文章目录
- 单调栈
- 总结
- 子序列问题
- 总结
- 编辑距离问题
- 总结
- 回文串问题
- 总结
- MySQL 执行流程是怎样的?
- 第一步:连接器
- 第二步:查询缓存
- 第三步:解析器 解析SQL
- 第四步:执行 SQL
- 2.2 MySQL 一行记录是怎么存储的?
- MySQL 的数据存放在哪个文件?
- 表空间文件的结构是怎么样的?
- InnoDB行格式有哪些?
- varchar(n)中n最大取值为多少?
- SDS
单调栈
| 题目 | 关键点 |
|---|---|
| 739. 每日温度 - 力扣(LeetCode) | 单调递增栈、存放下标 |
| 496. 下一个更大元素 I - 力扣(LeetCode) | 栈、Map |
| 503. 下一个更大元素 II - 力扣(LeetCode) | 栈、取模n、下标 |
| 42. 接雨水 - 力扣(LeetCode) | 备忘录解法、单调递增栈 |
| 84. 柱状图中最大的矩形 - 力扣(LeetCode) | 单调栈递减、弹出栈操作 |
-
739. 每日温度 - 力扣(LeetCode)
本题可以使用单调递增栈(栈头—>栈尾)。使用递增栈,顺序遍历数组放入栈中,在气温更高的时候,弹出之前气温低的一天,在弹出过程中,可以进行操作,比如返回更高的气温。本题要求返回与更高气温的相距天数,所以可以在栈中保存下标,更方便计算天数。
class Solution { public int[] dailyTemperatures(int[] temperatures) { Stack <Integer> stack= new Stack <Integer>(); int count = 0 ; int n = temperatures.length; int [] ans = new int [n]; /** 保持栈中元素为单调递增。(从栈头——栈尾) */ stack.push(0); for(int j = 1 ; j < n ; j ++){ int temp = temperatures[j]; if(temp <=temperatures[stack.peek()] ){ stack.push(j); }else{ while(!stack.empty() && temp > temperatures[stack.peek()] ){ int i = stack.pop(); ans[i] = j - i; } stack.push(j); } } return ans; } } -
496. 下一个更大元素 I - 力扣(LeetCode)
简化本题,就是要找到nums2数组中的下一个更大元素。自然联想到使用单调递增栈(栈头—>栈尾),基本逻辑与739. 每日温度 - 力扣(LeetCode)一致。但是本题需要多考虑一点,就是如何将nums1和nums2联系起来。我们使用Map这种数据结构,保存K-V,将nums1[i]与i映射。value的目的是在返回值时快速定位到下标,而key的作用是在弹出元素时,比较nums2中是否出现了nums1中的元素。
class Solution { public int[] nextGreaterElement(int[] nums1, int[] nums2) { Stack <Integer> stack = new Stack<>(); int n = nums1.length; int m = nums2.length; int [] ans = new int [n]; Map <Integer,Integer> map = new HashMap <>(); for(int i = 0 ; i < n ; i ++){ map.put(nums1[i] , i); } Arrays.fill(ans , -1); for(int i = 0 ; i < m ; i ++){ if(stack.empty()){ stack.push(nums2[i]); //比当前栈中数小的数字,维持单调递增性,直接入栈。 }else if(nums2[i] <= stack.peek()){ stack.push(nums2[i]); }else{ //找到了下一个更大的元素。 while(!stack.empty() && nums2[i] > stack.peek()){ int num = stack.pop(); //如果map中有这个数字,说明存在与nums1中. if(map.containsKey(num)){ ans[map.get(num)] = nums2[i]; } } stack.push(nums2[i]); } } return ans; } } -
503. 下一个更大元素 II - 力扣(LeetCode)
取模/多复制一份数组,这里只演示取模的效果(循环次数改为原来的二倍)。
这里的单调栈同样存放下标,方便确定返回值的下标。
class Solution { public int[] nextGreaterElements(int[] nums) { int n = nums.length; Stack <Integer> stack = new Stack <>(); int [] ans = new int [n]; Arrays.fill(ans , -1); for(int i = 0 ; i < n * 2 - 1 ; i ++){ if(!stack.empty() && nums[stack.peek()] >= nums[i % n]){ stack.push( (i % n) ); }else { while(!stack.empty() && nums[stack.peek()] < nums[i % n]){ int index = stack.pop(); ans[index] = nums[i % n]; } stack.push((i % n)); } } return ans; } } -
42. 接雨水 - 力扣(LeetCode)
备忘录解法:我们创建两个备忘录,
l_max表示 i 左边的最高高度 。r_max表示 i 右边的最高高度。最终,所盛水的总高度取决于两边的最低高度减去当前位置的高度。即:
Math.min(l_max[i],r_max[i]) - height[i]class Solution { public int trap(int[] height) { int sum = 0; int n = height.length; int l_max [] = new int [n]; int r_max [] = new int [n]; l_max[0] = height[0]; r_max[n - 1] = height[n - 1]; for(int i = n - 2 ; i > 0 ; i --){ r_max[i] = Math.max(r_max[i + 1] , height[i]); } for(int i = 1 ; i < n ; i ++){ l_max[i] = Math.max(l_max[i - 1] , height[i]); } for(int i = 1 ;i < n - 1 ; i ++){ sum += Math.min(l_max[i] , r_max[i]) - height[i]; } return sum; } }单调栈解法:
本题可以使用单调递增栈(栈头—>栈尾)。在弹出较小的值时(表示可以装水),计算弹出值下标的装水量。
class Solution { public int trap(int[] height) { int ans = 0; int n = height.length; Stack <Integer> s = new Stack<>(); s.push(0); for(int i = 1 ; i < n ; i ++){ if(height[s.peek()] >= height[i]){ s.push(i); }else { while(!s.empty() && height[s.peek()] < height[i]){ int right = i; int mid = height[s.pop()]; if(!s.empty()){ int left = s.peek(); int h = Math.min(height[left] , height[right]) - mid; int w = right - left - 1; ans += w * h; } } s.push(i); } } return ans; } } -
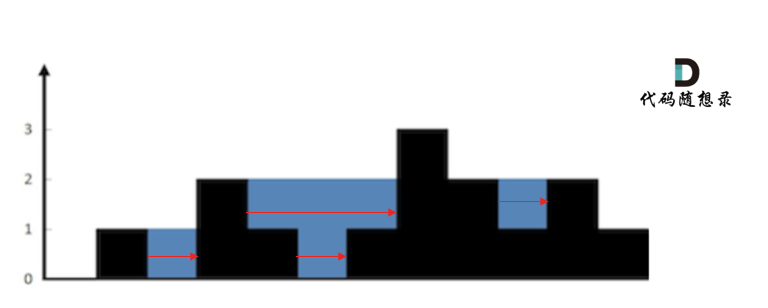
84. 柱状图中最大的矩形 - 力扣(LeetCode)
因为要求最大的矩形,所以当放入栈中的元素小于栈顶元素时,应该计算栈顶元素的最大面积,所以使用单调递减的栈(栈头—>栈尾)。栈顶和栈顶的下一个元素以及要入栈的三个元素组成了我们要求最大面积的高度和宽度
