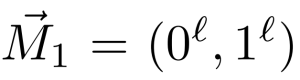Dimensionality reduction ,PCA and
autoencoders
Dimensionality reduction
我们清楚,数据降维其实都是减少数据的特征数量,如果把
e
n
c
o
d
e
r
encoder
encoder看作是由高维原有特征生成低维新特征的过程。把
d
e
c
o
d
e
r
decoder
decoder看作是将低维特征还原为高维特征的过程。那么数据降维就可以被看作是一个数据压缩过程。其中
e
n
c
o
d
e
r
encoder
encoder负责将数据从
i
n
i
t
a
l
s
p
a
c
e
inital space
initalspace压缩至
l
a
t
e
n
t
s
p
a
c
e
latent space
latentspace
d
e
c
o
d
e
r
decoder
decoder负责将数据从$latent space
空
间
压
缩
至
i
空间压缩至i
空间压缩至inital spade$中。
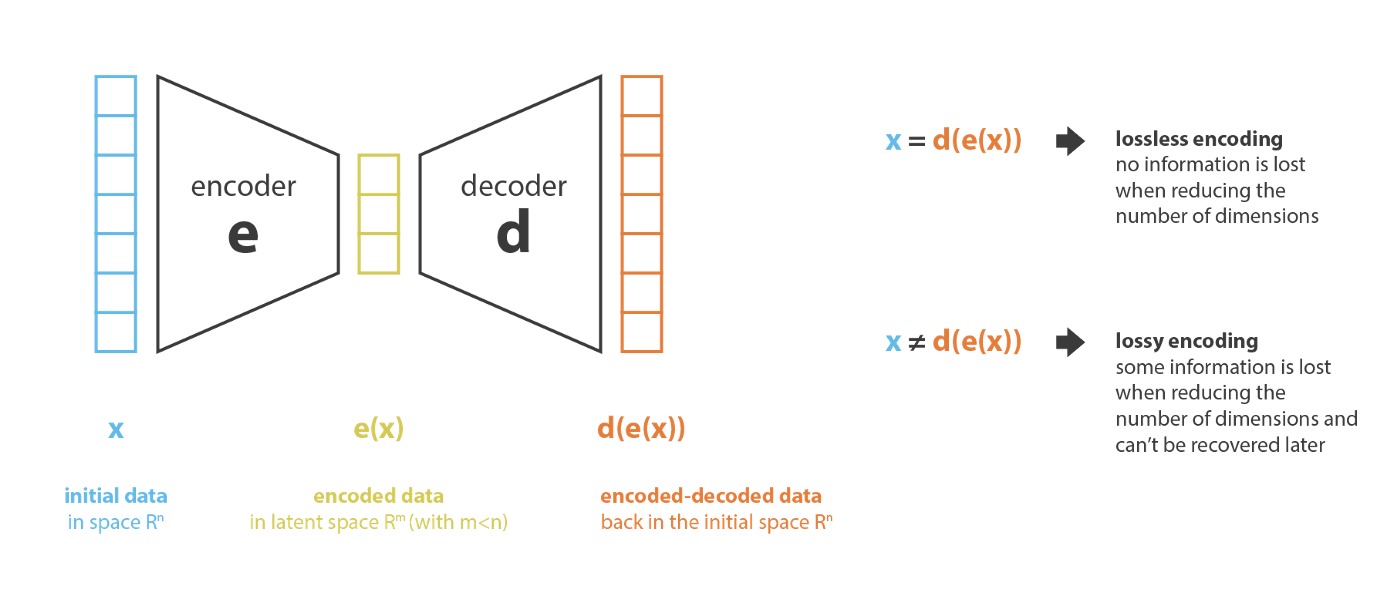
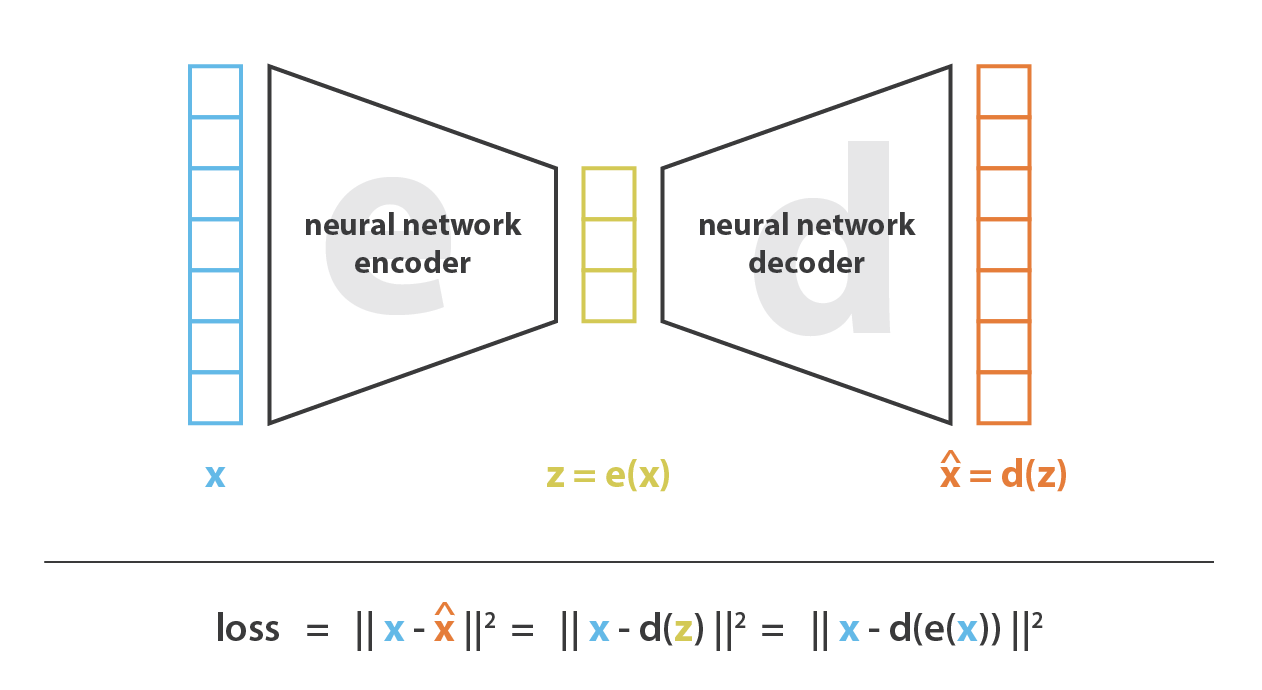
当然,encoder-decoder代表的数据压缩\j解压过程,很可能是由损的(losy). 因此数据降维的主要目的是找到一个
e
n
c
o
d
e
r
−
d
e
c
o
d
e
r
encoder-decoder
encoder−decoder
对使得编码能保留更多的信息。解码时候能保证尽可能的小的重建误差。这一过程可能被视为如下形式:

