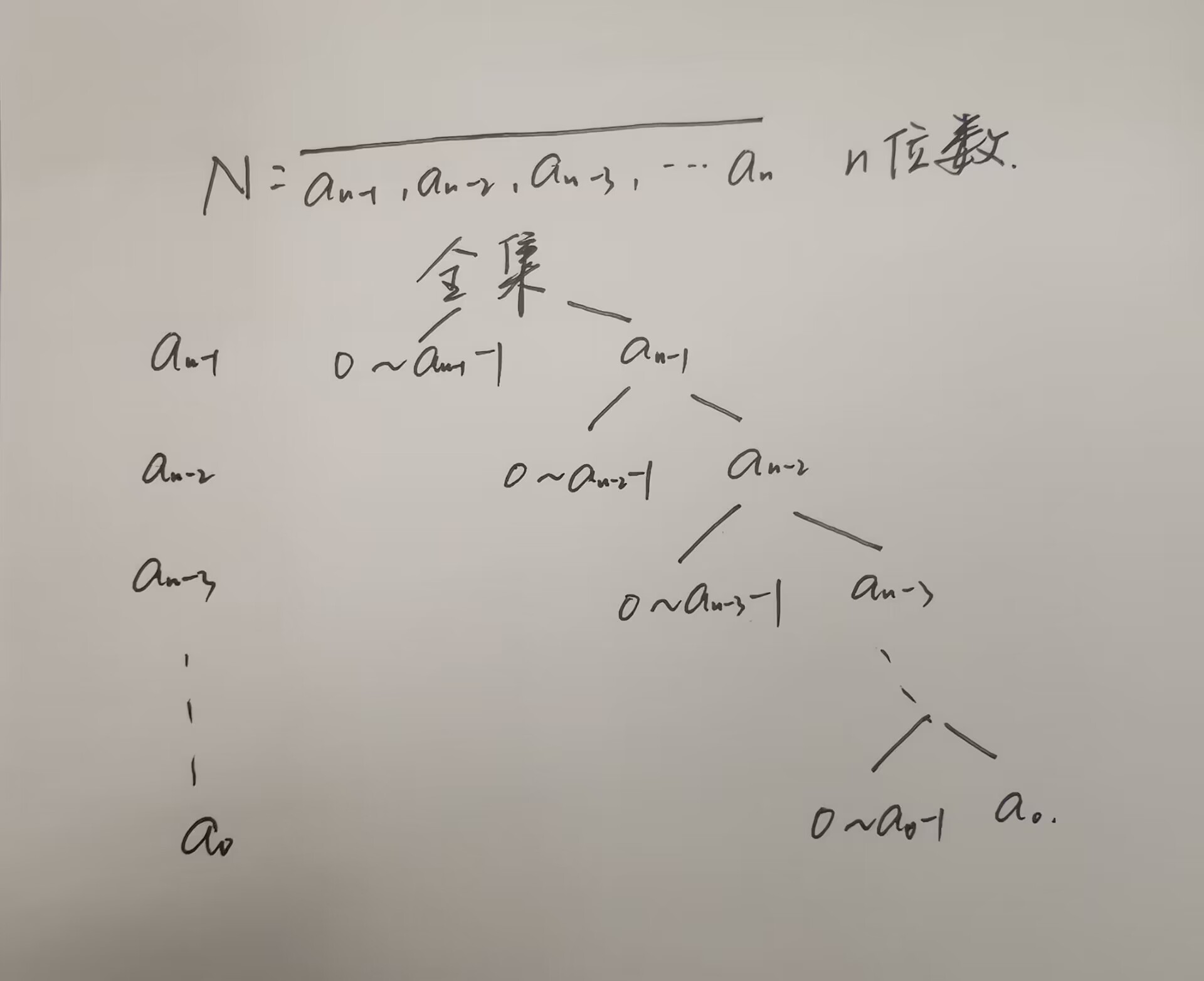
无监督图像到图像转换方法学习将给定类中的图像映射到不同类中的类似图像,使用非结构化(非注册)图像数据集。虽然非常成功,但目前的方法需要在训练时访问源类和目标类中的许多图像。我们认为这极大地限制了它们的使用。从人类从少量示例中提取新对象的本质并从中进行概括的能力中汲取灵感,我们寻求一种少量镜头,无监督的图像到图像的转换算法,该算法适用于以前未见过的目标类,在测试时,仅由少量示例图像指定。我们的模型通过将对抗性训练方案与新颖的网络设计耦合起来,实现了这种少数射击生成能力。通过广泛的实验验证和与基准数据集上的几种基线方法的比较,我们验证了所提出的框架的有效性。我们的实现和数据集可在:
https://github.com/NVlabs/FUNIT
1. Introduction
人类非常擅长泛化。比方说,当给我们一张从未见过的外来动物的照片时,我们可以在脑海中形成一幅生动的画面,那是同一种动物以不同的姿势出现,尤其是当我们之前遇到过类似但不同的动物以那种姿势出现的时候。例如,一个人第一次看到站立的老虎时,考虑到他一生都在接触其他动物,他会毫不费力地想象出老虎躺着的样子。
虽然最近的无监督图像到图像转换算法在跨图像类别转移复杂的外观变化方面非常成功[30,46,29,25,55,52],但基于先验知识从新类别的少数样本中泛化的能力完全超出了它们的能力。具体来说,它们需要在所有类别的图像上进行大量的训练集来执行翻译,即,它们不支持少镜头泛化。
为了弥合人类和机器想象能力之间的差距,我们提出了少镜头UN监督图像到图像转换(FUNIT)框架,旨在学习图像到图像转换模型,通过利用测试时给定的目标类的少量图像,将源类的图像映射到目标类的类似图像。在训练期间,模型从未显示目标类的图像,但在测试时要求生成其中一些图像。接下来,我们首先假设,人类的少数镜头生成能力是从他们过去的视觉经验发展而来的——如果一个人过去看过更多不同的物体类别,他就能更好地想象出一个新物体的视图。基于假设,我们使用包含许多不同对象类别的图像的数据集来训练我们的FUNIT模型,以模拟过去的视觉体验。具体来说,我们通过利用另一个类的少量示例图像来训练模型将图像从一个类转换到另一个类。
我们的框架基于生成对抗网络(GAN)[14]。我们表明,通过将对抗性训练方案与新颖的网络设计相结合,我们实现了所需的少镜头无监督图像到图像的翻译能力。通过对三个数据集进行广泛的实验验证,包括与使用各种性能指标的几种基线方法进行比较,我们验证了我们提出的框架的有效性。此外,我们表明所提出的框架可以应用于少镜头图像分类任务。通过在我们的模型生成的图像上训练分类器用于少数镜头类,我们能够优于基于特征幻觉的最先进的少数镜头分类方法。
2. Related Work
无监督/未配对图像到图像转换的目的是学习一个条件图像生成函数,该函数可以将源类的输入图像映射到没有对监督的目标类的类似图像。这个问题本质上是不适定的,因为它试图从边际分布中使用样本恢复联合分布[29,30]。为了解决这个问题,现有的作品使用了额外的约束条件。例如,一些工作强制转换以保留源数据的某些属性,例如像素值[41]、像素梯度[5]、语义特征[46]、类标签[5]或成对样本距离[3]。有一些工作强制执行循环一致性约束[52,55,25,1,56]。一些作品使用了共享/部分共享潜在空间假设[29,30]/[19,26]。我们的工作是基于部分共享潜空间假设,但设计用于少镜头无监督图像到图像的翻译任务。
现有的无监督图像到图像翻译模型虽然能够生成真实的翻译输出,但在两个方面存在局限性。首先,它们是样本效率低下的,如果在训练时只给出少量图像,就会产生糟糕的翻译输出。其次,所学习的模型在两个类之间转换图像时受到限制。一个翻译任务的训练模型不能直接用于新任务,尽管新任务与原始任务之间有相似之处。例如,一个哈士奇到猫的翻译模型不能被重新用于哈士奇到老虎的翻译,即使猫和老虎有很大的相似性。
最近,Benaim和Wolf[4]提出了一个无监督的图像到图像转换框架,部分解决了第一个方面。具体来说,他们使用一个由一个源类图像和许多目标类图像组成的训练数据集来训练一个模型,以将单个源类图像转换为目标类的类似图像。我们的工作在几个主要方面不同于他们的工作。首先,我们假设有很多源类图像,但目标类图像很少。此外,我们假设少数目标类图像仅在测试时可用,并且可以来自许多不同的对象类。
多类无监督图像到图像转换[8,2,20]将无监督图像到图像的转换方法扩展到多个类。我们的工作类似于这些方法,因为我们的训练数据集由多个类的图像组成。但我们不是在可见类之间转换图像,而是将可见类的图像转换为以前未见类的类似图像。
Few-shot分类。与很少镜头的图像到图像的翻译不同,使用很少的例子学习新类的分类器是一个长期研究的问题。早期的作品使用生成模型的外观,以分层的方式跨类共享先验[11,39]。最近的研究集中在使用元学习来快速调整模型以适应新的任务[12,35,38,34]。这些方法学习了更好的训练优化策略,因此在只看到少量示例时性能得到了提高。另一组工作专注于学习图像嵌入,更适合于少镜头学习[49,43,44]。最近的一些工作提出通过生成新类对应的新特征向量来扩充少镜头分类任务的训练集[10,15,51]。我们的工作是专为少镜头无监督图像到图像的翻译。但是,如实验部分所示,它可以应用于少枪分类。
3. Few-shot Unsupervised Image Translation
所提议的FUNIT框架旨在通过利用在测试时可用的一些目标类映像,将源类的映像映射到不可见的目标类的类似映像。为了训练FUNIT,我们使用一组对象类中的图像(例如各种动物物种的图像),称为源类。我们不假设存在任何两个类之间的成对图像(即没有两个不同物种的动物处于完全相同的姿势)。
我们使用源类图像来训练一个多类无监督图像到图像的转换模型。在测试过程中,我们为模型提供了一些来自新对象类的图像,称为目标类。该模型必须利用少数目标图像来将任何源类图像转换为目标类的类似图像。当我们从不同的新对象类中提供少数图像给同一个模型时,它必须将任何源类图像转换为不同的新对象类的类似图像。
