文章目录
- 视频资料:
- 一、Spark基础入门(环境搭建、入门概念)
- 第二章:Spark环境搭建-Local
- 2.1 课程服务器环境
- 2.2 Local模式基本原理
- 2.3 安装包下载
- 2.4 Spark Local模式部署
- 第三章:Spark环境搭建-StandAlone
- 3.1 StandAlone的运行原理
- 3.2 StandAlone环境安装操作
- 3.3 StandAlone程序测试
- 3.4 Spark程序运行层次结构
- 3.5 总结
- 第四章:Spark环境搭建-StandAlone-HA
- 4.1 StandAlone HA运行原理
- 4.2 基于Zookeeper实现HA
- spark配置双master时一直处于standby的情况
- 4.3 总结
- 第五章:Spark环境搭建-Spark On YARN
- 5.1 Spark On YARN的运行原理
- 5.2 Spark On YARN部署和测试
- 5.3 部署模式DeployMode
- 5.4 两种部署模式的演示和总结
- 5.5 两种模式任务提交流程
- 5.6 总结
- 第六章:PySpark库
- 6.1 框架 VS 类库
- 6.2 PySpark类库介绍
- 6.3 PySpark安装
- 6.4 总结
- 第七章:本机开发环境搭建
- 7.1 本机配置Python环境
- 7.2 PyCharm本地和远程解释器配置
- 7.3 编程入口SparkContext对象以及WordCount演示
- 7.4 WordCount代码流程解析
- 7.5 提交WordCount到Linux集群运行
- 7.6 总结
- 第八章:分布式代码执行分析
- 8.1 Spark运行角色回顾
- 8.2 分布式代码执行分析
- 8.3 Python On Spark执行原理
- 8.4 总结
- 2.Spark核心
- 学习目标
- 第一章:RDD详解
- 1.1 什么是RDD
- 1.2 RDD五大特性-特性1
- 1.3 RDD五大特性-特性2
- 1.4 RDD五大特性-特性3
- 1.5 RDD五大特性-特性4
- 1.6 RDD五大特性-特性5
- 1.7 WordCount结合RDD特性进行执行分析
- 1.8 第一章总结
- 第二章:RDD编程入门
- 2.1 程序执行入口SparkContext对象
- 2.2 RDD的创建
- 方式一:通过并行化集合创建(本地对象转分布式RDD)
- 方式二:读取外部数据源
- 2.3 RDD算子概念和分类
- 2.4 常用转换算子
- 转换算子-map
- 转换算子-flatMap
- 转换算子-reduceByKey
- 转换算子-mapValues
- WordCount案例回顾
- 转换算子-groupBy
- 转换算子-filter
- 转换算子-distinct
- 转换算子-union
- 转换算子-join
- 转换算子-intersection
- 转换算子-glom
- 转换算子-groupByKey
- 转换算子-sortBy
- 转换算子-sortByKey
- RDD算子-案例
- RDD算子-案例-提交到YARN执行
- 2.5 常用Action算子
- Action算子-countByKey
- Action算子-collect
- Action算子-reduce
- Action算子-fold-了解
- Action算子-first
- Action算子-take
- Action算子-top
- Action算子-count
- Action算子-takeSample
- Action算子-takeOrdered
- Action算子-foreach
- Action算子-saveAsTextFile
- 2.6 分区操作算子
- 转换算子-mapPartitions
- Action算子-foreachPartition
- 转换算子-partitionBy
- 转换算子-repartition
- 面试题:groupByKey和reduceByKey的区别
- 2.7 第二章总结
- 第三章:RDD的持久化
- 3.1 RDD的数据是过程数据
- 3.2 RDD缓存
- 3.3 RDD CheckPoint
- 3.4 第三章总结
- 第四章:Spark案例练习
- 4.1 搜索引擎日志分析案例
- 4.2 提交到集群运行
- 4.3 第四章作业和总结
- 作业
- 总结
- 第五章:共享变量
- 5.1 广播变量
- 5.2 累加器
- 5.3 广播变量累加器综合案例
- 5.4 第五章总结
- 第六章:Spark内核调度(重点理解)
- 6.1 DAG
- 6.2 DAG的宽窄依赖和阶段划分
- 6 .3 内存迭代计算
- 6.4 Spark并行度
- 6.5 Spark任务调度
- DAG调度器
- Task调度器
- 6.6 拓展-Spark概念名称大全
- 6.7 第六章总结
- 3.SparkSQL
- 学习目标
- 第一章:SparkSQL快速入门
- 1.1 什么是SparkSQL
- 1.2 为什么要学习SparkSQL
- 1.3 SparkSQL特点
- 1.4 SparkSQL发展历史
- 1.5 第一章总结
- 第二章:SparkSQL概述
- 2.1 SparkSQL和Hive的异同
- 2.2 SparkSQL的数据抽象
- 2.3 SparkSQL数据抽象的发展
- 2.4 DataFrame数据抽象
- 2.5 SparkSession对象
- 2.6 SparkSQL HelloWorld
- 2.7 第二章总结
- 第三章:DataFrame入门
- 3.1 DataFrame的组成
- 3.2 DataFrame的代码构建
- 基于RDD方式1-通过createDataFrame方法
- 基于RDD方式2-通过StructType对象
- 基于RDD方式3-使用toDF方法
- 基于Pandas的DataFrame
- 读取外部数据
- 读取Text文件
- 读取json文件
- 读取csv文件
- 读取parquet文件
- 3.3 DataFrame的入门操作
- DSL风格
- SQL风格
- 3.4 词频统计案例
- 3.5 电影数据分析
- 遇到问题:
- 3.6 SparkSQL Shuffle 分区数目
- 3.7 SparkSQL 数据清洗API
- 3.8 DataFrame数据写出
- 3.9 DataFrame通过JDBC读写数据库(MySQL示例)
- 3.10 第三章总结
- 第四章:SparkSQL函数定义
- 4.1 SparkSQL定义UDF函数
- sparksession.udf.register()
- pyspark.sql.functions.udf
- 注册一个ArraryType返回类型的UDF
- 注册一个字典返回类型的UDF
- 拓展-通过RDD代码模拟UDAF效果
- 4.2 SparkSQL使用窗口函数
- 4.3 第四章总结
- 第五章:SparkSQL的运行流程
- 5.1 SparkRDD的执行流程回顾
- 5.2 SparkSQL的自动优化
- 5.3 Catalyst优化器
- 5.4 SparkSQL的执行流程
- 5.5 第五章总结
- 第六章:Spark On Hive
- 6.1 原理
- 6.2 配置
- 6.3 在代码中集成
- 6.4 第六章总结
- 第七章:分布式SQL执行引擎
- 7.1 概念
- 7.2 客户端工具连接
- 配置
- 数据库工具连接ThriftServer
- 7.3 代码JDBC连接
- Pycharm软件连接ThriftServer
- 7.4 第七章总结
- 4.Spark综合案例
- 需求分析
- 需求1:
- 需求2:
- 需求3:
- 需求4:
- 5.Spark新特性+核心回顾
- 学习目标
- 第一章:Spark Shuffle
- 1.1 Spark Shuffle
- 1.2 HashShuffleManager
- 1.3 SortShuffleManager
- 1.4 第一章总结
- 第二章:Spark3.0新特性
- 2.2 Adaptive Query Execution自适应查询(SparkSQL)
- AQE总结
- 2.3 Dynamic Partition Pruning动态分区裁剪(SparkSQL)
- 2.4 增强的Python API:PySpark和Koalas
- 2.5 Koalas入门演示-Koalas DataFrame构建
视频资料:
黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程
一、Spark基础入门(环境搭建、入门概念)
学习目标:
1.[了解]Spark诞生背景
2.[了解]Saprk的应用场景
3.[掌握]Spark环境的搭建
4.[掌握]Spark的入门案例
5.[了解]Spark的基本原理
第一章:Spark框架概述
1.1 Spark是什么
定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
1.2 Spark风雨十年
1.3 扩展阅读:Spark VS Hadoop
1.4 Spark四大特点
1.5 Spark框架模型-了解
1.6 Spark运行模式
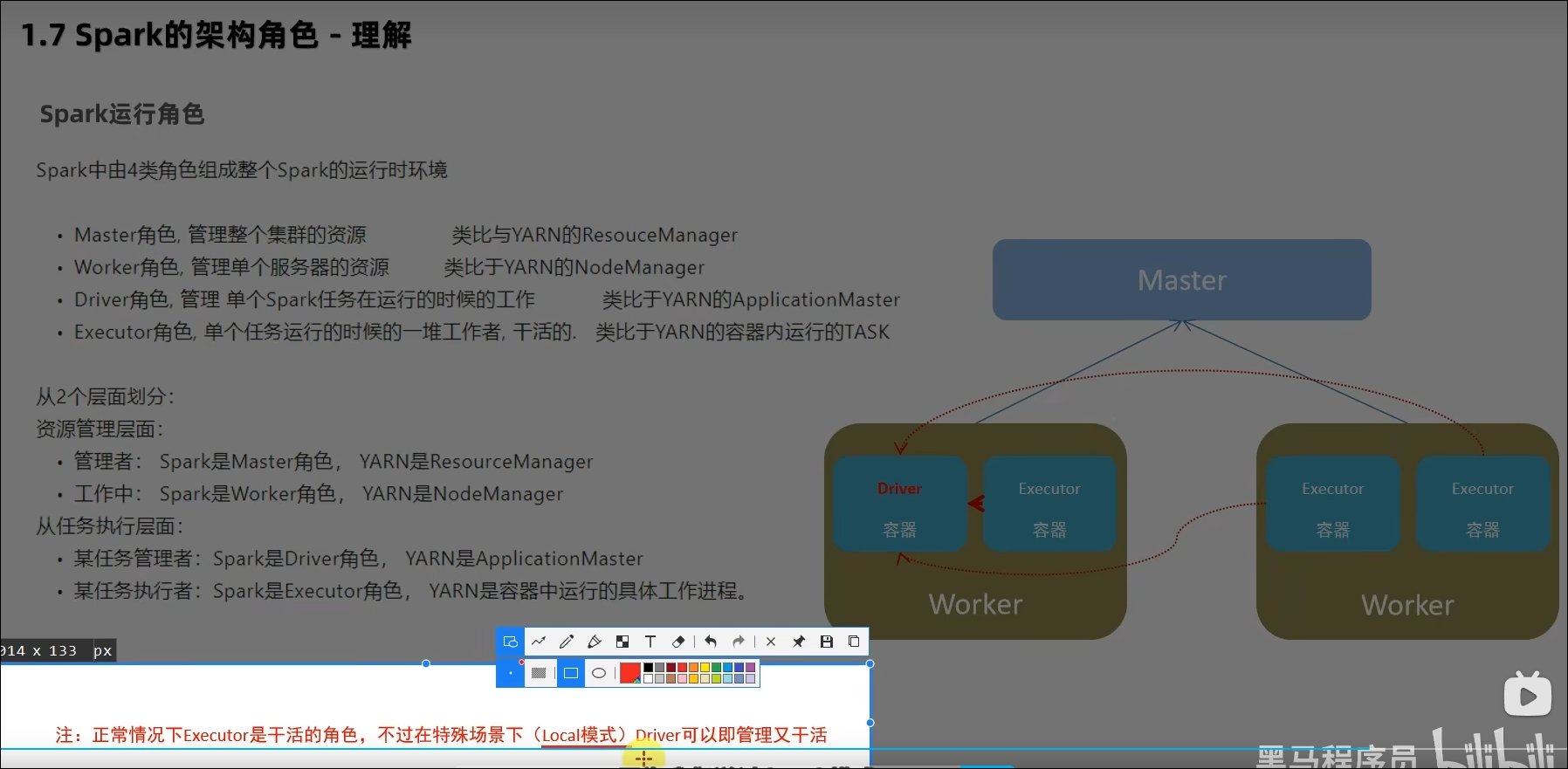
1.7 Spark架构角色
Spark解决什么问题?
- 海量数据的计算,可以进行离线批处理、实时流计算、机器学习计算、图计算、通过SQL完成结构化数据的处理。
Spark有哪些模块?
- 核心SparkCore、SQL计算(SparkSQL支持离线批处理, 其上面也有structured streaming支持实时流计算)、流计算(SparkStreaming,有缺陷)、图计算(GraphX)、机器学习(MLlib)
Spark特点有哪些?
- 速度快、使用简单、通用性强、多种模式运行。
Spark的运行模式?
-
本地模式(Local模式,在一个
-
集群模式(StandAlone、YARN、K8S)
-
云模式
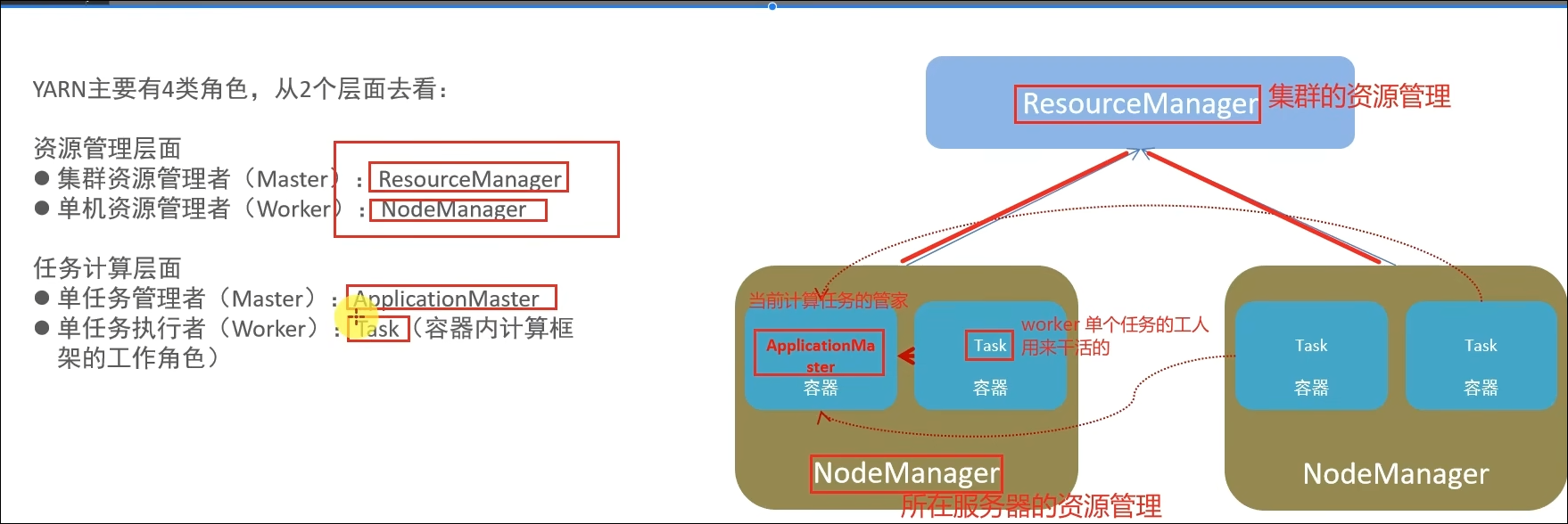
Spark的运行角色(对比YARN)?
Master:集群资源管理(类同ResourceManager)
Worker:单机资源管理(类同NodeManager)
Driver:单任务管理者(类同ApplicationMaster)
Executor:单任务执行者(类同YARN容器内的Task)
第二章:Spark环境搭建-Local
2.1 课程服务器环境

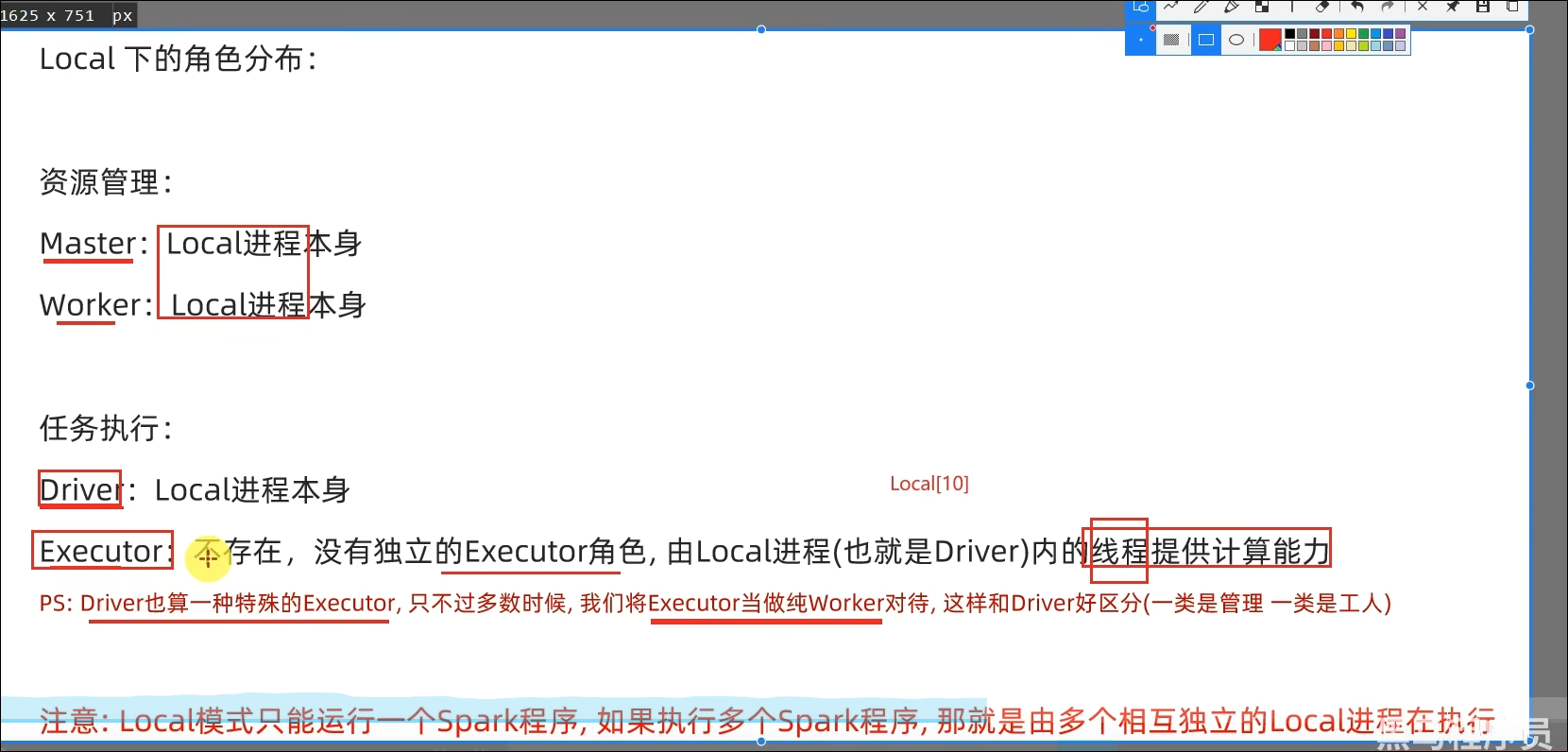
2.2 Local模式基本原理

2.3 安装包下载
PS:软连接与硬链接,参考资料:https://www.bilibili.com/video/BV1CZ4y1v7SR/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=c1627e67b359df87544f502955497bf7
配置环境变量:

2.4 Spark Local模式部署
- Local模式的运行原理?
Local模式就是以一个独立进程配合其内部线程来提供完成Spark运行时环境。Local模式可以通过spark-shell/pyspark/spark-submit等来开启。
- bin/pyspark是什么程序?
是一个交互式的解释器执行环境,环境启动后就得到了一个Local Spark环境,可以运行Python代码去进行Spark计算,类似Python自带解释器。
- Spark的4040端口是什么?
Spark的任务在运行后,会在Driver所在机器绑定到4040端口,提供当前任务的监控页面供查看。
PS:如果有多个Local模式下的Spark任务在一台机器上执行,则绑定的端口会依次顺延。
第三章:Spark环境搭建-StandAlone
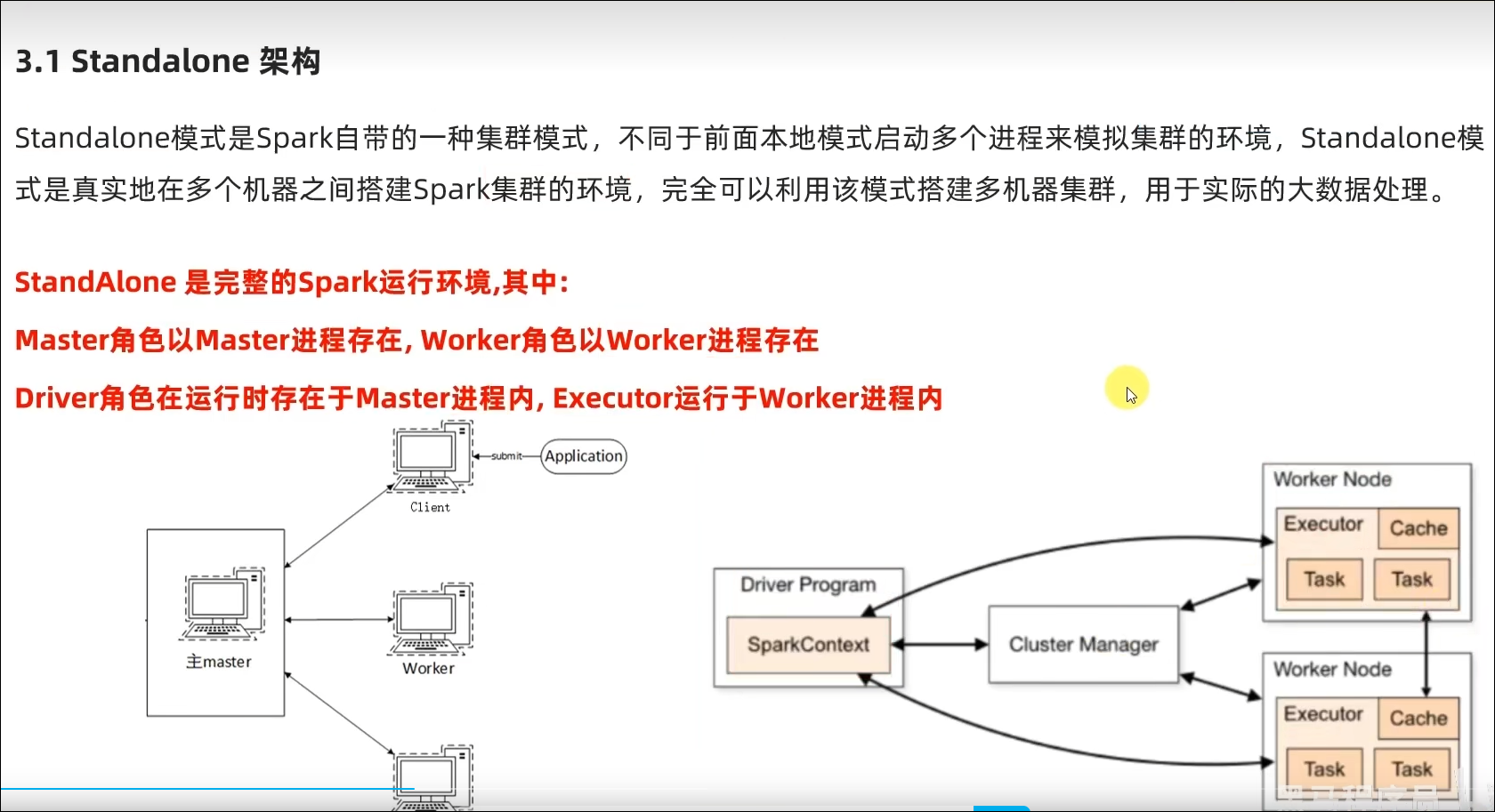
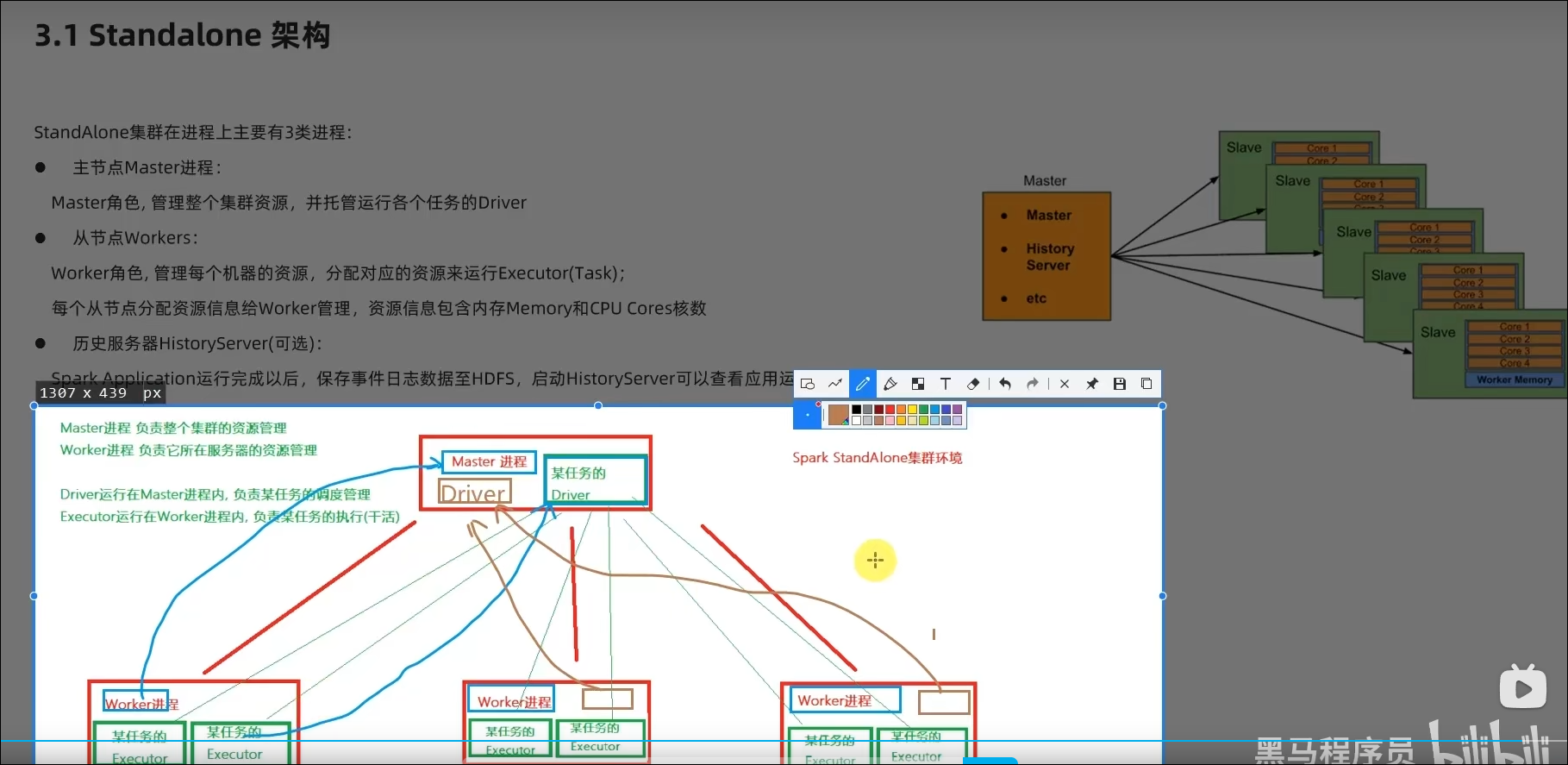
3.1 StandAlone的运行原理
3.2 StandAlone环境安装操作
详看视频
3.3 StandAlone程序测试

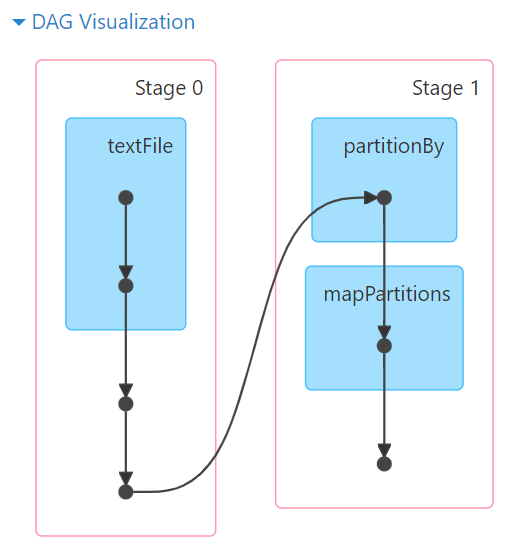
3.4 Spark程序运行层次结构


3.5 总结
- StandAlone的原理?
Master和Worker角色以独立进程的形式存在,并组成Spark运行时环境(集群)
- Spark角色在StandAlone中的分布?
Master角色:Master进程
Worker角色:Worker进程
Driver角色:以线程运行在Master中
Executor角色:以线程运行在Worker中
- StandAlone如何提交Spark应用?
bin/spark-submit --master spark://server:7077
- 4040\8080\18080分别是什么?
4040是单个程序运行的时候绑定的端口可供查看本任务运行情况(4040和Driver绑定,也和Spark的应用程序绑定)。
8080是Master运行的时候默认的WebUI端口(Master进程是守护进程)。
18080是Spark历史服务器的端口,可供我们查看历史运行程序的运行状态。
- Job\State\Task的关系?
一个Spark应用程序会被分成多个子任务(Job)运行,每一个Job会分成多个Stage(阶段)来运行,每一个Stage内会分出来多个Task(线程)来执行具体任务。
第四章:Spark环境搭建-StandAlone-HA
4.1 StandAlone HA运行原理
Spark Standalone集群存在Master单点故障(SPOF)的问题。
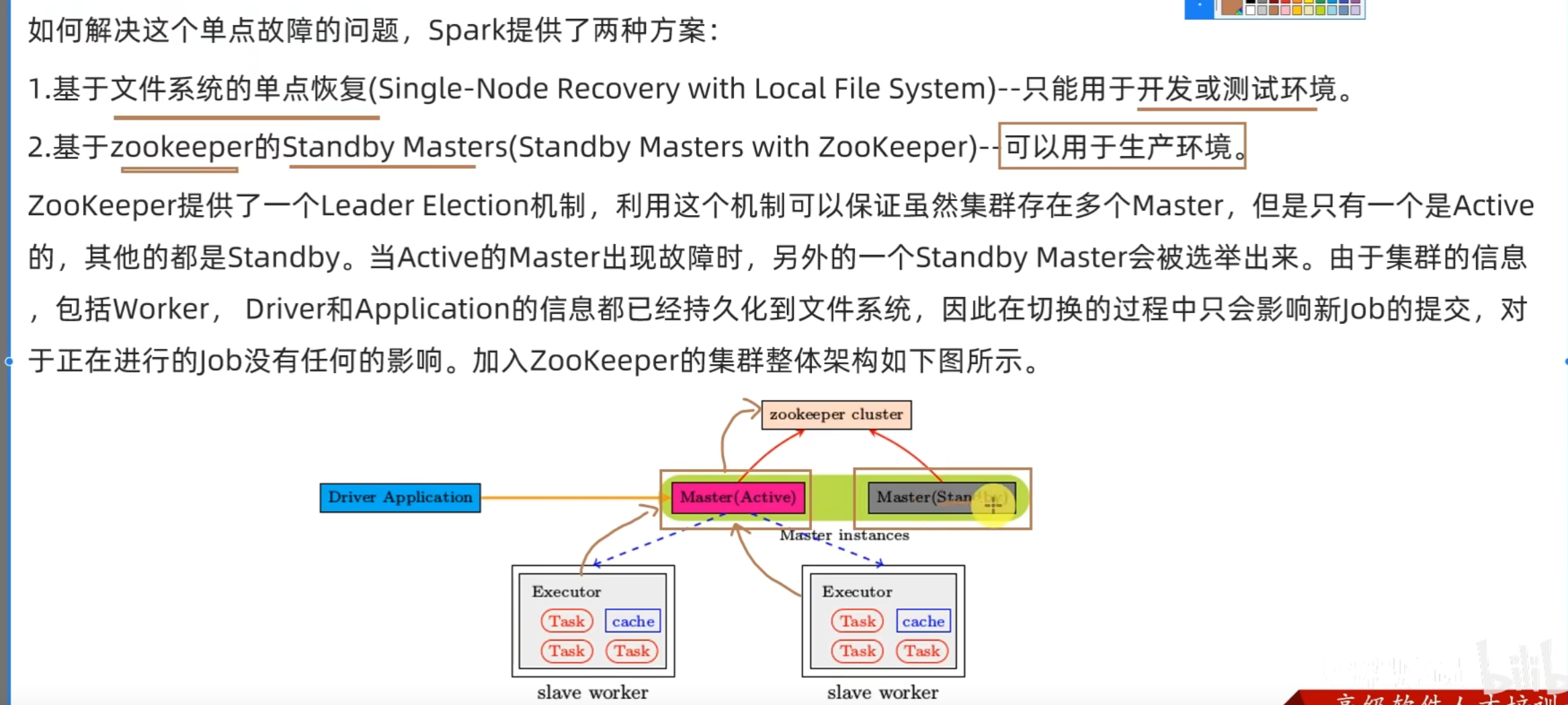
4.2 基于Zookeeper实现HA
spark配置双master时一直处于standby的情况
4.3 总结
- StandAloneHA的原理
基于Zookeeper做状态的维护,开启多个Master进程,一个作为活跃,其他的作为备份,当活跃进程宕机,备份的Master进行接管。
第五章:Spark环境搭建-Spark On YARN
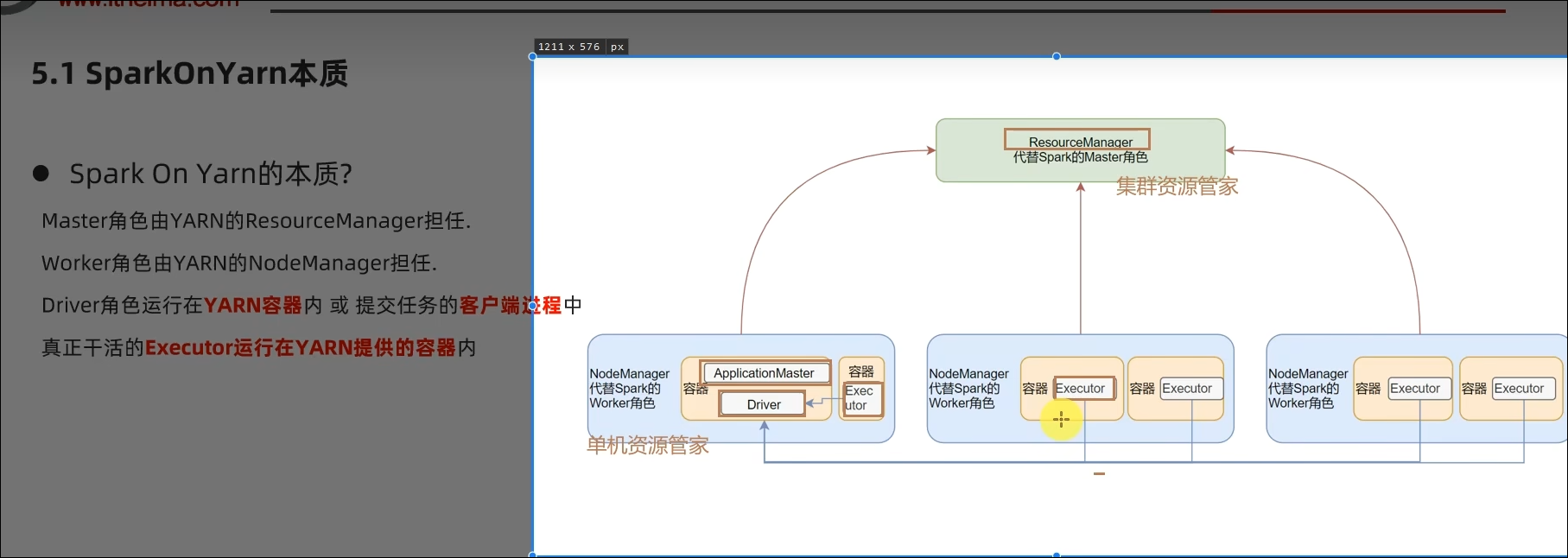
5.1 Spark On YARN的运行原理


5.2 Spark On YARN部署和测试
详见视频
5.3 部署模式DeployMode
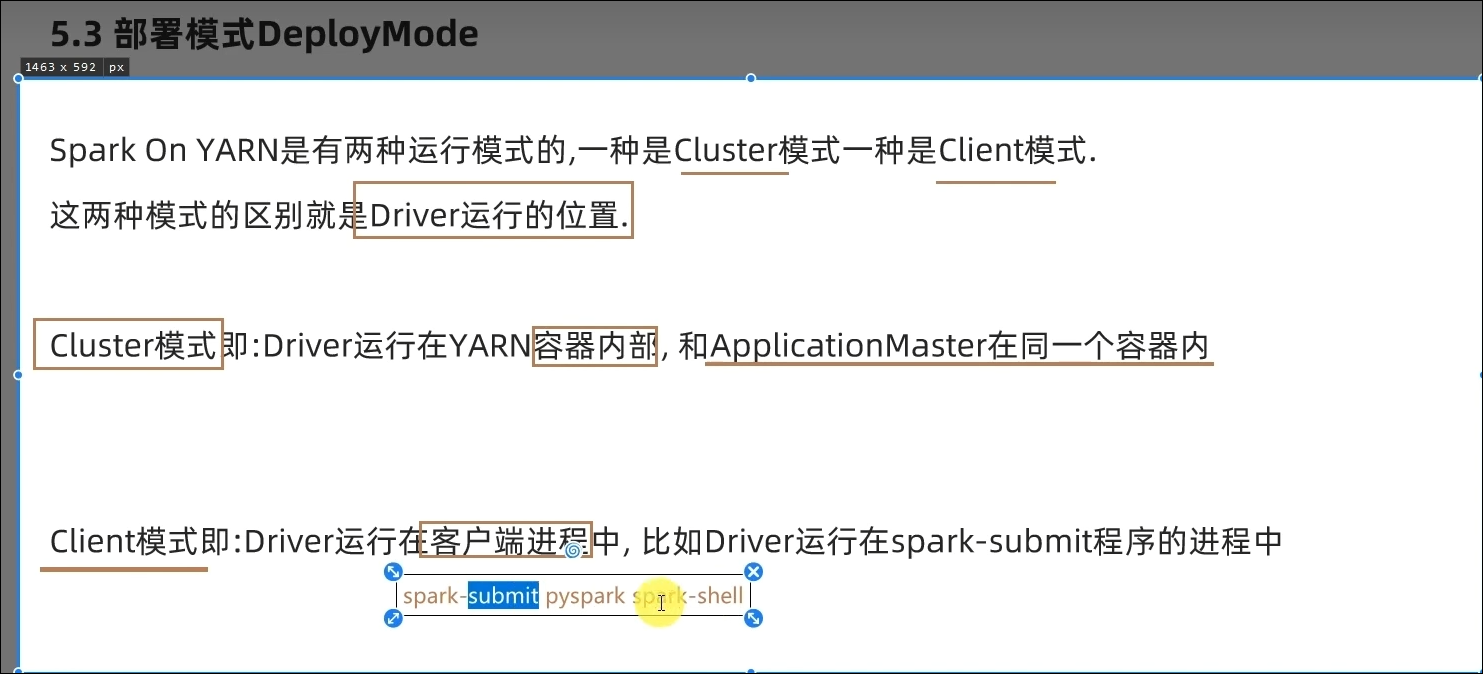
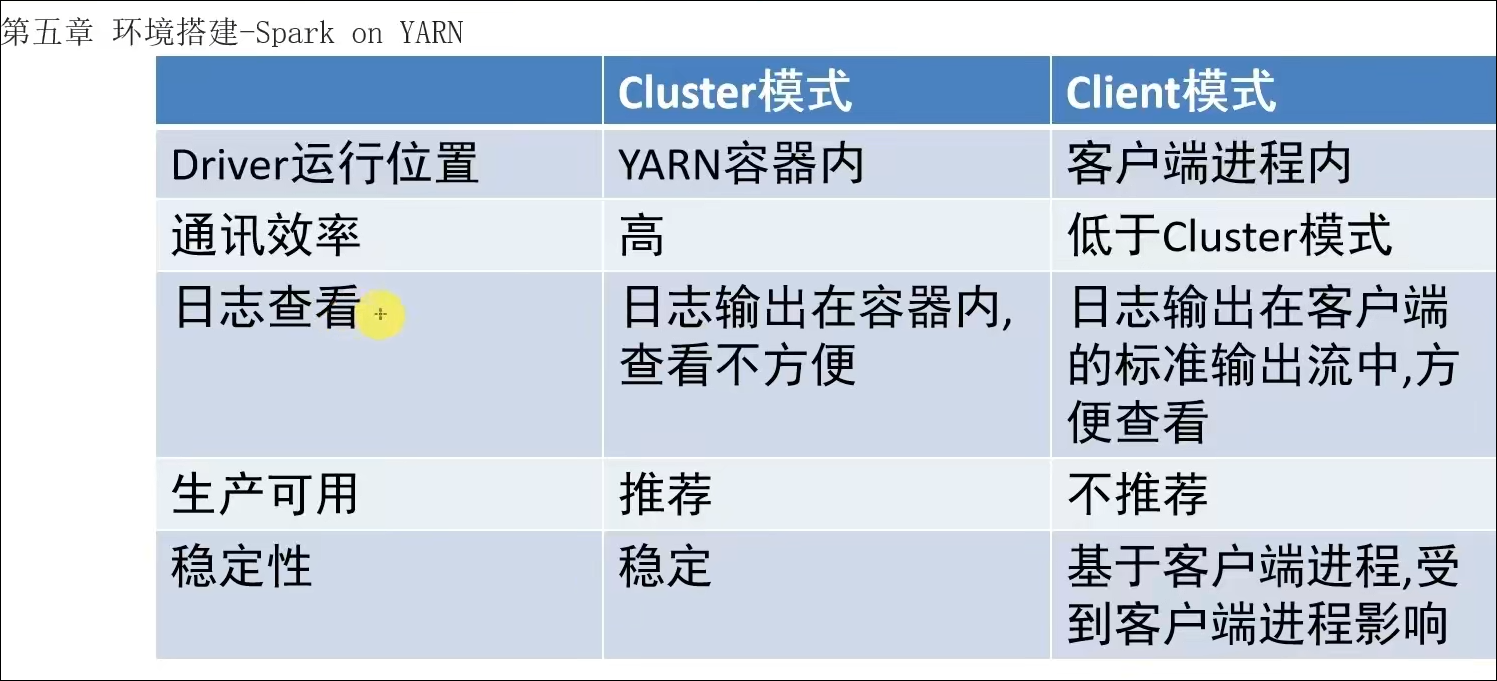
5.4 两种部署模式的演示和总结
Cluster模式
bin/spark-submit --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --num-executors 3 --total-executor-cores 3 /export/server/spark/examples/src/main/python/pi.py 100
需要通过下面命令打开Yarn的历史服务器(JobHistoryServer)
mapred --daemon start historyserver
Client模式
bin/spark-submit --master yarn --deploy-mode client --driver-memory 512m --executor-memory 512m --num-executors 3 --total-executor-cores 3 /export/server/spark/examples/src/main/python/pi.py 100

5.5 两种模式任务提交流程
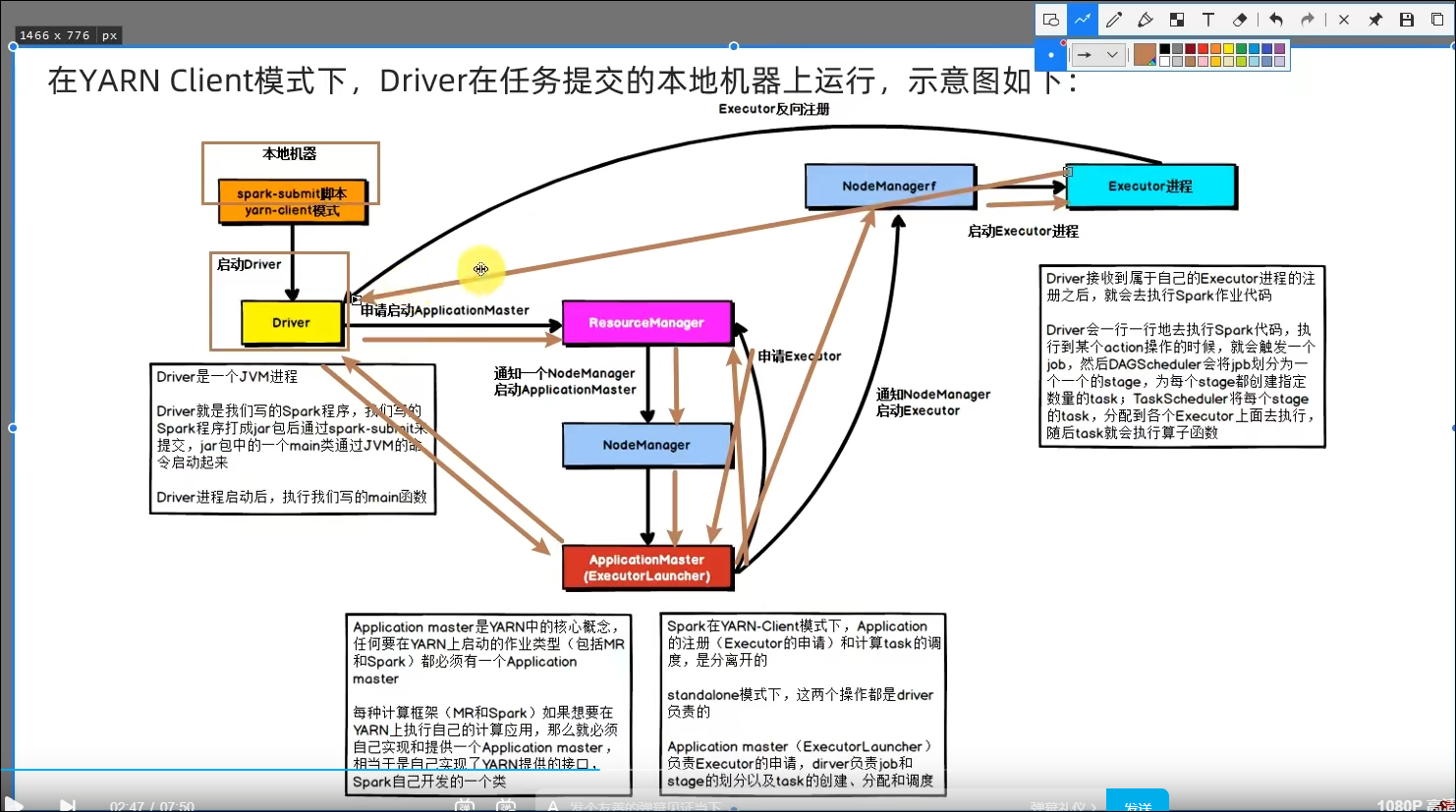
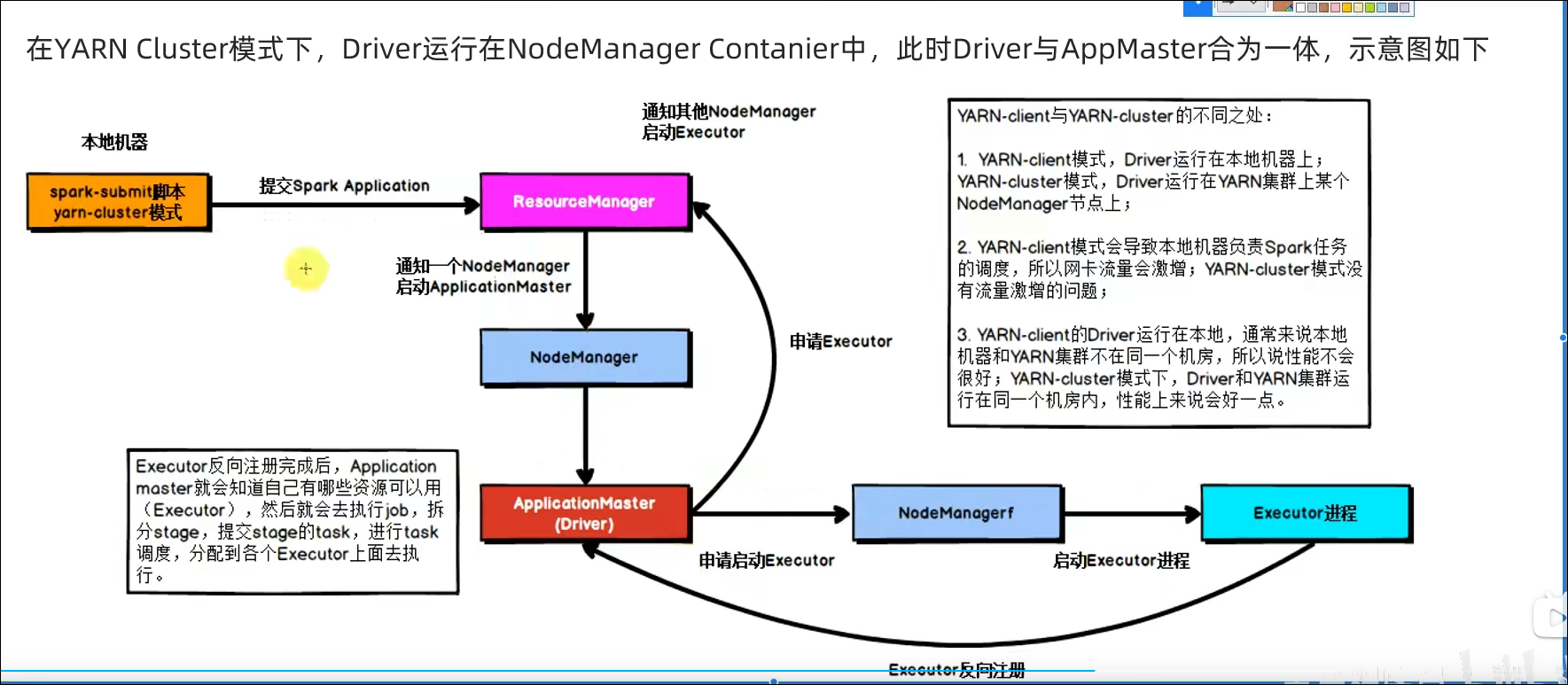
5.6 总结
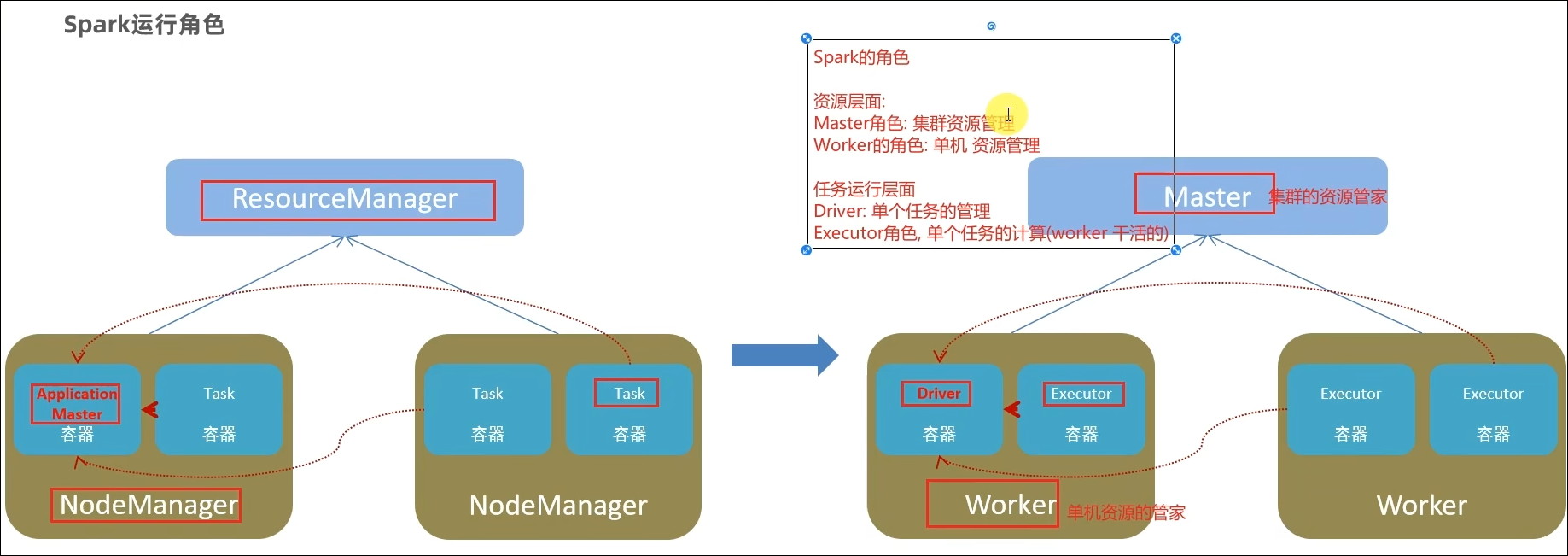
- SparkOnYarn本质?
Master由ResourceManager代替
Worker由NodeManager代替
Driver可以运行在容器内(Cluster模式)或客户端进程中(Client模式)
Executor全部运行在YARN提供的容器内
- Why Spark On YARN?
提供资源利用率,在已有YARN的场景下让Spark收到YARN的调度可以更好的管控资源提高利用率并方便管理。
第六章:PySpark库
6.1 框架 VS 类库

