如果有兴趣了解更多相关内容,欢迎来我的个人网站看看:耶瞳空间
一:执行引擎介绍
“虚拟机”是一个相对于“物理机”的概念,这两种机器都有代码执行能力,其区别是物理机的执行引擎是直接建立在处理器、缓存、指令集和操作系统层面上的,而虚拟机的执行引擎则是由软件自行实现的,因此可以不受物理条件制约地定制指令集与执行引擎的结构体系,能够执行那些不被硬件直接支持的指令集格式。
JVM的主要任务是负责装载字节码到其内部,但字节码并不能够直接运行在操作系统之上,因为字节码指令并非等价于本地机器指令,它内部包含的仅仅只是一些能够被JVM所识别的字节码指令、符号表,以及其他辅助信息。那么,如果想要让一个Java程序运行起来,执行引擎的任务就是将字节码指令解释/编译为对应平台上的本地机器指令才可以。简单来说,JVM中的执行引擎充当了将高级语言翻译为机器语言的译者。
从外观上来看,所有的Java虚拟机的执行引擎输入输出都是一致的:输入的是字节码二进制流,处理过程是字节码解析执行的等效过程,输出的是执行结果。
二:编译和解释的理解
在聊JVM的编译和解释之前,可以先看看语言层面的编译和解释。
| 类型 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 编译型语言 | 通过专门的编译器,将所有源代码一次性转换成特定平台的机器码,以可执行文件的形式存在 | 编译一次后,脱离了编译器也能运行,并且运行效率高 | 可移植性差,不够灵活 |
| 解释型语言 | 通过专门的解释器,根据需要可以将部分或全部源代码转换成特定平台的机器码 | 跨平台性好,通过不同的解释器,将相同的源代码解释成不同平台下的机器码。 | 一边执行一边转换,效率较低 |
编译型语言不能跨平台常常会让人误解。C语言就是编译性语言,但在windows上也能运行C程序,linux也能运行C程序,因为在window上编译成exe文件执行,在linux上也能编译成对应的可执行文件然后执行。那为什么叫做不能跨平台呢?
其实编译型语言不能跨平台表现在两个方面:
- 可执行程序不能跨平台:因为不同操作系统对可执行文件的内部结构有着截然不同的要求,彼此之间也不能兼容。
- 源代码不能跨平台:不同平台支持的函数、类型、变量等都可能不同,基于某个平台编写的源代码一般不能拿到另一个平台直接运行。以C语言为例:
- 在C语言中,要想让程序暂停,我们可以使用“睡眠”函数。在 Windows 平台下该函数是 Sleep() ,并以毫秒为时间单位,而在 Linux 平台下则是 sleep(), 以秒为单位。可以看出,首先两个函数的首字母大小写不同,再者 Sleep() 的参数是毫秒,而 sleep() 的参数是秒,单位也不一样。
- 虽然不同平台的C语言都支持 long 类型,但不同平台下 long 类型所占用的字节长度却不相同。例如 Windows 64 位平台下的 long 占用 4 个字节,Linux 64 位平台下的 long 却占用 8 个字节。如果在 Linux 64 位平台下编写代码时,将 8 字节的值赋值给 long 类型的变量,这是完全没有问题的,但如果是在 Windows 平台下就会导致数值溢出,让程序产生错误的运行结果。
可以看出,解释性语言要实现跨平台需要在代码层面对平台的兼容性做出处理,但这非常麻烦。
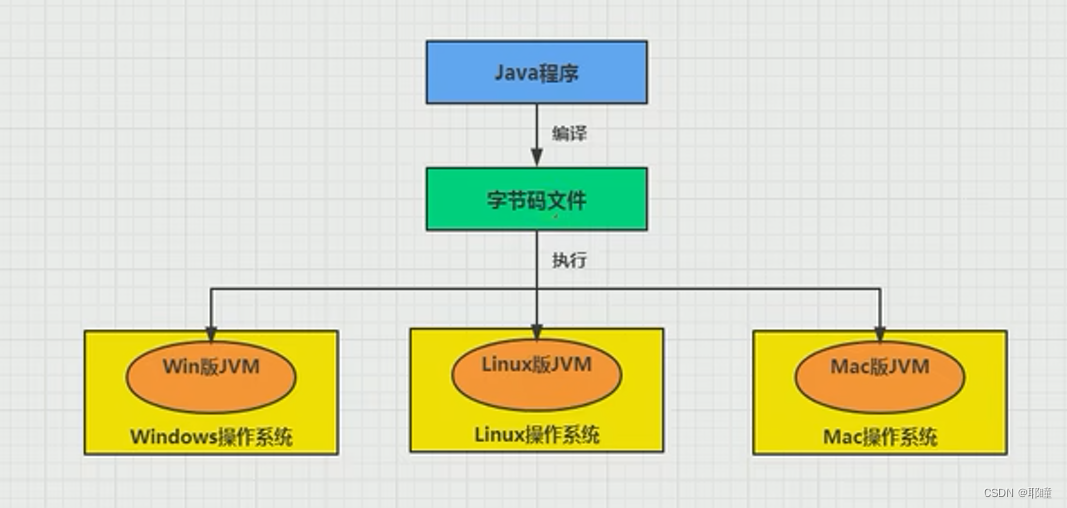
回到JVM,下图是Java程序的执行流程,从图中可以看到,流程中有两次编译,第一次是从java文件编译成class文件,第二次是JIT编译器将class文件编译成本地机器码,这两次编译也被分别称为前端编译和后端编译。
