排序算法是《数据结构与算法》中最基本的算法之一,排序算法可以分为内部和外部排序。
-
内部排序:数据记录在内存中进行排序。
-
外部排序:因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
常见排序算法:插入排序、希尔排序、选择排序、冒泡排序、快速排序、堆排序、基数排序等。
说明:由于对对象元素进行排序需要实现Comparable接口,这里为了实现简单,方便测试,仅对整数进行排序(即排序的对象为整型数组)。
一、插入排序
排序思想:把待排序的元素按其值的大小逐个插入到一个已经排好序的序列中,直到所有的元素插入完为止。
排序过程:
1.1、直接插入排序
其代码如下:
//核心代码
public void sort(int[] data) {
int size = data.length;
for (int i = 1; i < size; i++) {
for (int j = i; j >= 1 && data[j] < data[j-1]; j--) {
swap(data, j, j-1);
}
}
}
//交换两个元素
public void swap(int[] data,int i,int j) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
在内循环中将较大的元素一次性向右移动而不是交换两个元素,这样访问数组的次数将减半 。其代码如下:
public void sort(int[] data) {
int size = data.length;
for (int i = 1; i < size; i++) {
int temp = data[i];
int index = 0; //要插入的位置
for (int j = i; j >= 1; j--) {
if (temp < data[j-1]) {
data[j] = data[j-1];
}else {
index = j;
break;
}
}
data[index] = temp;
}
}
1.2、二分插入排序
将直接插入排序中寻找a[i]插入位置的方法改为二分查找,然后再一次性向右移动元素。
public void sort(int[] data) {
int size = data.length;
for (int i = 1; i < size; i++) {
int num = binaryFind(data, data[i], 0, i-1);
int temp = data[i];
//num后的元素向后移动
for (int j = i; j > num; j--) {
data[j] = data[j-1];
}
data[num] = temp;
}
}
//找出元素应在数组中插入的位置
public int binaryFind(int[] data, int temp, int down, int up) {
if(up<down || up>data.length || down<0) {
System.out.println("下标错误");
}
if(temp < data[down]) return down;
if(temp > data[up]) return up+1;
int mid = (up-down)/2 + down;
if(temp == data[mid]) {
return mid + 1;
}else if(temp < data[mid]) {
up = mid-1;
}else if(temp > data[mid]) {
down = mid+1;
}
return binaryFind(data,temp, down, up);
}
二分插入排序减少了比较次数,特别是当要排序的数据很大时,这个效果将更加明显。
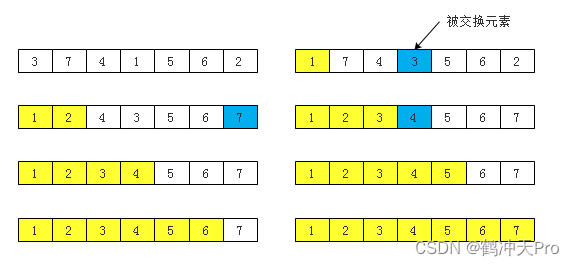
二、选择排序
排序思想:每一次从待排序的数据元素中找出最小(或最大)的一个元素,将它和待排序的元素中第一个位置的元素进行交换,直到全部待排序的数据元素排完程为止。
排序过程:
代码:
public void sort(int[] data) {
int size = data.length;
for(int i=0;i<size;i++) {
int min = i;
for(int j=i+1;j<size;j++) {
if(data[j] < data[min])
min=j;
}
swap(data,i,min);
}
}
//交换两个元素