PCA
- PCA是一种常用的数据降维方法,其主要思想是:找到 n e n_e ne个线性无关的新特征。每个新特征都是 n d n_d nd个旧特征的线性组合。
- n e < n d n_e < n_d ne<nd
- 其中数据在新特征张成的线性子空间上的投影与原始数据在欧式距离上尽量相似。也就是说,PCA是在寻找原始数据空间中,一个最佳线性子空间,它使得线性投影在该子空间上后可以使得信息损耗量尽可能的少。可以正得。这 n e n_e ne个特征即为样本矩阵的协方差,最大的 n e n_e ne个特征对应的特征向量。
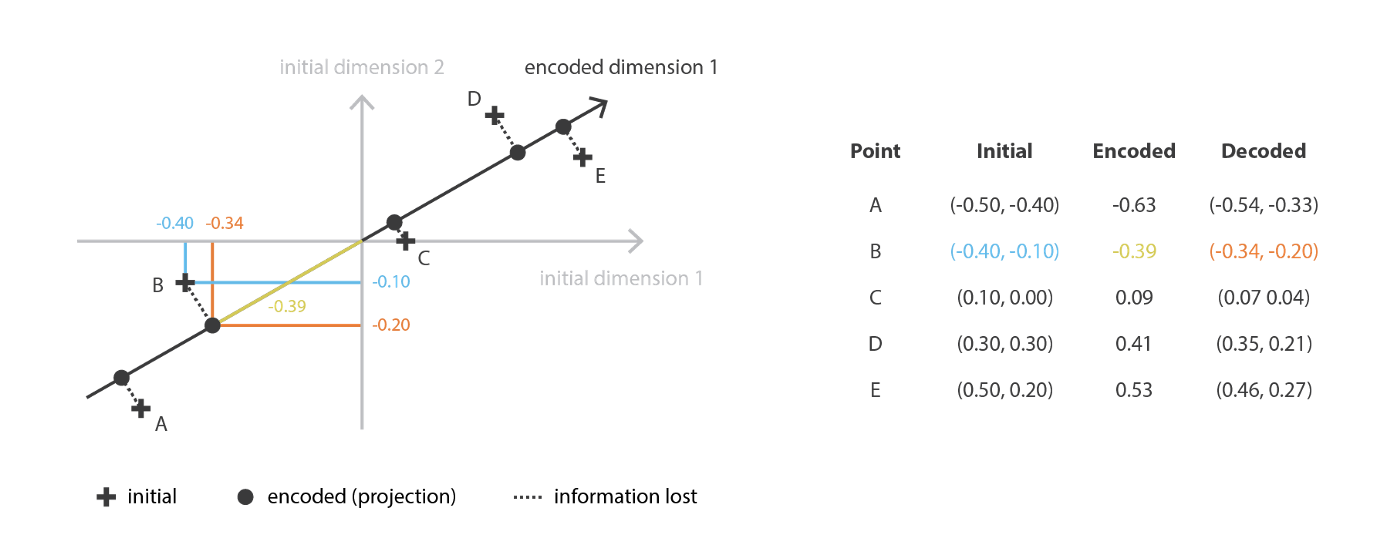
- 在PCA中,带入前面所述得到:encode\decoder思想。
- 设 P = [ u 1 , ⋯ , u n e ] P = [u_1,\cdots,u_{n_e}] P=[u1,⋯,une]为 n e n_e ne个新特征组成的
- n d × n e n_d \times n_e nd×ne的向量,则 e n c o d e r encoder encoder为 P T P^T PT decoer为 P P P.

-
Autoencoder
- 该方法也是一种数据降维的方法,其基本思想是用神经网络实现
-
e
n
c
o
d
e
r
encoder
encoder和
d
e
c
o
d
e
r
decoder
decoder 从而能够端到端的训练出一个最佳的encoder\decoder对。
学习总结
会自己构造损失函数,慢慢额自己构造出来都行啦的样子与打算。
当encoder和decoder都有一个线性层时候,
A
u
t
o
e
n
c
o
d
e
r
s
Auto encoders
Autoencoders和PCA就十分相似啦。它们都是寻找一个最佳线性子空间使得投影数据时带来的信息损失最小。当然,Autoencoders并没有像PCA一样施加了正交约束。
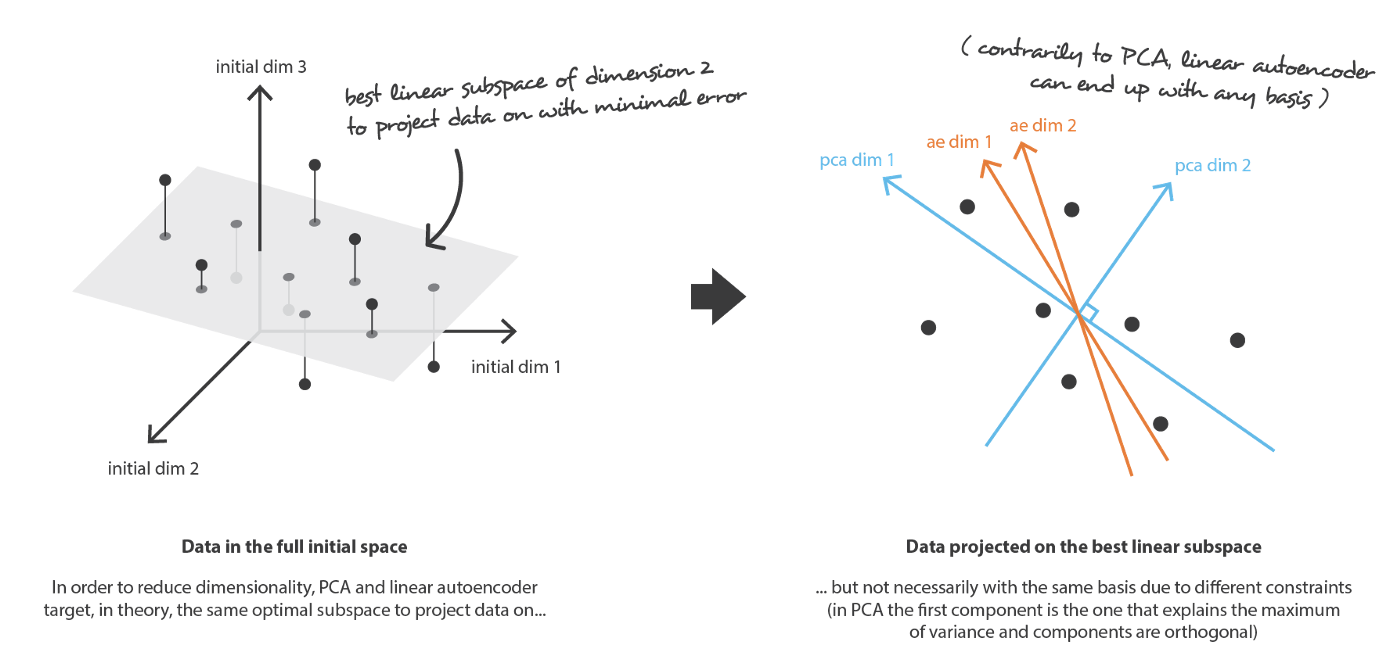
现在假如:Autoencoders 中的 encoder 和 decoder 都具有无限的拟合能力,那么理论上,我们就可以以无损地把任何高维数据都压缩至1维度。在此需要明确以下两点
- 无损数据压缩往往会使得潜在空间缺乏可解释性。
- 在大多数情况下,数据压缩的最终目的不仅仅是为了降低数据维度。而是为了在降低数据维度的同时还能在 l a t e n t s p a c e latent space latentspace中保留数据的主要结构信息。