class Solution { public int largestRectangleArea(int[] heights) { //在元素头尾各加一个0,来排除全部升序、降序的情况。 int [] newHeights = new int[heights.length + 2]; newHeights[0] = 0; newHeights[newHeights.length - 1] = 0; for (int index = 0; index < heights.length; index++){ newHeights[index + 1] = heights[index]; } heights = newHeights; int n = heights.length; Stack <Integer> s = new Stack<>(); s.push(0); int result = 0; for(int i = 1; i < n ; i ++){ if(heights[i] > heights[s.peek()]){ s.push(i); }else if(heights[i] == heights[s.peek()]){ s.pop(); s.push(i); }else { while(!s.empty() && heights[i] < heights[s.peek()]){ int mid = heights[s.pop()]; if(!s.empty()){ int w = i - s.peek() - 1; result = Math.max(result , w * mid); } } s.push(i); } } return result; } }class Solution { public int largestRectangleArea(int[] heights) { //在元素头尾各加一个0,来排除全部升序、降序的情况。 int [] newHeights = new int[heights.length + 2]; newHeights[0] = 0; newHeights[newHeights.length - 1] = 0; for (int index = 0; index < heights.length; index++){ newHeights[index + 1] = heights[index]; } heights = newHeights; int n = heights.length; Stack <Integer> s = new Stack<>(); s.push(0); int result = 0; for(int i = 1; i < n ; i ++){ if(heights[i] > heights[s.peek()]){ s.push(i); }else if(heights[i] == heights[s.peek()]){ s.pop(); s.push(i); }else { while(!s.empty() && heights[i] < heights[s.peek()]){ int mid = heights[s.pop()]; System.out.println("mid是:" + mid); //栈顶左边的元素 int left = s.peek(); //栈顶元素 int right = i; if(!s.empty()){ int w = right - left - 1; System.out.println("w是:" + w); result = Math.max(result , w * mid); System.out.println("w * mid是:" + (w * mid)); System.out.println("result是:" + result +"\n"); } } s.push(i); } } return result; } }
总结
-
739. 每日温度 - 力扣(LeetCode),单调递增栈,如果有更大的元素就弹出栈,可以作为单调栈模板背诵记忆。
-
496. 下一个更大元素 I - 力扣(LeetCode)对比上一题增加了Map简单映射操作。
-
503. 下一个更大元素 II - 力扣(LeetCode)增加取模操作。
-
42. 接雨水 - 力扣(LeetCode),该题在较小值弹出栈时有一些操作,当进入while循环后(要加入的元素比栈中元素大),计算弹出元素的深度(左右两个元素高度较小值 - 弹出元素高度),通过while循环以及弹出操作会增加宽度计算。
-
84. 柱状图中最大的矩形 - 力扣(LeetCode)栈顶和栈顶的下一个元素以及要入栈的三个元素组成了我们要求最大面积的高度和宽度。和上一题相似,同样是在弹出栈使做操作。
子序列问题
问题:
| 题目 | 关键点 |
|---|---|
| 300. 最长递增子序列 - 力扣(LeetCode) | 如何推导出dp[ i ] |
| 674. 最长连续递增序列 - 力扣(LeetCode) | 如何推导出dp[ i ],和不连续子序列的区别是? |
| 718. 最长重复子数组 - 力扣(LeetCode) | 二维dp数组的利用 |
| 1143. 最长公共子序列 - 力扣(LeetCode) | 二维dp、技巧性、三个方向(子问题)推导出的二维dp数组 |
| 1035. 不相交的线 - 力扣(LeetCode) | 问题转换为1143 |
| 53. 最大子数组和 - 力扣(LeetCode) | 如何推导出dp[ i ] |
- 300. 最长递增子序列 - 力扣(LeetCode)
-
确定dp数组及其下标含义:
dp[i] : 以nums[i]结尾的最长递增子序列的长度。
-
递推公式:dp[j]为0 ~ i - 1每个位置上,以nums[j]结尾的最长的子序列长度。
位置 i 的最长升序子序列等于j从0到i-1各个位置的最长升序子序列 + 1 的最大值。
if(nums[i] > nums[j]) dp[i] = Math.max(dp[i] , dp[j] + 1); -
初始化:由于是子序列,dp数组全部初始化为1。
-
顺序:遍历i的顺序一定是从前往后,因为dp[i]需要0 ~ i- 1推导而来。遍历j的顺序随意。
-
举例推导dp数组:
class Solution {
public int lengthOfLIS(int[] nums) {
//dp[i] : 以nums[i]结尾的最长递增子序列的长度。
int n = nums.length;
int [] dp = new int [n];
Arrays.fill(dp , 1);
for(int i = 0 ; i < n ; i ++){
for(int j = 0 ; j < i ; j ++){
if(nums[i] > nums[j])
dp[i] = Math.max(dp[i] , dp[j] + 1);
}
System.out.println("当前的dp[" + i + "]表示以" + nums[i] + "结尾的最长递增子序列是" + dp[i]);
}
int ans = 0 ;
for(int i = 0 ; i < n ; i ++){
ans = Math.max(ans , dp[i]);
}
return ans;
}
}
-
674. 最长连续递增序列 - 力扣(LeetCode)
-
dp数组下标以及含义:dp[i]表示以nums[i]结尾的最长连续递增子序列的长度。
-
递推公式:由于是连续递增子序列,本题dp[i]的状态由dp[i - 1]推导而来。而不需要dp[j]作为辅助。如果 nums[i] > nums[i - 1],那么以 i 为结尾的连续递增的子序列长度 一定等于 以i - 1为结尾的连续递增的子序列长度 + 1 。
dp[i] = dp[i - 1] + 1 -
初始化:由于是子序列,所以全部初始化为1。
-
遍历顺序,dp[i]由dp[i - 1]推导而来,顺序遍历。
-
举例推导dp数组。
-
class Solution {
public int findLengthOfLCIS(int[] nums) {
int n = nums.length;
int[] dp = new int [n];
Arrays.fill(dp , 1);
for(int i = 1; i < n ; i ++){
if(nums[i] > nums[i - 1]){
dp[i] = dp[i - 1] + 1;
}
//System.out.println("当前的dp[" + i + "]表示以" + nums[i] + "结尾的最长递增子序列是" + dp[i]);
}
int ans = 0 ;
for(int i = 0 ; i < n ; i ++){
ans = Math.max(ans, dp[i]);
}
return ans;
}
}
-
718. 最长重复子数组 - 力扣(LeetCode)