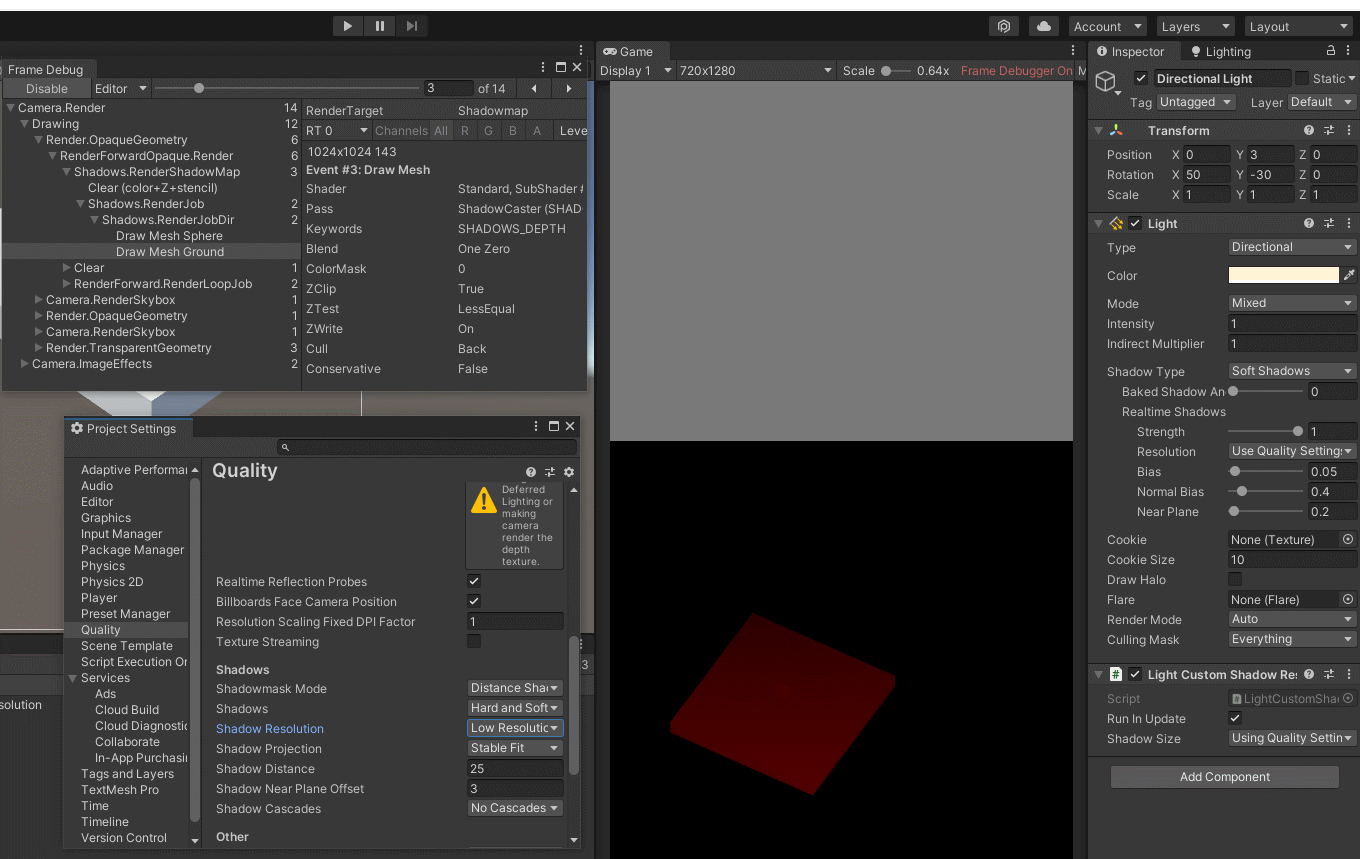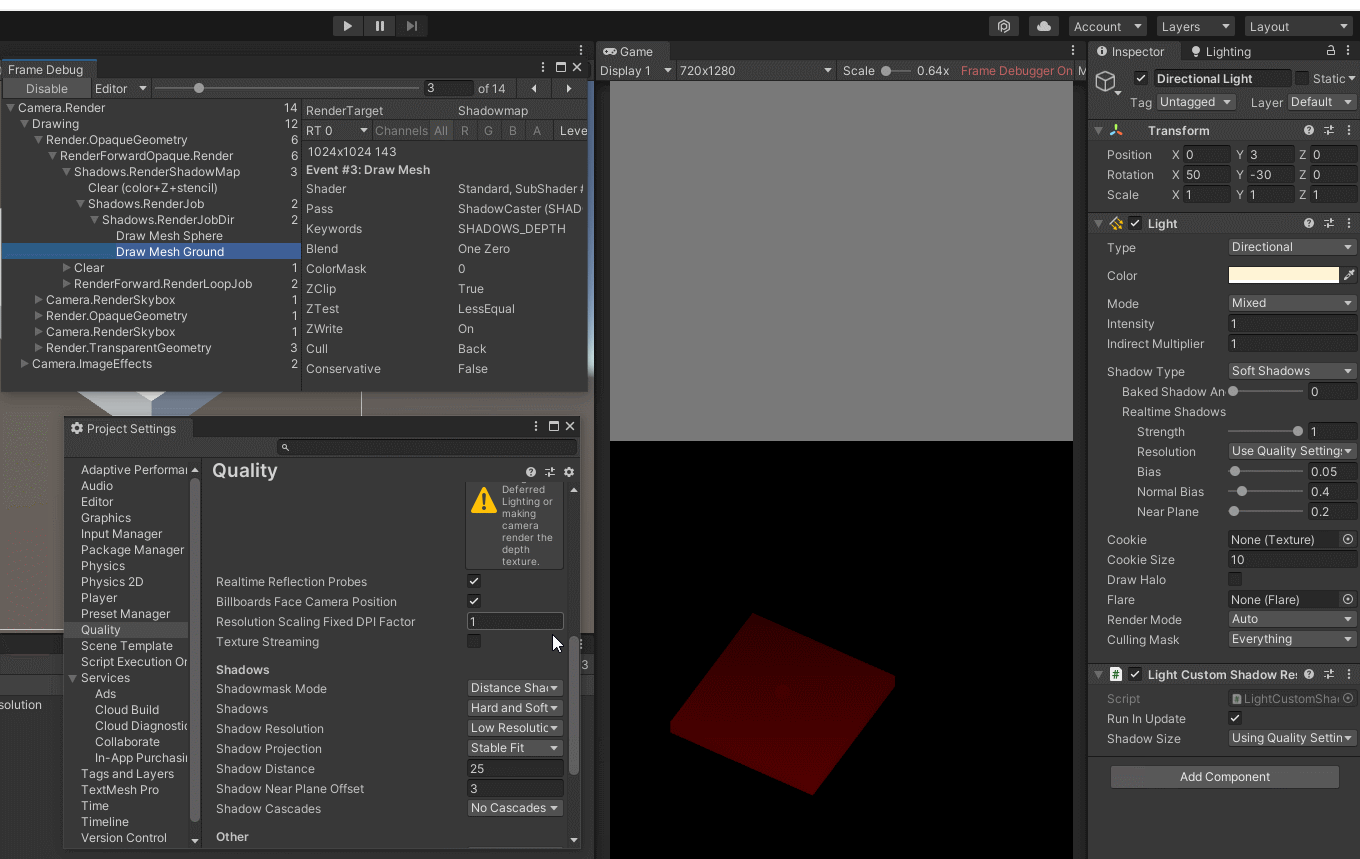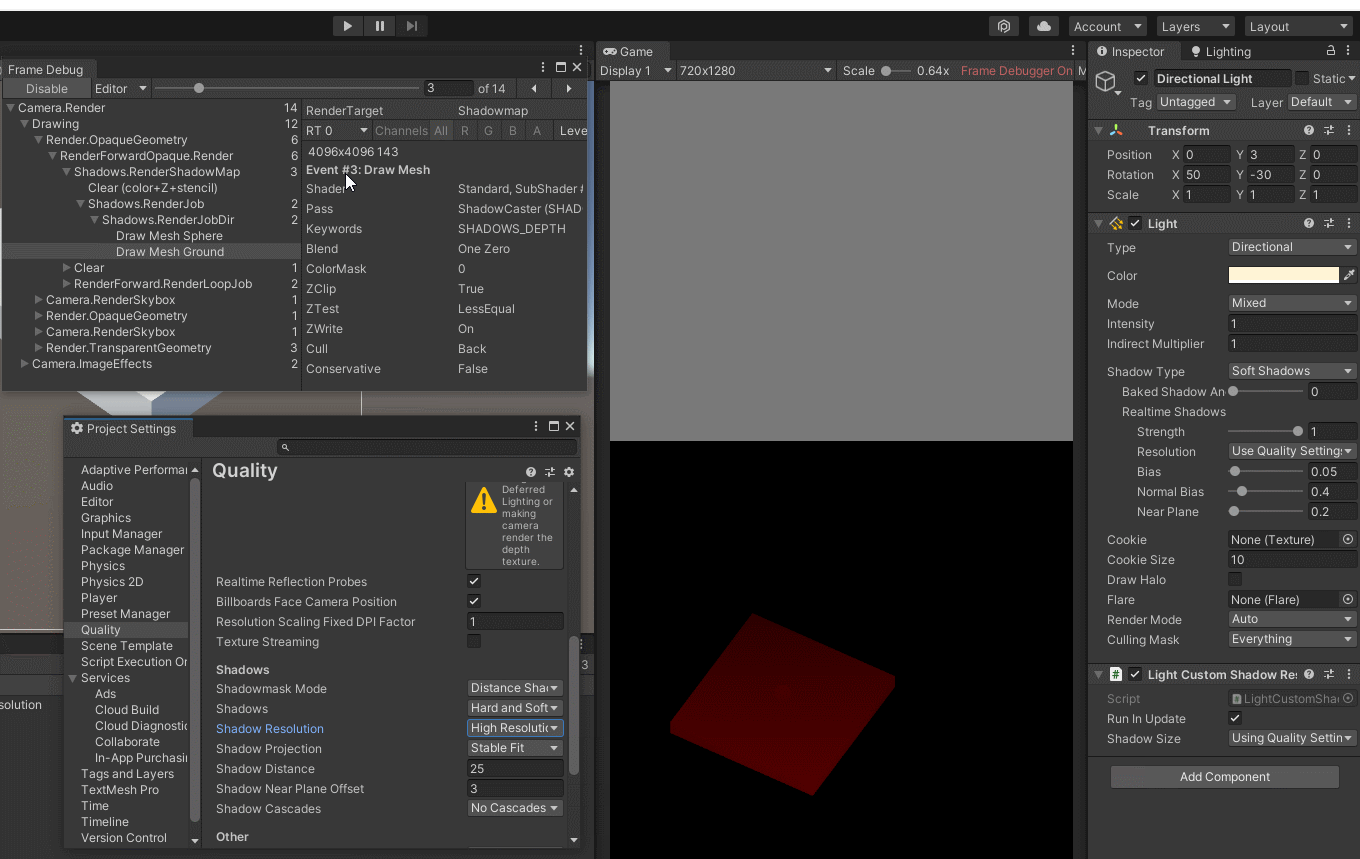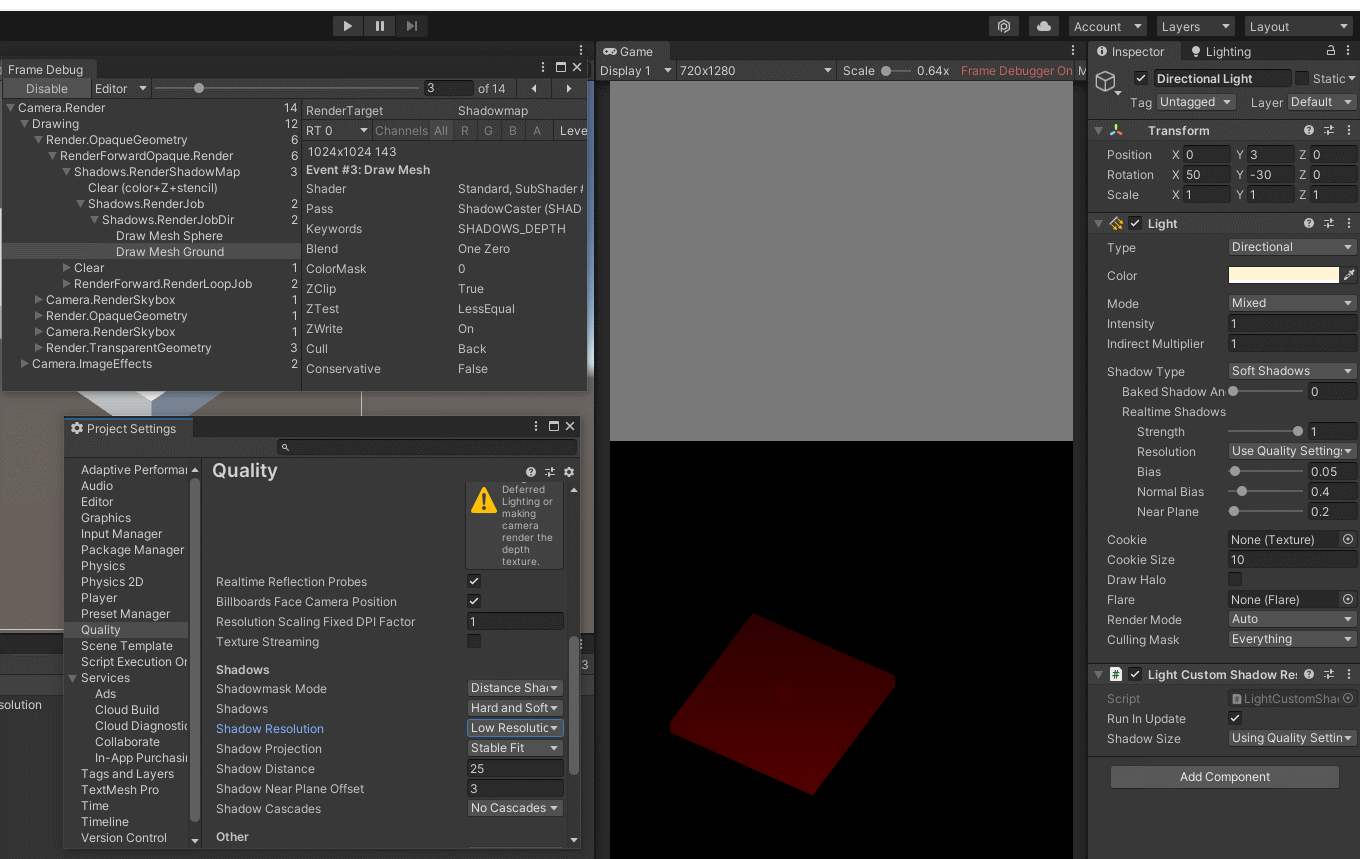
我们的框架由一个条件图像生成器G和一个多任务对抗辨别器d组成,与现有的无监督图像到图像转换框架[55,29]中以一张图像作为输入的条件图像生成器不同,我们的生成器G同时获取一张内容图像x和一组K类图像{y1,…, yK}作为输入,并生成输出图像¯x via
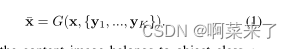
我们假设内容图像属于对象类cx,而K类图像中的每一个都属于对象类cy。
一般来说,K是一个很小的数,cx与cy不同。
我们将G作为少镜头图像转换器。
如图1所示,G将一个输入内容图像x映射到一个输出图像¯x,这样¯x看起来像一个属于对象类cy的图像,并且¯x和x具有结构相似性。设S和T分别表示源类的集合和目标类的集合。在训练过程中,G学习在两个随机采样的源类cx, cy∈S (cx 6= cy)之间转换图像,在测试时,G从一个看不见的目标类c∈T中选取一些图像作为类图像,并将从任意一个源类中采样的图像映射到目标类c的类似图像。
接下来,我们讨论网络设计和学习。详情见附录A。
3.1. Few-shot Image Translator
少镜头图像转换器G由内容编码器Ex、类编码器Ey和解码器Fx组成。内容编码器由几个二维卷积层和几个剩余块组成[16,22]。它将输入内容图像x映射到内容潜在代码zx,这是一个空间特征映射。类编码器由几个二维卷积层组成,然后沿着样本轴进行均值操作。具体来说,它首先映射K个单独的类图像{y1,…, yK}转换为一个中间潜在向量,然后计算中间潜在向量的平均值,得到最终的类潜在代码zy。
该解码器由几个自适应实例归一化(AdaIN)残差块[19]和几个高级卷积层组成。AdaIN残差块是以AdaIN[18]作为归一化层的残差块。对于每个样本,AdaIN首先将每个通道中样本的激活归一化,使其具有零平均值和单位方差。然后,它使用由一组标量和偏差组成的学习仿射变换来缩放激活。注意,仿射变换是空间不变的,因此只能用于获得全局外观信息。通过两层全连通网络,利用zy自适应计算仿射变换参数。Ex Ey和Fx,(1)变成
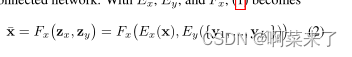
通过使用这种转换器设计,我们的目标是使用内容编码器提取类不变的潜在表示(例如,对象姿态),并使用类编码器提取类特定的潜在表示(例如,对象外观)。
通过通过AdaIN层将类潜在代码提供给解码器,我们让类图像控制全局外观(例如,对象外观),而内容图像决定局部结构(例如,眼睛的位置)。
在训练时,类编码器学习从源类的图像中提取特定于类的潜在表示。在测试时,这可以推广到以前未见过的类的图像。在实验部分,我们展示了泛化能力取决于在训练期间看到的源对象类的数量。当G使用更多的源类(例如,更多的动物物种)训练时,它有更好的少镜头图像翻译性能(例如,更好地翻译husky到mountain lion)。
3.2. Multi-task Adversarial Discriminator
我们的鉴别器D是通过同时解决多个对抗分类任务来训练的。每个任务都是一个二值分类任务,判断输入图像是源类的实像,还是来自g的平移输出。由于源类有|S|, D产生|S|输出。当为源类cx的实图像更新D时,如果D的第x个输出为假,则对D进行惩罚。对于产生源类cx的伪图像的翻译输出,如果D的第x个输出为正,则对D进行惩罚。对于其他类(S{cx})的图像,我们不会因为D没有预测到错误而惩罚D。当更新G时,我们只在D的第x个输出为假时惩罚G。我们通过经验发现,这个鉴别器比通过解决一个更难的|S|类分类问题训练出来的鉴别器工作得更好。
3.3. Learning
我们通过解决所给出的极大极小优化问题来训练所提出的FUNIT框架
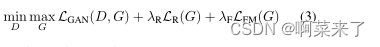
其中LGAN、LR、LF分别为GAN损耗、内容图像重建损耗、特征匹配损耗。GAN损耗是由给出的条件损耗
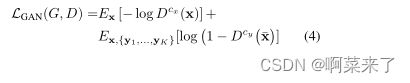
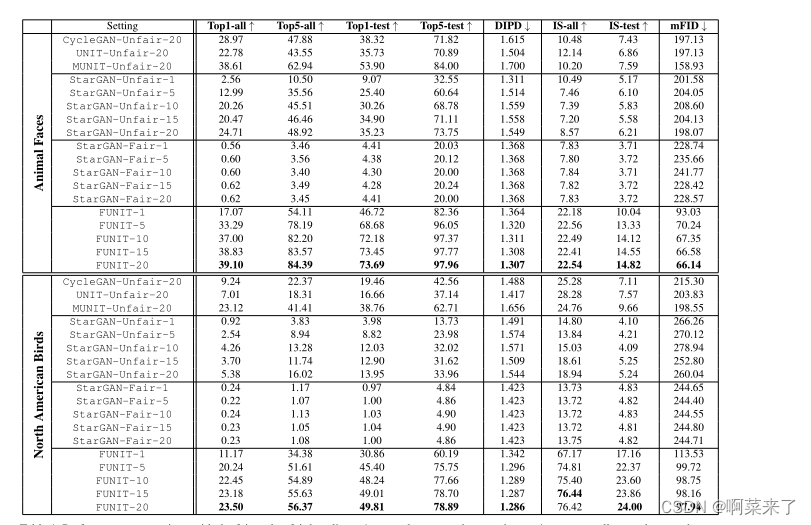
表1。与公平和不公平基准的性能比较。↑表示数字越大越好,↓表示数字越小越好。
附加到D的上标表示对象类;损失仅使用该类对应的二进制预测分数计算。
内容重构损失帮助G学习了一个翻译模型。具体来说,当对输入内容图像和输入类图像使用相同的图像时(在本例中K = 1),损失鼓励G生成与输入相同的输出图像
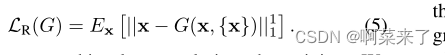
特征匹配损失使训练正则化。我们首先构造一个特征提取器,称为Df,从d中移除最后一个(预测)层。然后使用Df从平移输出¯x和类图像{y1,…, yK}和最小化
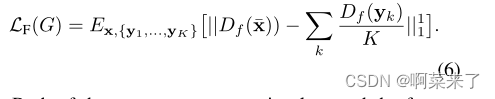
内容重构损失和特征匹配损失都不是图像到图像转换的新课题[29,19,50,37]。我们的贡献是将它们的使用扩展到更具挑战性和新颖的少镜头无监督图像到图像转换设置。

图2。少镜头无监督图像到图像翻译结果的可视化。计算结果采用FUNIT-5模型。从上到下,我们有来自动物脸、鸟、花和食物数据集的结果。我们为每个数据集训练一个模型。
对于每个例子,我们可视化5个随机采样的类图像中的2个y1y2,输入内容图像x和翻译输出¯x。
结果表明,FUNIT在困难的少数镜头设置下生成了合理的翻译输出,在训练期间,模型没有看到任何目标类的图像。我们注意到输出图像中的物体与输入图像具有相似的姿态。

