目录
前言
1、如何开启使用慢查询日志?
1.1 开启慢查询日志
1.2 设置慢查询阈值
1.3 确定慢查询日志的文件名和路径
1.3.1 查询MySQL数据目录
1.3.2 查询慢查询日志文件名
1.3.3 查询全局设置变量
1.3.4 查询单个变量命令
1.3.5 其他注意事项
2、如何定位并优化慢查询SQL?
2.1 慢查询例子演示
2.1.1 慢查询日志 查看执行语句与Query_time参数实际执行时间
2.1.2 其他注意事项
2.2、查询语句慢怎么办?explain分析sql执行计划
2.2.1 explain分析一下执行计划
2.2.2 select_type值表
2.2.3 type列,本文是ALl则是全表扫描
2.2.4 Extra列,这里是Using filesort
2.2.5 使用索引之后查看慢查询日志发现,查询数据的速度快了2s
2.2.6 实操练习联调索引与未添加索引 查询速度对比
3、当主键索引、唯一索引、普通索引都存在,查询优化器如何选择?
前言
简短总结即开启MySQL慢查询日志开关和并设置预期阀值,查看已记录超过预期阀值时间的日志记录慢的语句和时间,查看现有查询策略然后设置索引,尝试优化查询语句并对比查询结果耗时最终得到最优解。

1、如何开启使用慢查询日志?
1.1 开启慢查询日志
首先开启慢查询日志(默认关闭),在MySQL命令行下输入下面的命令:
MySQL > set global slow_query_log=on;1.2 设置慢查询阈值
SQL实际执行时间超过设置阈值就会被记录到慢查询日志里面。阈值默认是10s,线上业务一般建议把long_query_time设置为1s,如果某个业务的MySQL要求比较高的QPS,可设置慢查询为0.3s。
MySQL > set global long_query_time=1;1.3 确定慢查询日志的文件名和路径
1.3.1 查询MySQL数据目录
MySQL > show global variables like 'datadir';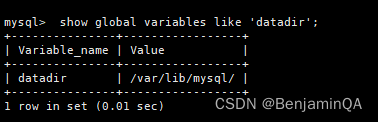
1.3.2 查询慢查询日志文件名
MySQL > show global variables like 'slow_query_log_file'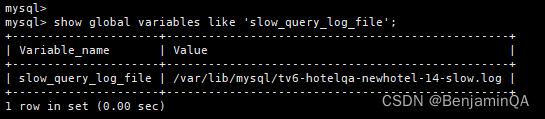
1.3.3 查询全局设置变量
MySQL > show global variables like '%quer%';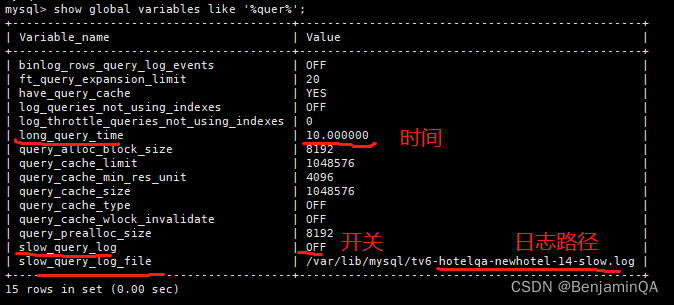
1.3.4 查询单个变量命令
MySQL > show status like '%slow_queries%';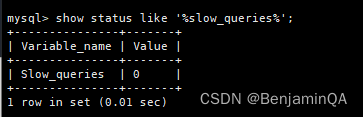
1.3.5 其他注意事项
发现慢查询及时优化或者提醒开发改写。一般测试环境建议long_query_time设置的阀值比生产环境的小,比如生产环境是1s,则测试环境建议配置成0.5s。便于在测试环境及时发现一些效率的SQL。 甚至某些重要业务测试环境long_query_time可以设置为0,以便记录所有语句。并留意慢查询日志的输出,上线前的功能测试完成后,分析慢查询日志每类语句的输出,重点关注Rows_examined(语句执行期间从存储引擎读取的行数)提前优化。
重启mysql客户端设置和统计慢查询日志条数就会清零,即所有命令配置修改会还原。在配置文件修改才能永久改变,否则重启数据库就还原。
2、如何定位并优化慢查询SQL?