-
Variational Autoencoders
- In a nutshell, a VAE is an autoencoder whose encodings distribution is regularised during the training in order to ensure that its latent space has good properties allowing us to generate some new data.
- Moreover, the term “variational” comes from the close relation there is between the regularisation and the variational inference method in statistics.
Limitations of autoencoders for content generation
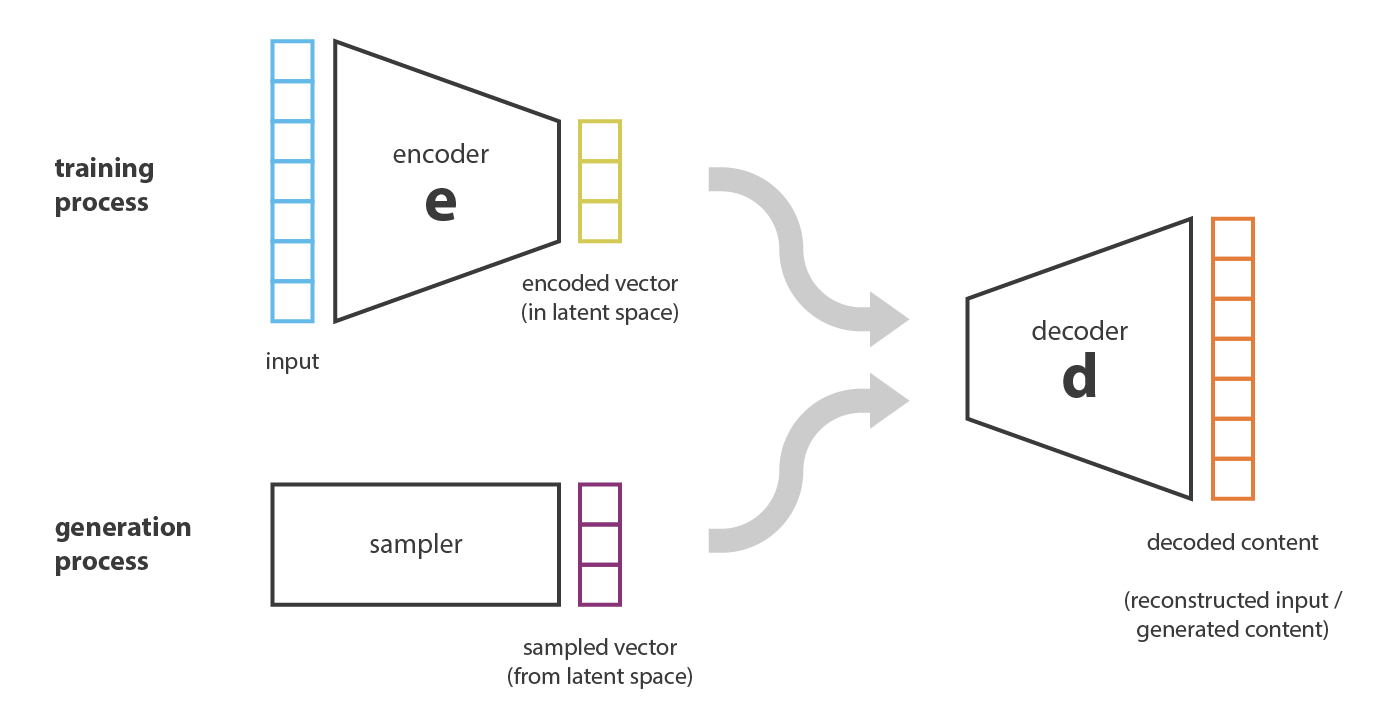
如果想要将Autoencoder用于生成式任务,一个直观的想法就是随机从
l
a
t
e
n
t
s
p
a
c
e
latent space
latentspace中采样,然后利用decoder进行生成。
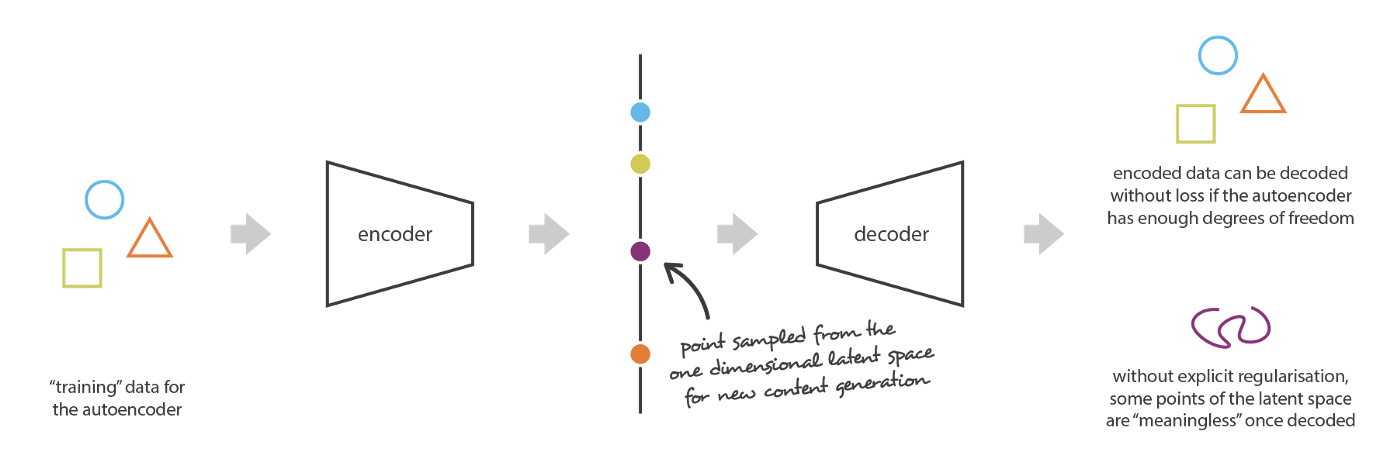
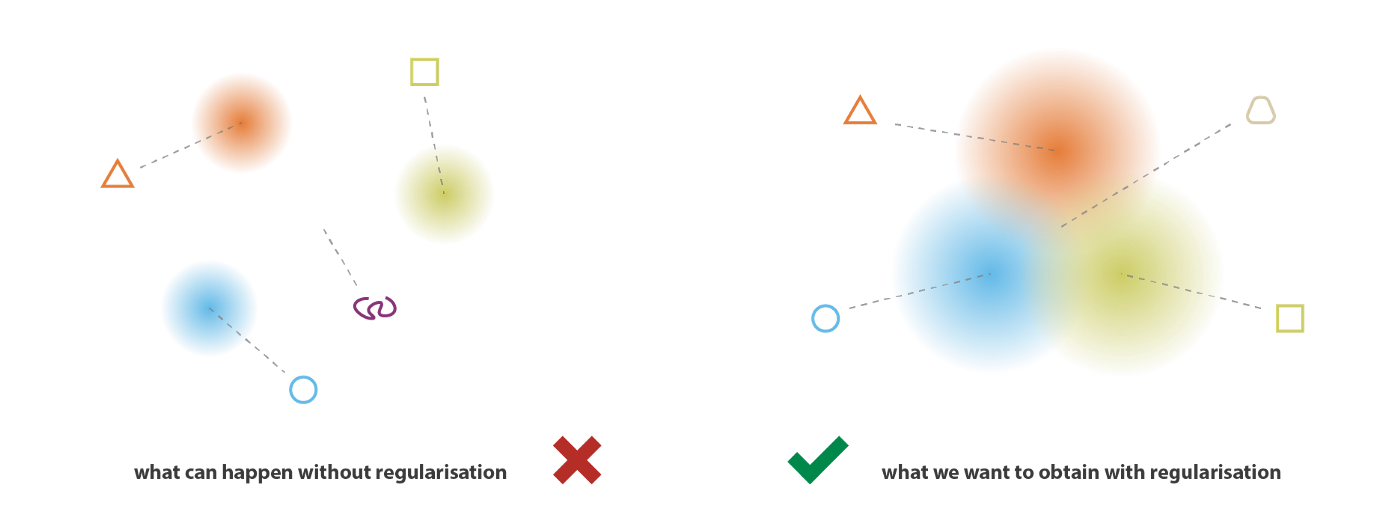
The problem of the autoencoders latent space regularity: 直接由 decoder 生成的样本质量取决于 latent space 的 regularity。然而正如前面所述,Autoencoders 由于缺乏必要的正则化,latent space 无法体现出数据的主要结构信息,缺乏可解释性,往往会陷入过拟合,因此直接由 decoder 生成的样本往往不具有实际意义。如下图所示,假设 encoder 和 decoder 都具有无限的拟合能力,当在 latent space 中采样的向量刚好是训练样本的 encoded vector 时,decoder 生成的样本就是有实际意义的样本,但当采样的向量不是训练样本的 encoded vector 时,就不能保证 decoder 生成的样本具有实际意义
Definition of variational autoencoders
为了能够将 decoder 用于生成,我们希望 latent space 具有如下性质:(1) continuity (latent space 中的两个相近点在解码后也应该具有相近的内容);(2) completeness (对于一个给定的概率分布 p ( z ) p(z)p(z),从 latent space 中采样得到的点在解码后应该得到有意义的输出)