4. Experiments
实现。λR = 0.1, λF = 1。我们使用RMSProp优化(3),学习率为0.0001。我们使用了GAN损失的铰链版本[28,33,53,6]和Mescheder等人提出的实梯度惩罚正则化[32]。最终生成器是中间生成器[23]的历史平均版本,其中更新权重为0.001。我们使用K = 1训练FUNIT模型,因为我们希望它即使在测试时只有一个目标类图像可用时也能很好地工作。在实验中,我们评估了其在K = 1,5,10,15,20时的性能。每个训练批次包含64个内容图像,这些图像均匀分布在NVIDIA DGX1机器的8个V100 gpu上。
数据集。我们使用以下数据集进行实验。
1、动物的脸。我们使用ImageNet[9]中的149种食肉动物类别的图像构建了这个数据集。我们首先在图像中手动标注10000个食肉动物面部的包围框。然后,我们训练一个Faster RCNN[13]来检测图像中的动物面孔。我们只使用检测分数高的边界框。这将呈现一组117574个动物面孔。我们将类分为源类集和目标类集,分别包含119个和30个动物类。
2、鸟[48]。48527张555种北美鸟类的图片。源类集使用444个物种,目标类集使用111个物种。
3、花[36]。来自102个物种的8189张照片。源集和目标集分别有85个和17个物种。
4、食品[24]。来自256种食物的31395张图片。源和目标集分别有224种和32种。
基线。根据目标类的图像在训练期间是否可用,我们定义了两组基线:公平(不可用)和不公平(可用)。
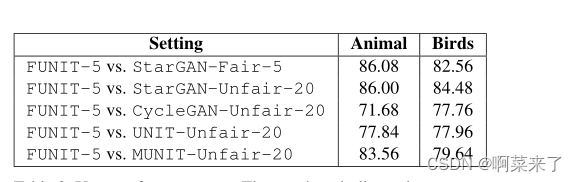
表2。用户偏好评分。这些数字表明,用户倾向于由提议的方法生成的结果而不是由竞争方法生成的结果的百分比。
公平的。这是提议的FUNIT框架的设置。由于之前的无监督图像到图像转换方法都不是为该设置设计的,我们通过扩展StarGAN方法[8]来构建基线,这是多类无监督图像到图像转换的最新技术。我们纯粹使用源类图像训练一个StarGAN模型。在测试过程中,给定目标类的K张图像,我们计算K张图像的平均VGG [42] Conv5特征,并计算其与每个源类图像的平均VGG Conv5特征的余弦距离。然后,我们通过对余弦距离应用softmax来计算类关联向量。我们使用类关联向量作为StarGAN模型的输入(代替单一热点类关联向量输入)来生成看不见的目标类的图像。基线方法的设计假设,类关联得分可以编码一个看不见的目标对象类与每个源类之间的关系,这可以用于少镜头生成。我们将此基线标记为StarGAN-Fair-K。
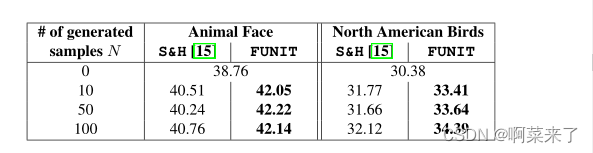
表3。少枪分类精度平均超过5次分割。
不公平的。这些基线包括训练中的目标类图像。我们将每个目标类的可用图像数量(K)从1到20,并训练各种无监督图像到图像的转换模型。我们将每个目标类用K张图像训练的StarGAN模型表示为StarGAN-不公平-K。我们还训练了一些最先进的双域翻译模型,包括CycleGAN [55], UNIT[29]和MUNIT[19]。
对于它们,我们将源类的图像作为第一个域,将一个目标类的图像作为第二个域。这导致每个数据集每个两类基线的|T|无监督图像到图像转换模型。
我们将这些基线标记为cyclegan -Unfair- k、unit -Unfair- k和munit -Unfair- k。
对于基线方法,我们使用源代码和默认参数设置由作者提供。
评估协议。我们从源类中随机抽取25000张图像作为内容图像。然后我们通过随机抽取目标类的K张图像将它们转换到每个目标类。这将为每个竞争方法生成|T|组图像,并用于评估。对于所有竞争的方法,我们对每个内容图像使用相同的K张图像。我们测试一个K值范围,包括1、5、10、15和20。
性能指标。我们使用几个标准进行性能比较。首先,我们衡量翻译是否与目标类的图像相似。其次,我们检查在翻译过程中是否保留了类不变内容。第三,量化输出图像的真实感。
最后,我们衡量模型是否可以用来生成目标类的图像分布。有关性能指标的详细信息见附录B。
翻译精度衡量翻译输出是否属于目标类。我们使用两个InceptionV3[45]分类器。一个分类器使用源类和目标类(记为all)进行训练,而另一个分类器使用目标类along进行训练(记为test)。我们报告Top1和Top5的准确度。
内容保存基于感知距离的变体[22,54],称为域不变感知距离(DIPD)[19]。距离由两个归一化VGG [42] Conv5特征之间的L2距离给出,对域变化[19]更不变性。
照相现实主义。这是通过初始分数(is)[40]来衡量的。我们使用两个训练用于测量翻译准确性的初始分类器报告初始分数,分别用all和test表示。
分布匹配基于Fréchet Inception Distance (FID)[17]。我们计算每个|T|目标对象类的FID,并报告它们的平均FID (mFID)。
主要的结果。如表1所示,在动物面孔和北美鸟类数据集的所有性能指标上,所提出的FUNIT框架优于少数镜头无监督图像到图像转换任务的基线。FUNIT在动物面部数据集上的1-shot和5-shot设置分别达到82.36和96.05 Top-5(测试)精度,在北美鸟类数据集上达到60.19和75.75。这些指标都明显好于相应的公平基准。类似的趋势可以在领域不变感知距离、初始得分和Fréchet初始距离中找到。此外,只有5个镜头,FUNIT在20个镜头设置下胜过所有不公平基线。
请注意,对于cyclegan -Unfair-20,unit -Unfair-20和munit -Unfair-20的结果来自|T|图像到图像的翻译网络,而我们的方法来自单个翻译网络。
从表中还可以看出,所提出的FUNIT模型的性能与测试时可用目标图像K的数量正相关。更大的K会导致所有指标的改进,最大的性能提升来自K = 1到K = 5。StarGAN-Fair基线没有表现出类似的趋势。