-
这里的子数组就是连续子序列。
-
确定dp数组及其下标含义:
dp[i - 1][j - 1]表示以nums1[i]为结尾和以nums2[j]为结尾的最长重复子数组。 -
确定递推公式:
dp[i][j] = dp[i - 1][j - 1] + 1,两个数组的状态都由前面的数组推导而来。 -
确定初始化:根据
dp[i][j]的定义,dp[i][0] 和dp[0][j]其实都是没有意义的,所以都初始化为0。 -
确定遍历顺序:外层for循环遍历A,内层for循环遍历B。
-
举例推导dp
class Solution { public int findLength(int[] nums1, int[] nums2) { int ans = 0; int m = nums1.length; int n = nums2.length; int dp [][] = new int [m + 1][n + 1]; for(int i = 1 ; i <= m ; i ++){ for(int j = 1; j <= n ; j ++){ if(nums1[i - 1] == nums2[j - 1]) dp[i][j] = dp[i - 1][j - 1] + 1; if(ans < dp[i][j]) ans = dp[i][j]; //System.out.println("dp[" + i + "][" + j + "]表示以" + "nums1[" + (i - 1) + "]和" +"nums2[" + (j - 1) +"]结尾的公共最长子数组是" + dp[i][j]); } } return ans; } }
-
-
1143. 最长公共子序列 - 力扣(LeetCode)
-
dp数组及其下标含义:
dp[i][j]:长度为[0, i - 1]的字符串text1与长度为[0, j - 1]的字符串text2的最长公共子序列为dp[i][j] -
递推公式:分为两种情况
text1[i - 1] 与 text2[j - 1]相同,text1[i - 1] 与 text2[j - 1]不相同
text1[i - 1] 与 text2[j - 1]相同:那么找到了一个公共元素,所以
dp[i][j] = dp[i - 1][j - 1] + 1;text1[i - 1] 与 text2[j - 1]不相同:那就看看 text1[0, i - 2] 与 text2[0, j - 1] 的最长公共子序列、 text1[0, i - 1] 与text2[0, j - 2]的最长公共子序列,取最大的。(text1往前找一个或者text2往前找一个,取最大即可。本质是重叠子问题)
即:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]); -
初始化:根据定义,
dp[0][j]或dp[i][0]没有意义。所以初始化为0。 -
遍历顺序:从前往后遍历。可以看出,有三个方向可以推出
dp[i][j],那么为了在递推的过程中,这三个方向都是经过计算的数值,所以要从前向后,从上到下来遍历这个矩阵。
-
举例推导dp数组
class Solution { public int longestCommonSubsequence(String text1, String text2) { int ans = 0; int m = text1.length(); int n = text2.length(); int [][] dp = new int [m + 1][n + 1]; for(int i = 1; i <= m ; i ++){ for(int j = 1 ; j <= n ; j ++){ char t1 = text1.charAt(i - 1); char t2 = text2.charAt(j - 1); if(t1 == t2){ dp[i][j] = dp[i - 1][j - 1] + 1; }else { dp[i][j] = Math.max(dp[i - 1][j] , dp[i][j - 1]); } if(ans < dp[i][j]) ans = dp[i][j]; //System.out.println("dp[" + i + "][" + j + "]表示以" + "text1[" + (i - 1) + "]和" +"text2[" + (j - 1) +"]结尾的最长公共子序列是" + dp[i][j]); } } return ans; } }
-
-
1035. 不相交的线 - 力扣(LeetCode)
本题的本质在与求nums1与nums2的最长公共子序列。所以与上一题一致。
-
53. 最大子数组和 - 力扣(LeetCode)
-
确定dp数组(dp table)以及下标的含义:dp[i]:包括下标i(以nums[i]为结尾)的最大连续子序列和为dp[i]。
-
确定递推公式:因为是连续子数组之和,所以dp[i]只有两个方向可以推出来:
-
dp[i - 1] + nums[i],即:nums[i]加入当前连续子序列和
-
nums[i],即:从头开始计算当前连续子序列和
一定是取最大的,所以dp[i] = max(dp[i - 1] + nums[i], nums[i]);
-
-
dp数组如何初始化:从递推公式可以看出来dp[i]是依赖于dp[i - 1]的状态,dp[0]就是递推公式的基础。dp[0]应为nums[0]即dp[0] = nums[0]。
-
确定遍历顺序:递推公式中dp[i]依赖于dp[i - 1]的状态,需要从前向后遍历。
-
举例推导dp数组
class Solution { public int maxSubArray(int[] nums) { int ans = nums[0] ; int n = nums.length; int [] dp = new int [n + 1]; dp[0] = nums[0]; for(int i = 1 ; i < n ; i ++){ dp[i] = Math.max(dp[i - 1] + nums[i], nums[i]); if(ans < dp[i]) ans = dp[i]; //System.out.println("nums[" + i + "]及之前的连续子数组之和为" + dp[i]); } return ans; } }
-
总结
-
对于300. 最长递增子序列 - 力扣(LeetCode)和674. 最长连续递增序列 - 力扣(LeetCode)。不连续递增子序列的跟前0-i 个状态有关,连续递增的子序列只跟前一个状态有关。根据这个性质去推导dp[i]即可。
-
对于718. 最长重复子数组 - 力扣(LeetCode)和1143. 最长公共子序列 - 力扣(LeetCode)。寻找的是两个数组的公共子序列/数组。所以要使用二维数组。对于718. 最长重复子数组 - 力扣(LeetCode),思路与674. 最长连续递增序列 - 力扣(LeetCode)最为类似,本质都是只跟前一个状态有关。但是对于1143题,却要转换为另一种思路,回归dp的本质,重叠子问题,那么在nums1[i - 1] != nums2[j - 1] ,寻找
dp[i][j]时,比较两个重叠子问题的大小就是解决答案。 -
使用二维数组解决的子序列问题中,dp定义一般都会为
dp[i][j]表示为下标i - 1和j - 1的数组。
编辑距离问题
| 题目 | 关键点 |
|---|---|
| 392. 判断子序列 - 力扣(LeetCode) | 递推公式与1143题的差别 |
| 115. 不同的子序列 - 力扣(LeetCode) | 递推公式的判断、dp数组由两个方向推导而来 |
| 583. 两个字符串的删除操作 - 力扣(LeetCode) | 两个字符串删除,相当于上两道题的结合,与1143基本一致 |
| 72. 编辑距离 - 力扣(LeetCode) | 删除 == 添加 、替换操作? |
- 392. 判断子序列 - 力扣(LeetCode)
-
确定dp数组(dp table)以及下标的含义:
dp[i][j]表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]。注意这里是判断s是否为t的子序列。即t的长度是大于等于s的。 -
确定递推公式
-
if (s[i - 1] == t[j - 1])
-
t中找到了一个字符在s中也出现了
-
if (s[i - 1] == t[j - 1]),那么
dp[i][j] = dp[i - 1][j - 1] + 1;,因为找到了一个相同的字符,相同子序列长度自然要在dp[i-1][j-1]的基础上加1。
-
-
if (s[i - 1] != t[j - 1])
-
相当于t要删除元素,继续匹配
-
if (s[i - 1] != t[j - 1]),此时相当于t要删除元素,t如果把当前元素t[j - 1]删除,那么
