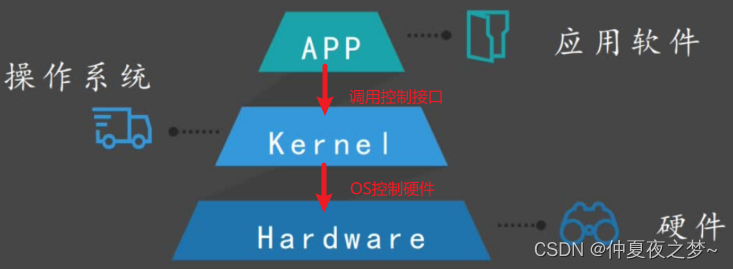
Abstract
短镜头字体生成(FFG)方法必须满足两个目标:生成的图像既要保留目标字符的底层全局结构,又要呈现多样化的局部参考风格。现有的FFG方法旨在通过提取通用表示样式或提取多个组件样式表示来分离内容和样式。然而,以往的方法要么无法捕捉不同的本地风格,要么无法推广到具有看不见的组件的字符,例如看不见的语言系统。为了缓解这些问题,我们提出了一种新的FFG方法,称为多本地化专家少镜头F - ont生成网络(MXF - ont)。MX-F ont提取多种风格特征,而不是明确地以组件标签为条件,而是由多个专家自动表示不同的局部概念,如左侧子字形。由于专家多,MX-F ont可以捕捉到不同的本地概念,并显示出对未知语言的普遍性。在培训过程中,我们利用组件标签作为弱监督,引导每个专家针对不同的局部概念进行专门化。我们将每个专家的分量分配问题表述为图匹配问题,并采用匈牙利算法进行求解。我们还采用了独立性损失和内容风格对抗性损失来实现内容风格的解缠。在我们的实验中,MX-F ont在中文代和跨语言(如中文到韩语)代中优于之前最先进的FFG方法。源代码可在https://github.com/clovaai/mxfont
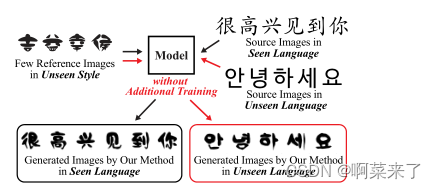
图1。MXFont的跨语言少镜头字体生成结果。本文提出的方法MX-Font只需要4个参考,就可以生成高质量的字体库。此外,我们首先展示了所提出的方法在零镜头跨语言少镜头生成任务上的有效性,即使用中文字体生成模型生成看不见的韩语字形。