文章目录
- 1.机器学习
- 1.1 机器学习简介
- 1.2 有监督学习(supervised learning)
- 1.3 无监督学习(unsupervised learning)
- 1.4 半监督学习
- 2. 机器学习工具SKlearn
- 2.1 sklearn
- 2.2 sklearn常用模块
- 2.2.1 分类
- 2.2.2 回归
- 2.2.3 聚类
- 2.2.4 降维
- 2.2.5 模型选择
- 2.2.6 数据预处理
- 2.3 sklearn使用流程
- 3. 数据集准备与划分
- 3.1 sklearn常用数据集
- 3.1.1 datasets.load_的数据集接口
- 3.1.2 datasets.fetch_的数据集接口
- 3.1.3 datasets.make_的数据集接口
- 3.2 数据集划分
- 4 模型选择及处理
- 4.1 分类
- 4.2 KNN算法
- 4.3 SVM 算法
- 4.4 决策树
- 4.5 逻辑回归
- 4.6 聚类
- 4.7 回归
- 4.7.1 线性回归
- 4.7.2 多项式回归
- 5 数据预处理
- 5.1 数据标准化
- 5.1.1 使用scale()函数实现数据标准化
- 5.1.2 使用StandardScaler()实现数据标准化
- 5.2 数据归一化
- 5.3 数据正则化
- 5.4 数据二值化
- 5.5 缺失值处理
- 6 模型调参
- 6.1 交叉验证
- 6.2 网格搜索
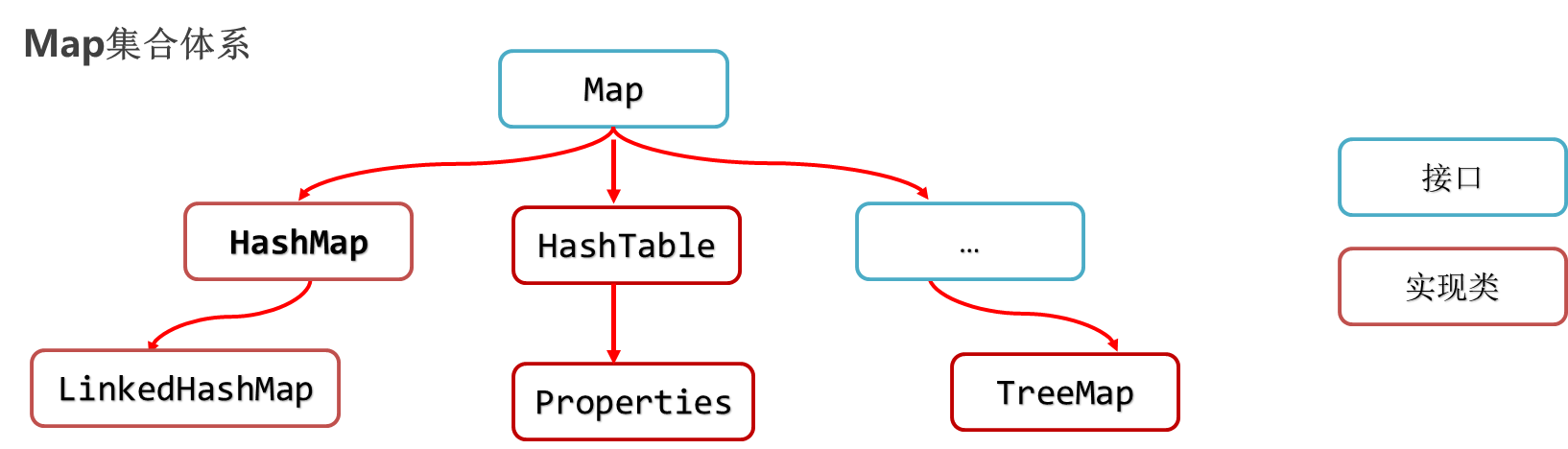
1.机器学习
1.1 机器学习简介
机器学习研究计算机如何模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识并不断改善自身的性能。它是一门综合性非常强的多领域交叉学科,涉及线性代数、概率论、统计学、逼近论和高等数学等学科。目前机器学习的应用非常广泛,包括数据分析与挖掘、计算机视觉、自然语言处理以及生物信息学等。
机器学习算法的分类方式有很多种,按照学习任务分类可以将机器学习算法和问题分为分类、聚类和回归;按照学习方式可以分为有监督学习、无监督学习和半监督学习。
1.2 有监督学习(supervised learning)
有监督学习算法是从有类别标签的训练数据集中学习出一个函数的机器学习算法。它对一组数据中每个样本的若干特征与类别标签之间的关联性进行建模,通过对大量已知样本的训练和学习确定模型参数;当新的未知标签数据到来时,可以根据这个模型预测未知标签数据的类别。
分类(classification)与回归(regression)都属于经典的有监督学习算法。在分类任务中,类别标签是离散值。通过对已知分类的数据进行训练和学习,找到同类的特征和规律,然后对未分类数据使用这些规律,用于预测未分类数据所属的类别。在回归任务中,需要预测的类别标签是连续值。
常用的有监督学习算法有决策树(decision tree)、支持向量机 (Support Vector Machines)、逻辑回归(logistic regression)、线性回归(linear regression)、朴素贝叶斯(naive Bayes).K-近邻(k-nearest neighbor algorithm)等。
1.3 无监督学习(unsupervised learning)
无监督学习算法根据无类别标签或类别标签未知的训练样本解决模式识别中的各种问题。由于样本数据的类别未知,无监督学习算法根据样本间的相似性发现样本集中的相似样本组合,或者确定数据的分布,或者将数据从高维空间投影到低维空间。
聚类(clustering)和降维(dimensionality reduction)是典型的无监督学习算法。聚类任务根据计算相似度将数据分成不同的组别,而降维任务可以减少与任务目标无关的特征数据并提高数据分析效率。
常用的无监督学习算法包括K-means聚类、主成分分析(Principal Component Analysis,PCA))和拉普拉斯特征映射算法等。
1.4 半监督学习
半监督学习是有监督学习与无监督学习相结合的学习方法。该方法使用大量的无标签数据一部分有标签数据共同进行模式识别工作,通常用于完成类别标签不完整的学习任务。
2. 机器学习工具SKlearn
2.1 sklearn
Python扩展库scikit-learn (http://scikit-learn.org) 简称sklearn,是使用最广泛的数据分析和机器学习库,它提供了用于模型选择和评估、数据转换、数据加载和模型持久化的工具,也包含SVM、随机森林、k-means等多种有监督和无监督的机器学习算法,可以用于分类、聚类、预测和其他常见任务。
sklearn是基于numpy、scipy和matplotlib等扩展库的python开源库,可以在Scripts文件夹下打开命令提示符窗口,安装好这些依赖库之后,再使用命令pip install scikit-learn或者pip install sklearn在线安装。如果使用Anaconda3集成开发环境,也可以在命令窗口下的Anaconda Prompt目录,使用conda命令安装、卸载或升级扩展库。
成功安装了sklearn及其依赖库,导入相关的模块,就可以使用扩展库sklearn提供的数据集、工具和算法开始数据分析和机器学习任务。
2.2 sklearn常用模块
扩展库scikit-learn提供的功能模块主要包括六大类,即分类Classification、回归Regression、聚类Clustering、数据降维Dimensionality reduction、模型选择Model selection和数据预处理Preprocessing。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
2.2.1 分类
分类算法使用一批已知类别标签的样本训练一个分类模型,使其能够对未知的样本进行分类。分类算法属于有监督学习算法,其分类过程是建立一个分类模型来描述给定的数据集或概念集,通过分析属性描述的数据记录来构造模型。分类的目的是使用训练好的模型对新数据进行类别划分,主要涉及分类规则的准确性、过拟合、矛盾划分的取舍等问题,常用于垃圾邮件检测、图像识别、人脸识别、信用卡申请人风险评估等。
传统的分类算法包括支持向量机、K-最邻近算法、逻辑回归(LR)、随机森林(RF)及决策树等。
2.2.2 回归
回归分析建立模型研究自变量和因变量之间的显著关系和影响强度,预测数值型数据的目标值,在管理、经济、社会学、医学、生物学等领域得到广泛应用。常用的回归方法包括支持向量回归、脊回归、Lasso回归、 弹性网络、最小角回归及贝叶斯回归等。
回归是一种预测性的建模技术,其原理是利用属性的历史数据预测未来趋势。首先假设一些已知类型的函数可以拟合目标数据,然后利用某种误差分析确定一个与目标数据拟合程度最好的函数。分类与回归的区别是预测值的数据类型不同,分类是采用离散值进行预测,而回归是采用连续值进行预测。
2.2.3 聚类
聚类模型自动识别具有相似属性的给定对象,将其划分至不同集合。聚类的输入是一组未被标记的数据,根据样本特征的距离或相似度进行划分。划分原则是保持最大的组内相似性和最小的组间相似性。因此,聚类属于无监督学习,常用于顾客细分、实验结果分组等场景。经典的聚类方法包括K-均值聚类、谱聚类、均值偏移、分层聚类和基于密度的聚类等。
聚类算法适用于客户分群以便进行精准营销等实际应用。分类与聚类的区别是样本集中是否提供类别标签,分类算法的输入值是带有类别标签的训练样本,而聚类的输入是一组没有给定类别标签的样本数据,根据样本特征的距离或相似度进行划分。其划分的原则是保证在同组数据的相似性高,不同组数据的相似度低。
2.2.4 降维
在机器学习任务中,面对一个具有上千特征的数据集,对于模型训练将是一个巨大的挑战。在高维数据中筛选出有用的变量,可以减小计算复杂度并提高模型的训练效率和准确率,这就是数据降维。数据降维是指采用某种映射方法,将原高维空间中的数据点映射到低维空间中,从而减少与任务无关的随机变量个数。常用于可视化处理、效率提升的应用场景。常用的数据降维算法有主成分分析(PCA)、非负矩阵分解(NMF)等。
2.2.5 模型选择
根据一组不同复杂度的模型表现,从某个模型空间中挑选最好的模型是模型选择的主要任务。模型选择是对给定参数和模型的比较、验证和选择的方法,是一系列找到最佳复杂度模型的方法。其主要思想是通过训练数据来估计期望的测试误差,从而在不同复杂度的模型中进行选择。模型选择的目的是通过参数调整来提升精度,sklearn模块已实现的模型选择方法包括网格搜索、交叉验证和各种针对预测误差评估的度量函数。
2.2.6 数据预处理
现实世界的数据极易受到噪声、缺失值和不一致数据的侵扰,低质量的数据无法直接进行数据分析和处理,或导致分析结果差强人意。在主要的数据分析和处理工作之前进行的数据预处理是提高数据质量的有效方法,主要包括数据清理、数据集成、数据规约和数据变换等。其中数据清理用于清除数据噪声并纠正不一致;数据集成可以将多个数据源合并成一致的数据存储起来;数据规约通过聚集、删除冗余特征或聚类等方法降低数据规模;数据变换实现数据的规范化。
2.3 sklearn使用流程
机器学习库sklearn的使用一般分为准备数据集、选择模型、训练模型和测试模型四个阶段。准备数据集是指所研究问题涉及的数据加载及数据预处理过程;选择模型需要根据任务的不同选取合适的模型,建立模型评估对象;训练模型就是将数据集送入模型,根据经验设定模型参数;测试模型就是根据评价指标评估模型以便进一步模型优化。
在sklearn使用流程下,KNN算法对应的代码是:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accurancy_score # 导入需要的模板
knn_model = KNeighborsClassifier() # 选择K近邻距离算法,实例化
knn_model.fit(x_train,y_train) # 用训练集数据训练模型