1. 根据慢日志定位慢查询sql
2. 使用explain等工具分析sql执行计划
3. 修改sql或者尽量让sql走索引
2.1 慢查询例子演示
2.1.1 慢查询日志 查看执行语句与Query_time参数实际执行时间
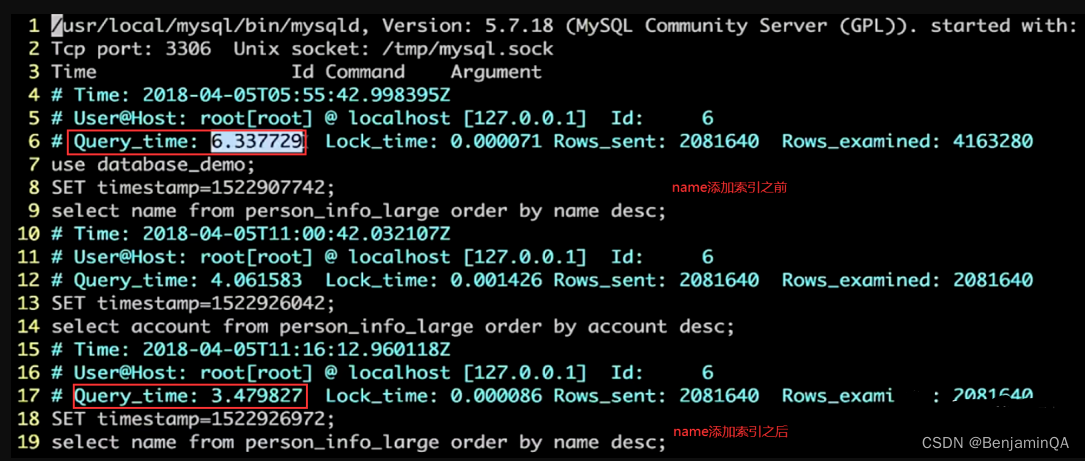
Linux > tail -n 500 /var/lib/ mysql/tv6 -hote lqa-newhotel-14-slow.log查询结果Query_time: 6.337729s,SQL执行时间超过了1s故被记录了,第9行为执行语句。
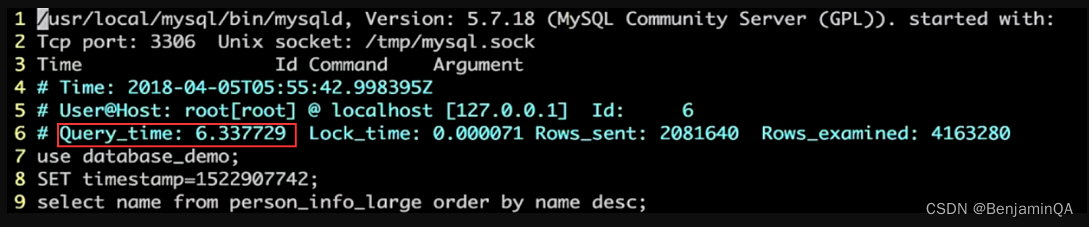
其他参数说明:
Time:慢查询发生的时间
Query_time:查询时间
Lock_time:等待锁表的时间
Rows_sent:语句返回的行数
Rows_exanined:语句执行期间从存储引擎读取的行数
2.1.2 其他注意事项
上述方式是用系统自带的慢查询日志查看,系统自带的慢查询日志不方便查看,可使用 pt-query-digest 或者 mysqldumpslow 等工具对慢查询日志进行分析。
部分慢查询正在执行结果已经导致数据库负载过高,而由于慢查询还没执行完,因此慢查询日志看不到任何语句,此时可以使用 show processlist 命令查看正在执行的慢查询。show processlist显示哪些线程正在运行,如果有PROCESS权限,则可以看到所有线程。否则只能看到当前会话线程。