为了使得latent space具有如上所述的性质,VAE的encoder将输入数据
x
x
x编码为latent space。上的一个概率分布
P
(
z
∣
x
)
P(z|x)
P(z∣x).
r然后按该分布采样出一个隐变量。
z
−
P
(
z
∣
x
)
z - P(z|x)
z−P(z∣x).然后将其解码,计算并传重构误差。
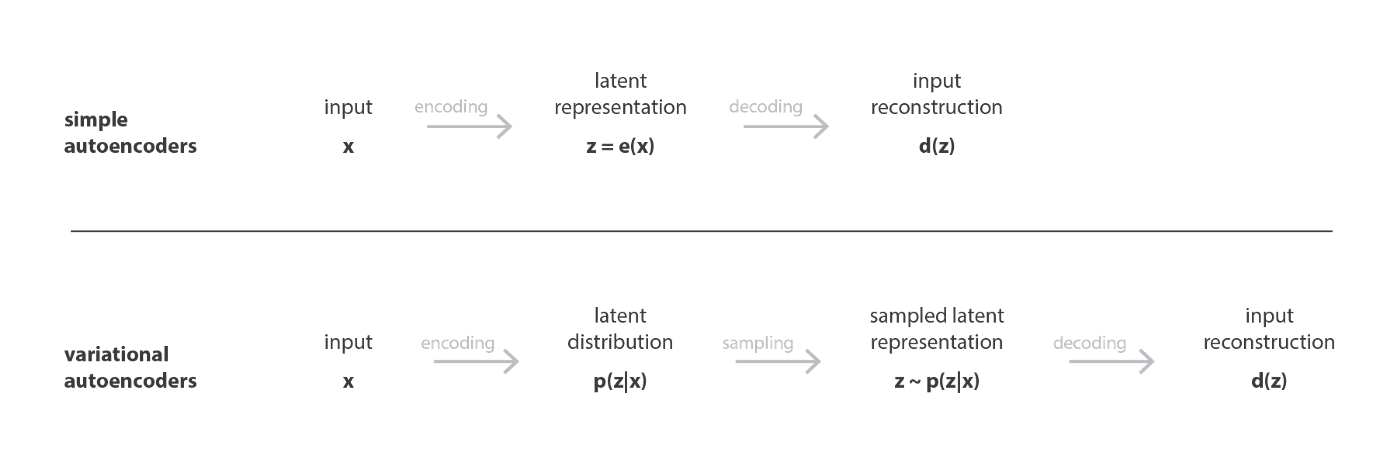
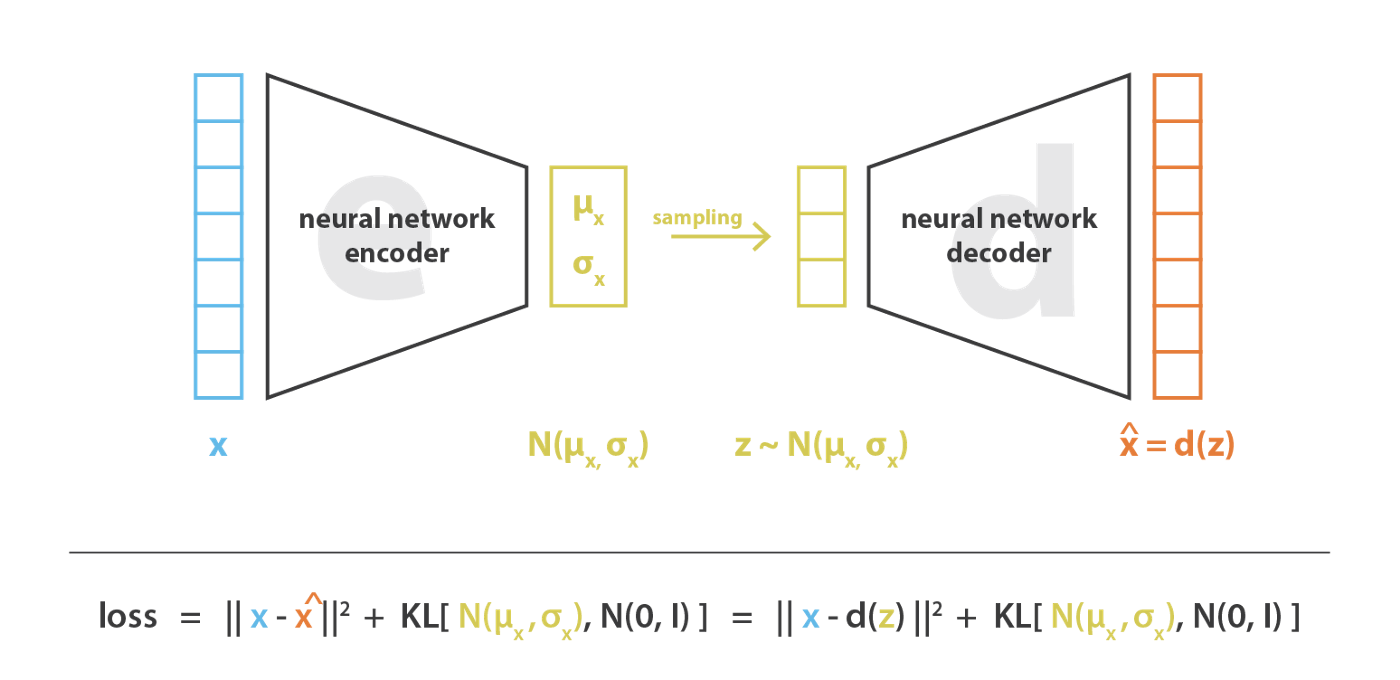
在实际应用中,VAE 假设似然$ p ( z ∣ x )$ 为一个正态分布,且协方差矩阵为对角矩阵,因此 encoder 仅需输出该正态分布的均值和方差向量。因此,这就假定了 VAE 生成的隐变量 z zz 的各维特征之间是解耦的,特征之间的相关性不强,因此在用作特征编码时相比普通 AE 更能提取有效信息.
然而,仅仅将输入的编码为概率分布还不足以保证continuity 和 completeness。这是因为将输入编码为概率分布会给 decoder 引入噪声从而加大重构误差,为了尽可能地减小重构误差,模型可能会使得 encoder 输出概率分布的方差特别小或不同输入对应分布的均值极不相近 (in both case variances of distributions become small relatively to distance between their means),这就使得输出概率分布与输出单一的点效果相似,VAE 会退化为传统自编码器。
