embedding_model 是什么:
嵌入式模型(Embedding)是一种广泛应用于自然语言处理(NLP)和计算机视觉(CV)等领域的机器学习模型,它可以将高维度的数据转化为低维度的嵌入空间(embedding space),并保留原始数据的特征和语义信息,从而提高模型的效率和准确性。本文将对嵌入式模型进行详细的介绍,包括其背景、原理、应用和常见类型等方面。
Embedding常用于将文本数据映射为固定长度的实数向量,从而使计算机能够更好地处理和理解这些数据。每个单词或句子都可以用一个包含其语义信息的实数向量来表示。
为什么使用embedding_model :
它能够将高维度的数据转化为低维度的嵌入空间,并保留原始数据的特征和语义信息,从而提高模型的效率和准确性。
能使用 SentenceTransformer 调用的模型
我们现在 魔塔社区查看到的 embedding_model类型模型:
通常情况embedding_model模型的核心目录如下:
text2vec-base-chinese-sentence/
├── 0_Transformer/
├── 1_Pooling/
├── 2_Normalize/
├── config.json
├── config_sentence_transformers.json
├── modules.json
└── pytorch_model.bin
我们这里以 text2vec-base-chinese 模型为例:
一种是huggingFace 格式模型

一种是带有 -sentence 后缀的模型;
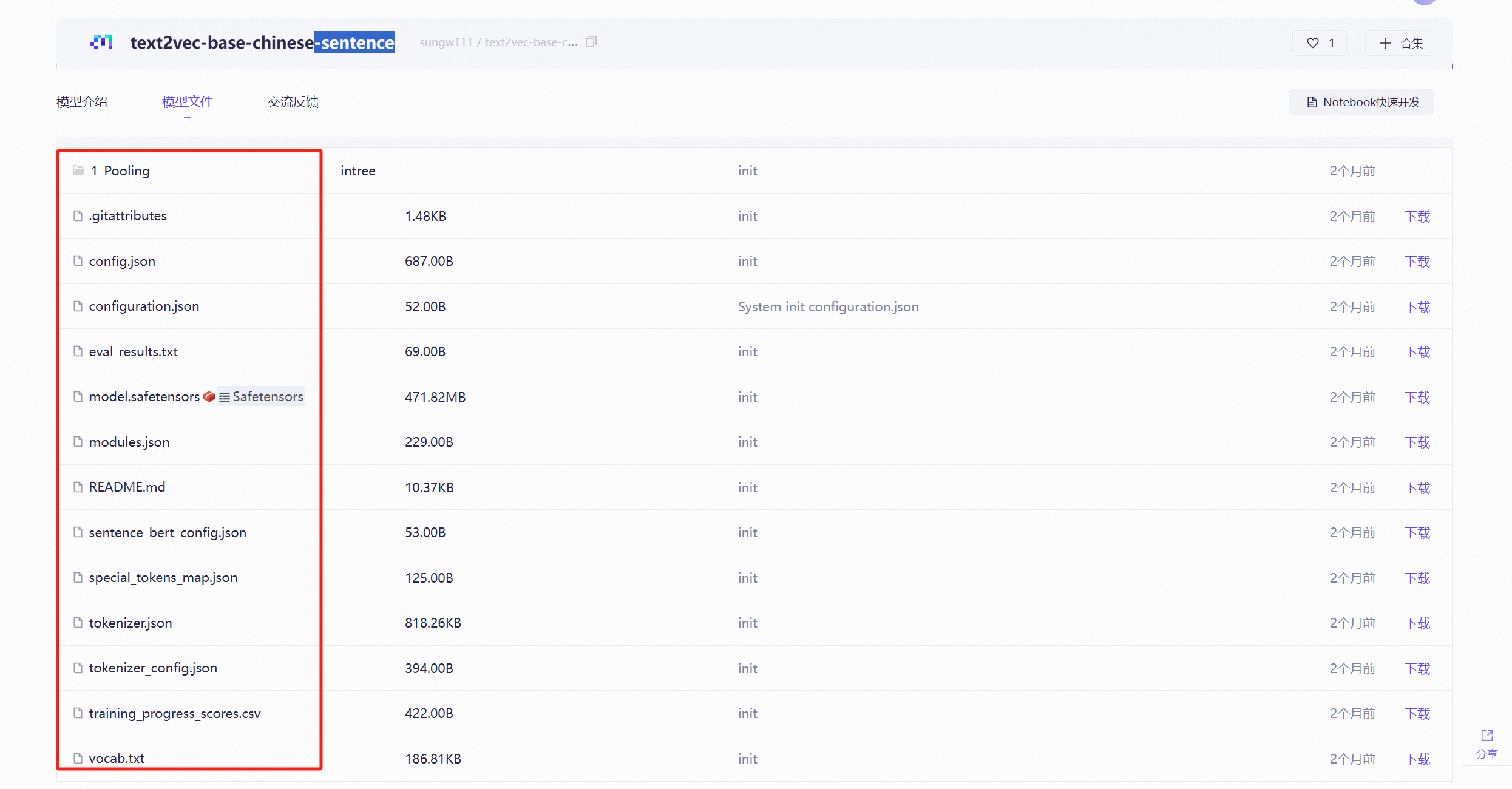
可以看出这个两种格式的模型所包含的文件都是不同的;带有-sentence 后缀的模型中有1_Pooling文件
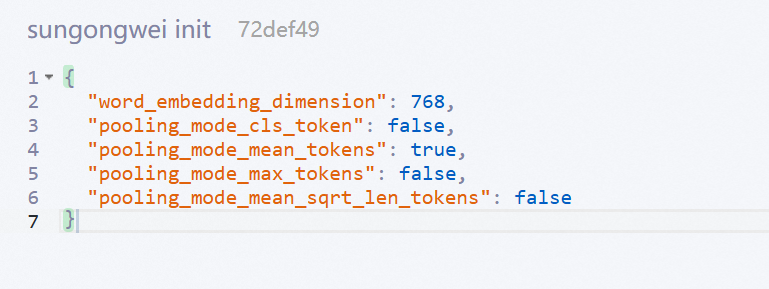
这文件中定义了模型的调用方式;当我们使用 SentenceTransformer 调用 huggingFace 格式模型是后报错所无法找到模型;需要指定的模型为sentence 格式的模型;
这里说的带-sentence 后缀是我这里使用 text2vec-base-chinese模型时举例使用的, 有的模型上传时文件名后缀也没有添加sentence后缀, 主要区分方式是看模型文件中是否有 1_Pooling 文件;有九八说明是sentence 格式的模型,可以使用 SentenceTransformer 调用;