- 前端编译:与源语言有关,与目标机无关(.java -> .class)。
- 后端编译:与源语言无关,与目标机有关(.class -> 机器指令)。
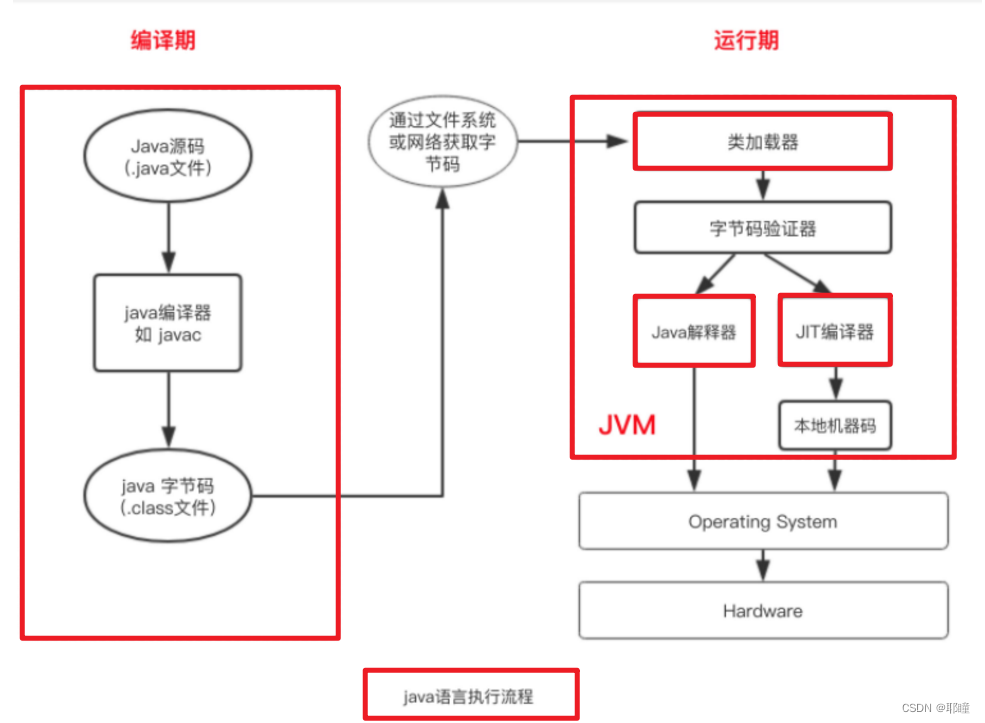
至于经过字节码验证器后是走Java解释器还是走JIT编译器,我们在下面介绍。
三:JIT编译器
JIT(Just In Time),也就是即时编译,通过JIT技术,能够做到Java程序执行速度的加速。那么,是怎么做到的呢?我们都知道,Java是一门解释型语言(或者说是半编译,半解释型语言)。Java通过编译器javac先将源程序编译成与平台无关的Java字节码文件(.class),再由JVM解释执行字节码文件,从而做到平台无关。 但是,有利必有弊。对字节码的解释执行过程实质为:JVM先将字节码翻译为对应的机器指令,然后执行机器指令。很显然,这样经过解释执行,其执行速度必然不如直接执行二进制字节码文件。
而为了提高执行速度,便引入了 JIT 技术。当JVM发现某个方法或代码块运行特别频繁的时候,就会认为这是“热点代码”(Hot Spot Code)。然后JIT会把部分“热点代码”编译成本地机器相关的机器码,并进行优化,然后再把编译后的机器码缓存起来,以备下次使用。
有些开发人员会感觉到诧异,既然HotSpot VM中已经内置JIT编译器了,那么为什么还需要再使用解释器来“拖累”程序的执行性能呢?比如JRockit VM内部就不包含解释器,字节码全部都依靠即时编译器编译后执行。
- 当程序启动后,解释器可以马上发挥作用,省去编译的时间,立即执行。编译器要想发挥作用,把代码编译成本地代码,需要一定的执行时间。但编译为本地代码后,执行效率高。所以尽管JRockit VM中程序的执行性能会非常高效,但程序在启动时必然需要花费更长的时间来进行编译。对于服务端应用来说,启动时间并非是关注重点,但对于那些看中启动时间的应用场景而言,或许就需要采用解释器与即时编译器并存的架构来换取一个平衡点。在此模式下,当Java虚拟器启动时,解释器可以首先发挥作用,而不必等待即时编译器全部编译完成后再执行,这样可以省去许多不必要的编译时间。随着时间的推移,编译器发挥作用,把越来越多的代码编译成本地代码,获得更高的执行效率。
- 当程序运行环境中内存资源限制较大(如部分嵌入式系统中),可以使用解释器执行节约内存,反之可以使用编译执行来提升效率。此外,如果编译后出现“罕见陷阱”,可以通过逆优化退回到解释执行。
- 说JIT比解释快,其实说的是“执行编译后的代码”比“解释器解释执行”要快,并不是说“编译”这个动作比“解释”这个动作快。JIT编译再怎么快,至少也比解释执行一次略慢一些,而要得到最后的执行结果还得再经过一个“执行编译后的代码”的过程。所以,对“只执行一次”的代码而言,解释执行其实总是比JIT编译执行要快。怎么算是“只执行一次的代码”呢?粗略说,这两个条件同时满足时就是严格的“只执行一次”:“只被调用一次,例如类的构造器”,“没有循环”。对只执行一次的代码做JIT编译再执行,可以说是得不偿失。对只执行少量次数的代码,JIT编译带来的执行速度的提升也未必能抵消掉最初编译带来的开销。只有对频繁执行的代码,JIT编译才能保证有正面的收益。