为了解决上述问题,VAE 在训练时针对 encoder 输出的概率分布加入了正则项。具体而言,VAE 要求 encoder 输出的概率分布与标准正态分布尽量接近,也就是使得它们之间的 KL 散度尽量得小。在加入正则项后,我们就能使得不同输入编码得到的概率分布之间互相重合,进而保证 continuity 和 completeness (该正则项实际包括了对 latent space 的 local 和 global 正则化,local 正则化来自于对方差的控制,global 正则化来自于对均值的控制)。
当 $p ( z ∣ x ) $接近标准正态分布时,可以证得 latent vector z zz 的先验分布就是标准正态分布:
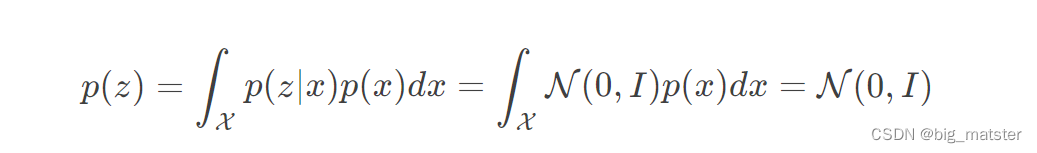
在加入正则化项之后,VAE的损失函数,如下所示:这也可以看作一个对抗过程。重构损失要求encoder输出的方差尽量小。而正则要求
e
n
c
o
d
e
r
encoder
encoder的方差接近1
由于我们考虑了各分量独立的多元正态分布,因此,只需要推导一元正太分布的情形即可:
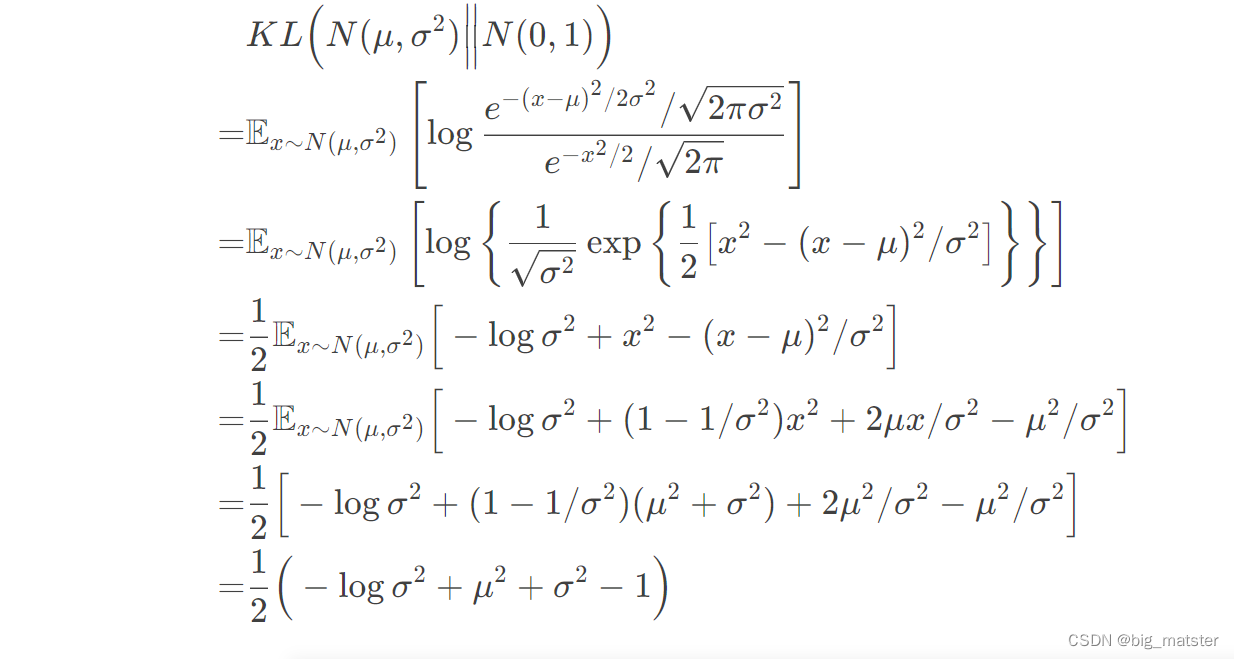
各分量独立的多元正太分布之间的
K
L
KL
KL散度为:
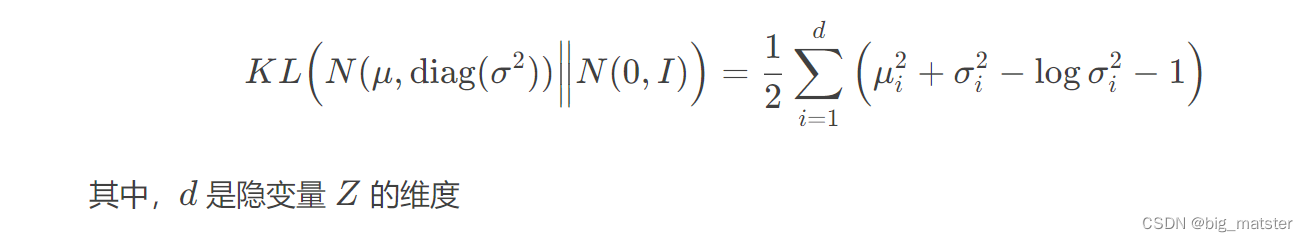
VAES的数学公式细节


