目录
前言
一、2024博客之星
1、所有排名数据
2、空间属性管理
二、数据抓取与处理
1、相关业务表的设计
2、数据抓取处理
3、空间查询分析实践
三、数据成果挖掘
1、省域分布解读
2、技术开发活跃
四、总结
前言
2024年博客之星的评选活动已经过去了一个月,还记得在网络投票环节中的硝烟四起。非常感谢各位朋友的支持,本人在本次活动中荣获Top28。通过活动看到很多优秀的博主,也看到了自己的不足,2025年希望一如既往地努力。在数字化浪潮席卷全球的今天,博客作为一种信息传播与思想表达的重要载体,早已超越了传统意义上的个人写作平台,成为连接个体与社会、文化与技术的桥梁。从早期的技术博客到如今多元化的内容生态,博客不仅记录了时代的变化,也塑造了人们获取信息、表达观点、参与公共讨论的方式。随着人工智能、短视频等新兴媒介的崛起,博客的形态和功能正在经历深刻的转型。然而,无论技术如何迭代,博客的核心价值——思想的自由表达与知识的广泛传播——始终未变。
在这样的背景下,研究博客之星的省域空间分布,不仅是对当代网络内容生态的一次剖析,更是对区域文化、经济、教育等多维度发展水平的一次映射。本文以2024年全网Top300博客之星为研究对象,试图通过数据可视化与深度分析,揭示博客创作者在地理空间上的分布规律,并探讨其背后的社会动因与文化逻辑。博客之星的评选,是对网络内容创作者影响力、原创性与社会价值的综合认可。这些创作者不仅是信息的传播者,更是文化的塑造者。他们的内容覆盖科技、文学、艺术、教育、商业等多个领域,反映了当代社会的多元需求与价值取向。
从地域分布来看,博客之星的涌现往往与区域的经济发展水平、教育资源分布以及文化氛围密切相关。例如,经济发达地区通常拥有更高的互联网普及率和更强的数字基础设施,这为博客创作者提供了更好的创作环境;而教育资源丰富的地区,则更容易培养出具有批判性思维和表达能力的内容生产者。此外,区域文化特质也对博客内容的风格与主题产生深远影响。例如,沿海地区的博客可能更关注全球化议题,而内陆地区的博客则可能聚焦于本土文化与社会问题。本文试图以地理空间分布的角度来看看技术的空间热点分布。
一、2024博客之星
在过去的 2024 年,博客世界精彩纷呈,各路博主笔耕不辍,用文字编织出无数动人的故事、深刻的见解和实用的知识。如今,我们终于迎来激动人心的 2024 年博客之星年度评选活动,这是一场属于博主们的荣耀盛宴,也是广大用户见证优秀创作者的绝佳机会!
本次评选旨在表彰那些在 2024 年中,凭借独特的视角、优质的内容、创新的形式以及强大的影响力,在博客领域脱颖而出的杰出博主。无论你是在哪个技术领域,只要你在博客世界留下了浓墨重彩的一笔,都有可能成为我们瞩目的 “博客之星”!