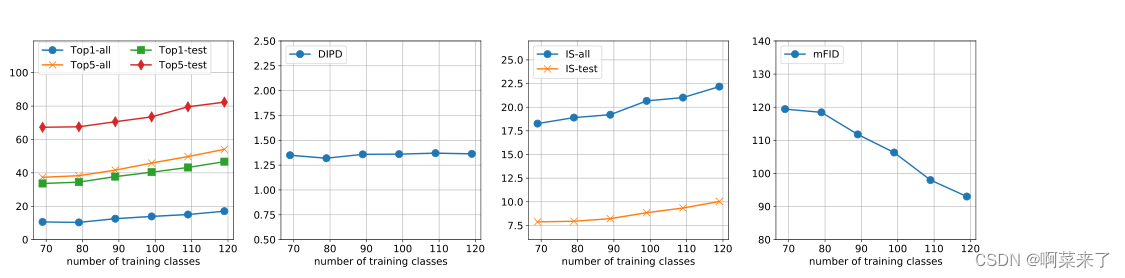
图4。在动物面孔数据集上训练期间看到的少数镜头图像翻译性能与对象类别的数量。性能与训练期间看到的源对象类的数量呈正相关。
在图2中,我们可视化了由FUNIT-5计算的少数镜头翻译结果。结果表明,FUNIT模型可以成功地将源类图像转换为新类的类似图像。在输入内容图像x和相应的输出图像¯x中,对象的姿态基本保持不变。输出的图像是逼真的,类似于目标类的图像。
更多结果见附录I。
在图3中,我们提供了一个可视化的比较。由于基线不是为很少镜头的图像翻译设置而设计的,他们在具有挑战性的翻译任务中失败了。它们要么生成带有大量工件的图像,要么只输出输入内容图像。另一方面,FUNIT生成高质量的图像翻译输出。
用户研究。为了比较翻译输出的真实感和真实性,我们使用亚马逊机械土耳其人(AMT)平台进行人工评估。具体来说,我们给工人一个目标类图像和两个翻译不同方法的输出[50,19],并让他们选择更接近目标类图像的输出图像。工人们有无限的时间来做出选择。我们同时使用了动物面孔和北美鸟类数据集。对于每个比较,我们随机生成500个问题,每个问题由5个不同的员工回答。在质量控制方面,工作人员的终身任务审批率必须大于98%才能参与评估。
根据表2,人类受试者认为在5个镜头设置(FUNIT-5)下提出的方法生成的翻译输出比在相同设置(StarGAN-Fair-5)下由公平基线生成的翻译输出与目标类图像更相似。即使与在训练时每个目标类可以访问20张图像的不公平基线的结果相比,我们的翻译结果仍然被认为更忠实。
训练集中源类的个数。在图4中,我们使用动物数据集分析了一次性设置(FUNIT-1)下训练集中不同数量源类的性能。我们通过将类的数量从69改变到119,以10为间隔来绘制曲线。如图所示,在翻译精度、图像质量和分布匹配方面,性能与对象类的数量呈正相关。
域不变感知距离保持平坦。这表明,在训练期间看到更多对象类(更大的多样性)的FUNIT模型在测试期间表现更好。鸟类数据集也有类似的趋势,见附录C。
参数分析及烧蚀研究。我们分析了目标函数中各个术语的影响,并发现它们都是必不可少的。特别是,内容重构的损失是用翻译精度来换取内容保存分数。详情见附录D。
与AdaIN风格转换方法的比较。我们训练了一个AdaIN风格转换网络[18]来完成少镜头动物面部翻译任务,并将其性能进行了比较,如附录e所示。我们发现,虽然风格转换网络可以改变输入动物的纹理,但它不会改变它们的形状。因此,翻译输出仍然与输入相似。
失败案例。附录f中可视化了该算法的几个失败案例,包括生成混合对象、忽略输入内容图像和忽略输入类图像。
潜在的插值。在附录G中,我们在两个源类图像之间插入类代码时,通过保持内容代码固定来显示插值结果。有趣的是,我们发现通过在两个源类(Siamese cat和Tiger)之间进行插值,我们有时可以生成一个模型从未观察到的目标类(Tabby cat)。
用于少镜头分类的少镜头翻译。我们使用动物和鸟类数据集评估FUNIT的少镜头分类。具体来说,我们使用经过训练的FUNIT模型为每个少数镜头类生成N张(从1,50到100)图像,并使用生成的图像来训练分类器。我们发现,使用FUNIT生成的图像训练的分类器的性能始终优于Hariharan等[15]提出的基于特征幻觉且样本数n为可控变量的S&H少镜头分类方法。结果如表3所示,实验细节见附录H。

图5。所提议的框架的局限性。当一个看不见的对象类的外观与源类的外观显著不同时(例如花和动物的脸)。
5. Discussion and Future Work
我们介绍了第一个少镜头无监督图像到图像的转换框架。我们表明,少数射击生成性能与训练期间看到的对象类别的数量正相关,也与测试期间提供的目标类别射击的数量正相关。
我们提供了经验证据,证明FUNIT可以通过利用测试时可用的少量不可见类的示例图像,学习将源类的图像转换为不可见对象类的对应图像。虽然实现了这个新功能,但FUNIT需要几个条件才能工作:1)内容编码器Ex是否可以学习一个类不变的潜在代码zx, 2)类编码器Ey是否可以学习一个类特定的潜在代码zy,最重要的是,3)类编码器Ey是否可以泛化到不可见对象类的图像。
我们观察到,当新类在视觉上与源类相关时,这些条件很容易满足。
然而,当新对象类的外观与源类的外观显著不同时,FUNIT无法实现转换,如图5所示。
在这种情况下,FUNIT倾向于生成输入内容图像的颜色变化版本。这是不可取的,但可以理解,因为外观分布已经发生了巨大的变化。解决这一限制是我们未来的工作。
References
[1] Amjad Almahairi, Sai Rajeswar, Alessandro Sordoni, Philip
Bachman, and Aaron Courville. Augmented cyclegan:
Learning many-to-many mappings from unpaired data. arXiv
preprint arXiv:1802.10151, 2018.
[2] Asha Anoosheh, Eirikur Agustsson, Radu Timofte, and Luc
V an Gool. Combogan: Unrestrained scalability for image
domain translation. arXiv preprint arXiv:1712.06909, 2017.
[3] Sagie Benaim and Lior Wolf. One-sided unsupervised do-
main mapping. In Advances in Neural Information Process-
ing Systems (NIPS), 2017.
[4] Sagie Benaim and Lior Wolf. One-shot unsupervised cross
domain translation. In Advances in Neural Information Pro-