public void swap(int[] data,int i,int j) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
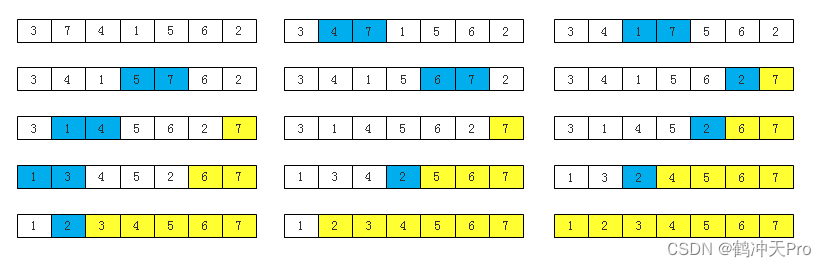
三、冒泡排序
排序思想:依次比较相邻的两个元素,若它们的顺序错误则交换,每次循环都将最大(或最小)元素放在序列一端。
排序过程:
代码:
public void sort(int[] data) {
int size = data.length;
for(int i=0; i<size; i++) {
for(int j=0; j<size-i-1; j++) {
if(data[j] > data[j+1])
swap(data,j,j+1);
}
}
}
//交换两个元素
public void swap(int[] data,int i,int j) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
冒泡排序与选择排序的区别:
- 冒泡排序法是两两依次比较,并做交换,交换的次数多。
- 选择排序法是每次循环找出最值,循环结束后将最值调整到合适位置,交换的次数少。
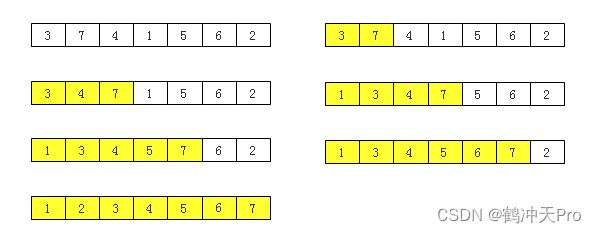
四、归并排序
排序过程:

4.1、自顶向下的归并排序
排序思想:要将一个数组排序,可以先(递归的)将它分为两半分别排序,然后将结果归并起来。
private int[] array; //辅助数组
public void sort(int[] data) {
array = new int[data.length];
mergeSort(data, 0, data.length - 1);
}
//核心算法
public void mergeSort(int[] data, int down, int up) {
if (up <= down) return; //结束条件
int mid = (up - down) / 2 + down;
mergeSort(data, down, mid); //左半边排序
mergeSort(data, mid + 1, up); //右半边排序
merge(data, down, mid, up);
}
//一个数组左右半边分别有序,归并
public void merge(int[] data, int down, int mid, int up) {
int i = down, j = mid + 1;
//复制数组中元素
for (int k = down; k <= up; k++) {
array[k] = data[k];
}
for (int k = down; k <= up; k++) {
if (i > mid)
data[k] = array[j++]; //左半边用尽,取右半边元素
else if (j > up)
data[k] = array[i++];
else if (array[i] < array[j]) //左半边元素比右半边小
data[k] = array[i++];
else
data[k] = array[j++];
}
}
对于自顶向下的归并排序的改进:
-
由于归并排序的方法调用过于频繁,会产生过多的额外开销,所以归并排序在处理小规模问题时,比插入排序要慢。在用归并排序处理大规模数据时,使用插入排序来处理小规模的子数组,一般可使归并排序的运行时间缩短10%-15%。
-
添加一个判断,如果data[mid]小于data[mid+1],则数组已经有序,不需要进行归并操作。这样可大大减小有序子数组的运行时间。
-
通过在递归调用的每个层次交换输入数组和辅助数组的角色,节省元素复制到辅助数组中的时间(空间不行)。即在递归中,数据从输入数组排序到辅助数组和从辅助数组排序到输入数组交替使用。
/*
* 改进自顶向下的归并排序
* 1. 对小规模数组使用插入排序
* 2. 加入数组是否有序的判断,减少归并次数
* 3. 通过在递归中交换参数,避免数组复制
*/
public class MergeInsSort {
public static final int CUTOFF = 5; //插入排序处理数组长度
private int[] array;
public void sort(int[] a) {
array = a.clone();
mergeSort(array, a, 0, a.length - 1);
}
//核心算法, 对dst进行排序
public void mergeSort(int[] src, int[] dst, int down, int up) {