embedding_model模型不带有归一化层怎么处理
embedding_model通常情况是自带有归一化层的。一般可以通过Normalize目录或者modules.json来
判断是否准确包含归一化层。如果未包含归一化层,则需要手动转换添加:
import numpy as np
from sentence_transformers import SentenceTransformer,models
model_path = r"D:ai_model\text2vec-
base-chinese-sentence"
bert = models.Transformer(model_path)
pooling = models.Pooling(bert.get_word_embedding_dimension(),
pooling_mode='mean')
# 添加缺失的归一化层
normalize = models.Normalize()
# 组合完整模型
full_model = SentenceTransformer(modules=[bert, pooling, normalize])
print(full_model)
save_path=r"D:ai_model\text2vec-base-chinese-sentence"
full_model.save(save_path)
# 加载修复后的模型
model =SentenceTransformer(r"D:ai_model\text2vec-base-chinese-sentence")
# 验证向量归一化
text = "测试文本"
vec = model.encode(text)
print("修正后模长:", np.linalg.norm(vec)) # 应输出≈1.0
转换后的modules.json如下
[
{
"idx": 0,
"name": "0",
"path": "",
"type": "sentence_transformers.models.Transformer"
},
{
"idx": 1,
"name": "1",
"path": "1_Pooling",
"type": "sentence_transformers.models.Pooling"
},
{
"idx": 2,
"name": "2",
"path": "2_Normalize",
"type": "sentence_transformers.models.Normalize"
}
]