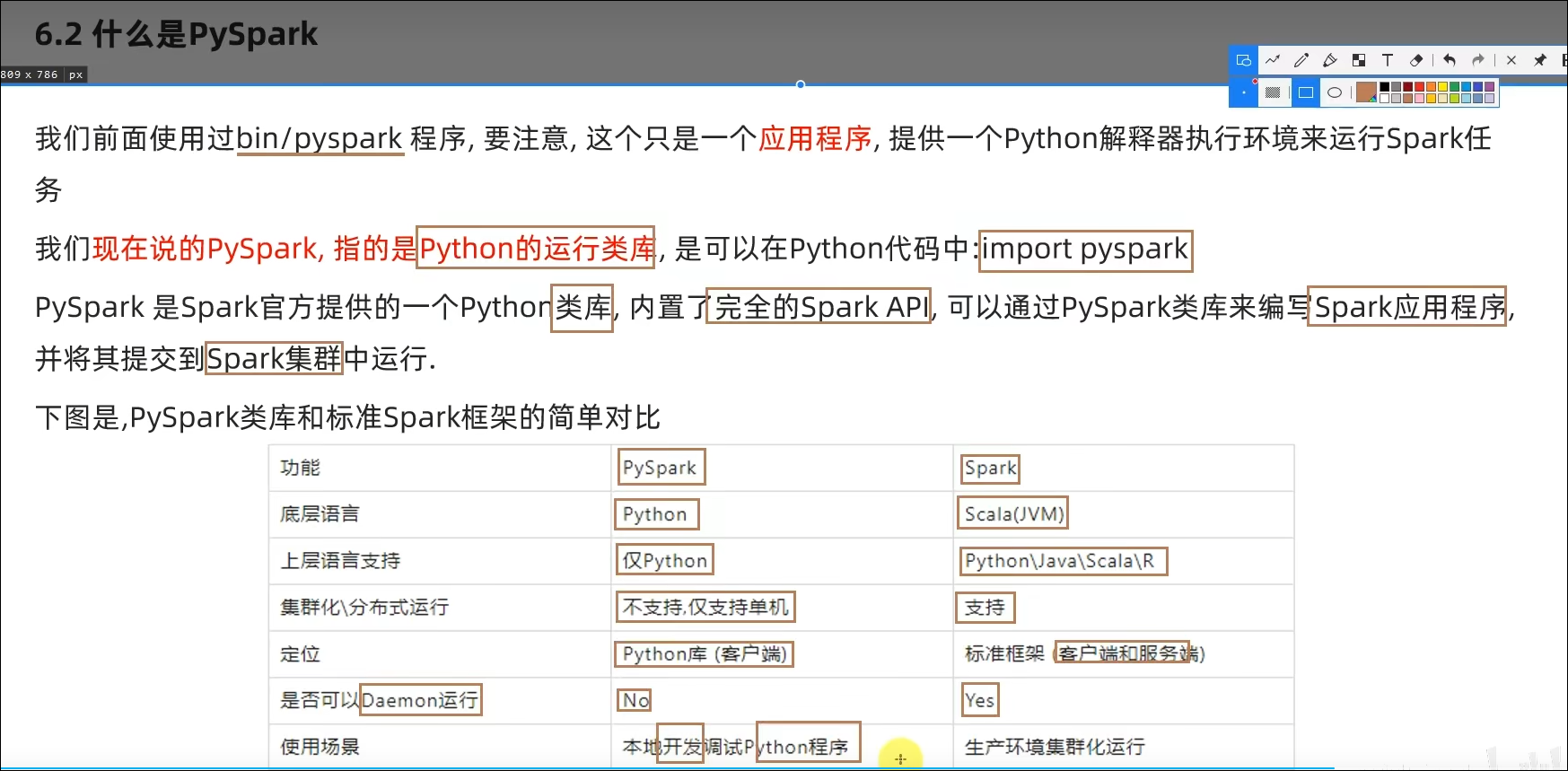
6.2 PySpark类库介绍
6.3 PySpark安装
详见视频
6.4 总结
- PySpark是什么?和bin/pyspark程序有何区别?
PySpark是一个Python的类库,提供Spark的操作API
bin/pyspark是一个交互式的程序,可以提供交互式编程并执行Spark计算
- 本课程的Python运行环境由什么来提供?
由Anaconda提供,并使用虚拟环境,环境名称叫做:pyspark
第七章:本机开发环境搭建
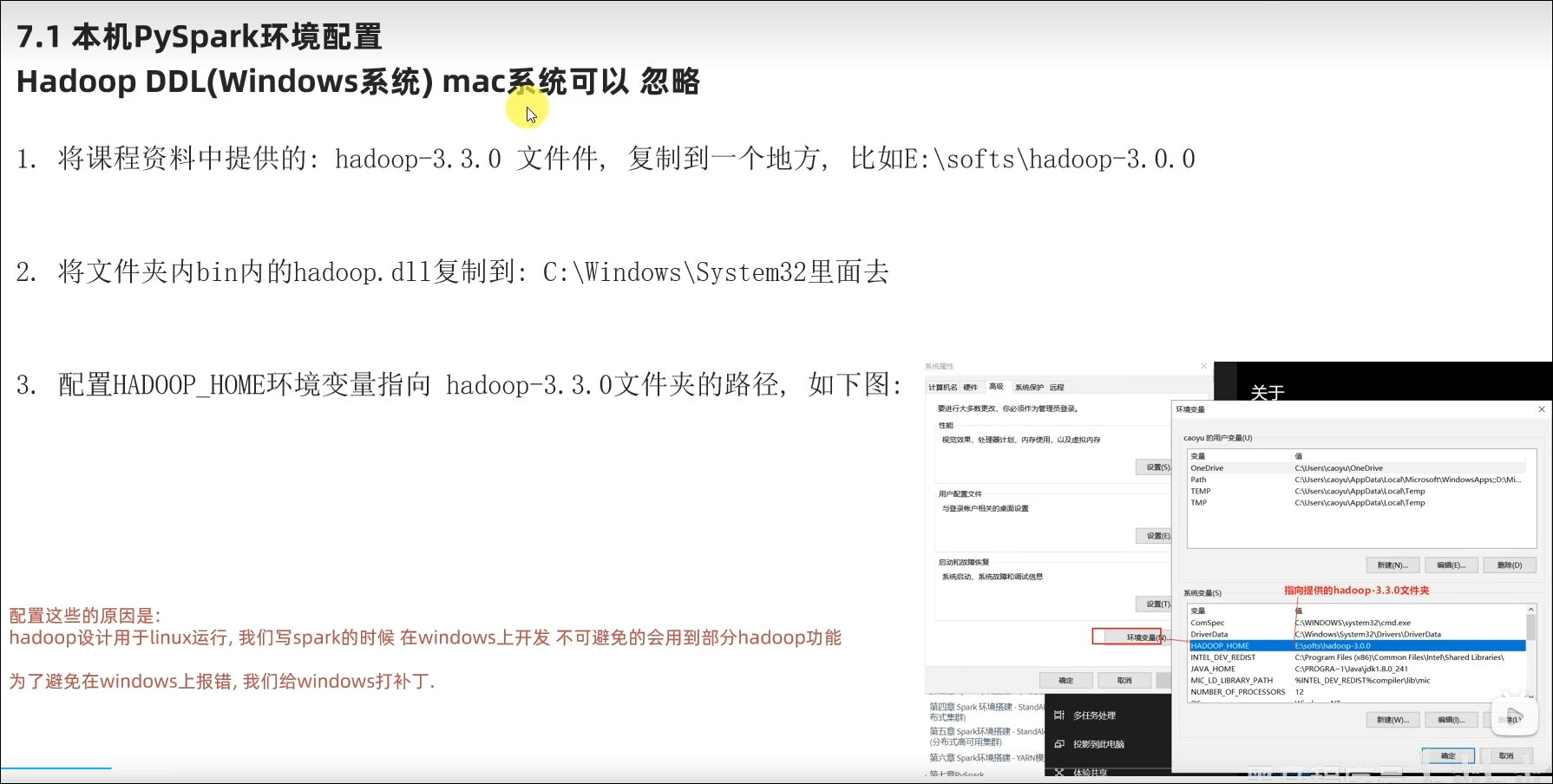
7.1 本机配置Python环境
7.2 PyCharm本地和远程解释器配置
详见视频
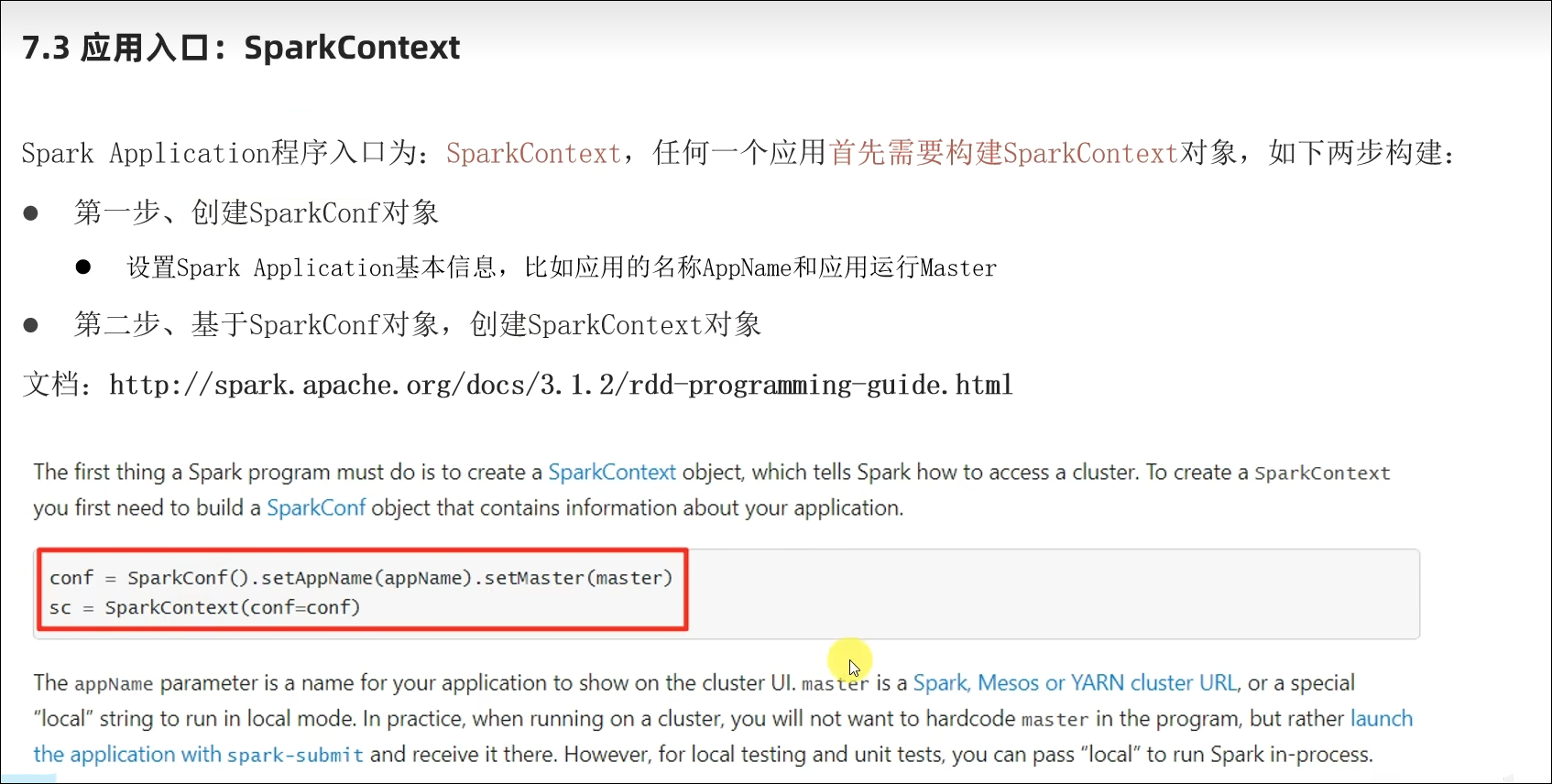
7.3 编程入口SparkContext对象以及WordCount演示
PS:解决WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform…警告

找了好几个都不行。
PS:解决

参考资料https://blog.csdn.net/weixin_51951625/article/details/117452855
https://blog.csdn.net/OWBY_Phantomhive/article/details/123088763
https://blog.csdn.net/qq_20540901/article/details/123499540

需要配置环境变量
7.4 WordCount代码流程解析
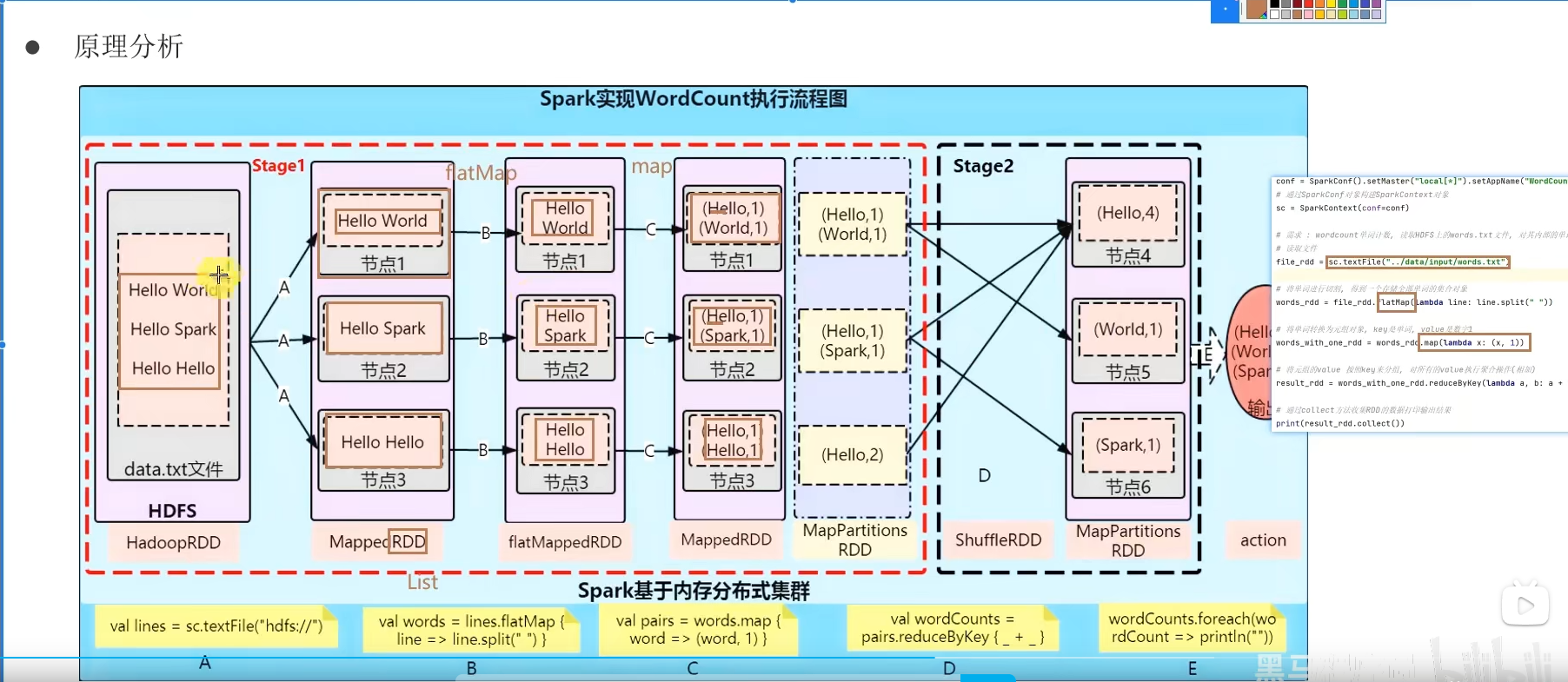
7.5 提交WordCount到Linux集群运行
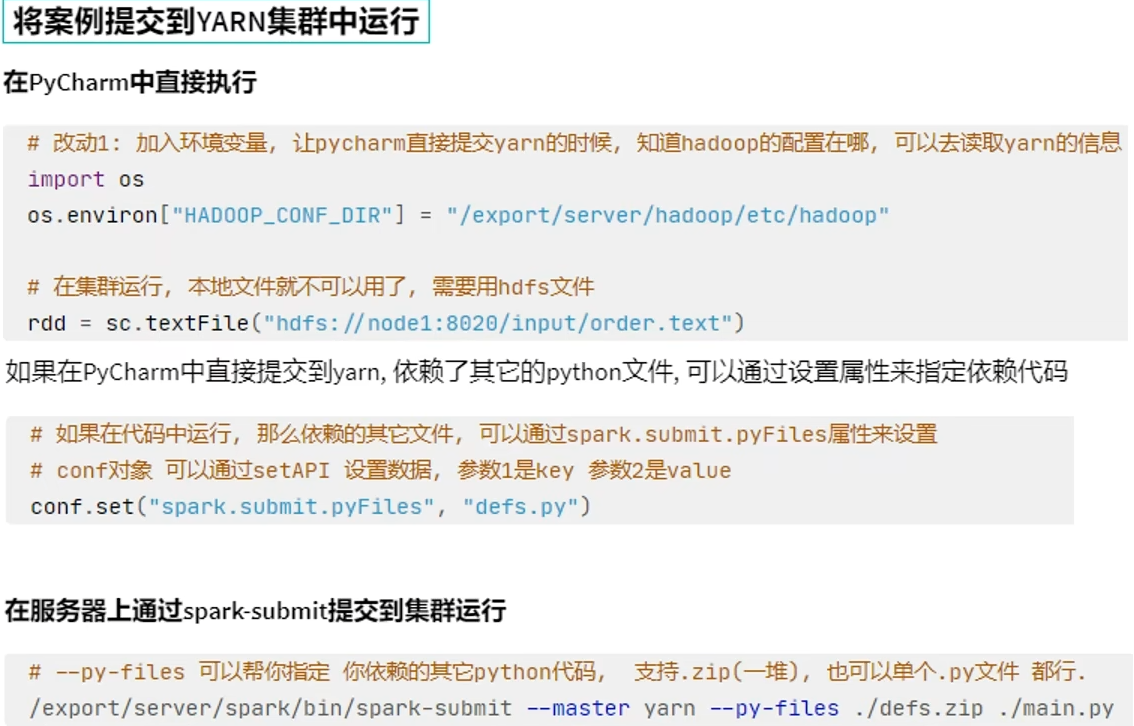
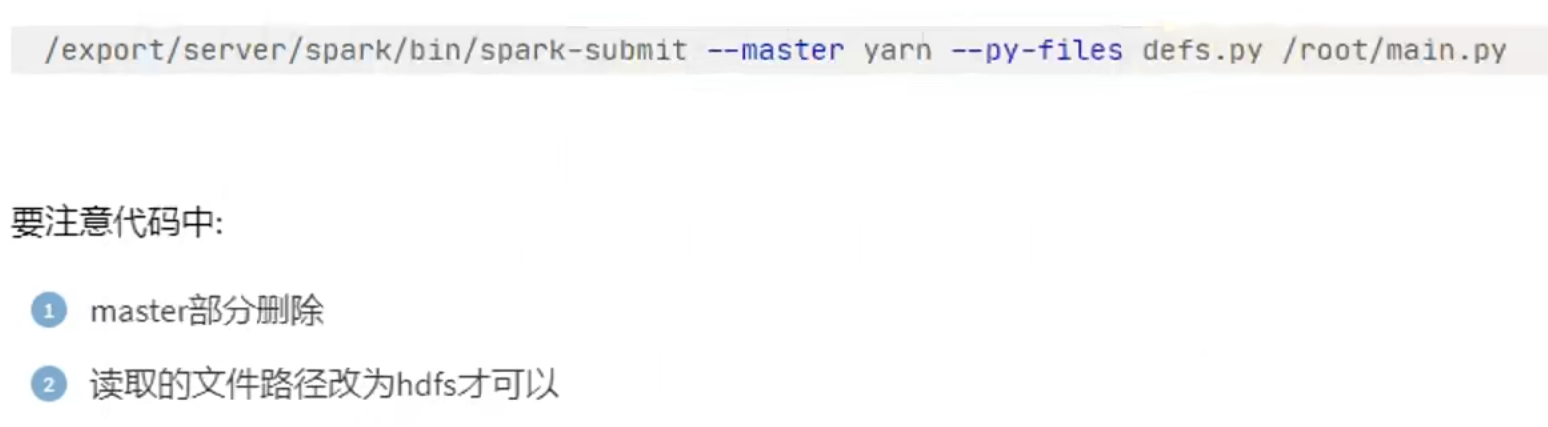
通过spark-submit yarn提交到集群的py文件中的地址,集群会默认去hdfs里面找。


在yarn模式或者standalone这样的集群下,访问的文件路径,要么是网络地址,要么是hdfs,这样每台机器都能访问到。
7.6 总结
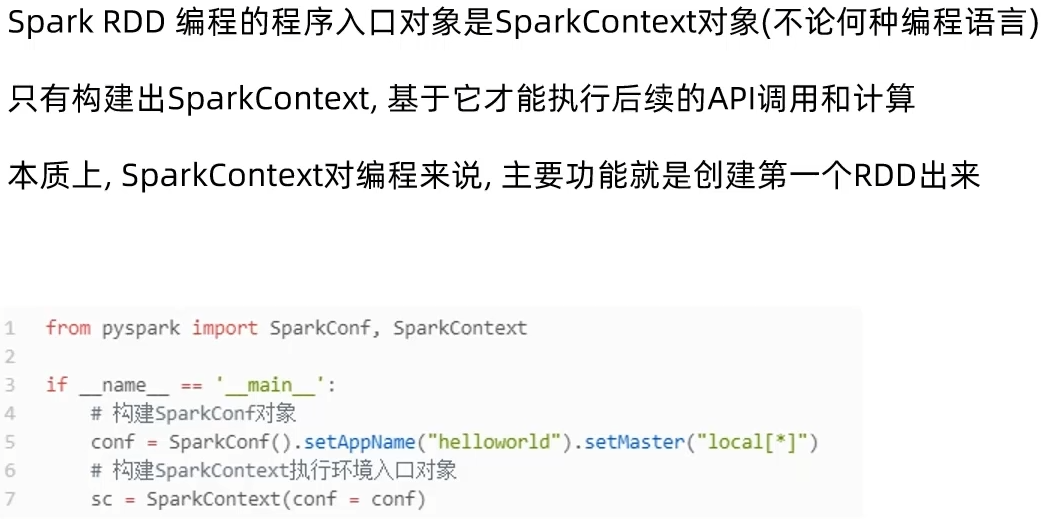
- Python语言开发Spark程序步骤?
主要是获取SparkContext对象,基于SparkContext对象作为执行环境入口。
- 如何提交Spark应用?
将程序代码上传到服务器上,通过spark-submit客户端工具进行提交。
1.在代码中不要设置master,如果设置了,会以代码为准,spark-submit工具的设置就无效了。
2.提交程序到集群中的时候,读取的文件一定是各个机器都能访问到的地址。比如HDFS。
第八章:分布式代码执行分析
8.1 Spark运行角色回顾
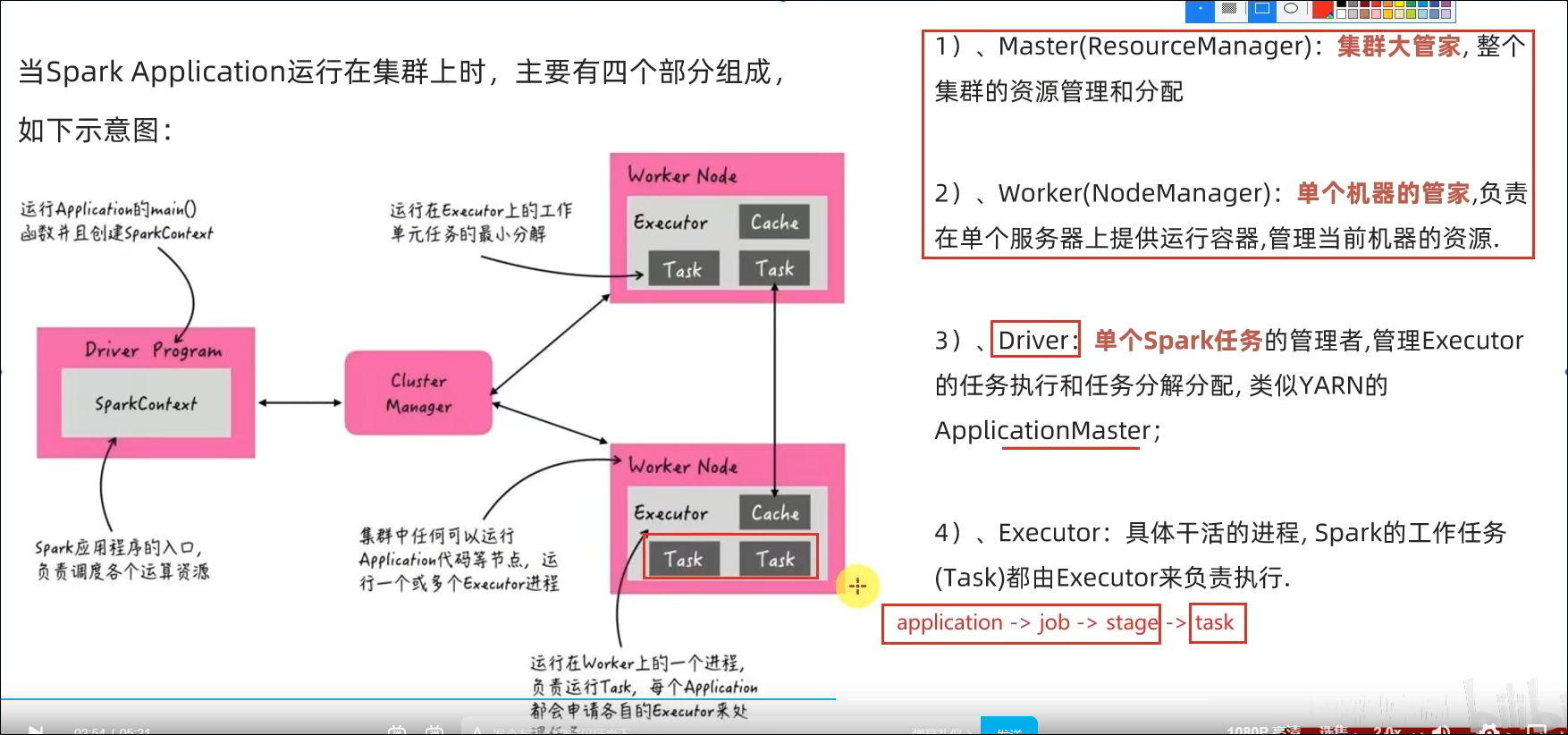
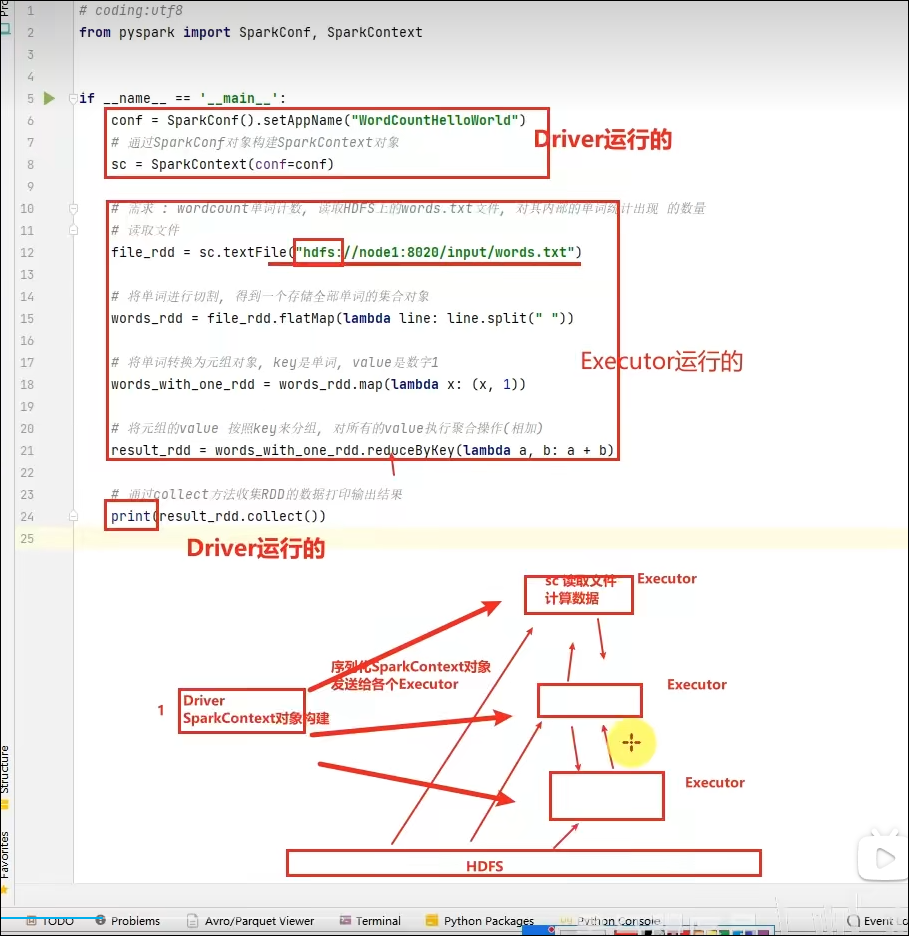
8.2 分布式代码执行分析
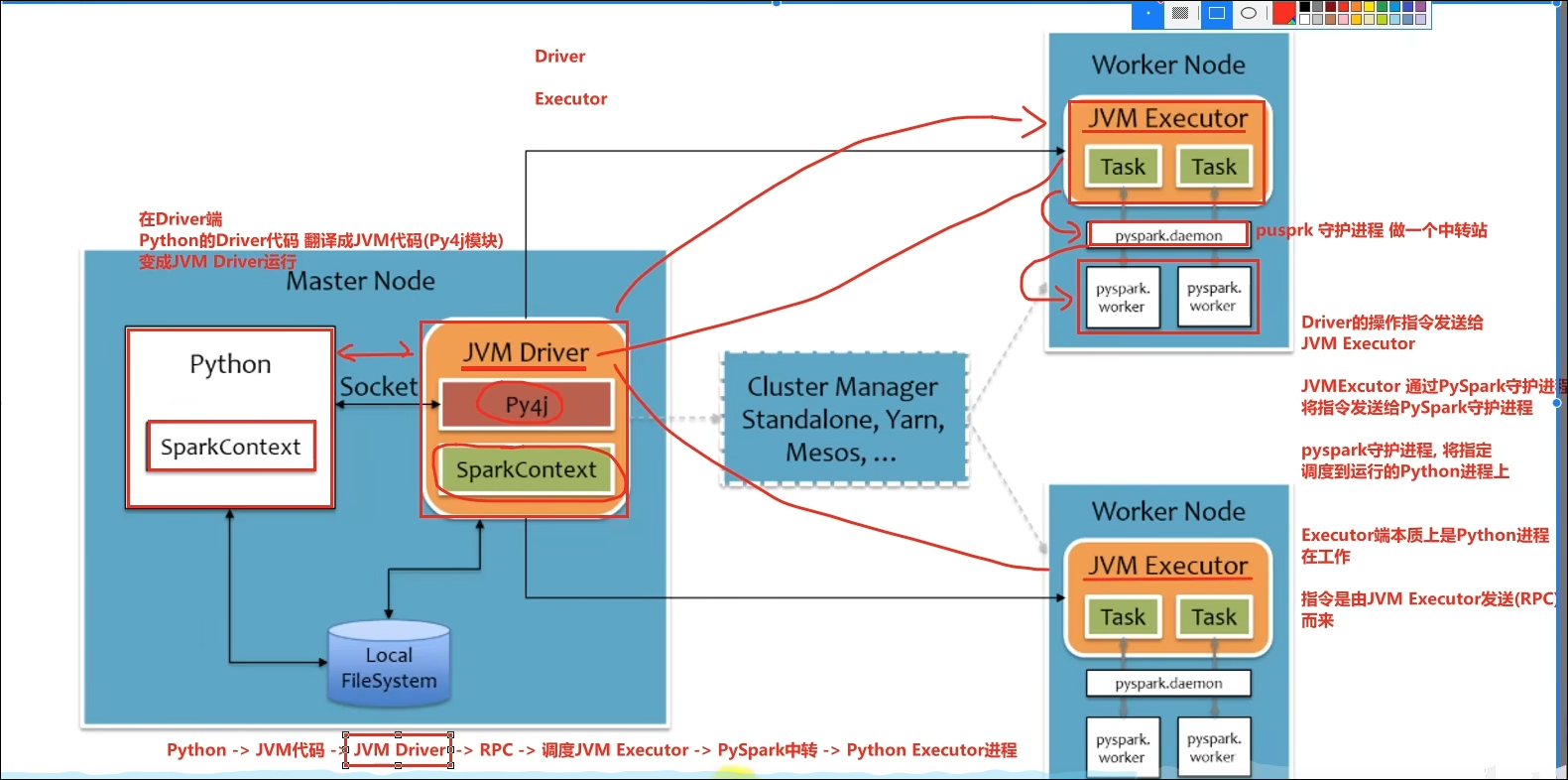
8.3 Python On Spark执行原理

8.4 总结
- 分布式代码执行的重要特征是什么?
代码在集群上运行,是被分布式运行的。
在Spark中, 非任务处理部分,由Driver执行(非RDD代码)。
任务处理部分由Executor执行(RDD代码)。
Executor的数量很多,所以任务的计算是分布式在运行的。
- 简述PySpark的架构体系。
Python On Spark:Driver端由JVM执行,Executor端由JVM做命令转发,底层由Python解释器进行工作。
2.Spark核心
学习目标
- 了解RDD产生背景
- 掌握RDD的创建
- 掌握RDD的重要算子
- 掌握RDD的缓存和检查点机制
- 熟悉Spark执行的基本原理
第一章:RDD详解
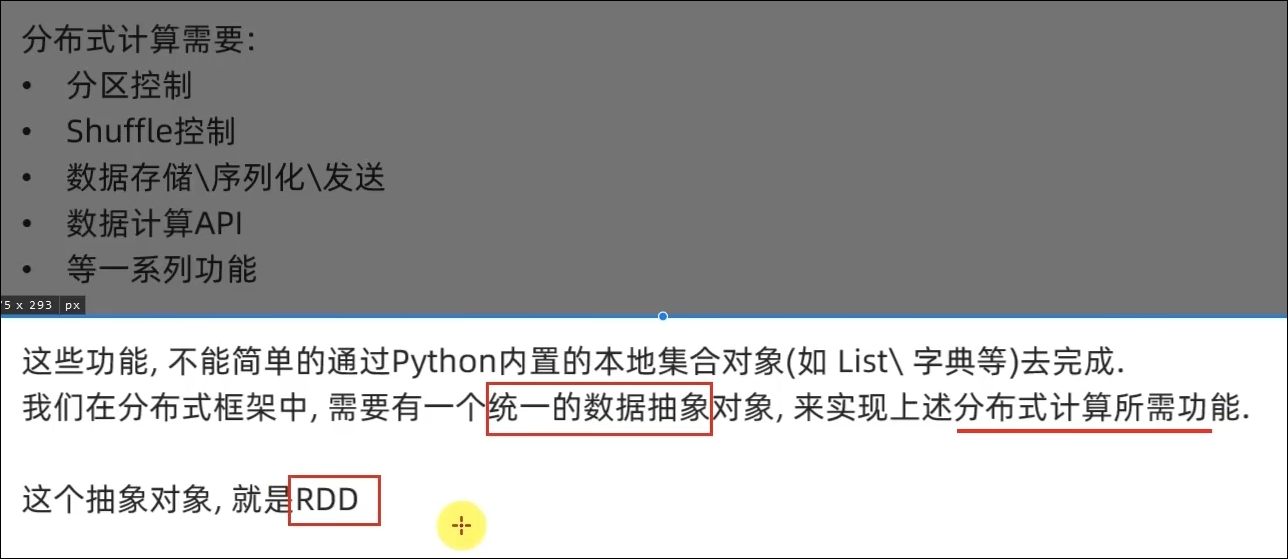
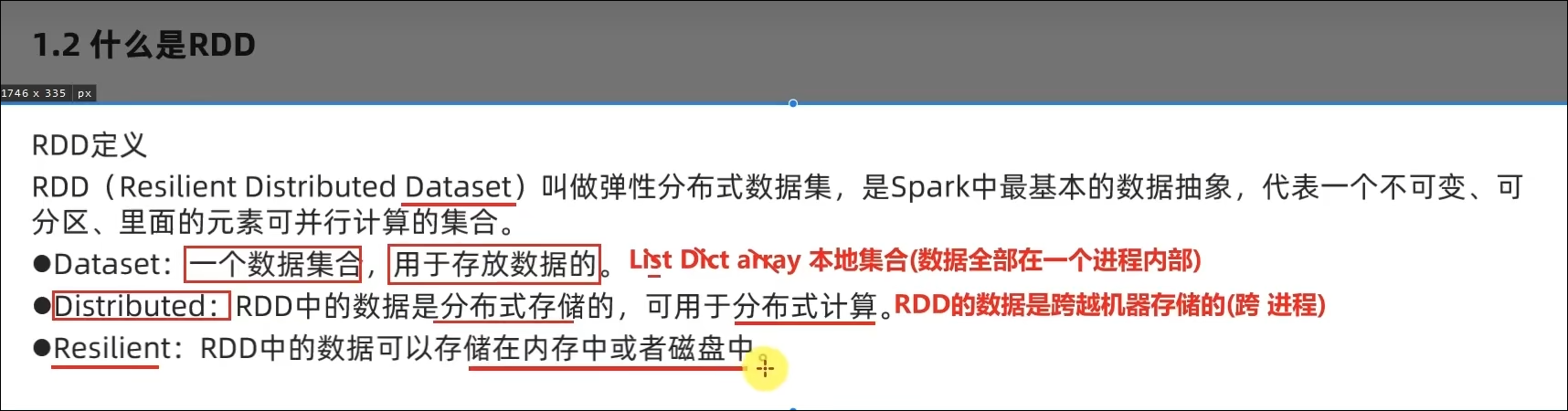
1.1 什么是RDD

