小写敏感比较
std::cout << "\n大小写敏感比较:" << std::endl;
int result5 = s1.compare(s5);
showCompareResult(s1, s5, result5);
// 5. 自定义比较函数(不区分大小写)
std::cout << "\n不区分大小写比较:" << std::endl;
auto caseInsensitiveCompare = [](const std::string& a, const std::string& b) -> bool {
if (a.length() != b.length()) return false;
for (size_t i = 0; i < a.length(); ++i) {
if (tolower(a[i]) != tolower(b[i])) return false;
}
return true;
};
bool equal = caseInsensitiveCompare(s1, s5);
std::cout << "不区分大小写比较 \"" << s1 << "\" 和 \"" << s5 << "\": "
<< (equal ? "相等" : "不相等") << std::endl;
// 输出:
// 使用比较运算符:
// s1 == s3: true
// s1 != s2: true
// s1 < s2: true
// s2 > s1: true
// s1 <= s3: true
// s1 >= s3: true
//
// 使用compare方法:
// 比较 "apple" 和 "banana": s1 < s2
// 比较 "apple" 和 "apple": s1 == s2
// 比较 "banana" 和 "apple": s1 > s2
//
// 比较部分字符串:
// 比较 "appl" 和 "appl": 相等
//
// 大小写敏感比较:
// 比较 "apple" 和 "APPLE": s1 > s2
//
// 不区分大小写比较:
// 不区分大小写比较 "apple" 和 "APPLE": 相等
return 0;
}比较操作
string s1 = "abc";
string s2 = "abd";
if (s1 == s2) { /* 相等 */ }
if (s1 != s2) { /* 不相等 */ }
if (s1 < s2) { /* s1小于s2 */ } // 字典序比较
if (s1 > s2) { /* s1大于s2 */ }
if (s1 <= s2) { /* s1小于等于s2 */ }
if (s1 >= s2) { /* s1大于等于s2 */ }
// 也可以使用compare方法
int result = s1.compare(s2); // 小于0表示s1<s2,等于0表示s1=s2,大于0表示s1>s24.string类的内存管理
string类是一个动态内存管理的类,它会根据需要自动调整内存大小。了解其内存管理机制有助于写出更高效的代码。
字符串的长度和容量
string s = "Hello";
size_t len = s.length(); // 字符串长度:5(等价于s.size())
size_t cap = s.capacity(); // 字符串当前分配的容量(通常大于长度)
cout << "长度: " << len << ", 容量: " << cap << endl;容量的自动调整
当字符串内容需要更多空间时,string会自动扩容:
string s = "Hello";
cout << "初始容量: " << s.capacity() << endl; // 例如15
s += " World!";
cout << "追加后容量: " << s.capacity() << endl; // 可能扩大到31
// 多次追加会导致多次重新分配
for (int i = 0; i < 10; i++) {
s += " Hello";
cout << "第" << i << "次追加后容量: " << s.capacity() << endl;
}reserve预留空间
使用`reserve()`可以预先分配足够的空间,避免频繁的内存重新分配:
string s;
s.reserve(100); // 预留100个字符的空间
cout << "预留后容量: " << s.capacity() << endl; // 至少100
// 在容量范围内添加不会导致重新分配
for (int i = 0; i < 10; i++) {
s += "Hello";
}
cout << "多次追加后容量: " << s.capacity() << endl; // 仍然是预留的容量resize改变字符串大小
string s = "Hello";
s.resize(10); // 扩展到10个字符,新增的用'\0'填充
cout << s << ", 长度: " << s.length() << endl; // "Hello", 长度: 10
s.resize(10, '*'); // 扩展到10个字符,新增的用'*'填充
cout << s << endl; // "Hello*****"
s.resize(3); // 截断为3个字符
cout << s << endl; // "Hel"shrink_to_fit收缩多余空间
在不需要额外容量时,可以释放多余空间:
string s = "Hello World";
s.reserve(100); // 预留大量空间
cout << "预留后容量: " << s.capacity() << endl; // 至少100
s.shrink_to_fit(); // 收缩到实际需要的大小
cout << "收缩后容量: " << s.capacity() << endl; // 接近字符串长度string::reserve实现原理
当调用`reserve()`函数时,string类会执行以下操作:
1. 检查请求的容量是否大于当前容量
2. 如果需要扩容,则分配新的更大内存块
3. 将原有数据复制到新内存
4. 释放旧内存
5. 更新内部指针和容量计数
这个过程可以示意如下:
// 假设string的简化实现
class SimpleString {
private:
char* data; // 指向实际字符数据的指针
size_t length; // 字符串长度
size_t capacity; // 当前分配的容量
public:
void reserve(size_t new_capacity) {
if (new_capacity <= capacity)
return; // 已有足够容量,不需操作
// 分配新内存
char* new_data = new char[new_capacity + 1]; // +1为了存储结尾的'\0'
// 复制现有数据
if (data) {
std::memcpy(new_data, data, length + 1);
delete[] data; // 释放旧内存
}
// 更新指针和容量
data = new_data;
capacity = new_capacity;
}
// 其他成员函数...