以上是博客之星的活动说明,来源于官网链接:2024 博客之星年度评选活动,闪耀开启!。

为了很好的进行省域数据的挖掘与分析,这里将需要对官方公布的数据进行清洗和处理。清洗的步骤分为两步,第一步是从官网中获取所有排名的数据,第二步是抓取空间属性数据,为省域分析奠定基础。
1、所有排名数据
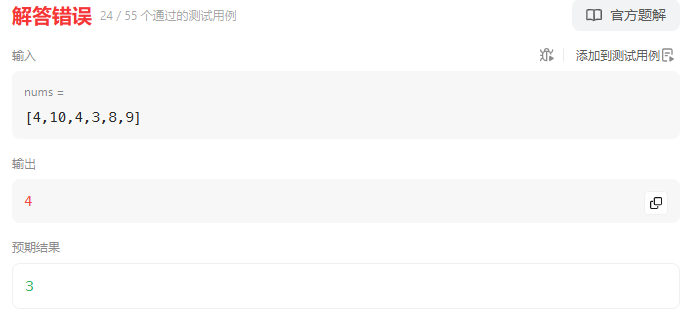
本次博客之星的最终排名:2024年博客之星年度评选——个人影响力评审得分+获奖榜单公布。大家可以在官方网站上查看相关的信息,如下图所示这里贴出了前10名的优秀大佬:
2、空间属性管理
我们在每个博客之星的博客主页上,都可以看到博主的IP所属信息。虽然有一些博主的IP归属有一定的误差,但大多数还是比较准确的。所有上榜的博主的博客都值得深入阅读学习,这里以博主个人的博客主页为例,主要讲解空间属性的数据展示,打开个人主页:夜郎King的博客。打开主页后可以看到以下信息:

在博主的个人首页上可以看到许多的关键信息,除了常规的博客昵称、码龄、性别、博客等级、博客访问量、博客原创数、博客排名、粉丝数、个人简介、IP归属地、加入CSDN的时间、原力等级等诸多的信息,为了实现博客的空间关联,主要是使用IP属地来进行归属地空间关联,其它的关键信息在后续的系列博客中会进行详细介绍。
二、数据抓取与处理
为了实现对博客之星的省域空间分布进行全面的数据挖掘与处理。需要我们对相关的博客地址以及排名情况进行抓取和处理。后续我们会加上时间的维度,来综合展示不同年度的省域人员分布,从而揭示其时空特性。本节将分三个部分介绍,第一部分是详细介绍相关的业务表设计,第二部分讲解如何进行数据的获取,第三部分是基于业务表的空间查询分析实践。
1、相关业务表的设计
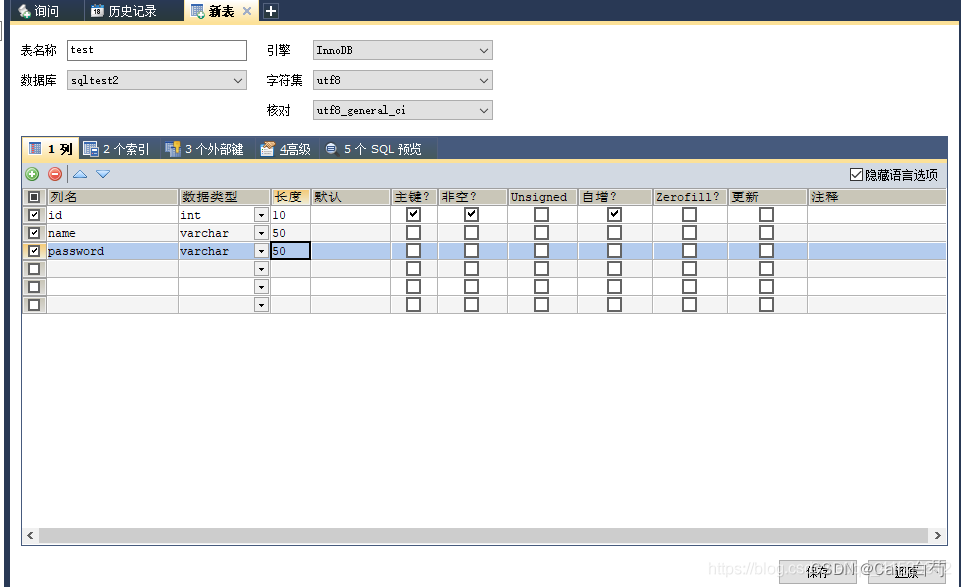
为了实现对数据的整体挖掘,这里我们使用关系型数据库来进行相关数据的存储。为了很好的进行数据挖掘,这里我们设计三张表,如下面的PowerDesigner所示:
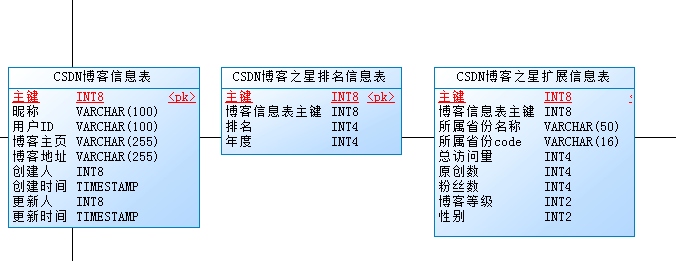
首先需要存储博客的基本信息、其次要存储不同年份的的博客排名信息表,最后就是存储博客的扩展信息,比如所属省份、总访问量、原创数、博客等级、性别等信息。其中,博客之星的排名信息表与扩展信息表和博客信息表是一一对应的关系。这三张表的物理表结构如下:
博客信息表:
CREATE TABLE "public"."biz_csdn_blog" (
"pk_id" int8 NOT NULL,
"nick_name" varchar(100) COLLATE "pg_catalog"."default" NOT NULL,
"blog_id" varchar(100) COLLATE "pg_catalog"."default",
"blog_home" varchar(255) COLLATE "pg_catalog"."default" NOT NULL,
"blog_href" varchar(255) COLLATE "pg_catalog"."default" NOT NULL,
"create_by" int8,
"create_time" timestamp(6),
"update_by" int8,
"update_time" timestamp(6),
CONSTRAINT "pk_biz_csdn_blog" PRIMARY KEY ("pk_id")
);
CREATE INDEX "idx_biz_csdn_blog_href" ON "public"."biz_csdn_blog" USING btree (