注意解释执行与编译执行在线上环境微妙的辩证关系。机器在热机状态可以承受的负载要大于冷机状态。如果以热机状态时的流量进行切流,可能使处于冷机状态的服务器因无法承载流量而假死。在生产环境发布过程中,以分批的方式进行发布,根据机器数量划分成多个批次,每个批次的机器数至多占到整个集群的1/8。曾经有这样的故障案例:某程序员在发布平台进行分批发布,在输入发布总批数时,误填写成分为两批发布。如果是热机状态,在正常情况下一半的机器可以勉强承载流量,但由于刚启动的JVM均是解释执行,还没有进行热点代码统计和JIT动态编译,导致机器启动之后,当前1/2发布成功的服务器马上全部宕机,此故障说明了JIT 的存在。—阿里团队
想要触发JIT编译,首先要识别出热点代码。目前主要的热点代码识别方式是热点探测(Hot Spot Detection),有以下两种:
- 基于采样方式探测(Sample Based Hot Spot Detection):周期性检测各个线程的栈顶,发现某个方法经常出现在栈顶,就认为是热点方法。好处就是简单,缺点就是无法精确确认一个方法的热度。容易受线程阻塞或别的原因干扰热点探测。
- 基于计数器的热点探测(Counter Based Hot Spot Detection):采用这种方法的虚拟机会为每个方法,甚至是代码块建立计数器,统计方法的执行次数,某个方法超过阀值就认为是热点方法,触发JIT编译。
在HotSpot虚拟机中使用的是第二种——基于计数器的热点探测方法,因此它为每个方法准备了两个计数器:方法调用计数器(记录一个方法被调用次数)和回边计数器(循环的运行次数)。
四:AOT编译器
JDK9引入了AOT编译器(静态提前编译器,Ahead of Time Compiler)。这是与即时编译相对立的一个概念。即时编译指的是在程序的运行过程中,将字节码转换为可在硬件上直接运行的机器码,并部署至托管环境中的过程。而 AOT 编译指的则是,在程序运行之前,便将字节码转换为机器码,以便在程序运行时直接使用本地代码。
AOT的优点很明显,Java 虚拟机加载已经预编译成的二进制库,可以直接执行。不必等待及时编译器的预热,减少 Java 应用给人带来“第一次运行慢” 的不良体验。
但缺点也很明显,Java语言本身的动态特性给其带来了额外的复杂性,影响了Java程序静态编译代码的质量。例如Java语言中的动态类加载,因为AOT是在程序运行前编译的,所以无法获知这一信息,所以会导致一些问题的产生。
总的来说,AOT编译器从编译质量上来看,肯定比不上JIT编译器。其存在的目的在于避免JIT编译器的运行时性能消耗或内存消耗,或者避免解释程序的早期性能开销。
在运行速度上来说,AOT编译器编译出来的代码比JIT编译出来的慢,但是比解释执行的快。而编译时间上,AOT也是一个始终的速度。所以说,AOT编译器的存在是JVM牺牲质量换取性能的一种策略。就如JVM其运行模式中选择Mixed混合模式一样,使用C1编译模式只进行简单的优化,而C2编译模式则进行较为激进的优化。充分利用两种模式的优点,从而达到最优的运行效率。
最后,2022年11月正式发布的Spring6中引入了AOT,意味着Spring生态正式引入了提前编译技术,相比于JIT编译,AOT有助于优化Spring框架启动慢、占用内存多、以及垃圾无法被回收等问题。
![Java高效率复习-SpringMVC[SpringMVC-2]](https://img-blog.csdnimg.cn/a3b4fce9b7c040e8aa4fb792b5eefa89.png)






![[数据结构]:10-二叉排序树(无头结点)(C语言实现)](https://img-blog.csdnimg.cn/66ca6eda1b4348cdbbbbb94a414f6cc5.png)