acc = accurancy_score(x_test,y_test) # 导入测试集,评估模型
使用sklearn实现鸢尾花分类
# 引入包
import pandas as pd
import numpy as np
# 导入数据
iris_data = pd.read_csv('work/iris.csv')
iris_data.head()
"""
sepal_length sepal_width petal_length petal_width species label
0 5.1 3.5 1.4 0.2 setosa 1
1 4.9 3.0 1.4 0.2 setosa 1
2 4.7 3.2 1.3 0.2 setosa 1
3 4.6 3.1 1.5 0.2 setosa 1
4 5.0 3.6 1.4 0.2 setosa 1
"""
# 获取特征
X = iris_data[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']].values
# 获取标签
y = iris_data['label'].values
from sklearn.neighbors import KNeighborsClassifier #选择K近邻模型
knn_model = KNeighborsClassifier() # 实例化
knn_model.fit(X, y) # 训练模型
# 选择第一个样本
knn_model.predict([[5.1, 3.5, 1.4, 0.2]])
"""
array([1])
"""
# 选择最后一个样本
knn_model.predict([[5.9, 3.0, 5.1, 1.8]])
"""
array([3])
"""
3. 数据集准备与划分
3.1 sklearn常用数据集
机器学习过程离不开数据。扩展库sklearn自身内置了少量数据集,供人们学习使用。用户可以登录官网(网址: http://scikit-learn.org/stable/modules/classes.html#module-sklearn.dataset)查看sklearn提供的全部数据集列表。

扩展库sklearn提供的数据集都在sklearn.dataset包中,该模块主要提供了导入、在线下载及本地生成数据集的方法,可以通过dir或help命令查看。对于不同类型的内置数据集,sklearn提供三种不同类型的数据集接口,即dataset.load_<dataset_name>、datasets.fetch_<dataset_name>和datasets.make_<dataset_name>。
3.1.1 datasets.load_的数据集接口
scikit-learn内置的一些小型标准数据集是安装sklearn扩展库时打包下载到本地的,不需要从外部网站下载任何文件,直接加载就可以使用。例如,可以分别使用命令load_iris()和load_boston()加载入门训练使用最多的鸢尾花数据集和波士顿房价数据集,加载数据集的可选参数return_X_y默认值为False,表示以字典形式返回包括data和target在内的全部数据;若return_x y=True,则以(data,target)元组形式返回数据。
from sklearn.datasets import load_iris
data = load_iris(return_X_y=True)
type(data)
"""
tuple
"""
使用扩展库sklearn中dataset.load_()的数据集接口加载内置的小型标准数据集,默认获取的数据集是类字典类型,可以按照字典的方式使用,可以通过keys()方法查看数据集的元素,包括data 数据、target标签、target_names标签名、feature_names特征名、DESCR数据集描述等。
from sklearn.datasets import load_iris
data = load_iris()
print(dir(data)) #查看data所具有的属性或方法
"""
['DESCR', 'data', 'feature_names', 'filename', 'target', 'target_names']
"""
print(data.DESCR) #查看数据集的描述
print(data.feature_names) #查看数据的特征名(属性名)
print(data.data) # 查看数据
print(data.target_names) #查看数据的分类名
print(data.target) # 查看数据的标签
print(data.target[[1,10, 100]]) #查看第2、11、101个样本的目标值
3.1.2 datasets.fetch_的数据集接口
扩展库scikit-learn提供了加载较大数据集的工具。必要时用户从网络上下载大规模数据集,用datasets.fetch_<dataset_name>()加载。scikit-learn提供了大规模数据集的完整目录,可以通过datasets.get_data_home()函数获取,使用完毕,用户可以调用clear_data_home(data_home=None)函数删除所有下载的数据。
这些比较大的数据集,主要用于测试解决实际问题,必要时在线下载。以20newsgroups数据集为例。扩展库sklearn提供了两种加载20newsgroups数据集的方式。第一种是使用sklearn.datasets.fetch 20newsgroups()函数,返回一个能够被文本特征提取器接受的原始文本列表,;第二种使用是sklearn.datasets.fetch_20newsgroups_vectorized(),返回一个已提取特征的文本序列,即不需要使用特征提取器了。
这里使用datasets.fetch_20newsgroups()加载机器学习的标准数据集20newsgroup,语法格式如下:
fetch_20newsgroups(data_home=None, subset='train', categories=None, shuffle=True,random_state=42, remove=(), download_if_missing=True)
# 参数data_home:设置数据集的下载路径,默认所有scikit学习数据都存储在“~/scikit_learn data/”子文件夹中,也可以修改环境变量SCIKIT_LEARN_DATA指定自己的默认目录;
# 参数subset: 选择要加载的数据集,接收字符串'train'、'test'或" all',分别表示加载数据集中的训练数据、测试数据和所有数据;
# 参数categories:指定选取哪一类数据集,接收表示新闻类别的列表类型,默认20类;
# 参数shuffle指定是否将数据随机排序,接收布尔值True或False;
# 参数random_state用于设置随机数生成器或种子整数;
# 参数remove=()表示去除部分文本;
# 参数download_if_missing=True表示如果没有下载过,可以重新下载数据集。
3.1.3 datasets.make_的数据集接口
扩展scikit-learn包括各种随机样本的生成器,可以用来建立可控制大小和复杂性的人工数据集。scikit-learn.datasets模块提供了生成随机数据的API。与numpy相比,该接口可以用来生成适合特定机器学习模型的数据,用于分类、回归、聚类、流形学习或者因子分解等任务。
生成分类模型随机数据可以使用sklearn.datasets.make_classification生成分类模型随机数据,主要参数如下:
# 参数n_samples:指定生成的样本数量,整数类型,默认值为100;
# 参数n_features: 指定生成的样本特征总数,取值为n_informative、n_redundant和n_repeated特征值之和,整数类型,默认值为20;
# 参数n_informative:指定多信息特征的个数;
# 参数n_redundant:表示冗余信息,informative特征的随机线性组合;
# 参数n_repeated:表示重复信息,随机提取n_informative和n_redundant特征;
# 参数n_classes:指定分类类别,整数类型,默认值为2;
# 参数n_clusters_per_class:表示某一个类别是由几个cluster构成;
# 参数random_state:指定随机数生成器使用的种子,整数类型。
# 用make_classification生成三元分类模型数据
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets.samples_generator import make_classification
# X1为样本特征,Y1为样本类别输出, 共400个样本,每个样本2个特征,输出有3个类别,没有冗余特征,每个类别一个簇
X1, Y1 = make_classification(n_samples=400, n_features=2, n_redundant=0,
n_clusters_per_class=1, n_classes=3)
plt.scatter(X1[:, 0], X1[:, 1], marker='o',c=Y1)
plt.show()

生成回归模型随机数据可以使用sklearn.datasets.make_regression生成回归模型数据,主要参数除了生成样本数n_samples、样本特征数n_features和指定随机数生成器种子的random_state,还有样本随机噪音noise和指定是否返回回归系数的coef参数。
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets.samples_generator import make_regression