dp[i][j]的数值就是 看s[i - 1]与 t[j - 2]的比较结果了,即:dp[i][j] = dp[i][j - 1];
-
和 1143.最长公共子序列 (opens new window)的递推公式基本那就是一样的**,区别就是 本题 如果删元素一定是字符串t,而 1143.最长公共子序列 是两个字符串都可以删元素。**
-
dp数组如何初始化
从递推公式可以看出
dp[i][j]都是依赖于dp[i - 1][j - 1]和dp[i][j - 1],所以dp[0][0]和dp[i][0]是一定要初始化的。dp[i][0]表示以下标i-1为结尾的字符串,与空字符串的相同子序列长度,所以为0.dp[0][j]同理。 -
确定遍历顺序:同理从递推公式可以看出
dp[i][j]都是依赖于dp[i - 1][j - 1] 和 dp[i][j - 1],那么遍历顺序也应该是从上到下,从左到右。 -
举例推导dp数组
class Solution { public boolean isSubsequence(String s, String t) { int ans = 0; int m = s.length(); int n = t.length(); int [][] dp = new int [m + 1][n + 1]; for(int i = 1 ; i <= m ; i ++){ for(int j = 1 ; j <= n ; j ++){ char s1 = s.charAt(i - 1); char t1 = t.charAt(j - 1); if(s1 == t1) dp[i][j] = dp[i - 1][j - 1] + 1; else dp[i][j] = dp[i][j - 1]; //System.out.println("以下标" + (i - 1) + "为结尾的字符串s,和以下标" + (j - 1) + "为结尾的字符串t,相同子序列的长度为" + dp[i][j]); } } return dp[m][n] == m ? true : false; } }
-
115. 不同的子序列 - 力扣(LeetCode)
-
确定dp数组(dp table)以及下标的含义
dp[i][j]:以i-1为结尾的s子序列中出现以j-1为结尾的t的个数为dp[i][j]。 -
确定递推公式:这一类问题,基本是要分析两种情况
-
s[i - 1] 与 t[j - 1]相等
-
当s[i - 1] 与 t[j - 1]相等时,
dp[i][j]可以有两部分组成。一部分是用s[i - 1]来匹配,那么个数为
dp[i - 1][j - 1]。即不需要考虑当前s子串和t子串的最后一位字母,所以只需要dp[i-1][j-1]。一部分是不用s[i - 1]来匹配,个数为
dp[i - 1][j]。
-
-
s[i - 1] 与 t[j - 1] 不相等
当s[i - 1] 与 t[j - 1]不相等时,
dp[i][j]只有一部分组成,不用s[i - 1]来匹配(就是模拟在s中删除这个元素),即:dp[i - 1][j]所以递推公式为:
dp[i][j] = dp[i - 1][j];
-
为什么还要考虑 不用s[i - 1]来匹配,都相同了指定要匹配啊。
例如: s:bagg 和 t:bag ,s[3] 和 t[2]是相同的,但是字符串s也可以不用s[3]来匹配,即用s[0]s[1]s[2]组成的bag。
当然也可以用s[3]来匹配,即:s[0]s[1]s[3]组成的bag。
所以当s[i - 1] 与 t[j - 1]相等时,
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];为什么只考虑 “不用s[i - 1]来匹配” 这种情况, 不考虑 “不用t[j - 1]来匹配” 的情况呢。
这里大家要明确,我们求的是 s 中有多少个 t,而不是 求t中有多少个s,所以只考虑 s中删除元素的情况,即 不用s[i - 1]来匹配 的情况。
-
dp数组如何初始化
从递推公式
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]; 和dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j]是从上方和左上方推导而来,如图:,那么dp[i][0]和dp[0][j]是一定要初始化的。-
dp[i][0]表示:以i-1为结尾的s可以随便删除元素,出现空字符串的个数。那么dp[i][0]一定都是1,因为也就是把以i-1为结尾的s,删除所有元素,出现空字符串的个数就是1。 -
dp[0][j]:空字符串s可以随便删除元素,出现以j-1为结尾的字符串t的个数。那么dp[0][j]一定都是0,s如论如何也变成不了t。 -
dp[0][0]应该是1,空字符串s,可以删除0个元素,变成空字符串t。
-
-
遍历的时候一定是从上到下,从左到右,这样保证dp[i][j]可以根据之前计算出来的数值进行计算。
-
举例推导dp
class Solution { public int numDistinct(String s, String t) { int m = s.length(); int n = t.length(); int [][] dp = new int [m + 1][n + 1]; //dp数组的初始化 for(int i = 1 ; i <= m ; i ++){ dp[i][0] = 1; } for(int i = 1 ; i <= n ; i ++){ dp[0][i] = 0; } dp[0][0] = 1; for(int i = 1 ; i <= m ; i ++){ char s1 = s.charAt(i - 1); for(int j = 1 ; j <= n ; j ++){ char t1 = t.charAt(j - 1); //s1 == t1 存在两种情况,不用s[i - 1]匹配 + 用s[i - 1]匹配 if(s1 == t1) dp[i][j] = dp[i - 1][j] + dp[i - 1][j - 1]; //s1 != t1 只有一种情况,不用s[i - 1]匹配。 else dp[i][j] = dp[i - 1][j]; // System.out.println("以s[" + (i - 1) + "]结尾的字符串中,以t[" + (j - 1) +"]结尾的子序列的个数为" + dp[i][j]); } } return dp[m][n]; } }
-
-
583. 两个字符串的删除操作 - 力扣(LeetCode)
-
dp[i][j]:以i - 1结尾的word1和以j - 1结尾的word2,删除字符后使两个单词相等的最小删除步数为dp[i][j]。 -
word1[i - 1] = word2[j - 1]:不需要删除:
dp[i][j] = dp[i - 1][j - 1]。word1[i - 1] != word2[j - 1]:需要删除:删除word1或删除word2
dp[i][j] = Math.min(dp[i - 1][j] + 1, dp[i][j - 1] + 1) -
dp[i][0]:word2为空字符串,以i-1为结尾的字符串word1要删除多少个元素,才能和word2相同呢,很明显dp[i][0] = i。dp[0][j]的话同理。 -
遍历顺序从前往后,从上往下遍历。
-
举例推导dp
class Solution { public int minDistance(String word1, String word2) { int m = word1.length(); int n = word2.length(); int [] [] dp = new int [m + 1][n + 1]; for(int i = 0 ; i <= m ; i ++){ dp[i][0] = i; } for(int j = 0 ; j <= n ; j ++){ dp[0][j] = j; } for(int i = 1 ; i <= m ; i ++){ char w1 = word1.charAt(i - 1); for(int j = 1 ; j <= n ; j ++){ char w2 = word2.charAt(j - 1); if(w1 == w2) dp[i][j] = dp[i - 1][j - 1]; else dp[i][j] = Math.min(dp[i - 1][j] + 1 , dp[i][j - 1] + 1); //System.out.println("以word1[" + (i - 1) + "]和word[" + (j - 1) + "]结尾的单词,最少需要" + dp[i][j] + "步删除才能使word1与word2相等"); } } return dp[m][n]; } }
-
-
72. 编辑距离 - 力扣(LeetCode)
-