1.2 RDD五大特性-特性1
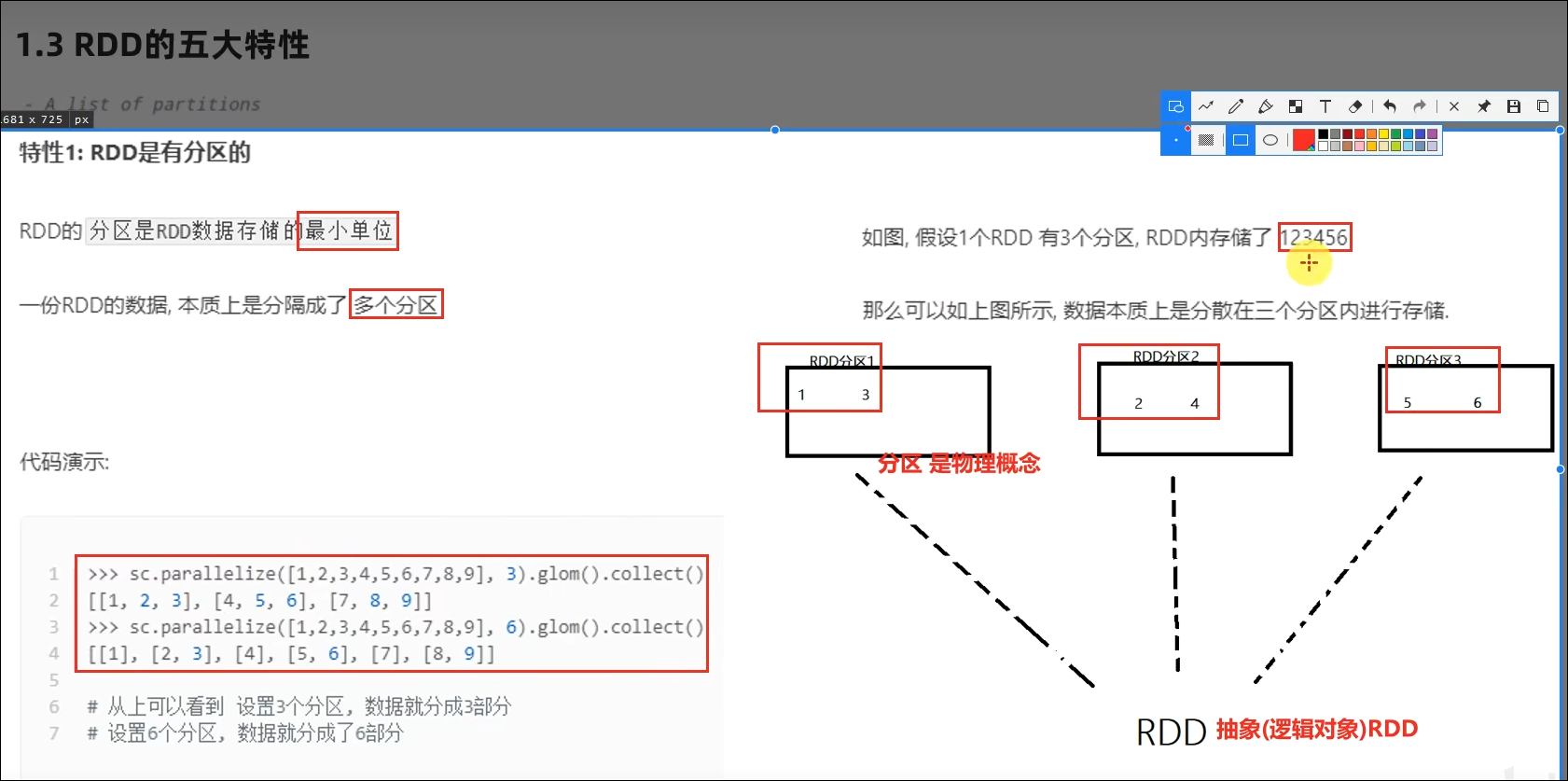
1.3 RDD五大特性-特性2

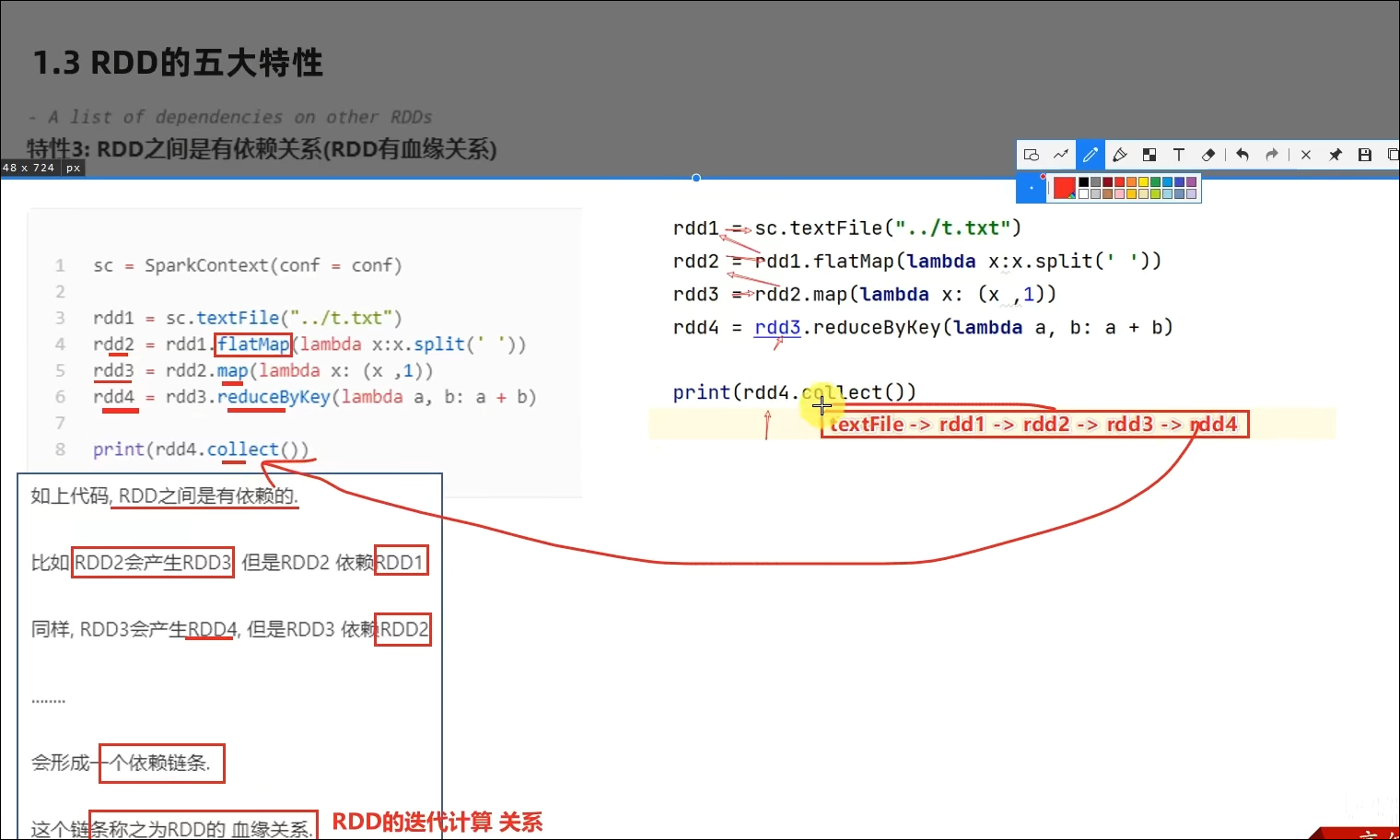
1.4 RDD五大特性-特性3
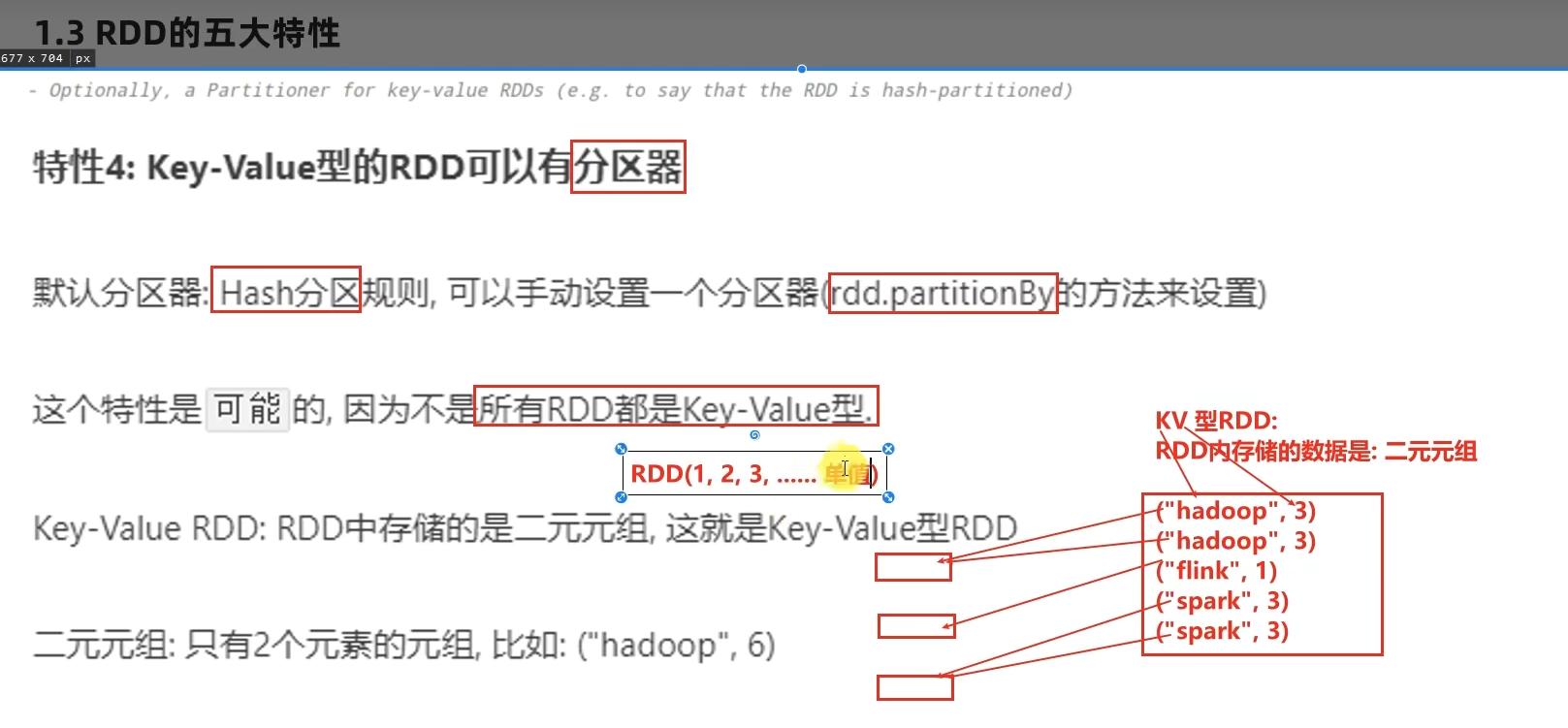
1.5 RDD五大特性-特性4
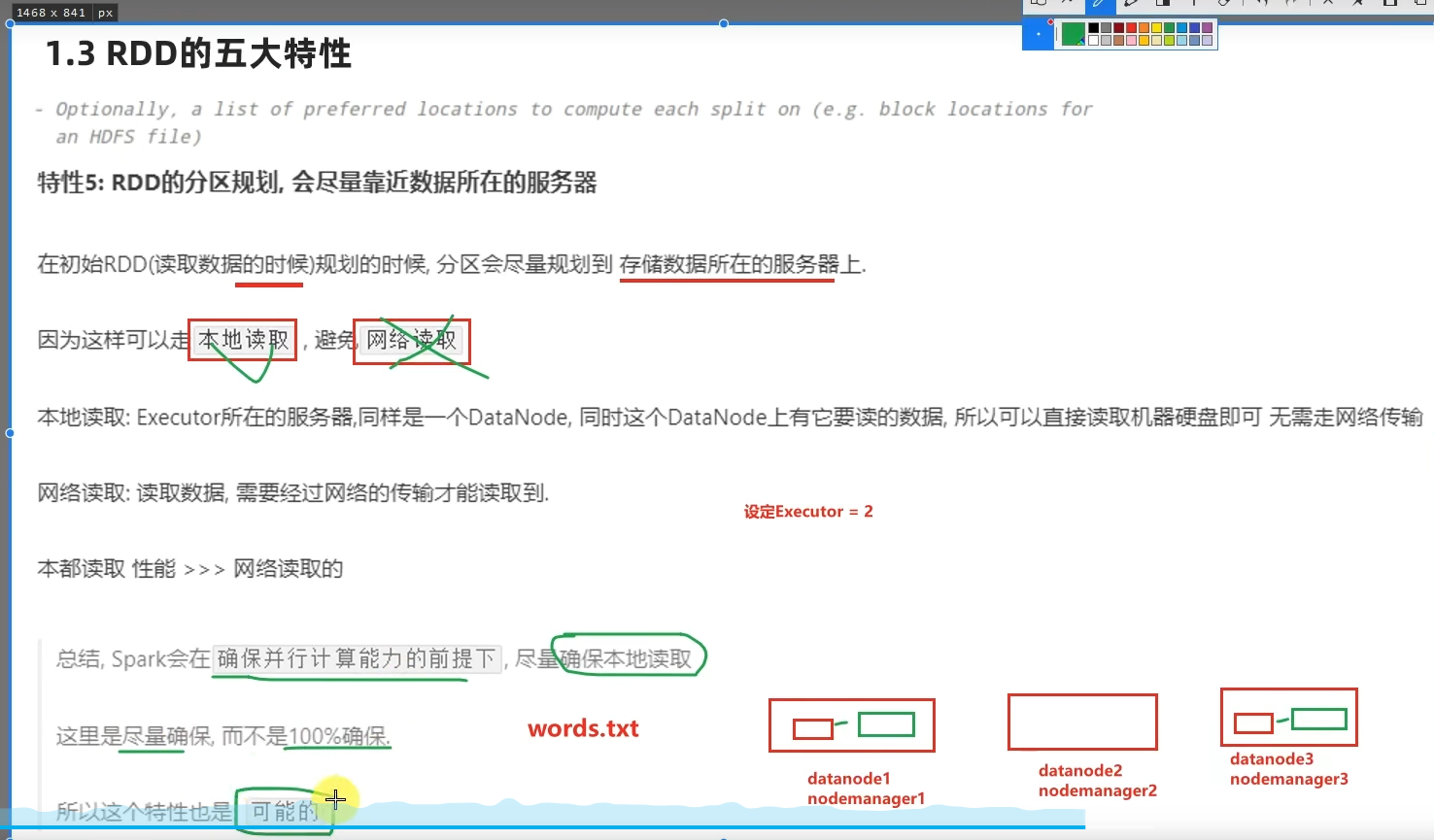
1.6 RDD五大特性-特性5
1.7 WordCount结合RDD特性进行执行分析
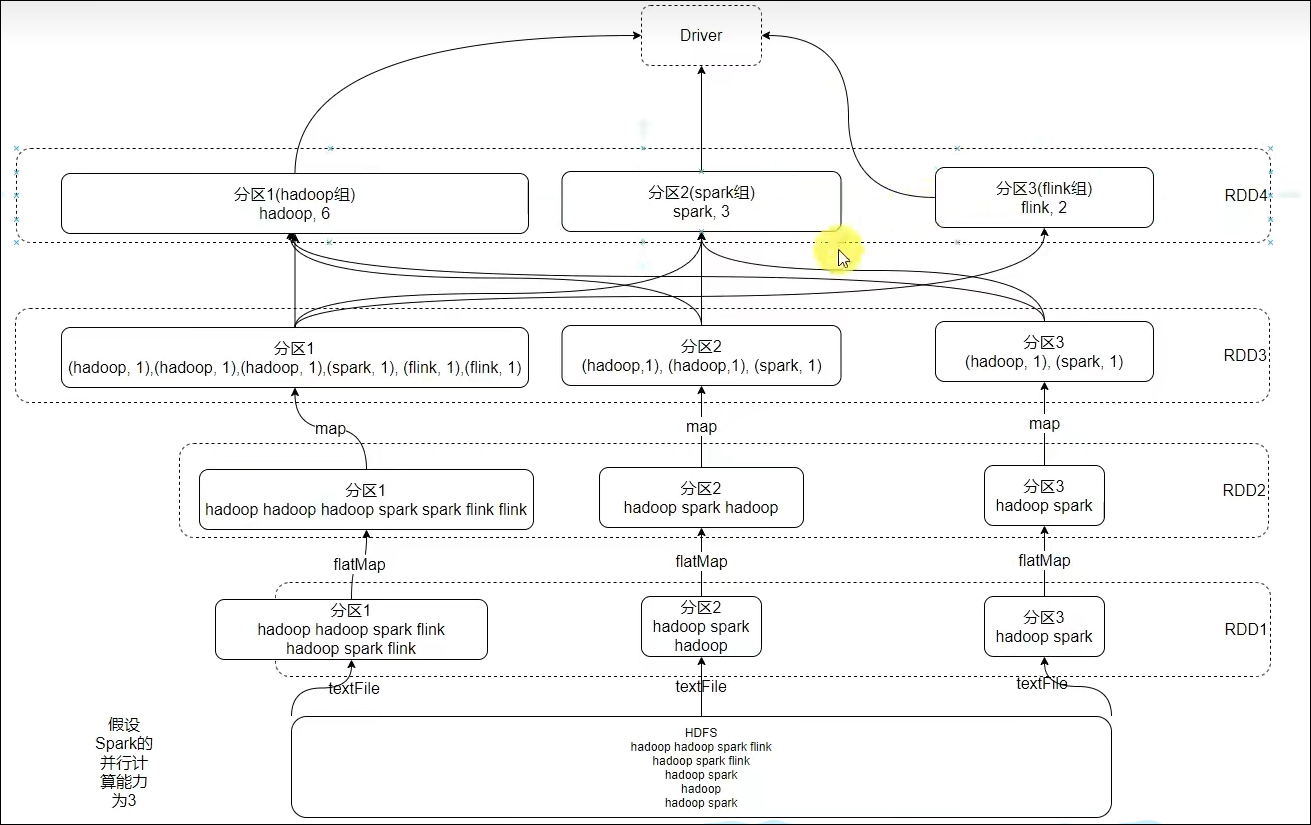
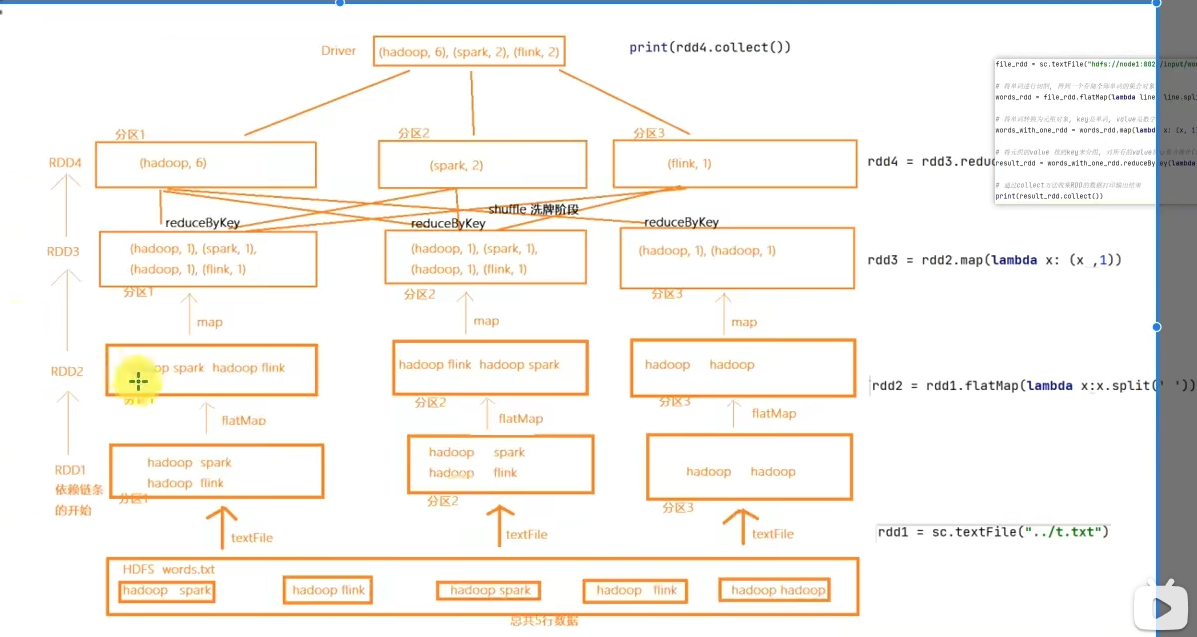
1.8 第一章总结
- 如何正确理解RDD?
不可变、可分区、并行计算的弹性分布式数据集,分布式计算的实现载体(数据抽象)
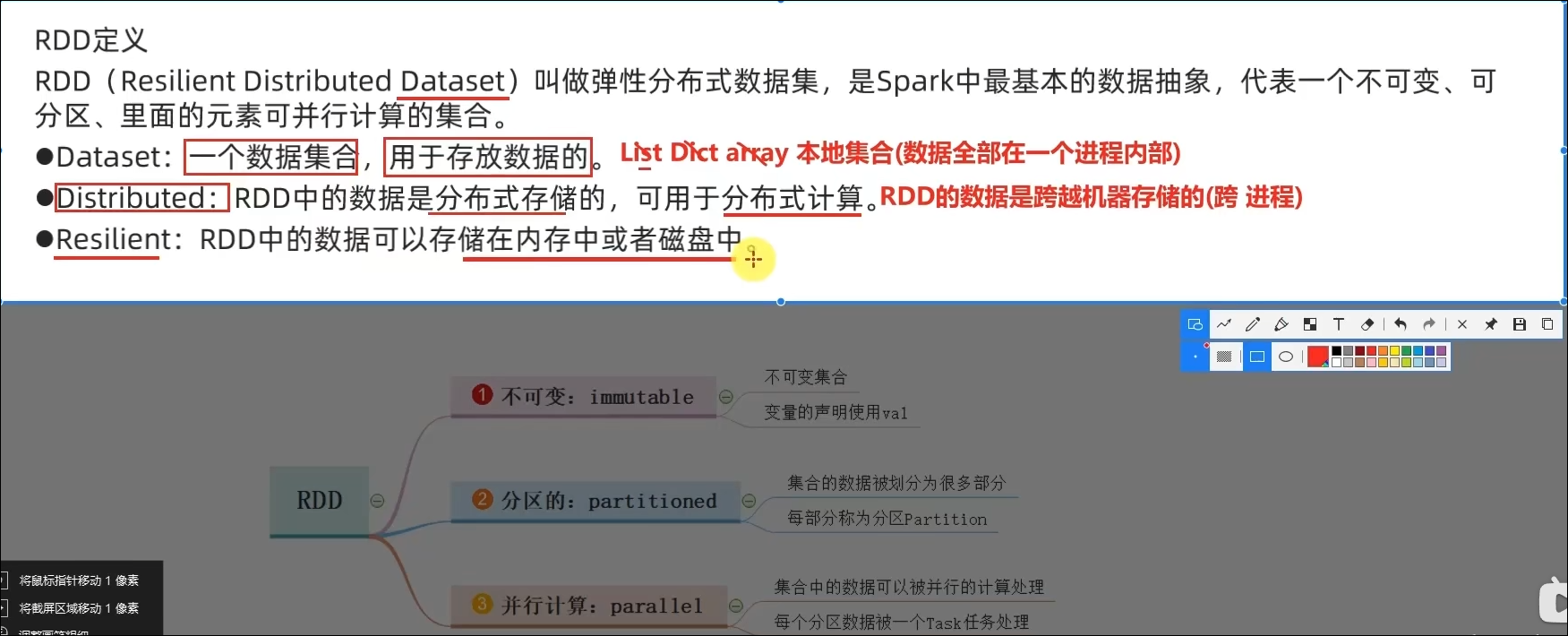
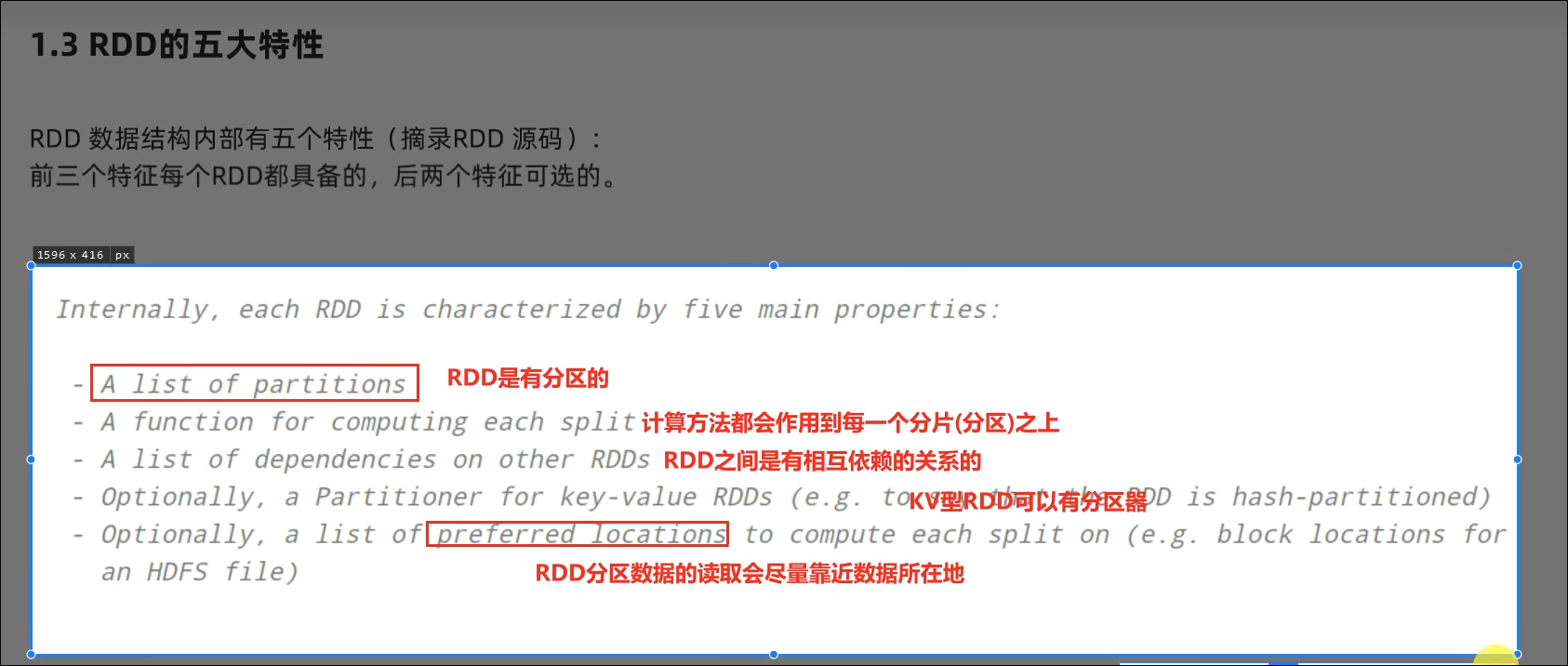
- RDD五大特点分别是?
RDD有分区;RDD的方法会作用在所有分区上;RDD之间有依赖关系;KV型的RDD是有分区器的;RDD的分区规划,会尽量靠近数据所在服务器。
第二章:RDD编程入门
2.1 程序执行入口SparkContext对象
2.2 RDD的创建
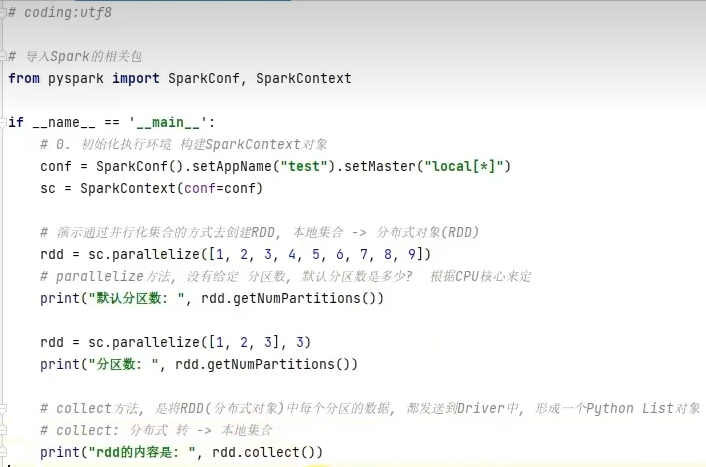
方式一:通过并行化集合创建(本地对象转分布式RDD)
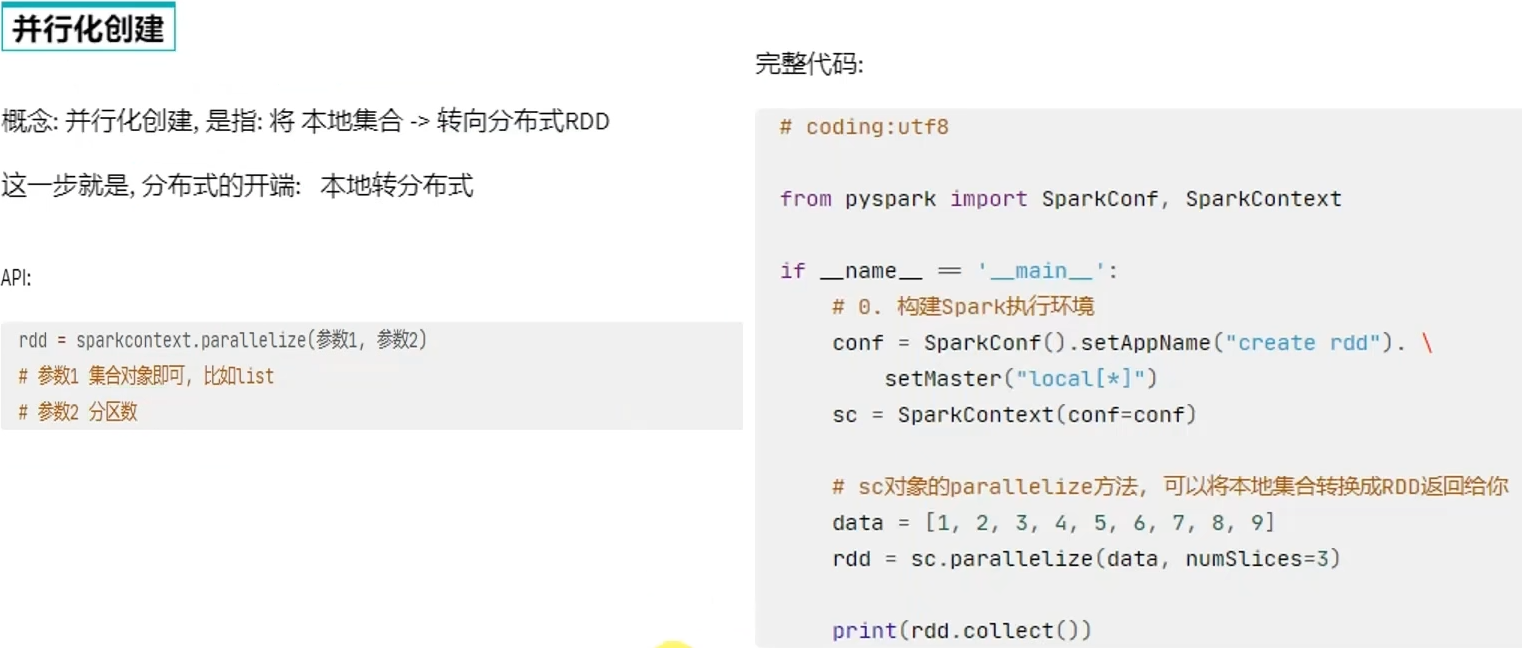
在local[*]方法下,parallelize方法,没有给定分区数的情况下,默认分区数是根据CPU核心数来定。
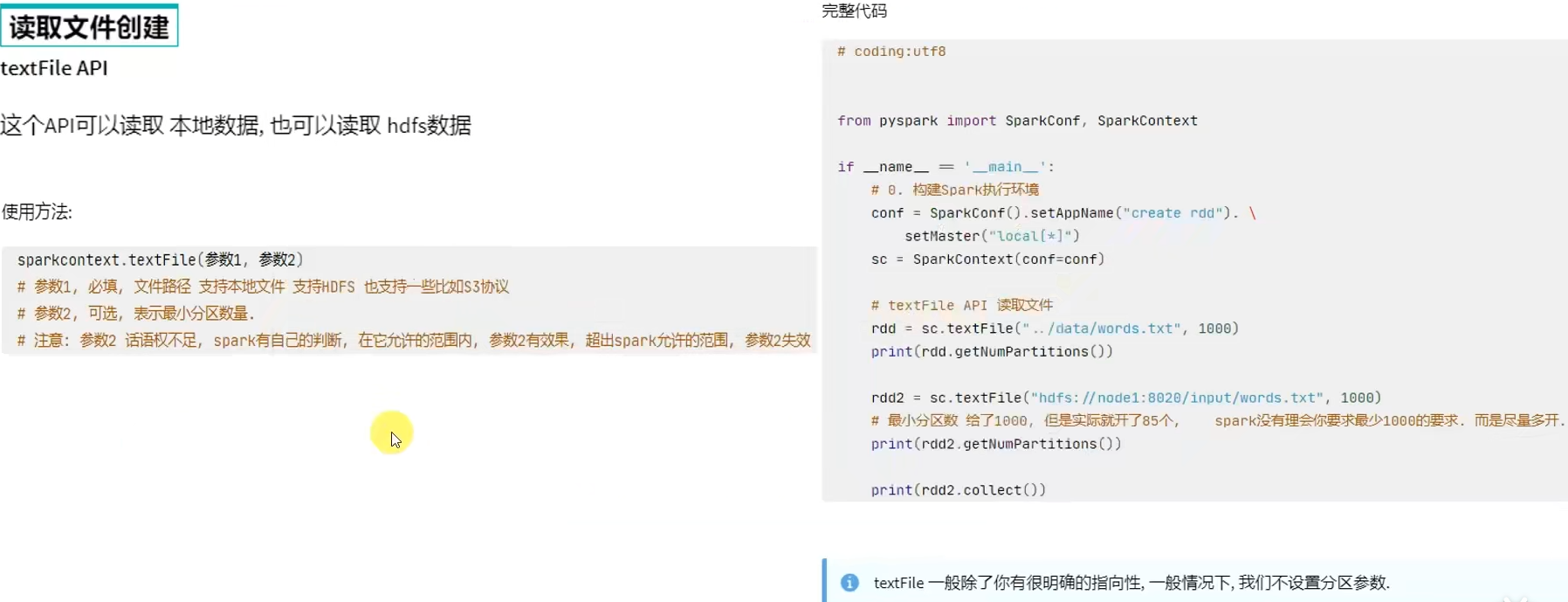
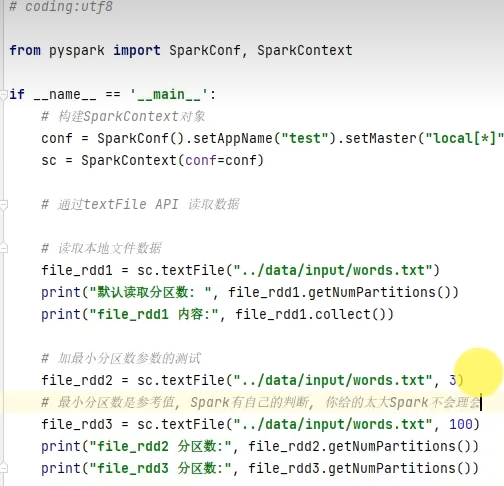
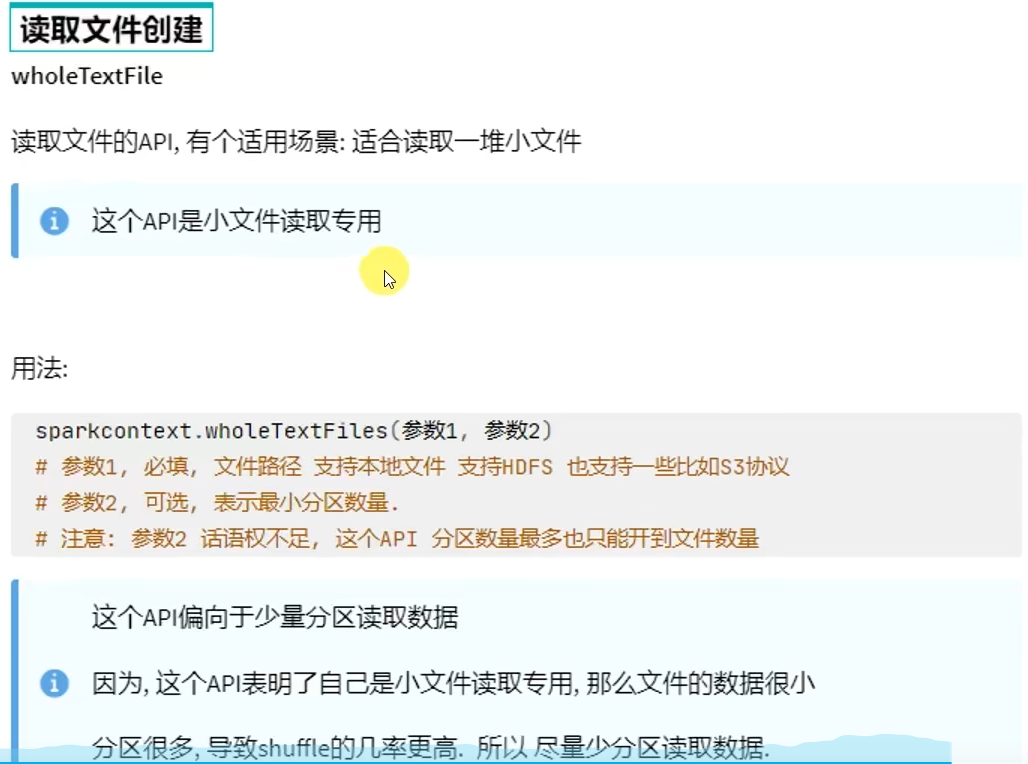
方式二:读取外部数据源
2.3 RDD算子概念和分类


2.4 常用转换算子
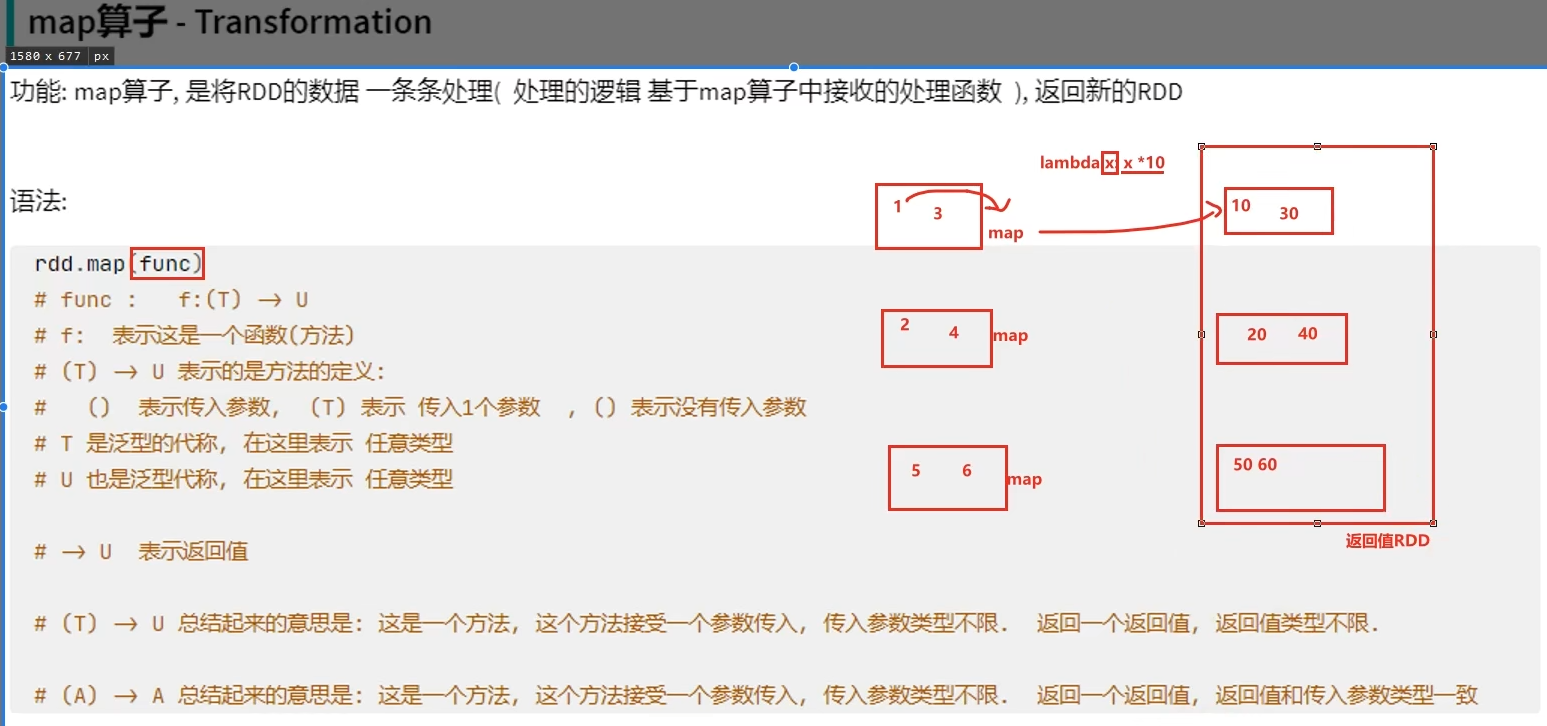
转换算子-map
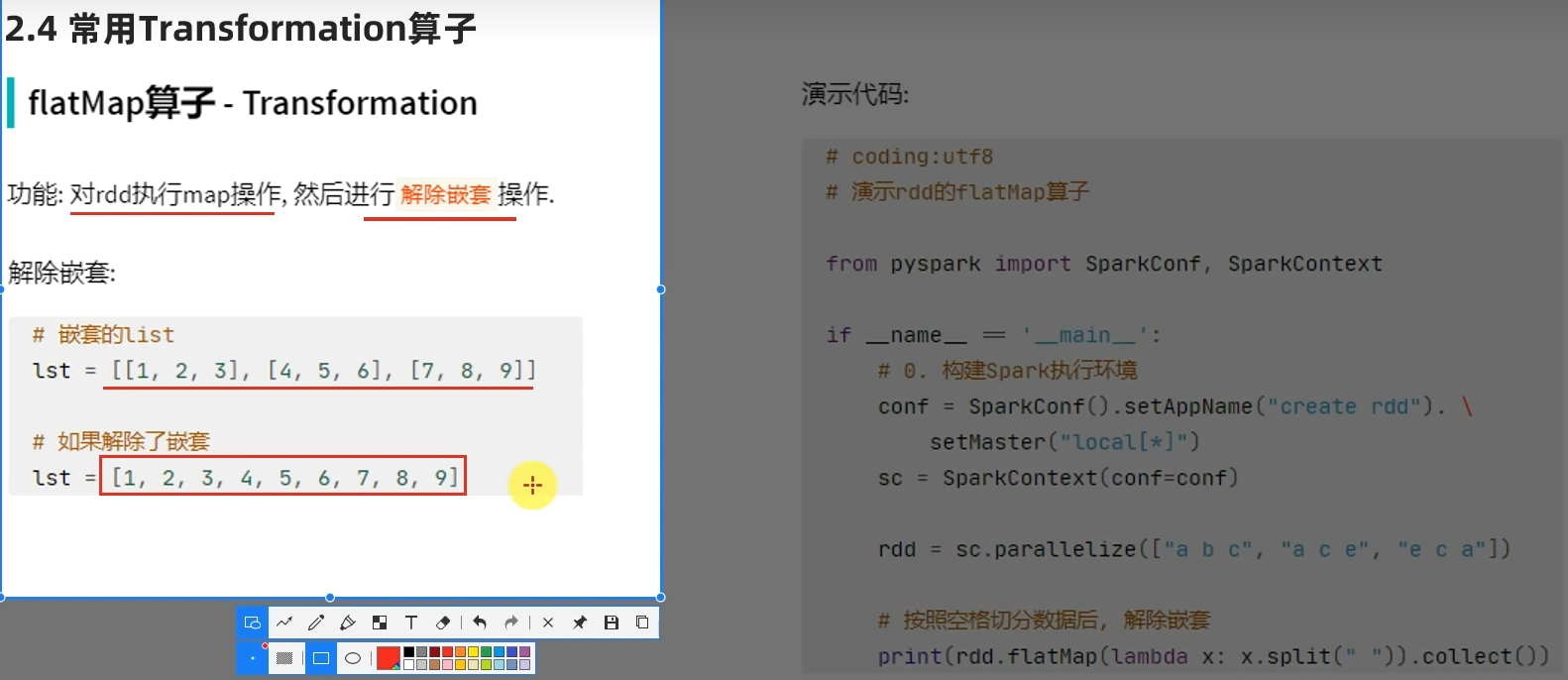
转换算子-flatMap

转换算子-reduceByKey

PS:报错:UserWarning: Please install psutil to have better support with spilling
参考资料:https://blog.csdn.net/sqlserverdiscovery/article/details/102936203

PS:未正确退出conda环境,会报错
参考资料:https://blog.csdn.net/weixin_44211968/article/details/122483304
conda deactivate
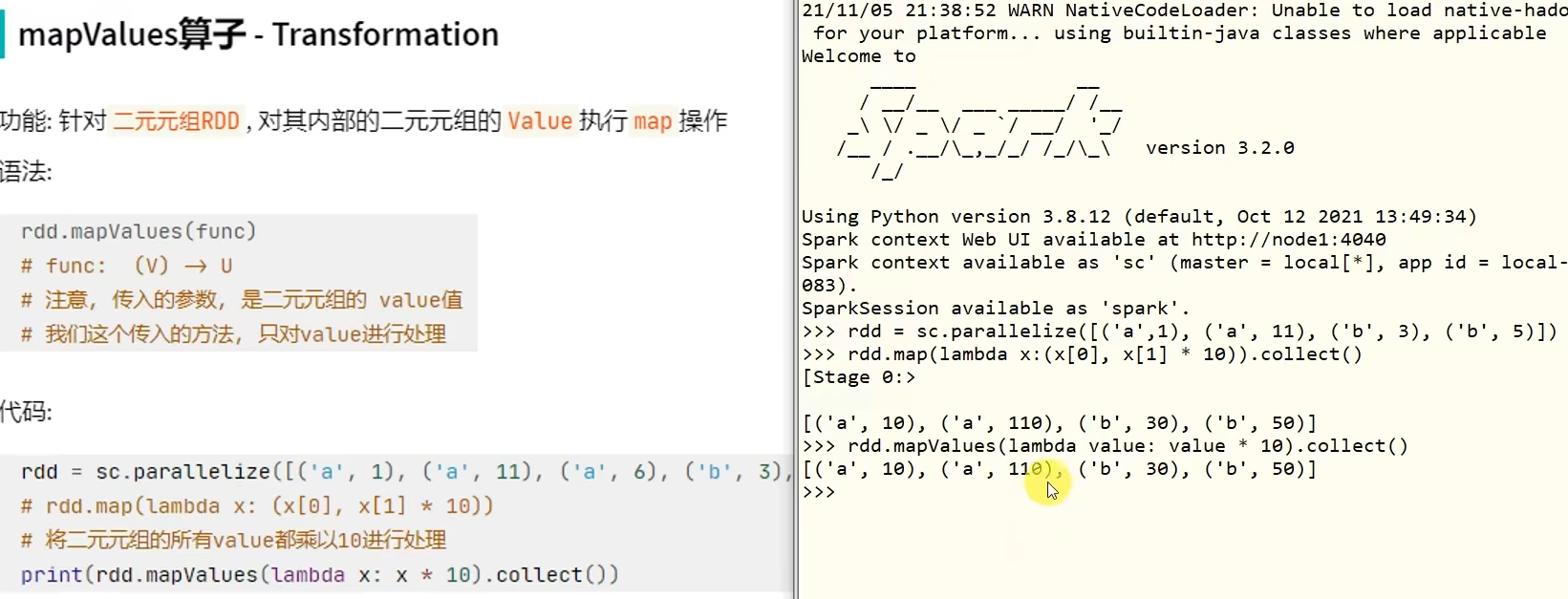
转换算子-mapValues
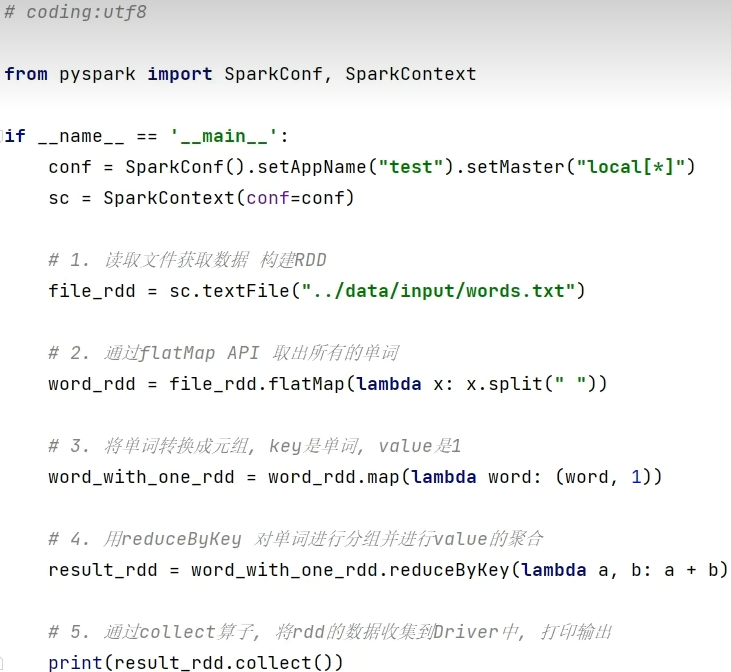
WordCount案例回顾
转换算子-groupBy
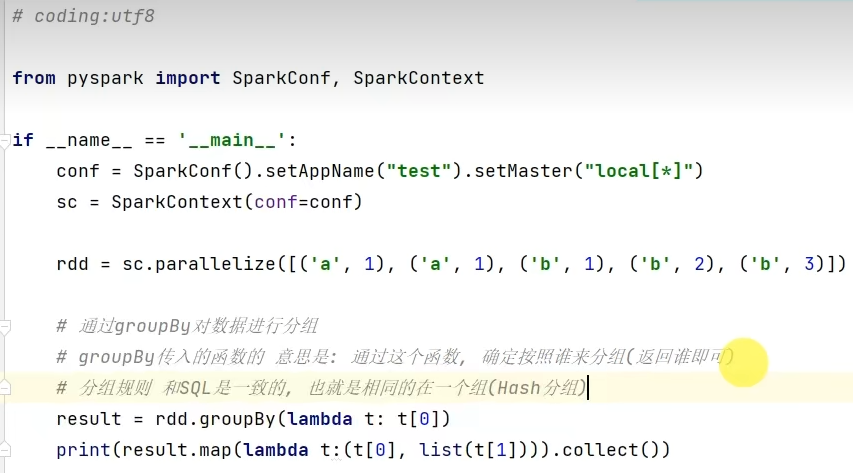
转换算子-filter
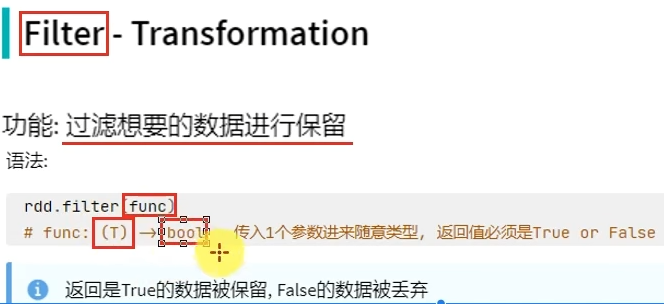
转换算子-distinct

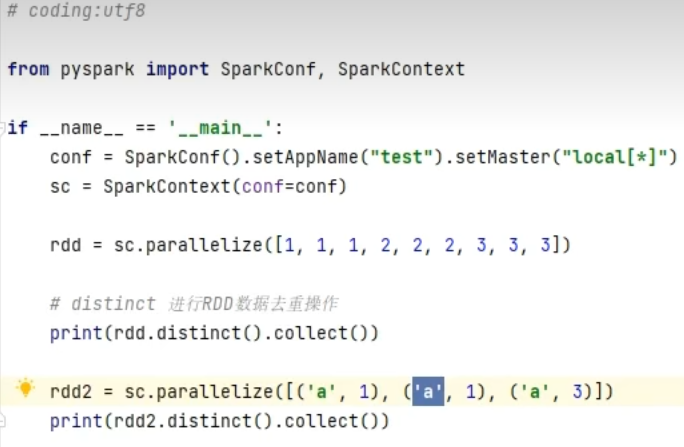
转换算子-union

转换算子-join
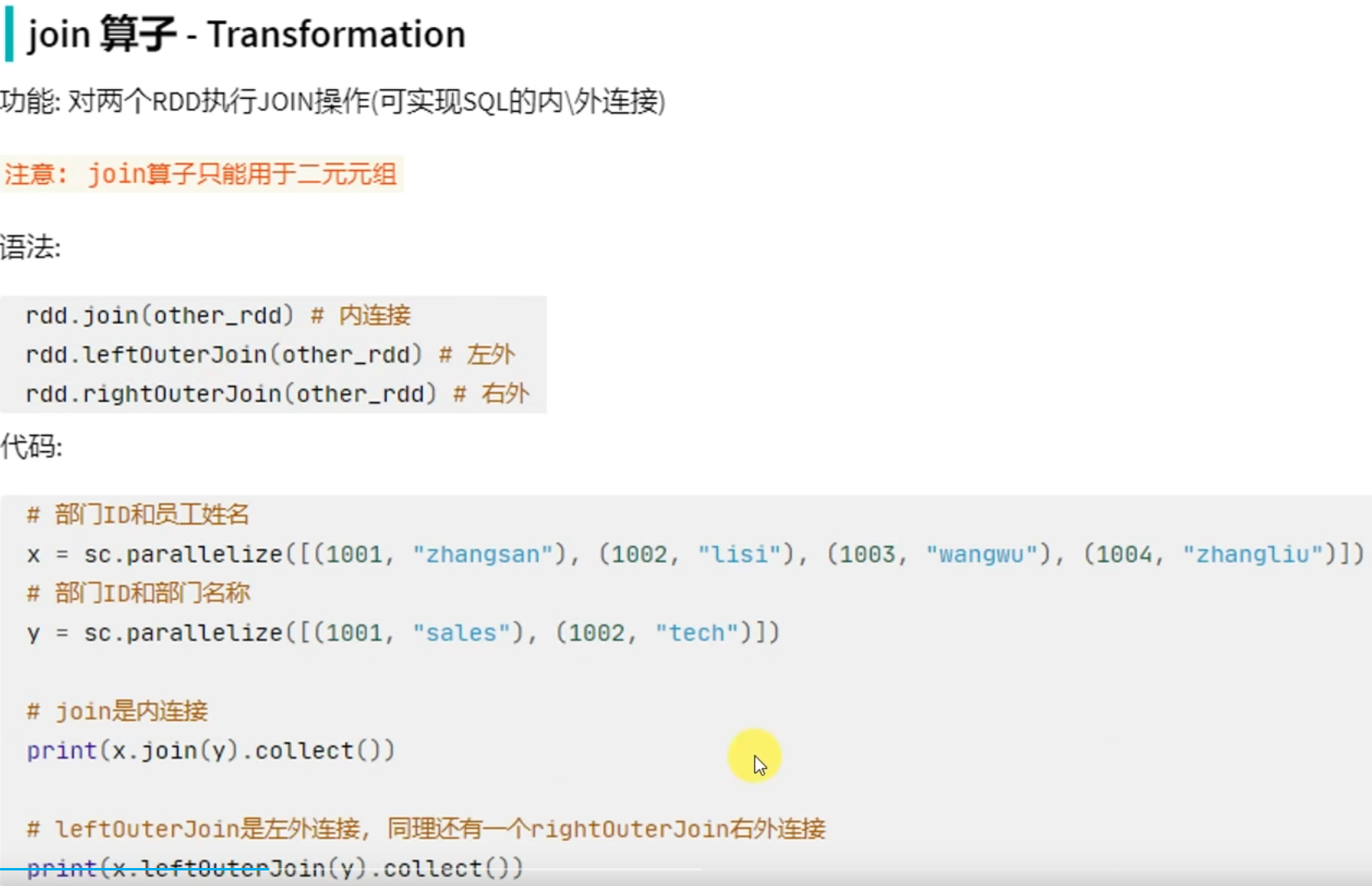
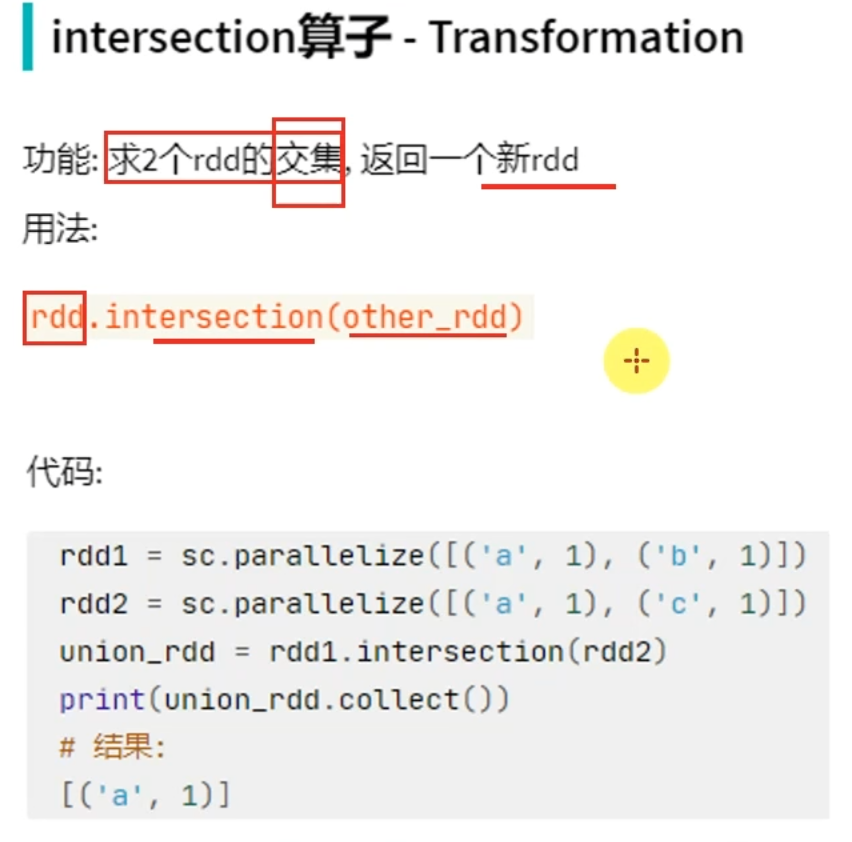
转换算子-intersection
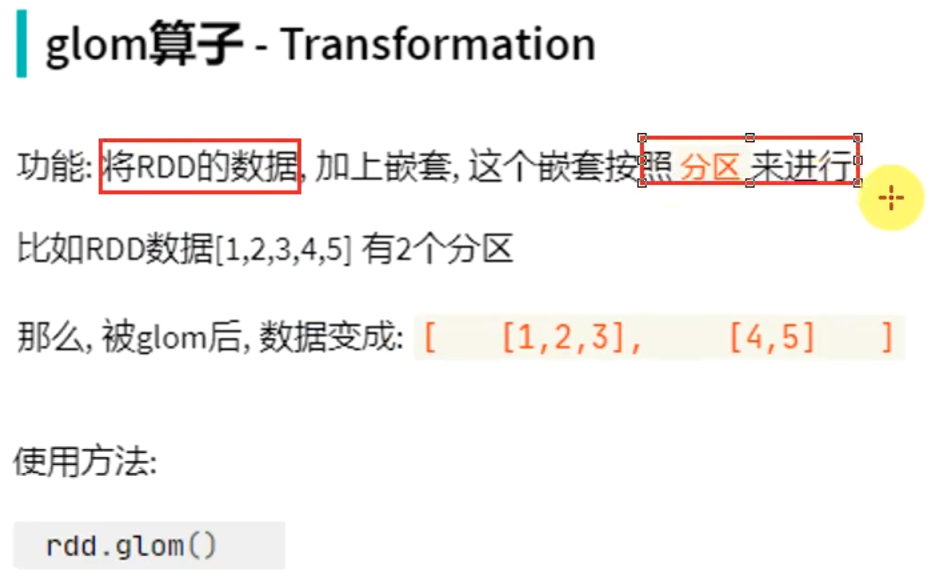
转换算子-glom
转换算子-groupByKey

groupByKey只保留同组的值,而groupBy还保留key。
转换算子-sortBy
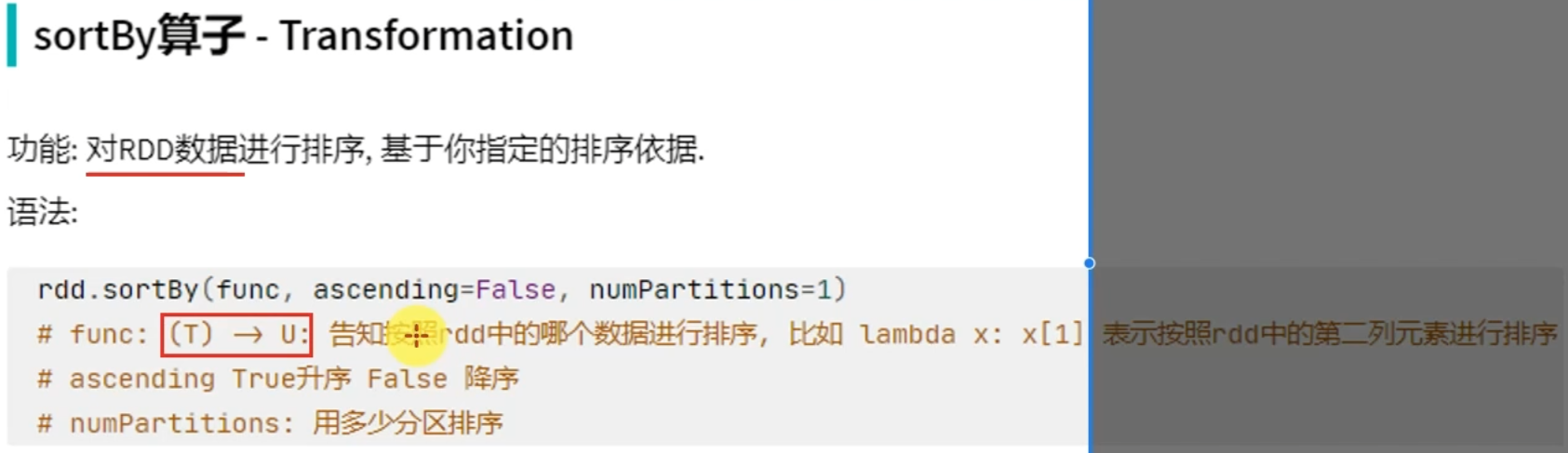
注意:如果选择多个分区来进行排序,那么就意味着有多个excutor,每个excutor只能保证局部有序。所以如果要全局有序,排序分区的并行任务数请设置为1
转换算子-sortByKey

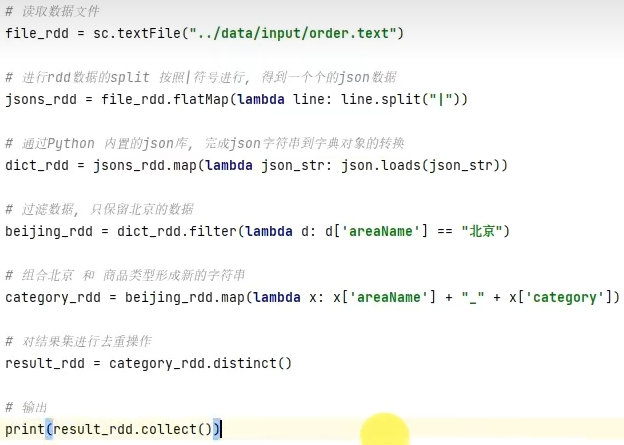
RDD算子-案例
RDD算子-案例-提交到YARN执行
2.5 常用Action算子
Action算子-countByKey

Action算子-collect

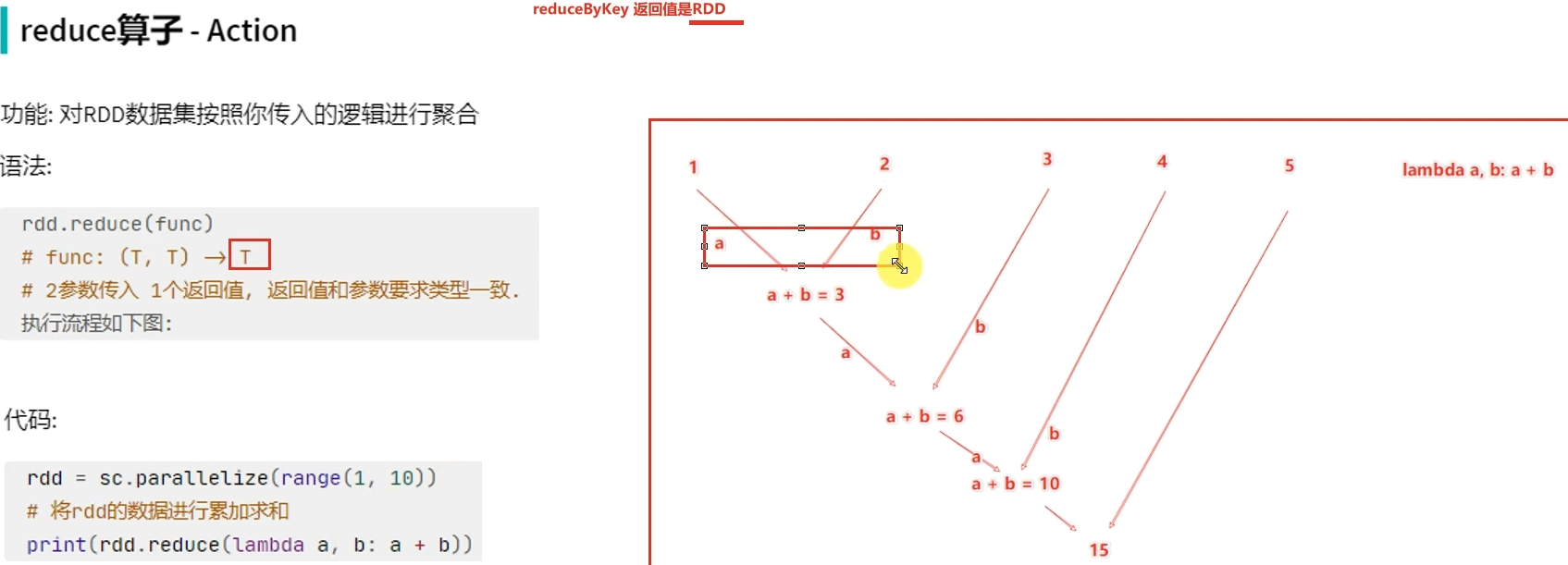
Action算子-reduce
Action算子-fold-了解

Action算子-first

Action算子-take

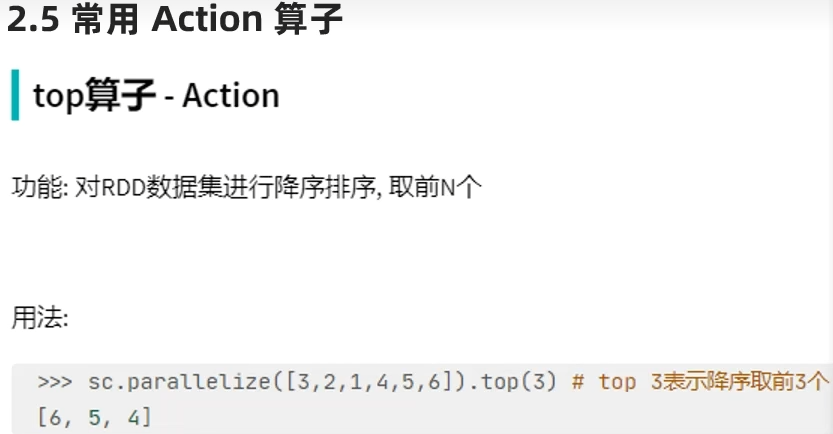
Action算子-top
Action算子-count

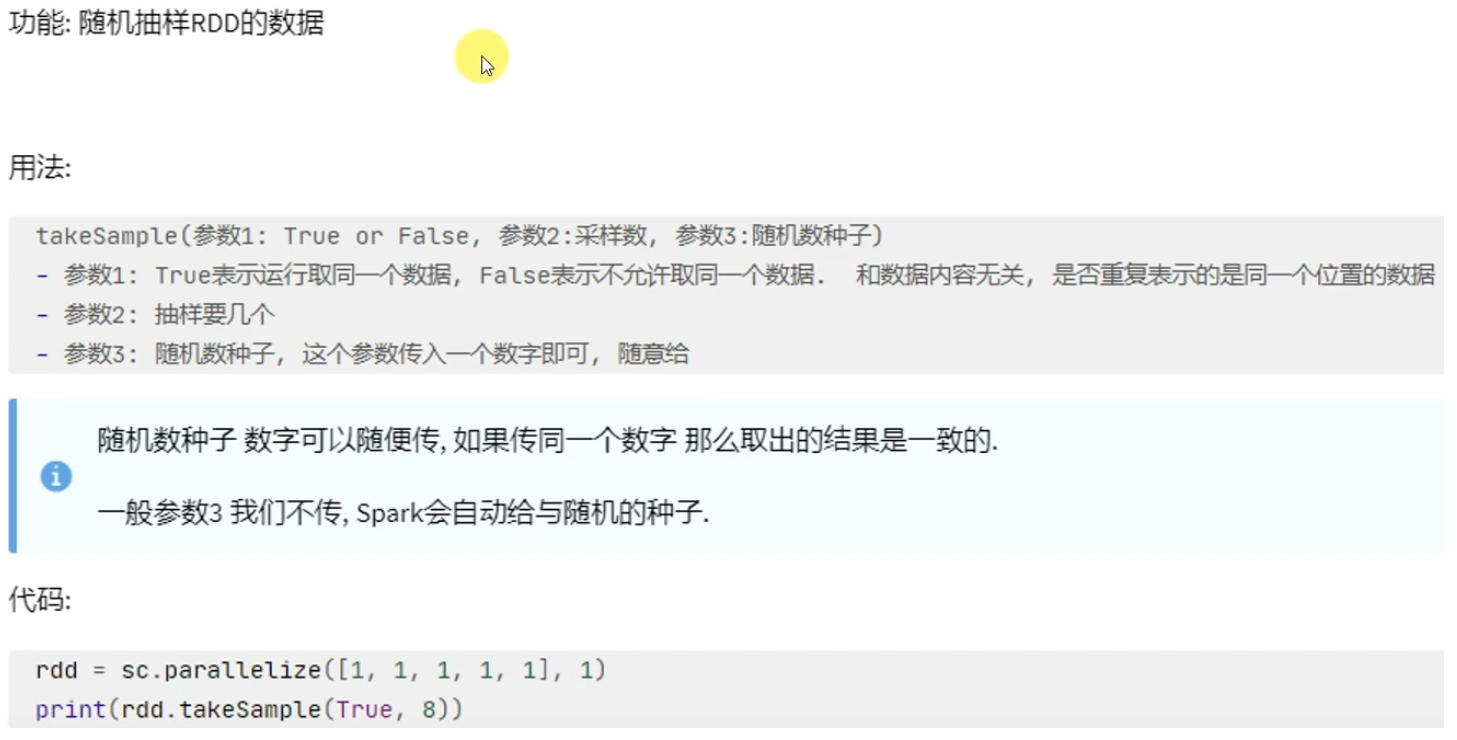
Action算子-takeSample
Action算子-takeOrdered