# X为样本特征,y为样本输出, coef为回归系数,共1000个样本,每个样本1个特征
X, y, coef =make_regression(n_samples=1000, n_features=1,noise=10, coef=True)
# 画图
plt.scatter(X, y, color='blue')
plt.plot(X, X*coef, color='yellow',
linewidth=3)
plt.show()

生成聚类模型随机数据使用sklearn.datasets. make_blobs生成聚类模型随机数据,关键参数除了包括生成样本数n_samples和样本特征数n_features,还有指定簇中心个数或者自定义簇中心的参数centers和指定簇数据方差的参数cluster_std。
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets.samples_generator import make_blobs
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本2个特征,共3个簇,簇中心在[-1,-1], [1,1], [2,2], 簇方差分别为[0.4, 0.5, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [1,1], [2,2]], cluster_std=[0.4, 0.5, 0.2])
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.show()

3.2 数据集划分
数据集准备阶段,送入模型的数据可以分为样本特征矩阵X和标签y两部分。其中样本特征X可以表示为一个numpy二维数组,数组的行数代表样本个数,列数表示样本特征数;标签y就是每个样本对应的类别,表示为一维数组,元素个数与样本个数相同。
现实应用中,待预测的样本是从未见过的。为了测试模型的性能,需要通过实验对模型的泛化误差进行评估,进而做出选择,所以需要一个“测试集”来测试模型对新样本的判别能力。因此,在机器学习任务中可以将数据集划分为训练集和测试集两部分,人为地将一小部分数据作为为测试数据以供测试模型的性能。首先在训练集上训练模型,输入训练数据的特征矩阵X和标签y;然后在测试集上测试模型,输入测试数据的特征;最后根据输出的预测标签和真实标签进行比较,检验模型的性能。
扩展库sklearn中提供了用于划分测试集和训练集的train_test_split()函数,返回划分好的训练集、测试集样本和训练集、测试集的标签。语法格式如下:
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=1/4,random_state)
# 参数X:表示原始数据集样本的所有特征;
# 参数y:表示所有样本的类别标签;
# 参数test_size:设置测试集样本占比或数量,如果是浮点数,在0-1之间,表示样本占比;如果是整数,就是样本的数量;如果是None,test size自动设置为0.25;
# 参数random_state:指定随机数生成器的种子,以保证重复试验的时候,得到一组一样的随机数。
import pandas as pd
import numpy as np
iris_data = pd.read_csv('work/iris.csv')
# 获取特征
X = iris_data[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']].values
# 获取标签
y = iris_data['label'].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/4, random_state=10)
print('原数据集的样本个数:', X.shape[0])
print('训练集的样本个数:', X_train.shape[0])
print('测试集的样本个数:', X_test.shape[0])
"""
原数据集的样本个数: 150
训练集的样本个数: 112
测试集的样本个数: 38
"""
# 选择K近邻距离算法
from sklearn.neighbors import KNeighborsClassifier
knn_model = KNeighborsClassifier()
在训练集上进行训练
knn_model.fit(X_train, y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform')
# 在测试集上测试模型
y_pred = knn_model.predict(X_test)
# 输出测试集真实值和预测值
print('真实值:', y_test)
print('预测值:', y_pred)
# 模型准确率
from sklearn.metrics import accuracy_score
acc = accuracy_score(y_test, y_pred)
print('准确率:', acc)
4 模型选择及处理
不同模型适用于处理不同规模的数据,解决不同类型的问题,目前不存在适用于解决机器学习领域所有问题的通用模型和算法。在实际应用中,用户需要对问题类型和数据规模进行深入分析,从数据量大小、特征维度多少以及给定的任务要求等多方面综合考量,选择适合的机器学习模型和算法。
4.1 分类
分类模型的使用包括两个阶段,其中学习阶段的任务是构建分类模型,分类阶段的任务是使用模型预测给定数据的类标签。常用的分类模型主要有决策树、K-近邻、支持向量机、朴素贝叶斯等。
4.2 KNN算法
K-近邻(K-Nearest Neighbor Classification,KNN)属于有监督学习算法,所谓K是指K个最邻近的样本。在特征空间中,如果一个样本附近的k个最邻近样本大多数属于某一个类别,则该样本也属于这个类别。KNN算法一般应用于字符识别、文本分类、图像识别等领域,既可以用于解决分类问题又可以用于解决回归问题。
KNN算法根据距离函数计算待分类样本x和其他每个训练样本的距离,选择与待分类样本距离最小的K个样本作为样本x的K个最近邻,最后以x的K个最近邻中大多数样本所属的类别作为样本x的类别。如何度量样本之间的距离是KNN算法的关键。常见的距离度量方法包括闵可夫斯基距离(当参数p=2时为欧几里得距离,参数p=1时为曼哈顿距离)、余弦相似度、皮尔逊相关系数、汉明距离、杰卡德相似系数等。对于每一个待分类样本,都要计算它到全部已知样本的距离,因此KNN算法的计算量较大。
扩展库sklearn.neighbors提供了实现K近邻分类算法的**KNeighborsClassifier()**函数,语法格式如:
sklearn.neighbors.KNeighborsClassifier(self,n_neighbors=5,weights='unifom',algorithm='auto',leaf_size=30,p=2,metric=' minkowski',metric_params=None,n_jobs=1,**kwargs)
| 参数 | 说明 |
|---|---|
| n_neighbors | 对应于算法中的K值。 |
| weights | 预测时使用的权重函数,取值可以为’uniform’、‘distance’和’callable’。取值’uniform’表示统一权重,即领域内所有样本使用同一权重;取值’distance’表示权重为两点间距离的倒数;取值’callable’表示自定义函数,接受距离数组,返回—组维度相同的权重 |
| algorithm | 指定合适的k-近邻搜索算法。取值可以为’ball_tree’、‘kd_tree’.‘brute’和’auto’。取值’brute’表示计算未知样本与空间中所有样本的距离;取值’ball_tree’表示构建球树加速寻找最近邻样本; |
| leaf_size | BallTree和KDtree算法的叶子大小 |
| metric | 距离度量公式。默认度量采用闵可夫斯基距离,也就是p=2的欧氏距离 |
| p | 闵可夫斯基距离计算参数,默认值为2,使用欧式距离公式进行距离度量;也可以设置为1,使用曼哈顿距离公式进行距离度量 |
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 准备数据集
movie_data= pd.read_csv('work/movie_data.csv')
# 获取特征
X = movie_data.iloc[:, 2:-1].values
# 获取标签
y = movie_data['电影类型'].values
print(y)
print('----------')
print(X)
"""
['喜剧片' '动作片' '动作片' '爱情片' '爱情片' '动作片' '喜剧片' '喜剧片']
----------
[[39 0 31]
[ 3 2 65]
[ 2 3 55]
[ 9 38 2]
[ 8 34 17]
[ 5 2 57]
[21 17 5]
[45 2 9]]
"""
knn_model = KNeighborsClassifier()
# 训练模型
knn_model.fit(X, y)
# 预测
knn_model.predict([[23,2,17]])
"""
array(['喜剧片'], dtype=object)
"""
4.3 SVM 算法
支持向量机 (Support Vector Machine,SVM)是一种有监督学习算法,既可以对线性数据分类,又可以对非线性数据回归,广泛应用于统计分类和回归分析任务。
支持向量机通过寻找将样本点分隔开的最优决策超平面来实现分类或预测任务。支持向量机的关键是找到决定分隔超平面的支持向量样本点,使得分类间隔最大化。在二维平面上相当于寻找两条分隔样本点的平行直线,在保证不出现错分样本的前提下,使得平行线间的距离最大。这两条平行线之间的垂直距离就是最优决策超平面对应的分类间隔,位于平行线上的样本点在坐标系中对应的向量就是支持向量。如果样本在二维平面上是线性不可分的,可以将所有样本映射到一个更高维空间,尝试在更高维空间寻找一个最大间隔超平面。在分隔数据的超平面两边建立两个互相平行的超平面,分隔超平面使得两个平行超平面的距离最大化,决定平行超平面的样本点就是要寻找的支持向量样本点。平行超平面间的距离越大,分类器的总误差越小。
