作者:几冬雪来
时间:2023年3月5日
内容:数据结构链表讲解
目录
前言:
剩余的链表应用:
1.查找:
2.改写数据:
3.在pos之前插入数据:
4.pos位置删除:
5.在pos的后面插入:
6.pos后面进行删除:
7.代码:
结尾:
前言:
在上一篇博客中,我们初步认识了C语言,还完成了对链表初始化,头删头插和尾插尾删的代码书写和说明。并且对链表中代码书写过程可能会遇到的坑进行了讲解,最后还进行了链表与顺序表之间的对比。这让我们对链表了解了不少,但是链表的内容并没有结束,这篇博客我们将进一步的了解链表。

剩余的链表应用:
在上一篇博客中,我们讲解了链表的初始化,头插头删等四种应用方法,但是和顺序表一样,链表也不只这几种应用而已。那么今天我们将会将链表剩下的程序都讲完。
1.查找:
首先就是在链表中查找一个数据,链表查找数据和顺序表查找数据的方法是异曲同工的,也就是暴力查找,这里就不进行过多的说明,直接上代码。
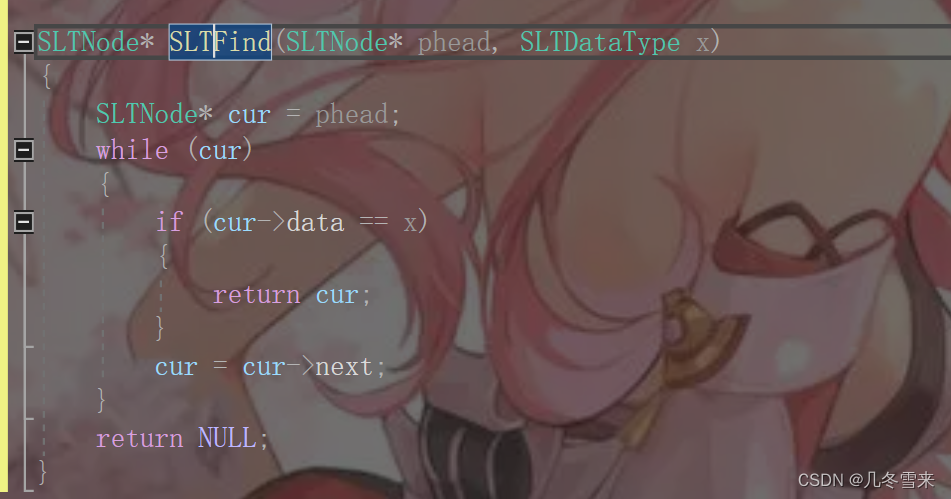
这个就是我们查找值的代码,先把phead的值赋给我们创立的cur,接下来写一个循环来判断,再后来在循环中嵌套一个判断语句。如果cur->data为我们要寻找的值,那么就可以直接返回cur的地址,第一次没有找到的话就让cur->next并赋值给cur。相反,如果整个链表都遍历完了还是没有找到那个值,这里就直接返回空。