2.2、查询语句慢怎么办?explain分析sql执行计划
2.2.1 explain分析一下执行计划
> explain select group_name from groups order by group_name desc;
2.2.2 select_type值表
| 序号 | Column | 描述 |
|---|---|---|
| 1 | SIMPLE | 简单查询(不使用UNION或子查询) |
| 2 | PRIMARY | 主查询、外查询 |
| 3 | UNION | UNION中第二个语句或后面的语句 |
| 4 | UNION RESULT | UNION每个结果集的取出来后,进行合并操作 |
| 5 | DEPENDENT SUBQUERY | 子查询中第一个SELECT |
| 6 | DEPENDENT UNION | 子查询中的UNION操作,从UNION 中第二个及之后的所有SELECT语句 |
| 7 | DERIVED | 派生表,子查询在 FROM子句中 |
| 8 | MATERIALIZED | 被物化的子查询 |
| 9 | UNCACHEABLE SUBQUERY | 一个子查询的结果不能被缓存,必须重新评估外层查询的每一行 |
| 10 | UNCACHEABLE UNION | 关联查询第二个或后面的语句属于不可缓存的子查询 |
2.2.3 type列,本文是ALl则是全表扫描
| 序号 | Type值 | 描述 |
| 1 | system | 查询对象表只有一行数据,且只能用于 MySAM 和 Memory 引擎的表,这是最好的情况 |
| 2 | const | 基于主键或唯一索引查询,最多返回一条结果 |
| 3 | eq_ref | 表连接时基于主键或非 NULL 的唯一索引完成扫描 |
| 4 | ref | 基于普通索引的等值查询,或者表间等值连接 |
| 5 | fulltext | 全文检索 |
| 6 | ref_or_null | 表连接类型是 ref,但进行扫描的索引列中可能包含 NULL 值 |
| 7 | index_merge | 利用多个索引 |
| 8 | unique_subquery | 子查询中使用唯一索引 |
| 9 | index_subquery | 子查询中使用普通索引 |
| 10 | range | 利用索引进行范围查询 |
| 11 | index | 全索引扫描 |
| 12 | ALL | 全表扫描 |
表格从上到下代表了sql查询性能从最优到最差,如果是type类型是all,说明sql语句需要优化。
说明:如果type = NULL,则表明个MySQL不用访问表或者索引,直接就能得到结果,比如explain select sum(1+2);