扩展库sklearn.svm提供了实现支持向量机分类器的SVC函数,语法格式如下:
sklearn.svm.sVC(self,C=1.0,kernel='rbf',degree=3,gamma='auto',coef0=0.0,shrinking=True,probability=Flase,tol=0.001,cache_size=200,class_weight=None,verbose=False,max_iter=1,decision_function_shape='ovr',random_state=None)
| 参数名称 | 说明 |
|---|---|
| c | 设置惩罚项系数,默认为1.0。C值越大,对误分类的惩罚越大,训练样本的准确率越高;c值越小,对误分类的容忍度越高,泛化能力较强。对带有噪声的训练样本可采用后者,将误分类的训练样本作为噪声。 |
| kernel | 设置核函数类型,默认为’rbf’,取值可以是’linear’、‘poly’、‘rbf’、 ‘sigmoid’、'precomputed或可调用对象;取值’linear’表示样本是线性可分的。 |
| degree | 只用于kernel='poly’时,设置多项式核函数的度,默认为3 |
| gamma | 只用于kernel='poly’时,设置多项式核函数的度,默认为3 |
| coef0 | 设置核函数的常数项,只对’poly"和’sigmoid’核函数有用 |
| probability | 是否启用概率估计。必须调用fit()之前启用,并且会使fit()方法速度变慢 |
| tol | 设置SVM停止训练的误差精度,默认为1e-3。 |
| max_iter | 设置最大迭代次数,-1表示无限制 |
| decision function_shape | 设置决策函数的形状,取值可以是’over’或’ovo’,分别表示决策函数形状为(n_samples,n_classes)或(n_samples,n_classes*(n_classes-1)/2)。 |
# 利用np.meshgrid()生成一个坐标矩阵,然预测坐标矩阵中每个点所属的类别,最后用contourf()函数
# 为坐标矩阵中不同类别填充不同颜色
import numpy as np
def plot_hyperplane(clf, X, y,
h=0.02,
draw_sv=True,
title='hyperplan'):
# create a mesh to plot in
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
plt.title(title)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap='hot', alpha=0.5)
markers = ['o', 's', '^']
colors = ['b', 'r', 'c']
labels = np.unique(y)
for label in labels:
plt.scatter(X[y==label][:, 0],
X[y==label][:, 1],
c=colors[label],
marker=markers[label], s=20)
if draw_sv:
sv = clf.support_vectors_
plt.scatter(sv[:, 0], sv[:, 1], c='black', marker='x', s=15)
%matplotlib inline
from matplotlib import pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=100, centers=2, random_state=0, cluster_std=0.3)
clf = svm.SVC(C = 1.0, kernel='linear')
clf.fit(X,y)
print(clf.score(X,y))
plt.figure(figsize=(10,3), dpi=100)
plot_hyperplane(clf, X, y, h=0.01, title='Maximiin Margin Hyperplan')
运行结果如图所示。该示例使用np.meshgrid()生成一个网格点坐标矩阵,预测坐标矩阵中每个点所属的类别;使用matplotlib.pyplot模块提供的contourf()函数绘制等高线;在scatter()函数中设置参数为不同类别的样本点填充不同颜色;使用make_blobs函数生成数据集,其中n_features=2表示每一个样本有2个特征值,n_samples=100表明样本个数,centers=3指定聚类中心点个数,可以理解为类别标签的种类数,cluster_std=[0.8,2,5]指定每个类别的方差。

4.4 决策树
决策树(Decision Tree)是一种有监督的归纳学习算法。它能够从一系列包含特征和标签的数据中总结出决策规则,并用类似流程图的树结构呈现规则,形成分类器和预测模型,对未知数据进行分类、预测、数据预处理和数据挖掘等。
机器学习中的决策树代表对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,每个分叉路径代表某个可能的属性值,而每个叶结点则表示对应从根节点到该叶节点的路径上表示的对象值。一般地说,决策树仅有单一输出,可以根据属性的取值对一个未知实例集进行分类。使用决策树对实例进行分类时,由树根开始对该对象的属性逐渐测试其值,并且顺着分支向下走,直至到达某个叶节点,此叶节点代表的类即为该对象的类别标签。
构造决策树的核心问题是在每一步如何选择恰当的属性划分样本。ID3 (lterativeDichotomiser)以信息增益为准则来选择最优属性进行样本集划分,C4.5选择信息增益率最高的属性作为最优划分属性,CART以基尼指数最小的属性作为最优划分属性。
扩展库sklearn.tree提供了实现决策树模型的DecisionTreeClassifier函数,语法格式为:
sklearn.tree.DecisionTreeClassifier(criterion='gini',splitter='best',max_depth=None, min_samples_split=2, min_samples_leaf=1,min_weight_fraction_leaf=0.0, max_features=None, random_state=None,max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None,class_weight=None, presort=False)
| 参数名称 | 说明 |
|---|---|
| cirterion | 指定不纯度的计算方法,取值为’gini ‘或’entropy’,分别表示基尼系数和信息嫡。 |
| splitter | 指定在每个节点选择划分的策略。默认值’best’表示在所有特征中找最好的切分点,适合样本量不大的情况;值’random’表示在部分特征中选择,适合样本数据量非常大的情况。 |
| max_depth | 设置决策树的最大深度,超过指定深度的树枝需要剪掉,是使用最广泛的剪枝参数。深度越大,越容易过拟合。 |
| min_samples_split | 指定分裂节点的最小样本数量。当样本数量可能小于此值时,结点将不再进一步划分。 |
| min_samples leaf | 指定叶子节点最少的样本数。如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。样本量达到10W,推荐使用该值。 |
| .max_features | 指定分枝时考虑的特征个数,默认值None’,表示考虑所有特征 |
| random_state | 设置决策树分枝中随机模式的参数,决定特征选择的随机性。 |
| max_leaf_nodes | 通过限制最大叶子节点数,可以防止过拟合,默认值None’表示不限制最大叶子节点数。 |
| min_impurity_decr ease | 指定节点分裂时不纯度减少值,若大于或等于该值,则分裂。 |
| min_impurity _split | 用于限制决策树的增长,如果某节点的不纯度小于该阙值,那么此节点不再生成子节点,即为叶子节点。 |
| presort | 设置是否对数据预排序来加速训练过程。 |
# 导入相关库
import pandas as pd
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
# 加载红酒数据集
wine=load_wine()
wine.data.shape
"""
(178, 13)
"""
pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1) #创建DataFrame对象,放入红酒数据集

print(wine.feature_names)
"""
['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline']
"""
print(wine.target_names)
"""
['class_0' 'class_1' 'class_2']
"""
# 划分数据集
X_train,X_test,y_train,y_test=train_test_split(wine.data,wine.target,test_size=0.3)
print(X_train.shape)