"blog_href" COLLATE "pg_catalog"."default" "pg_catalog"."text_ops" ASC NULLS LAST
);
COMMENT ON COLUMN "public"."biz_csdn_blog"."pk_id" IS '主键';
COMMENT ON COLUMN "public"."biz_csdn_blog"."nick_name" IS '用户昵称';
COMMENT ON COLUMN "public"."biz_csdn_blog"."blog_id" IS '用户ID';
COMMENT ON COLUMN "public"."biz_csdn_blog"."blog_home" IS '博客主页';
COMMENT ON COLUMN "public"."biz_csdn_blog"."blog_href" IS '博客地址';
COMMENT ON COLUMN "public"."biz_csdn_blog"."create_by" IS '创建人';
COMMENT ON COLUMN "public"."biz_csdn_blog"."create_time" IS '创建时间';
COMMENT ON COLUMN "public"."biz_csdn_blog"."update_by" IS '更新人';
COMMENT ON COLUMN "public"."biz_csdn_blog"."update_time" IS '更新时间';
COMMENT ON TABLE "public"."biz_csdn_blog" IS '用于保存CSDN的博客信息表';排名信息表:
CREATE TABLE "public"."biz_csdn_blog_rank" (
"pk_id" int8 NOT NULL,
"blog_info_id" int8 NOT NULL,
"rank" int4 NOT NULL,
"year" int4,
CONSTRAINT "pk_biz_csdn_blog_rank" PRIMARY KEY ("pk_id")
);
COMMENT ON COLUMN "public"."biz_csdn_blog_rank"."pk_id" IS '主键';
COMMENT ON COLUMN "public"."biz_csdn_blog_rank"."blog_info_id" IS '博客信息表主键';
COMMENT ON COLUMN "public"."biz_csdn_blog_rank"."rank" IS '排名';
COMMENT ON COLUMN "public"."biz_csdn_blog_rank"."year" IS '年度';
COMMENT ON TABLE "public"."biz_csdn_blog_rank" IS 'CSDN博客之星排名信息表';扩展信息表:
CREATE TABLE "public"."biz_csdn_blog_ext" (
"pk_id" int8 NOT NULL,
"blog_info_id" int8 NOT NULL,
"province_name" varchar(50) COLLATE "pg_catalog"."default" NOT NULL,
"province_code" varchar(16) COLLATE "pg_catalog"."default",
"access_total" int4,
"original_total" int4,