//改进,小规模用插入排序,结束条件
if (up - down <= CUTOFF) {
insertionSort(dst, down, up);
return;
}
int mid = (up - down) / 2 + down;
mergeSort(dst, src, down, mid); //左半边排序,交换输入数组和辅助数组角色
mergeSort(dst, src, mid + 1, up); //右半边排序,结果:src中有序
if(src[mid] < src[mid + 1]) { //是否已经有序
System.arraycopy(src, down, dst, down, up-down+1);
return;
}
merge(src, dst, down, mid, up);
}
//一个数组左右半边分别有序,src归并到dst
public void merge(int[] src, int[] dst, int down, int mid, int up) {
assert isSorted(src, down, mid); //断言,左右半边均有序
assert isSorted(src, mid+1,up);
int i = down, j = mid + 1;
for (int k = down; k <= up; k++) {
if (i > mid) dst[k] = src[j++]; //左半边用尽,取右半边元素
else if (j > up) dst[k] = src[i++];
else if (src[i] < src[j]) //左半边元素比右半边小
dst[k] = src[i++];
else dst[k] = src[j++];
}
assert isSorted(dst, down, up);
}
//插入排序
public void insertionSort(int[] a, int down, int up) {
for (int i = down+1; i <= up; i++) {
for (int j = i; j >= down+1 && a[j] < a[j-1]; j--) {
swap(a, j, j-1);
}
}
}
/*******************************************************************************/
//交换两个元素
public void swap(int[] a,int i,int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
//判断down到up的元素是否有序
public boolean isSorted(int[] a, int down, int up) {
for (int i = down+1; i <= up; i++) {
if (a[i] < a[i - 1])
return false;
}
return true;
}
}
4.2、自底向上的归并排序
排序思想:先两两归并(把每个元素当成一个长度为1的数组),在四四归并,然后八八归并,一直下去。每轮归并中最后一次归并的第二个数组可能比第一个小(注意不要越界)。
private int[] array; //辅助数组
public void sort(int[] a) {
array = new int[a.length];
mergeSort(a);
}
//核心算法
public void mergeSort(int[] a) {
int N = a.length;
for (int i = 1; i < N; i = 2 * i) {
for (int j = 0; j < N - i; j += 2 * i)
merge(a, j, j + i - 1, Math.min(j + 2 * i - 1, N - 1));
}
}
//一个数组左右半边分别有序,归并
public void merge(int[] a, int down, int mid, int up) {
int i = down, j = mid + 1;
//复制数组中元素
for (int k = down; k <= up; k++) {
array[k] = a[k];
}
for (int k = down; k <= up; k++) {
if (i > mid) a[k] = array[j++]; //左半边用尽,取右半边元素
else if (j > up) a[k] = array[i++];
else if (array[i] < array[j]) //左半边元素比右半边小