dp[i][j]:以i - 1结尾的word1和以j - 1结尾的word2,转换所需的最小操作数为dp[i][j]。 -
word1[i - 1] == word2[j - 1] :不需要进行操作,
dp[i][j] = dp[i - 1][j - 1]。word1[i - 1] != word2[j - 1]:需要进行操作:
删除(添加):word2删除一个元素,相当于word1添加一个元素。
word1删除一个元素:
dp[i][j] = dp[i - 1][j] + 1。word2删除一个元素(word1添加元素):
dp[i][j] = dp[i][j - 1] + 1替换:可以回顾一下,
if (word1[i - 1] == word2[j - 1])的时候我们的操作 是dp[i][j] = dp[i - 1][j - 1]对吧。那么只需要一次替换的操作,就可以让 word1[i - 1] 和 word2[j - 1] 相同。所以
dp[i][j] = dp[i - 1][j - 1] + 1; -
dp数组初始化:
dp[i][0]:以下标i-1为结尾的字符串word1,和空字符串word2,最近编辑距离为dp[i][0]。那么
dp[i][0]就应该是i,对word1里的元素全部做删除操作,即:dp[i][0] = i;同理
dp[0][j] = j; -
从上往下,从左往右遍历。
-
举例推导dp数组
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6cHIxoKf-1678023204478)(C:\Users\不知名网友鑫\AppData\Roaming\Typora\typora-user-images\image-20230301092225525.png)]
class Solution { public int minDistance(String word1, String word2) { int m = word1.length(); int n = word2.length(); int [] [] dp = new int [m + 1][n + 1]; for(int i = 0 ; i <= m ; i ++){ dp[i][0] = i; } for(int j = 0 ; j <= n ; j ++){ dp[0][j] = j; } for(int i = 1 ; i <= m ; i ++){ char w1 = word1.charAt(i - 1); for(int j = 1 ; j <= n ; j ++){ char w2 = word2.charAt(j - 1); if(w1 == w2) dp[i][j] = dp[i - 1][j - 1]; else dp[i][j] = Math.min(dp[i - 1][j - 1] + 1 , Math.min(dp[i - 1][j] + 1 , dp[i][j - 1] + 1)); //System.out.println("以word1[" + (i - 1) + "]和word2[" + (j - 1) + "]结尾的单词,word1最少需要" + dp[i][j] + "步操作才能使word1与word2相等"); } } return dp[m][n]; } }
-
总结
- 392. 判断子序列 - 力扣(LeetCode)对比1143T,1143是两个字符串都可以删元素,而本题如果删元素是删除字符串t,因为只有t有多余的字符串。
- 115. 不同的子序列 - 力扣(LeetCode),与392. 判断子序列 - 力扣(LeetCode)类似,也是删除元素,并且只能删除其中有多余字符的字符串。不同的是,在s[i - 1]与t[i - 1]相等时,也要考虑不使用s[i - 1]的情况。
- 583. 两个字符串的删除操作 - 力扣(LeetCode)与1143题思路基本一致。1143题的本质也是删除字符串。
- 72. 编辑距离 - 力扣(LeetCode)比起删除,多了一步替换的操作,根据word1[i - 1] == word2[j - 1]推导而来,很巧妙。
回文串问题
| 题目 | 关键点 |
|---|---|
| 647. 回文子串 - 力扣(LeetCode) | dp数组定义、dp推导、遍历顺序 |
| 516. 最长回文子序列 - 力扣(LeetCode) | dp数组定义 |
-
647. 回文子串 - 力扣(LeetCode)
判断一个子字符串(字符串的下表范围[i,j])是否回文,依赖于,子字符串(下表范围[i + 1, j - 1])) 是否是回文。
-
所以定义一个boolean类型的
dp[i][j],表示区间范围[i , j ]的子串是否回文。 -
s[i] == s[j]时分三种情况:
下标i == j(a):
dp[i][j] = true下标i与j相差为1(aa):
dp[i][j] = true下标i与j相差大于1(cabac):此时就看
dp[i + 1][j - 1]是不是回文即可。 -
dp[i][j]初始化为false。正好也解决了当s[i] != s[j]时的问题。 -
遍历顺序:
dp[i + 1][j - 1]在dp[i][j]的左下角,如图:所以应该从下往上,从左到右遍历。
-
举例推导dp数组
class Solution { public int countSubstrings(String s) { //记录回文串数量。 int ans = 0; int m = s.length(); boolean dp [][] = new boolean [m][m]; for(int i = m - 1; i >=0 ; i --){ char si = s.charAt(i); for(int j = i ; j < m ; j ++){ char sj = s.charAt(j); if(si ==sj){ if( j - i <= 1){ ans ++; dp[i][j] = true; }else if(dp[i + 1][j - 1]){ ans ++; dp[i][j] = true; } } // System.out.println("以[" + i + "," + j + "]为区间的字符串" + dp[i][j]+"回文串"); } } return ans; } }
-
-
516. 最长回文子序列 - 力扣(LeetCode)
-
dp数组初始化:
dp[i][j]:字符串s在[i, j]范围内最长的回文子序列的长度为dp[i][j]。 -
递推公式:如果s[i] == s[j] ,那么
dp[i][j] = dp[i + 1][j - 1] + 2。如果s[i] != s[j] ,那么就是根据加上s[i]或者加上s[j]两种情况的不同长度来判断,
dp[i][j] = Math.max(dp[i + 1][j] , dp[i][j - 1])。 -
初始化:
dp[i][j] = dp[i + 1][j - 1] + 2计算不到相同的情况,所以当i == j时,初始化为1。 -
遍历顺序与上一题一致
-
举例推导dp数组
class Solution { public int longestPalindromeSubseq(String s) { int m = s.length(); int [][] dp = new int [m][m]; for(int i = 0 ; i < m ; i ++){ dp[i][i] = 1; } for(int i = m - 1 ; i >= 0 ; i --){ char si = s.charAt(i); for(int j = i + 1; j < m ; j ++){ char sj = s.charAt(j); if(si == sj){ dp[i][j] = dp[i + 1][j - 1] + 2; }else { dp[i][j] = Math.max(dp[i + 1][j] , dp[i][j - 1]); } } } return dp[0][m - 1]; } }
-
总结
- 647. 回文子串 - 力扣(LeetCode)巧妙定义dp数组为boolean类型,并且二维数组表示区间。该题的dp数组由
dp[i + 1][j - 1]推导而来。并且dp[i + 1][j - 1]在dp[i][j]的左下方,所以遍历顺序应该从下往上,从左往右。该题a也算一个回文序列,所以j 从 i 开始。 - 516. 最长回文子序列 - 力扣(LeetCode)注意该题dp数组定义与上一题不同,所以递推方法也不同,如果s[i] !=s[j]时,那么就比较i + 1 ~ j 区间 和i ~ j - 1区间的情况,取其中的最大回文区间即可。在进行比较时,已经默认
dp[i + 1][j]和dp[i][j - 1]是回文区间了。该题还比较不到i == j的情况,注意初始化。并且注意j的范围,应该从j = i + 1开始。
MySQL 执行流程是怎样的?