};5.字符串操作性能优化
容量预留
对于需要频繁追加的字符串,预先分配足够的空间可以避免多次重新分配内存:
// 低效的方式
void badPerformance() {
string result;
for (int i = 0; i < 10000; i++) {
result += "Hello"; // 可能导致多次内存重新分配
}
}
// 高效的方式
void goodPerformance() {
string result;
result.reserve(50000); // 预留足够空间
for (int i = 0; i < 10000; i++) {
result += "Hello"; // 不会导致内存重新分配
}
}性能对比:
- 未使用reserve:多次重新分配内存,时间复杂度可能达到O(n²)
- 使用reserve:只分配一次内存,时间复杂度降至O(n)
避免不必要的拷贝
使用引用传递和移动语义可以提高性能:
// 不好的做法(产生拷贝)
string concatenate(string a, string b) {
return a + b;
}
// 更好的做法(避免拷贝)
string concatenate(const string& a, const string& b) {
return a + b;
}
// C++11移动语义
string getResult() {
string result = "Result";
return result; // 编译器可能应用返回值优化(RVO)或移动语义
}
// 移动语义的显式使用
void processStrings() {
string heavy = "很长的字符串...";
string target;
// 移动而非复制
target = std::move(heavy); // heavy内容被移动到target,heavy变为空
}string_view (C++17)
对于只读操作,使用`std::string_view`可以避免不必要的内存分配:
#include <string_view>
// 传统方式:会创建string的副本
void processOld(const std::string& s) {
std::cout << s.substr(0, 5) << std::endl;
}
// 高效方式:不创建副本
void processNew(std::string_view sv) {
std::cout << sv.substr(0, 5) << std::endl;
}
// 使用示例
void example() {
std::string s = "Hello World";
// 字符串字面量直接传递
processNew("直接传字面量"); // 不会创建string对象
// string也可以直接传递
processNew(s); // 不会创建新的string
// 创建子视图也不会分配新内存
std::string_view sv = s;
std::string_view subview = sv.substr(0, 5); // 不会分配新内存
}字符串池化
对于频繁使用的固定字符串,可以考虑使用字符串池:
#include <unordered_map>
#include <string>
class StringPool {
private:
std::unordered_map<std::string, std::string> pool;
public:
const std::string& intern(const std::string& s) {
auto it = pool.find(s);
if (it != pool.end()) {
return it->second; // 返回池中已有的字符串引用
}
auto result = pool.emplace(s, s);
return result.first->second; // 返回新添加的字符串引用
}
};
// 使用示例
void example() {
StringPool pool;
// 频繁使用的字符串
for (int i = 0; i < 1000; i++) {
const std::string& s1 = pool.intern("Hello");
const std::string& s2 = pool.intern("World");
// s1和s2分别只存储了一份实际数据
}
}字符串与数值转换
// 字符串转数值
string numStr = "123";
int num = stoi(numStr); // 字符串转int:123
double dNum = stod("3.14"); // 字符串转double:3.14
// 带错误处理的转换
try {
int x = stoi("not_a_number");
} catch (const std::invalid_argument& e) {
cout << "无效参数: " << e.what() << endl;
} catch (const std::out_of_range& e) {
cout << "超出范围: " << e.what() << endl;
}
// 数值转字符串
string s1 = to_string(42); // 整数转字符串:"42"
string s2 = to_string(3.14); // 浮点数转字符串:"3.14"6.实用案例分析
案例1:字符串分割
vector<string> split(const string& s, char delimiter) {
vector<string> tokens;
string token;
istringstream tokenStream(s);
while (getline(tokenStream, token, delimiter)) {
if (!token.empty()) {
tokens.push_back(token);
}
}
return tokens;
}
// 使用
string text = "apple,banana,orange";
vector<string> fruits = split(text, ',');
// fruits包含:"apple", "banana", "orange"案例2:字符串连接
string join(const vector<string>& v, const string& delimiter) {
// 计算最终字符串的长度,优化性能
size_t totalLength = 0;
for (const auto& s : v) {
totalLength += s.length();
}
totalLength += delimiter.length() * (v.size() > 0 ? v.size() - 1 : 0);
// 预分配空间
string result;
result.reserve(totalLength);
// 连接字符串
for (size_t i = 0; i < v.size(); i++) {
if (i > 0) {
result += delimiter;
}
result += v[i];
}
return result;
}
// 使用
vector<string> words = {"Hello", "World", "C++"};
string sentence = join(words, " ");
// sentence为:"Hello World C++"案例3:字符串替换
void replaceAll(string& str, const string& from, const string& to) {
// 如果替换的结果会更长,预先计算并预留空间
if (to.length() > from.length()) {
size_t count = 0;