2.改写数据:
在书写完了查找数据的代码,接下来就是增删查改中的改,也就是改写数据。但是这里改写数据并不用写一个全新的代码,我们可以沿用上面查找数据的代码,并对其略微进行添加和修改。
这里就需要我们先在链表中找到那个值后,对其进行修改,这就是修改链表数据的方法。
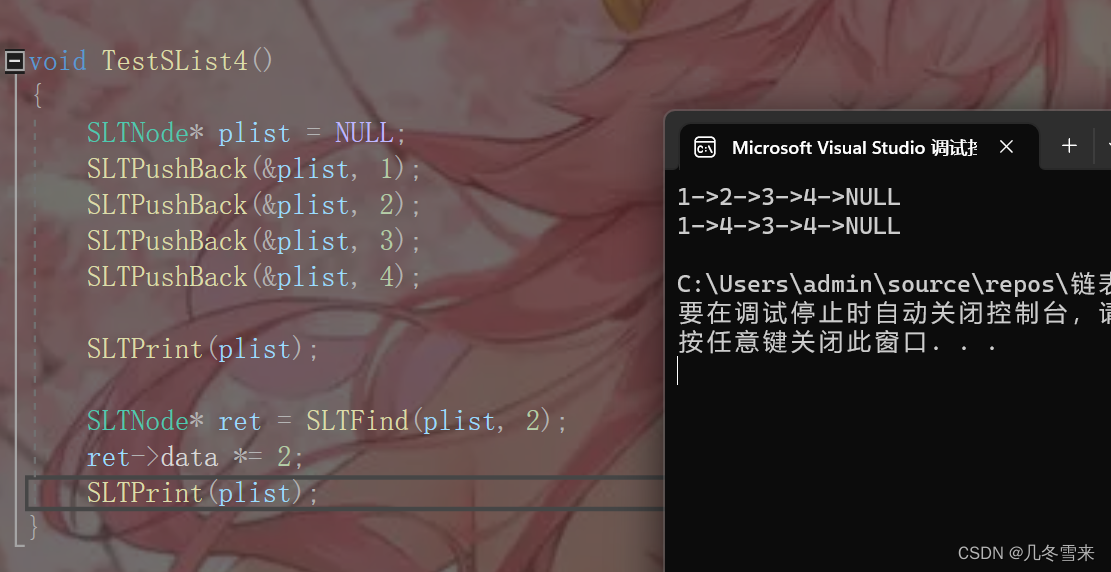
3.在pos之前插入数据:
讲解完了两个较清楚的代码之后,我们来讲在pos之前插入数据的方法。

既然了解了原理,那么下来就开始着手代码的书写了。
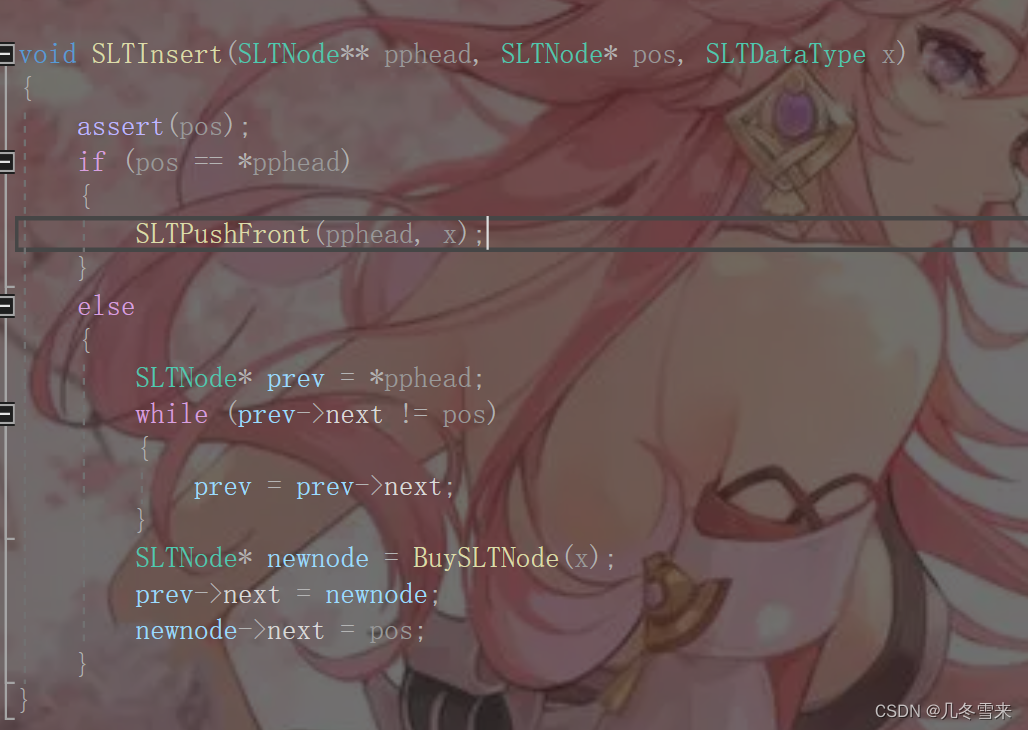
首先代码一进去就需要对其断言,如果pos传了一个我们没有的值,那么代码下面的prev->next的循环条件就一直不满足,最后会访问到空指针。
如果我们的pos的地址和pphead的地址一致的话,那么这里就相当于头插操作。要是不一致的话,我们先创建一个指针指向第一个结点的位置。而后进行判断,prev->next不为pos的时候,prev进行修改赋值,这里找到的为pos的前一个值。
剩下的就更加简单了,找到pos前一个值后,我们想创立一个新结点,并命名为newnode。
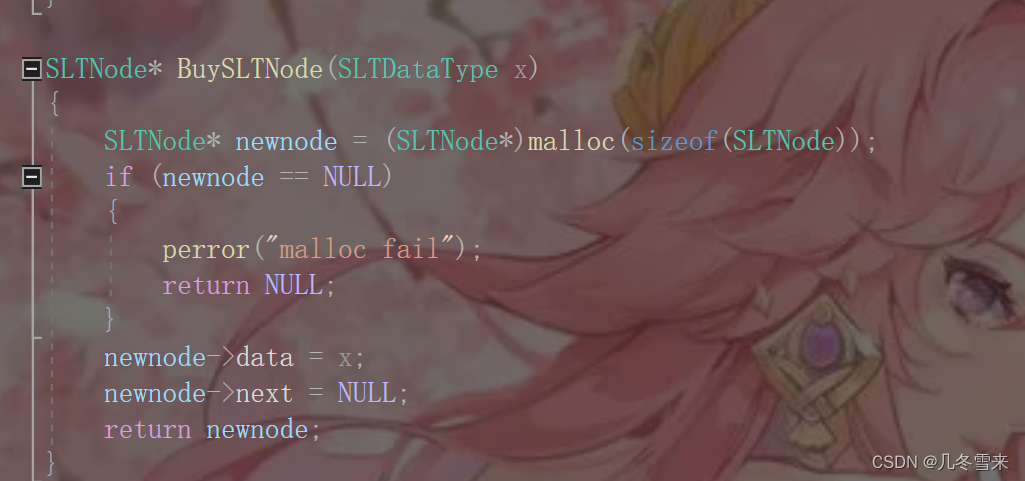