print(X_test.shape)
"""
(124, 13)
(54, 13)
"""
# 构造决策树模型
clf=tree.DecisionTreeClassifier(criterion="entropy" #设置信息熵计算节点不纯度
, max_depth=3 #设置决策树最大深度为3
,random_state=30 #设置随机数值30
)
clf=clf.fit(X_train,y_train)
score=clf.score(X_test,y_test)
score
"""
0.9074074074074074
"""
# 可视化决策树
import graphviz
feature_name=['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','稀释葡萄酒的0280/0D315','脯氨酸']
dot_data=tree.export_graphviz(clf
,feature_names=feature_name #设定特征名称
,class_names=['1','2','3'] #设置类别名称
,filled=True #决策树填充颜色
,rounded=True
,special_characters=True
)
graph=graphviz.Source(dot_data)
graph.render('wine-tree')

4.5 逻辑回归
逻辑回归实际上是一个用于分类的线性模型。逻辑回归的因变量既可以是二分类的,也可以是多分类的,但是二分类的更为常用。通常利用已知的自变量来预测一个离散型因变量的值,也就是通过拟合一个逻辑回归函数来预测一个事件发生的概率。所以预测结果是一个属于[0,1]区间的概率值。逻辑回归模型常用于数据挖掘、疾病自动诊断、经济预测等领域。
扩展库sklearn.linear_model提供了实现逻辑回归算法的LogisticRegression函数。其语法格式如下:
sklearn.linear.LogisticRegression(self,penalty='12',dual=False,tol=0.0001,C=1.0,fit_intercept=True,intercept_scaling=1,class_weight=None,random_state=None,solver='liblinear',max_iter=100,multi_class='ovr',verbose=0,warm_start=False,n jobs=1)
| 参数名称 | 说明 |
|---|---|
| penalty | 用于指定惩罚项的范数,可选值为"I1"和"I2",分别对应L1正则化和L2正则化,默认是L2正则化。newton-cg、sag和lbfgs优化算法只支持L2范数。 |
| c | 正则化系数的倒数,是正浮点数,默认值1.0,数值越小表示正则化越强。 |
| solver | 用于优化算法选择,可选值为’newton-cg’、‘lbfgs’、‘liblinear’、‘sag’或’saga’。默认值’liblinear’。该参数决定了逻辑回归损失函数的优化方法。 |
| multi_class | 分类方式选择参数,可选值为’ovr’和’multinomial’,默认值’ovr’。 |
| n_jobs | 指定在类上并行使用的CPU核数。整型,默认值1表示用CPU的一个内核运行程序;值为-1表示用所有CPU的内核运行程序。 |
# 导入相关包
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 准备数据
# 复习情况,格式为(时长,效率),其中时长单位为小时,效率为小数
X=[(0,0),(2,0.8),(3,0.5),(3,0.9)
,(4,0.9),(5,0.4),(6,0.4),(6,0.8)
,(6,0.7),(7,0.3),(7.5,0.8),(7,0.9)
,(8,0.1),(8,0.1),(8,0.8),(3,0.9)
,(7,0.5),(7,0.2),(4,0.5),(4,0.7)]
# 0表示不及格,1表示及格
y=[0,0,0,1,1,1,1,0,1,1,0,1,1,0,1,0,1,0,0,1]
# 划分数据集
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=3)
# 训练模型
reg=LogisticRegression()
reg.fit(X_train,y_train)
# 预测输出结果
score=reg.score(X_test,y_test)
learning=[(8,0.9)]
result=reg.predict_proba(learning)
msg='''模型得分:{0}
复习时长:{1[0]},效率为:{1[1]}
您不及格的概率为:{2[0]}
您及格的概率为:{2[1]}
综合判断,您会:{3}'''.format(score,
learning[0],
result[0],
'不及格'if result[0][0]>0.5 else '及格')
print(msg)
"""
模型得分:0.8333333333333334
复习时长:8,效率为:0.9
您不及格的概率为:0.2979375631448309
您及格的概率为:0.7020624368551691
综合判断,您会:及格
"""
4.6 聚类
将一群物理的或抽象的对象,根据它们之间的相似程度,分为若干组,其中相似的对象构成一组,这一过程称为聚类。聚类(Clustering)是根据物以类聚的原理,对未知类别标签的数据对象分组,使得组与组之间的相似度尽可能小,而组内数据之间的相似度较大。与分类算法不同,聚类的输入数据没有类别标签,产生的聚类结果中类别标签也是未知的。聚类没有预测功能,属于非监督学习算法。
K-Means (K均值)算法是最著名的划分聚类算法,在数据预处理时使用较多,常用来精简和压缩数据。K-means聚类算法的基本思想是,首先在样本空间中随机选取k个样本点作为初始聚类中心,然后分别计算其余样本到所有聚类中心的距离,把样本归到离它最近的那个聚类中心所在的类。通过求各个类中样本的均值或其它方法确定新的聚类中心;,重复上述过程,直到样本不会被重新分配类别或者聚类中心不再发生变化为止。
K-Means算法的关键在于类别个数K值的确定以及初始聚类中心和距离计算公式的选择。该算法擅长处理球状分布的数据,当类和类之间的区别比较明显时,K均值的效果比较好。缺点是K均值对噪声数据和孤立点数据敏感,数据量巨大时算法的时间开销太大。
扩展库sklearn.cluser的**KMeans()**函数用于实现K-Means算法,其语法格式如下:
sklearn.cluster.KMeans(self,n_clusters=8,init='K-means++',n_init=10,max_iter=300,tol=0.001,precompute_distances='auto',verbose=0,random_state=None,copy_x=True,n_jobs=1,algorithm=' auto’)
| 参数名称 | 说明 |
|---|---|
| n_clusters | 指定生成的聚类个数,对应算法的k值,整型,默认值为8。 |
| init | 设置初始化聚类中心的方法,可选值为’k-means++'、'random’或者ndarray向量。默认值’k-means++'表示选择相距尽可能远的初始聚类中心以加速算法收敛; 'random’表示从训练数据随机选取初始聚类中心;若传递的是一个ndarray对象,则以(n_clusters,n_features)的形式显式设置初始聚类中心。 |
| n_init | 设置使用不同初始聚类中心运行算法的次数,最终结果为n_init次连续运行得到的最优输出,接收整型数据,默认值为10。 |
| max _iter | 单次执行k-means算法的最大迭代次数,整型,默认值为300。 |
| precompute_distances | 设置预计算距离的方式,这个参数会权衡算法的空间和时间复杂度,值True总是预计算距离;值auto默认在样本数乘以聚类数大于1200万则不预计算距离;值False表示永不预计算距离。 |
| algorithm | 设置k-means算法实现方式,值’elkan’表示使用三角不等式获得更高性能;值’full’使用期望值最大化算法;值’auto’表示密集数据自动选择’elkan’,稀疏数据自动选择’full’。 |
# 使用KMeans压缩图像颜色
import numpy as np
from sklearn.cluster import KMeans
from PIL import Image
import matplotlib.pyplot as plt
# 读取图像像素颜色值并转换为二维数组
imorign=Image.open('work/颜色压缩测试图像.jpg')
dataorigin=np.array(imorign)
data=dataorigin.reshape(-1,3)
# 使用KMeans聚类算法将所有像素的颜色值划分为4类
clf=KMeans(n_clusters=4)
clf.fit(data)
temp=clf.labels_ #存储样本标签
datanew=clf.cluster_centers_[temp]
datanew.shape=dataorigin.shape
plt.imshow(datanew/255)
plt.imsave('结果图.jpg',datanew/255)


4.7 回归
回归分析是一种预测性的建模技术,它所研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析、时间序列模型以及发现变量之间的因果关系,包括自变量和因变量之间的显著关系,多个自变量对一个因变量的影响强度等。
4.7.1 线性回归
线性回归通常是预测模型的首选技术之一。线性回归使用最佳的拟合直线(即回归线)在因变量和一个或多个自变量之间建立关系,其中因变量是连续的,自变量可以是连续的也可以是离散的,回归线是线性的。