size_t pos = 0;
while ((pos = str.find(from, pos)) != string::npos) {
++count;
pos += from.length();
}
str.reserve(str.length() + count * (to.length() - from.length()));
}
// 执行替换
size_t pos = 0;
while ((pos = str.find(from, pos)) != string::npos) {
str.replace(pos, from.length(), to);
pos += to.length();
}
}
// 使用
string text = "The cat sat on the mat with another cat";
replaceAll(text, "cat", "dog");
// text变为:"The dog sat on the mat with another dog"案例4:字符串转换工具
// 转换为大写
string toUpper(const string& s) {
string result = s;
for (char& c : result) {
c = toupper(c);
}
return result;
}
// 转换为小写
string toLower(const string& s) {
string result = s;
for (char& c : result) {
c = tolower(c);
}
return result;
}
// 修剪字符串首尾空白
string trim(const string& s) {
const char* whitespace = " \t\n\r\f\v";
// 找到第一个非空白字符
size_t start = s.find_first_not_of(whitespace);
if (start == string::npos) return ""; // 全是空白
// 找到最后一个非空白字符
size_t end = s.find_last_not_of(whitespace);
// 提取子字符串
return s.substr(start, end - start + 1);
}实际项目应用场景
场景1:配置文件解析
#include <string>
#include <fstream>
#include <unordered_map>
#include <iostream>
// 配置文件解析器
class ConfigParser {
private:
std::unordered_map<std::string, std::string> configs;
// 修剪空白
std::string trim(const std::string& s) {
const char* whitespace = " \t\n\r\f\v";
size_t start = s.find_first_not_of(whitespace);
if (start == std::string::npos) return "";
size_t end = s.find_last_not_of(whitespace);
return s.substr(start, end - start + 1);
}
public:
bool loadFromFile(const std::string& filename) {
std::ifstream file(filename);
if (!file.is_open()) {
return false;
}
std::string line;
while (std::getline(file, line)) {
// 跳过空行和注释行
std::string trimmed = trim(line);
if (trimmed.empty() || trimmed[0] == '#') {
continue;
}
// 查找分隔符
size_t pos = trimmed.find('=');
if (pos != std::string::npos) {
std::string key = trim(trimmed.substr(0, pos));
std::string value = trim(trimmed.substr(pos + 1));
// 存储配置项
configs[key] = value;
}
}
return true;
}
std::string getValue(const std::string& key, const std::string& defaultValue = "") const {
auto it = configs.find(key);
if (it != configs.end()) {
return it->second;
}
return defaultValue;
}
int getIntValue(const std::string& key, int defaultValue = 0) const {
auto it = configs.find(key);
if (it != configs.end()) {
try {
return std::stoi(it->second);
} catch (...) {
return defaultValue;
}
}
return defaultValue;
}
bool getBoolValue(const std::string& key, bool defaultValue = false) const {
auto it = configs.find(key);
if (it != configs.end()) {
std::string value = trim(it->second);
if (value == "true" || value == "yes" || value == "1") return true;
if (value == "false" || value == "no" || value == "0") return false;
}
return defaultValue;
}
};
// 使用示例
void configExample() {
ConfigParser config;
if (config.loadFromFile("settings.conf")) {
std::string serverName = config.getValue("server_name", "localhost");
int port = config.getIntValue("port", 8080);
bool debugMode = config.getBoolValue("debug", false);
std::cout << "服务器: " << serverName << ":" << port << std::endl;
std::cout << "调试模式: " << (debugMode ? "开启" : "关闭") << std::endl;
} else {
std::cout << "无法加载配置文件" << std::endl;
}
}场景2:URL解析
#include <string>
#include <unordered_map>
#include <iostream>
// URL解析器
class URLParser {
private:
std::string scheme;
std::string host;
int port;
std::string path;
std::string query;
std::string fragment;
std::unordered_map<std::string, std::string> queryParams;