cessing Systems (NIPS), 2018.
[5] Konstantinos Bousmalis, Nathan Silberman, David Dohan,
Dumitru Erhan, and Dilip Krishnan. Unsupervised pixel-
level domain adaptation with generative adversarial net-
works. In IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), 2017.
[6] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large
scale gan training for high fidelity natural image synthe-
sis. In International Conference on Learning Representa-
tions (ICLR), 2019.
[7] Qifeng Chen and Vladlen Koltun. Photographic image syn-
thesis with cascaded refinement networks. In IEEE Interna-
tional Conference on Computer Vision (ICCV), 2017.
[8] Y unjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha,
Sunghun Kim, and Jaegul Choo. Stargan: Unified genera-
tive adversarial networks for multi-domain image-to-image
translation. In IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), 2018.
[9] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei.
ImageNet: A Large-Scale Hierarchical Image Database. In
IEEE Conference on Computer Vision and Pattern Recogni-
tion (CVPR), 2009.
[10] Mandar Dixit, Roland Kwitt, Marc Niethammer, and Nuno
V asconcelos. Aga: Attribute-guided augmentation. In IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), 2017.
[11] Li Fei-Fei, Rob Fergus, and Pietro Perona. One-shot learning
of object categories. IEEE Transactions on Pattern Analysis
and Machine Intelligence (TPAMI), 2006.
[12] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-
agnostic meta-learning for fast adaptation of deep networks.
In International Conference on Machine Learning (ICML),
2017.
[13] Ross Girshick. Fast r-cnn. In Advances in Neural Informa-
tion Processing Systems (NIPS), 2015.
[14] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing
Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and
Y oshua Bengio. Generative adversarial nets. In Advances in
Neural Information Processing Systems (NIPS), 2014.
[15] Bharath Hariharan and Ross B Girshick. Low-shot visual
recognition by shrinking and hallucinating features. In IEEE
International Conference on Computer Vision (ICCV), 2017.
[16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Deep residual learning for image recognition. In IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), 2016.
[17] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner,
Bernhard Nessler, and Sepp Hochreiter. GANs trained by a
two time-scale update rule converge to a local Nash equilib-
rium. In Advances in Neural Information Processing Systems
(NIPS), 2017.