简单线性回归模型可以表示为Y=a+b*X+e,其中a表示截距,b表示直线的斜率,e是误差项。该模型可以根据给定的预测变量来预测目标变量的值。在大多数回归问题中,参数a、b的值以及误差的方差是未知的,需要通过样本数据进行评估。通常情况下使用最小二乘法估计回归方程中的回归系数,使用残差来衡量模型与样本点的拟合度,这里回归方程即回归模型拟合,残差定义为因变量的实际值与模型预测的值之间的差异。
线性回归模型的使用要点:该算法对异常值非常敏感;使用线性回归模型的自变量与因变量之间必须要有线性关系;在多个自变量的情况下,可以使用向前选择法,向后剔除法和逐步筛选法来选择最重要的自变量。
通常使用扩展库sklearn.linear_model中的LinearRegression()函数实现线性回归模型,语法格式如下:
sklearn.linear_model.LinearRegression(fit_intercept=True,normalize=False,copy_X=True, n_jobs=1)
# 参数fit_intercept:指定是否需要为模型添加截距项。默认值True表示训练模型需要加一个截距项;若参数值为False,表示模型无需添加截距项;
# 参数normalize:指定是否对数据进行标准化处理。默认值False表示训练模型之前,可以使用sklearn.preprocessing.StandardScaler进行数据标准化处理;当参数fit_intercept设置为False时,参数normalize无需设置;若normalize=True,则对输入的样本数据标准化,即减去平均值,并且除以相应的L2范数。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets , linear_model
from sklearn.metrics import mean_squared_error , r2_score
from sklearn.model_selection import train_test_split
#加载糖尿病数据集
diabetes = datasets.load_diabetes()
X = diabetes.data[:,np.newaxis ,2] #diabetes.data[:,2].reshape(diabetes.data[:,2].size,1)
y = diabetes.target
X_train , X_test , y_train ,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
LR = linear_model.LinearRegression()
LR.fit(X_train,y_train)
print('截距项intercept_:%.3f' % LR.intercept_)
print('回归系数(斜率)coef_:%.3f' % LR.coef_)
print('Mean squared error: %.3f' % mean_squared_error(y_test,LR.predict(X_test)))##((y_test-LR.predict(X_test))**2).mean()
print('Variance score: %.3f' % r2_score(y_test,LR.predict(X_test))) #(y_test-LR.predict(X_test))**2).sum()/((y_test - y_test.mean())**2).sum()
print('score: %.3f' % LR.score(X_test,y_test))
plt.scatter(X_test , y_test ,color ='green')
plt.plot(X_test ,LR.predict(X_test) ,color='red',linewidth =3)
plt.show()
"""
截距项intercept_:152.003
回归系数(斜率)coef_:998.578
Mean squared error: 4061.826
Variance score: 0.233
score: 0.233
"""

diabetes = datasets.load_diabetes()
X = diabetes.data[:,np.newaxis ,2] #diabetes.data[:,2].reshape(diabetes.data[:,2].size,1)
y = diabetes.target
X_train , X_test , y_train ,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
LR = linear_model.LinearRegression(fit_intercept=False)
LR.fit(X_train,y_train)
print('截距项intercept_:%.3f' % LR.intercept_)
print('回归系数(斜率)coef_:%.3f' % LR.coef_)
print('Mean squared error: %.3f' % mean_squared_error(y_test,LR.predict(X_test)))##((y_test-LR.predict(X_test))**2).mean()
print('Variance score: %.3f' % r2_score(y_test,LR.predict(X_test))) #(y_test-LR.predict(X_test))**2).sum()/((y_test - y_test.mean())**2).sum()
print('score: %.3f' % LR.score(X_test,y_test))
plt.scatter(X_test , y_test ,color ='green')
plt.plot(X_test ,LR.predict(X_test) ,color='red',linewidth =3)
plt.show()
"""
截距项intercept_:0.000
回归系数(斜率)coef_:1116.799
Mean squared error: 27774.612
Variance score: -4.242
score: -4.242
"""
diabetes = datasets.load_diabetes()
X = diabetes.data[:,np.newaxis ,2] #diabetes.data[:,2].reshape(diabetes.data[:,2].size,1)
y = diabetes.target
X_train , X_test , y_train ,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
LR = linear_model.LinearRegression(fit_intercept=True, normalize=False,copy_X=True, n_jobs=1)
LR.fit(X_train,y_train)
print(X_train[:5])
print('截距项intercept_:%.3f' % LR.intercept_)
print('回归系数(斜率)coef_:%.3f' % LR.coef_)
print('Mean squared error: %.3f' % mean_squared_error(y_test,LR.predict(X_test)))##((y_test-LR.predict(X_test))**2).mean()
print('Variance score: %.3f' % r2_score(y_test,LR.predict(X_test))) #(y_test-LR.predict(X_test))**2).sum()/((y_test - y_test.mean())**2).sum()
print('score: %.3f' % LR.score(X_test,y_test))
plt.scatter(X_test , y_test ,color ='green')
plt.plot(X_test ,LR.predict(X_test) ,color='red',linewidth =3)
plt.show()
"""
[[ 0.01211685]
[-0.01806189]
[ 0.04984027]
[-0.03530688]
[-0.06548562]]
截距项intercept_:152.003
回归系数(斜率)coef_:998.578
Mean squared error: 4061.826
Variance score: 0.233
score: 0.233
"""

4.7.2 多项式回归
实际应用中,使用线性模型有时无法很好地拟合数据,这时可以尝试曲线拟合。根据数学相关理论,任何曲线都可以使用多项式进行逼近,这就是多项式回归(Ploynomial Regression)的理论基础。
研究一个因变量与一个或多个自变量间多项式的回归分析方法,称为多项式回归(Polynomial Regression)。如果自变量只有一个,称为一元多项式回归;如果自变量有多个,称为多元多项式回归。在一元回归分析中,如果因变量与自变量的关系为非线性的,但是又找不到适当的函数曲线来拟合,则可以采用一元多项式回归。
多项式回归是线性回归模型的一种,此时回归函数关于回归系数是线性的。一般来说,需要事先判断模型的可能形式,再决定使用何种模型处理数据。一般情况下,通过绘制散点图大致判断。例如,如果数据的散点图有一个“弯”,可以考虑使用二次多项式回归;若有两个“弯”则可以考虑使用三次多项式,以此类推。真实函数不一定是某个多项式,但是只要拟合得好,用适当的多项式来近似模拟真实的回归函数是可行的。