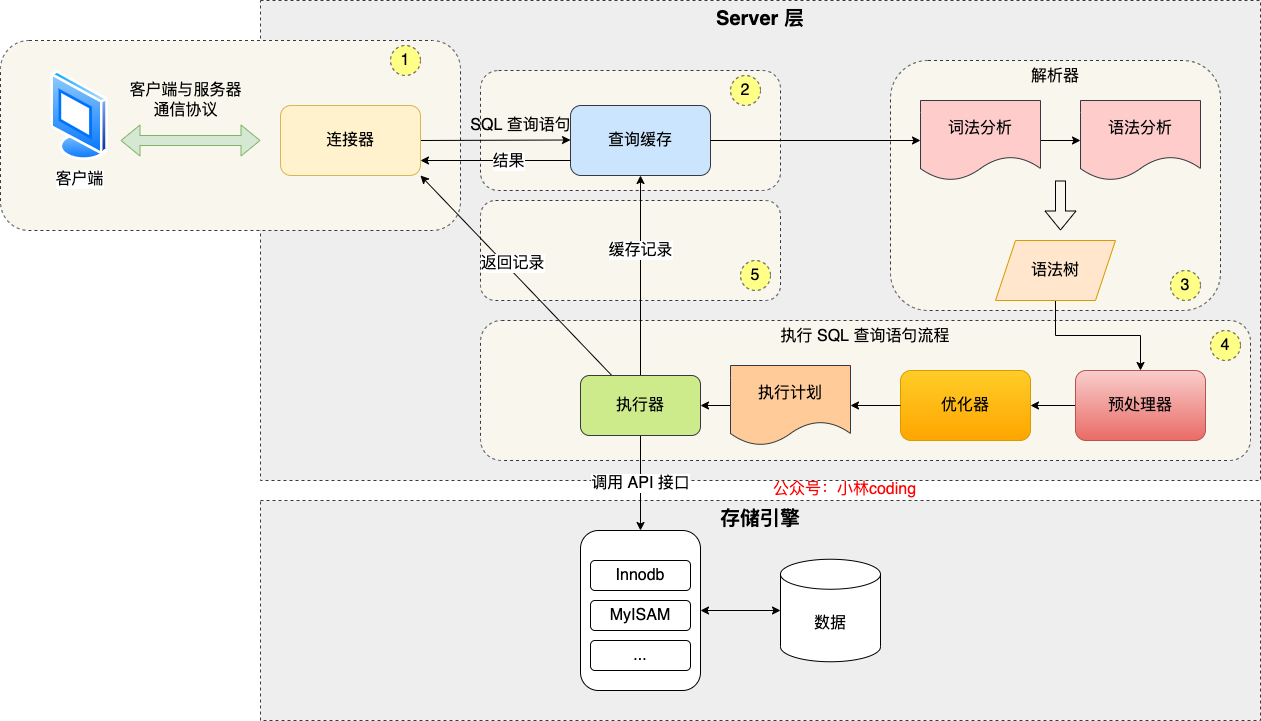
- MySQL 的架构共分为两层:Server 层和存储引擎层。
- Server 层负责建立连接、分析和执行 SQL。MySQL 大多数的核心功能模块都在这实现,主要包括连接器,查询缓存、解析器、预处理器、优化器、执行器等。
- 存储引擎层负责数据的存储和提取。支持 InnoDB、MyISAM、Memory 等多个存储引擎,不同的存储引擎共用一个 Server 层。现在最常用的存储引擎是 InnoDB,从 MySQL 5.5 版本开始, InnoDB 成为了 MySQL 的默认存储引擎。
第一步:连接器
- 连接器的工作主要如下:
- MySQL是基于TCP协议进行传输的,需要与客户端进行 TCP 三次握手建立连接;
- 校验客户端的用户名和密码,如果用户名或密码不对,则会报错;
- 如果用户名和密码都对了,会读取该用户的权限,然后后面的权限逻辑判断都基于此时读取到的权限;
-
查看MySQL服务被多少客户端连接了?
- 执行
show processlist命令进行查看。
- 执行
-
空闲连接会一直占用着吗?
- MySQL 定义了空闲连接的最大空闲时长,由
wait_timeout参数控制的,默认值是 8 小时(28880秒)。
- MySQL 定义了空闲连接的最大空闲时长,由
-
MySQL 的连接数有限制吗?
-
MySQL的连接和HTTP一样,也有长连接和短链接的概念。
// 短连接 连接 mysql 服务(TCP 三次握手) 执行sql 断开 mysql 服务(TCP 四次挥手) // 长连接 连接 mysql 服务(TCP 三次握手) 执行sql 执行sql 执行sql .... 断开 mysql 服务(TCP 四次挥手) -
MySQL 服务支持的最大连接数由 max_connections 参数控制,比如我的 MySQL 服务默认是 151 个,超过这个值,系统就会拒绝接下来的连接请求,并报错提示“Too many connections”。
-
-
怎么解决长连接占用内存的问题?
- 第一种,定期断开长连接。既然断开连接后就会释放连接占用的内存资源,那么我们可以定期断开长连接。
- 第二种,客户端主动重置连接。MySQL 5.7 版本实现了
mysql_reset_connection()函数的接口,注意这是接口函数不是命令,那么当客户端执行了一个很大的操作后,在代码里调用 mysql_reset_connection 函数来重置连接,达到释放内存的效果。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
第二步:查询缓存
- 连接器的工作完成后,客户端就可以向 MySQL 服务发送 SQL 语句了,MySQL 服务收到 SQL 语句后,就会解析出 SQL 语句的第一个字段,看看是什么类型的语句。
- 如果 SQL 是查询语句(select 语句),MySQL 就会先去查询缓存( Query Cache )里查找缓存数据,看看之前有没有执行过这一条命令,这个查询缓存是以 key-value 形式保存在内存中的,key 为 SQL 查询语句,value 为 SQL 语句查询的结果。如果查询的语句命中查询缓存,那么就会直接返回 value 给客户端。如果查询的语句没有命中查询缓存中,那么就要往下继续执行,等执行完后,查询的结果就会被存入查询缓存中。
- 对于更新比较频繁的表,查询缓存的命中率很低的,因为只要一个表有更新操作,那么这个表的查询缓存就会被清空。所以,MySQL 8.0 版本直接将查询缓存删掉了。
第三步:解析器 解析SQL
- 第一件事情,词法分析。MySQL 会根据你输入的字符串识别出关键字出来,构建出 SQL 语法树,这样方便后面模块获取 SQL 类型、表名、字段名、 where 条件等等。
- 第二件事情,语法分析。根据词法分析的结果,语法解析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。
第四步:执行 SQL
-
经过解析器后,接着就要进入执行 SQL 查询语句的流程了,每条
SELECT查询语句流程主要可以分为下面这三个阶段:-
prepare 阶段,也就是预处理阶段,使用预处理器;
-
检查 SQL 查询语句中的表或者字段是否存在;
-
将
select *中的*符号,扩展为表上的所有列;(SELECT * 意为查询所有列)
-
-
optimize 阶段,也就是优化阶段,使用优化器;
- 负责将 SQL 查询语句的执行方案确定下来,选择查询成本最小的执行计划,比如在表里面有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使用哪个索引。如果想要知道优化器选择了哪个索引,我们可以在查询语句最前面加个
explain命令,这样就会输出这条 SQL 语句的执行计划。
- 负责将 SQL 查询语句的执行方案确定下来,选择查询成本最小的执行计划,比如在表里面有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使用哪个索引。如果想要知道优化器选择了哪个索引,我们可以在查询语句最前面加个
-
execute 阶段,也就是执行阶段,使用执行器;
- 根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;在执行的过程中,执行器就会和存储引擎交互了,交互是以记录为单位的。
-
-
用三种方式执行过程,体现执行器和存储引擎的交互过程:
-
主键索引查询
select * from product where id = 1;- 执行器第一次查询,会调用 read_first_record 函数指针指向的函数,因为优化器选择的访问类型为 const,这个函数指针被指向为 InnoDB 引擎索引查询的接口,把条件
id = 1交给存储引擎,让存储引擎定位符合条件的第一条记录。 - 存储引擎通过主键索引的 B+ 树结构定位到 id = 1的第一条记录,如果记录是不存在的,就会向执行器上报记录找不到的错误,然后查询结束。如果记录是存在的,就会将记录返回给执行器;
- 执行器从存储引擎读到记录后,接着判断记录是否符合查询条件,如果符合则发送给客户端,如果不符合则跳过该记录。