然后让我们原先上一个结点的next指向这个新结点的地址。有因为创建结点的时候,newnode->next为0,因此这里要将pos给newnode->next,使它指向pos。
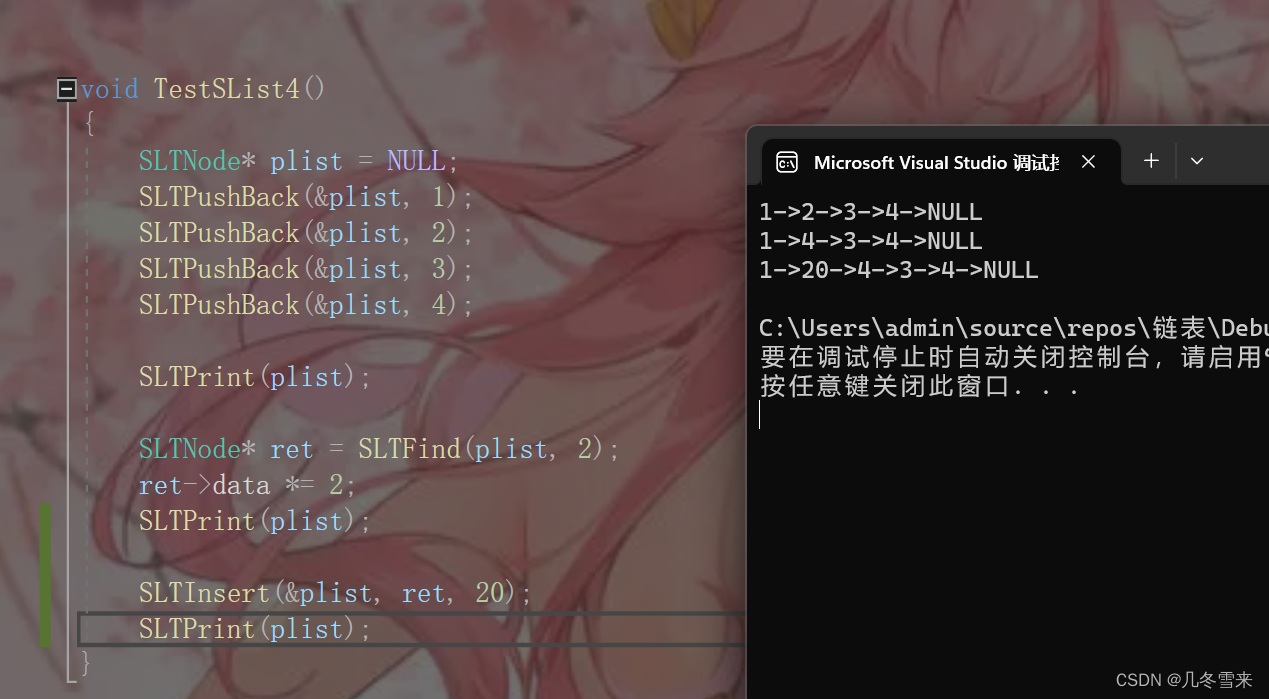
这里就将我们4之前(第一个4)插入一个值为20的结点。
那么在我们插入代码的过程中,只需要对pos进行断言吗?其实不止,在这里不仅仅要对pos进行断言,而且还要对pphead进行断言。

这是为什么呢?还记得我们的**pphead是指向指针plist的地址,那么如果plist为空的话,pphead会为空吗?这里是一定不会的,为什么?我们画一张图来了解一下。

这里plist为指针,如果plist为空的话。但是在这里的**pphead为指针,存放的是plist这个值的地址,即使plist为空但是它还是有地址的存在,地址不为空。
在数据结构中,断言的操作并没有什么规律可循,我们只要知道当我们一个值一定不能为空的时候要进行断言。
既然知道了这个道理,那我们上面的头删尾删等涉及到pphead的地方都应该进行断言,为的是防止我们传错。
4.pos位置删除:
下一个就是我们pos位置的删除,有了上面的基础,一开始我们就要对其进行断言。