Action算子-foreach
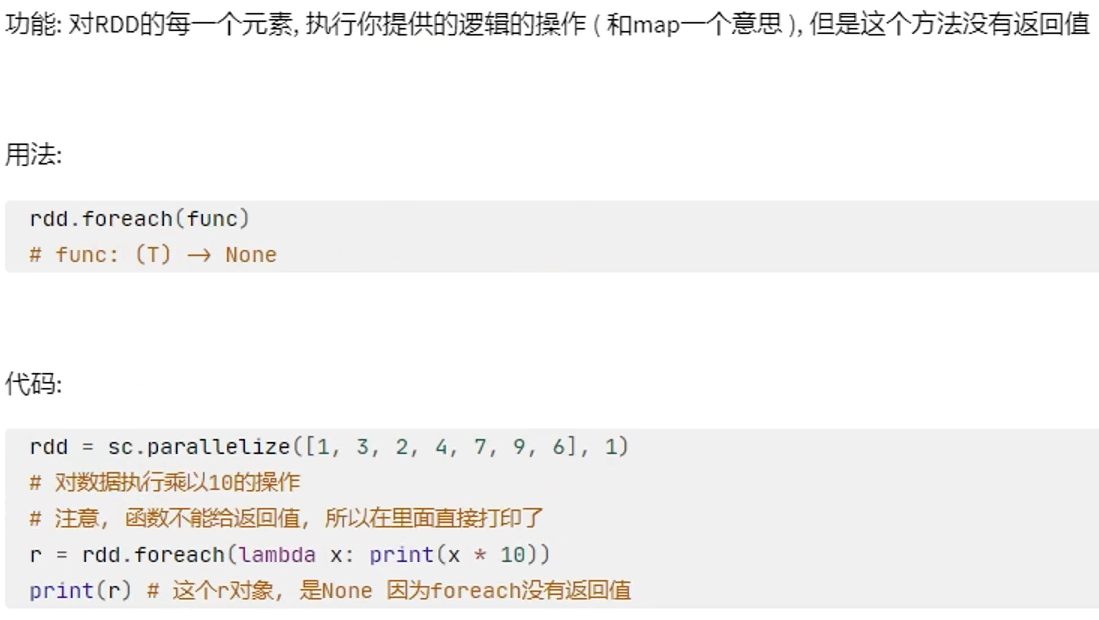
Action算子-saveAsTextFile
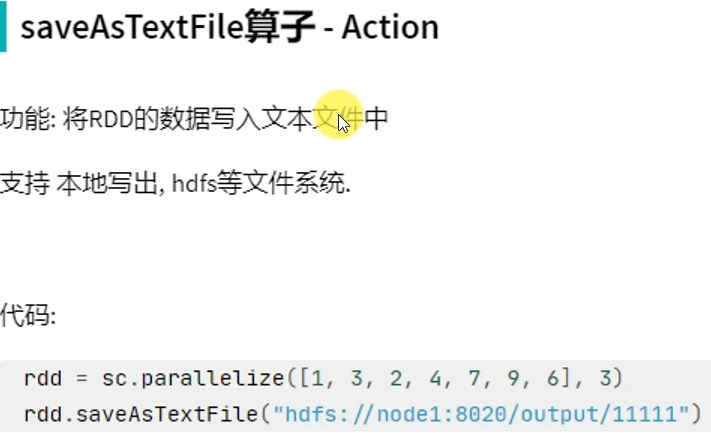
rdd有几个分区,写出的数据就有几个"part-xxxx"文件

2.6 分区操作算子
转换算子-mapPartitions
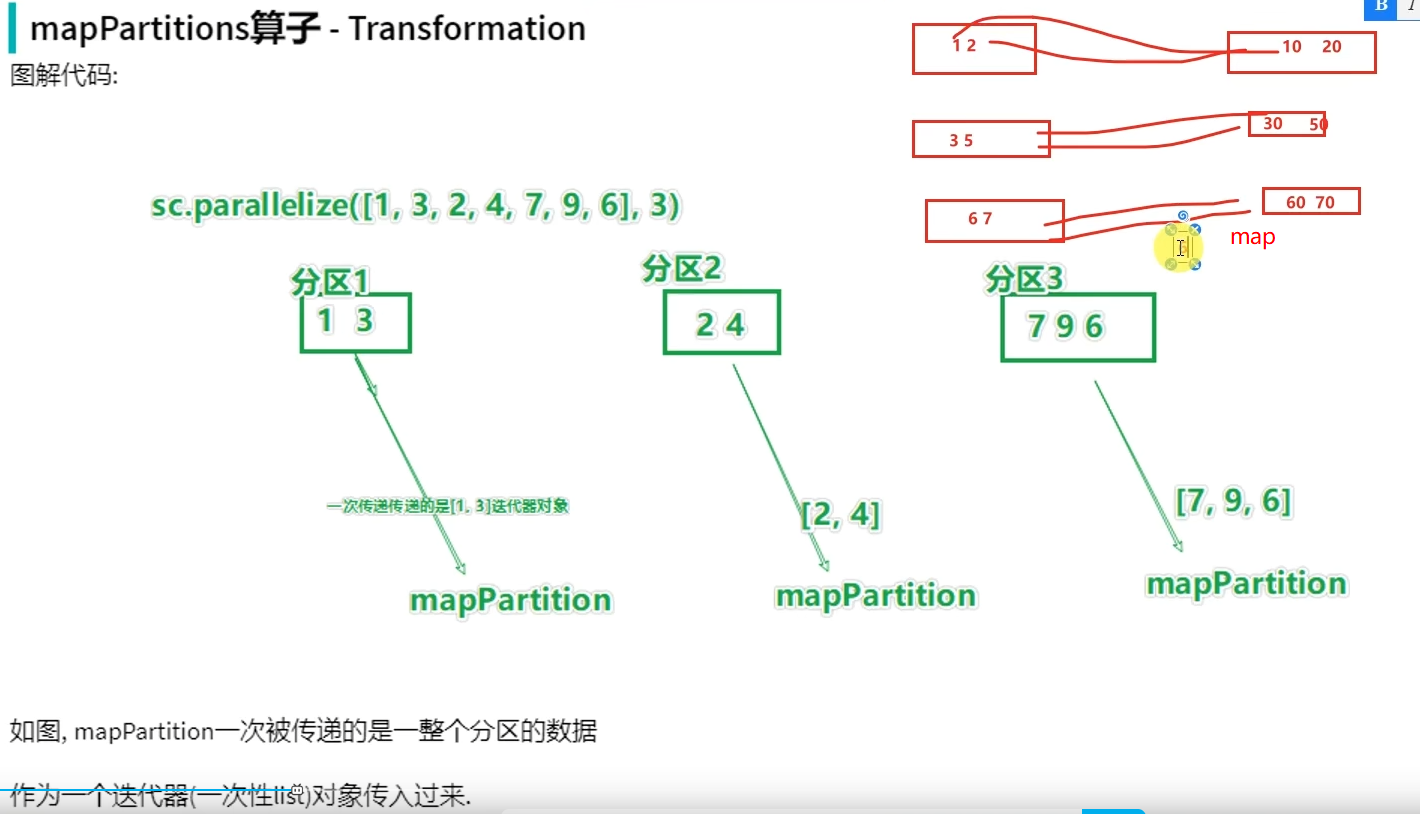
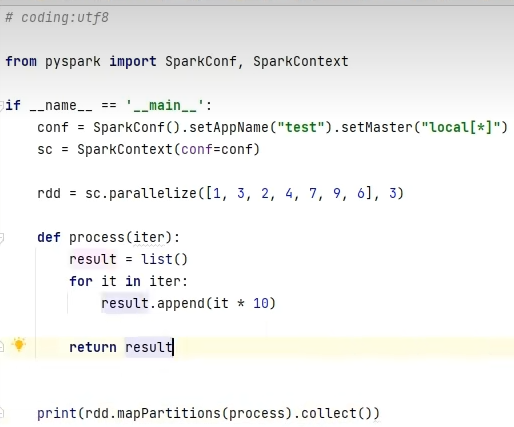
mapPartitions并没有节省CPU执行层面的东西,但节省了网络管道IO开销,所以他的性能比map好。
Action算子-foreachPartition

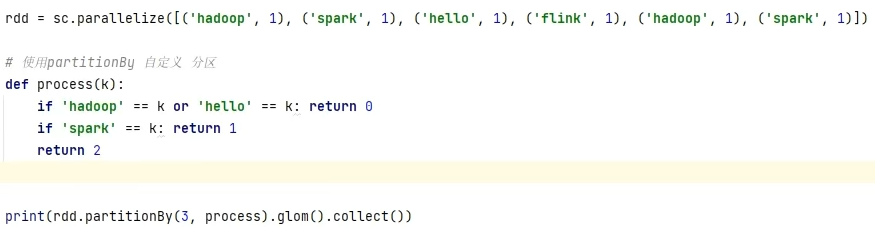
转换算子-partitionBy

转换算子-repartition
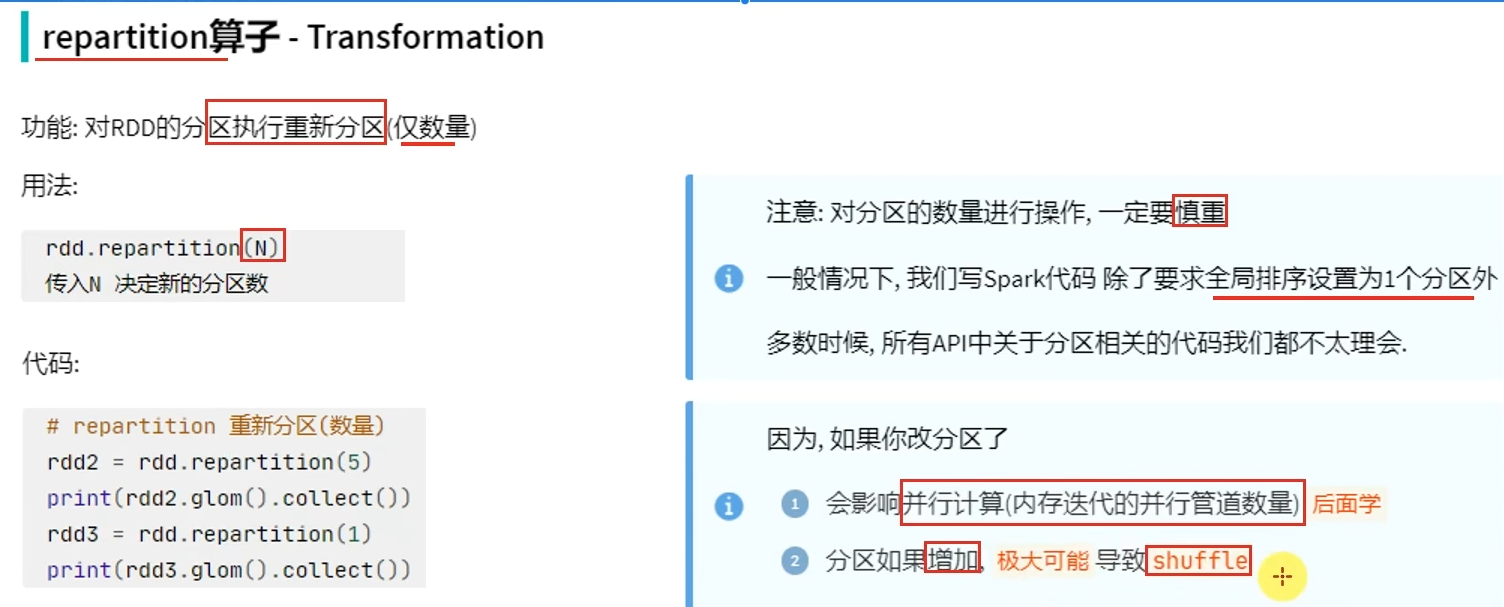
shuffle是有状态计算,有状态计算涉及到状态的获取,就会导致性能下降。而没有shuffle,大部分都是无状态计算,可以并行执行,效果很快。

coalesce有安全机制,当增加分区但没有设置shuffle参数为True时,分区并不会增加
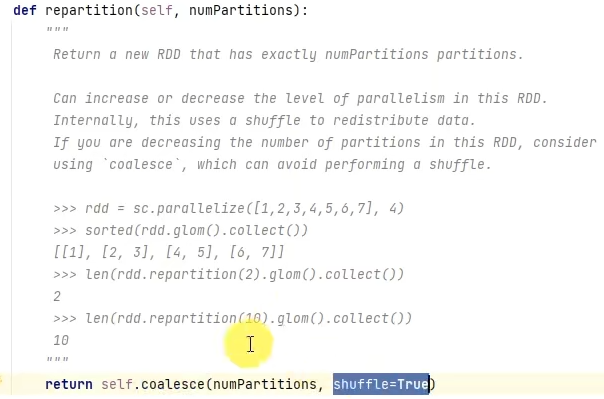
repartition底层调用的是coalesce,只是参数shuffle默认设置为True
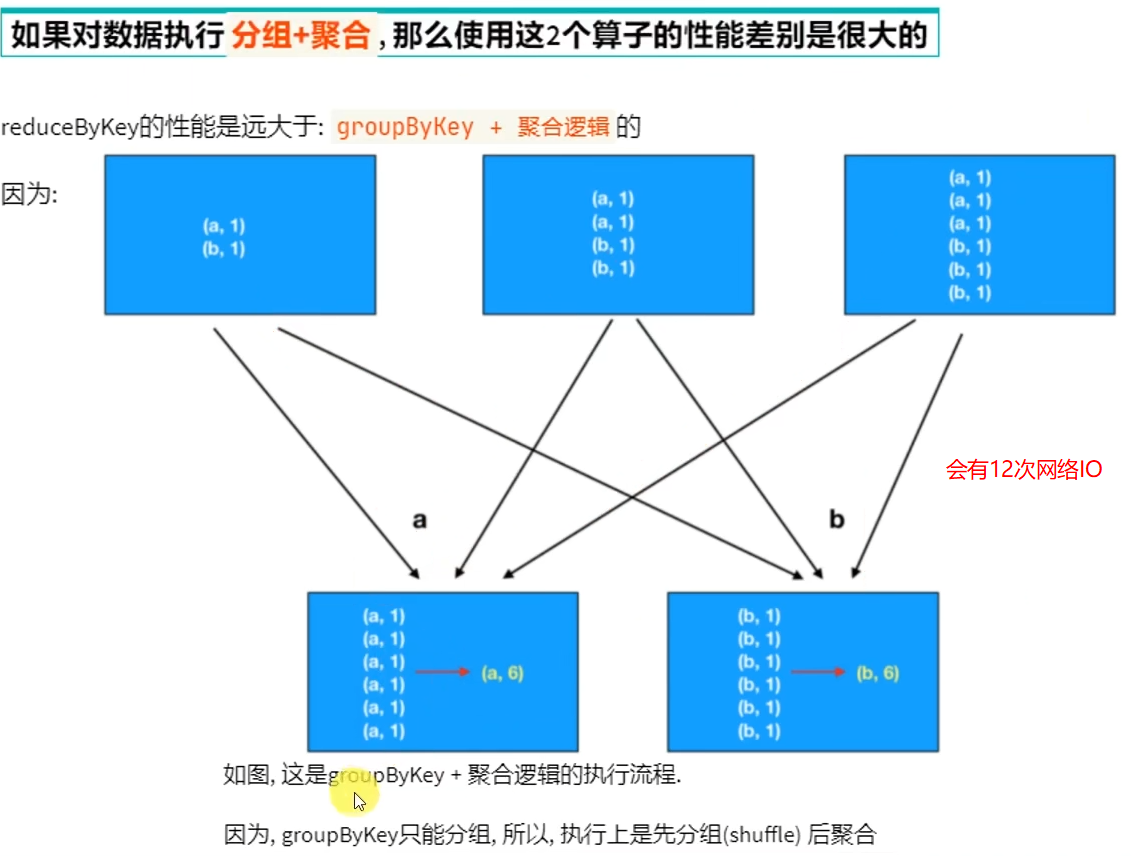
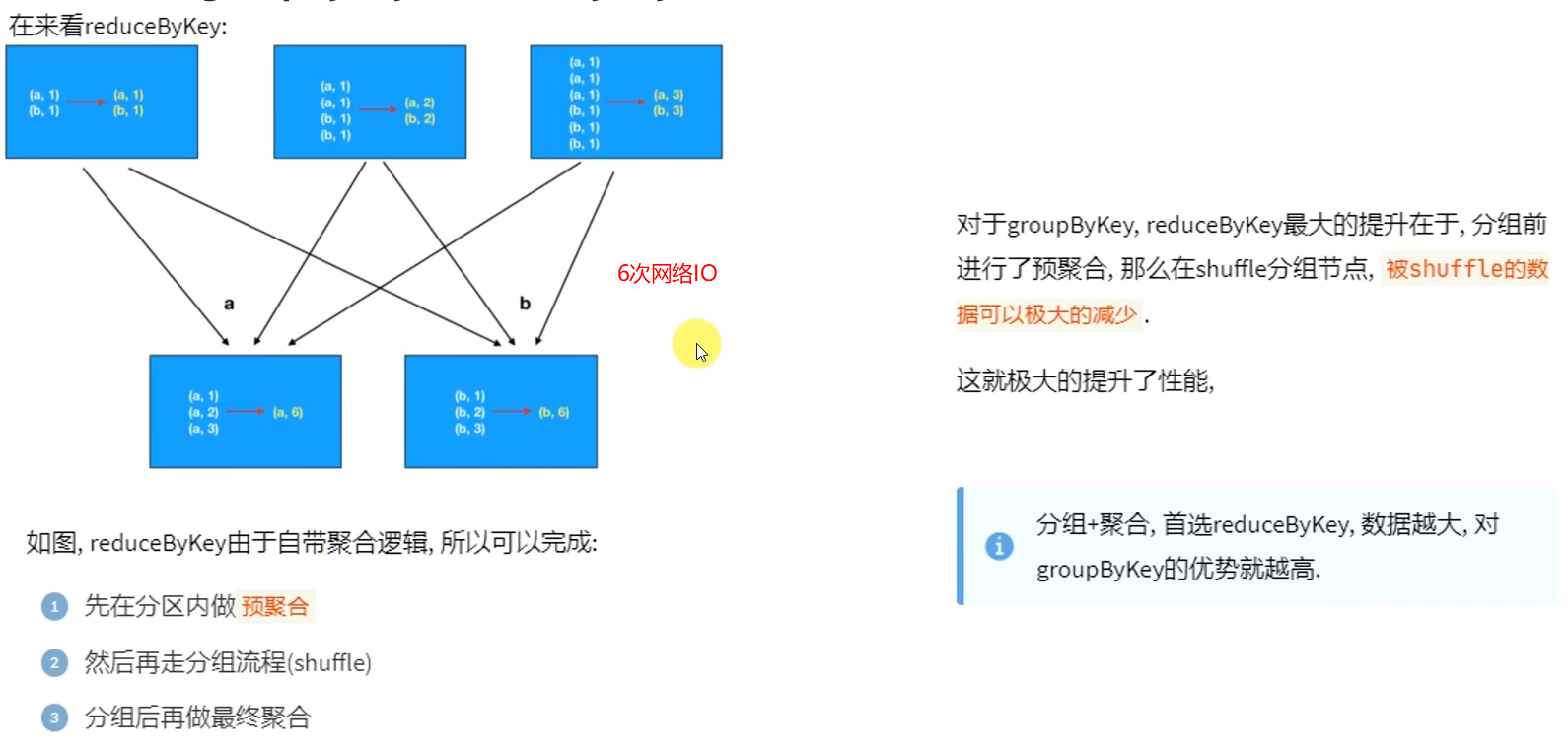
面试题:groupByKey和reduceByKey的区别

2.7 第二章总结
- RDD创建有哪几种方法?
通过并行化集合的方式(本地集合转分布式集合)
或者读取数据的方式创建(TextFile\WholeTextFile)
- RDD分区数如何查看?
通过getNumPartitions API查看,返回Int
- Transformation和Action的区别?
转换算子的返回值100%是RDD,而Action算子的返回值100%不是RDD。
转换算子是懒加载的,只有遇到Action才会执行。Action就是转换算子处理链条的开关。
- 哪两个Action算子的结果不经过Driver,直接输出?
foreach和saveAsTextFile直接由Executor执行后输出,不会将结果发送到Driver上去(foreachPartition也是)
- reduceByKey和groupByKey的区别?
reduceByKey自带聚合逻辑,groupByKey不带
如果做数据聚合reduceByKey的效果更好,因为可以先聚合后shuffle再最终聚合,传输的IO小
- mapPartitions和foreachPartition的区别?
mapPartitions带有返回值,是个转换算子;foreachPartition不带返回值,是个Action算子
- 对于分区操作有什么要注意的地方?
尽量不要增加分区,可能破坏内存迭代的计算管道
第三章:RDD的持久化
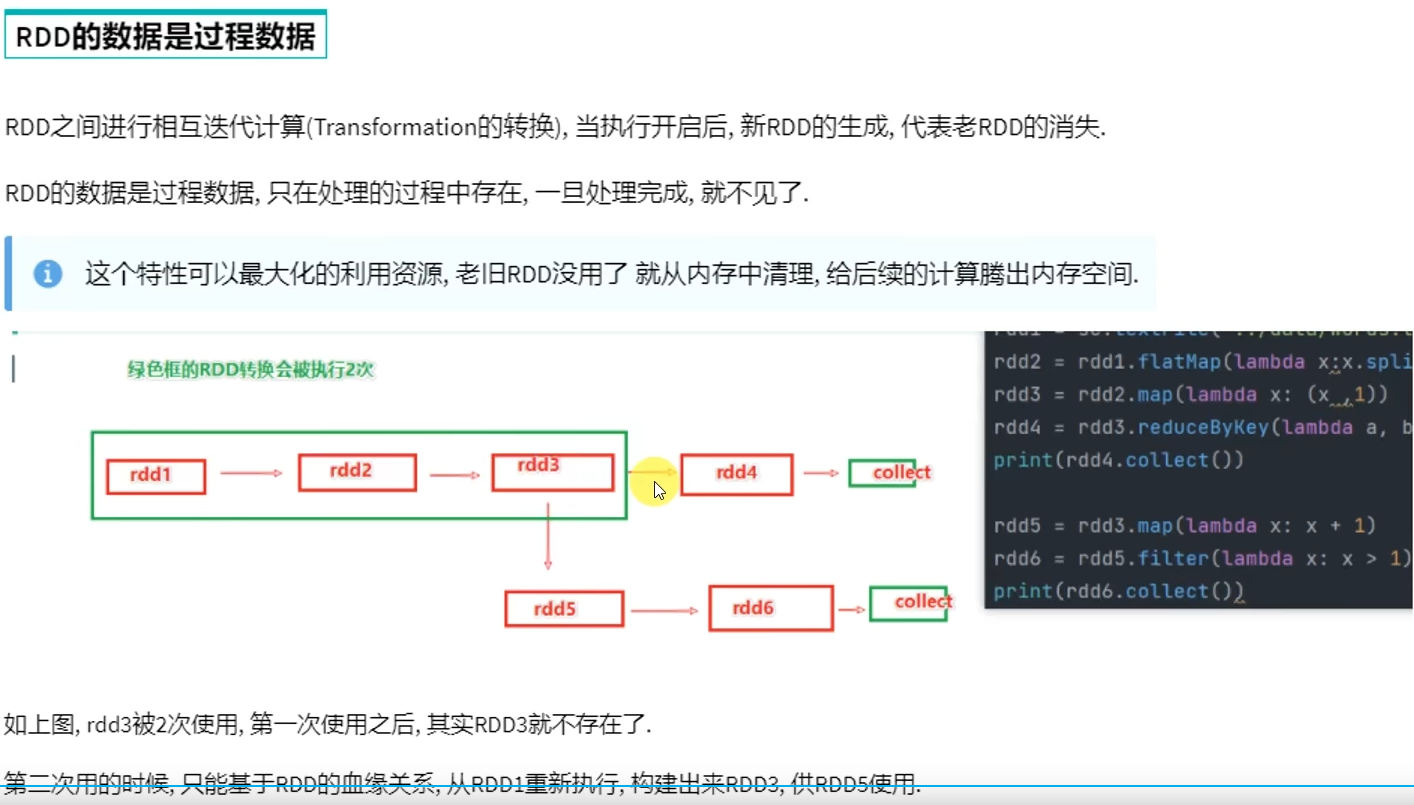
3.1 RDD的数据是过程数据
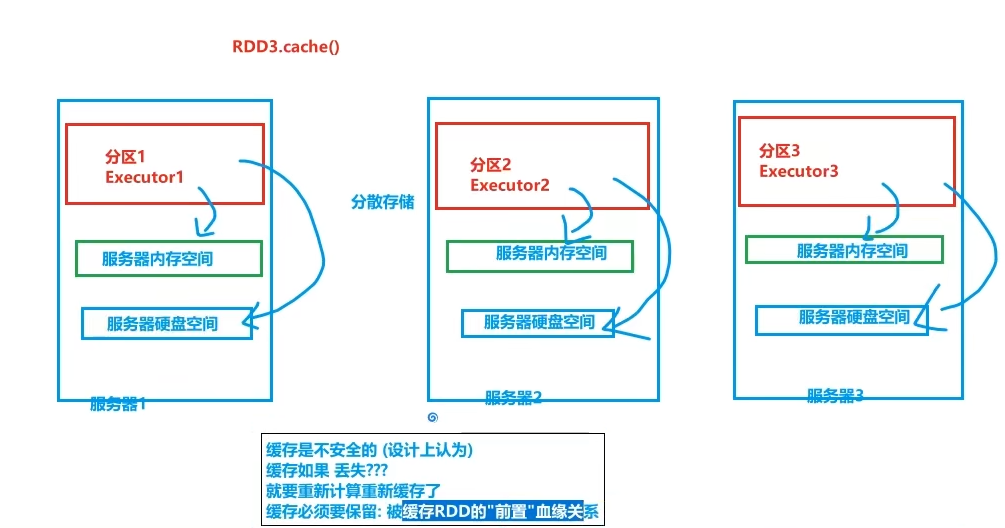
3.2 RDD缓存

PS:linux下kill -9不能强制杀死spark-submit进程
参考资料:https://blog.csdn.net/intersting/article/details/84492999(原因分析)
https://blog.csdn.net/qq_41870111/article/details/126068306
https://blog.csdn.net/agonysome/article/details/125722926(如何清理僵尸进程)

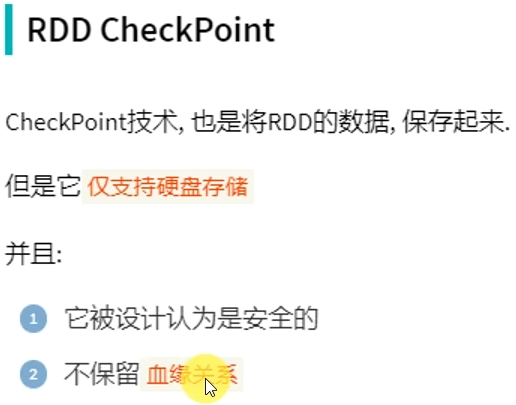
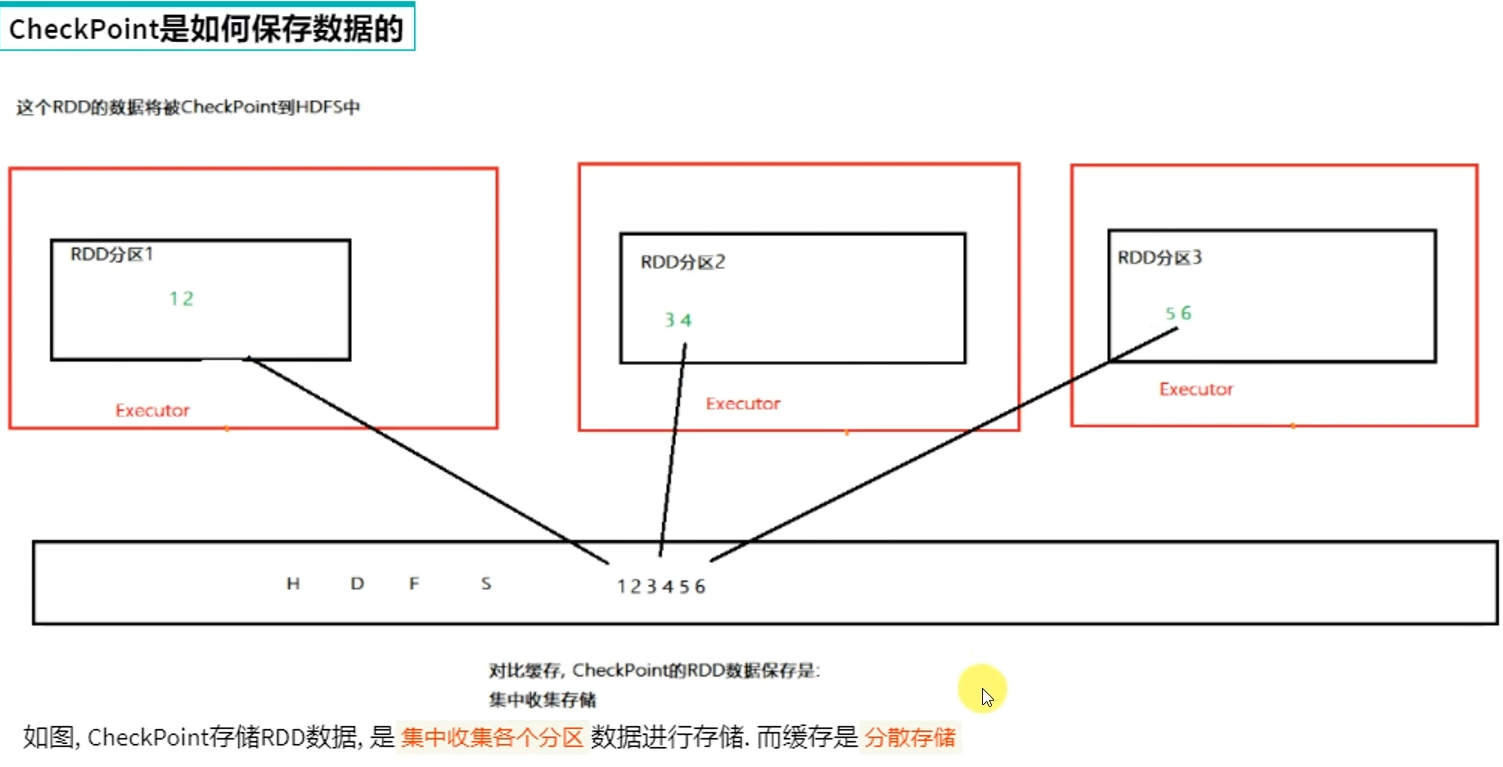
3.3 RDD CheckPoint

3.4 第三章总结
- Cache和Checkpoint区别
Cache是轻量化保存RDD数据,可存储在内存和硬盘,是分散存储,设计上数据是不安全的(保留RDD血缘关系)
CheckPoint是重量级保存RDD数据,是集中存储,只能存储在硬盘(HDFS)上,设计上是安全的(不保留RDD血缘关系)
- Cache和CheckPoint的性能对比?
Cache性能更好,因为是分散存储,各个Executor并行,效率高,可以保存到内存中(占内存),更快
CheckPoint比较慢,因为是集中存储,涉及到网络IO,但是存储在HDFS上更加安全(多副本)
第四章:Spark案例练习
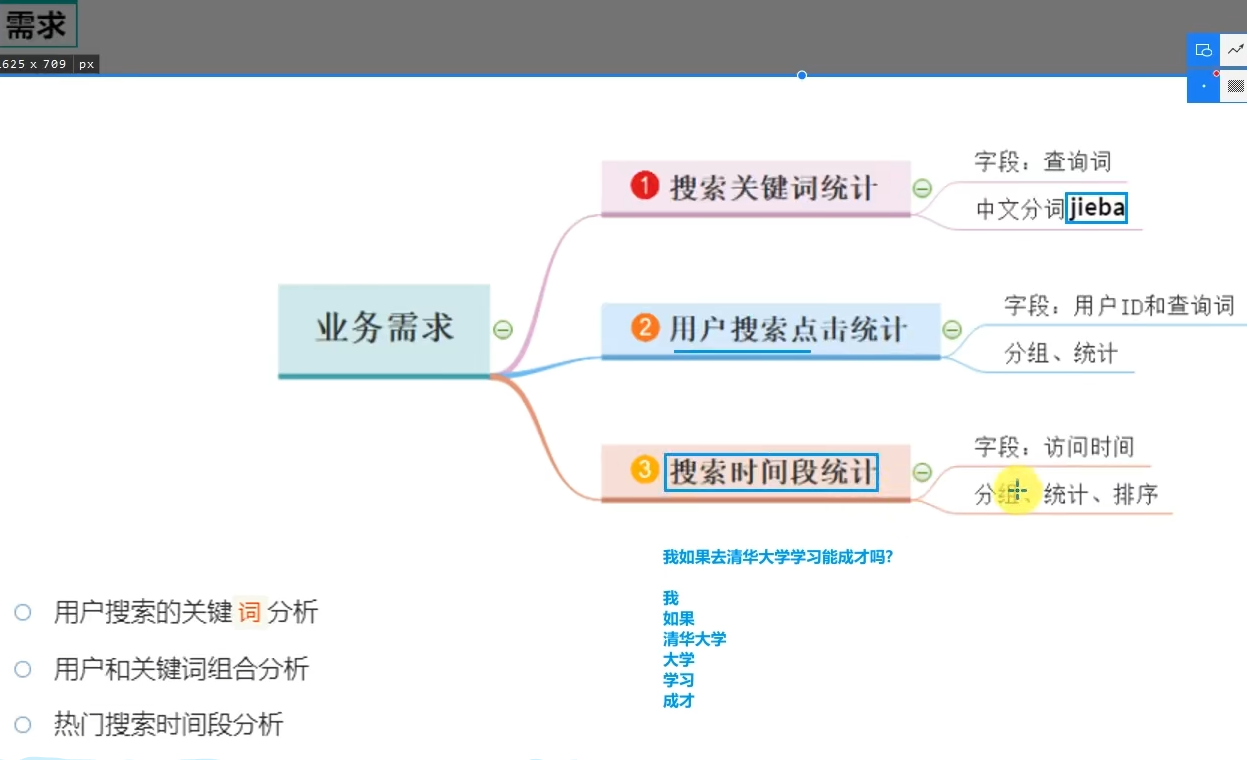
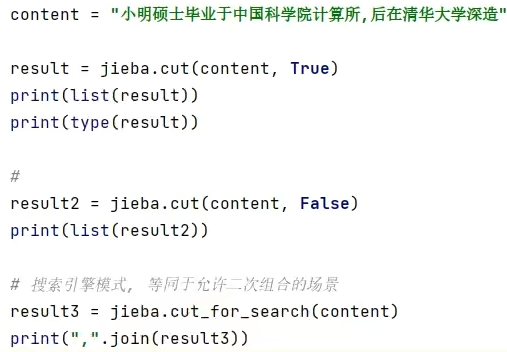
4.1 搜索引擎日志分析案例

4.2 提交到集群运行
4.3 第四章作业和总结
作业

总结
- 案例中使用的分词库是?
jieba库
- 为什么要在全部的服务器安装jieba库?
因为YARN是集群运行,Executor可以在所有服务器上执行,所以每个服务器都需要有jieba库提供支撑
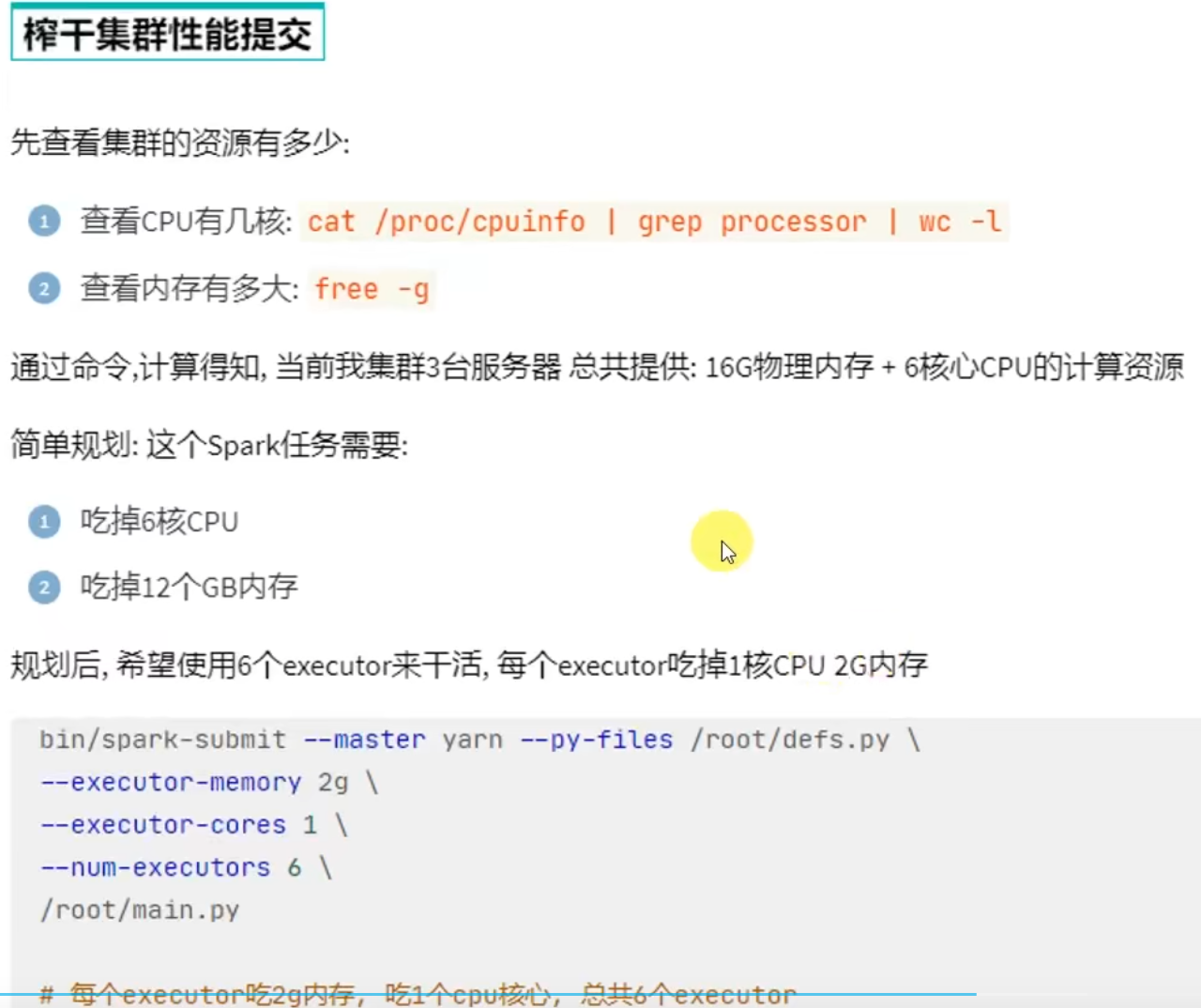
- 如何尽量提高任务计算的资源?
计算CPU核心和内存量,通过–executor-memory指定executor内存,通过–executor-cores指定executor的核心数
通过–num-executors指定总executor数量
第五章:共享变量
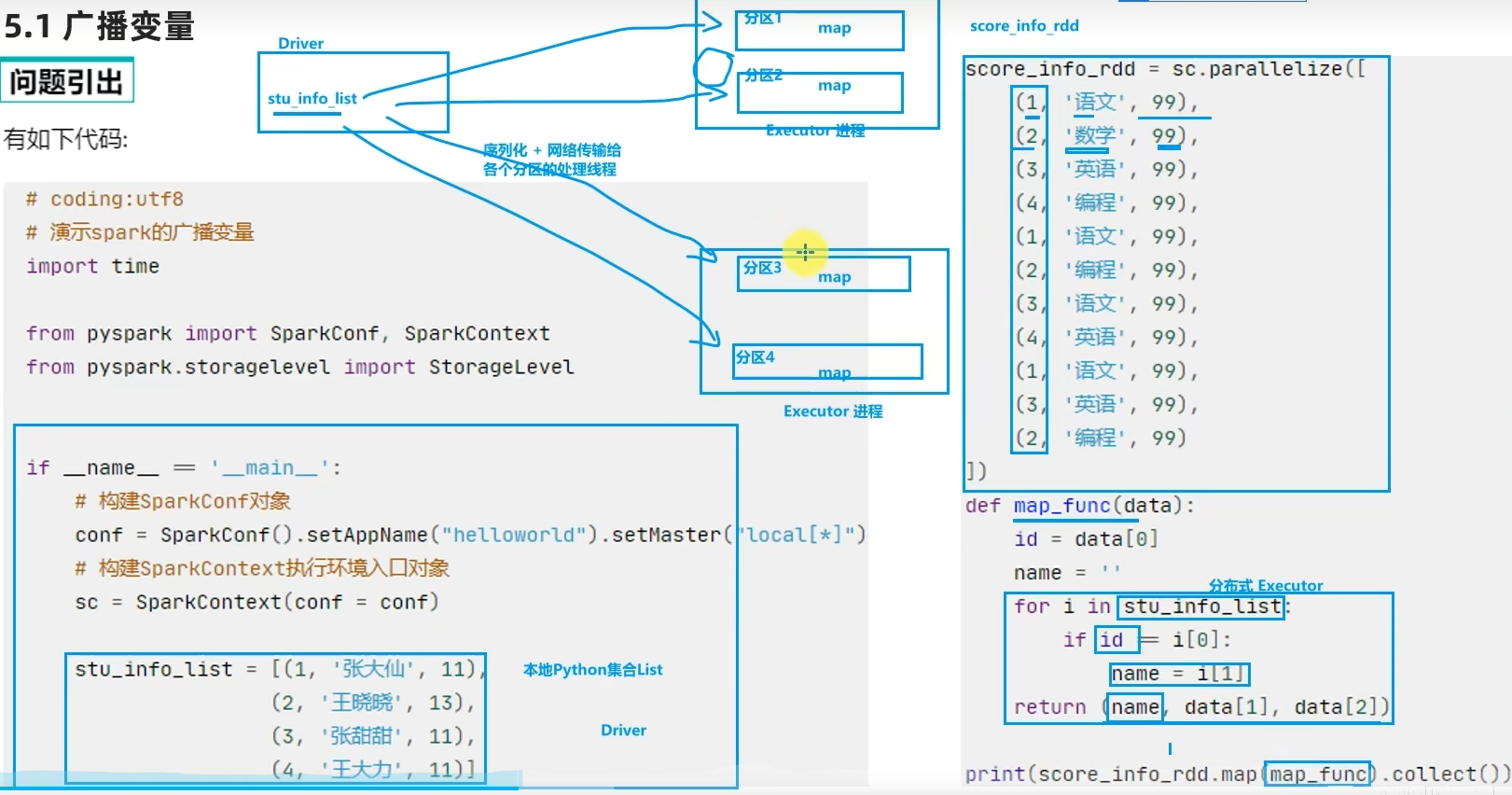
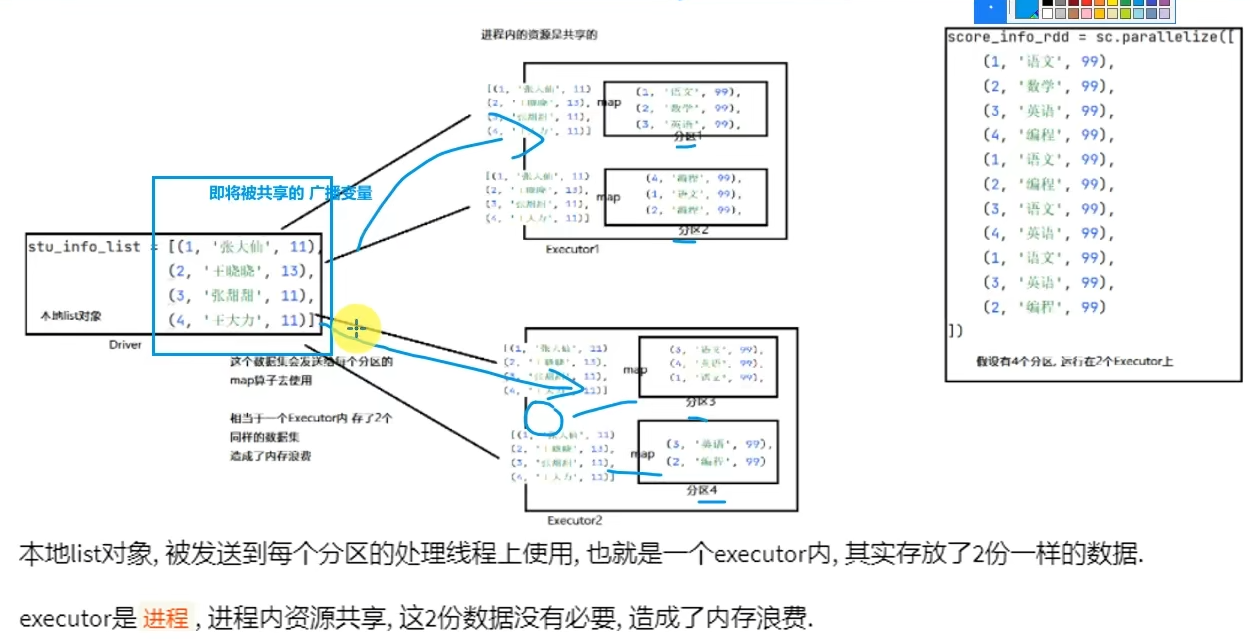
5.1 广播变量