"fans_total" int4,
"blog_level" int2,
"gender" int2,
CONSTRAINT "pk_biz_csdn_blog_ext" PRIMARY KEY ("pk_id")
);
COMMENT ON COLUMN "public"."biz_csdn_blog_ext"."pk_id" IS '主键';
COMMENT ON COLUMN "public"."biz_csdn_blog_ext"."blog_info_id" IS '博客信息表主键';
COMMENT ON COLUMN "public"."biz_csdn_blog_ext"."province_name" IS '所属省份名称';
COMMENT ON COLUMN "public"."biz_csdn_blog_ext"."province_code" IS '所属省份code';
COMMENT ON COLUMN "public"."biz_csdn_blog_ext"."access_total" IS '总访问量';
COMMENT ON COLUMN "public"."biz_csdn_blog_ext"."original_total" IS '原创数';
COMMENT ON COLUMN "public"."biz_csdn_blog_ext"."fans_total" IS '粉丝数';
COMMENT ON COLUMN "public"."biz_csdn_blog_ext"."blog_level" IS '博客等级';
COMMENT ON COLUMN "public"."biz_csdn_blog_ext"."gender" IS '性别';
COMMENT ON TABLE "public"."biz_csdn_blog_ext" IS 'CSDN博客之星扩展信息表,用于保存加入CSDN时间,所在省份,性别,访问量,博客等级,个人成就json,兴趣领域json';2、数据抓取处理
对于全网的综合排名以及IP所属地的获取,这里采用Java和Jsoup的方式来进行获取。后台使用SpringBoot的开发架构,数据的抓取分三步。第一步是从公布的前300名的博客列表,第二步是循环所有的博客列表,再打开的页面中来获取IP归属地,第三步就是将获取的数据插入到数据库中。首先来讲解第一步,如何利用Jsoup来抓取数据,示例代码如下:
@Test
public void FetchCsdnBlogStart2024() throws Exception {
List<CsdnBlogStar> blogStarList = new ArrayList<CsdnBlogStar>();
Document doc = Jsoup.connect(blog_site_2024)
.ignoreContentType(true)
.timeout(300000)
.header("referer","https://blog.csdn.net")
.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8")
.header("Accept-Encoding", "gzip, deflate, sdch")
.header("Accept-Language", "zh-CN,zh;q=0.8")
.get();
Elements tableElements = doc.getElementsByTag("table");
Element final_top300 = tableElements.get(1);