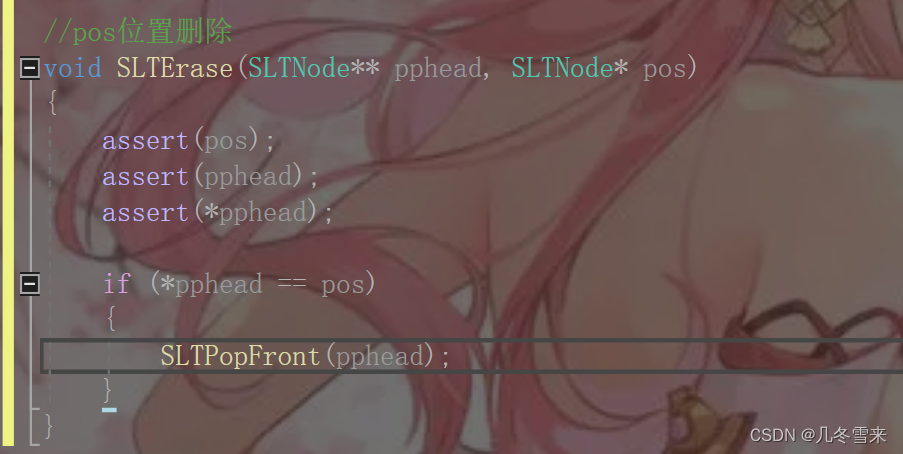
这里如果指针pos等于pphead,pphead指向第一个结点的地址,那么这个时候这里就相当于我们的头删操作了。
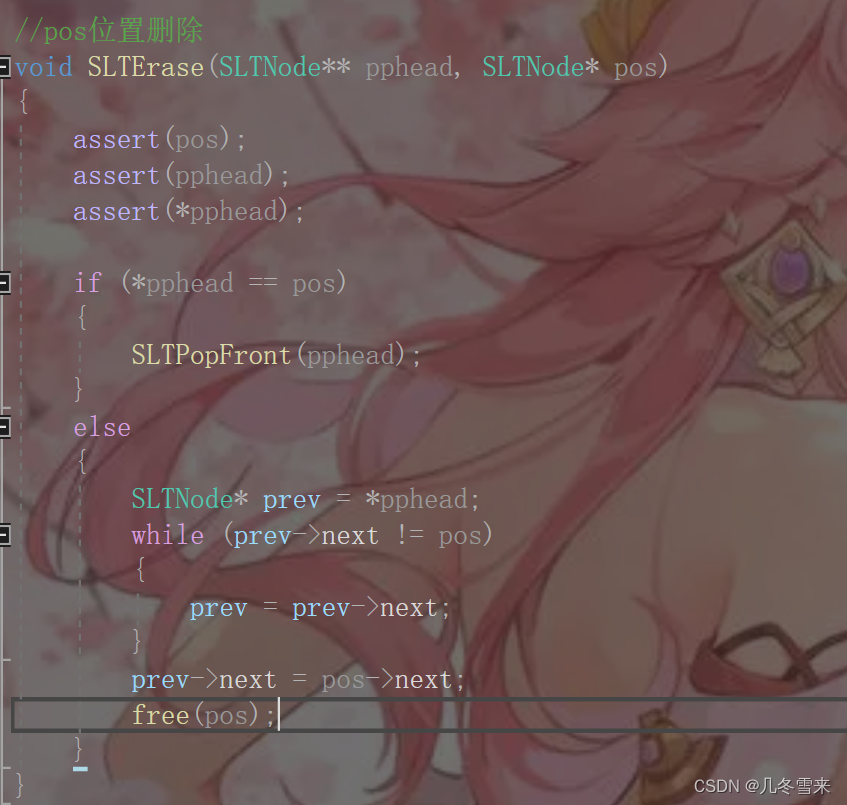
如果这里的pos不为头结点的地址,那么就进入另一个分支语句。将头结点的位置赋值给新创立的一个指针prev,如果prev->next不为我们要的值,那就对prev进行修改,找到以后将我们pos->next也就是pos下一个结点的地址给pos上一个结点的next,最后将pos进行释放即可。
这里将pos释放之后,我们可以不用将它置为空。因为我们的pos是语句局部变量,形参的改变不影响实参。
在这里我们pos置空的操作在这里进行即可。
通过书写上面代码我们发现,单链表其实不太适合进行前面插入和删除当前位置,我们的单链表更适合后面插入或者删除后面位置。
5.在pos的后面插入:
在这里我们知道在单链表中不太适合进行前面插入和删除当前位置,我们通常运用的是后面插入和删除后面位置的值。那么现在就先来讲解——在pos的后面插入的代码是怎么样写的。
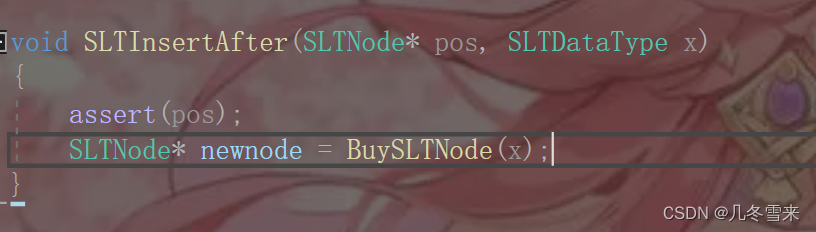
首先还是我们的断言,并且创建一个新的结点来进行插入操作。
那么我们的代码是怎么样进行的呢?