void parseQueryParams() {
if (query.empty()) return;
size_t startPos = 0;
while (startPos < query.length()) {
size_t endPos = query.find('&', startPos);
if (endPos == std::string::npos) {
endPos = query.length();
}
std::string param = query.substr(startPos, endPos - startPos);
size_t equalPos = param.find('=');
if (equalPos != std::string::npos) {
std::string key = param.substr(0, equalPos);
std::string value = param.substr(equalPos + 1);
queryParams[key] = value;
} else {
queryParams[param] = "";
}
startPos = endPos + 1;
}
}
public:
bool parse(const std::string& url) {
// 找到冒号和双斜杠分隔协议
size_t protocolEnd = url.find("://");
if (protocolEnd != std::string::npos) {
scheme = url.substr(0, protocolEnd);
protocolEnd += 3; // 跳过"://"
} else {
protocolEnd = 0; // 没有协议
}
// 找到主机结尾(可能是端口、路径或查询)
size_t hostEnd = url.find_first_of(":/?\#", protocolEnd);
if (hostEnd == std::string::npos) {
host = url.substr(protocolEnd);
return true;
}
host = url.substr(protocolEnd, hostEnd - protocolEnd);
// 检查端口
if (url[hostEnd] == ':') {
size_t portEnd = url.find_first_of("/?\#", hostEnd);
std::string portStr = url.substr(hostEnd + 1,
(portEnd == std::string::npos ? url.length() : portEnd) - hostEnd - 1);
try {
port = std::stoi(portStr);
} catch (...) {
port = 0; // 无效端口
return false;
}
hostEnd = portEnd;
if (hostEnd == std::string::npos) return true;
}
// 解析路径
if (url[hostEnd] == '/') {
size_t pathEnd = url.find_first_of("?\#", hostEnd);
path = url.substr(hostEnd, (pathEnd == std::string::npos ? url.length() : pathEnd) - hostEnd);
hostEnd = pathEnd;
if (hostEnd == std::string::npos) return true;
}
// 解析查询参数
if (url[hostEnd] == '?') {
size_t queryEnd = url.find('#', hostEnd);
query = url.substr(hostEnd + 1,
(queryEnd == std::string::npos ? url.length() : queryEnd) - hostEnd - 1);
parseQueryParams();
hostEnd = queryEnd;
if (hostEnd == std::string::npos) return true;
}
// 解析片段
if (url[hostEnd] == '#') {
fragment = url.substr(hostEnd + 1);
}
return true;
}
std::string getScheme() const { return scheme; }
std::string getHost() const { return host; }
int getPort() const { return port; }
std::string getPath() const { return path; }
std::string getQuery() const { return query; }
std::string getFragment() const { return fragment; }
std::string getQueryParam(const std::string& name, const std::string& defaultValue = "") const {
auto it = queryParams.find(name);
if (it != queryParams.end()) {
return it->second;
}
return defaultValue;
}
};
// 使用示例
void urlExample() {
URLParser parser;
if (parser.parse("https://www.example.com:8080/path/to/resource?param1=value1¶m2=value2#section1")) {
std::cout << "协议: " << parser.getScheme() << std::endl;
std::cout << "主机: " << parser.getHost() << std::endl;
std::cout << "端口: " << parser.getPort() << std::endl;
std::cout << "路径: " << parser.getPath() << std::endl;
std::cout << "参数param1: " << parser.getQueryParam("param1") << std::endl;
std::cout << "参数param2: " << parser.getQueryParam("param2") << std::endl;
std::cout << "片段: " << parser.getFragment() << std::endl;
}
}场景3:日志格式化
#include <string>
#include <iostream>
#include <chrono>
#include <iomanip>
#include <sstream>
// 简单日志格式化器
class LogFormatter {
private:
// 获取当前时间戳
std::string getCurrentTimestamp() {
auto now = std::chrono::system_clock::now();
auto time_t = std::chrono::system_clock::to_time_t(now);
auto ms = std::chrono::duration_cast<std::chrono::milliseconds>(
now.time_since_epoch()) % 1000;
std::stringstream ss;