QA
Q1: 为什么 encoder 输出的 z zz 不能是高维张量,比如 256 × 32 × 32 256\times32\times32256×32×32?
A1: 这是因为我们希望先验分布$ p ( z )$ 是一个多元的、独立的正态分布,那就意味着 encoder 出来的特征是解藕的,各分量相互独立,互不影响。如果**
z
z
z 是一个矩阵甚至高维张量**,看上去似乎没有什么问题,你可能还想 z zz 后面接个 CNN 来 decode,但是要注意,如果一旦使用 CNN(或 RNN),那么就相当于假设了 z zz 具有局部相关性(如果局部没有联系,那么使用 CNN 就没意义了),但是这就违反了 z zz 的各分量相互独立的假设了。也就是说,encoder 出来的结果不能是一个高维张量并且 decoder 的第一层就对这个高维张量用 CNN,一般情况下 z zz 必须是向量,然后对 z zz 进行处理后(上采样,或者简单接多个并行的全连接得到一个矩阵输出)才能接 CNN 进行 decode
Q2: 为什么隐变量的先验分布用高斯分布而不是均匀分布?
A2: 这是因为 KL 散度有一个比较明显的问题,就是当 q ( x ) q(x)q(x) 在某个区域等于 0,而 p ( x ) p(x)p(x) 在该区域不等于 0,那么 KL 散度就出现无穷大。这是 KL 散度的固有问题,我们只能想办法规避它,比如隐变量的先验分布我们用高斯分布而不是均匀分布。对于正态分布来说,所有点的概率密度都是非负的,因此不存在这个问题。但对于均匀分布来说,只要两个分布不一致,那么就必然存在 p ( x ) ≠ 0 p(x)≠0p(x)
=0 而 q ( x ) = 0 q(x)=0q(x)=0 的区间,因此 KL 散度会无穷大。当然,写代码时我们会防止这种除零错误,但依然避免不了 KL loss 占比很大,因此模型会迅速降低 KL loss,也就是后验分布 p ( Z ∣ X ) p(Z|X)p(Z∣X) 迅速趋于先验分布 p ( Z ) p(Z)p(Z),而噪声和重构无法起到对抗作用,encoder 无法区分哪个 z zz 对应哪个 x xx 了。当然,非得要用均匀分布也不是不可能,就是算好两个均匀分布的 KL 散度,然后做好除零错误处理,加大重构 loss 的权重,等等~但这样就显得太丑陋了
Variational inference formulation