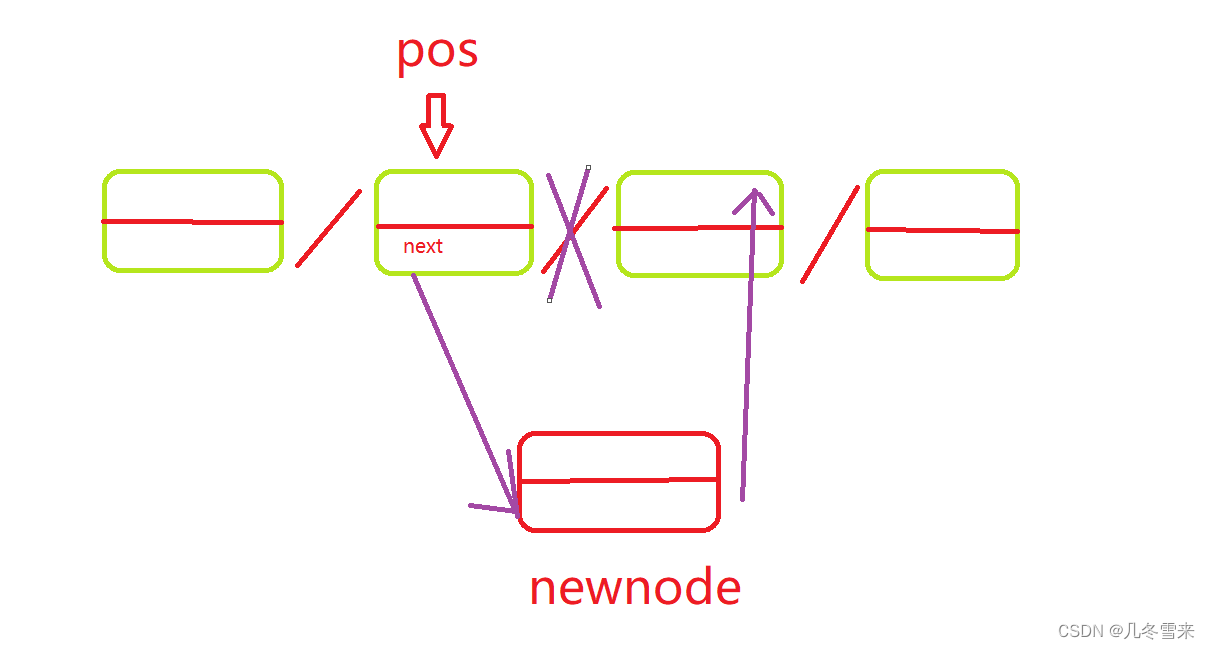
这里就是单链表pos后面插入一个值的方法,但是有一部分人跟着这个图写代码却掉进坑里,这又是怎么回事? 我们将它们的代码写出:
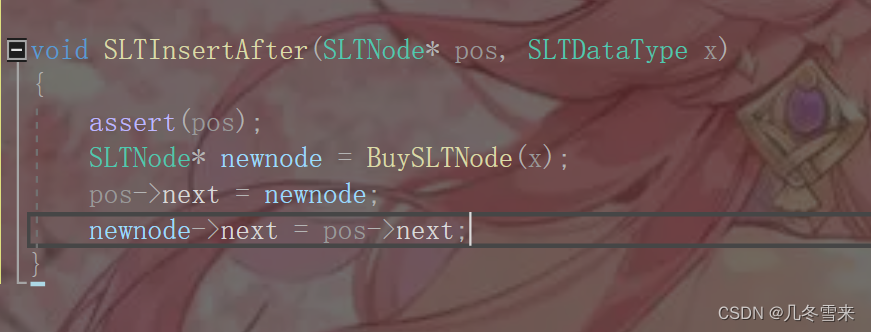
这个代码大家看得出来哪里出错了吗?我们来看一看,在创建新结点后,newnode的值赋值给pos->next,这里的next就是指向我们newnode的值,而后再把原pos->next,也就是我们插入后newnode后面的一个结点,我们将它的地址交给newnode。
看似一切都没有问题,逻辑上说得通,且看样子貌似可以运行,但是实际上这个代码是错误的。
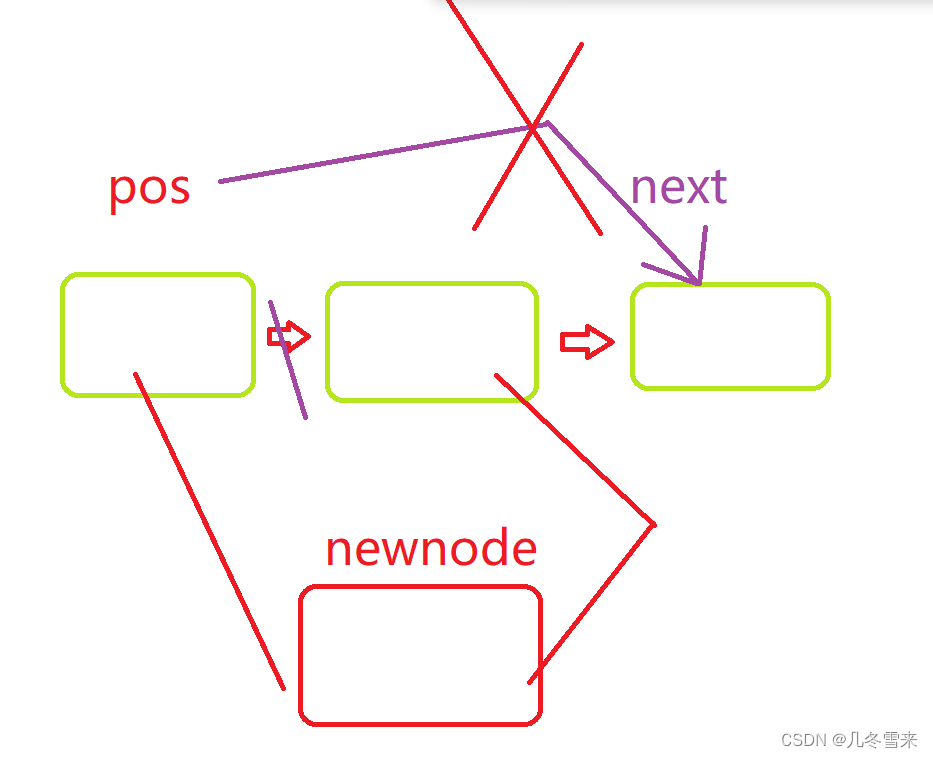
在这个代码中,我们pos->next指向我们的新结点这一步是没有错误的,那么报错的就是我们接下来的一步了,这里代码的pos的next原本指向的是未修改前下一个结点的地址,但是在上一步我们在上一步就另我们的pos->next指向我们的新结点,因此这里的pos->next的赋值已经不是原来的值。
那我们的代码要怎么修改,其实很简单。
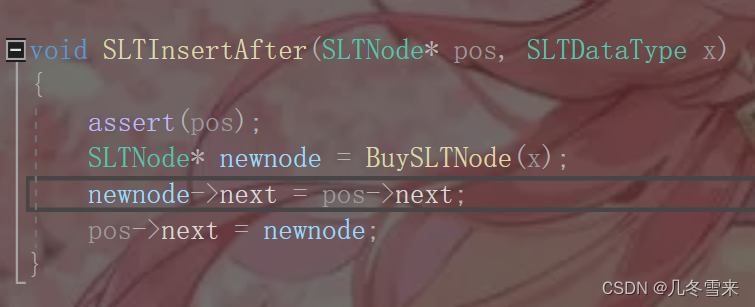
我们只需要将两个代码的书写顺序调换一下即可,这里也提醒我们写代码要注意它的执行顺序。
6.pos后面进行删除:
接下来就是我们的pos后面进行删除,删除的代码相较于插入的代码可能还要更简单一点。
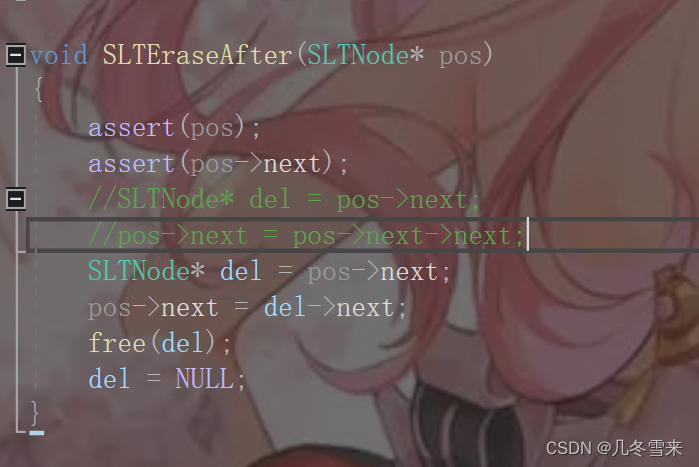
在这里我们仅需要注意要将我们删除的值先进行一次保留,如果直接pos->next=pos->next->next的话,中间那个元素就会被省略掉。
7.代码:
到这里我们的链表内容基本结束了,在最后我将所有的代码写上。
SList.h文件
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
void SLTPrint(SLTNode* phead);
void SLTPushBack(SLTNode** pphead,SLTDataType x);
void SLTPushFront(SLTNode** pphead, SLTDataType x);
void SLTPopBack(SLTNode** pphead);
void SLTPopFront(SLTNode** pphead);
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
void SLTErase(SLTNode** pphead, SLTNode* pos);
//pos后面插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
//pos位置后面删除