[18] Xun Huang and Serge Belongie. Arbitrary style transfer in
real-time with adaptive instance normalization. In IEEE In-
ternational Conference on Computer Vision (ICCV), 2017.
[19] Xun Huang, Ming-Y u Liu, Serge Belongie, and Jan Kautz.
Multimodal unsupervised image-to-image translation. Euro-
pean Conference on Computer Vision (ECCV), 2018.
[20] Le Hui, Xiang Li, Jiaxin Chen, Hongliang He, and
Jian Yang. Unsupervised multi-domain image translation
with domain-specific encoders/decoders. arXiv preprint
arXiv:1712.02050, 2017.
[21] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A
Efros. Image-to-image translation with conditional adver-
sarial networks. In IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), 2017.
[22] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual
losses for real-time style transfer and super-resolution. In
European Conference on Computer Vision (ECCV), 2016.
[23] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen.
Progressive growing of gans for improved quality, stability,
and variation. In International Conference on Learning Rep-
resentations (ICLR), 2018.
[24] Y oshiyuki Kawano and Keiji Yanai. Automatic expansion
of a food image dataset leveraging existing categories with
domain adaptation. In European Conference on Computer
Vision (ECCV) Workshop, 2014.
[25] Taeksoo Kim, Moonsu Cha, Hyunsoo Kim, Jungkwon Lee,
and Jiwon Kim. Learning to discover cross-domain relations
with generative adversarial networks. In International Con-
ference on Machine Learning (ICML), 2017.
[26] Hsin-Ying Lee, Hung-Y u Tseng, Jia-Bin Huang, Ma-
neesh Kumar Singh, and Ming-Hsuan Yang. Diverse image-
to-image translation via disentangled representation. In Eu-
ropean Conference on Computer Vision (ECCV), 2018.
[27] Yanghao Li, Naiyan Wang, Jianping Shi, Jiaying Liu, and
Xiaodi Hou. Revisiting batch normalization for practical do-
main adaptation. arXiv preprint arXiv:1603.04779, 2016.
[28] Jae Hyun Lim and Jong Chul Ye. Geometric gan. arXiv
preprint arXiv:1705.02894, 2017.
[29] Ming-Y u Liu, Thomas Breuel, and Jan Kautz. Unsupervised
image-to-image translation networks. In Advances in Neural
Information Processing Systems (NIPS), 2017.
[30] Ming-Y u Liu and Oncel Tuzel. Coupled generative adversar-
ial networks. In Advances in Neural Information Processing
Systems (NIPS), 2016.
[31] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang.
Deep learning face attributes in the wild. In IEEE Interna-
tional Conference on Computer Vision (ICCV), 2015.
[32] Lars Mescheder, Andreas Geiger, and Sebastian Nowozin.
Which training methods for gans do actually converge?
In International Conference on Machine Learning (ICML),
2018.
[33] Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and
Y uichi Y oshida. Spectral normalization for generative ad-
versarial networks. In International Conference on Learning
Representations (ICLR), 2018.
[34] Tsendsuren Munkhdalai and Hong Y u. Meta networks. In In-
ternational Conference on Machine Learning (ICML), 2017.
[35] Alex Nichol, Joshua Achiam, and John Schulman. On
first-order meta-learning algorithms. arXiv preprint
arXiv:1803.02999, 2018.
[36] Maria-Elena Nilsback and Andrew Zisserman. Automated
flower classification over a large number of classes. In Indian
Conference on Computer Vision, Graphics & Image Process-
ing, 2008.
[37] Taesung Park, Ming-Y u Liu, Ting-Chun Wang, and Jun-Yan
Zhu. Semantic image synthesis with spatially adaptive nor-
malization. In IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), 2019.
[38] Sachin Ravi and Hugo Larochelle. Optimization as a model
for few-shot learning. In International Conference on Learn-
ing Representations (ICLR), 2017.
[39] Ruslan Salakhutdinov, Joshua Tenenbaum, and Antonio Tor-
ralba. One-shot learning with a hierarchical nonparametric
bayesian model. In International Conference on Machine
Learning (ICML) Workshop, 2012.
[40] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki
Cheung, Alec Radford, and Xi Chen. Improved techniques
for training gans. In Advances in Neural Information Pro-
cessing Systems (NIPS), 2016.
[41] Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Josh
Susskind, Wenda Wang, and Russ Webb. Learning from sim-
ulated and unsupervised images through adversarial training.
In IEEE Conference on Computer Vision and Pattern Recog-
nition (CVPR), 2017.
[42] Karen Simonyan and Andrew Zisserman. V ery deep con-
volutional networks for large-scale image recognition. In In-
ternational Conference on Learning Representations (ICLR),
2015.
[43] Jake Snell, Kevin Swersky, and Richard Zemel. Prototypi-
cal networks for few-shot learning. In Advances in Neural
Information Processing Systems (NIPS), 2017.
[44] Flood Sung, Y ongxin Yang, Li Zhang, Tao Xiang, Philip HS
Torr, and Timothy M Hospedales. Learning to compare: Re-
lation network for few-shot learning. In IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), 2018.
[45] Christian Szegedy, Vincent V anhoucke, Sergey Ioffe, Jon
Shlens, and Zbigniew Wojna. Rethinking the inception ar-
chitecture for computer vision. In IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR), 2016.
[46] Yaniv Taigman, Adam Polyak, and Lior Wolf. Unsupervised
cross-domain image generation. In International Conference
on Learning Representations (ICLR), 2017.
[47] Dmitry Ulyanov, Andrea V edaldi, and Victor Lempitsky. Im-
proved texture networks: Maximizing quality and diversity
in feed-forward stylization and texture synthesis. In IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), 2017.
[48] Grant V an Horn, Steve Branson, Ryan Farrell, Scott Haber,
Jessie Barry, Panos Ipeirotis, Pietro Perona, and Serge Be-
longie. Building a bird recognition app and large scale
dataset with citizen scientists: The fine print in fine-grained
dataset collection. In IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), 2015.
[49] Oriol Vinyals, Charles Blundell, Tim Lillicrap, Daan Wier-
stra, et al. Matching networks for one shot learning. In
Advances in Neural Information Processing Systems (NIPS),
2016.
[50] Ting-Chun Wang, Ming-Y u Liu, Jun-Yan Zhu, Andrew Tao,
Jan Kautz, and Bryan Catanzaro. High-resolution image syn-
thesis and semantic manipulation with conditional gans. In
IEEE Conference on Computer Vision and Pattern Recogni-
tion (CVPR), 2018.
[51] Y u-Xiong Wang, Ross Girshick, Martial Hebert, and Bharath
Hariharan. Low-shot learning from imaginary data. In IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), 2018.
[52] Zili Yi, Hao Zhang, Ping Tan, and Minglun Gong. Dual-
gan: Unsupervised dual learning for image-to-image transla-
tion. In IEEE International Conference on Computer Vision
(ICCV), 2017.
[53] Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augus-
tus Odena. Self-attention generative adversarial networks.
arXiv preprint arXiv:1805.08318, 2018.
[54] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht-
man, and Oliver Wang. The unreasonable effectiveness of
deep features as a perceptual metric. In IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), 2018.
[55] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A
Efros. Unpaired image-to-image translation using cycle-
consistent adversarial networks. In IEEE International Con-
ference on Computer Vision (ICCV), 2017.
[56] Jun-Yan Zhu, Richard Zhang, Deepak Pathak, Trevor Dar-
rell, Alexei A Efros, Oliver Wang, and Eli Shechtman. To-
ward multimodal image-to-image translation. In Advances
in Neural Information Processing Systems (NIPS), 2017.