Integer year = 2024;
Elements rows = final_top300.getElementsByTag("tr");
List<CsdnBlog> csdnBlogList = new ArrayList<CsdnBlog>();
List<CsdnBlogRank> blogRandList = new ArrayList<CsdnBlogRank>();
List<CsdnBlogExt> blogExtList = new ArrayList<CsdnBlogExt>();
for(int i = 1;i< rows.size();i++) {
Element row = rows.get(i);
String blogHref = row.getElementsByTag("a").attr("href");
//System.out.println("225==" + blogHref);
// 获取<tr>中的所有<td>元素
Elements cells = row.getElementsByTag("td");
String sno = cells.get(0).text();
String nickName = cells.get(1).text();
String blogHome = cells.get(2).text();
Integer rank = Integer.valueOf(cells.get(7).text());
CsdnBlogStar star = new CsdnBlogStar(sno, nickName,"", blogHome,blogHref, rank,year);
blogStarList.add(star);
System.out.println(star);
Long size = csdnBlogService.getSizeByCsdnBlogHref(blogHref);
System.out.println("size===>" + size);
//数据库中未存在再入库
if(size <= 0) {
Long csdnBlogId = IdWorker.getId();
CsdnBlog csdnBlog = new CsdnBlog(nickName, "", blogHome, blogHref);
csdnBlog.setPkId(csdnBlogId);
CsdnBlogRank blogRank = new CsdnBlogRank(csdnBlogId, rank, year);
CsdnBlogExt blogExt = FetchBlogExtInfo(blogHref);
blogExt.setBlogInfoId(csdnBlogId);
csdnBlogService.save(csdnBlog);
csdnBLogRandService.save(blogRank);
csdnBlogExtService.save(blogExt);
}
}
System.out.println("finished");
}在抓取综合排名博客后,在来抓取其IP所在地和其他的业务信息,业务实现代码如下:
private CsdnBlogExt FetchBlogExtInfo(String blogHref) throws Exception {
Document doc = Jsoup.connect(blogHref)
.ignoreContentType(true)
.timeout(300000)