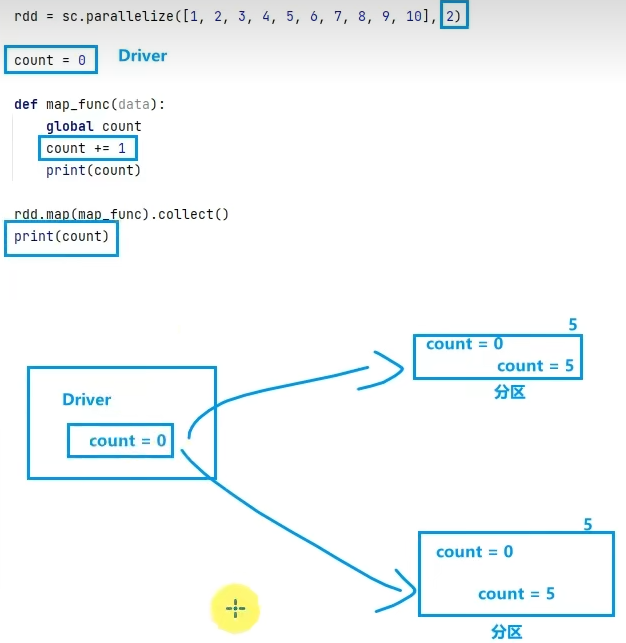
5.2 累加器


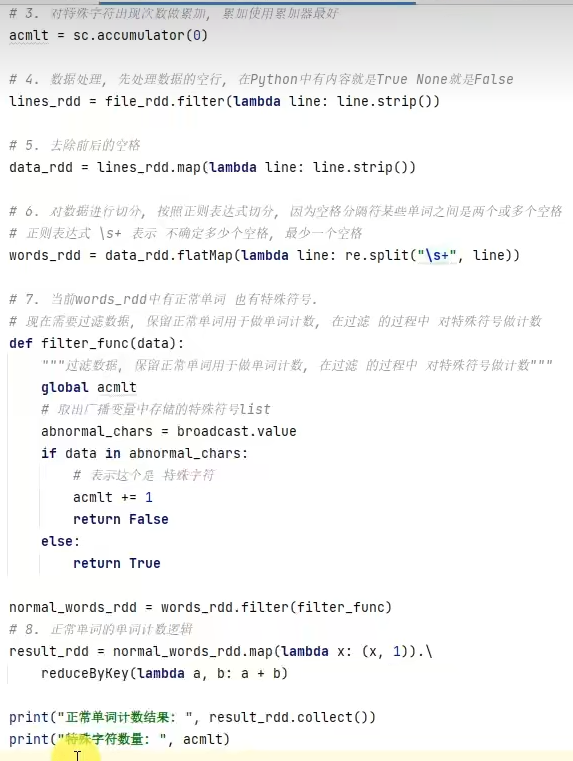
5.3 广播变量累加器综合案例
5.4 第五章总结
- 广播变量解决了什么问题?
分布式集合RDD和本地集合进行关联使用的时候,降低内存占用以及减少网络IO传输,提高性能。
- 累加器解决了什么问题?
分布式代码执行中,进行全局累加。
第六章:Spark内核调度(重点理解)
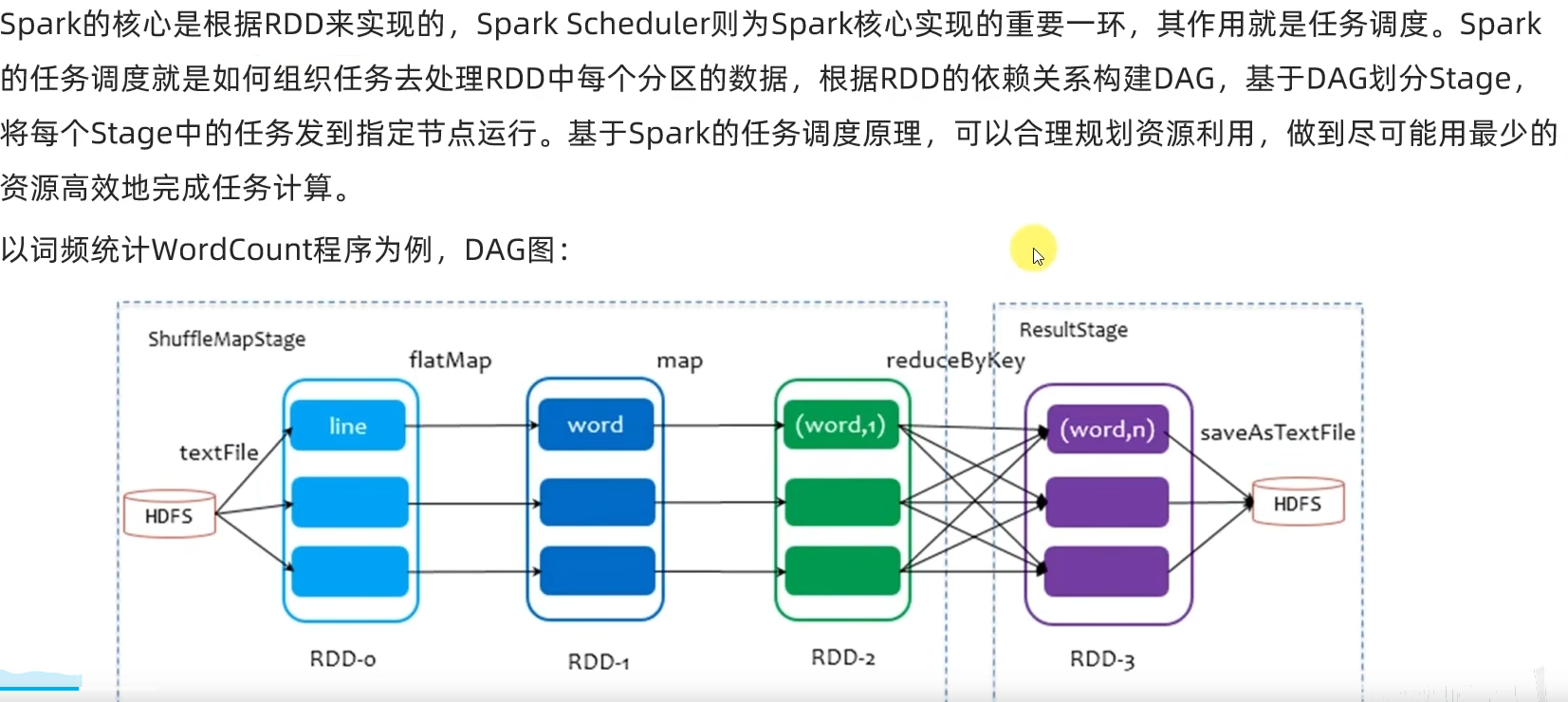
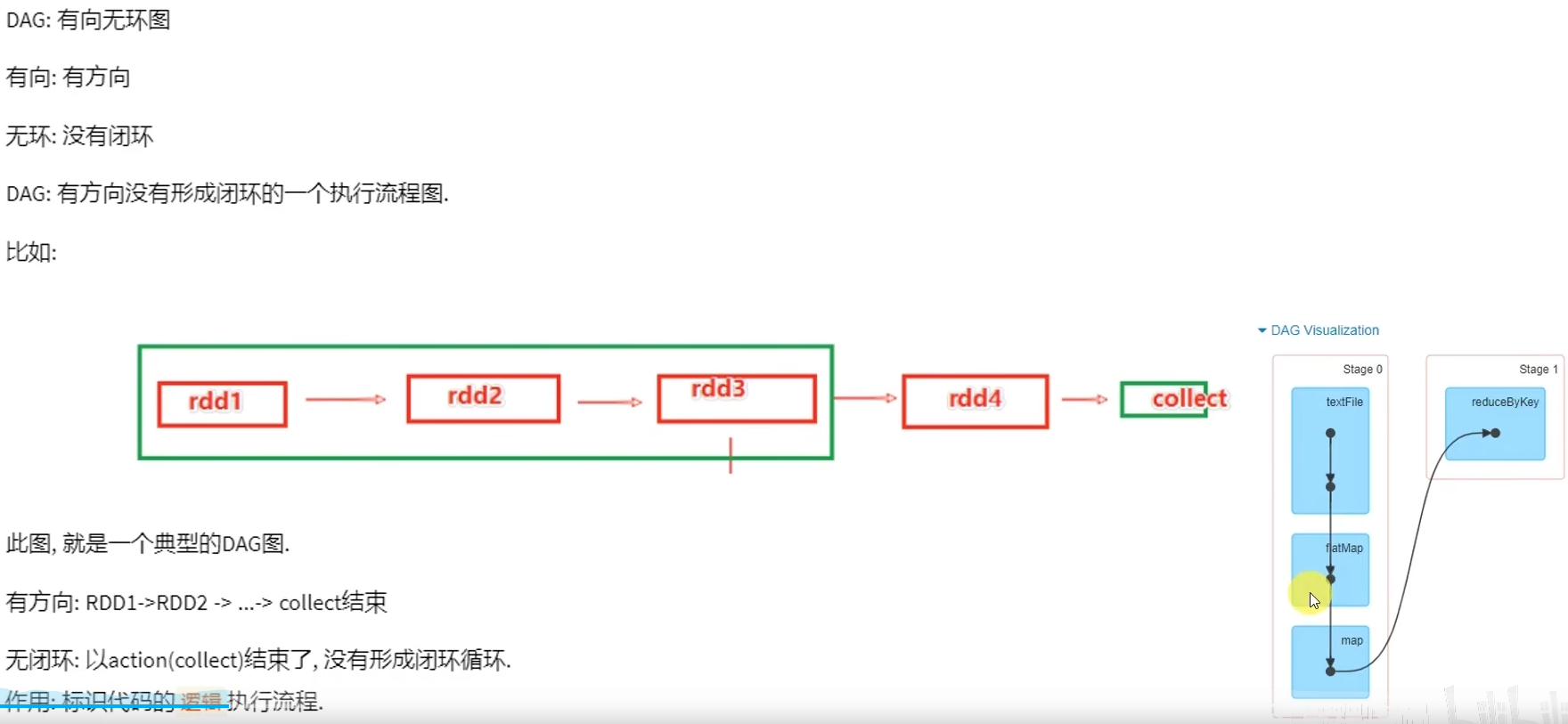
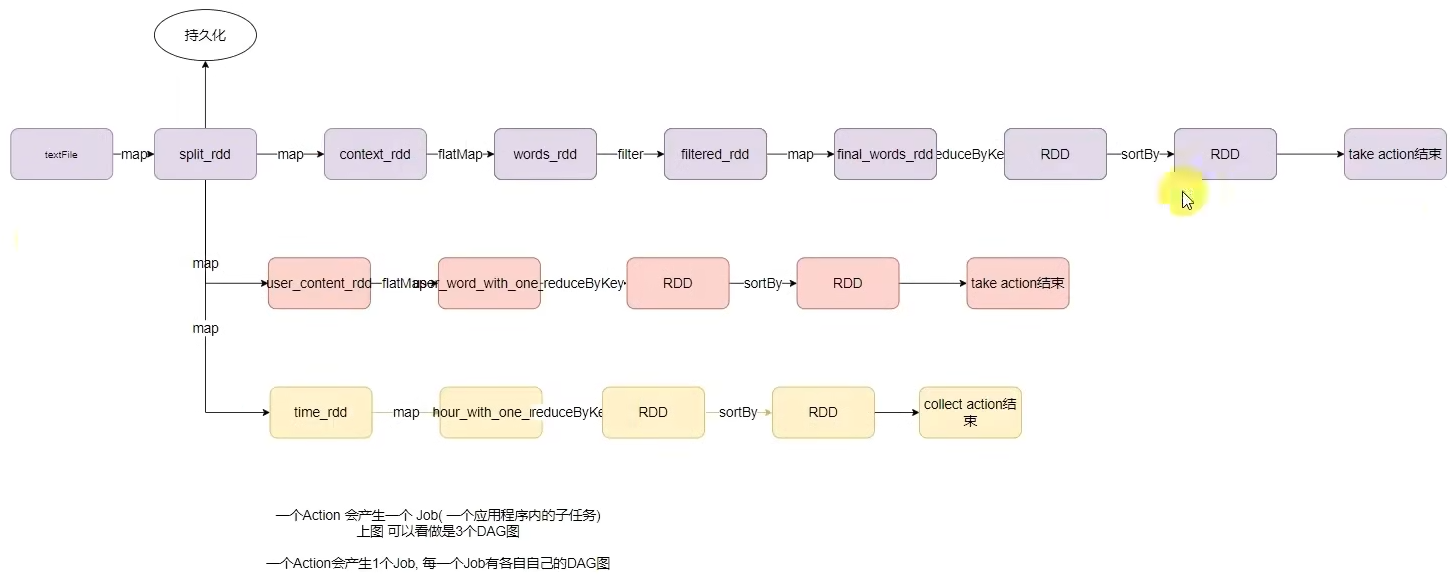
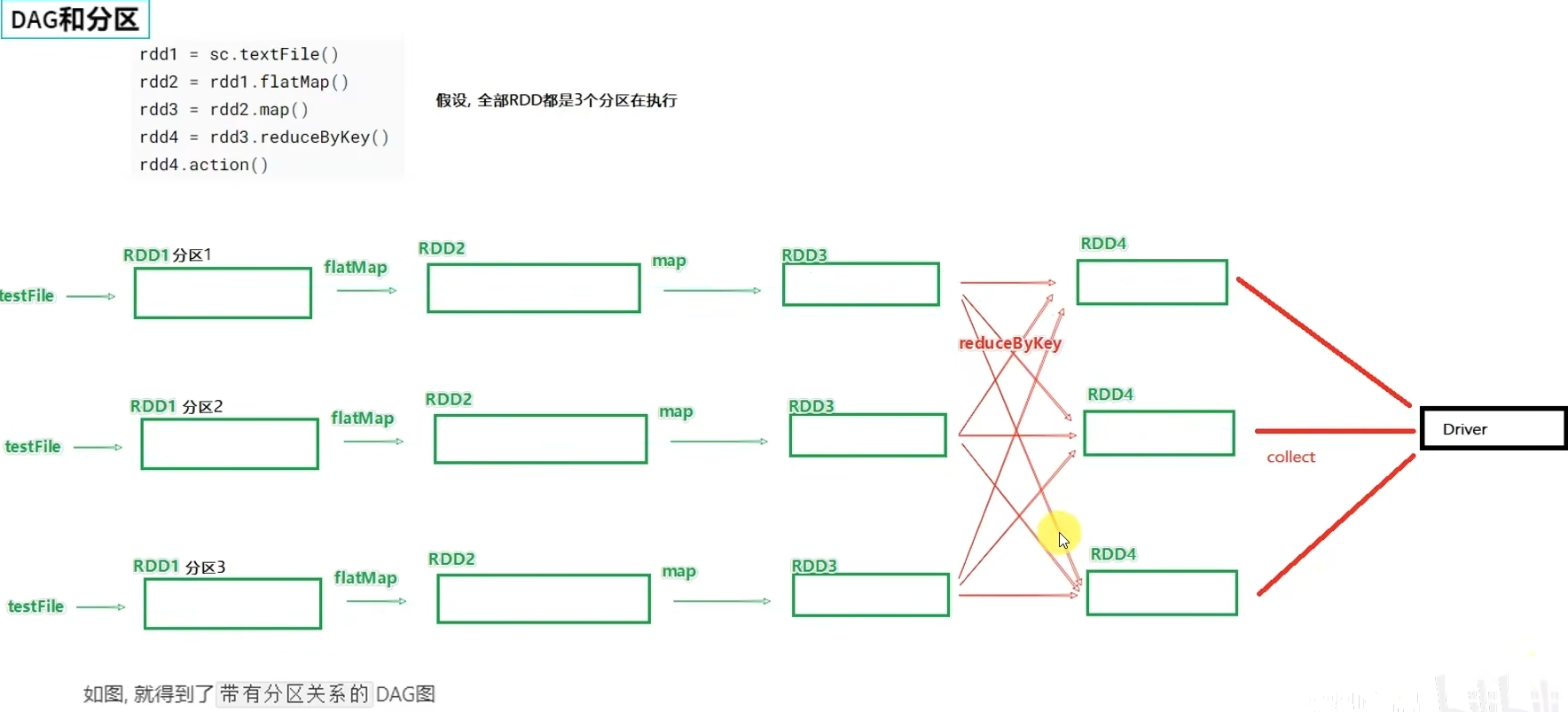
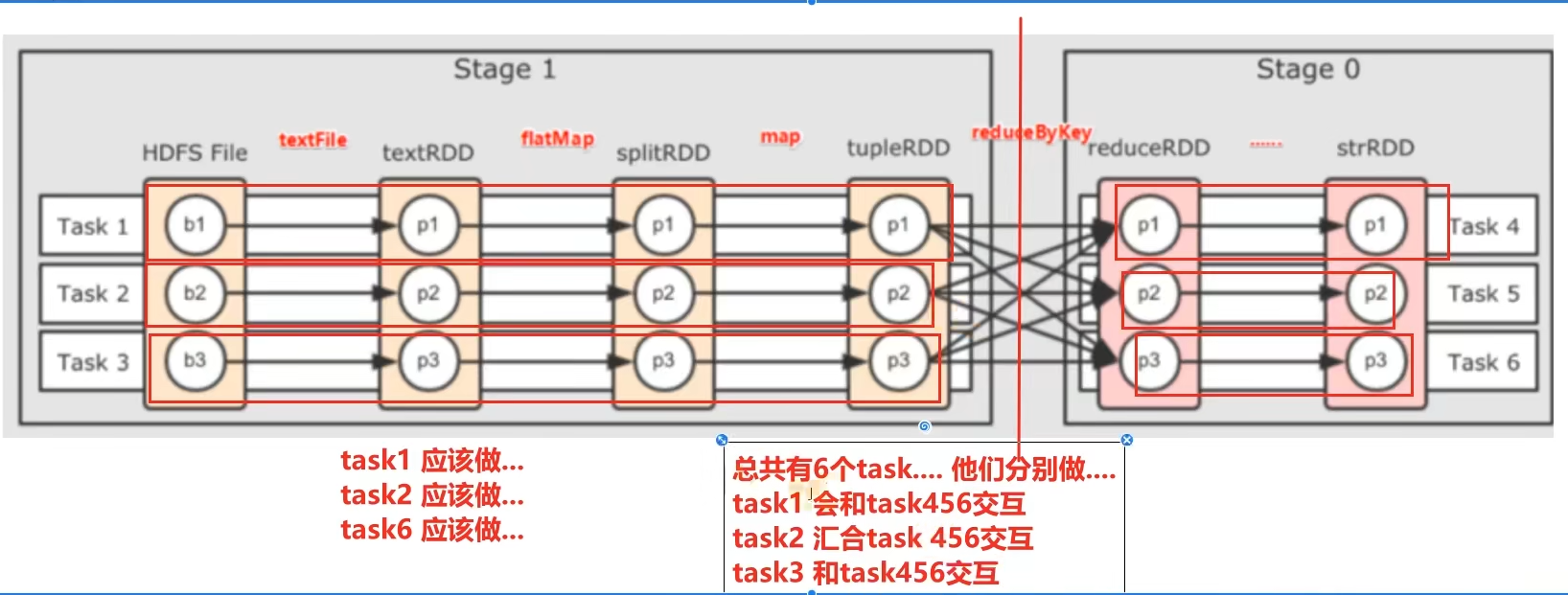
6.1 DAG

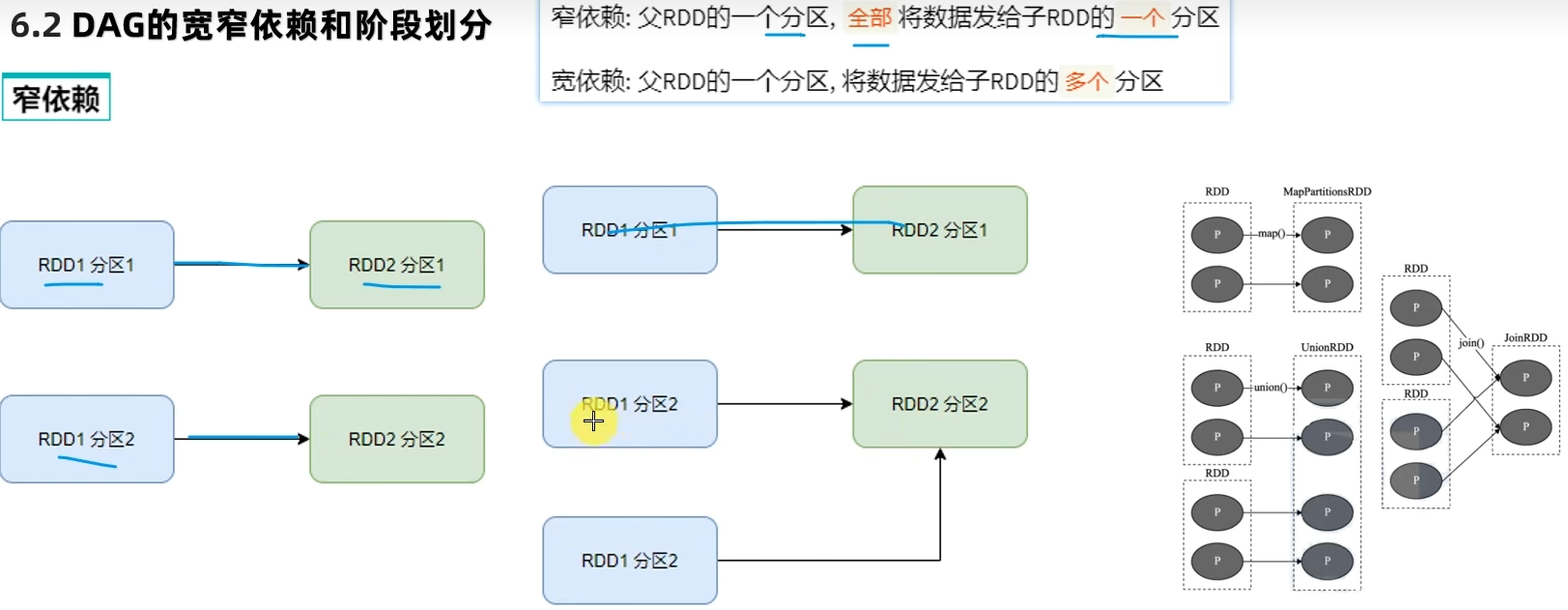
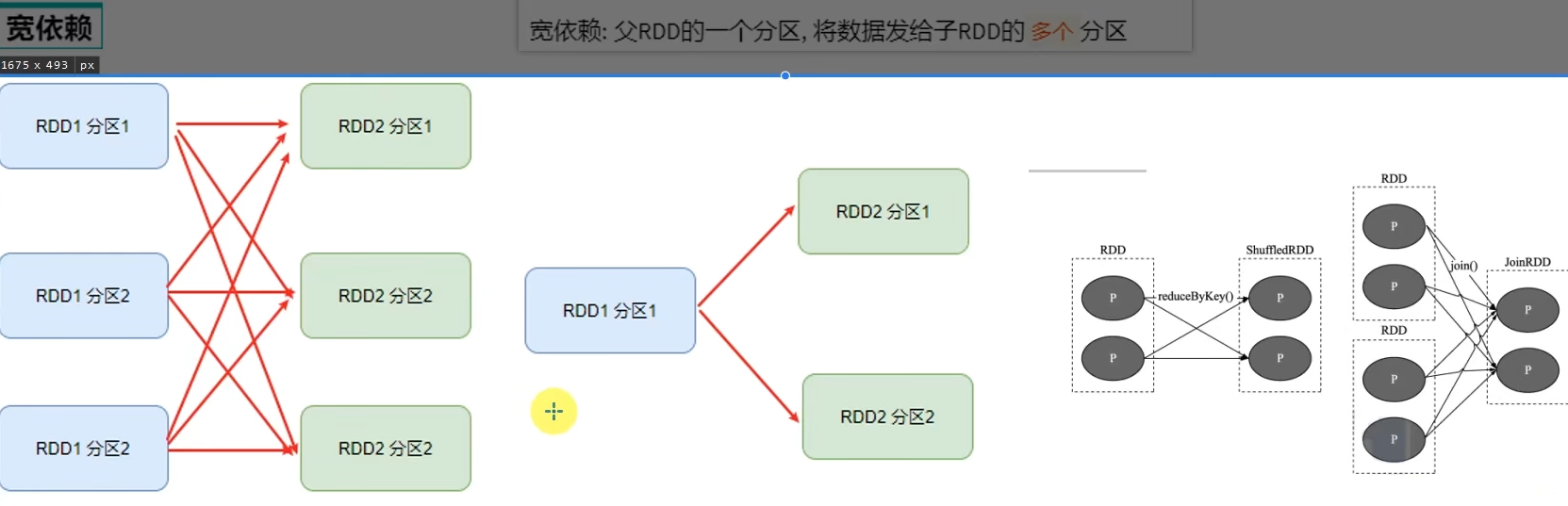
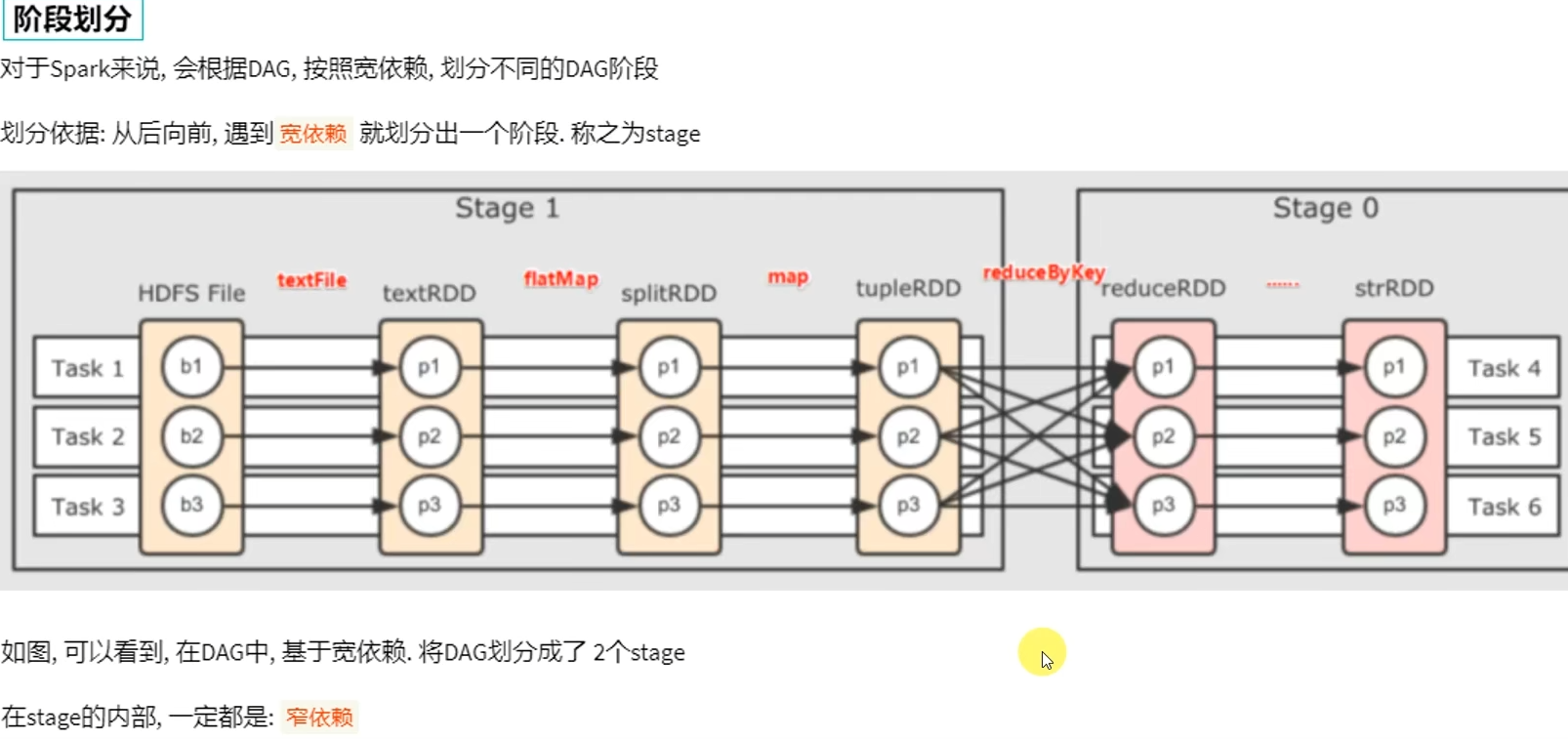
6.2 DAG的宽窄依赖和阶段划分

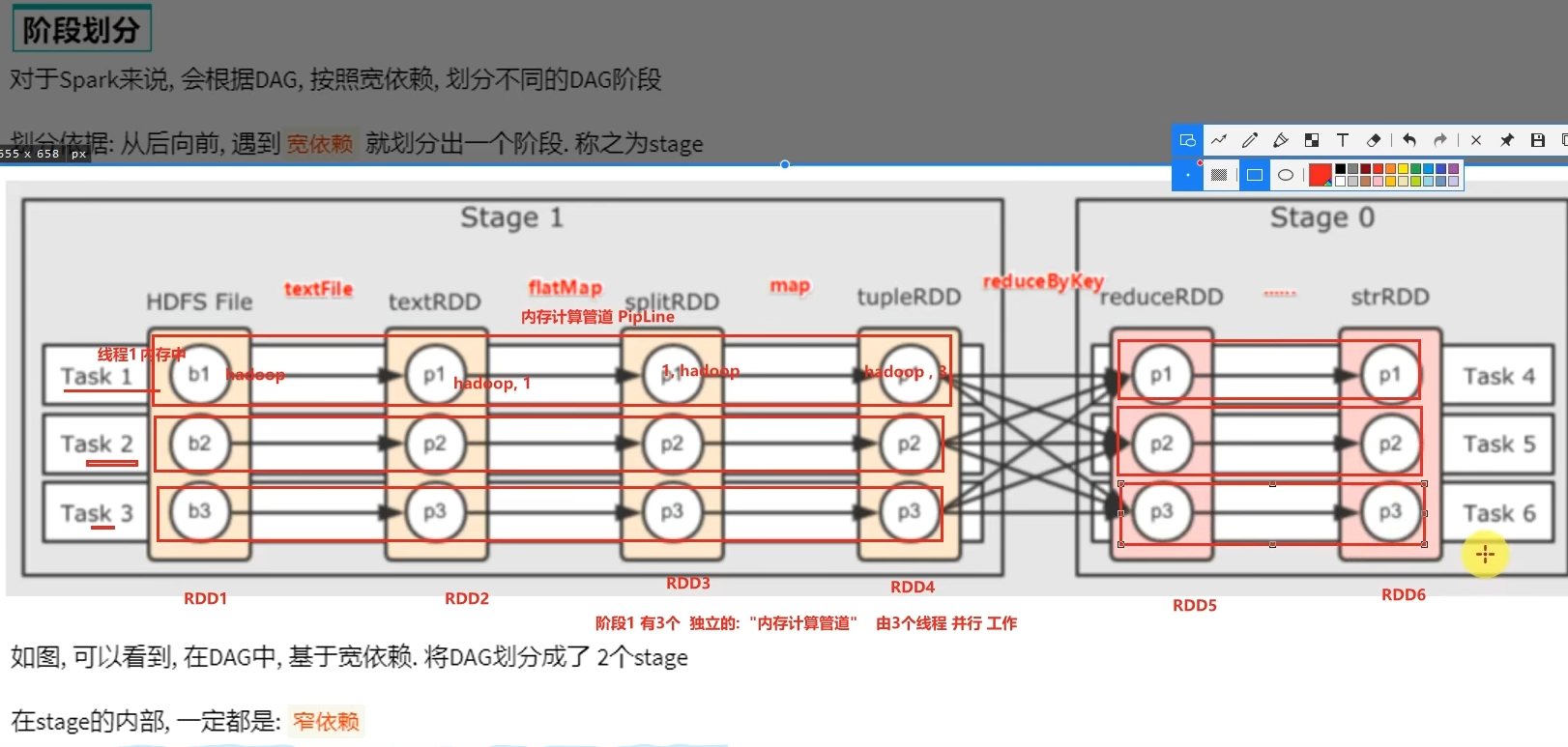
6 .3 内存迭代计算
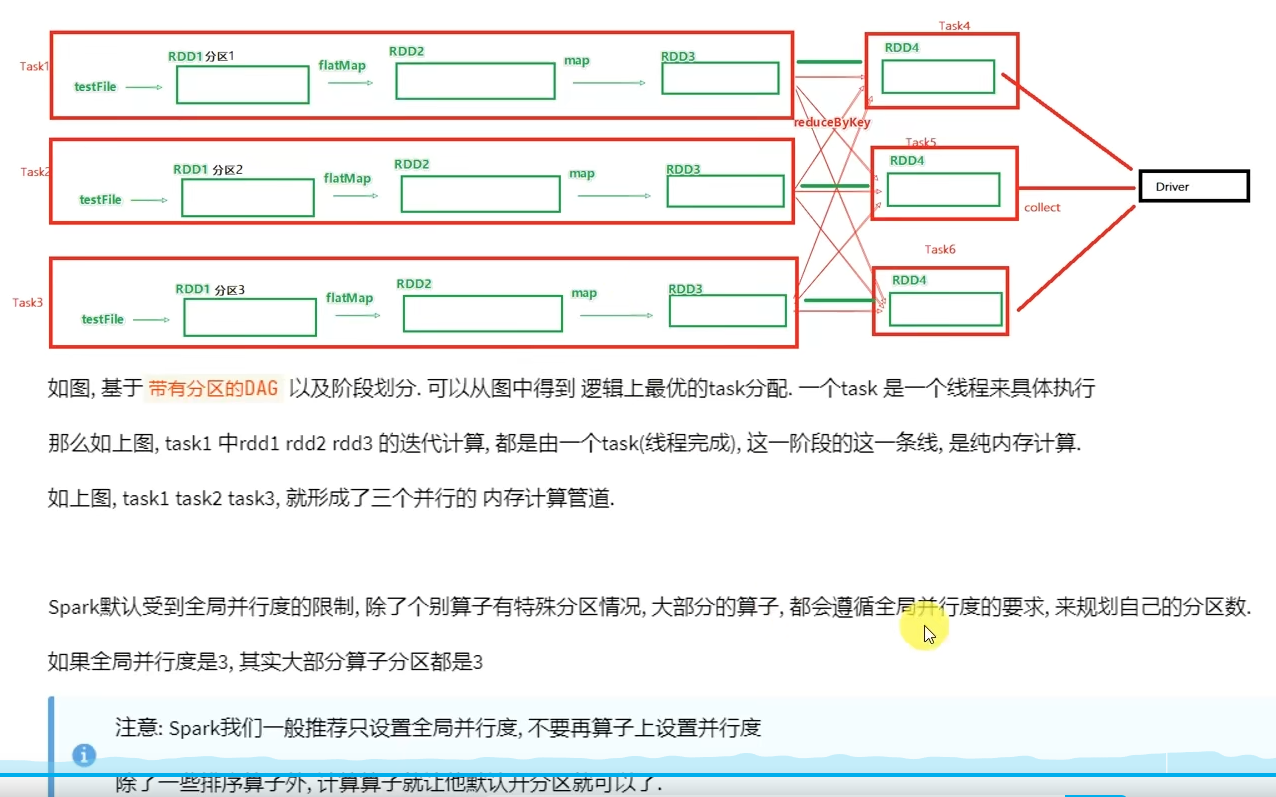


6.4 Spark并行度


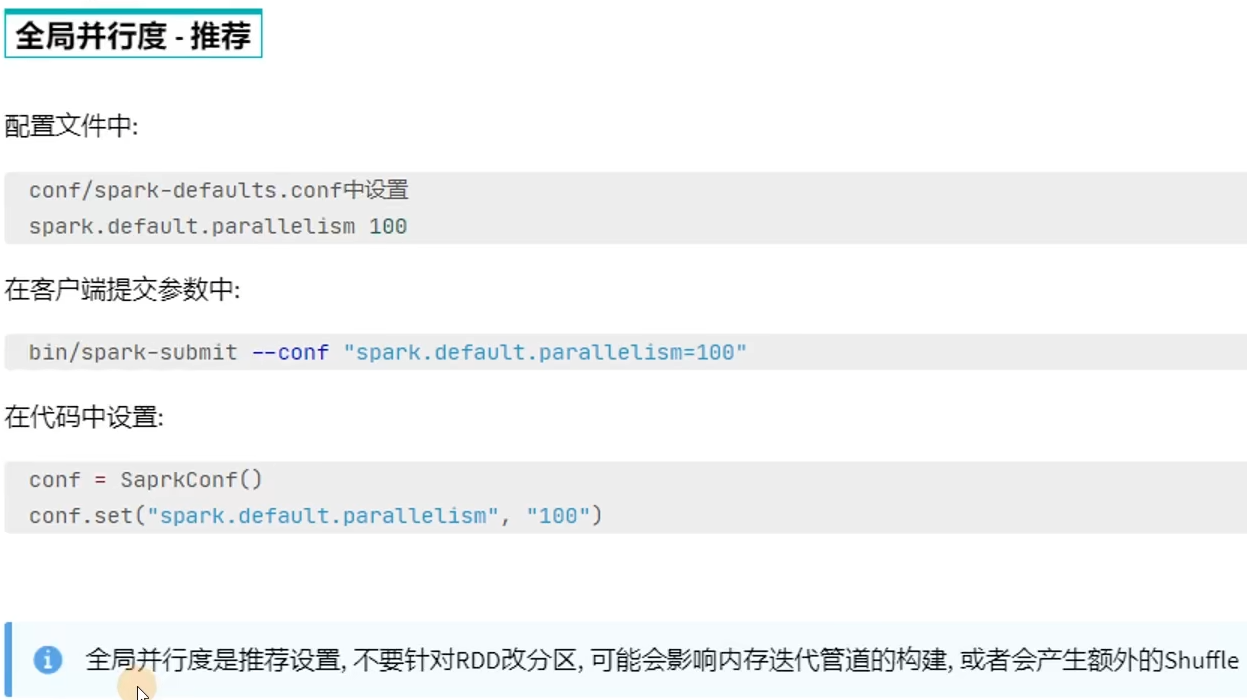


6.5 Spark任务调度
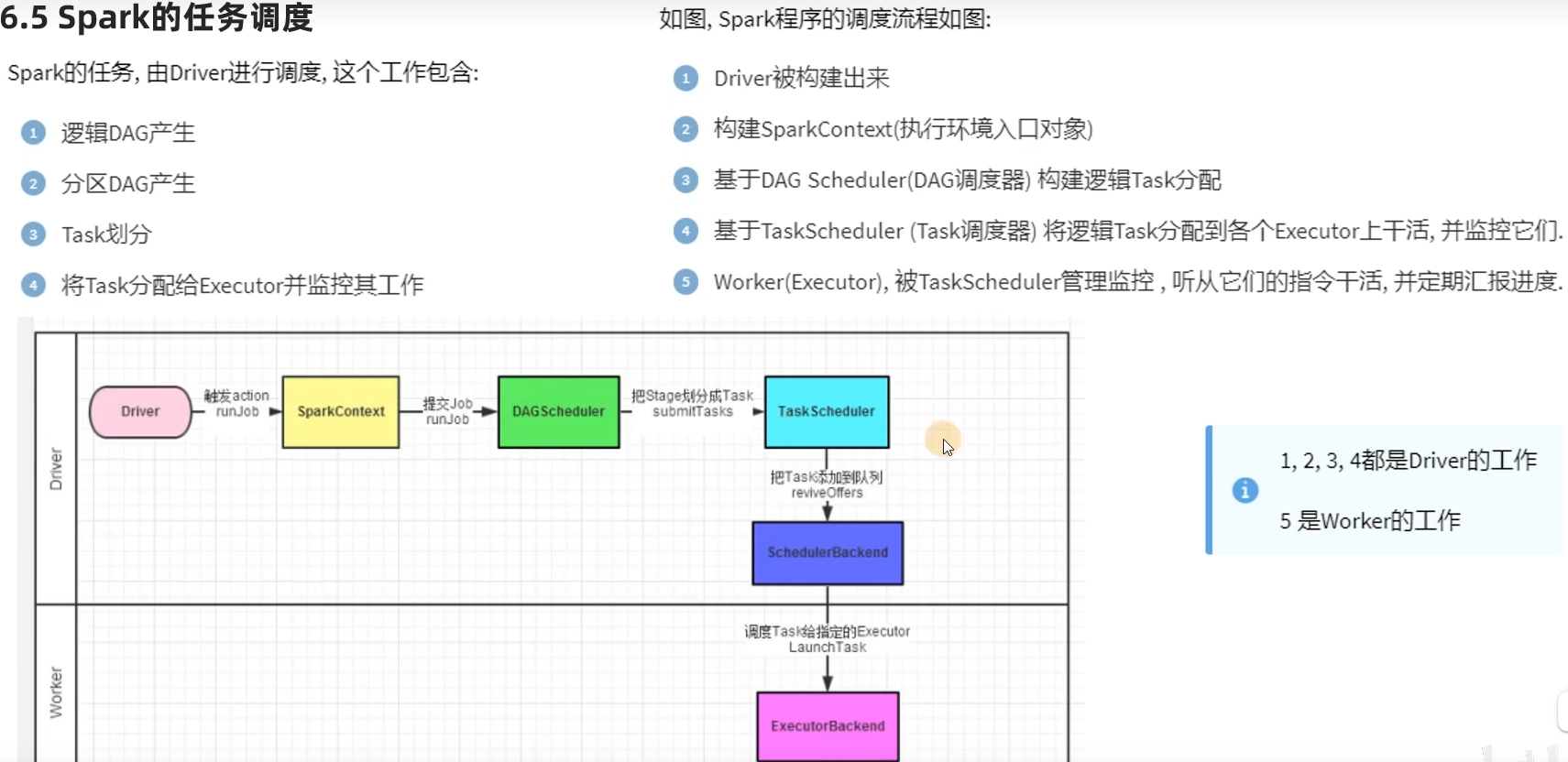
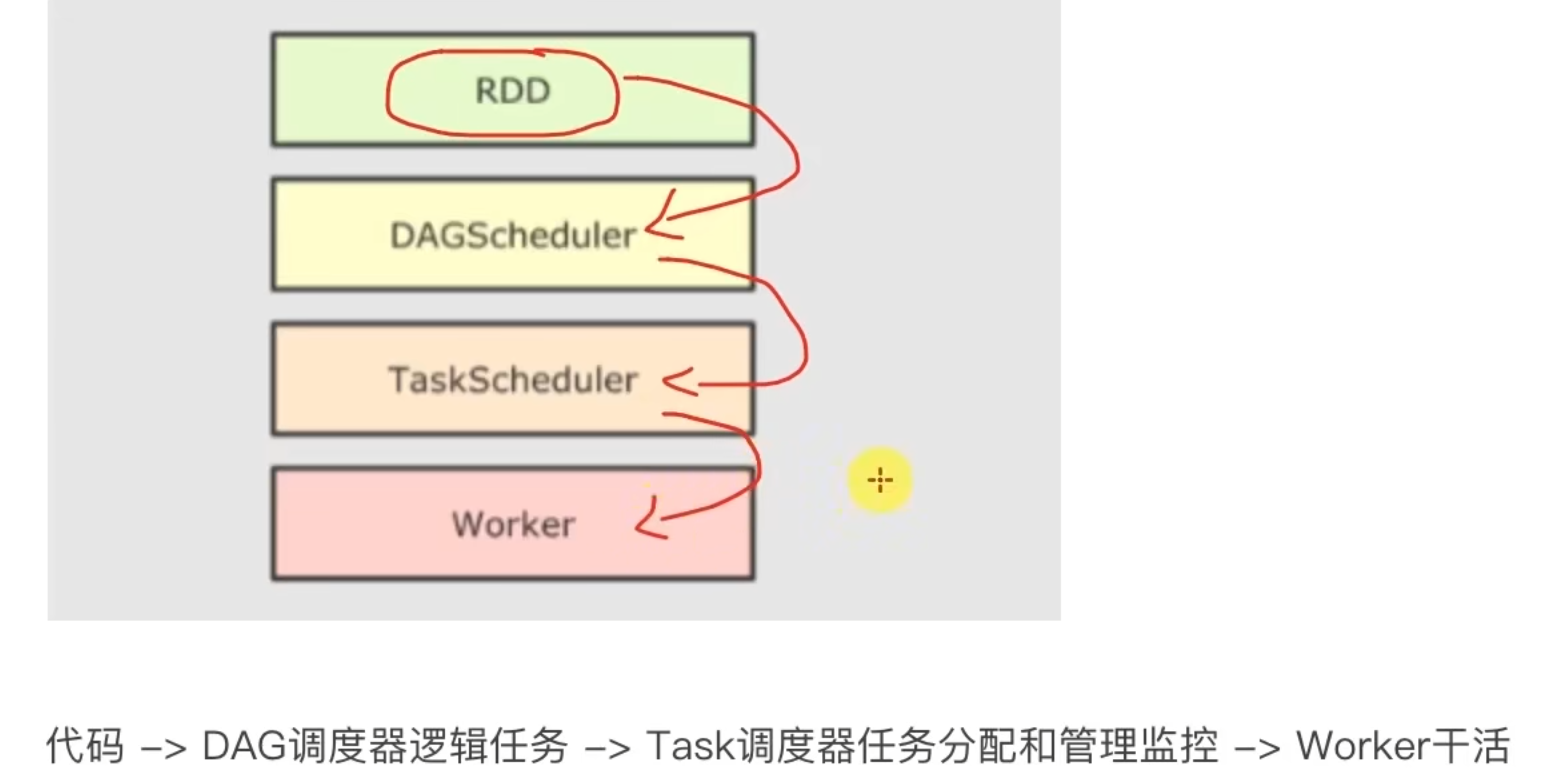
DAG调度器


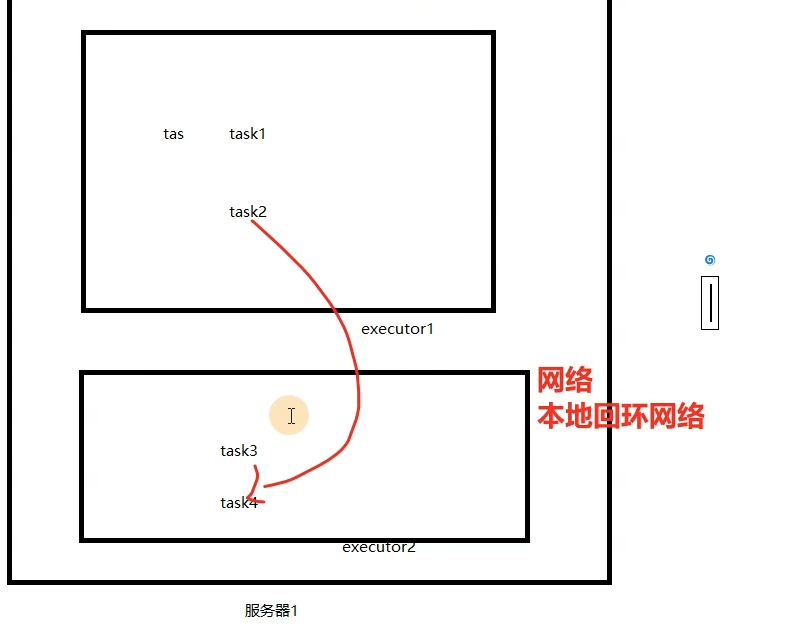
如果一台服务器内开多个executor,会进行进程间的通信(所以建议一台服务器就开一个executor)
Task调度器

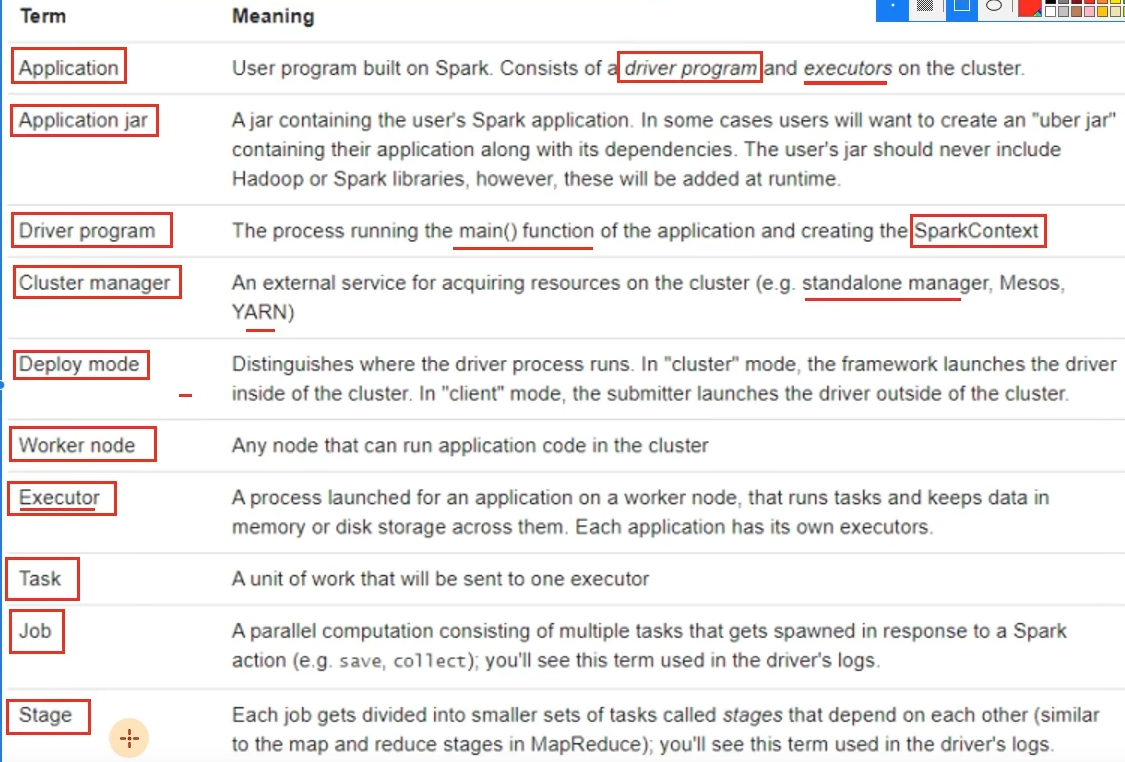
6.6 拓展-Spark概念名称大全

6.7 第六章总结
- DAG是什么有什么用?
DAG有向无环图,用以描述任务执行流程,主要作用是协助DAG调度器构建Task分配用以做任务管理。
- 内存迭代/阶段划分?
基于DAG的宽窄依赖划分阶段,阶段内部都是窄依赖可以构建内存迭代的管道。
- DAG调度器是?
构建Task分配用以做任务管理。
3.SparkSQL
学习目标
- 了解SparkSQL框架模块的基础概念和发展历史
- 掌握SparkSQL DataFrame API开发
- 理解SparkSQL的运行流程
- 掌握SparkSQL和Hive的集成
第一章:SparkSQL快速入门
1.1 什么是SparkSQL

1.2 为什么要学习SparkSQL

1.3 SparkSQL特点

1.4 SparkSQL发展历史
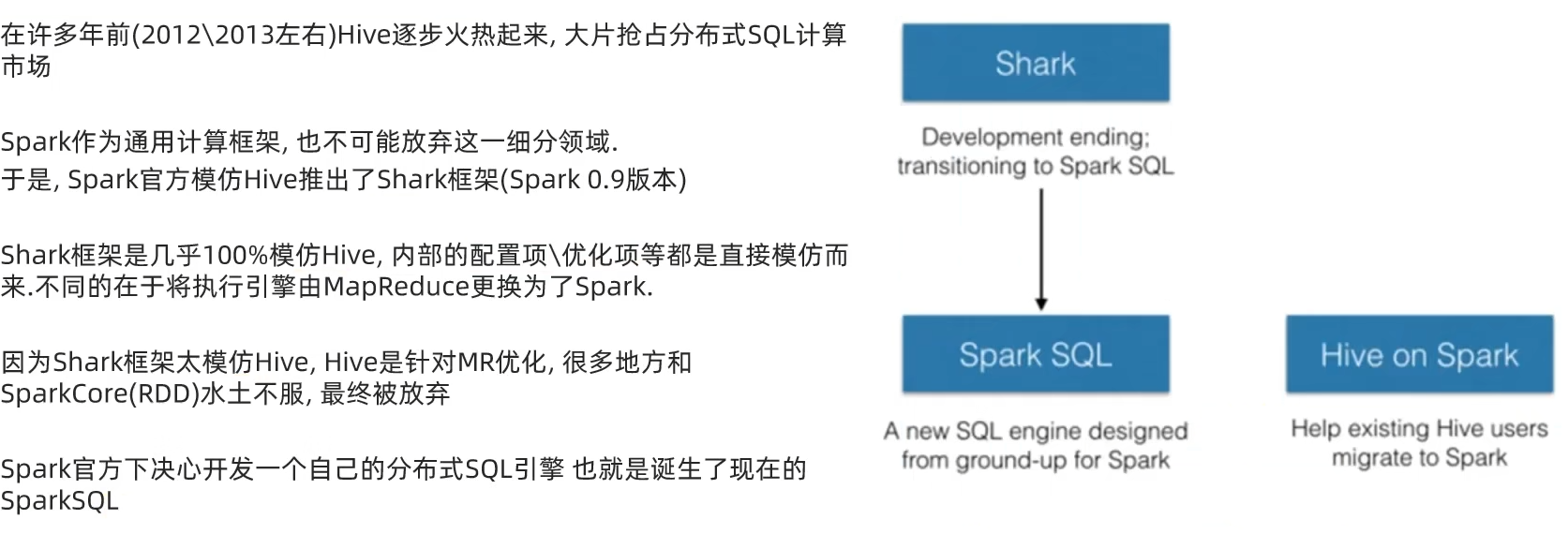
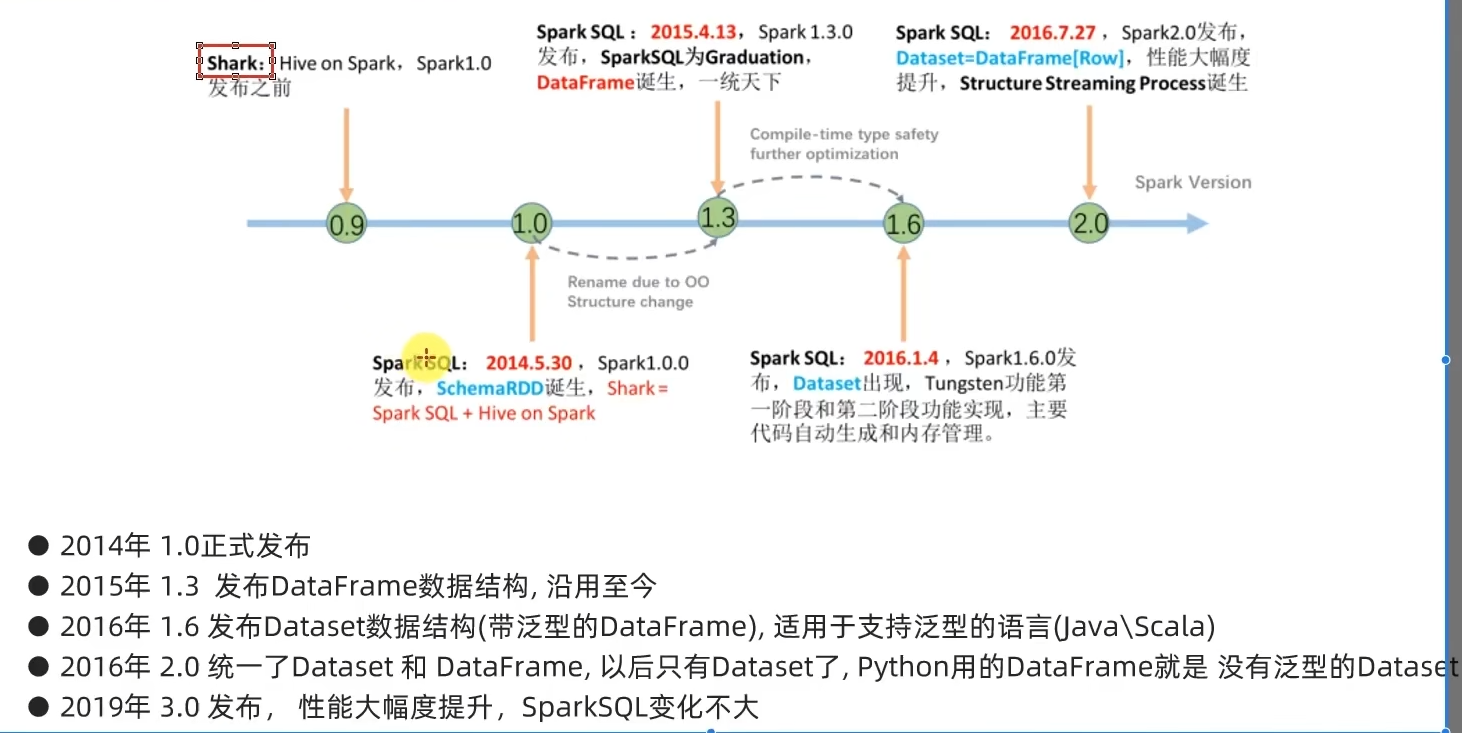
1.5 第一章总结

第二章:SparkSQL概述
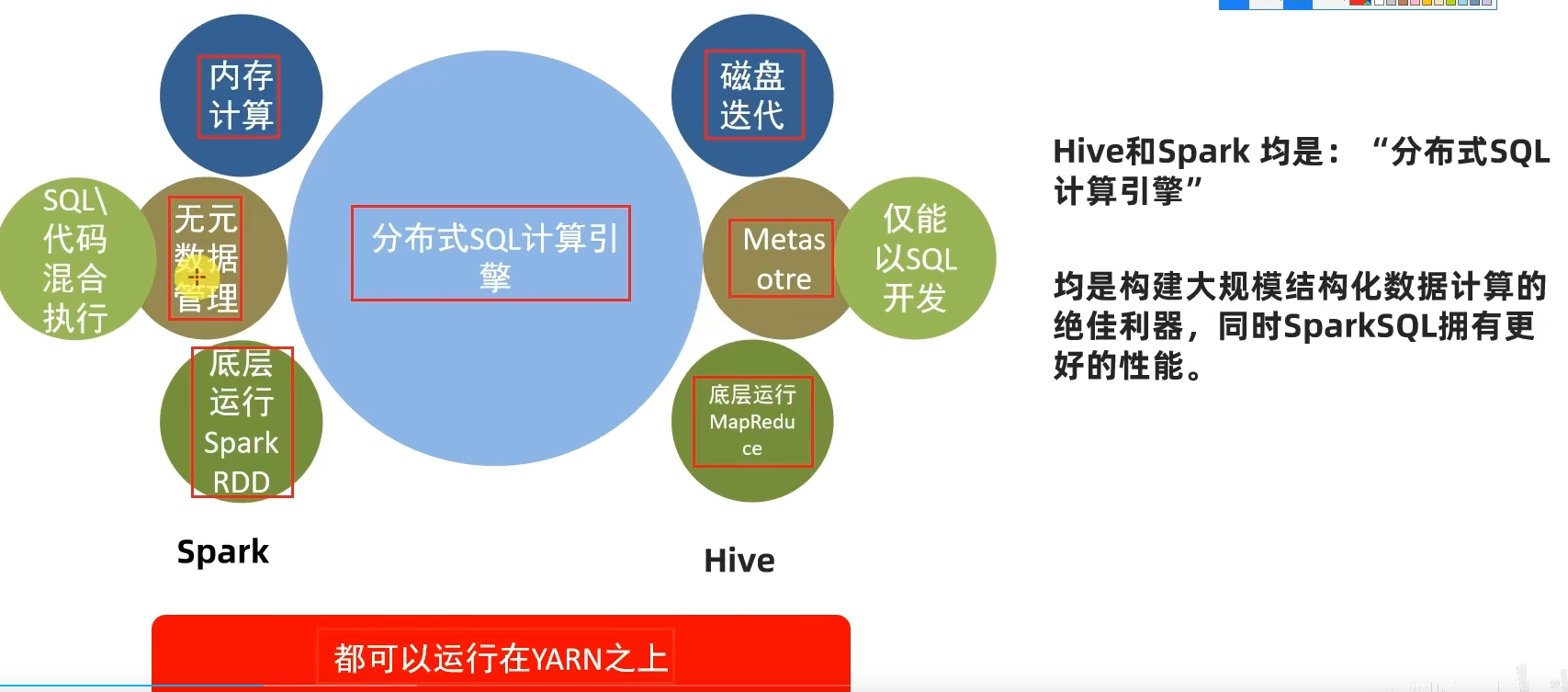
2.1 SparkSQL和Hive的异同
2.2 SparkSQL的数据抽象