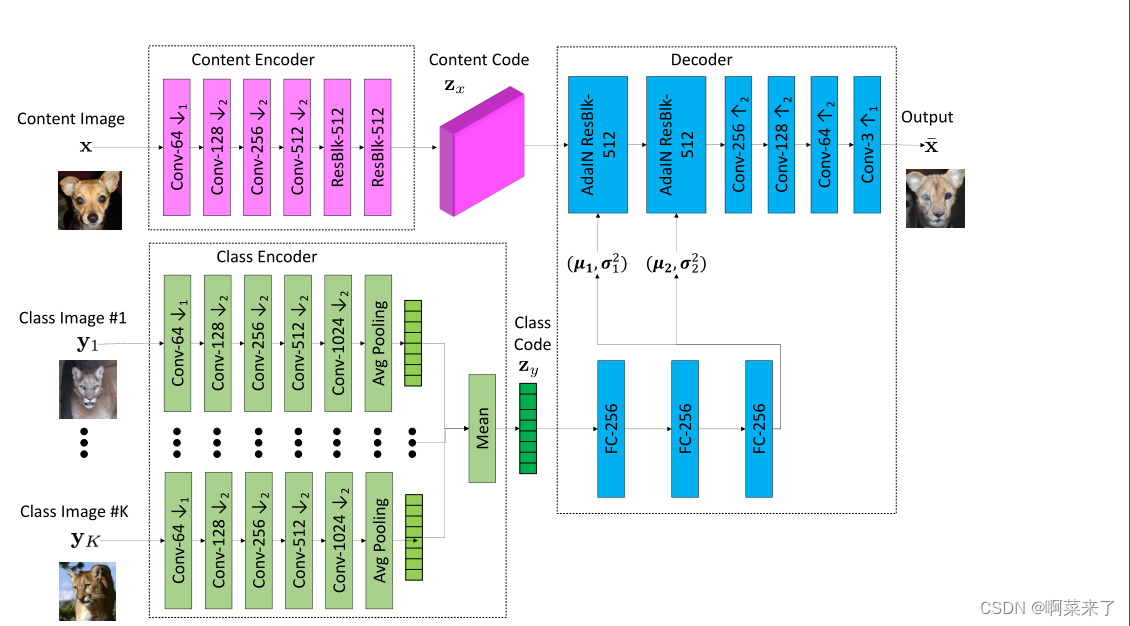
图6。生成器体系结构的可视化。为了生成一个¯xxx的翻译输出,翻译器结合从类图像yyy1,…中提取的类潜在代码zzzy,…yyyK用内容潜码zzzx从输入内容图像中提取。注意,非线性和归一化操作不包括在可视化中。
A. Network Architecture
少镜头图像转换器由三个子网络组成:内容编码器、类编码器和解码器,如图6所示。内容编码器将输入内容图像映射到内容潜在代码,这是一个特征映射。如果输入图像的分辨率为128x128,则特征图的分辨率将为16x16,因为有3个stride-2向下采样操作。此特征映射被设计用于编码类不变内容信息。
它应该编码部件的位置,而不是它们特定于类的外观1。另一方面,类编码器将一组K类图像映射到一个类潜在代码,这是一个向量,目的是特定于类。它首先将每个输入类图像映射到使用的中间潜在代码类似于vgg的网络。这些潜在向量然后按元素平均,以产生最终的类潜在代码。
如图所示,解码器首先将特定于类别的潜在代码解码为一组均值和方差向量(µµµi, σσσ2i),其中i = 1,2。然后将这些向量用作AdaIN残差块中的仿射变换参数,其中σσσ2i ’ s为标度因子,µµµi ’ s为偏差。对于每个残差块,同样的仿射变换应用于特征图中的每个空间位置。它控制如何解码内容潜在代码以生成输出图像。
图6中每个块中显示的数字表示该层中过滤器的数量。在可视化中排除了网络中包含的非线性和归一化操作。对于内容编码器,每一层后面都是实例归一化和ReLU非线性。对于类编码器,每一层后面都是ReLU非线性。对于解码器,除AdaIN残差块外,每一层后面都是实例归一化和ReLU非线性。我们使用最近邻上采样,沿每个空间维度将特征图放大2倍。
我们的鉴别器是Patch GAN鉴别器[21]。该方法利用了Leaky ReLU非线性,并且没有进行任何恶意化处理。鉴别器由一个卷积层和10个激活前残差块[32]组成。
该体系结构通过以下操作链进行说明:
Conv-64 → ResBlk-128 → ResBlk-128 → AvePool2x2 → ResBlk-256 → ResBlk-256 → AvePool2x2 → ResBlk-512 → ResBlk-512 → AvePool2x2 → ResBlk-1024 → ResBlk-1024 → AvePool2x2 → ResBlk-1024 → ResBlk-1024 → Conv-||S||其中||S||是源类的个数。
B. Performance Metrics
翻译的准确性。我们使用两个Inception-V3[45]分类器来测量翻译精度。第一个分类器,记为all,是通过对imagenet预训练的Inception-V3模型进行微调,以分类所有源对象和目标对象类(例如,动物面孔数据集的所有149个类和北美鸟类数据集的所有555个类)来获得的。第二个分类器(记为test)是通过在分类目标对象类(例如30个目标类)的任务上对imagenet预训练的Inception-V3模型进行微调来获得的动物面孔数据集和北美鸟类数据集的111个目标类别)。我们将分类器应用于翻译输出,以查看它们是否可以将输出识别为目标类的图像。如果是,我们将其标记为正确的翻译。我们使用Top1和Top5的准确度来比较竞争模型的性能。因此,我们有4个评估翻译准确性的指标:Top1all, Top5-all, Top1-test和Top5-test。无监督图像到图像的平移模型具有较高的精度。我们注意到,相似的评估协议被用于比较语义标签映射上的图像到图像翻译模型与图像翻译任务[21,50,7]。
保存的内容。我们使用域不变感知距离(DIPD)[19]来量化内容保存性能。DIPD是知觉距离的变体[22,54]。为了计算DIPD,我们首先从输入内容图像和输出平移图像中提取VGG [42] conv5特征。然后我们将实例归一化[47]应用于特征,这将删除它们的均值和方差。这样,我们可以过滤掉特征中大量特定于类的信息[18,27],并专注于类不变的相似性。DIPD由实例归一化特征之间的L2距离给出。
照相现实主义。我们使用初始评分(IS)[40],它被广泛用于量化图像生成性能。设p(t|y)为初始模型的类标签t在输出平移图像y上的分布。初始得分由
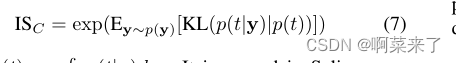
其中p(t) = R y p(t|y)dy。Salimans et al[40]认为,inception评分与神经网络生成图像的视觉质量呈正相关。
分布匹配。Frechet Inception Distance FID[17]用于测量两组图像之间的相似性。我们使用imagenet预训练的Inception-V3[45]模型的最后一个平均池化层的激活作为图像的特征向量,用于计算FID。
由于我们有|T|看不见的类,我们将源图像转换为每个|T|看不见的类,并产生|T|组翻译输出。对于每个|T|集的翻译输出,我们计算该集与对应的地面真实图像集之间的FID。这将呈现|T| FID分数。|T| FID分数的平均值被用作我们的最终分布匹配性能指标,称为平均FID (mFID)。
C. Effect on Number of Source Classes
在主要论文中,我们证明了动物面部翻译任务的少镜头翻译性能与训练集中源类的数量正相关。在图7中,我们展示了鸟类翻译任务的相同情况。具体来说,我们使用北美鸟类数据集报告所提议模型的性能与训练集中可用源类的数量。我们将源类的数量从189、222、289、333、389变化到444,并绘制性能分数。
我们发现分数的曲线遵循与主论文中显示的动物面孔数据集相同的趋势。当模型在训练期间看到大量的源类时,它在测试期间表现得更好。
D. Ablation Study
在表4中,我们分析了内容图像重建失重对Animal Faces数据集的影响。
我们发现,λR值越大,域不变感知距离越小,但翻译精度越低。从表中可以看出,λR = 0.1是一个很好的权衡,我们在整个论文中都将其作为默认值。有趣的是,非常小的权重值λR = 0.01会导致内容保存和翻译准确性的性能下降。这说明内容重构损失有助于训练的正则化。
表5给出了一项消融研究的结果,该研究分析了所提算法中损失项对动物面孔数据集的影响。我们发现,删除特征匹配损失项会导致性能略有下降。但是当去掉以零为中心的梯度惩罚后,内容的保存和翻译精度都大大降低。
在图8中,我们绘制了所提出的模型在一次射击设置(FUNIT-1)上的训练迭代的性能。
一般来说,随着迭代次数的增加,翻译精度、内容保存、图像质量和分布匹配得分都会提高。这种改进在早期阶段更为显著,并在大约10000次迭代时减慢速度。因此,我们使用10000次迭代作为整个论文报告实验结果的默认参数。
E. Comparison with AdaIN Style Transfer
在图9中,我们将所提出的方法与AdaIN风格传输方法[18]进行了比较,用于少数镜头动物面部翻译任务。虽然AdaIN样式转移方法可以改变输入动物的纹理,但它不会改变它们的形状。因此,翻译输出在外观上仍然与输入相似。
F. Failure Case
图10给出了该算法的几个失败案例。它们包括生成混合类、忽略输入内容图像和忽略输入类图像
图7。在北美鸟类数据集上训练期间看到的少数镜头图像转换性能与对象类别的数量。

表4。内容图像重建失重参数敏感性分析,λR。↑表示数字越大越好,↓表示数字越小越好。0.1值在内容保存和翻译准确性之间提供了一个很好的平衡,在整个论文中都使用它作为默认值。本实验采用FUNIT-1模型。

表5所示。对象术语的消融研究。↑表示数字越大越好,↓表示数字越小越好。FM表示去除特征匹配损失项后的框架设置,GP表示不含梯度惩罚损失的框架设置。默认设置在大多数情况下在各种标准上呈现更好的性能。本实验采用FUNIT-1模型。