多项式回归和线性回归的思路以及优化算法是一致的。在线性回归的基础上,多项式回归在原来数据集的维度特征上增加一些新的多项式特征,使得原始数据集的维度增加,然后基于升维后的数据集用线性回归的思路求解,得到相应的预测结果和各项的系数。作为线性回归方式的一种特例,多项式回归模型在sklearn机器学习库中没有定义专门的函数,用户可以使用sklearn.linear_model.LinearRegression()函数自己定义多元线性回归的实现方式。
import numpy as np
import matplotlib.pyplot as plt
x = np.random.uniform(-3,3,size=100)
X = x.reshape(-1,1)
# 一元二次方程
y = 0.5*x**2 + x + 2+np.random.normal(0,1,size=100)
plt.scatter(x,y)

from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X,y)
y_predict = lin_reg.predict(X)
plt.scatter(x,y)
plt.plot(X,y_predict,color='r')
plt.show()

X2 = np.hstack([X,X**2])
print(X2)
lin_reg2 = LinearRegression()
lin_reg2.fit(X2, y)
y_predict2 = lin_reg2.predict(X2)
plt.scatter(x, y)
# 由于x是乱的,所以应该进行排序
plt.plot(np.sort(x), y_predict2[np.argsort(x)], color='r')
plt.show()

5 数据预处理
数据预处理包括数据标准化、数据归一化、数据二值化、非线性转换、数据特征编码以及处理缺失值等。数据预处理的工具有许多,除了扩展库pandas提供了简单的数据预处理功能,机器学习库scikit-learn的preprocessing模块提供了多种数据预处理的类,用于数据的标准化、正则化、缺失数据的填补、类别特征的编码以及自定义数据转换等数据预处理操作。
5.1 数据标准化
数据标准化是对数据集中数据的一种预处理操作,它使得特征的分布满足标准正态分布,避免某些特征影响算法的学习和收敛。如果数据集中某些特征数据的方差过大,就会主导目标函数从而使模型无法正确地学习其他特征。数据标准化有助于去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标进行比较和加权,避免数据的偏差与跨度影响机器学习的性能。
数据标准化是许多机器学习模型训练的常见要求:如果单个特征看起来不像标准正态分布数据,即均值为0的高斯分布和单位方差,那么模型的性能可能会很差。将特征数据的分布调整成标准正态分布,使得特征数据的均值为0,方差为1再参与模型训练,可以达到加速收敛的效果,有效提升机器学习的效率。
扩展库sklearn的preprocessing模块提供了两种数据标准化实现方式,一是调用sklearn.preprocessing.scale()函数,二是实例化一个sklearn.preprocessing.StandardScaler()对象。
5.1.1 使用scale()函数实现数据标准化
基于sklearn.preprocessing.scale()函数的数据标准化适用于不区分训练集与测试集的一次性变换,语法格式如下:
scale(x,axis=O, with_mean=True, with_std=True, copy=True)[source]
# 参数X表示待处理的数组;
# 参数axis指定处理的维度,默认值为0表示处理行数据,当axis=1时表示处理列数据;
# 参数with_mean=True表示使均值为0;
# 参数with_std=True表示使标准差为1。
from sklearn import preprocessing
import numpy as np
X = np.array([[5., -1., 2.], [2., 51., 37.], [0., 9., -10.]])
X_scaled = preprocessing.scale(X, axis=0)
print('scaled之后:',X_scaled)
# scaled之后的数据零均值,单位方差
print('scaled之后 均值=',X_scaled.mean(axis=0)) # column mean: array([ 0., 0., 0.])
print('scaled之后 方差=',X_scaled.std(axis=0)) # column standard deviation: array([ 1., 1., 1.])
"""
scaled之后: [[ 1.29777137 -0.91733643 -0.38451003]
[-0.16222142 1.3908004 1.37086183]
[-1.13554995 -0.47346396 -0.9863518 ]]
scaled之后 均值= [-7.40148683e-17 -3.70074342e-17 1.11022302e-16]
scaled之后 方差= [1. 1. 1.]
"""
5.1.2 使用StandardScaler()实现数据标准化
基于sklearn.preprocessing.StandardScaler进行数据标准化,计算并保存训练集的平均值和标准差,以便使用相同的参数对测试数据进行变换。调用方式为:
ss = sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True)
# 其中参数copy、with_mean和with_std的默认值都是True。如果copy =False表示用标准化的值替代原来的值; with_mean=False表示不需要均值中心化; with_std=False表示不需要方差单位化为1。
from sklearn.preprocessing import StandardScaler
data = [[5, 78], [3, 9], [1277, 5691], [43, 21]]
scaler = StandardScaler()
print(scaler.fit(data)) # 调用fit方法,根据已有的训练数据创建一个标准化的转换器
"""
StandardScaler(copy=True, with_mean=True, with_std=True)
"""
print(scaler.mean_)
print(scaler.transform(data)) # 使用上面这个转换器去转换数据data,调用transform方法
"""
[ 332. 1449.75]
[[-0.59908902 -0.56016648]
[-0.60275318 -0.58834325]
[ 1.73131232 1.73195267]
[-0.52947012 -0.58344294]]
"""
5.2 数据归一化
数据归一化是将样本的特征值转换到同一量纲下,把数据映射到[0.,1]或者[-1,1]区间内。数据归一化仅由变量的极值决定,最常见的归一化方法就是Min-Max归一化,将原始数据映射到[0.,1]区间,消除量纲的影响。数据标准化是依照特征矩阵的列处理数据,通过求z-score的方法,转换为标准正态分布。数据标准化和整体样本分布相关,每个样本点都能对标准化产生影响。二者的相同点在于都能取消量纲不同引起的误差;都是一种线性变换,都是对向量X按照比例压缩再进行平移。
扩展库sklearn的preprocessing模块提供了数据归一化的实现方法,可以通过MinMaxScaler()将数据特征缩放至[0,1]范围内,或者使用MaxAbsScaler()将特征归一化到[-1,1]区间内,二者实现原理相似。
MinMaxScaler()默认是对每一列做数据归一化操作,这也是实际应用的需求。需要注意归一化操作需要先对训练集进行,然后再对测试集进行。在测试集上的scaler和训练集上的scaler要保持一致,不能在训练集和测试集分别使用不同的scaler。
# 特征范围归一化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
# 在训练集上进行归一化
X_train_scaled = scaler.fit_transform(X_train)
# 在测试集上使用相同的scaler进行归一化
X_test_scaled = scaler.transform(X_test)
5.3 数据正则化
数据正则化是将样本在向量空间模型上的一个转换,经常用在分类与聚类中。当训练数据量不足或者过度训练时,常常会导致过拟合(overfitting),致使模型失去了泛化能力,表现为模型在训练数据上效果非常好,但是在测试数据或验证数据上表现很差。数据正则化就是在此时向原始模型引入额外信息,以便防止过拟合和提高模型泛化能力的一类方法。
造成过拟合的原因可能是训练数据过少,或者模型过于复杂。对于后者,可以通过数据正则化的方法降低模型的复杂度以提高模型的泛化能力。实际上,正则化控制模型的复杂度,模型复杂度越高,越容易过拟合。数据正则化方法通过向目标函数添加一个正则化项来降低模型的复杂度。
扩展库sklearn的processing模块提供了两种数据正则化的实现方法
# 使用normalize()函数实现数据正则化 对一个单向量进行数据正则化
from sklearn import preprocessing
import numpy as np
# 创建一组特征数据,每一行表示一个样本,每一列表示一个特征
x = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
x_normalized = preprocessing.normalize(x, norm='l2')
print(x_normalized)
"""