ss << std::put_time(std::localtime(&time_t), "%Y-%m-%d %H:%M:%S");
ss << '.' << std::setfill('0') << std::setw(3) << ms.count();
return ss.str();
}
// 替换格式化占位符
std::string format(const std::string& pattern, const std::unordered_map<std::string, std::string>& values) {
std::string result;
result.reserve(pattern.length() * 2); // 预留足够空间
size_t pos = 0;
while (pos < pattern.length()) {
size_t placeholderStart = pattern.find('{', pos);
if (placeholderStart == std::string::npos) {
// 没有更多占位符
result += pattern.substr(pos);
break;
}
// 添加占位符前的内容
result += pattern.substr(pos, placeholderStart - pos);
// 寻找占位符结束位置
size_t placeholderEnd = pattern.find('}', placeholderStart);
if (placeholderEnd == std::string::npos) {
// 未闭合的占位符,当作普通文本
result += pattern.substr(placeholderStart);
break;
}
// 提取占位符名称
std::string placeholder = pattern.substr(placeholderStart + 1,
placeholderEnd - placeholderStart - 1);
// 替换占位符
auto it = values.find(placeholder);
if (it != values.end()) {
result += it->second;
} else {
// 未知占位符保留原样
result += "{" + placeholder + "}";
}
// 更新位置
pos = placeholderEnd + 1;
}
return result;
}
public:
enum LogLevel {
DEBUG,
INFO,
WARNING,
ERROR
};
std::string formatLog(LogLevel level, const std::string& message,
const std::string& component = "main") {
std::string levelStr;
switch (level) {
case DEBUG: levelStr = "DEBUG"; break;
case INFO: levelStr = "INFO"; break;
case WARNING: levelStr = "WARNING"; break;
case ERROR: levelStr = "ERROR"; break;
}
std::unordered_map<std::string, std::string> values = {
{"timestamp", getCurrentTimestamp()},
{"level", levelStr},
{"component", component},
{"message", message}
};
return format("[{timestamp}] [{level}] [{component}] {message}", values);
}
};
// 使用示例
void logExample() {
LogFormatter formatter;
std::cout << formatter.formatLog(LogFormatter::INFO, "系统启动成功", "System") << std::endl;
std::cout << formatter.formatLog(LogFormatter::WARNING, "磁盘空间不足", "Storage") << std::endl;
std::cout << formatter.formatLog(LogFormatter::ERROR, "数据库连接失败: 超时", "Database") << std::endl;
// 输出类似:
// [2023-11-30 15:30:45.123] [INFO] [System] 系统启动成功
// [2023-11-30 15:30:45.124] [WARNING] [Storage] 磁盘空间不足
// [2023-11-30 15:30:45.124] [ERROR] [Database] 数据库连接失败: 超时
}字符串处理的最佳实践
1. 性能优化
- **预分配内存**:使用`reserve()`避免频繁重新分配
- **引用传递**:优先使用`const string&`作为函数参数
- **移动语义**:利用`std::move()`减少不必要的复制
- **string_view**:对于只读操作,使用C++17的`string_view`
2. 安全使用
- **边界检查**:优先使用带边界检查的`at()`而非`[]`访问单个字符
- **容错处理**:解析和转换操作要有异常处理
- **输入验证**:处理用户输入时,先验证长度和内容
3. 避免常见陷阱
- **内存泄漏**:确保在使用C风格字符串时正确释放动态分配的内存
- **错误的字符串比较**:理解`==`和`compare()`的正确使用方式
- **失效的指针**:避免使用可能失效的`c_str()`或`data()`返回值
- **编码问题**:注意处理UTF-8等多字节编码
4. 接口设计
- **一致性**:在项目中保持一致的字符串处理风格
- **显式转换**:字符串与其他类型间的转换应该是明确的,不依赖隐式转换
- **可扩展性**:设计接受字符串的接口时,考虑未来可能的字符集变化
总结
C++提供了丰富的字符串处理功能,从C风格的底层操作到高级的string类。掌握这些功能可以让你的代码更加简洁、高效和安全。
关键要点回顾:
1. **C风格字符串**:简单但需要手动管理内存和注意缓冲区溢出。
2. **std::string**:现代C++首选的字符串处理方式,自动管理内存。
3. **内存管理**:了解并合理使用`reserve()`和`shrink_to_fit()`可以显著提高性能。
4. **性能优化**:
- 合理预留空间避免频繁重新分配
- 使用引用传递减少拷贝
- 利用C++17的`string_view`处理只读操作
- 对于关键路径,考虑自定义字符串池化方案
5. **实用技巧**:掌握字符串分割、连接、替换等常见操作的高效实现。
在实际开发中,推荐优先使用`std::string`而非C风格字符串,以避免内存问题并获得更好的可读性。对于性能敏感的场景,可以考虑使用`std::string_view`、容量预留以及移动语义等优化技巧。
希望这篇博客能帮助你更好地理解和使用C++中的字符串操作!
参考资料
- C++ Reference: [std::string](https://en.cppreference.com/w/cpp/string/basic_string)
- C++ Reference: [std::string_view](https://en.cppreference.com/w/cpp/string/basic_string_view) (C++17)
- C++ Reference: [cstring](https://en.cppreference.com/w/cpp/header/cstring)