possible_keys代表可能用到的索引列,key表示实际用到的索引列,以实际用到的索引列为准,这是查询优化器优化过后选择的,然后我们也可以根据实际情况强制使用我们自己的索引列来查询。
2.2.4 Extra列,这里是Using filesort
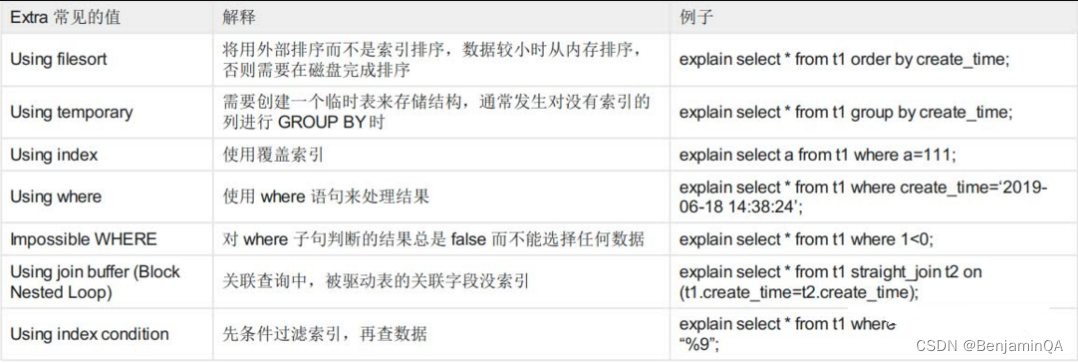
一定要注意,Extra中出现Using filesort、Using temporary代表MySQL根本不能使用索引,效率会受到严重影响,应当尽可能的去优化。
出现Using filesort说明MySQL对结果使用一个外部索引排序,而不是从表里按索引次序读到相关内容,有索引就维护了B+树,数据本来就已经排好序了,这说明根本没有用到索引,而是数据读完之后再排序,可能在内存或者磁盘上排序。也有人将MySQL中无法利用索引的排序操作称为“文件排序”。出现Using temporary表示MySQL在对查询结果排序时使用临时表,常见于order by和分组查询group by。
2.2.5 使用索引之后查看慢查询日志发现,查询数据的速度快了2s
MySQL > select name from person_info_large order by name desc;
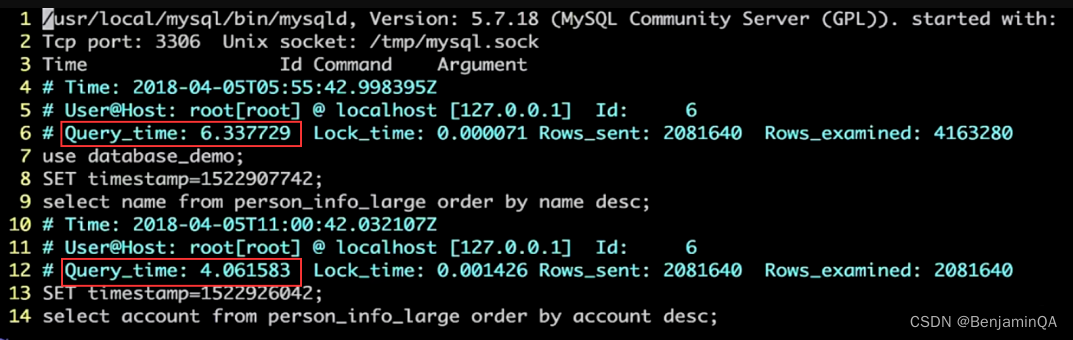
2.2.6 实操练习联调索引与未添加索引 查询速度对比
// 添加索引
MySQL > alter table person_ info_ large add index idx_ name(name);