2.3 SparkSQL数据抽象的发展

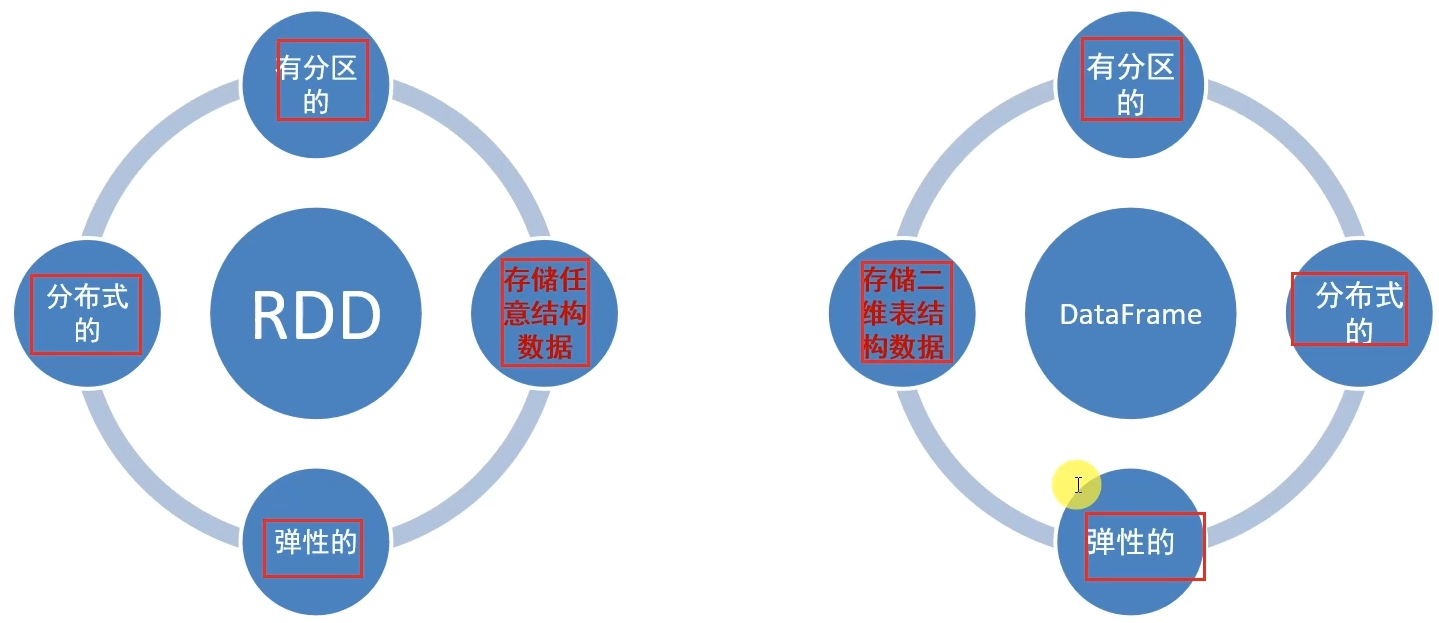
2.4 DataFrame数据抽象
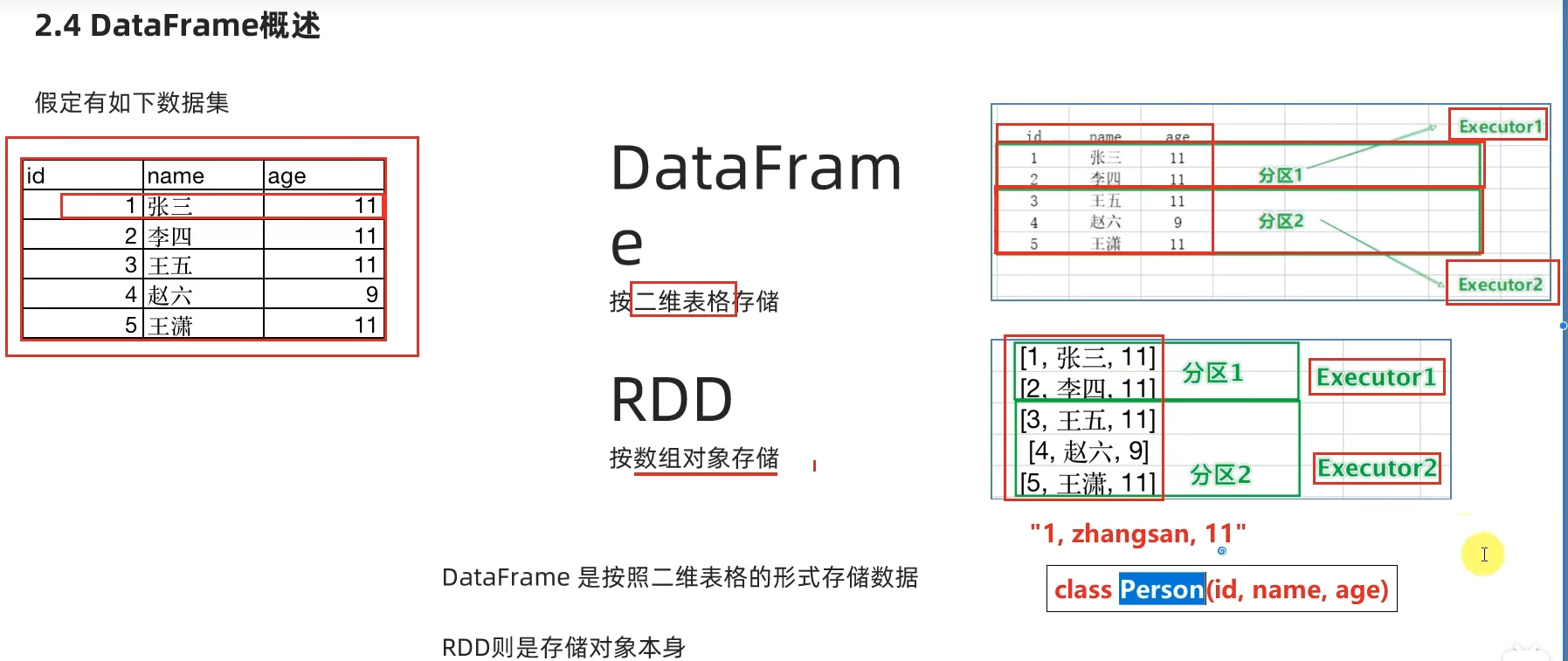
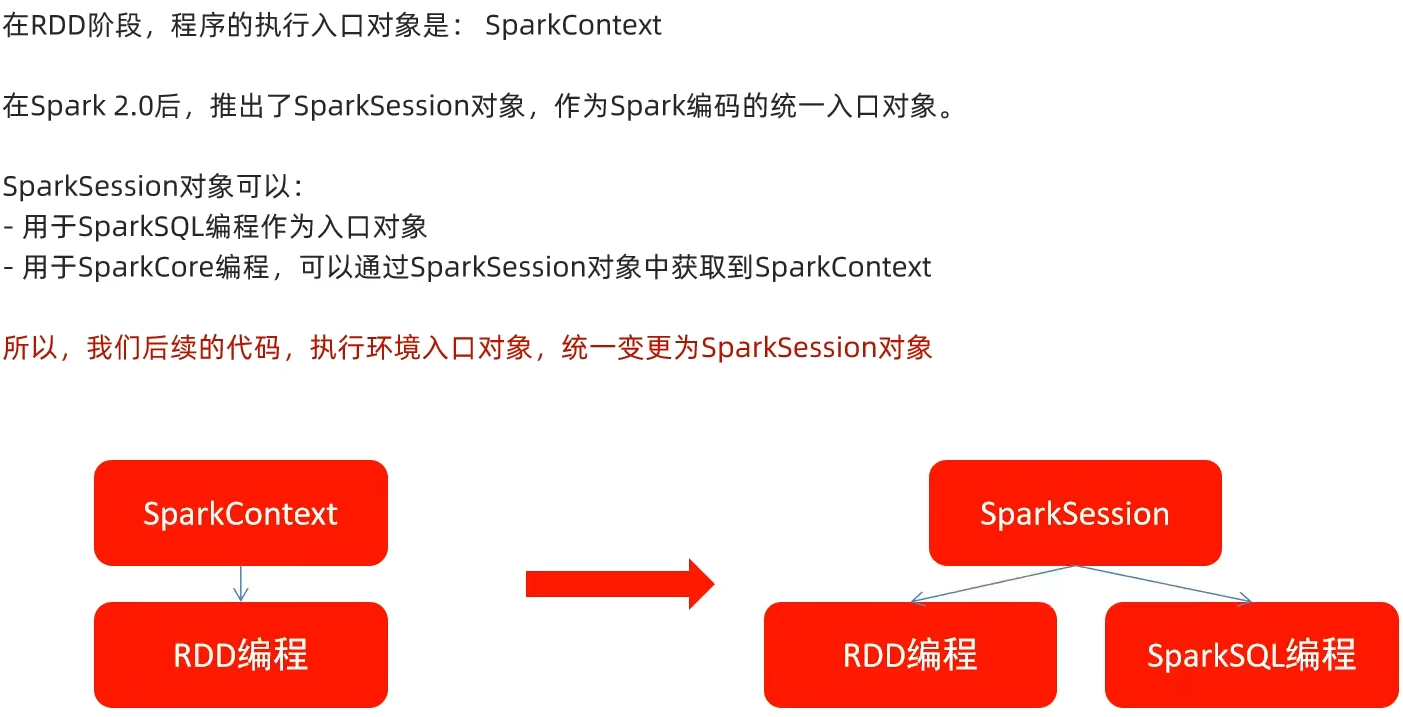
2.5 SparkSession对象
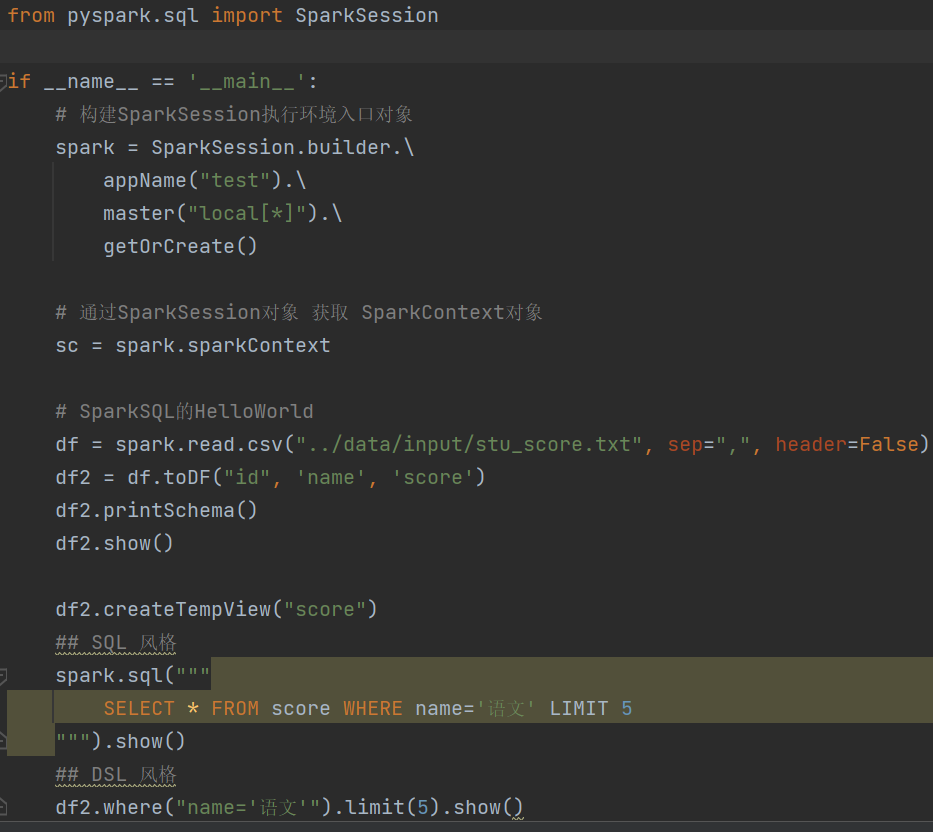
2.6 SparkSQL HelloWorld
2.7 第二章总结

第三章:DataFrame入门
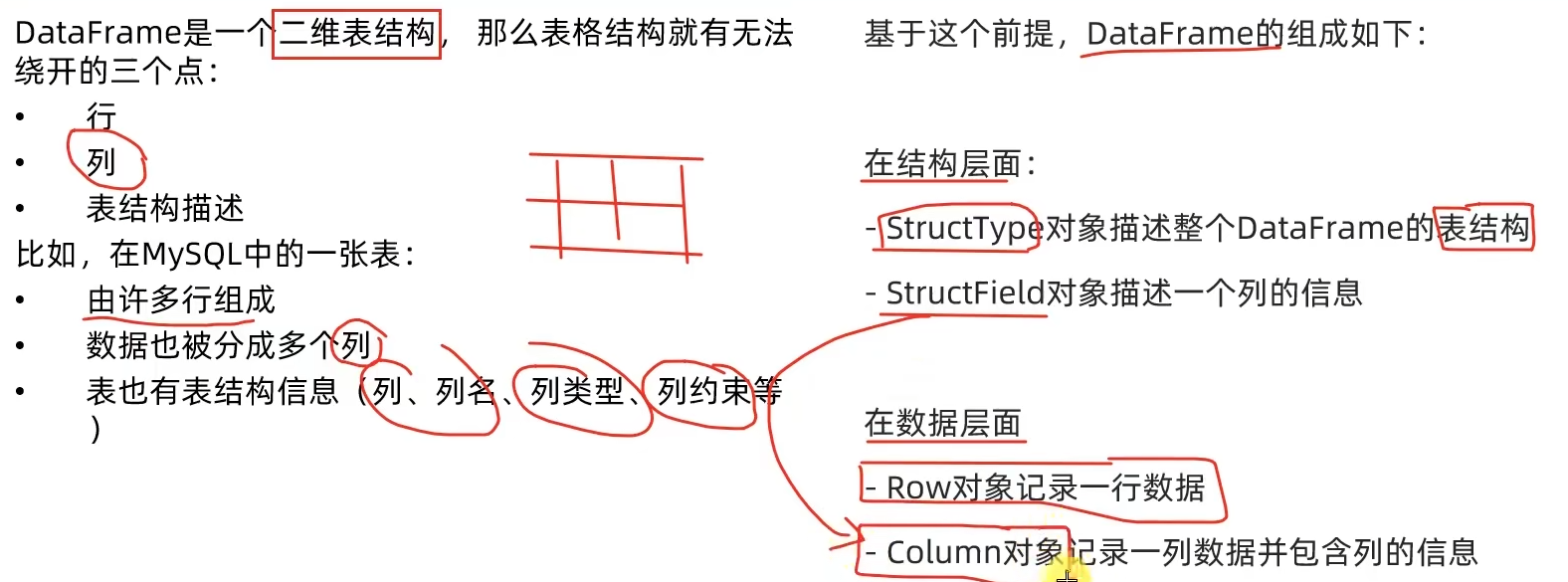
3.1 DataFrame的组成

3.2 DataFrame的代码构建
基于RDD方式1-通过createDataFrame方法

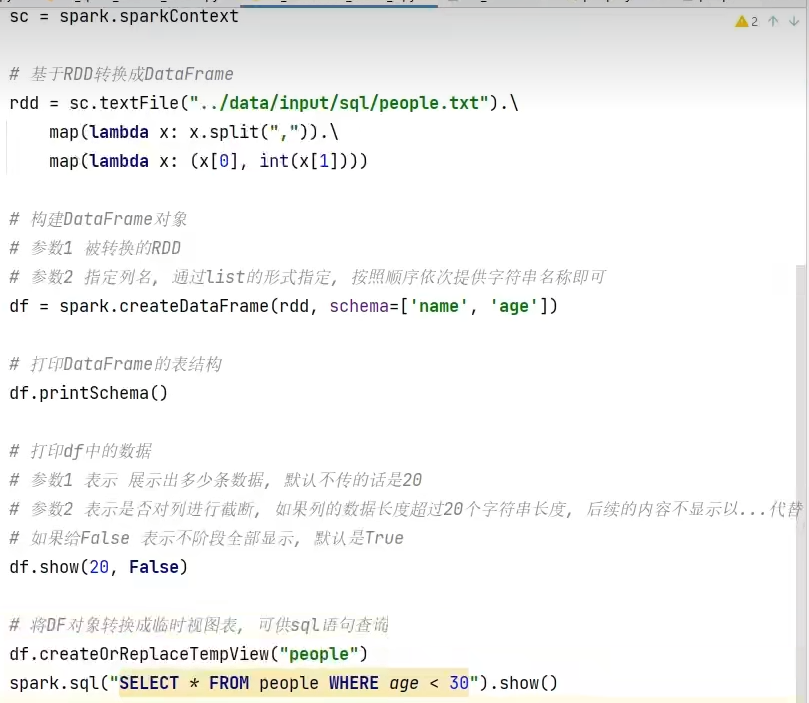
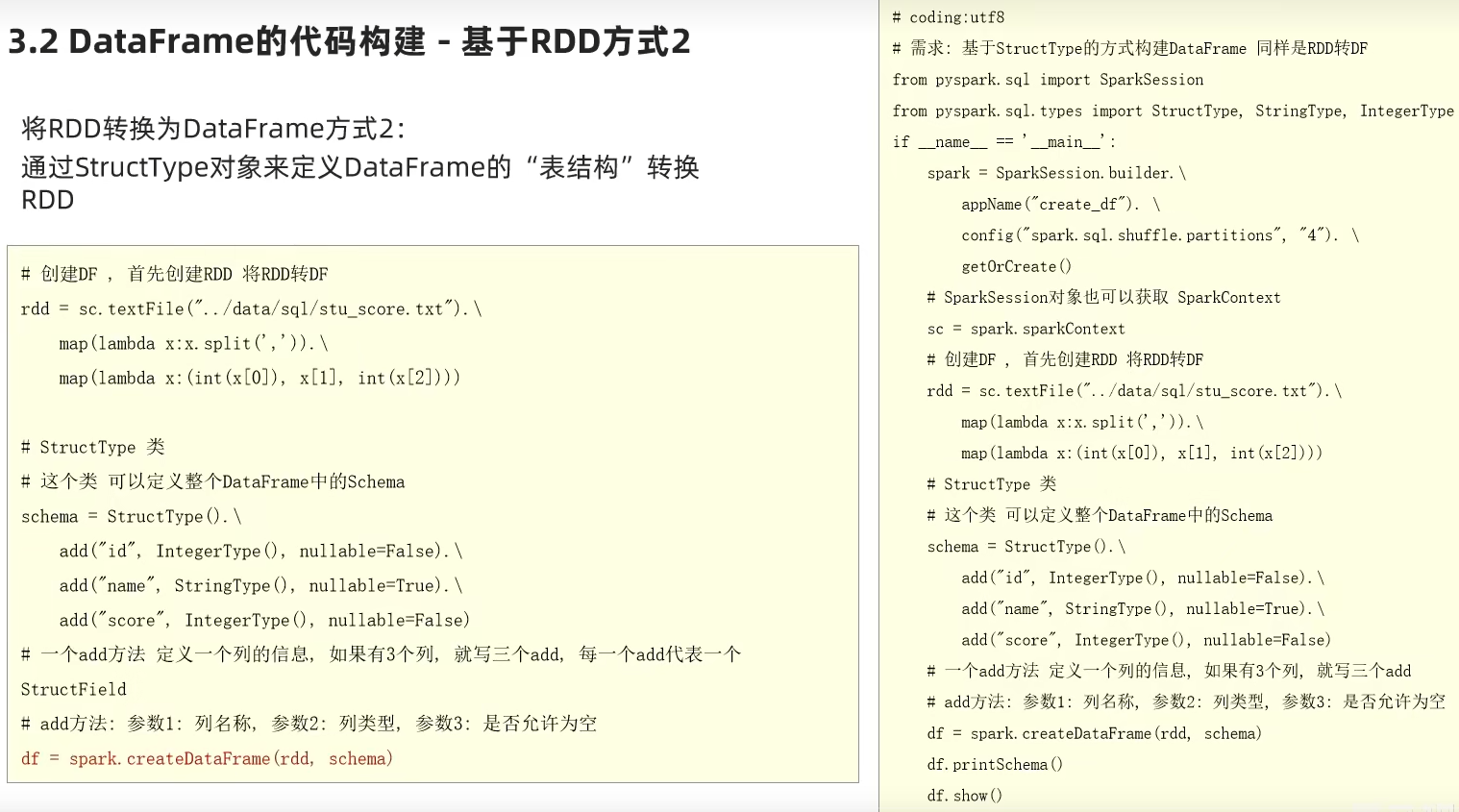
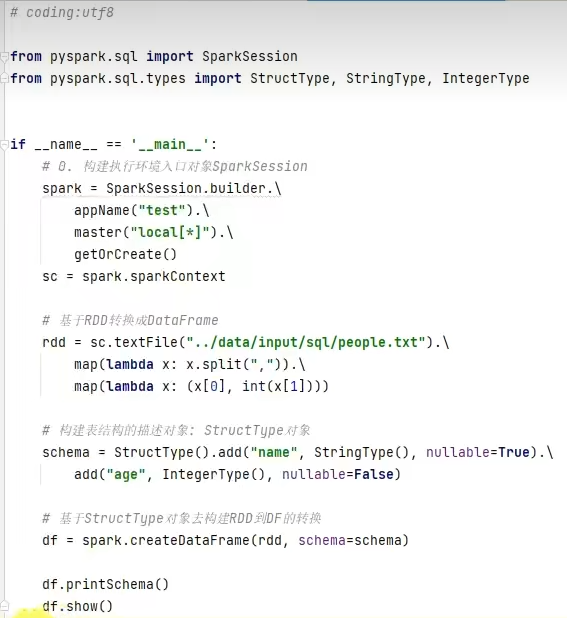
基于RDD方式2-通过StructType对象
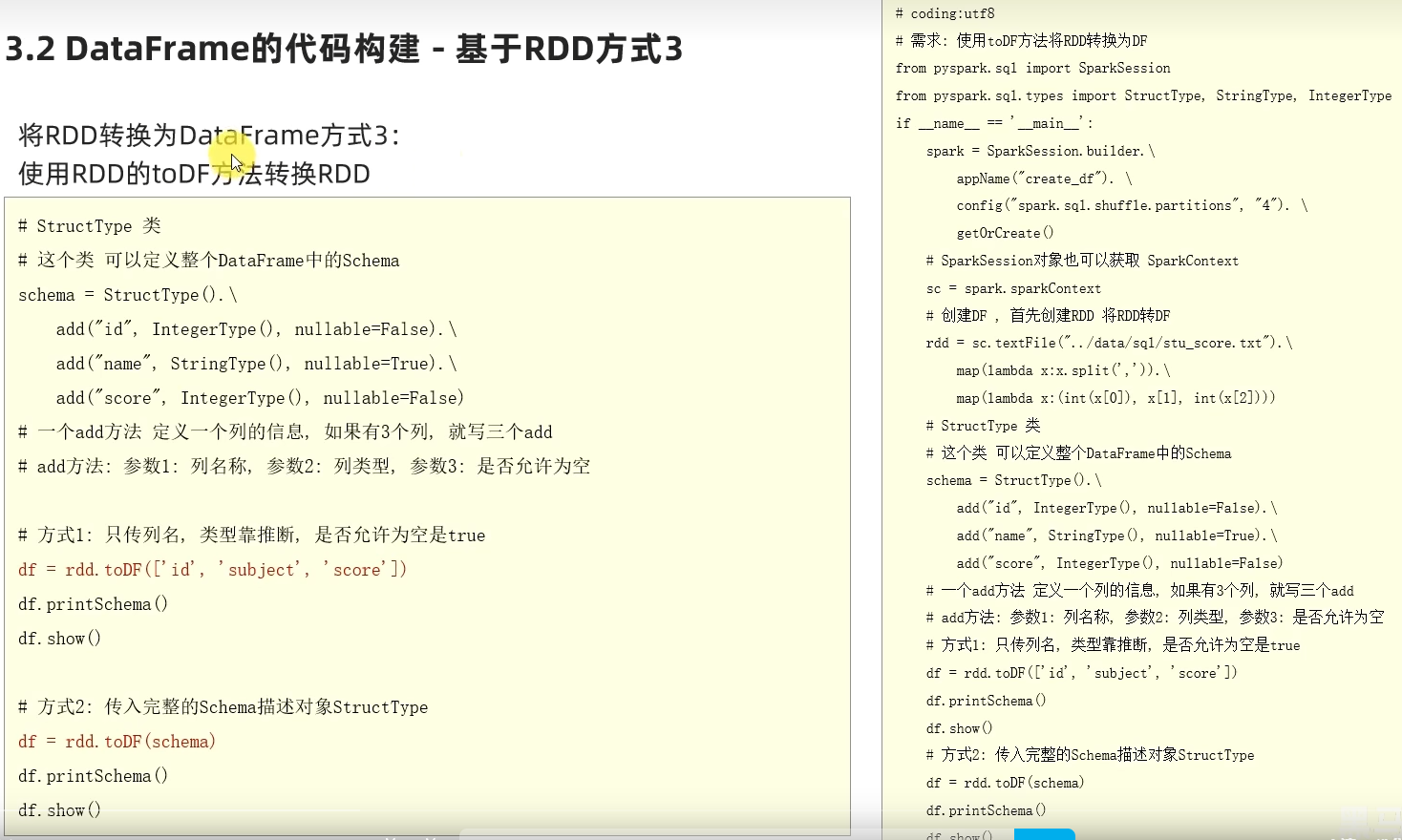
基于RDD方式3-使用toDF方法
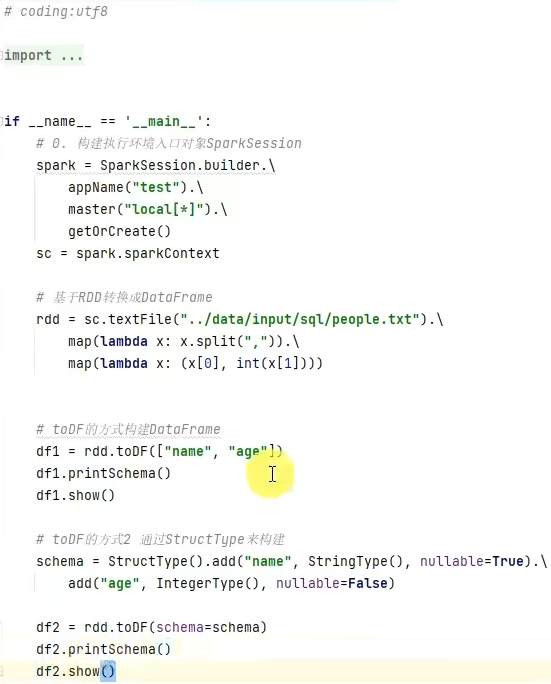
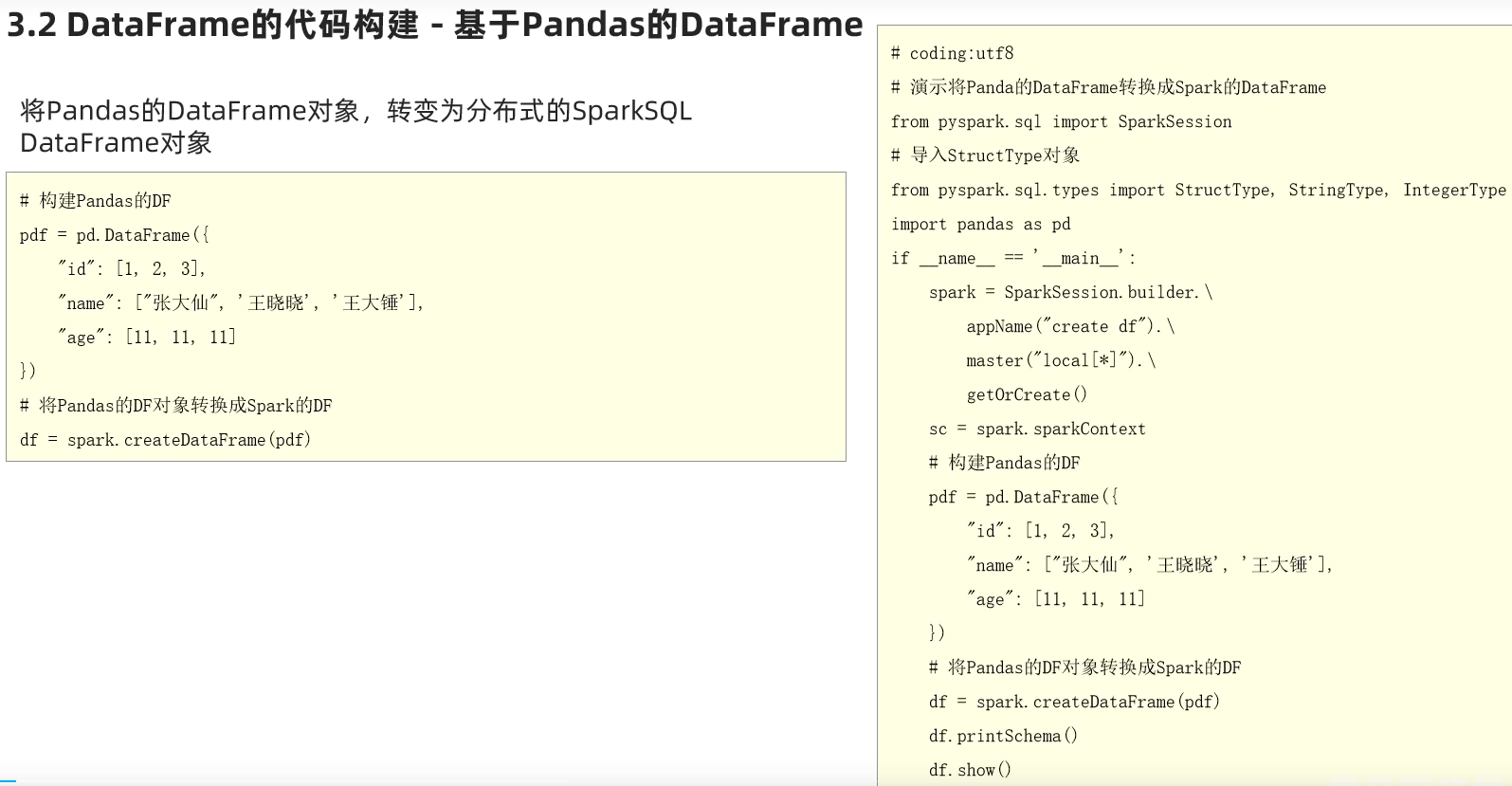
基于Pandas的DataFrame
读取外部数据

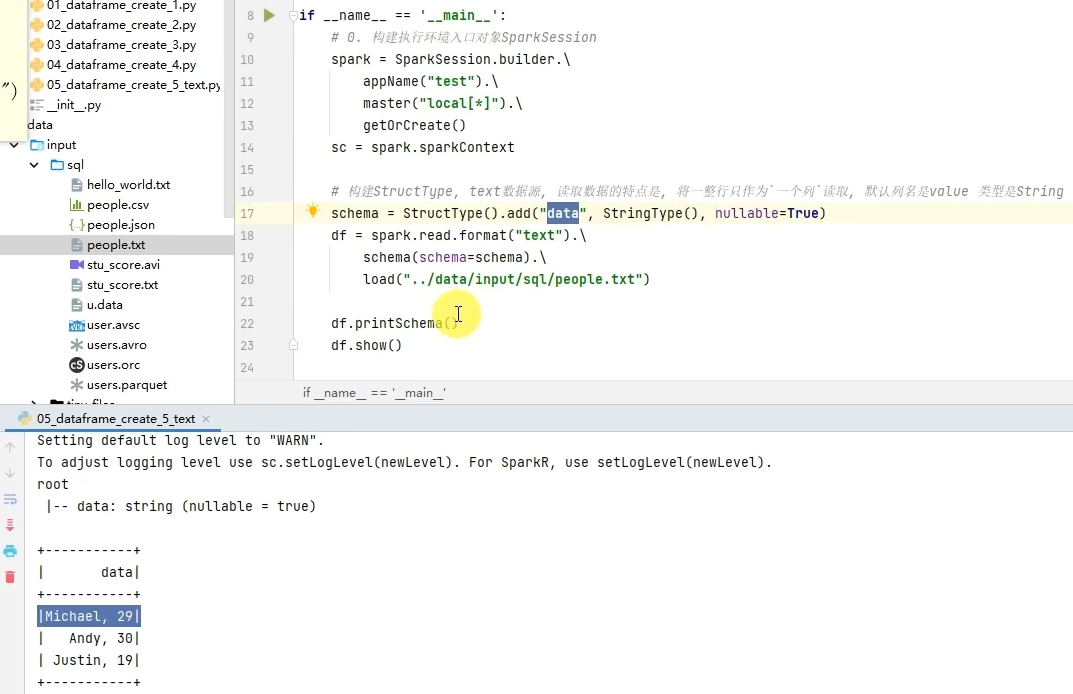
读取Text文件
读取json文件

读取csv文件

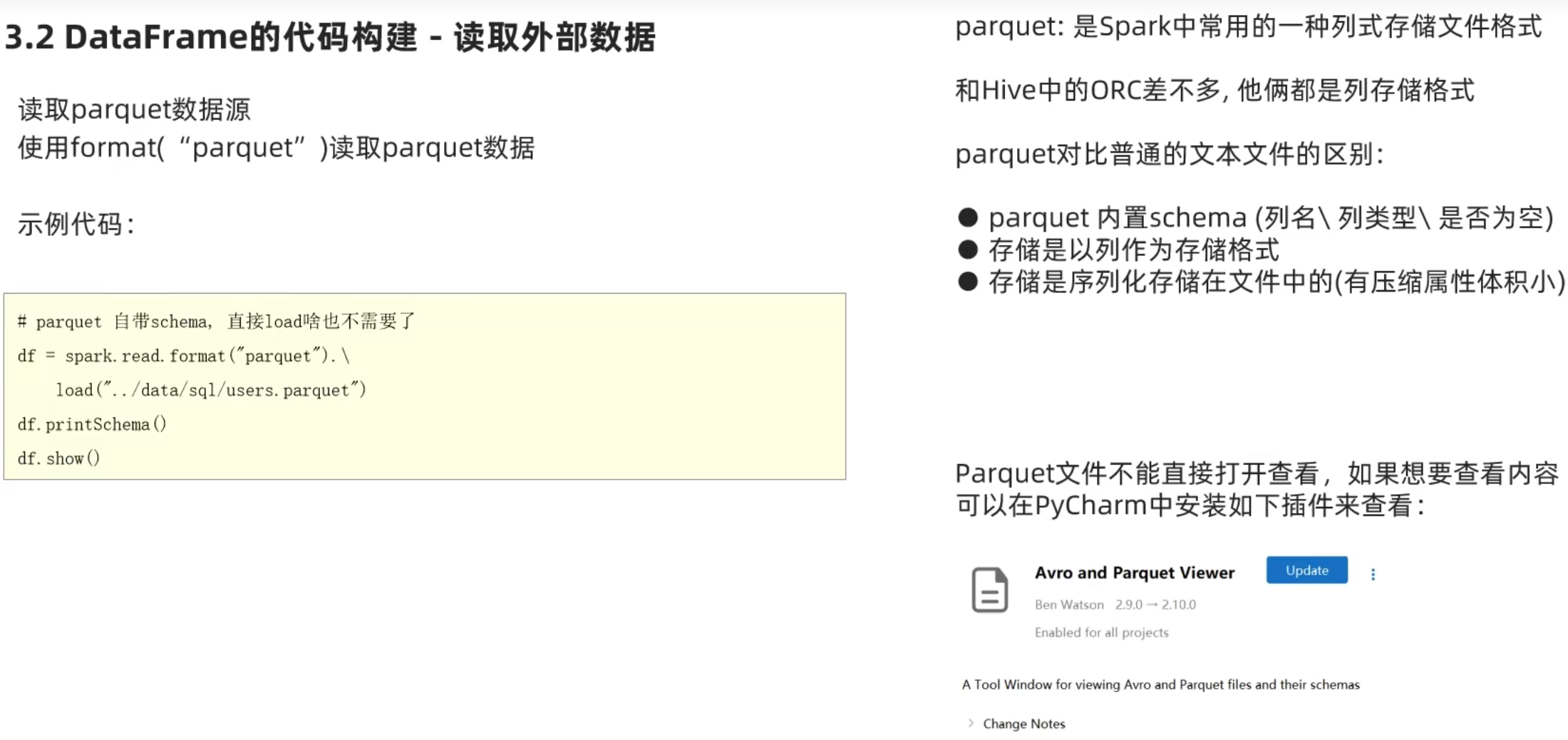
读取parquet文件
3.3 DataFrame的入门操作

DSL风格
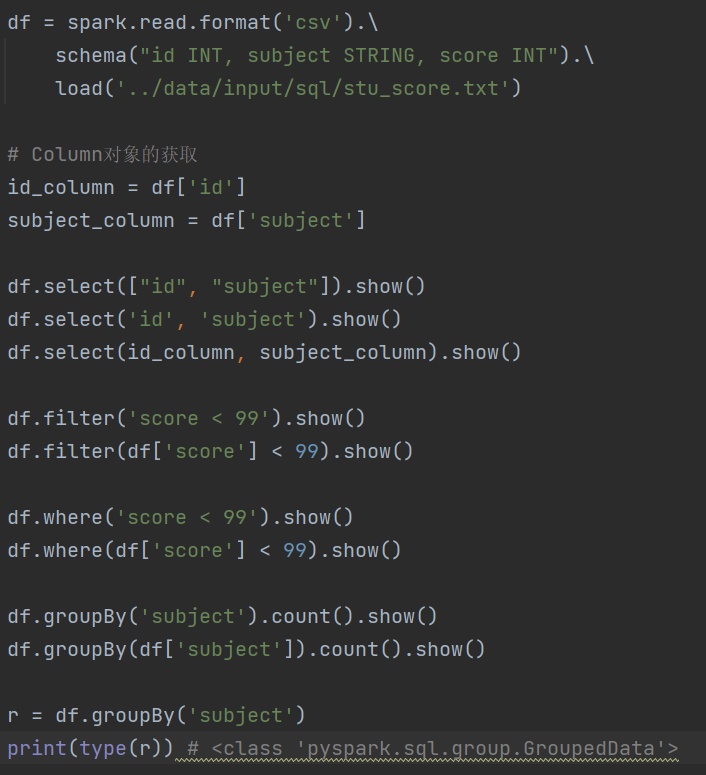
SQL风格

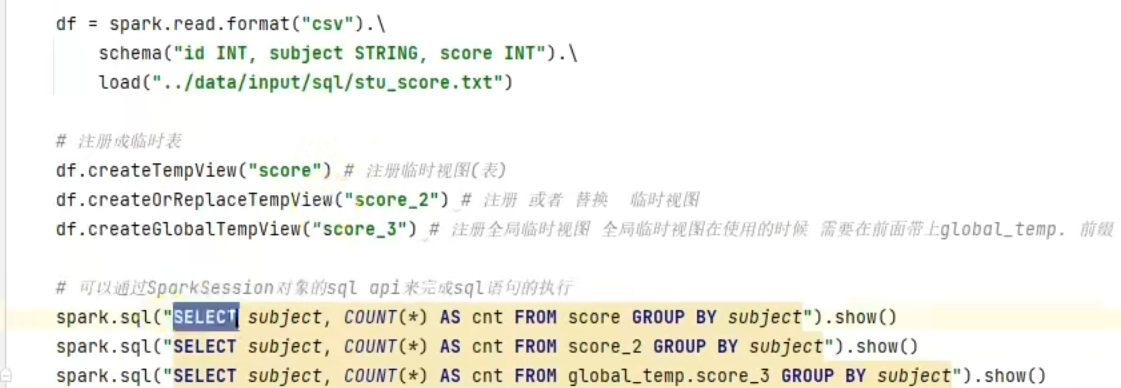

3.4 词频统计案例

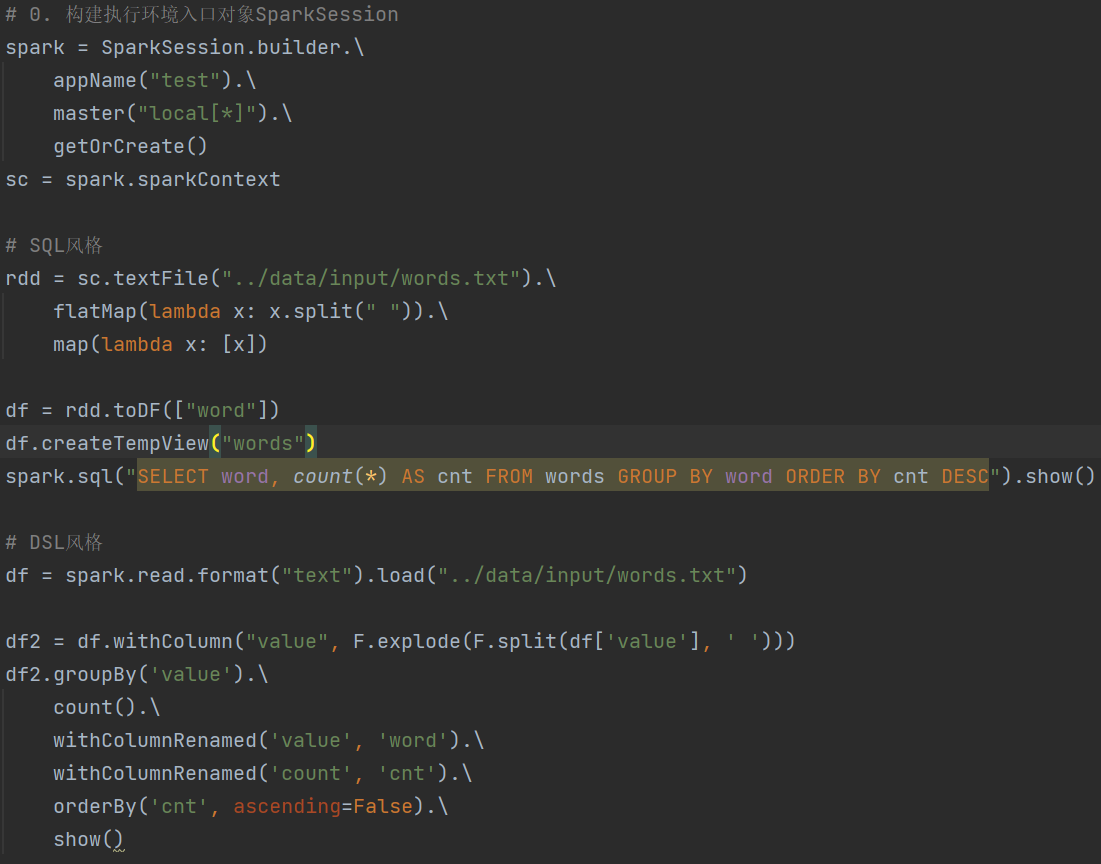
3.5 电影数据分析
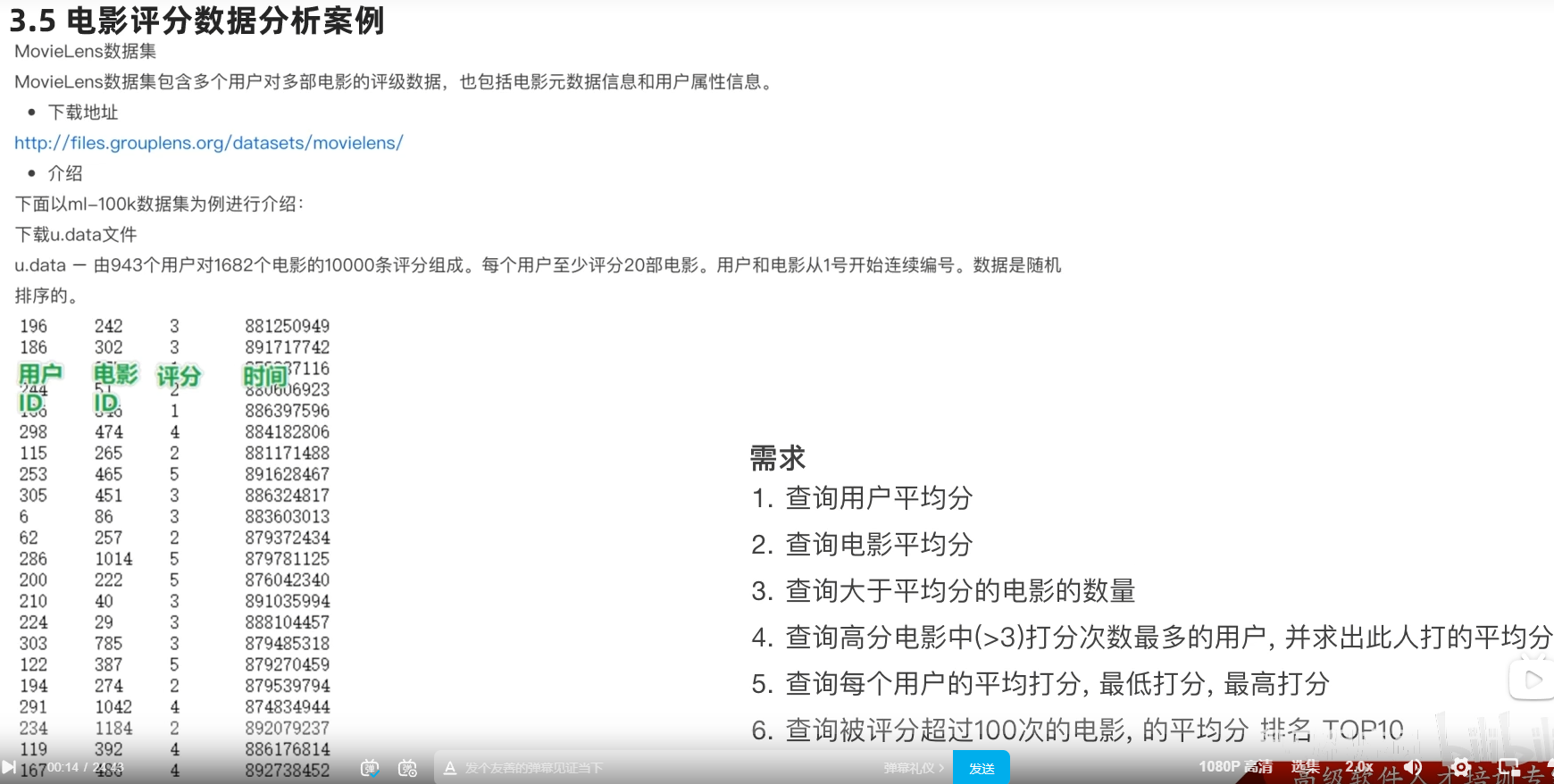
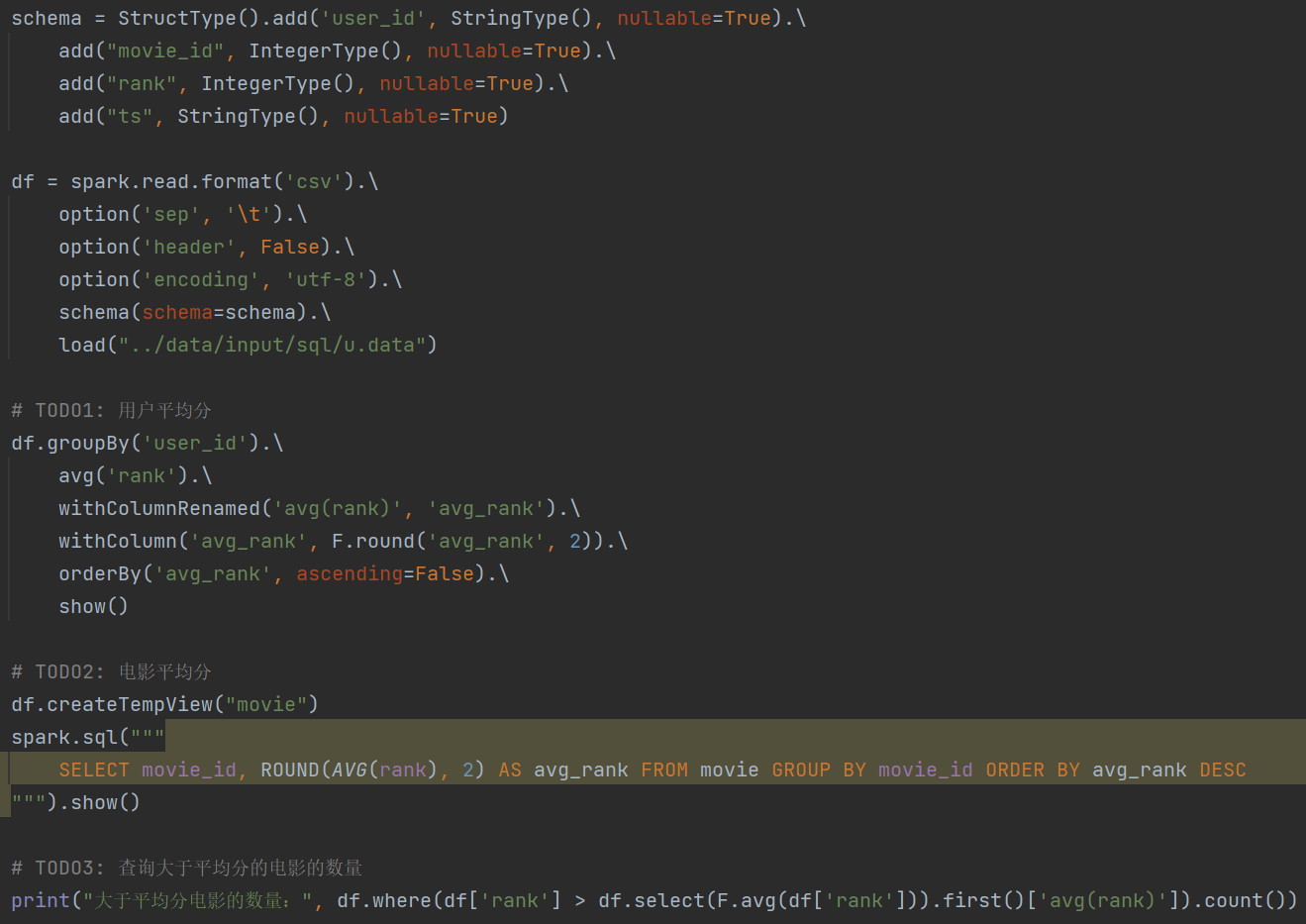
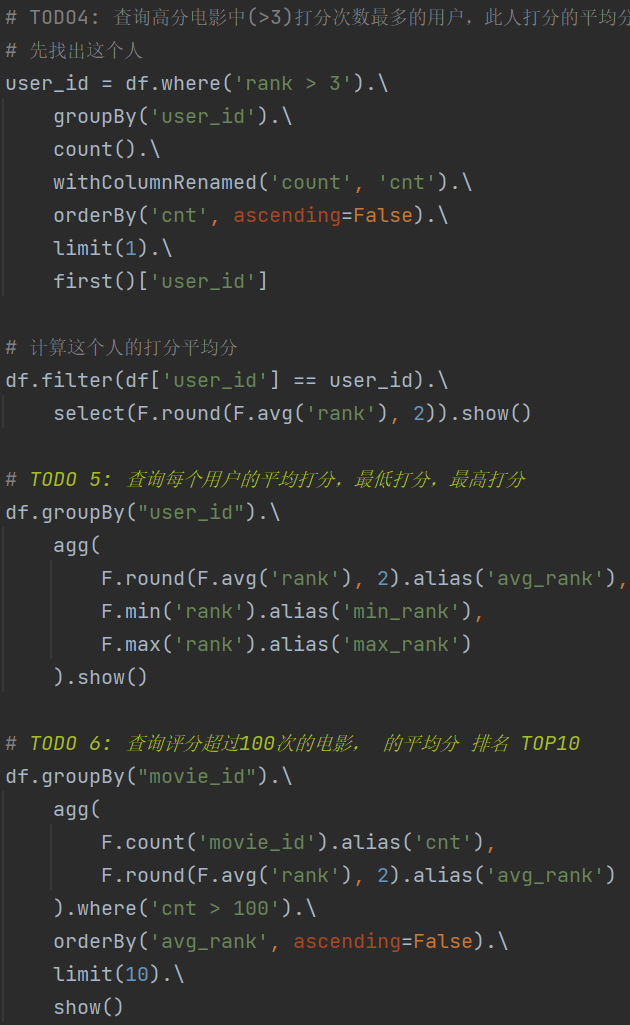