void SLTEraseAfter(SLTNode* pos);test.c文件
#include "SLish.h"
//void TestSList1()
//{
// SLTNode* plist = NULL;
// SLTPushBack(&plist, 1);
// SLTPushBack(&plist, 2);
// SLTPushBack(&plist, 3);
// SLTPushBack(&plist, 4);
//
// SLTPrint(plist);
//}
//void TestSList2()
//{
// SLTNode* plist = NULL;
// SLTPushFront(&plist, 1);
// SLTPushFront(&plist, 2);
// SLTPushFront(&plist, 3);
// SLTPushFront(&plist, 4);
// SLTPrint(plist);
//
// SLTPopBack(&plist);
// SLTPrint(plist);
//
// SLTPopBack(&plist);
// SLTPrint(plist);
//
// SLTPopBack(&plist);
// SLTPrint(plist);
//}
//void TestSList3()
//{
// SLTNode* plist = NULL;
// SLTPushBack(&plist, 1);
// SLTPushBack(&plist, 2);
// SLTPushBack(&plist, 3);
// SLTPushBack(&plist, 4);
//
// SLTPrint(plist);
//
// SLTPopFront(&plist);
// SLTPrint(plist);
//
// SLTPopFront(&plist);
// SLTPrint(plist);
//
// SLTPopFront(&plist);
// SLTPrint(plist);
//
// SLTPopFront(&plist);
// SLTPrint(plist);
//}
//void TestSList4()
//{
// SLTNode* plist = NULL;
// SLTPushBack(&plist, 1);
// SLTPushBack(&plist, 2);
// SLTPushBack(&plist, 3);
// SLTPushBack(&plist, 4);
//
// SLTPrint(plist);
//
// SLTNode* ret = SLTFind(plist, 2);
// ret->data *= 2;
// SLTPrint(plist);
//
// SLTInsert(&plist, ret, 20);
// SLTPrint(plist);
//}
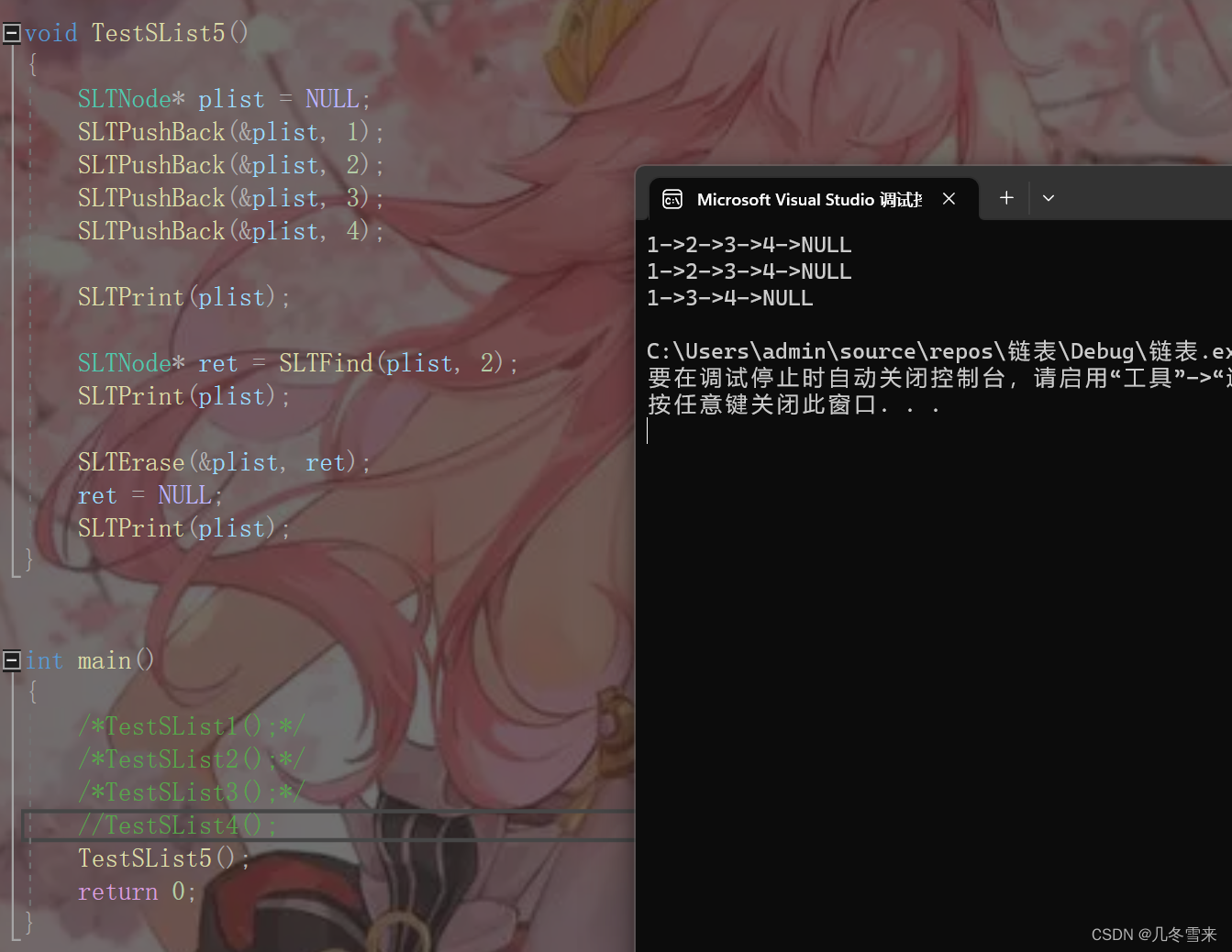