- 执行器查询的过程是一个 while 循环,所以还会再查一次,但是这次因为不是第一次查询了,所以会调用 read_record 函数指针指向的函数,因为优化器选择的访问类型为 const,这个函数指针被指向为一个永远返回 - 1 的函数,所以当调用该函数的时候,执行器就退出循环,也就是结束查询了。
- 执行器第一次查询,会调用 read_first_record 函数指针指向的函数,因为优化器选择的访问类型为 const,这个函数指针被指向为 InnoDB 引擎索引查询的接口,把条件
-
全表扫描
select * from product where name = 'iphone';- 执行器第一次查询,会调用 read_first_record 函数指针指向的函数,因为优化器选择的访问类型为 all,这个函数指针被指向为 InnoDB 引擎全扫描的接口,让存储引擎读取表中的第一条记录;
- **定位到符合条件的记录。**执行器会判断读到的这条记录的 name 是不是 iphone,如果不是则跳过;如果是则将记录发给客户端(是的没错,Server 层每从存储引擎读到一条记录就会发送给客户端,之所以客户端显示的时候是直接显示所有记录的,是因为客户端是等查询语句查询完成后,才会显示出所有的记录)。
- 执行器查询的过程是一个 while 循环,所以还会再查一次,会调用 read_record 函数指针指向的函数,因为优化器选择的访问类型为 all,read_record 函数指针指向的还是 InnoDB 引擎全扫描的接口,所以接着向存储引擎层要求继续读刚才那条记录的下一条记录,存储引擎把下一条记录取出后就将其返回给执行器(Server层),执行器继续判断条件,不符合查询条件即跳过该记录,否则发送到客户端;
- 一直重复上述过程,直到存储引擎把表中的所有记录读完,向执行器(Server层) 返回了读取完毕的信息; 执行器收到存储引擎报告的查询完毕的信息,退出循环,停止查询。
-
索引下推
索引下推能够减少二级索引在查询时的回表操作,提高查询的效率,因为它将 Server 层负责的事情,交给存储引擎层去处理了。
select * from t_user where age > 20 and reward = 100000;联合索引当遇到范围查询 (>、<) 就会停止匹配,也就是 age 字段能用到联合索引,但是 reward 字段则无法利用到索引。
不使用索引下推优化:
- Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
- 存储引擎根据二级索引的 B+ 树快速定位到这条记录后,获取主键值,然后进行回表操作,将完整的记录返回给 Server 层;
- Server 层在判断该记录的 reward 是否等于 100000,如果成立则将其发送给客户端;否则跳过该记录;
- 接着,继续向存储引擎索要下一条记录,存储引擎在二级索引定位到记录后,获取主键值,然后回表操作,将完整的记录返回给 Server 层;
- 如此往复,直到存储引擎把表中的所有记录读完。
使用索引下推优化:
- Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
- 存储引擎定位到二级索引后,先不执行回表操作,而是先判断一下该索引中包含的列(reward列)的条件(reward 是否等于 100000)是否成立。如果条件不成立,则直接跳过该二级索引。如果成立,则执行回表操作,将完成记录返回给 Server 层。
- Server 层在判断其他的查询条件(本次查询没有其他条件)是否成立,如果成立则将其发送给客户端;否则跳过该记录,然后向存储引擎索要下一条记录。
- 如此往复,直到存储引擎把表中的所有记录读完。
-
2.2 MySQL 一行记录是怎么存储的?
MySQL 的数据存放在哪个文件?
mysql> SHOW VARIABLES LIKE 'datadir';
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| datadir | /var/lib/mysql/ |
+---------------+-----------------+
1 row in set (0.00 sec)
- 进入/var/lib/mysql/my_test目录,创建一个t_order表,会随之创建三个文件:
db.opt,用来存储当前数据库的默认字符集和字符校验规则。t_order.frm,t_order 的表结构会保存在这个文件。在 MySQL 中建立一张表都会生成一个.frm 文件,该文件是用来保存每个表的元数据信息的,主要包含表结构定义。t_order.ibd,t_order 的表数据会保存在这个文件。- 参数 innodb_file_per_table 控制表数据存在哪里,从 MySQL 5.6.6 版本开始,它的默认值就是 1 了,那么会将存储的数据、索引等信息单独存储在一个独占表空间(.ibd 文件)。
表空间文件的结构是怎么样的?
表空间由段(segment)、区(extent)、页(page)、行(row)组成。
- 行:数据库表中的记录都是按行(row)进行存放的,每行记录根据不同的行格式,有不同的存储结构。
- 页:InnoDB 的数据是按「页」为单位来读写的,也就是说,当需要读一条记录的时候,并不是将这个行记录从磁盘读出来,而是以页为单位,将其整体读入内存。默认每个页的大小为 16KB,也就是最多能保证 16KB 的连续存储空间。
- 区:B + 树每一层都是通过双向链表连接的,如果只使用页来存储空间,可能链表中相邻的两个页之间物理位置并不是连续的。在表中数据量大的时候,为某个索引分配空间的时候就不再按照页为单位分配了,而是按照区(extent)为单位分配。每个区的大小为 1MB,对于 16KB 的页来说,连续的 64 个页会被划为一个区,这样就使得链表中相邻的页的物理位置也相邻,就能使用顺序 I/O 了。
- 段:表空间是由各个段(segment)组成的,段是由多个区(extent)组成的。段一般分为数据段、索引段和回滚段等。
- 索引段:存放 B + 树的非叶子节点的区的集合;
- 数据段:存放 B + 树的叶子节点的区的集合;
- 回滚段:存放的是回滚数据的区的集合。
InnoDB行格式有哪些?