.header("referer","https://blog.csdn.net")
.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8")
.header("Accept-Encoding", "gzip, deflate, sdch")
.header("Accept-Language", "zh-CN,zh;q=0.8")
.get();
String provinceName = doc.getElementsByClass("address").text().replaceAll("IP 属地:", "");
Elements userProfileHeadInfo = doc.getElementsByClass("user-profile-head-info-r-c");
String accessTotalStr = userProfileHeadInfo.select(" ul > li:eq(0) .user-profile-statistics-num ").text();
String originalTotalStr = userProfileHeadInfo.select(" ul > li:eq(1) .user-profile-statistics-num ").text();
String fansTotalStr = userProfileHeadInfo.select(" ul > li:eq(3) .user-profile-statistics-num ").text();
accessTotalStr = accessTotalStr.indexOf(",") < 0 ? accessTotalStr : accessTotalStr.replaceAll(",", "");
originalTotalStr = originalTotalStr.indexOf(",") < 0 ? originalTotalStr : originalTotalStr.replaceAll(",", "");
fansTotalStr = fansTotalStr.indexOf(",") < 0 ? fansTotalStr : fansTotalStr.replaceAll(",", "");
Integer accessTotal = StringUtils.isEmpty(accessTotalStr) ? 0 : Integer.valueOf(accessTotalStr);//总访问量
Integer originalTotal = StringUtils.isEmpty(originalTotalStr) ? 0 : Integer.valueOf(originalTotalStr);//原创数
Integer fansTotal = StringUtils.isEmpty(fansTotalStr) ? 0 : Integer.valueOf(fansTotalStr);//粉丝数
return new CsdnBlogExt(provinceName, accessTotal, originalTotal, fansTotal);
}在获取博客的IP归属地后,使用下面的代码进行地点替换:
doc.getElementsByClass("address").text().replaceAll("IP 属地:", "");//所属省份名称获取以上的数据后,我们来数据库中看下具体的数据,执行sql如下:
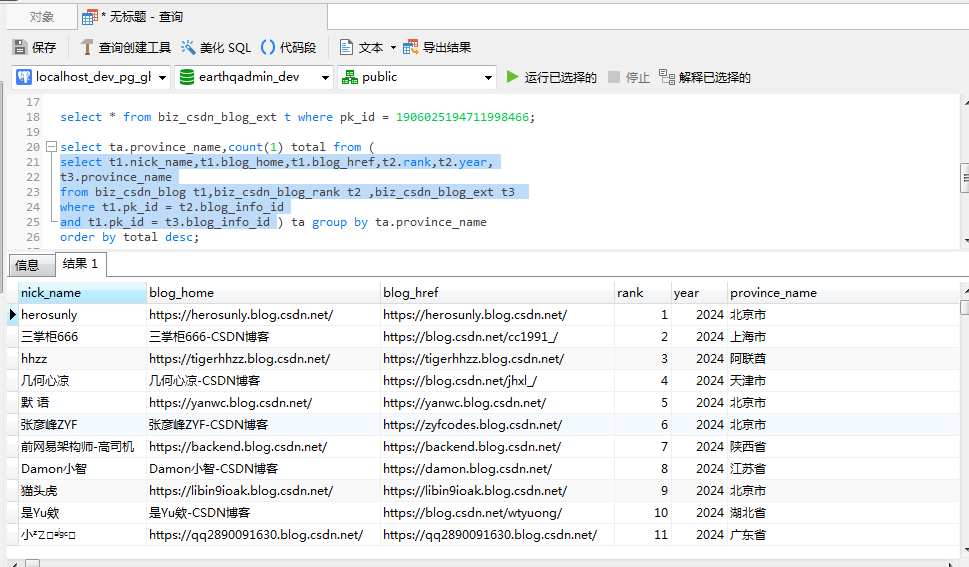