遇到问题:
1.dataframe对象经过多次.之后,IDE无法自动补全得到withColumnRenamed方法?
仍未解决。
其他解决方案:使用AI代码补全插件
2.需要安装pytest模块
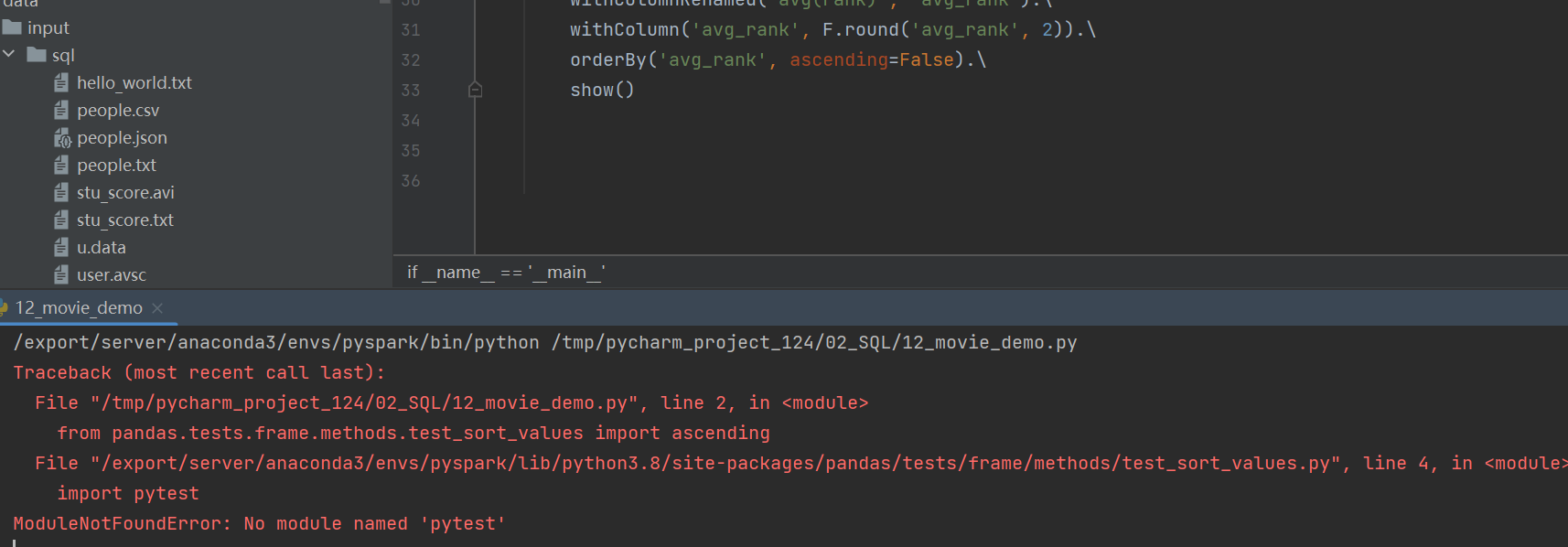
解决方案:在虚拟环境中安装pytest
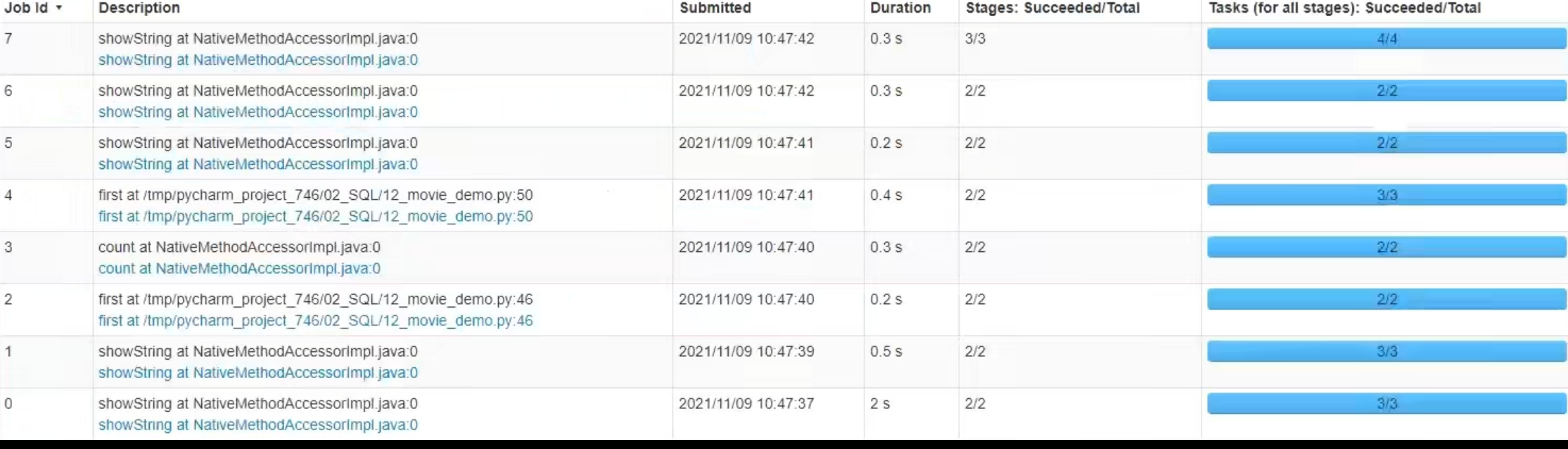
3.6 SparkSQL Shuffle 分区数目
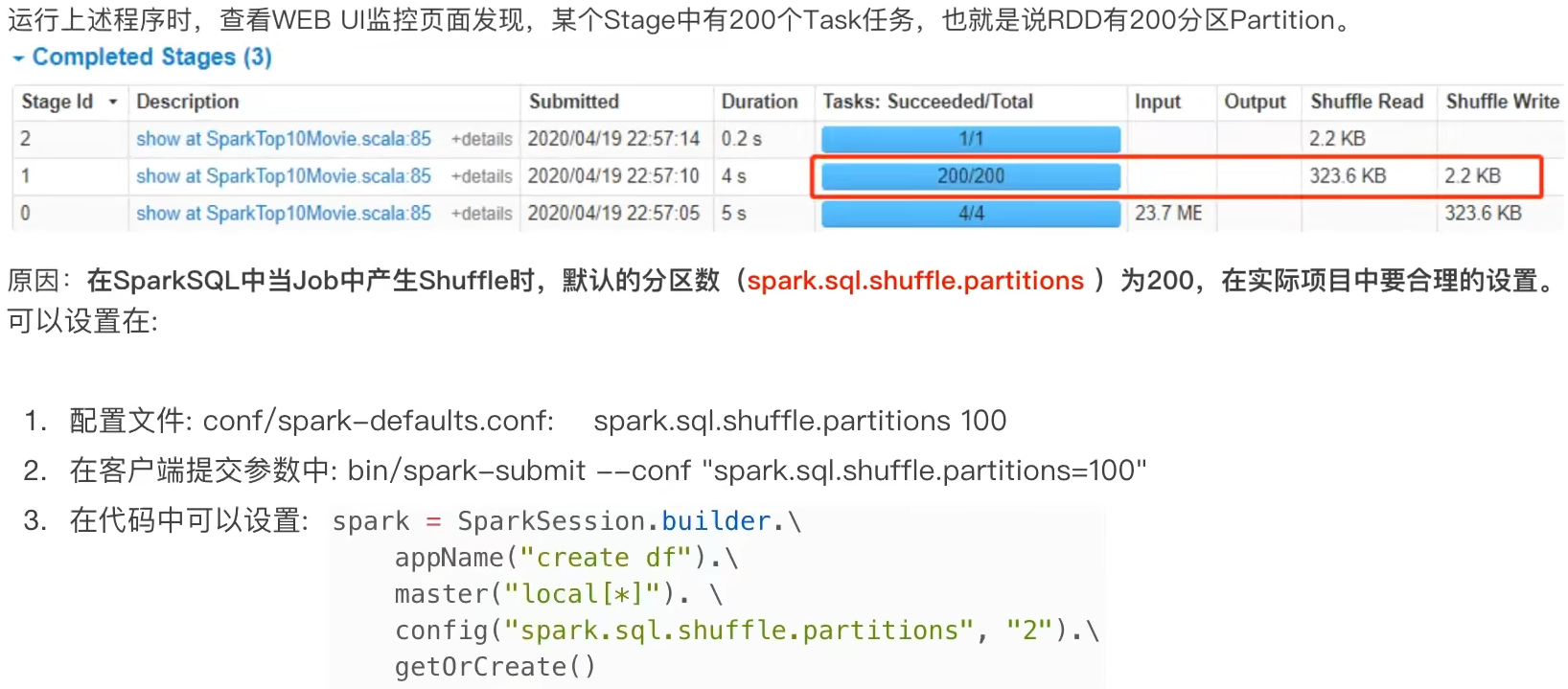
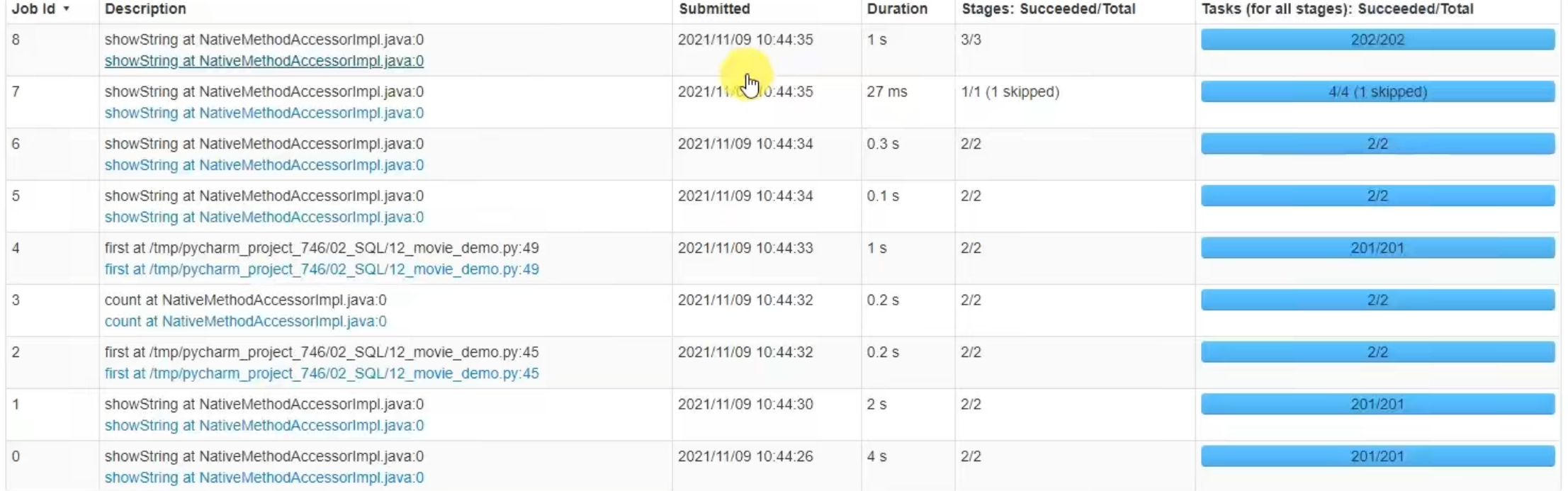
可以看出,速度变快了

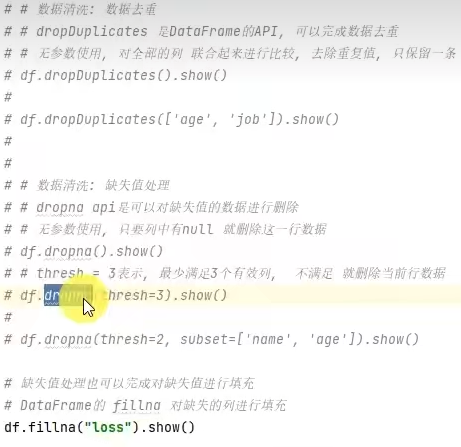
3.7 SparkSQL 数据清洗API

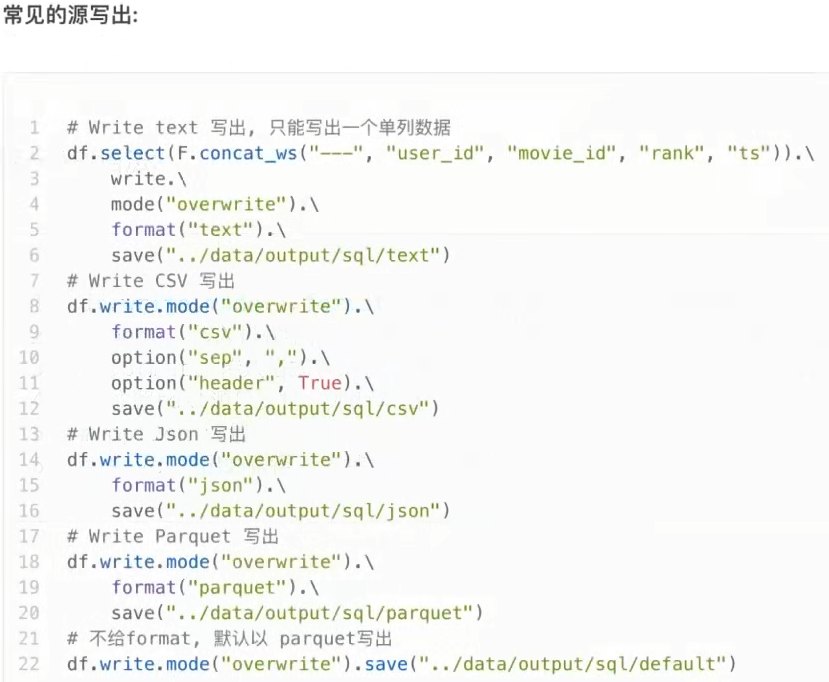
3.8 DataFrame数据写出

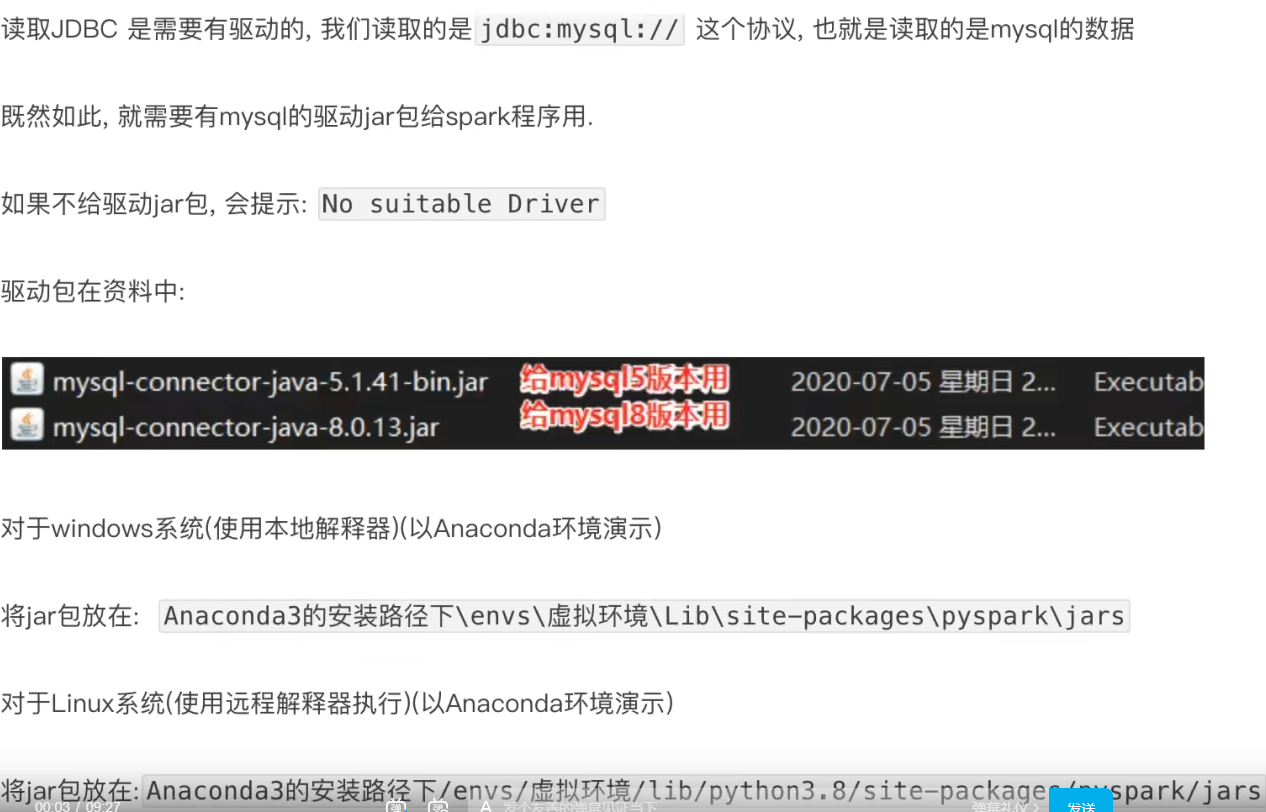
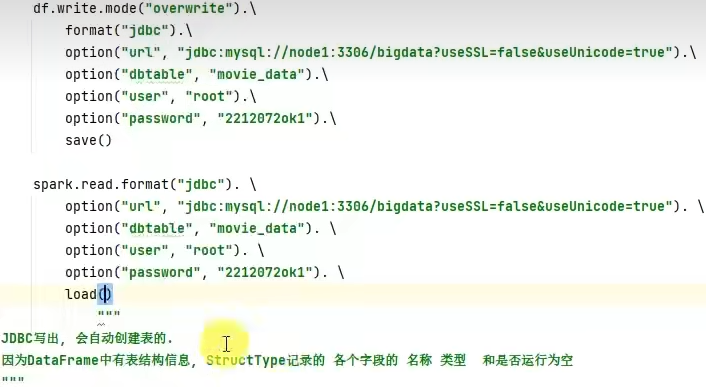
3.9 DataFrame通过JDBC读写数据库(MySQL示例)
3.10 第三章总结
- DataFrame在结构层面上由StructField组成列描述,由StructType构造表描述。在数据层面上,Column对象记录列数据,Row对象记录行数据。
- DataFrame可以从RDD转换、Pandas DF转换、读取文件、读取JDBC等方法构建
- spark.read.format()和df.write.format()是DataFrame读取和写出的统一化标准API
- SParkSQL默认在Shuffle阶段200个分区,可以修改参数获得最好性能
- dropDuplicates可以去重,dropna可以删除缺失值、fillna可以填充缺失值
- SparkSQL支持JDBC读写,可用标准API对数据库进行读写操作
第四章:SparkSQL函数定义
4.1 SparkSQL定义UDF函数


sparksession.udf.register()

pyspark.sql.functions.udf

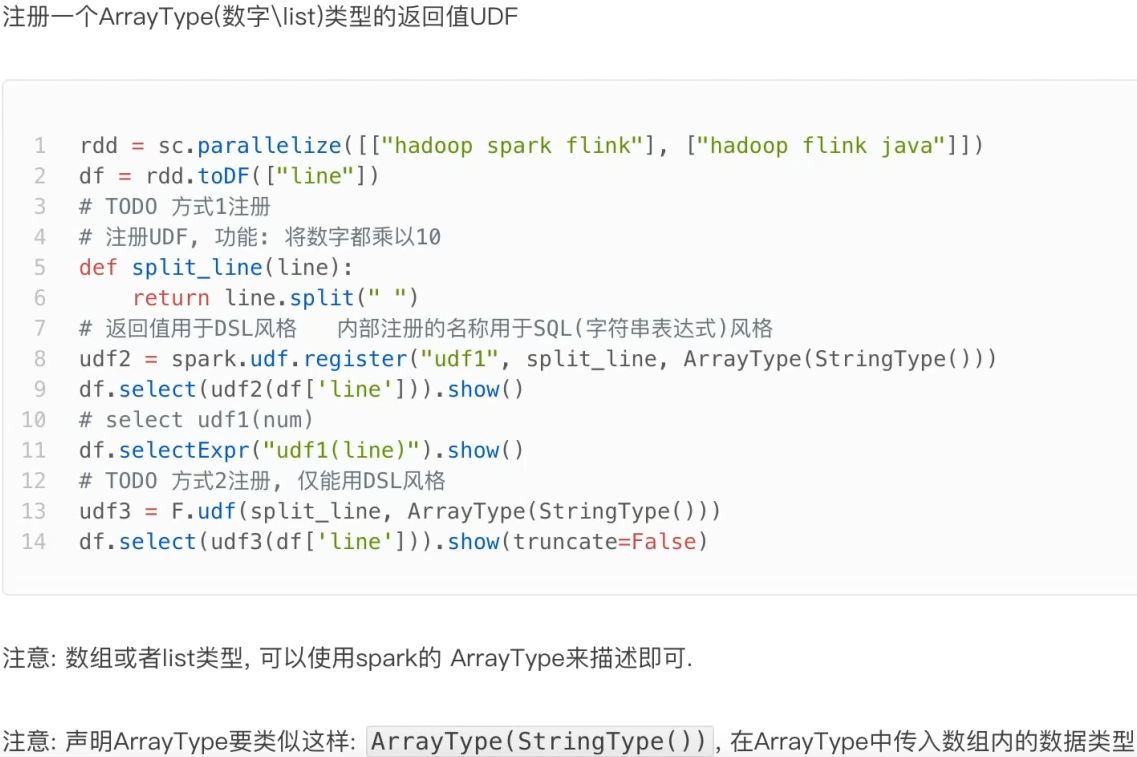
注册一个ArraryType返回类型的UDF
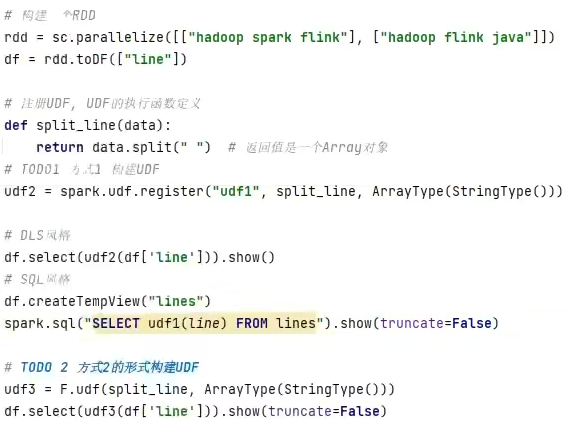
注册一个字典返回类型的UDF
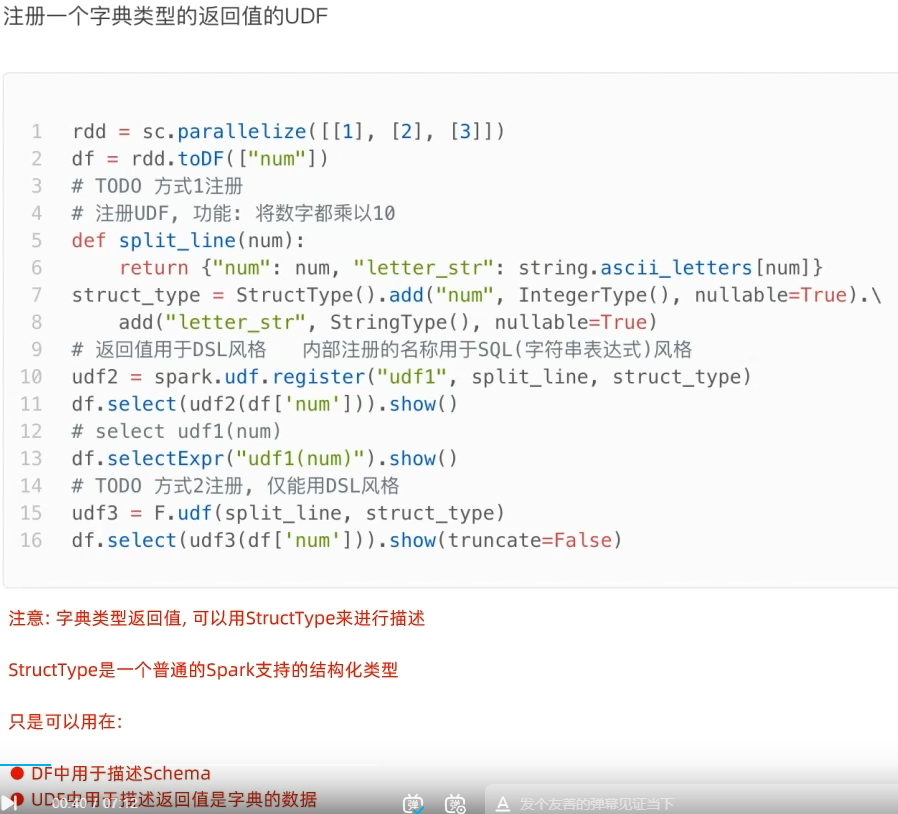
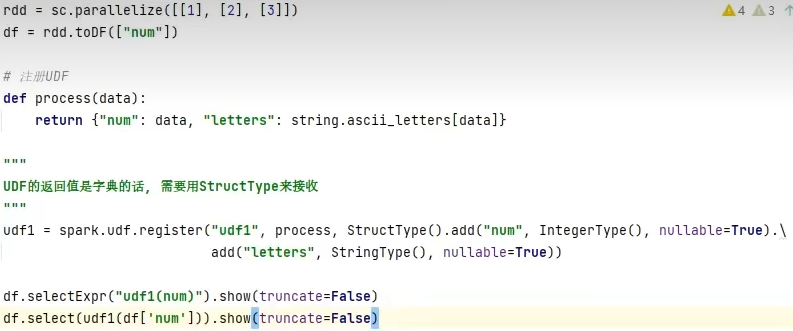
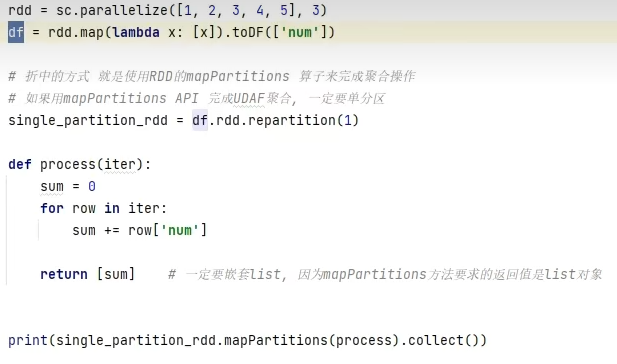
拓展-通过RDD代码模拟UDAF效果
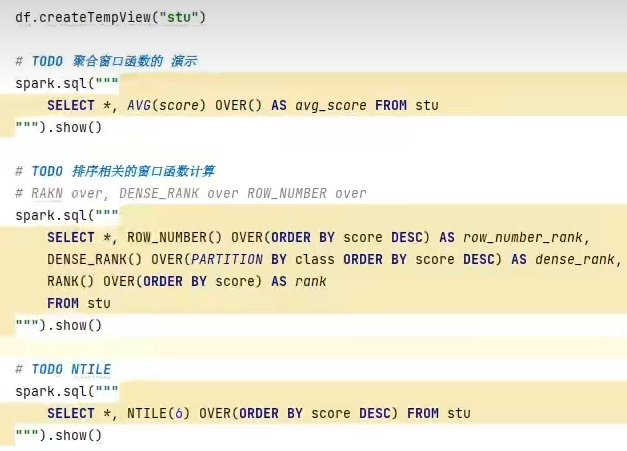
4.2 SparkSQL使用窗口函数

4.3 第四章总结
- SparkSQL支持UDF和UDAF定义,但在Python中,暂时只能定义UDF
UDAF可以通过rdd的mapPartitions算子模拟实现
UDTF可以通过返回array或者dict类型来模拟实现
- UDF定义支持2种方式,1:使用SparkSession对象构建。2:使用functions包种提供的UDF API构建。要注意,方式1可用DSL和SQL风格,方式2仅可用DSL风格
- SparkSQL支持窗口函数使用,常用SQL中的窗口函数均支持,如聚合窗口\排序窗口\NTILE分组窗口等
第五章:SparkSQL的运行流程
5.1 SparkRDD的执行流程回顾
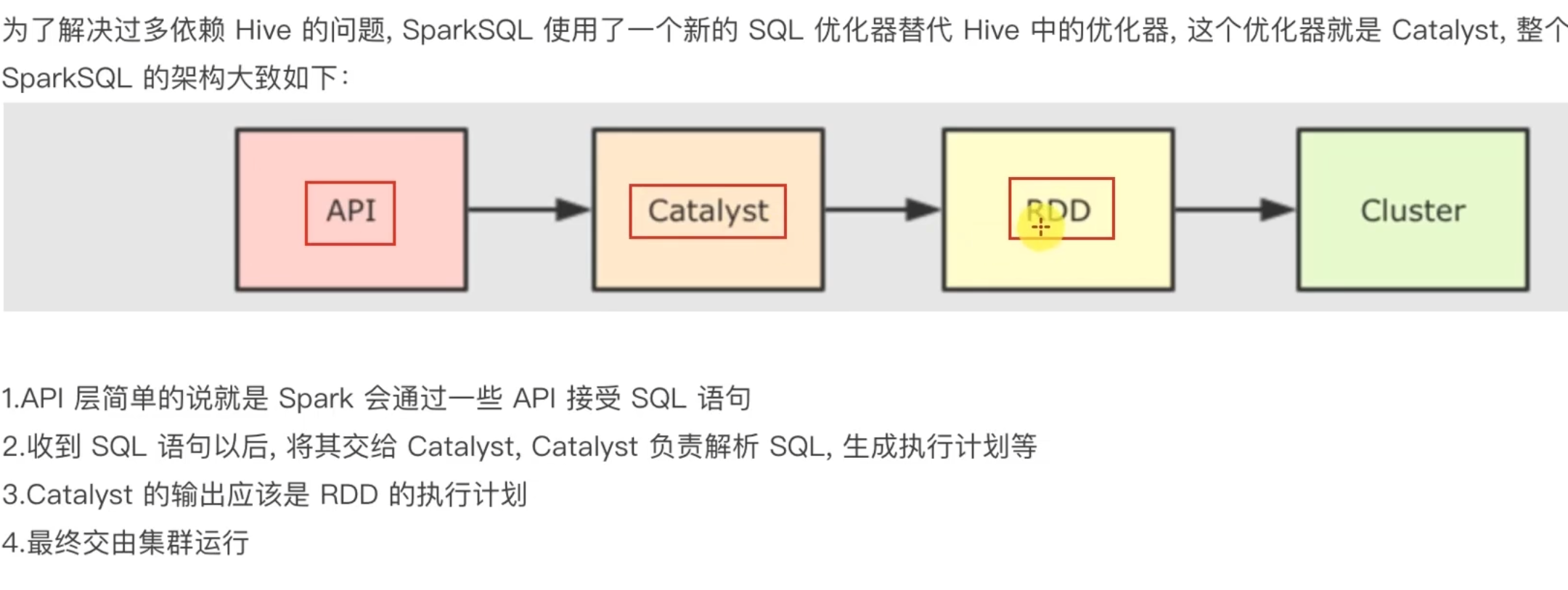
5.2 SparkSQL的自动优化

5.3 Catalyst优化器
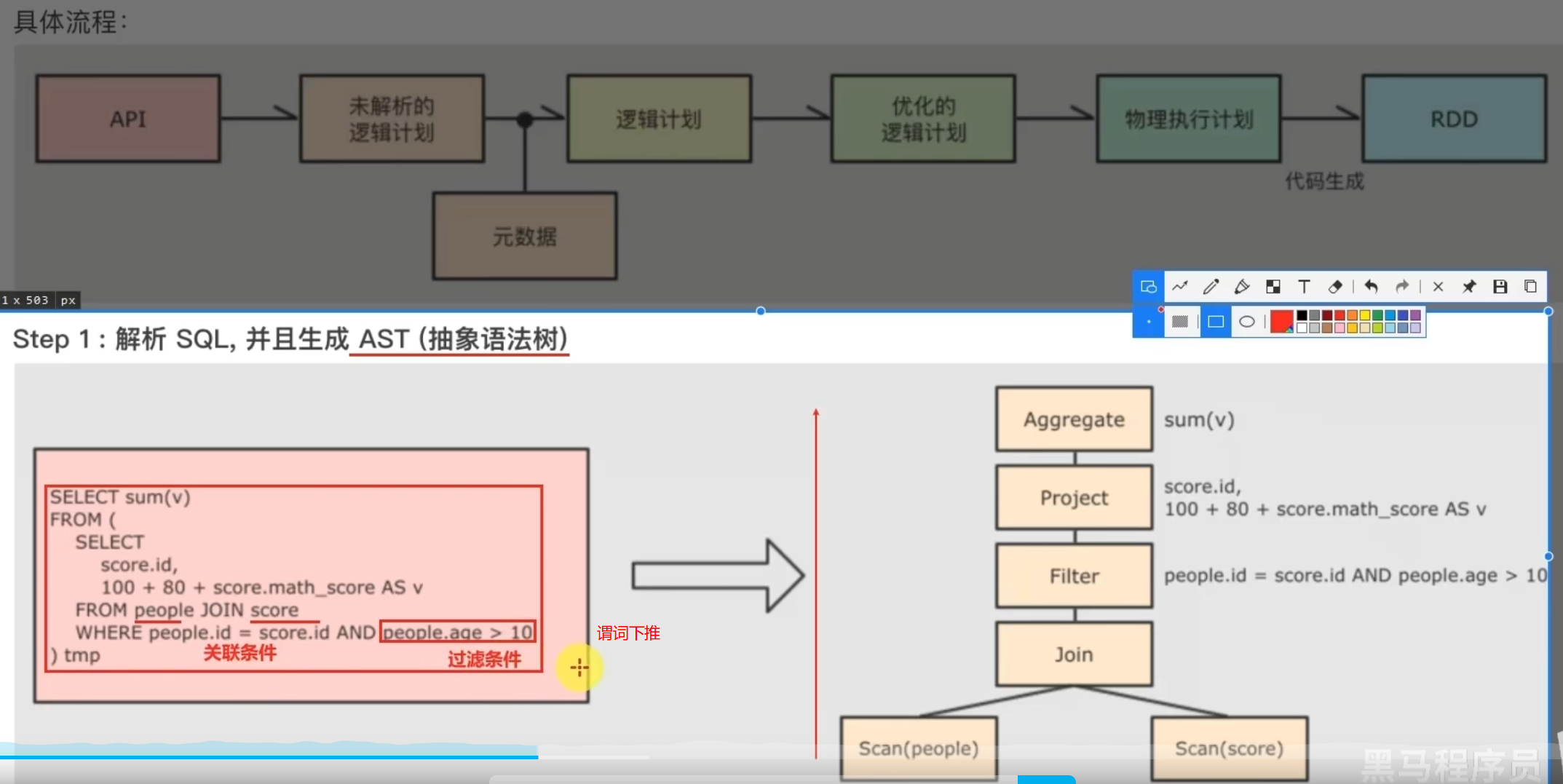

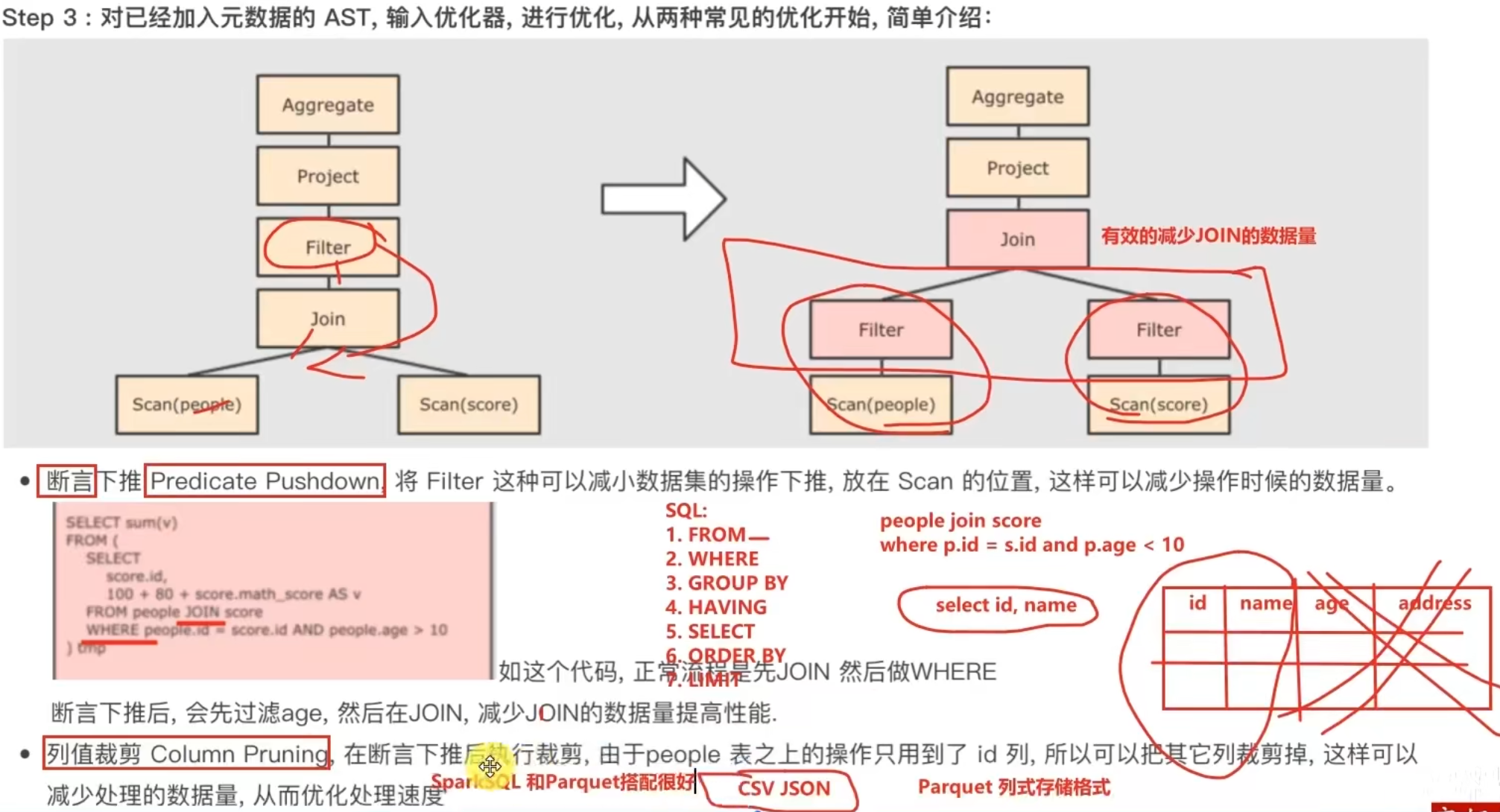
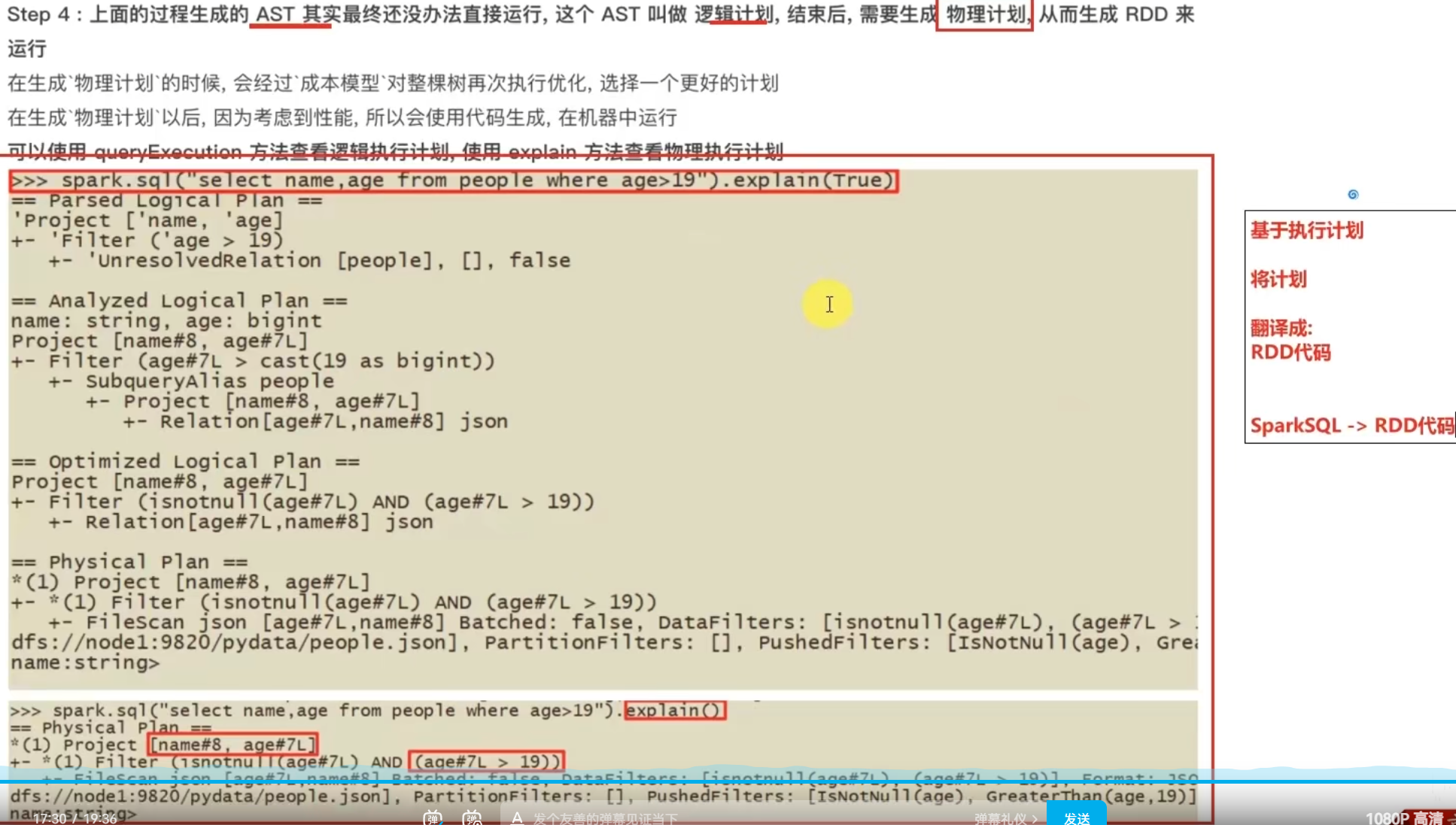

5.4 SparkSQL的执行流程
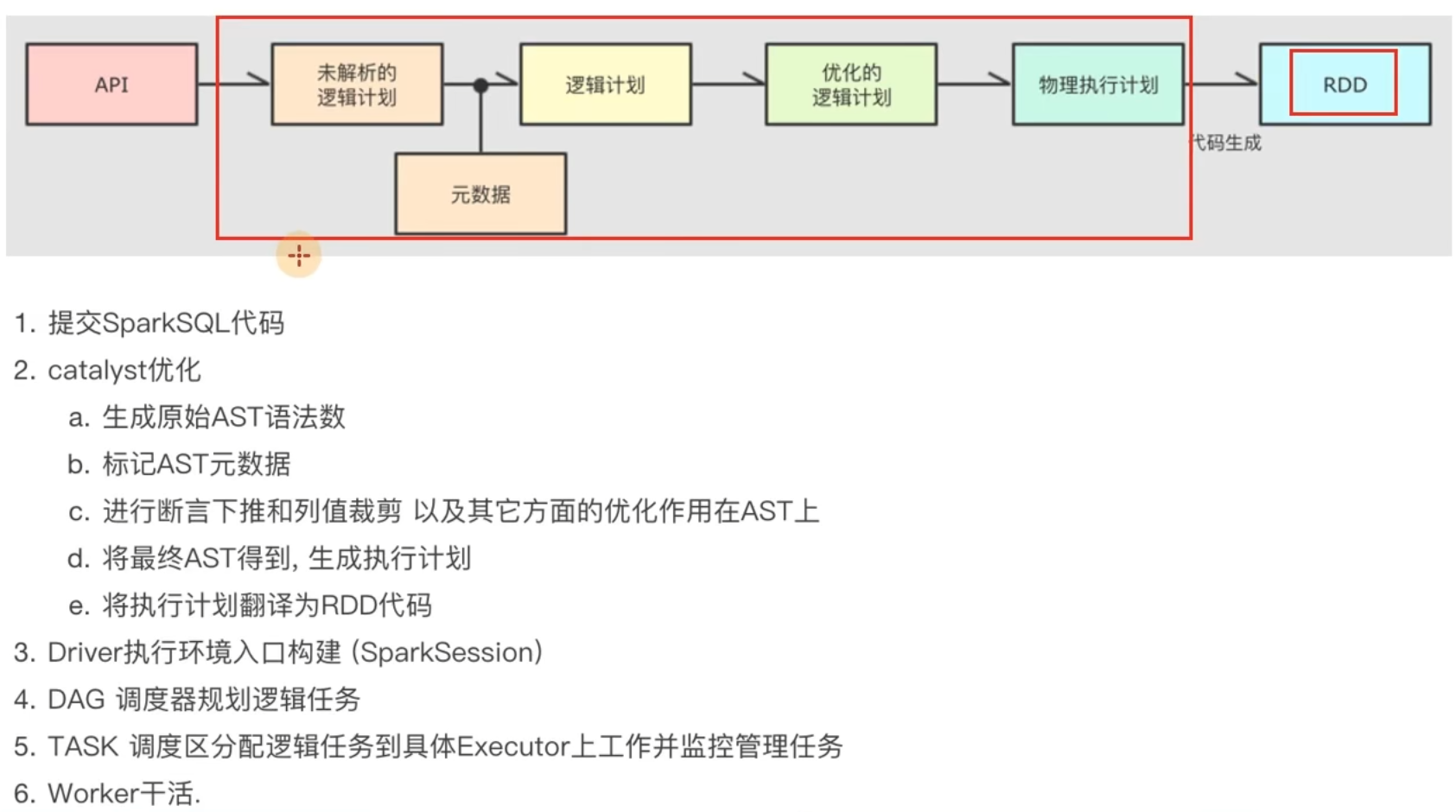
5.5 第五章总结

第六章:Spark On Hive
6.1 原理
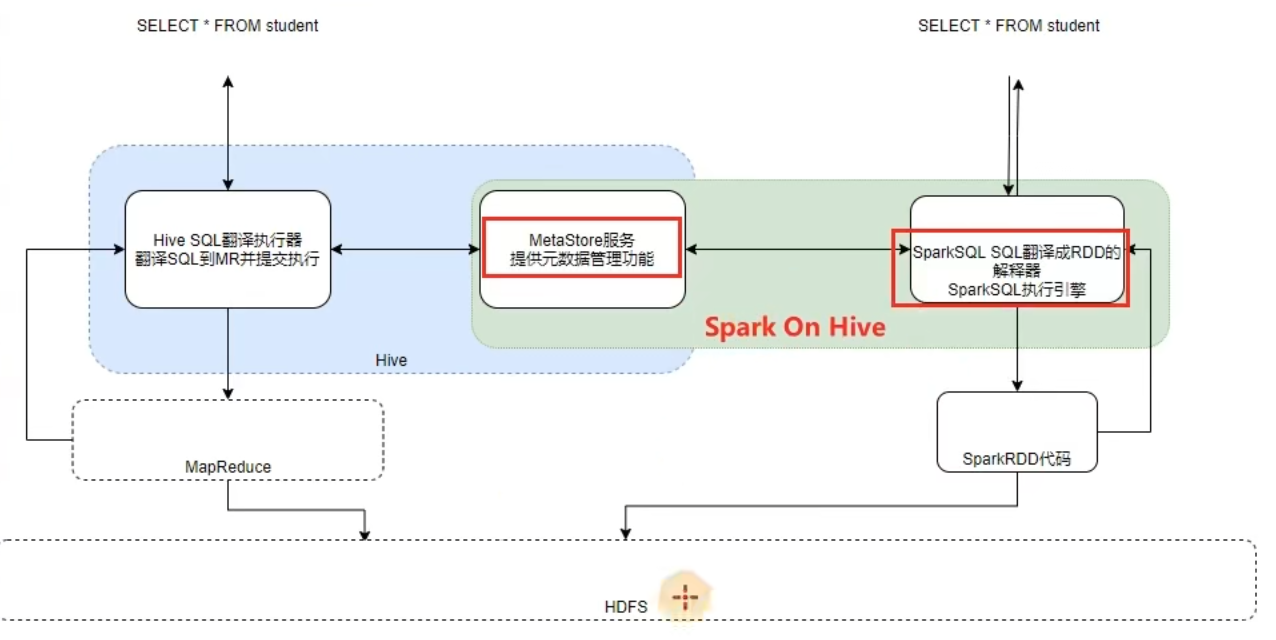


6.2 配置
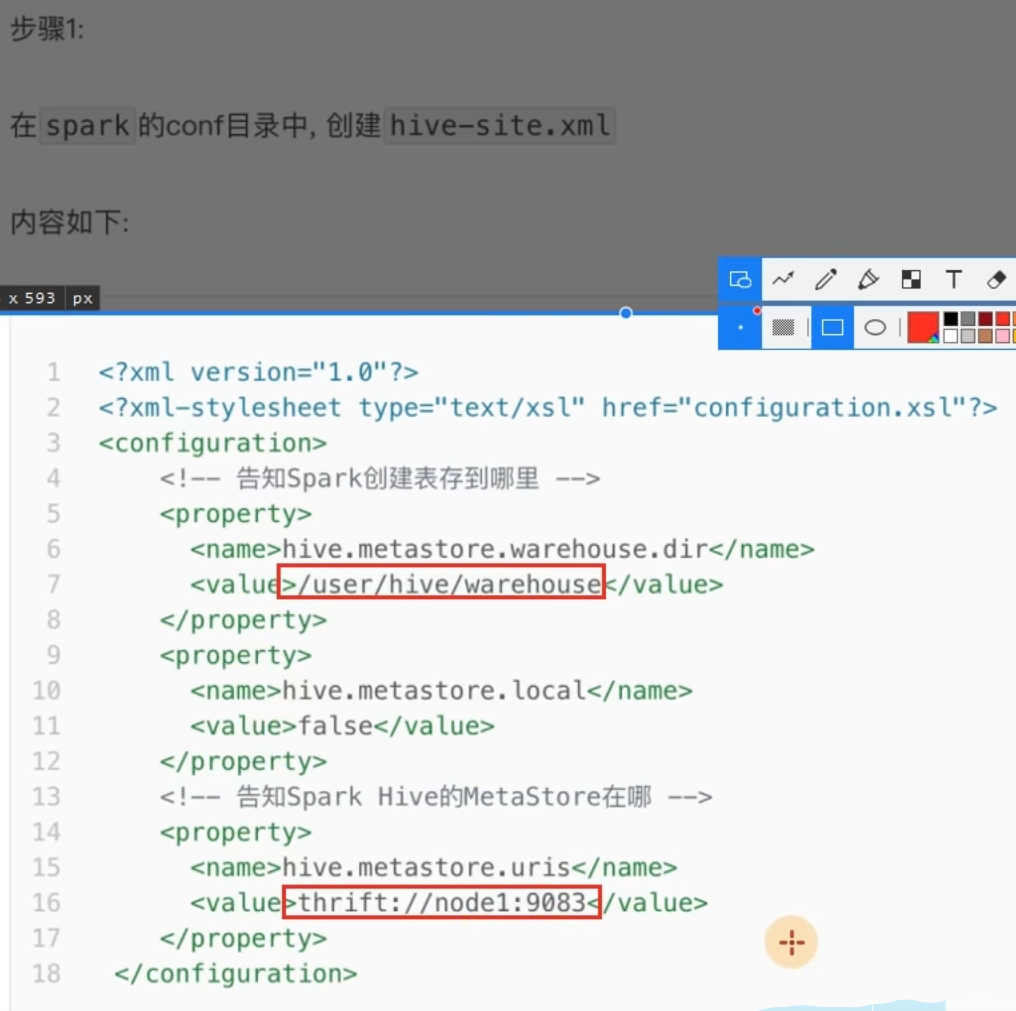

nohup /export/server/hive/bin/hive --service metastore 2>&1 >> /export/server/hive/metastore.log &
PS:2>&1的含义:将标准错误输出重定向到标准输出。
https://blog.csdn.net/icanlove/article/details/38018169
6.3 在代码中集成
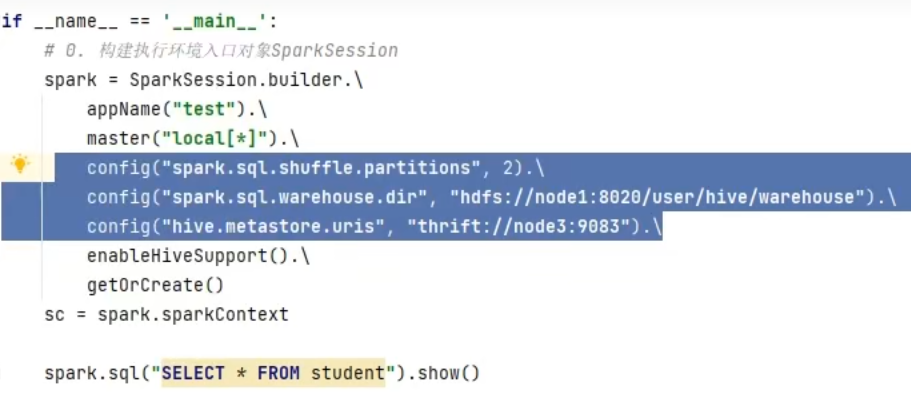
6.4 第六章总结

第七章:分布式SQL执行引擎
7.1 概念
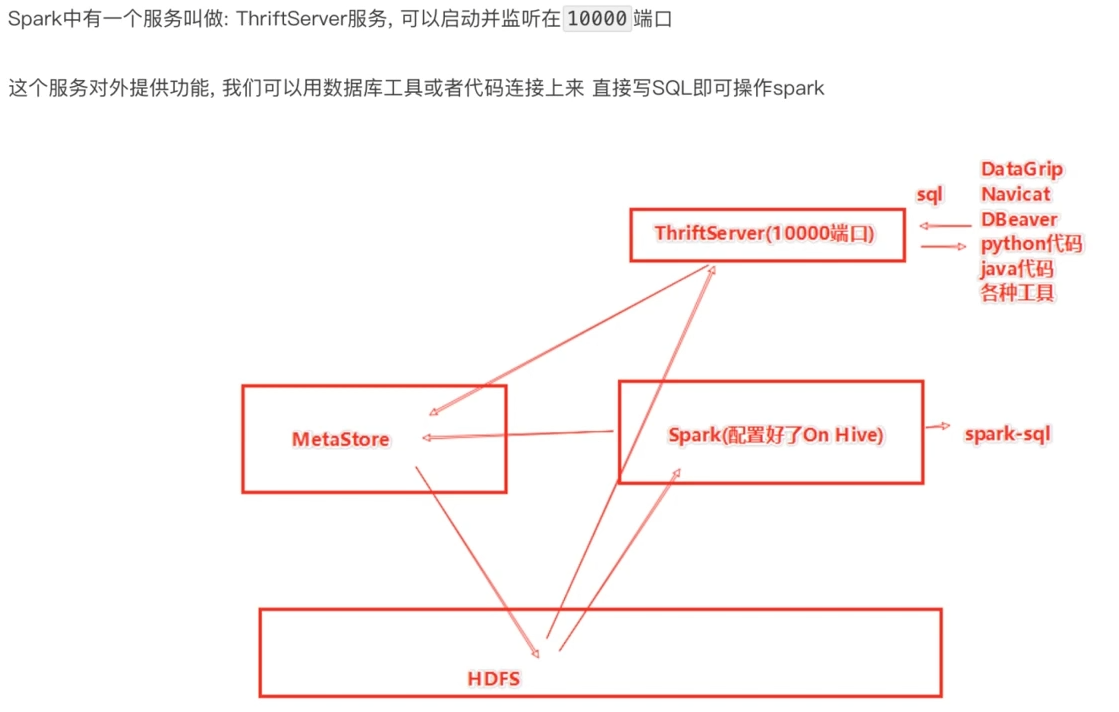
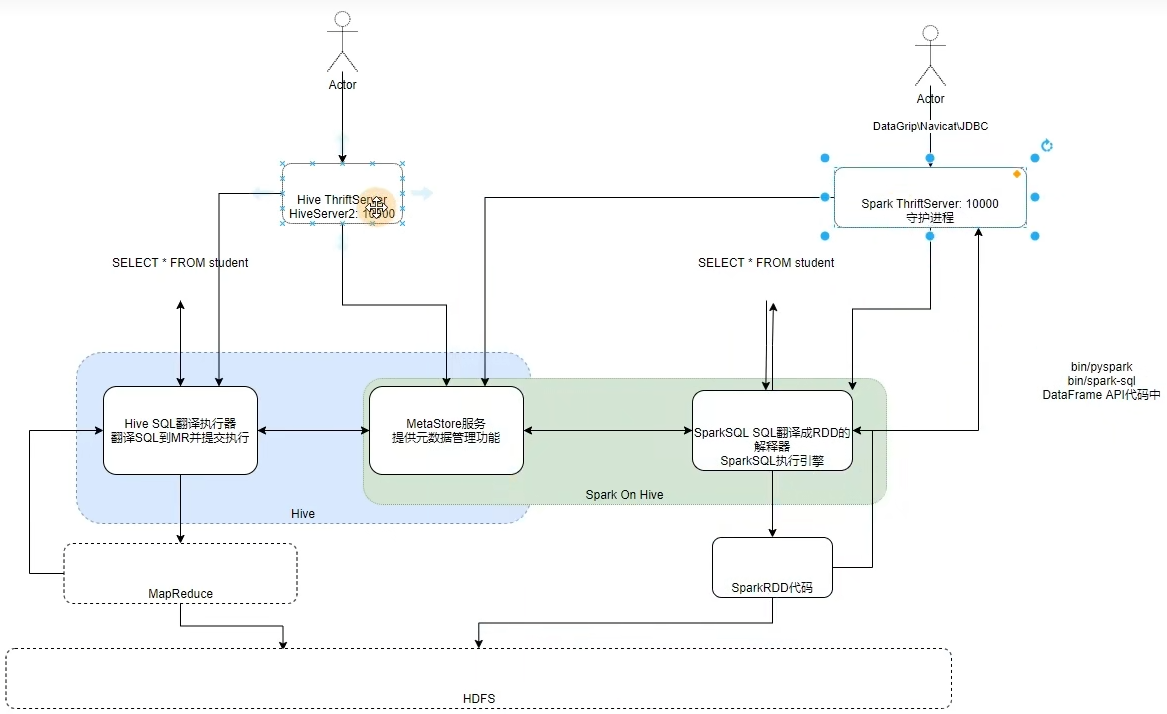
7.2 客户端工具连接
配置