// 查看执行计划
MySQL > explain select name from person_info_large order by name desc;
// 执行查询语句
MySQL > select name from person_ info_large order by name desc;对比一下前面name不加索引时的执行计划就会发现,加了索引后,type由ALL全表扫描变成index索引扫描。order by并没有 using filesort,而是using index,这里B+树已经将这个非聚集索引的索引字段的值排好序了,而不是等到查询的时候再去排序。
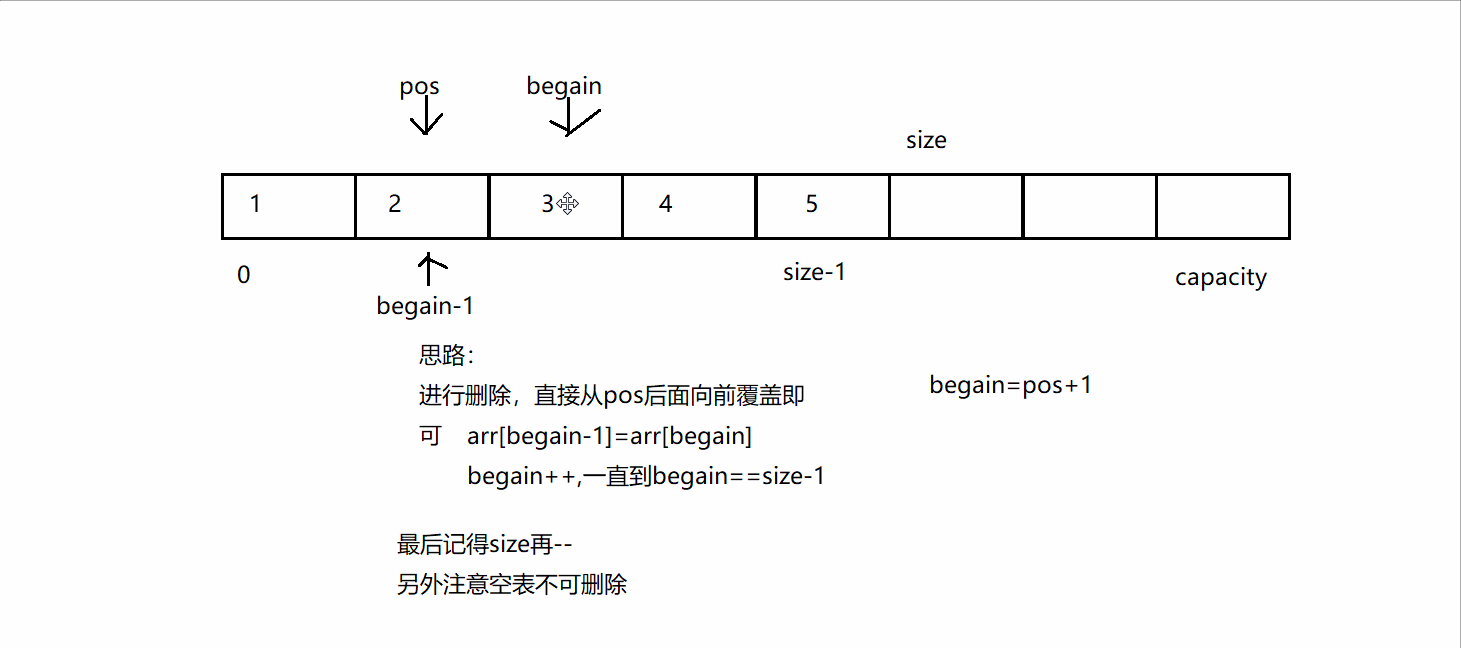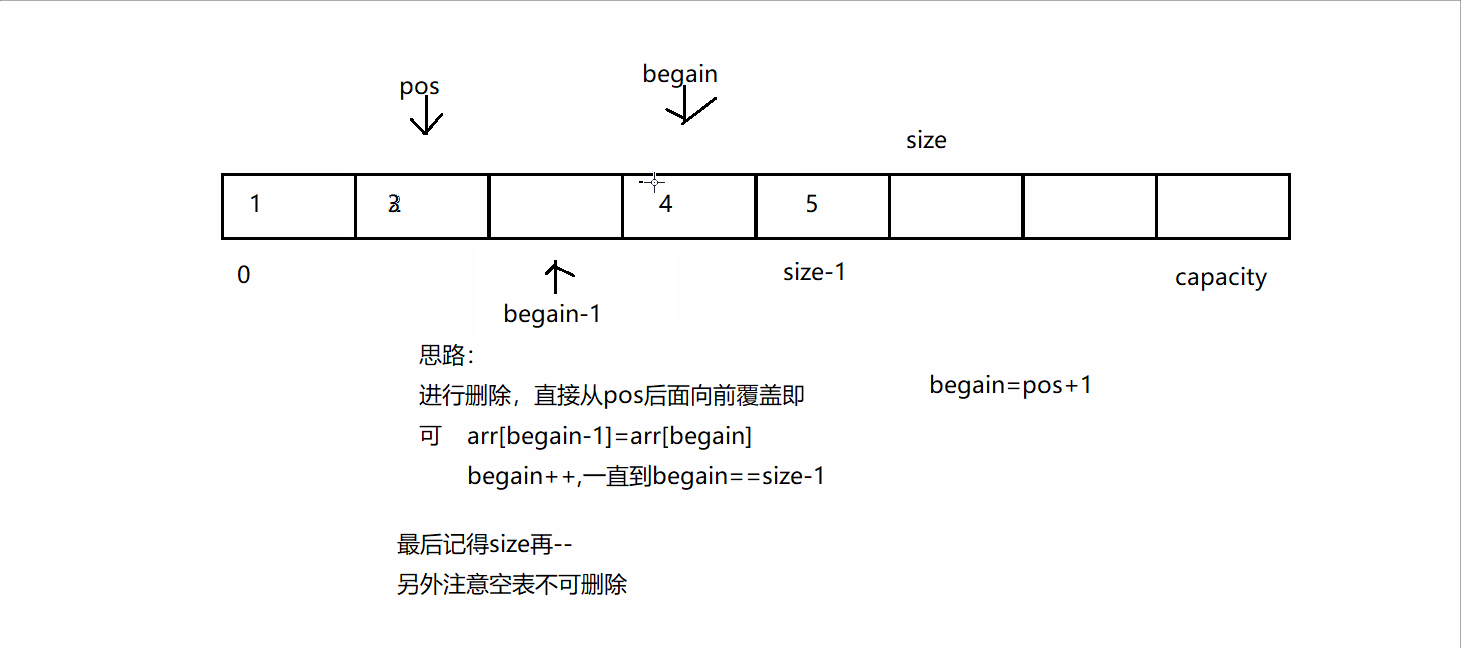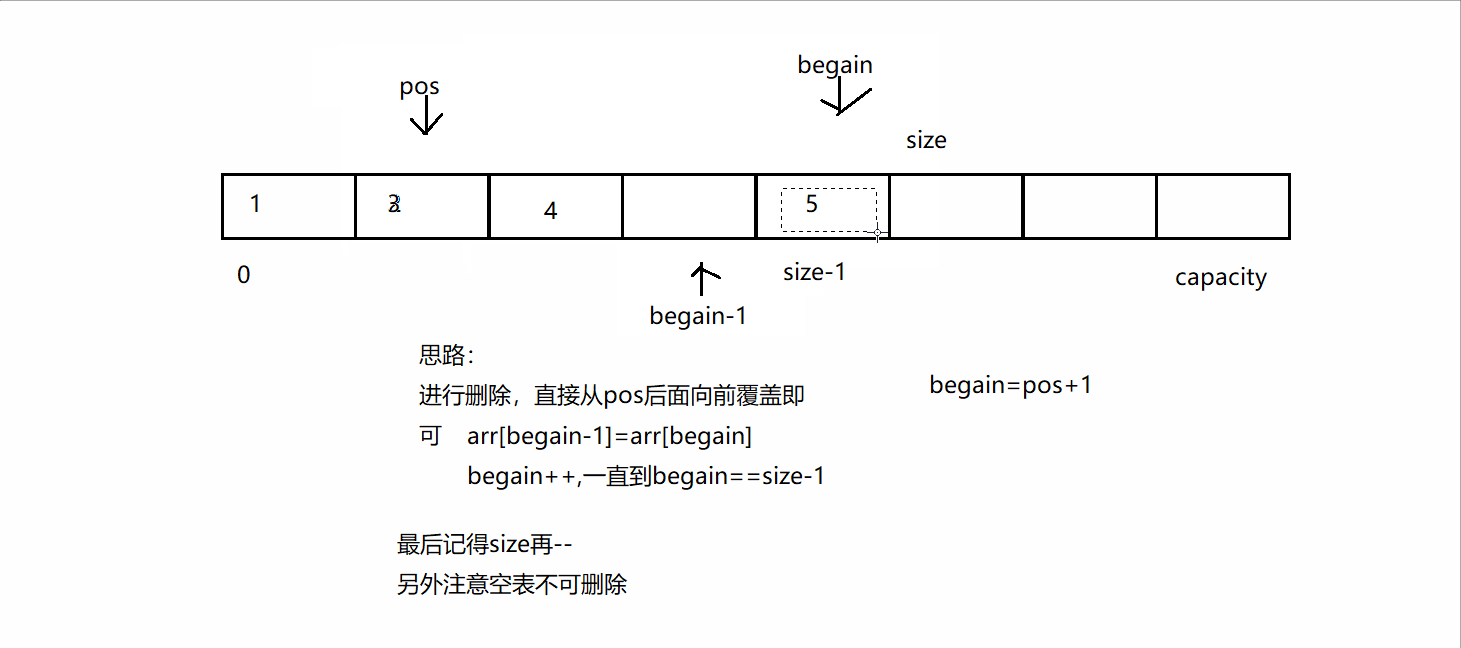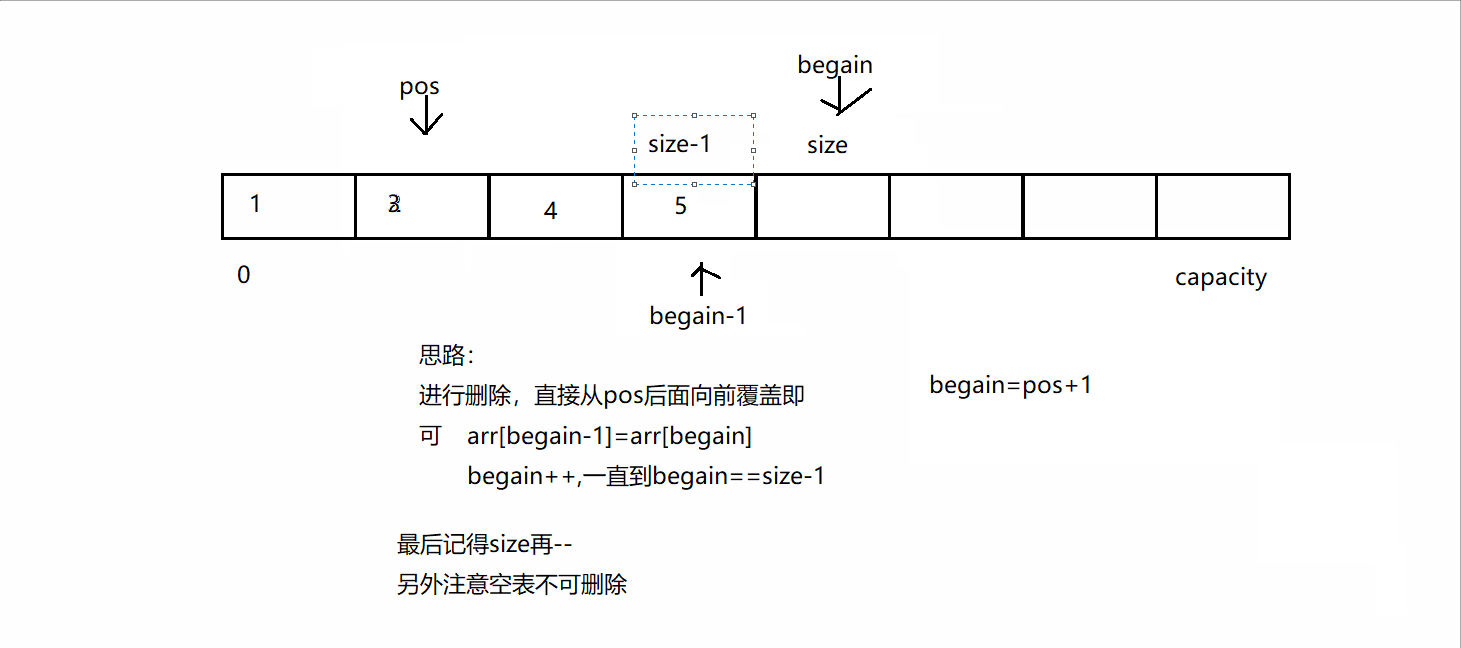
3、当主键索引、唯一索引、普通索引都存在,查询优化器如何选择?
实际使用哪个索引是查询优化器决定的,B+树的叶子结点就是链表结构,遍历链表就可以统计数量,但是这张表,有主键索引、唯一索引、普通索引,优化器选择了account这个唯一索引,这肯定不会使用主键索引,因为主键索引是聚集索引,每个叶子包含具体的一个行记录(很多列的数据都在里面),而非聚集索引每个叶子只包含下一个主键索引的指针,很显然叶子结点包含的数据是越少越好,查询优化器就不会选择主键索引。
// 强制使用主键索引,然后分析sql执行计划
MySQL > explain select count(id) from person_ info large force index (primary);
// 优化器默认使用唯一索引大致执行时间
MySQL > select count(id) from person_info_large;
// 强制使用主键索引大致执行时间
MySQL > select count(id) from person_info_large force index (primary);
使用 force index 强制指定索引,然后去分析执行计划看看哪个索引是更好的,因为查询优化器选择索引不一定是百分百准确的,具体情况可以根据实际场景分析来确定是否使用查询优化器选择的索引。





![[足式机器人]Part3机构运动微分几何学分析与综合Ch02-3 平面机构离散运动鞍点综合——【读书笔记】](https://img-blog.csdnimg.cn/8ff87b007ee64973ae5d2ad3fc56e331.png)


![[附源码]java毕业设计中小企业人力资源管理系统](https://img-blog.csdnimg.cn/b9bf0f1de8db4079bb2ac3fdaaaff4d2.png)