select t1.nick_name,t1.blog_home,t1.blog_href,t2.rank,t2.year,
t3.province_name
from biz_csdn_blog t1,biz_csdn_blog_rank t2 ,biz_csdn_blog_ext t3
where t1.pk_id = t2.blog_info_id
and t1.pk_id = t3.blog_info_id 执行之后,我们来看一下具体的数据:
3、空间查询分析实践
为了实现对排名前300的数据进行简单分析,这里将按照各省份来进行排名和查询。将这三张表进行联合查询的SQL如下:
SELECT
t1.nick_name,
t1.blog_home,
t1.blog_href,
t2.RANK,
t2.YEAR,
t3.province_name,
t3.pk_id
FROM
biz_csdn_blog t1,
biz_csdn_blog_rank t2,
biz_csdn_blog_ext t3
WHERE
t1.pk_id = t2.blog_info_id
AND t1.pk_id = t3.blog_info_id;得到的查询结果如下:
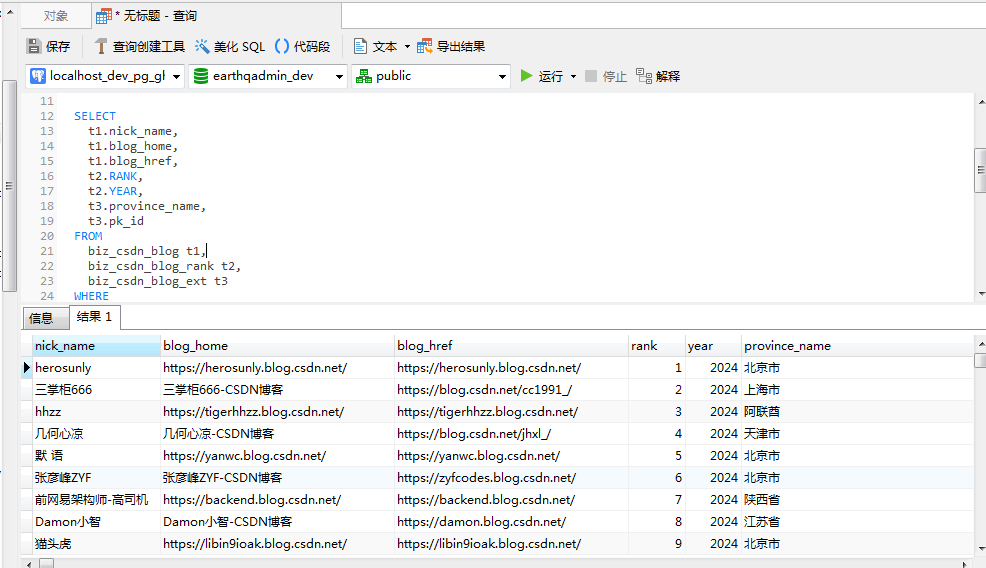
请注意,在采集博主的IP归属地时,有的博主的归属地是不准确的,因此需要额外的手动修正。 修正的方式主要是通过首页的相关信息,比如从最近的评论列表中寻找IP,比如某博主,其IP归属地显示是A,在评论中却是广东省,因此需要结合最新的数据来进行过滤。空间查询且进行排名的SQL如下:
SELECT ta.province_name,COUNT ( 1 ) total
FROM (
SELECT t1.nick_name,t1.blog_home,t1.blog_href,t2.RANK,t2.YEAR,t3.province_name
FROM
biz_csdn_blog t1,
biz_csdn_blog_rank t2,
biz_csdn_blog_ext t3
WHERE
t1.pk_id = t2.blog_info_id
AND t1.pk_id = t3.blog_info_id
) ta
GROUP BY ta.province_name
ORDER BY total DESC;执行以后在客户端软件可以看到以下信息:
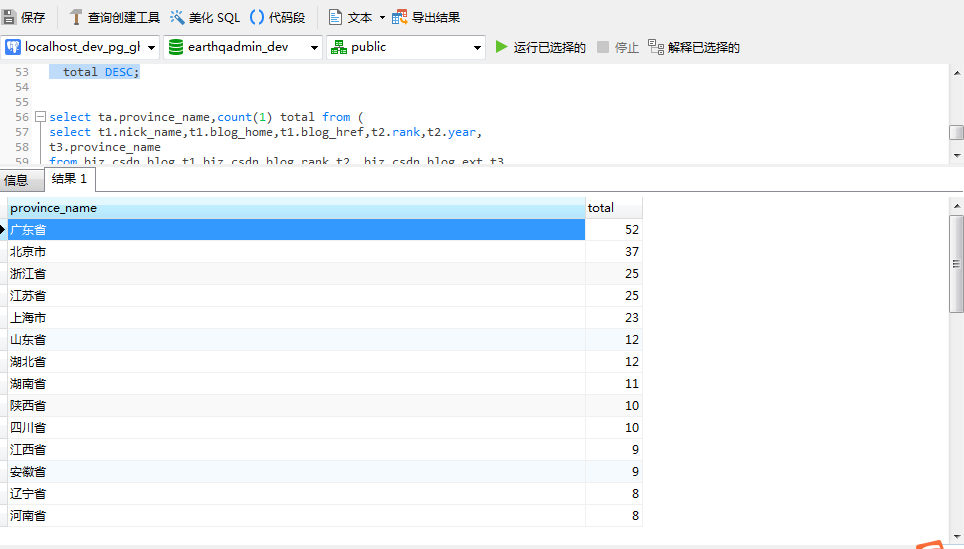
三、数据成果挖掘
研究博客之星的省域分布,不仅有助于理解数字内容生产的区域差异,也为区域文化与经济发展的研究提供了新的视角。通过分析博客创作者的地理分布,我们可以发现区域数字基础设施的建设水平、教育资源的分配状况以及文化氛围的塑造能力对内容创作的影响。这些发现对于推动区域均衡发展、优化数字资源配置具有重要的政策意义。
1、省域分布解读
首先我们来看一下这300位博主的空间分布情况,按照前300名的分布如下:
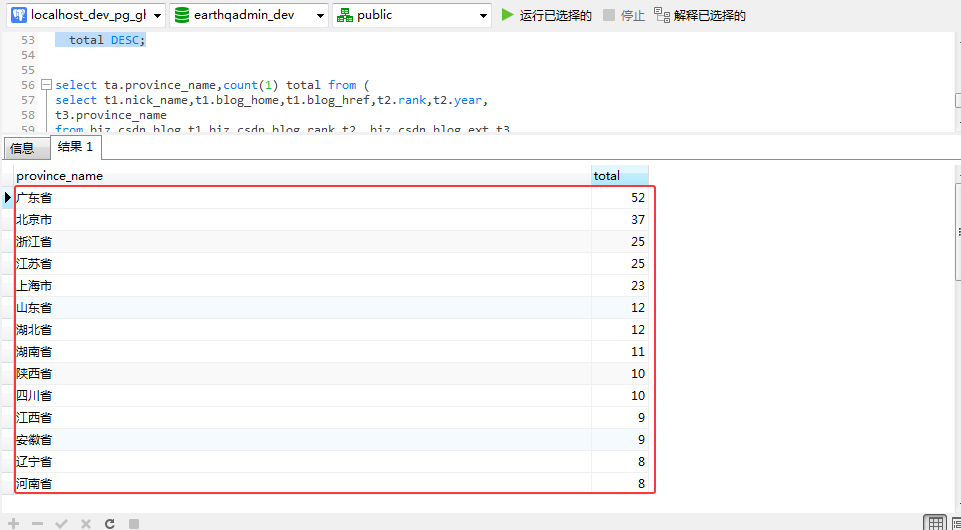
可以很明显的看到,在前300名中,广东省的人数最多,达到了52人,其次是北京37人,浙江和江苏并列第三,分别25人,第五名是上海市23人。博主所在省份湖南前300名有11人上榜。
按照排名来进行人员筛选sql如下:
SELECT ta.province_name,
COUNT ( 1 ) total
FROM (
SELECT t1.nick_name, t1.blog_home,t1.blog_href,t2.RANK,t2.YEAR,t3.province_name
FROM