InnoDB 提供了 4 种行格式,分别是 Redundant(冗余)、Compact(紧凑)、Dynamic(动态)和 Compressed (压缩)行格式。
-
Redundant 是很古老的行格式了, MySQL 5.0 版本之前用的行格式。
-
Dynamic 和 Compressed 两个都是紧凑的行格式,它们的行格式都和 Compact 差不多,因为都是基于 Compact 改进一点东西。从 MySQL5.7 版本之后,默认使用 Dynamic 行格式。
-
由于 Redundant 不是一种紧凑的行格式,所以 MySQL 5.0 之后引入了 Compact 行记录存储方式,Compact 是一种紧凑的行格式,设计的初衷就是为了让一个数据页中可以存放更多的行记录,从 MySQL 5.1 版本之后,行格式默认设置成 Compact。
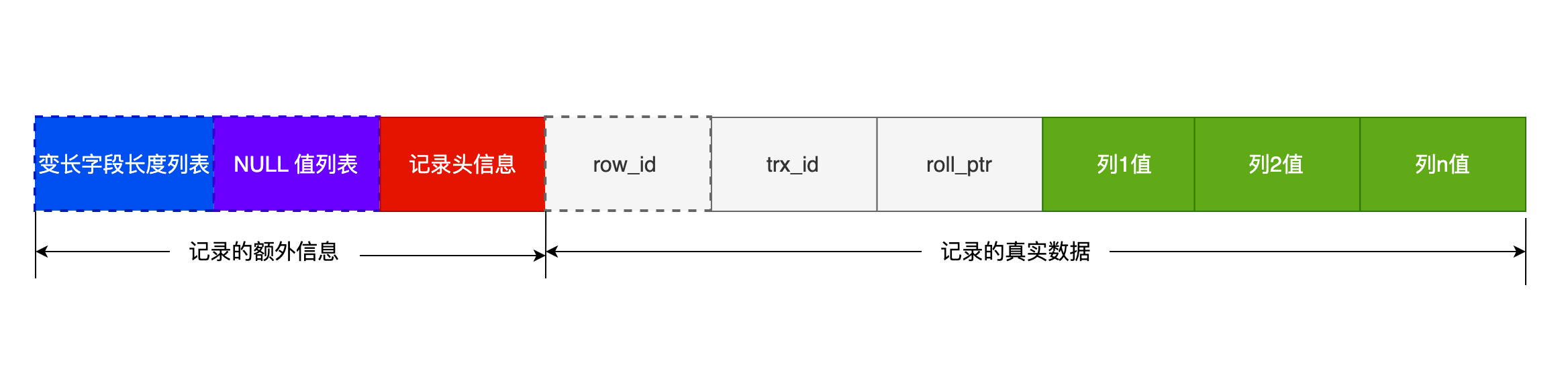
-
记录的额外信息
- 其中包含 3 个部分:变长字段长度列表、NULL 值列表、记录头信息。
- 变长字段长度列表:存放变长字段的数据的长度大小,读取数据时根据这个「变长字段长度列表」去读取对应长度的数据。
- **变长字段长度列表和NULL值列表的信息要按照逆序存放。**逆序存放主要是因为记录头信息中指向下一个记录的指针,指向的是下一条记录的「记录头信息」和「真实数据」之间的位置,这样的好处是向左读就是记录头信息,向右读就是真实数据,比较方便。这样使得位置靠前的记录的真实数据和数据对应的字段长度信息可以同时在一个 CPU Cache Line 中,这样就可以提高 CPU Cache 的命中率。
- 变长字段列表不是必须的。当数据表没有变长字段的时候,比如全部都是 int 类型的字段,就会去掉节省空间。
- NULL值列表:表中的某些列可能会存储 NULL 值,如果把这些 NULL 值都放到记录的真实数据中会比较浪费空间,所以 Compact 行格式把这些值为 NULL 的列存储到 NULL值列表中。
- 如果存在允许 NULL 值的列,则每个列对应一个二进制位(bit),二进制位按照列的顺序逆序排列。0表示不为NULL,1表示为NULL。
- NULL 值列表也不是必须的。当数据表的字段都定义成 NOT NULL 的时候,这时候表里的行格式就不会有 NULL 值列表了。
- NULL 值列表的空间不是固定 1 字节的。当一条记录有 9 个字段值都是 NULL,那么就会创建 2 字节空间的NULL 值列表,以此类推。
- 记录头信息:有几个比较重要的记录头信息。
- delete_mask :标识此条数据是否被删除。从这里可以知道,我们执行 detele 删除记录的时候,并不会真正的删除记录,只是将这个记录的 delete_mask 标记为 1。
- next_record:下一条记录的位置。从这里可以知道,**记录与记录之间是通过链表组织的。**在前面我也提到了,指向的是下一条记录的「记录头信息」和「真实数据」之间的位置,这样的好处是向左读就是记录头信息,向右读就是真实数据,比较方便。
- record_type:表示当前记录的类型,0表示普通记录,1表示B+树非叶子节点记录,2表示最小记录,3表示最大记录。
-
记录的真实数据
trx_id 和 roll_pointer主要为MVCC服务。
-
row_id:如果我们建表的时候指定了主键或者唯一约束列,那么就没有 row_id 隐藏字段了。如果既没有指定主键,又没有唯一约束,那么 InnoDB 就会为记录添加 row_id 隐藏字段。row_id不是必需的,占用 6 个字节。 -
trx_id:事务id,表示这个数据是由哪个事务生成的。 trx_id是必需的,占用 6 个字节。 -
roll_pointer:这条记录上一个版本的指针。roll_pointer 是必需的,占用 7 个字节。
-
-
varchar(n)中n最大取值为多少?
- MySQL 规定除了 TEXT、BLOBs 这种大对象类型之外,其他所有的列(不包括隐藏列和记录头信息)占用的字节长度加起来不能超过 65535 个字节(16位)。
- varchar(n) 字段类型的 n 代表的是最多存储的字符数量,并不是字节大小。所以要看数据库表的字符集,因为字符集代表着1个字符要占用多少字节,比如 ascii 字符集, 1 个字符占用 1 字节,那么 varchar(100) 意味着最大能允许存储 100 字节的数据。
- 单字段的情况:只有一个 varchar(n) 类型的列且字符集是 ascii。varchar(n) 中 n 最大值 = 65535 - 2(「变长字段长度列表」所占字节数) - 1(「NULL值列表」所占字节数) = 65532。
- 计算变长字段长度列表:「变长字段长度列表」所占用的字节数 = 所有「变长字段长度」占用的字节数之和。
- 条件一:如果变长字段允许存储的最大字节数小于等于 255 字节,就会用 1 字节表示「变长字段长度」;条件二:如果变长字段允许存储的最大字节数大于 255 字节,就会用 2 字节表示「变长字段长度」;
- 反观我们这里字段类型是 varchar(65535) ,字符集是 ascii,所以代表着变长字段允许存储的最大字节数是 65535,符合条件二,所以会用 2 字节来表示「变长字段长度」。
- 计算NULL值列表:创建表时,如果字段是允许为 NULL 的,用 1 字节来表示「NULL 值列表」。
- 计算变长字段长度列表:「变长字段长度列表」所占用的字节数 = 所有「变长字段长度」占用的字节数之和。
- 多字段的情况:如果有多个字段的话,要保证所有字段的长度 + 变长字段长度列表所占用的字节数 + NULL值列表所占用的字节数 <= 65535。
- 单字段的情况:只有一个 varchar(n) 类型的列且字符集是 ascii。varchar(n) 中 n 最大值 = 65535 - 2(「变长字段长度列表」所占字节数) - 1(「NULL值列表」所占字节数) = 65532。
SDS
-
String类型的底层的数据结构是用什么实现的?
- String 类型的底层的数据结构实现主要是 SDS(simple dynamic string 简单动态字符串)。
-
SDS 与C字符串有什么区别?
-
相比C语言,Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出。、
- 因为 SDS 的API 在拼接字符串之前会检查 SDS 空间是否满足要求,如果空间不够会自动扩容。
-
SDS 结构里用 len 属性记录了字符串长度,所以获取字符串长度的时间复杂度为 O(1)。
-
相比C字符串,SDS 保存的数据是二进制安全的。也就是数据保存时是什么样,读取时就是什么样,不会像C字符串,遇到空字符串,会被程序误认为是字符串结尾。
- 为了确保Redis可以适用于不用的使用场景,SDS 的所有 API 都会以处理二进制的方式来处理 SDS 存放在 buf[] 数组里的数据。
-