a[k] = array[i++];
else a[k] = array[j++];
}
}
五、希尔排序
排序思想:交换不相邻的元素以对数组的局部进行排序,并最终用插入排序将局部有序的数组排序。使数组中任意间隔为h的元素都是有序的。其中h为任意以1结尾的整数序列。
希尔排序的执行时间依赖于增量序列h,好的增量序列的共同特征:
- 最后一个增量必须为1;
- 应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况。
排序过程:
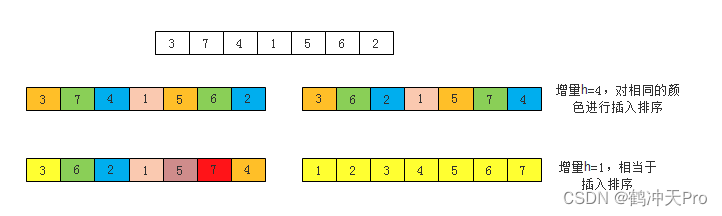
希尔排序比插入排序要快的多,并且数组越大,优势越大。
代码:
//核心算法,增量序列 1 4 13 ....(3*h+1)
public void sort(int[] data) {
int size = data.length;
int h = 1;
while(h < size/3)
h = 3*h + 1;
while(h > 0 ) {
//插入排序,间隔h
for(int i=h; i<size; i++) {
for(int j=i; j>=h && data[j] < data[j-h]; j = j-h) {
swap(data, j, j-h);
}
}
h = h/3;
}
}
//交换两个元素
public void swap(int[] data,int i,int j) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
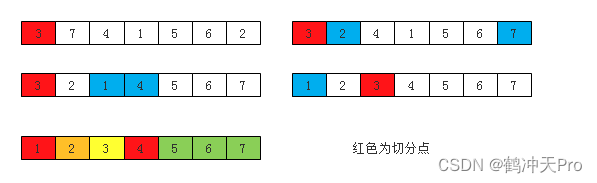
六、快速排序
排序思想:通过一趟排序将要排序的数据切分成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
切分过程:

取数组中第一个元素作为切分元素V,从数组的左端开始向右扫描直达找到一个大于等于V的元素,再从数组右端向左扫描直到找到一个小于等于V的元素,交换他们的位置。如此继续,保证左指针左侧的元素都小于等于V,右指针右侧的元素都大于等于V。直到两个指针相遇,将V和左子数组最右侧元素交换,返回j
排序过程:
public void sort(int[] data) {
sort(data, 0, data.length - 1);
}
//核心算法
public void sort(int[] data, int down, int up) {
if(up <= down)
return;
int temp = partition(data, down, up); //找到切分点
sort(data, down, temp - 1); //左半边排序
sort(data, temp + 1, up); //右半边排序
}
//切分
public int partition(int[] data, int down, int up) {
int i = down;
int j = up + 1;
int v = data[down]; //使用data[down]作为切分元素
while (true) {
while (data[++i] < v) {
if (i == up)
break;
}
while (v < data[--j]) {
if (j == down)
break;
}
if (i >= j) break;
swap(data, i, j);
}
swap(data, down, j);
return j;
}
//交换两个元素
public void swap(int[] data, int i, int j) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
快速排序的改进:
快速排序切分不平衡时可能会非常低效,如:第一次以最小的元素切分,第二次以第二小的元素切分,如此,每次调用只会移动一个元素,这将使快速排序退化为冒泡排序。所以快速排序前要将数组进行随机排序,打乱其顺序。另外对于小规模数组,可以使用插入排序来提高排序的性能。原因和归并排序时一样。
改进后的代码:
//使用插入排序的阙值
public static final int CUTOFF = 5;
public void sort(int[] data) {
shuffle(data); //打乱数组,消除对输入的依赖
sort(data, 0, data.length - 1);
}
public void sort(int[] data, int down, int up) {