biz_csdn_blog t1,
biz_csdn_blog_rank t2,
biz_csdn_blog_ext t3
WHERE
t1.pk_id = t2.blog_info_id
AND t1.pk_id = t3.blog_info_id
AND t2."rank" <= 200
) ta GROUP BY
ta.province_name
ORDER BY
total DESC;前100名的省域分布如下,广东依然是名列前茅,北京紧随其后:
广东省 18 北京市 15 上海市 9 江苏省 8 浙江省 6
湖南省 4 四川省 4 山东省 4 湖北省 3 河北省 3
福建省 3 天津市 3 吉林省 3 安徽省 3
前50名的省域分布、可以看到,广东省依然领先:
广东省 8 北京市 8 江苏省 5 浙江省 5 湖南省 2 河北省 2
上海市 2 四川省 2 天津市 2 山东省 2 吉林省 2 安徽省 2
湖北省 2 阿联酋 1 甘肃省 1 黑龙江省 1 陕西省 1 河南省 1
江西省 1 福建省 1
前30省域分布,在前30名中,北京稍微领先一个人,广东依然有恐怖的5个:
北京市 6 广东省 5 上海市 2 湖北省 2 河北省 2 江苏省 2
山东省 2 浙江省 2 天津市 1 河南省 1 湖南省 1 阿联酋 1
四川省 1 陕西省 1 安徽省 1
前10的省域分布如下,可以看到在前10名的分布中,北京独占鳌头,有4个,很多省份已经完全没有了上榜博主
北京市 4 上海市 1 湖北省 1 天津市 1 陕西省 1 阿联酋 1
江苏省 1
最后来看下前10的具体分布,可以看到,第一、五、六、九名在北京、第二名上海,第三名海外,第四名天津市,第七名陕西省,第八名是江苏省,第十是湖北的,第十一是广东省:
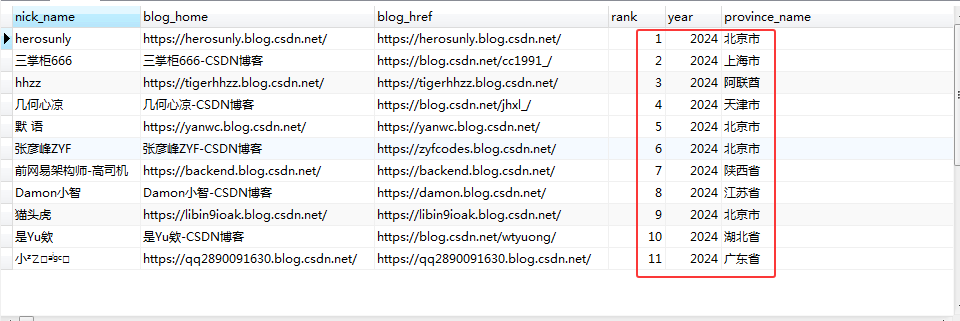
综合可以看到,位于北京的博主还是非常多,而且排名比较靠前。
2、技术开发活跃
博客之星的空间分布还为我们提供了一个观察当代社会文化变迁的窗口。通过分析不同地区的博客内容主题与风格,我们可以洞察区域文化特质的演变,以及全球化与本土化之间的张力。这种研究不仅具有学术价值,也为文化政策的制定与文化产业的发展提供了实践指导。通过上面的分析结果不难看出,津京冀地区的技术开发活跃度比较高,在活动中的整体排名较好。除此之外,长三角(江苏、上海、浙江)的头部排名也不错,一个中部省份湖北省和西部省份陕西在本次评选中脱颖而出。通过区域的分布可以看到,经济越发达的地区,技术活跃度越高。当然,受限于采用的样本数量问题,因此分析的视角仅代表个人意见。
四、总结
以上就是本文的主要内容,本文以2024年全网Top300博客之星为研究对象,试图通过数据可视化与深度分析,揭示博客创作者在地理空间上的分布规律,并探讨其背后的社会动因与文化逻辑。2024年博客之星的省域空间分布,是数字时代区域发展与文化表达的一面镜子。通过对这一现象的深入分析,我们不仅能够更好地理解当代网络内容生态的运行逻辑,也能为区域文化的传承与创新提供新的思路。本文将通过数据可视化与案例分析,展示博客之星的地理分布规律,为读者呈现一幅数字时代区域发展的文化图景。

](https://i-blog.csdnimg.cn/direct/9c39af636829460aacfdfd715a8e4416.png)






![python manimgl数学动画演示_微积分_线性代数原理_ubuntu安装问题[已解决]](https://i-blog.csdnimg.cn/direct/91cbb2b855cc414281f519f33a4e280a.png)