void TestSList5()
{
SLTNode* plist = NULL;
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
SLTPushBack(&plist, 4);
SLTPrint(plist);
SLTNode* ret = SLTFind(plist, 2);
SLTPrint(plist);
SLTErase(&plist, ret);
ret = NULL;
SLTPrint(plist);
}
int main()
{
/*TestSList1();*/
/*TestSList2();*/
/*TestSList3();*/
//TestSList4();
TestSList5();
return 0;
}SList.c文件
#include "SLish.h"
void SLTPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur != NULL)
//while(cur)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
SLTNode* BuySLTNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail");
return NULL;
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
void SLTPushBack(SLTNode** pphead,SLTDataType x)
{
assert(pphead);
/*SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail");
return;
}
newnode->data = x;
newnode->next = NULL;*/
SLTNode* newnode = BuySLTNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuySLTNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
void SLTPopBack(SLTNode** pphead)
{
assert(pphead);
assert(*pphead);
/*assert(*pphead);*/
if (*pphead == NULL)
{
return;
}
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLTNode* prev = NULL;
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
//while(tail->next->next!=NULL)
//{
// tail = tail->next;
//}
//free(tail->next);
//tail->next = NULL;
free(tail);
tail = NULL;
prev->next = NULL;
}
}
void SLTPopFront(SLTNode** pphead)
{
assert(pphead);
assert(*pphead);
/*assert(*pphead);*/
if (*pphead == NULL)
{
return;
}
SLTNode* first = *pphead;
*pphead = first->next;
free(first);
first = NULL;
}
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pos);
assert(pphead);
if (pos == *pphead)
{
SLTPushFront(pphead, x);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SLTNode* newnode = BuySLTNode(x);
prev->next = newnode;
newnode->next = pos;
}
}
//pos位置删除
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pos);
assert(pphead);
assert(*pphead);
if (*pphead == pos)
{
SLTPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
}
}
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = BuySLTNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);
//SLTNode* del = pos->next;
//pos->next = pos->next->next;
SLTNode* del = pos->next;
pos->next = del->next;
free(del);
del = NULL;
}结尾:
这篇博客的结束也意味着我们在链表方面的知识学习结束了,但是进入了数据结构的学习中,每次学习不再是一次就能吃透,代码的难度都得到了提升,在这种情况下我们更应该反复学习巩固知识。随着难度的提高,我的表达能力一定程度被限制了,这可能会使博客质量会下滑,这一点望理解,最后还是希望这篇对在学习链表的人有所帮助。




![[一篇读懂]C语言十一讲:单链表的删除和单链表真题实战](https://img-blog.csdnimg.cn/9316603659cc4974993d65ce035aa358.png#pic_center)