[[ 0.40824829 -0.40824829 0.81649658]
[ 1. 0. 0. ]
[ 0. 0.70710678 -0.70710678]]
"""
# 使用Normalizer实现数据正则化
# 使用实用类Normalizer,通过transform方法可以对新数据进行向量空间模型上的转换,实现数据正则化
from sklearn.preprocessing import Normalizer
# 根据训练数据创建一个正则器
normalizer = preprocessing.Normalizer().fit(x)
# 对训练数据进行正则
normalizer.transform(x)
5.4 数据二值化
数据二值化是指将数值型的特征数据转换成布尔类型的值。可以使用sklearn.preprocessing模块提供的类Binarizer,默认根据0进行二值化,大于0的标记为1,小于等于0的标记为0。也可以设置阀值参数threshold,根据阈值将数据二值化,大于阈值的值映射为1,而小于或等于阈值的值映射为0,常用于处理连续型变量。
from sklearn import preprocessing
import numpy as np
x = np.array([-1,-2,0,1,2]).reshape(-1,1)
binarizer = preprocessing.Binarizer().fit(x)
binarizer.transform(x)
"""
array([[0],
[0],
[0],
[1],
[1]])
"""
5.5 缺失值处理
扩展库scikit-learn中的模型假设输入的数据都是数值型的,并且是有意义的。如果数据集中包含缺失值NAN或者空值的话,就无法识别与计算。一般来说,可以使用均值、中位数或众数等弥补缺失值。
sklearn.preprocessing模块提供的类Simplelmputer可以用于缺失值处理。
import numpy as np
from sklearn import preprocessing
from sklearn.impute import SimpleImputer as Imputer
imp = Imputer()
imp.fit([[1, 2], [np.nan, 3], [7, 6]])
x = [[np.nan, 2], [6, np.nan], [7, 6]]
imp.transform(x)
"""
array([[4. , 2. ],
[6. , 3.66666667],
[7. , 6. ]])
"""
6 模型调参
机器学习模型的参数可以分为两种,第一种是模型自身的参数,可以通过训练样本学习得到,如逻辑回归的参数、神经网络的权重及偏置等;第二种是超参数,是在建立模型时用于控制算法行为的参数,这些参数不能从常规训练过程中获得,如KNN中的初始值个数k和SVM中的正则项系数C等。在模型训练之前,需要对超参数赋值。
模型调参就是为模型找到最好的超参数。机器学习模型的性能与超参数直接相关。超参数调优越好,得到的模型就越好。实际应用中,通常依靠经验设定超参数,也可以依据实验获得。模型训练过程中,可以从训练集中单独留出一部分样本集,用于调整模型的超参数和对模型性能进行初步评估,称之为验证集。
6.1 交叉验证
在实际训练中,模型训练的结果对训练集的拟合程度通常很好,但是对于训练集之外的数据拟合程度可能就差强人意了。因此人们通常不会把所有的数据集都用于模型训练,而是单独留出一部分样本集对训练集生成的参数进行测试,相对客观地判断这些参数对训练集之外的数据拟合程度。这种方法称为交叉验证(Cross Validation)。交叉验证的基本思想是在某种意义下将原始数据集进行分组,一部分作为训练集,另一部分作为验证集,首先用训练集进行模型训练,再利用验证集来测试训练得到的模型,以此作为评价模型的性能指标。
扩展库sklearn的model_selection子模块提供了cross_val_score函数对数据集进行指定次数的交叉验证,并对每次的验证效果进行评测。其语法格式为:
cross val score(eatimator,X,y=None,groups=None,scoring=None,cv=None,n_jobs=1,verose=0,fit_ params=None,pre_fispatch='2*n_jobs')
# 参数eatimator指定要评估的模型
# 参数X和y指定数据集及对应的标签;
# 参数scoring:指定交叉验证的评价方法,具体可用的评价指标可以登录网址https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter,查看官方的详细解释;
# 参数cv指定交叉验证折数或可迭代次数,设置为整数时表示把数据集拆分成几个部分对模型进行训练和评分,也可以设置为随机划分或逐一测试等策略。例如,当cv=5时表示采用5折交叉验证策略,其中训练集的1/5作为验证数据,4/5作为训练数据,循环进行了5次训练后得到5个评价指标,将这5个评价指标的均值作为模型的评价指标。
# 引入包
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
# 加载数据
iris_data = pd.read_csv('work/iris.csv')
# 获取特征
X = iris_data[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']].values
# 获取标签
y = iris_data['label'].values
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/3, random_state=10)
# 交叉验证
from sklearn.model_selection import cross_val_score
# K近邻距离算法
k_list = [1, 3, 5, 7, 9]
for k in k_list:
knn_model = KNeighborsClassifier(n_neighbors=k)
val_scores = cross_val_score(knn_model, X_train, y_train, cv=3)
val_score = val_scores.mean()
print('k={}, acc={}'.format(k, val_score))
"""
k=1, acc=0.9402852049910874
k=3, acc=0.960190136660725
k=5, acc=0.960190136660725
k=7, acc=0.9500891265597149
k=9, acc=0.9500891265597149
"""
该函数返回浮点型元素的数组,数组中的浮点型元素表示每次的评价结果。实际应用中往往将k次评价指标的平均值作为模型最终的评价结果。
# 选择最优参数,重新训练模型
best_knn = KNeighborsClassifier(n_neighbors=3)
best_knn.fit(X_train, y_train)
# 测试模型
print(best_knn.score(X_test, y_test))
"""
0.96
"""
6.2 网格搜索
网格搜索(GridSearchCV)是一种自动调整参数的方式,只要把参数输进去,就能给出最优化的结果和参数。这个方法适用于小数据集和需要调试多个超参数的情况,是一种指定参数值的穷举搜索方法。首先将各个参数可能的取值排列组合,通过循环遍历尝试每一种可能,列出所有可能的参数组合以生成“网格”;然后将每个参数组合用于模型训练,并使用交叉验证对模型表现进行评估;在拟合函数尝试了所有的参数组合之后,返回一个合适的模型,并自动调整至最佳参数组合。
扩展库sklearn的model_selection模块中GridSearchCV类用于网格搜索调参,通过模型训练求出所需的最佳参数。其语法格式如下:
sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, cv=None, fit_params=None,n_jobs=1, iid=True, refit=True, verbose=0, pre_dispatch= '2*n jobs', error_score=' raise',return_train_score=' warn')
# 参数estimator 指定待选择参数的模型;
# 参数param_grid:指定需要测试的参数,为字典或列表类型,其中每个元素是超参数;
# 参数scoring:指定模型评价标准,取值为字符串函数名或者可调用对象,如果取默认值None,表示使用estimator的误差估计函数;
# 参数cv:指定交叉验证划分策略,取值可以为整数,用于指定交叉验证折数或可迭代次数;取值为None表示默认使用3折交叉验证;
# 参数refit:默认值为True,表示用交叉验证训练集得到的最佳参数对所有可用的训练集与测试集自动重新训练,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再学习一遍全部数据集。
from sklearn.model_selection import GridSearchCV
params = {'n_neighbors': [1, 3, 5, 7, 9]}
knn = KNeighborsClassifier()
clf = GridSearchCV(knn, params, cv=3)
clf.fit(X_train, y_train)
# 最优参数
clf.best_params_
# 最优模型
# 注意:GridSearchCV默认会使用最优的参数自动重新训练,所以不需要手工操作(refit=True)
best_model = clf.best_estimator_
# 测试模型
print(best_model.score(X_test, y_test))
"""
0.96
"""