图8。少镜头图像翻译性能与训练迭代。上一行:Animal Faces数据集的结果;下一行:北美鸟类数据集的结果。
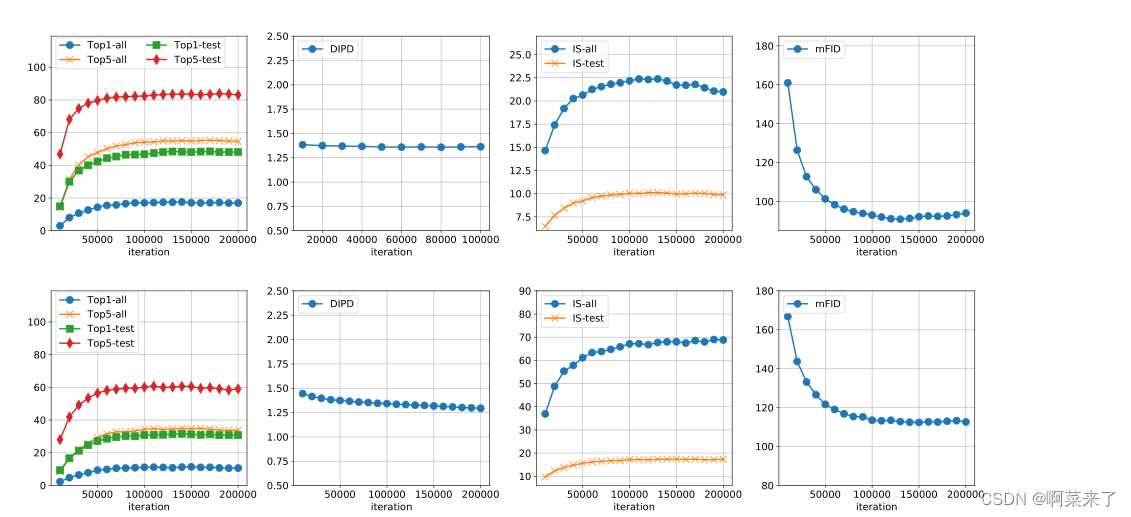
表6所示。使用生成的图像和1张真实图像时,对动物面部数据集的5个分割的一次拍摄精度。每次分割报告超过5次独立运行的平均精度(每次对生成的图像进行不同的采样)。
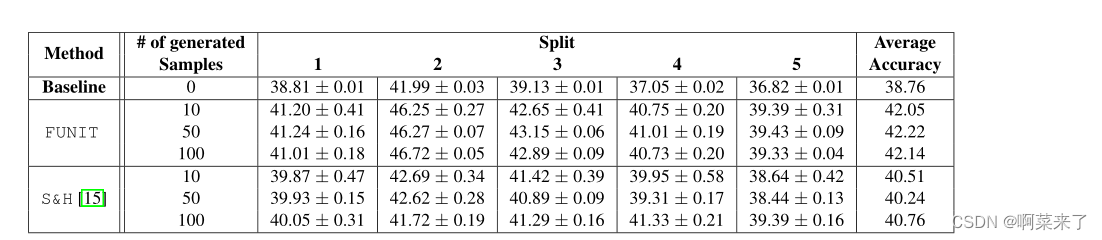
表7所示。在使用生成图像和1个真实图像时,北美鸟类数据集的5个分割上的一次拍摄精度。每次分割报告超过5次独立运行的平均精度(每次对生成的图像进行不同的采样)。

图9。FUNIT-1与AdaIN风格转换[18]用于少镜头图像转换。

表8所示。使用原型网络方法[39]生成的图像,在动物面孔和北美鸟类数据集上的1个镜头精度,平均超过5个分割。
G. Latent Space Interpolation
我们探索类编码器学习的潜在空间。
在图11中,我们使用t-SNE在二维空间中可视化类代码。从图中可以看出相似的类在类嵌入空间中被分组在一起。
图12显示了在两个源类图像之间插入类代码时保持内容代码固定的插值结果。有趣的是,我们发现通过在两个源类(Siamese cat和Tiger)之间进行插值,我们有时可以生成一个模型从未观察到的目标类(Tabby cat)。这表明类编码器学习了一般的特定于类的表示,从而能够泛化到新类。
H. Few-Shot Classification
正如在主论文中提到的,我们使用FUNIT生成器生成的图像进行了一个实验使用动物面孔和北美鸟类数据集,在一次性设置中训练新类别的分类器。按照Hariharan et al[15]中的设置,我们创建了5个不同的一次性训练分割,每个分割都有一个训练集、验证集和测试集。训练集由|T|图像组成,每个|T|测试类一个图像。验证集由来自每个测试类的20-100个图像组成。测试集由剩余的测试类映像组成。
我们使用FUNIT生成器生成一个合成训练集,将分类训练集中的图像作为类图像输入,从源类中随机采样的图像作为内容图像输入。我们使用原始训练集和合成训练集训练一个分类器。我们将我们的方法与Hariharan等人[15]的收缩和幻觉(S&H)方法进行比较,后者学习生成与新类对应的最终层特征。我们使用预训练的10层ResNet网络作为特征提取器,该网络仅使用源类图像进行预训练,并在目标类上训练线性分类器。我们发现,将生成图像上的损失加权为低于真实图像上的损失是至关重要的。我们使用验证集对权重值和权重衰减值进行详尽的网格搜索,并报告测试集上的性能。为了进行公平的比较,我们还对S&H方法执行了相同的穷举搜索。
在主论文的表3中,我们报告了在两个具有挑战性的细粒度分类任务中,我们的方法和S&H方法[15]在不同数量的生成样本(即FUNIT的图像和S&H的特征)上的性能。这两种方法都比只使用每个新类提供的单个真实图像的基线分类器性能更好。使用我们生成的图像,我们比生成特征的S&H方法获得了大约2%的改进。
基础10层ResNet网络训练90个epoch,初始学习率为0.1,每30个epoch衰减10倍。线性分类器在新类上的权重衰减是从介于0.000001和0.1之间并包括0.000001和0.1之间的15个对数间隔值中选择。生成的图像和特征上的损失的损失乘数从7个对数间隔的值中选择,这些值介于0.001和1之间。重量衰减和损失乘数的值是根据在Split #1上训练时获得的最佳验证集精度选择的。然后这些值被固定,并用于所有剩余的2-5段。使用固定特征学习L2正则化分类器的任务是一个凸优化问题,我们使用L-BFGS算法进行行搜索,因此不必指定学习率。
在表6和表7中,我们报告了动物面孔和北美鸟类数据集的所有5个一次性分割的一次性学习的测试准确性及其相关方差。在所有实验中,我们只使用从用于训练图像生成器的类集上训练的网络中提取的特征来学习一个新的分类器层。
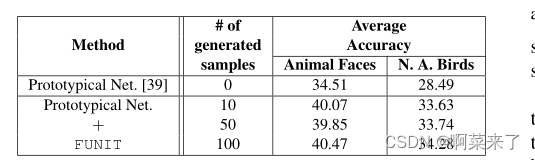
我们的方法也可以与现有的少镜头分类方法结合使用。在表8中,我们展示了使用原型网络方法[43]获得的1次分类结果,该方法将从给定的少数火车样本中获得的最接近的原型(聚类中心)的标签分配给测试样本。显然,在测试时使用我们生成的样本和每个类提供的1个样本来计算类原型表示,有助于将两个数据集的准确性提高5.5%以上。
图10。失败案例。提出的FUNIT模型的典型失败案例包括生成混合对象(例如列1、2、3和4),忽略输入内容图像(例如列5和6),以及忽略输入类图像(例如列7)。


图11。类代码的二维表示,使用t-SNE对50个源类中的5000张图像进行表示。详情请放大。
I. More Translation Results
在图13、14、15和16中,我们展示了动物面部图像翻译任务、鸟类图像翻译任务、花卉图像翻译任务、食物图像翻译任务和面部图像翻译任务的额外少量翻译结果。对于人脸转换,每个类都由一个人标识定义。本实验使用名人人脸数据集[31]进行。所有结果都是使用FUNIT-5计算的。
图12。在源类的两个类代码之间进行插值时,通过保持内容代码固定来进行插值。

J. FUNIT-All
为了评估所提出的方法在标准图像到图像转换设置(在训练时间内目标类别图像可用)下的性能,我们使用动物面部数据集中的所有训练图像训练了一个FUNIT模型。由此产生的模型被称为funit -不公平-所有。在此设置中,测试时间中没有看不见的类。如表9所示,我们的funit - fair- all优于目前最先进的图像到图像转换模型,包括CycleGAN [55], UNIT [29], MUNIT[19]和StarGAN[8]。
(对于只能处理两个域之间转换的模型。我们训练了许多人进行评估。)这表明所提出的FUNIT模型也是一个具有竞争力的多类图像到图像转换模型。
图13。少镜头动物面部图像翻译任务的额外可视化结果。所有结果都是使用相同的FUNIT-5模型计算的。通过访问目标类中的5个图像,可以在测试时间重新使用该模型来生成动态指定的目标类的图像。变量xxx是输入内容图像,yyy1和yyy1是5个输入目标类图像中的2个,¯xxx是翻译输出。我们发现翻译输出中的动物面部与输入内容图像具有相似的姿态,但外观与类图像中的动物面部外观相似。

图14。额外的可视化结果的少数射击鸟图像翻译任务。所有结果都是使用相同的FUNIT-5模型计算的。通过访问目标类中的5个图像,可以在测试时间重新使用该模型来生成动态指定的目标类的图像。变量xxx是输入内容图像,yyy1和yyy1是5个输入目标类图像中的2个,¯xxx是翻译输出。我们发现翻译输出中的鸟的姿态与输入内容图像相似,但外观与类图像中的鸟的外观相似。

图15。额外的可视化结果的少数镜头的花和食物图像翻译任务。相同任务的所有结果都使用相同的FUNIT-5模型计算。通过访问目标类中的5个图像,可以在测试时间重新使用该模型来生成动态指定的目标类的图像。变量xxx是输入内容图像,yyy1和yyy1是5个输入目标类图像中的2个,¯xxx是翻译输出。对于花朵的翻译,我们发现输出图像和输入图像中的花朵具有相似的姿态。对于食物转换,碗和盘子保持在相同的位置,而食物从一种变成另一种。

图16。少镜头人脸图像转换任务的可视化结果。所有结果都是使用相同的FUNIT-5模型计算的。

通过访问目标类中的5个图像,可以在测试时间重新使用该模型来生成动态指定的目标类的图像。变量xxx是输入内容图像,yyy1和yyy1是5个输入目标类图像中的2个,¯xxx是翻译输出。我们发现翻译输出中的人脸具有与输入内容图像相似的姿态,但外观与目标人的面部外观相似。