//小规模时用插入排序
if (up - down <= CUTOFF) {
insertionSort(data, down, up);
return;
}
//大规模时使用快速排序
int temp = partition(data, down, up); //切分
sort(data, down, temp - 1); //左半边排序
sort(data, temp + 1, up); //右半边排序
}
//切分
public int partition(int[] data, int down, int up) {
int i = down;
int j = up + 1;
while (true) {
//使用data[down]作为切分元素
while (data[++i] < data[down]) {
if (i == up)
break;
}
while (data[down] < data[--j]) {
if (j == down)
break;
}
if (i >= j) break;
swap(data, i, j);
}
swap(data, down, j);
return j;
}
//插入排序
public void insertionSort(int[] data, int down, int up) {
for (int i = down + 1; i <= up; i++) {
for (int j = i; j >= down + 1 && data[j] < data[j - 1]; j--) {
swap(data, j, j - 1);
}
}
}
//交换两个元素
public void swap(int[] data, int i, int j) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
//随机打乱数组
public static void shuffle(int[] data) {
int N = data.length;
Random rand = new Random();
for (int i = 0; i < N; i++) {
int r = i + rand.nextInt(N-i); // between i and N-1
int temp = data[i];
data[i] = data[r];
data[r] = temp;
}
}
七、堆排序
排序思想:利用堆的有序性(根节点最大)来进行排序,每次从堆中取出根节点,并保持堆有序。
如果对堆这种数据结构不太了解的话,可以先看我的另一篇博客《数据结构与算法(五),优先队列》。
这里需要注意:这篇博客中实现的堆是从数组中下标为0的位置开始的,所以结点k的子结点下标分别为2k+1和2k+2,这和在《数据结构与算法(五),优先队列》中的堆实现有些不同。
排序过程:
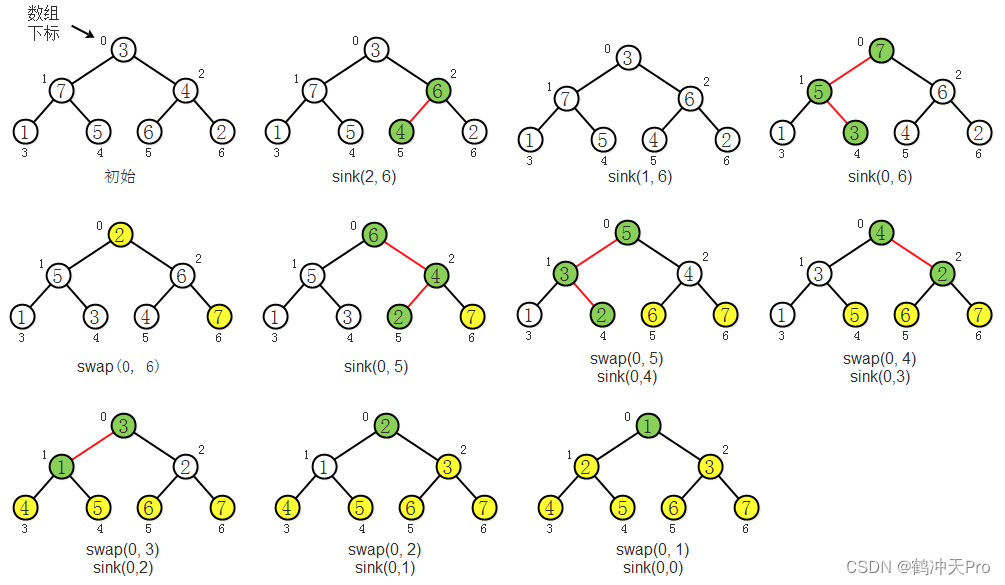
代码:
public void sort(int[] data) {
int N = data.length-1;
for(int k = (N-1)/2; k>=0; k--) {
sink(data, k, N); //使堆有序
}
//将最大元素放到最后
while(N > 0) {
swap(data, 0, N--);
sink(data, 0, N);
}
}
//下沉操作,从下标0开始
private void sink(int[] data, int k, int N) {
while(2*k+1 <= N) {
int j = 2*k+1;
if(j < N && data[j] < data[j+1])
j++;
if(data[k] >= data[j])
break;
swap(data, k, j);
k = j;
}
}
//交换两个元素
public void swap(int[] data, int i, int j) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
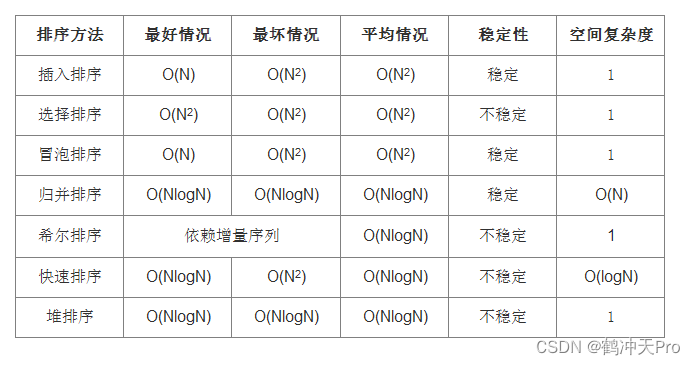
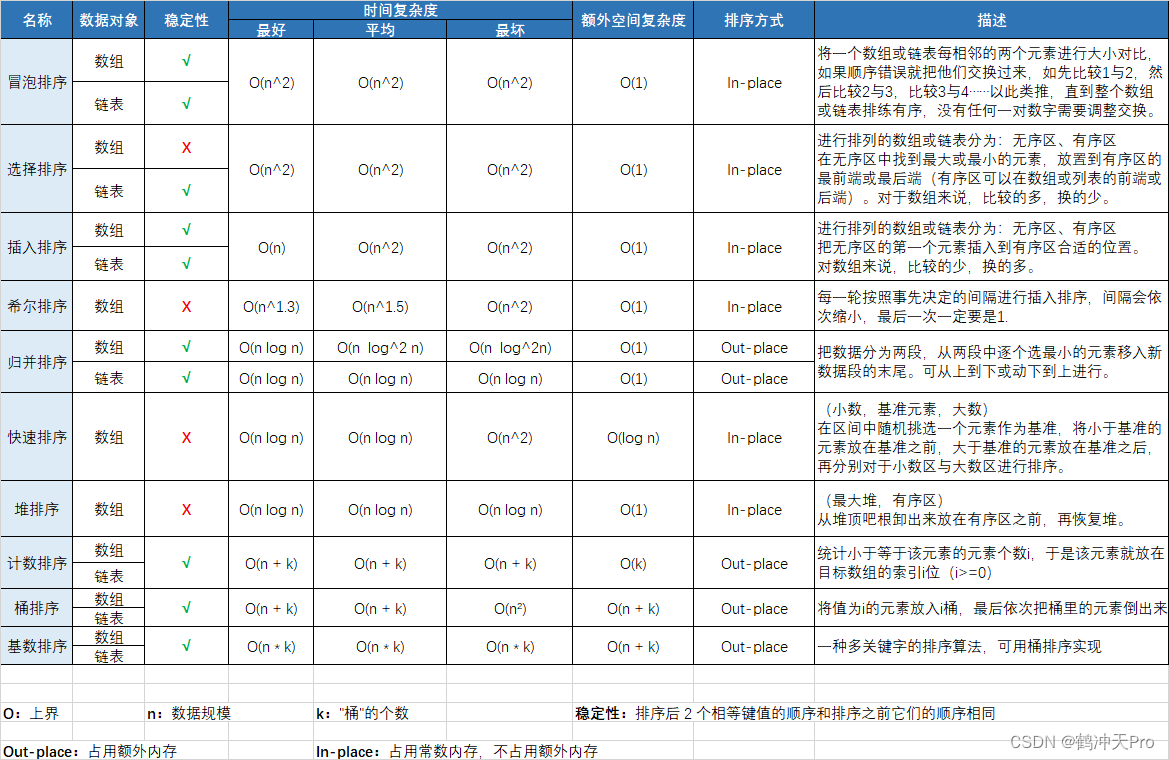
八、性能比较
说明:这里只比较通用的实现方法,而不会对排序方法的改进版本进行比较。
排序的稳定性:
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,ri=rj,且ri在rj之前,而在排序后的序列中,ri仍在rj之前,则称这种排序算法是稳定的;否则称为不稳定的。