一种给定概率分布簇中寻找复杂概率分布的最佳近似概率分布方法。其中误差度量为
K
L
KL
KL散度。
优化方法采用梯度下降法:使用变分推理来得到后验概率
P
(
z
∣
x
)
P(z|x)
P(z∣x)
的近似概率分布
q
x
(
z
)
q_x(z)
qx(z),其中概率分布簇为协方差矩阵为对角矩阵的正太分布。规定近似概率分布的协方差矩阵
h
(
x
)
h(x)
h(x)必为对角矩阵时为了便于模型训练。牺牲变分推理近似精度,来换取计算开销降低。在此条件下, encoder只输出,
n
n
n个标准差,而不需要输出一个完整的协方差矩阵。
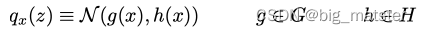
因此优化问题如下:




Bringing neural networks into the model


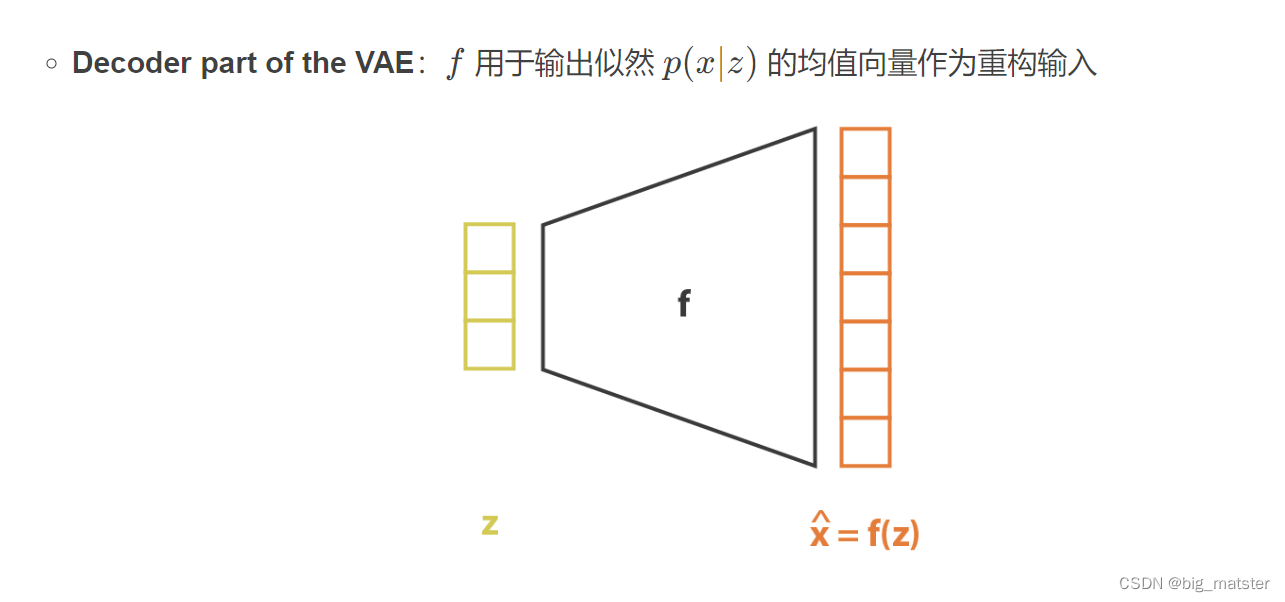


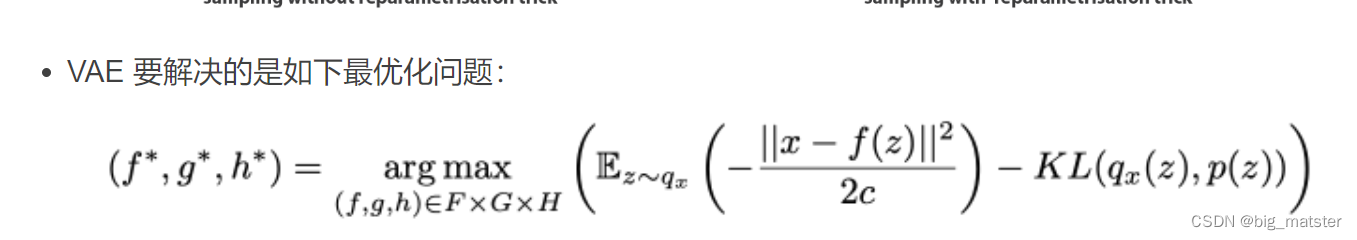


从联合分布近似来理解VAE

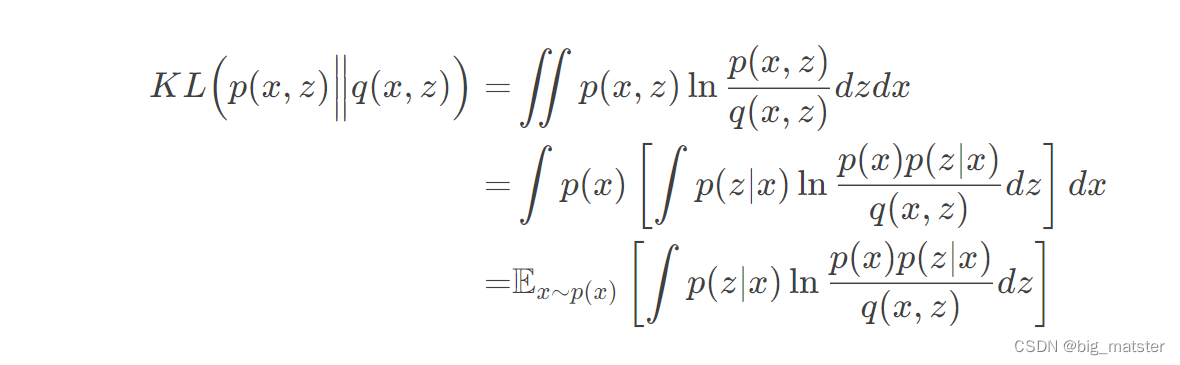
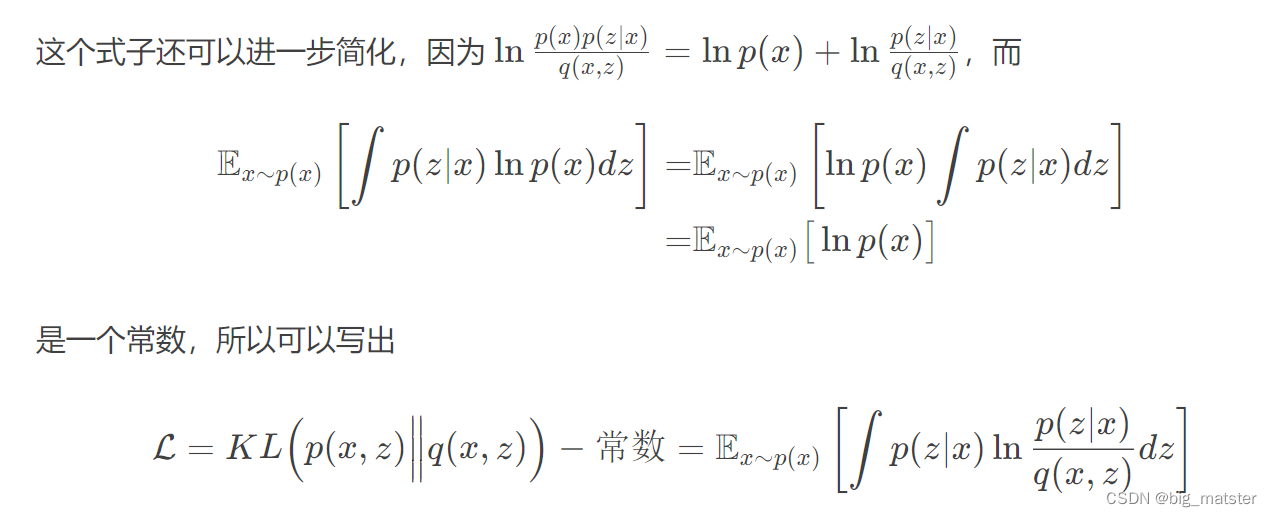

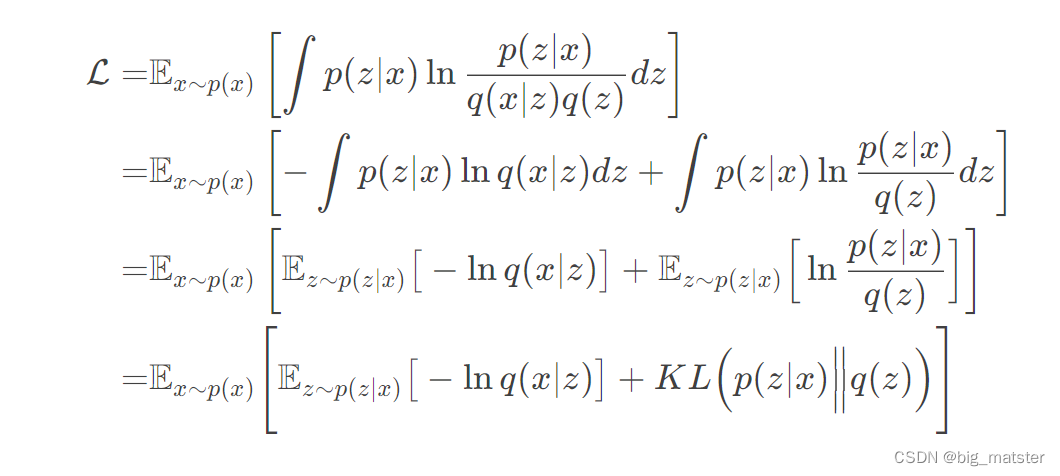

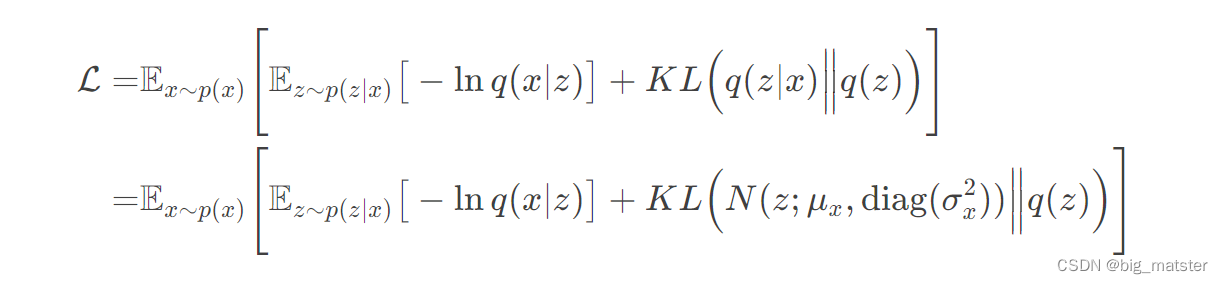



可以看出,此时重构损失就是二分类交叉熵损失。并欸重构损失和KL损失权重为1.

从最大似然来理解VAE
从最大似然角度也可以得到VAE的损失函数:
最大似然角度来理解VAE并提出模型概览
可以看到,前两项即为VAE的优化目标。后一项一定大于等于0,因此VAE的优化目标为对数似然的一个下界。
cVAE
下面考虑一种最简单的VAE结构,其通过调整先验概率
p
(
z
)
p(z)
p(z),来引入标签的条件信息。具体而言,我们希望同一个类的样本都有一个专属均值
μ
Y
\mu_{Y}
μY(方差不变,还是单位方差)
这个让模型自己训练起来,这样的话,有多少个类就有多少个正太分布。而在生成的时候,我们都可以通过控制均值来控制审生成图像的类别。上述cVAE只需通过修改
K
L
l
o
s
s
KL loss
KLloss类别实现:
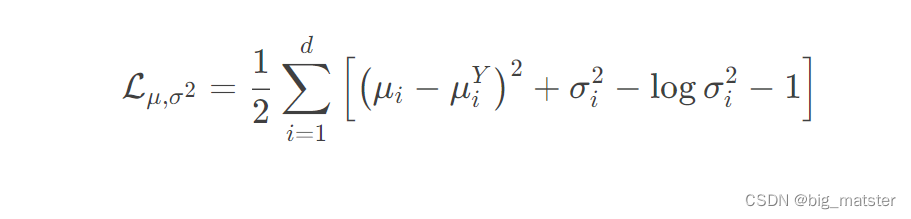
总结
慢慢的通过自己理解来学习VAE的模型,并将该model啥的全部都将其搞清楚,慢慢的学习各种model的
以及会自己复现论文,将各种论文啥的都复现一波,全部都将其搞定,研究彻底都行啦的样子与打算。慢慢的各种论文都研究彻底,研究透彻都行啦的样子与打算。
自己慢慢的研究各种modela.





![[附源码]Python计算机毕业设计高校辅导员工作管理系统](https://img-blog.csdnimg.cn/4c27509c5c9a49daa7bc97df794b9968.png)