数据库工具连接ThriftServer
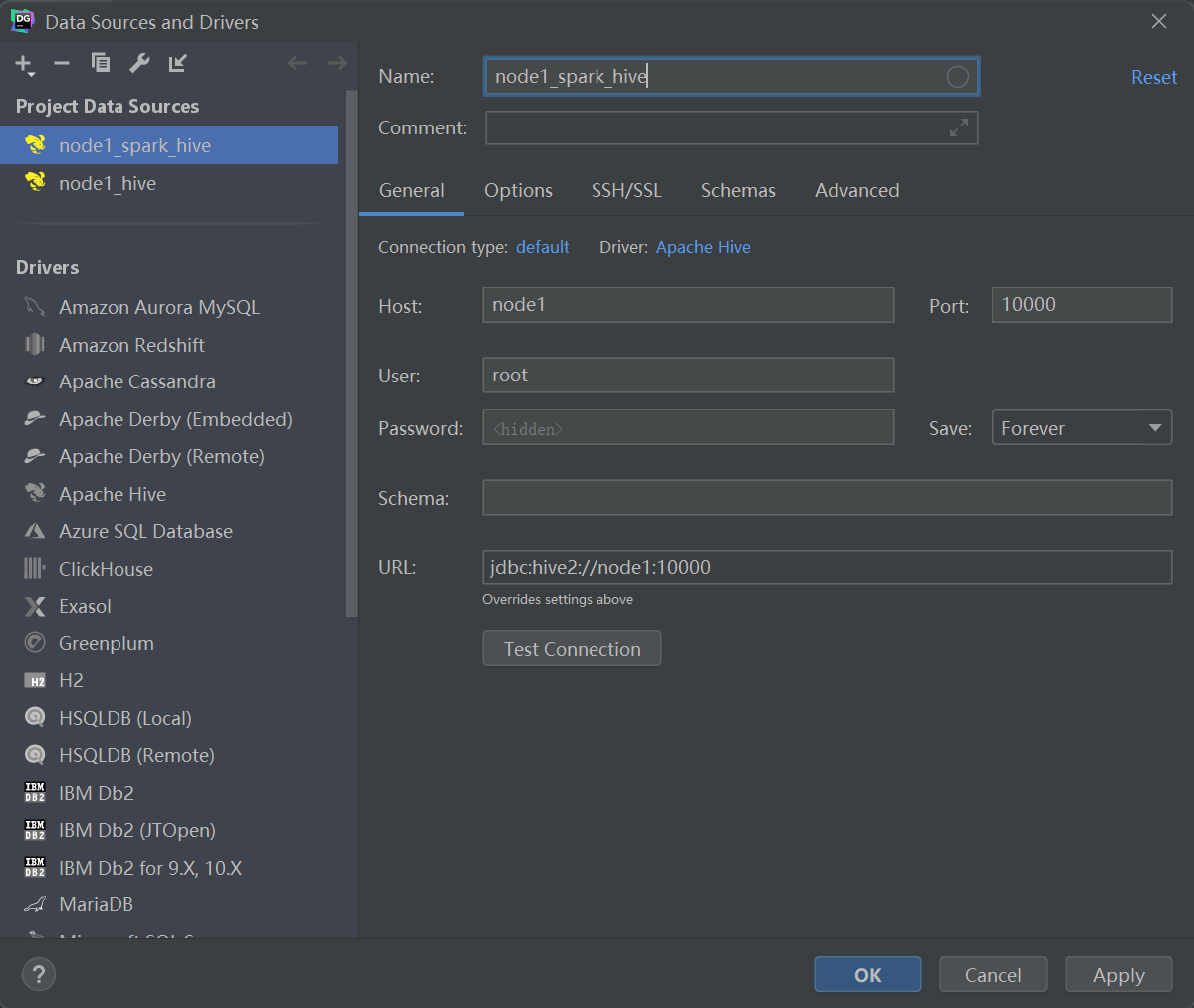
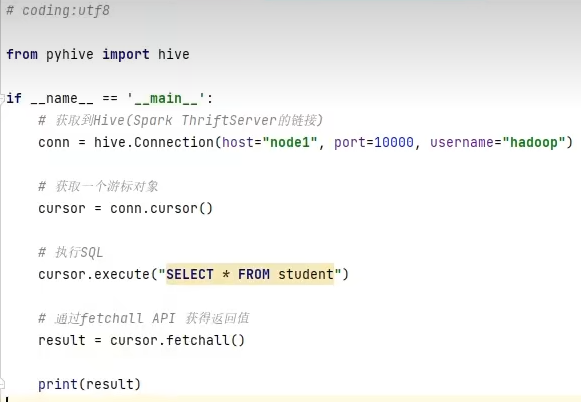
7.3 代码JDBC连接
Pycharm软件连接ThriftServer
通过yum命令安装依赖
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel libffi-devel gcc make gcc-c++ python-devel cyrus-sasl-devel cyrus-sasl-devel cyrus-sasl-plain cyrus-sasl-gssapi -y
切换到pyspark虚拟环境,通过pip命令安装
pip install pyhive pymysql sasl thrift thrift_sasl
7.4 第七章总结

4.Spark综合案例
需求分析
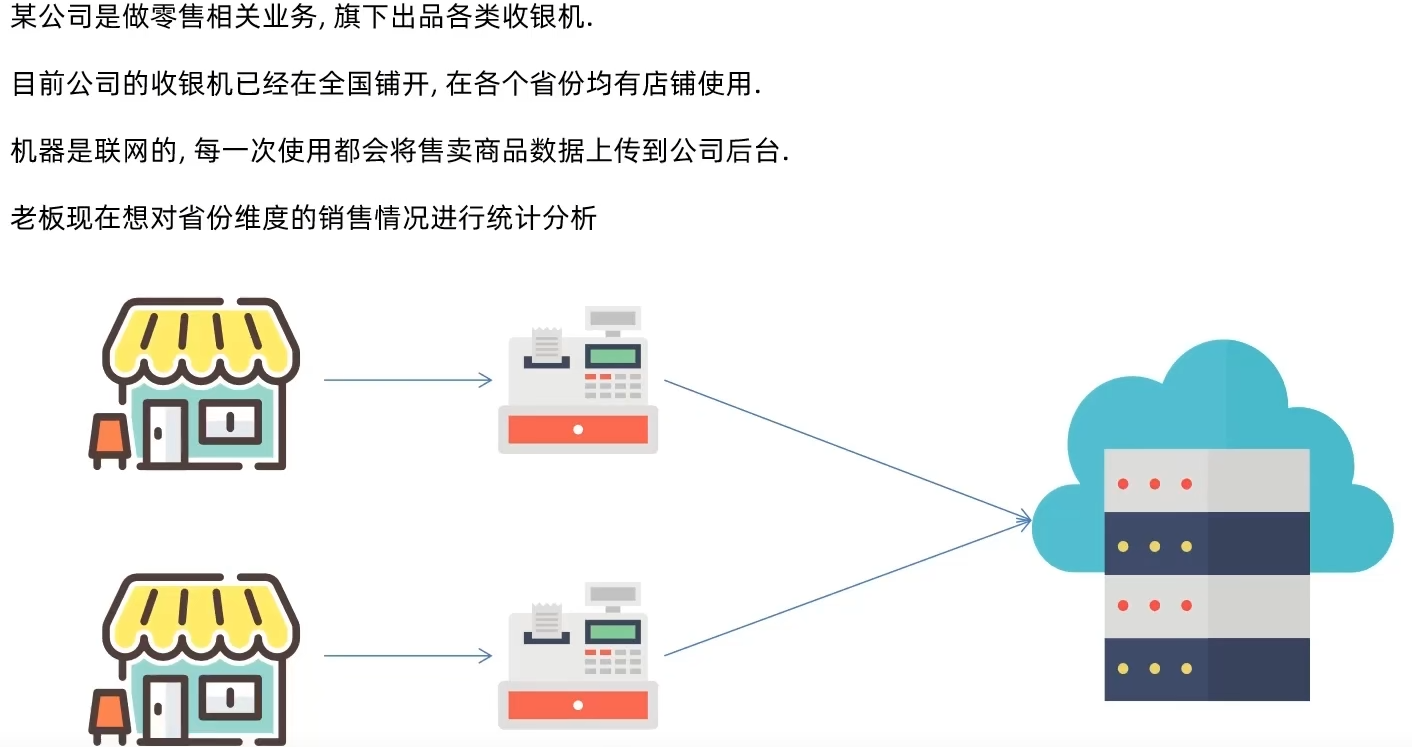


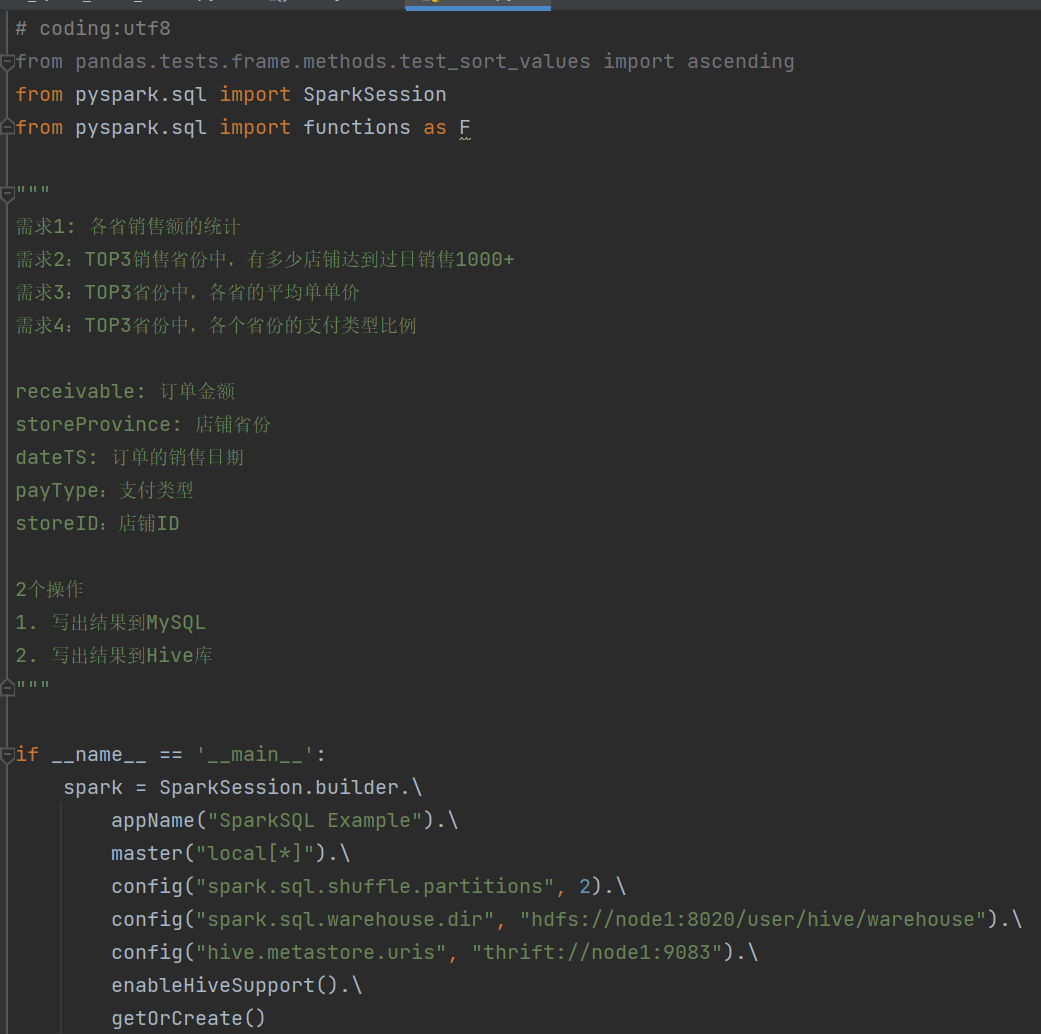
需求1:
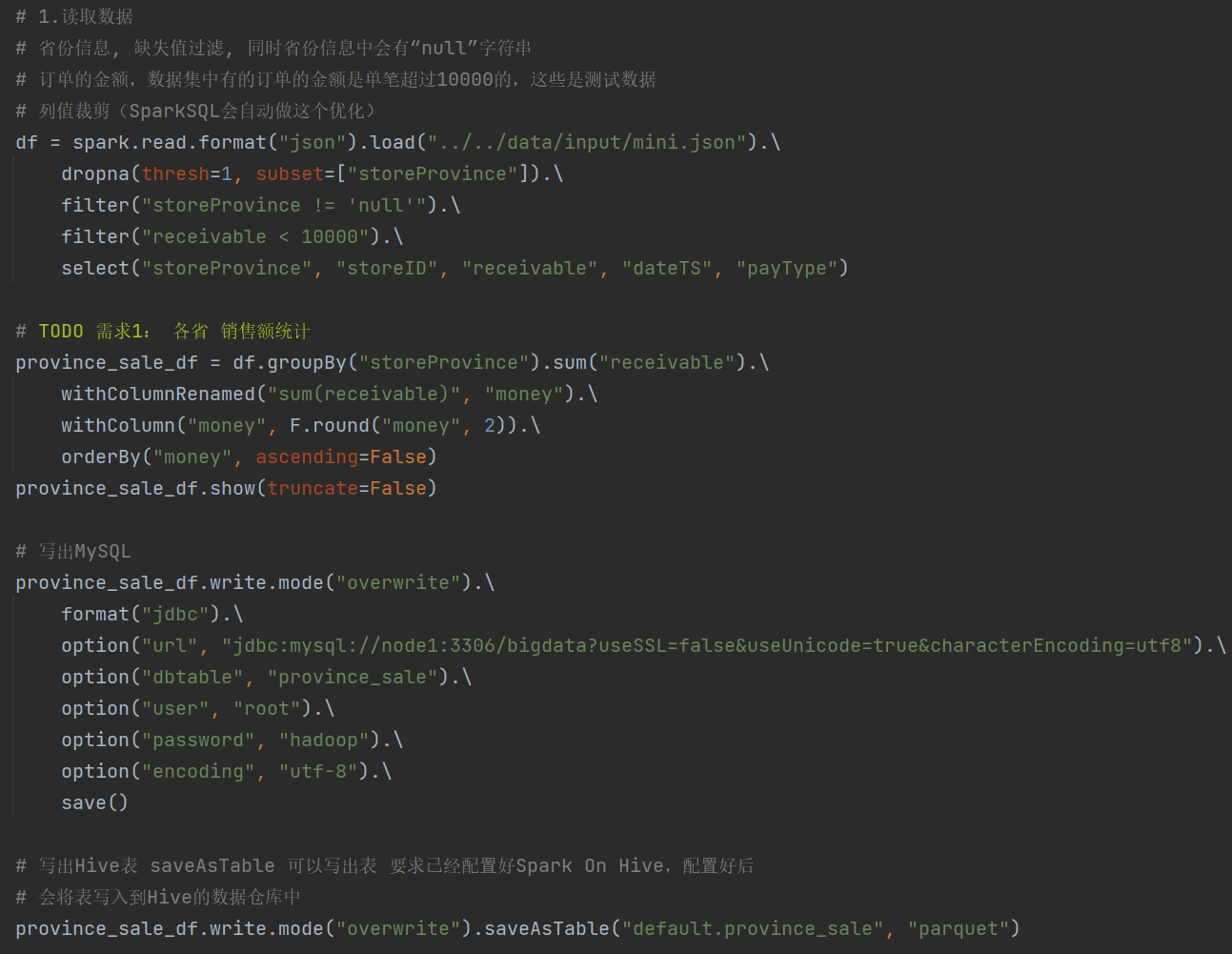
PS:
遇到问题:

解决方案:https://blog.csdn.net/debimeng/article/details/113101894
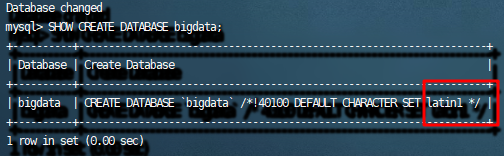
# 1.查看数据库和表的编码
SHOW CREATE DATABASE mydb;
# 2.修改数据库和表的编码
ALTER DATABASE mydb DEFAULT CHARACTER SET utf8;
3.检查数据库和表的编码
SHOW CREATE DATABASE mydb;
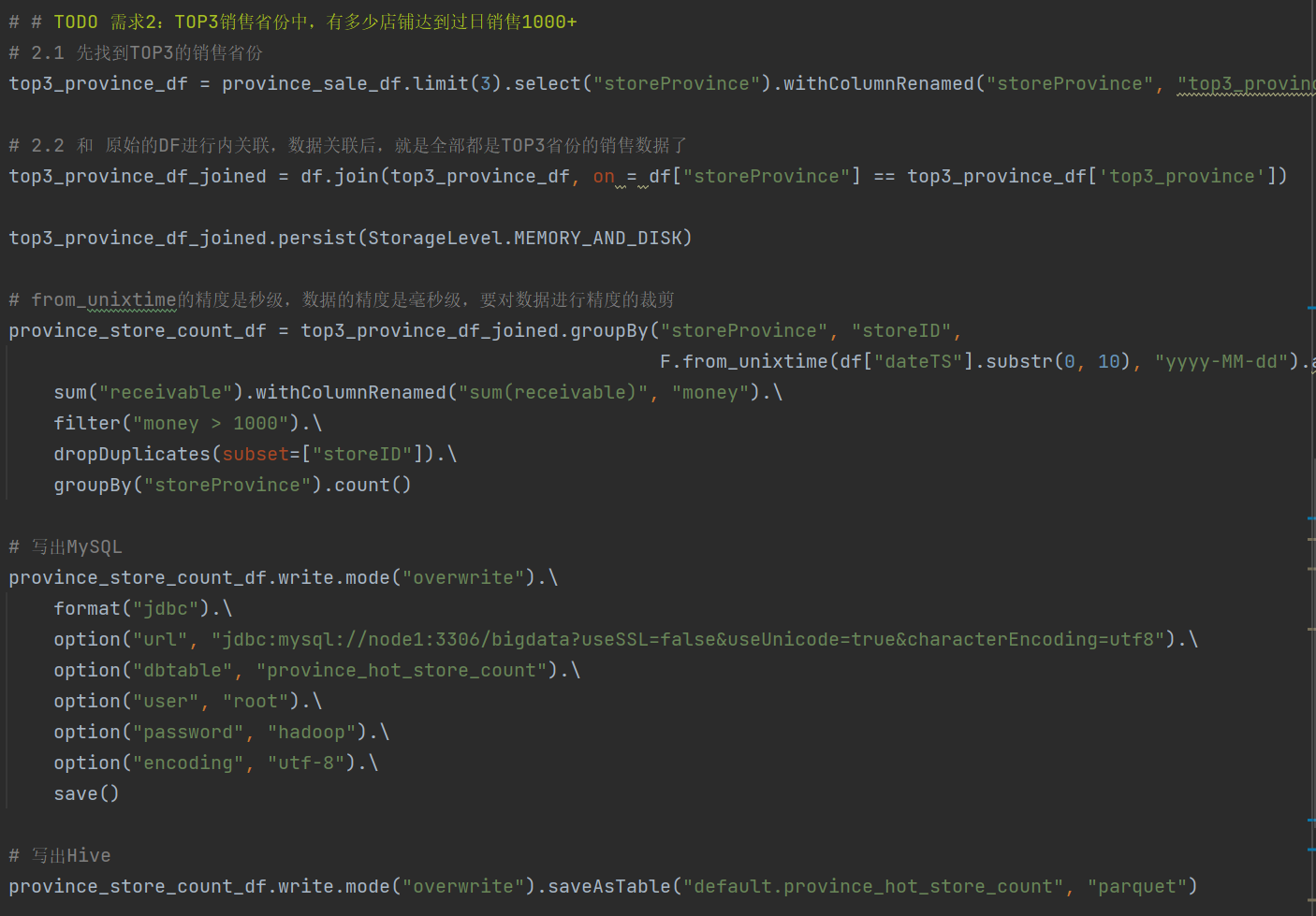
需求2:
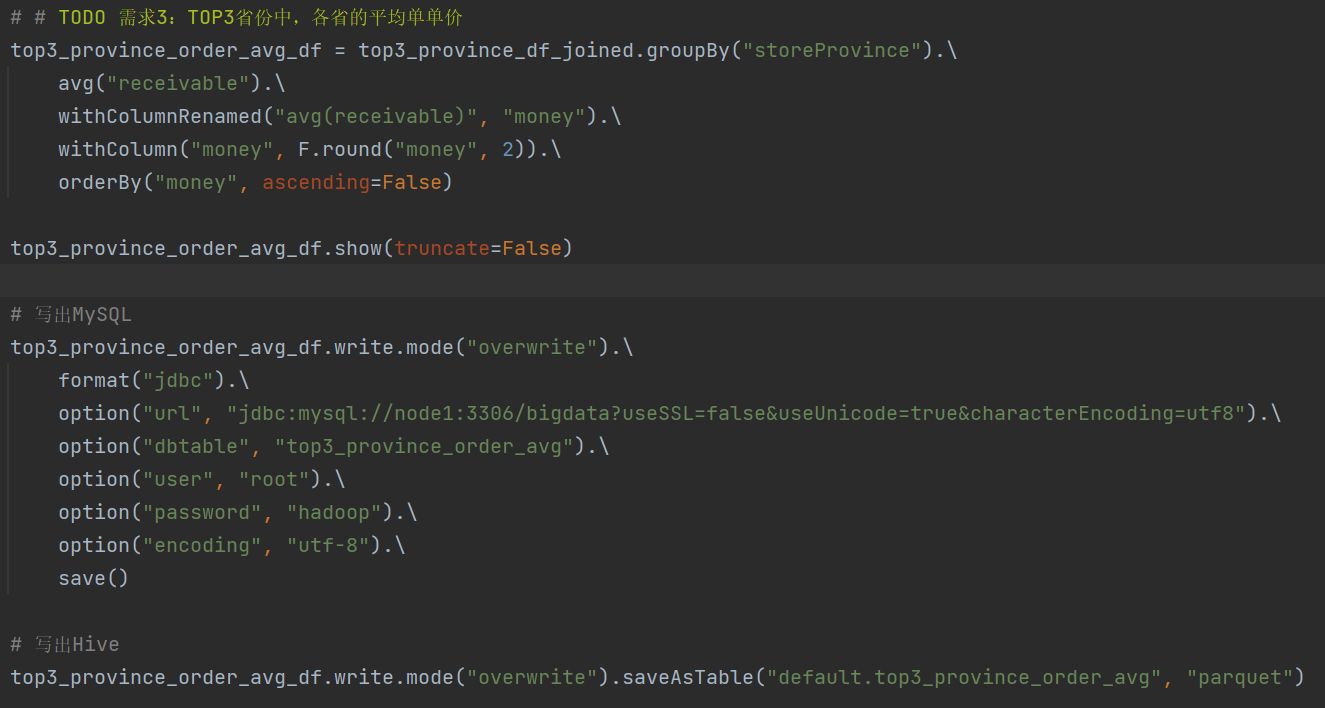
需求3:
需求4:
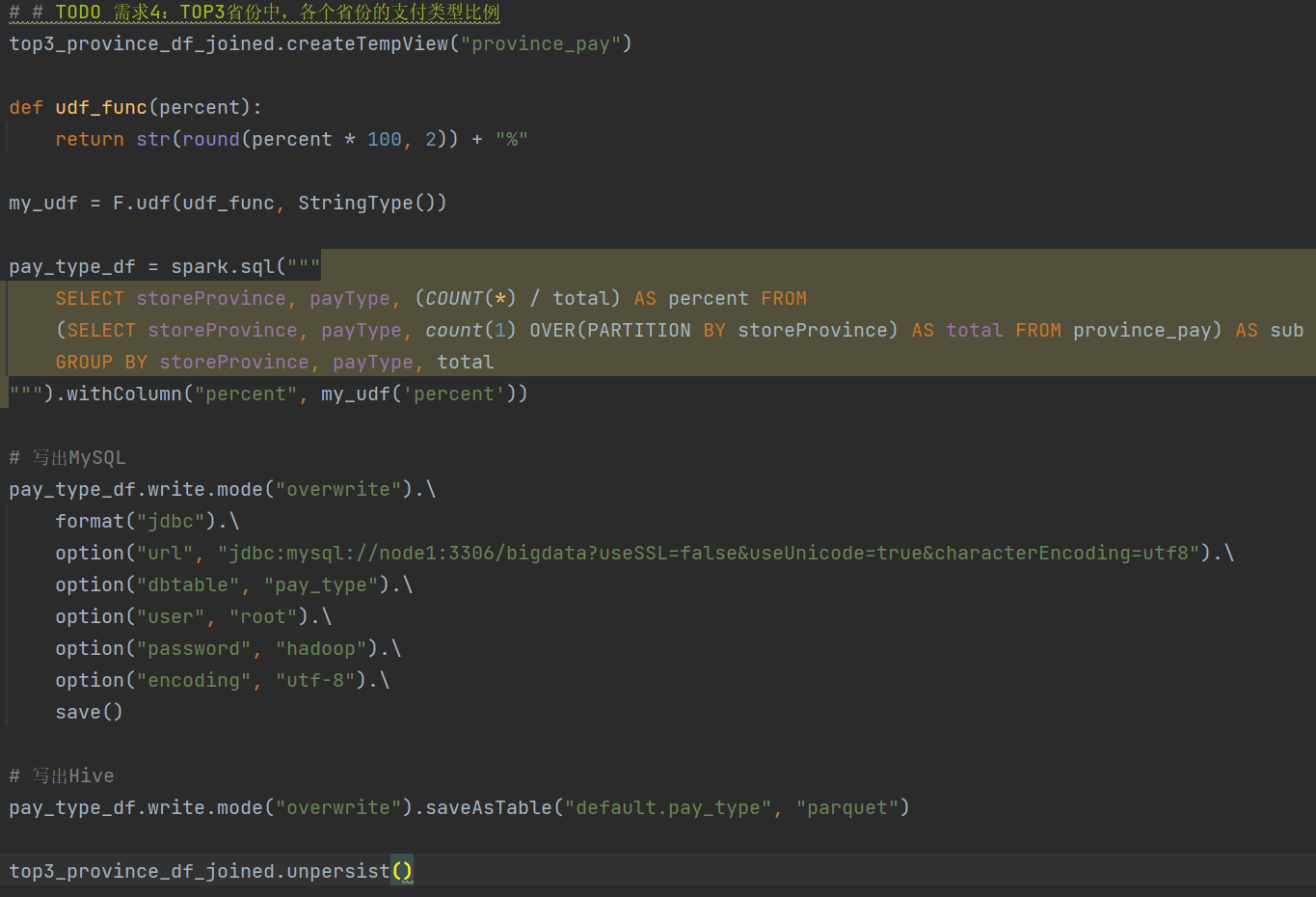
5.Spark新特性+核心回顾
学习目标
- 掌握Spark的Shuffle流程
- 掌握Spark3.0新特性
- 理解并复习Spark的核心概念
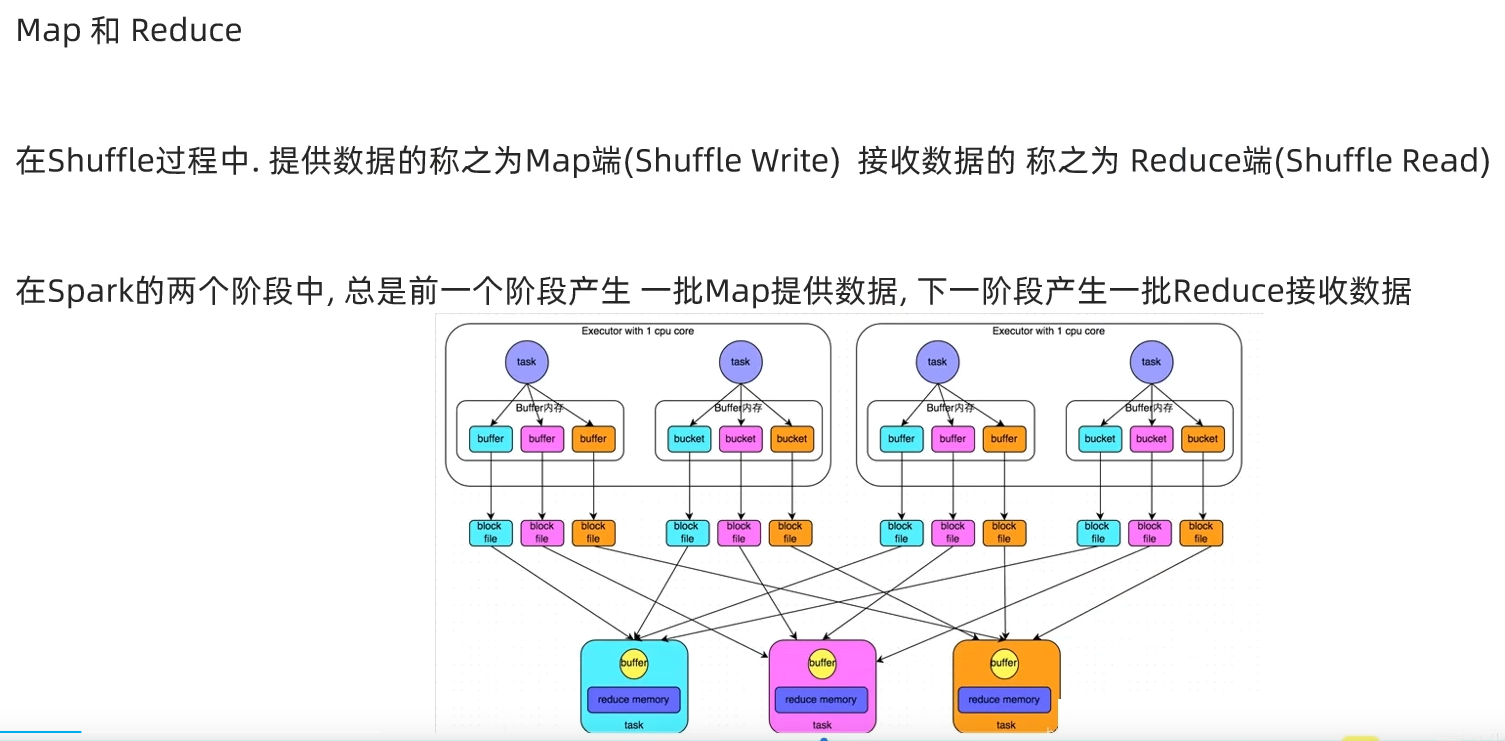
第一章:Spark Shuffle
1.1 Spark Shuffle
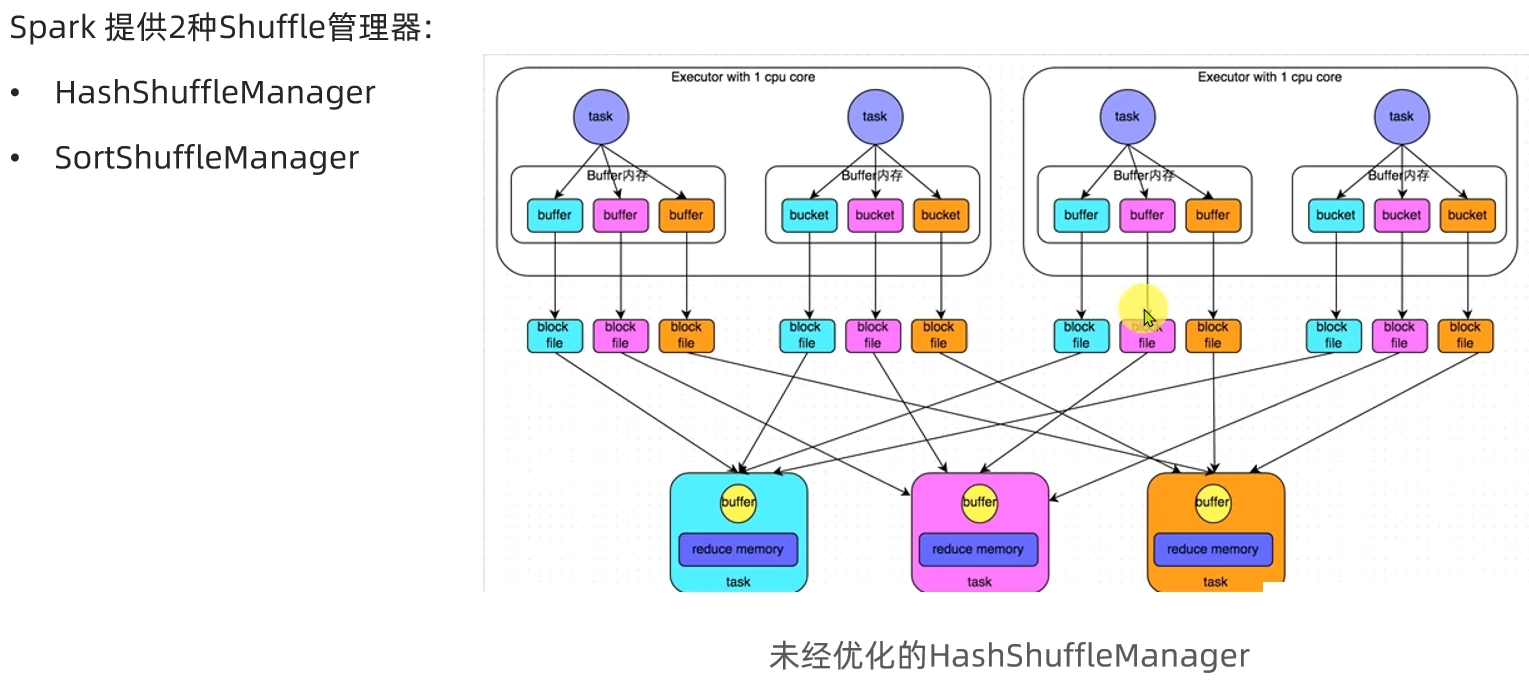
1.2 HashShuffleManager
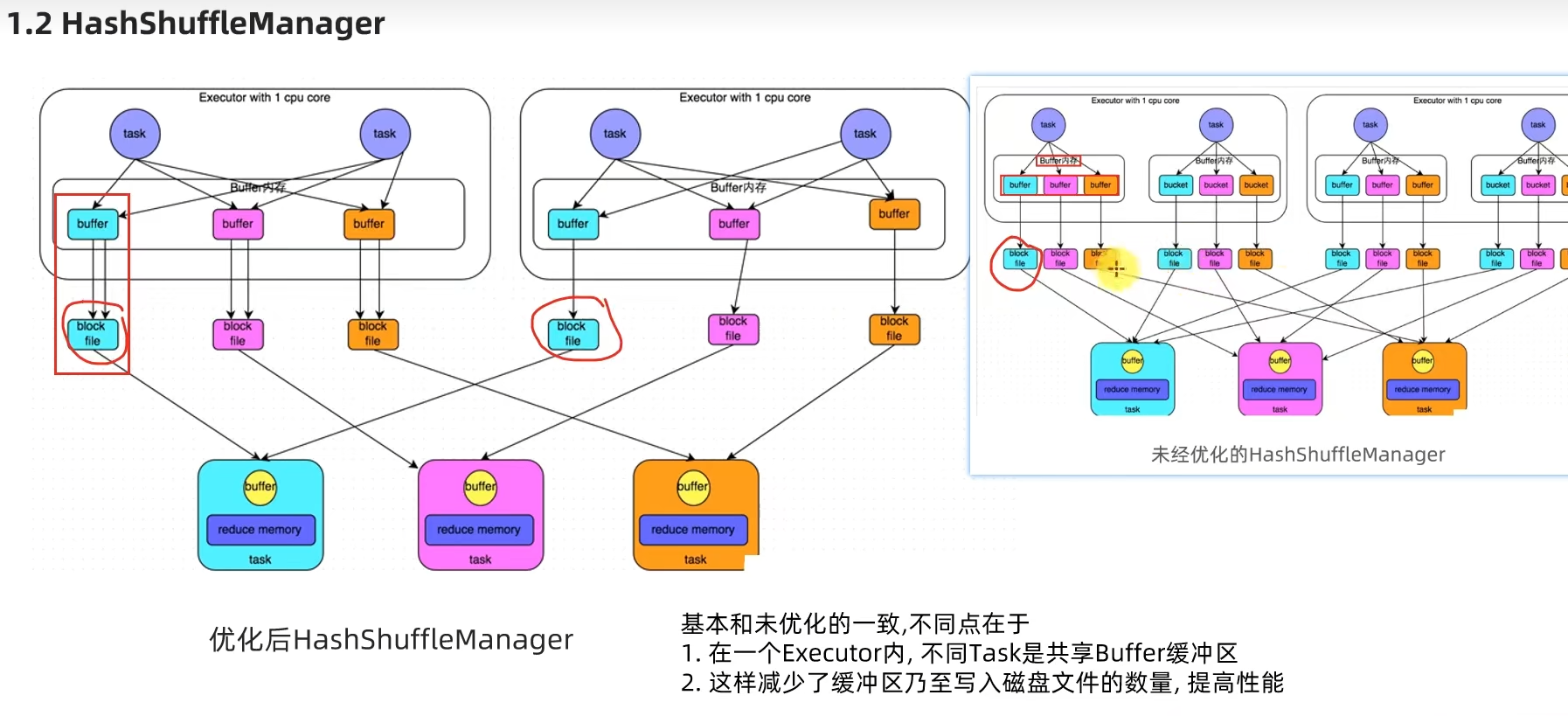
1.3 SortShuffleManager
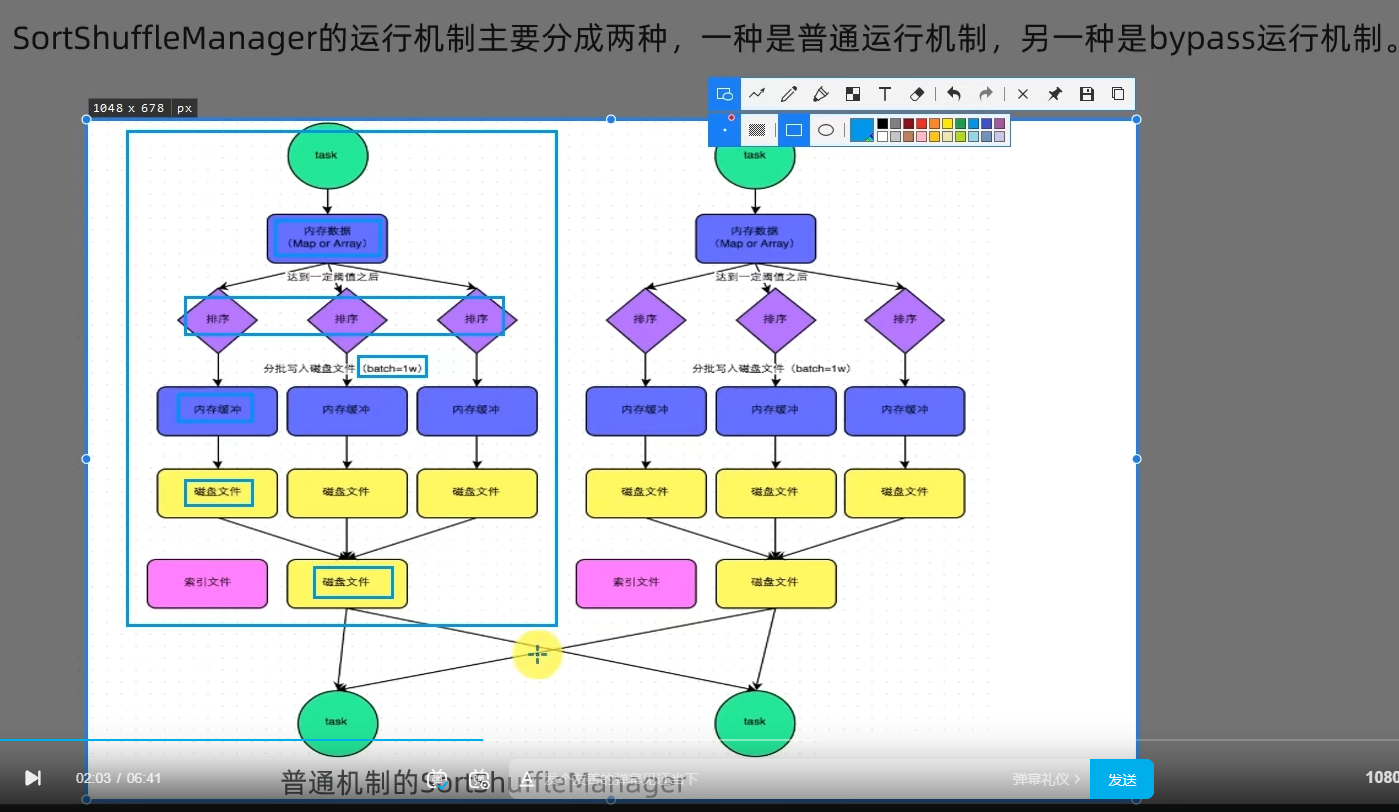

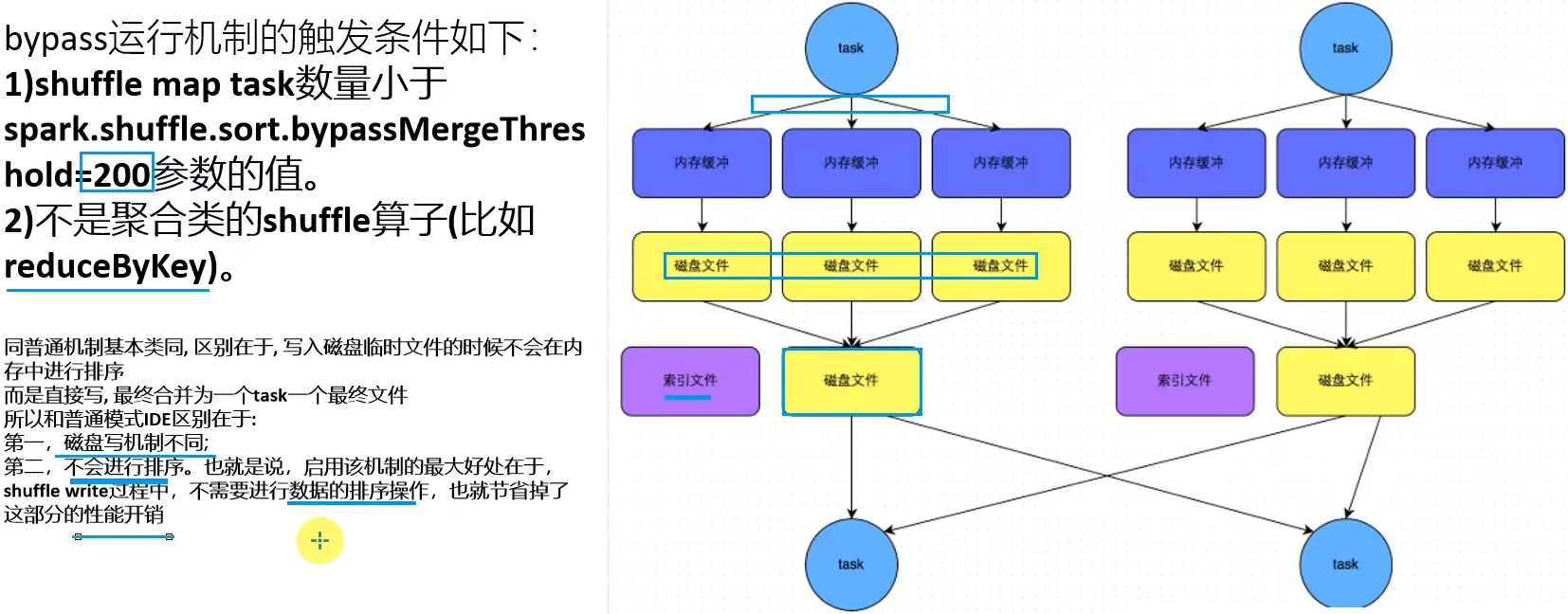
1.4 第一章总结

第二章:Spark3.0新特性
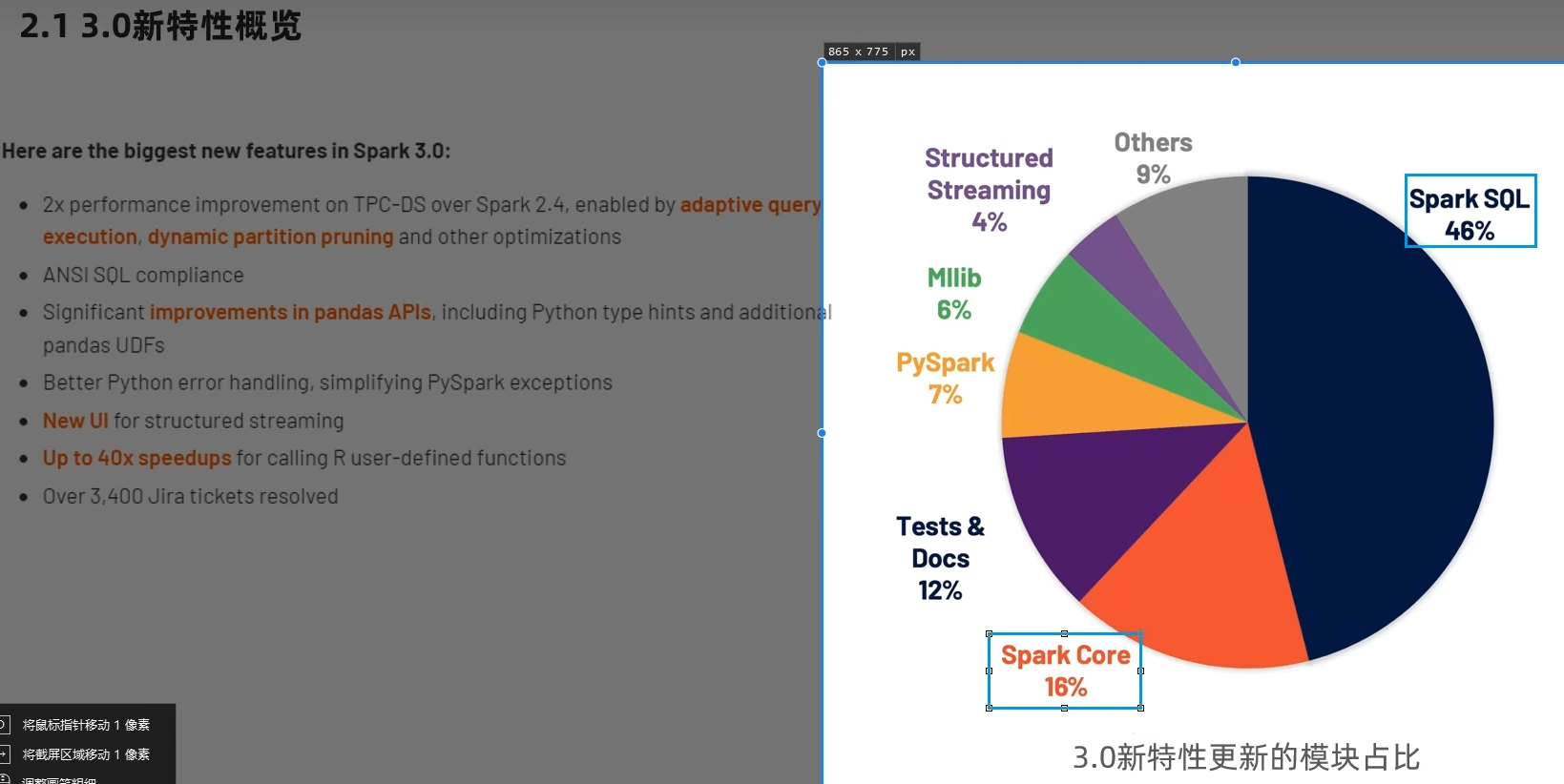
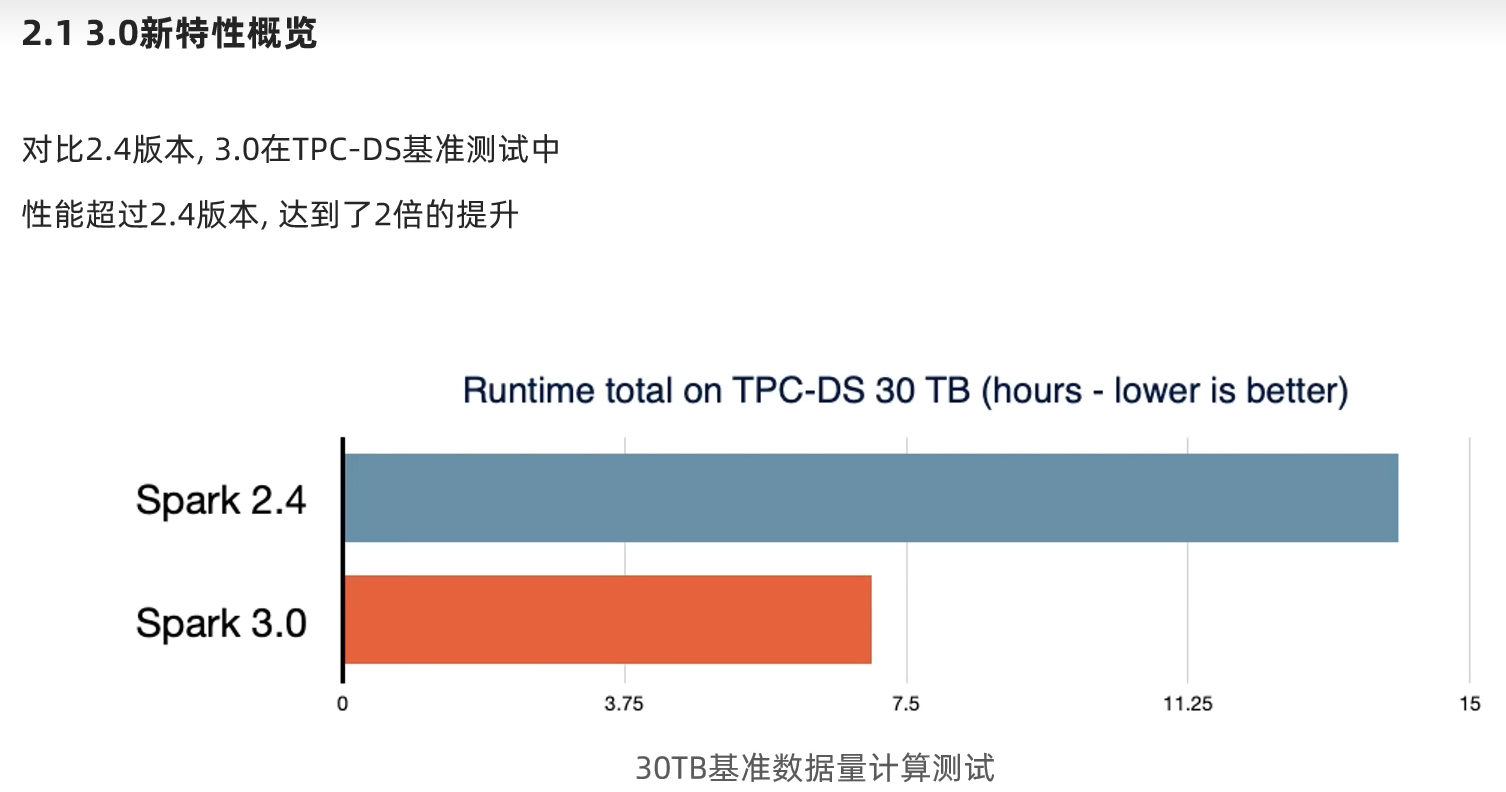
2.2 Adaptive Query Execution自适应查询(SparkSQL)

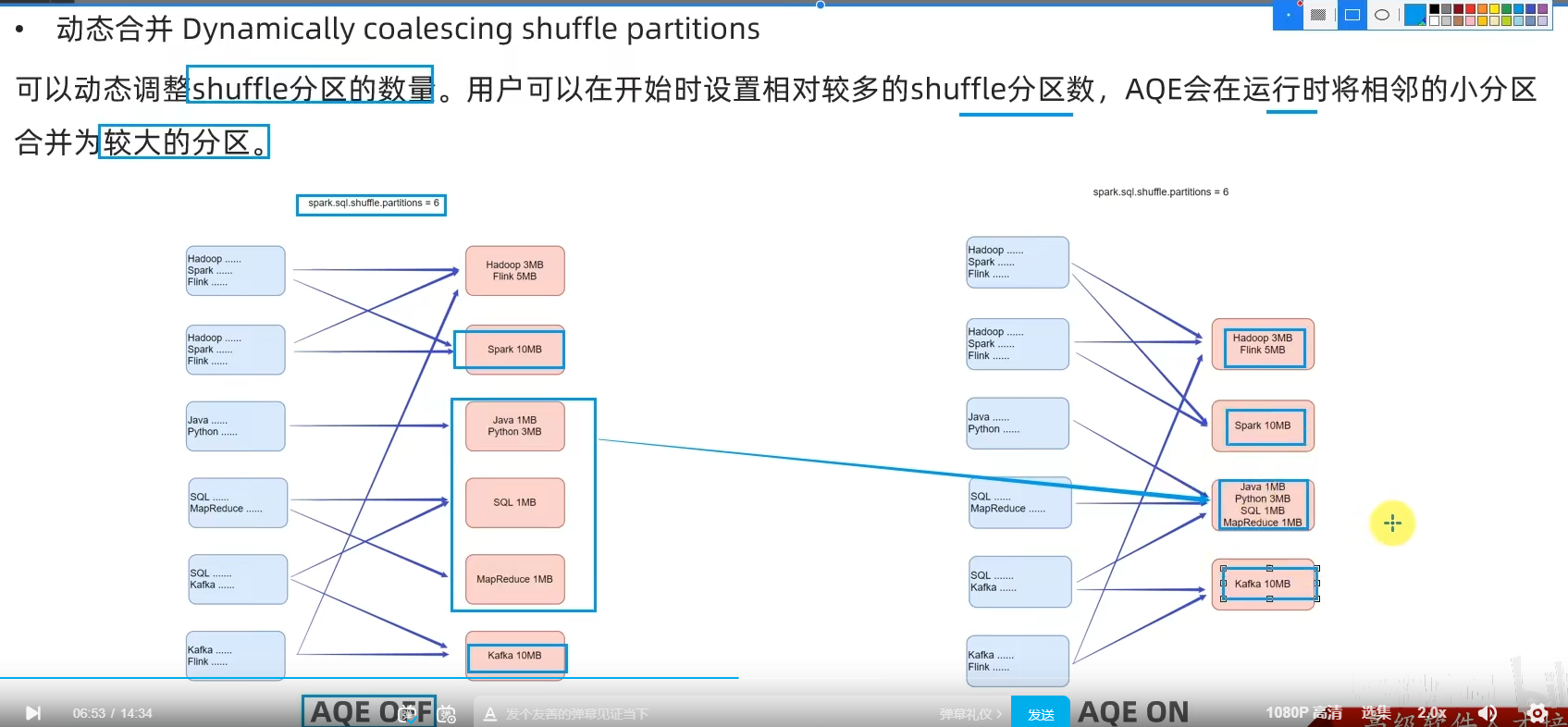
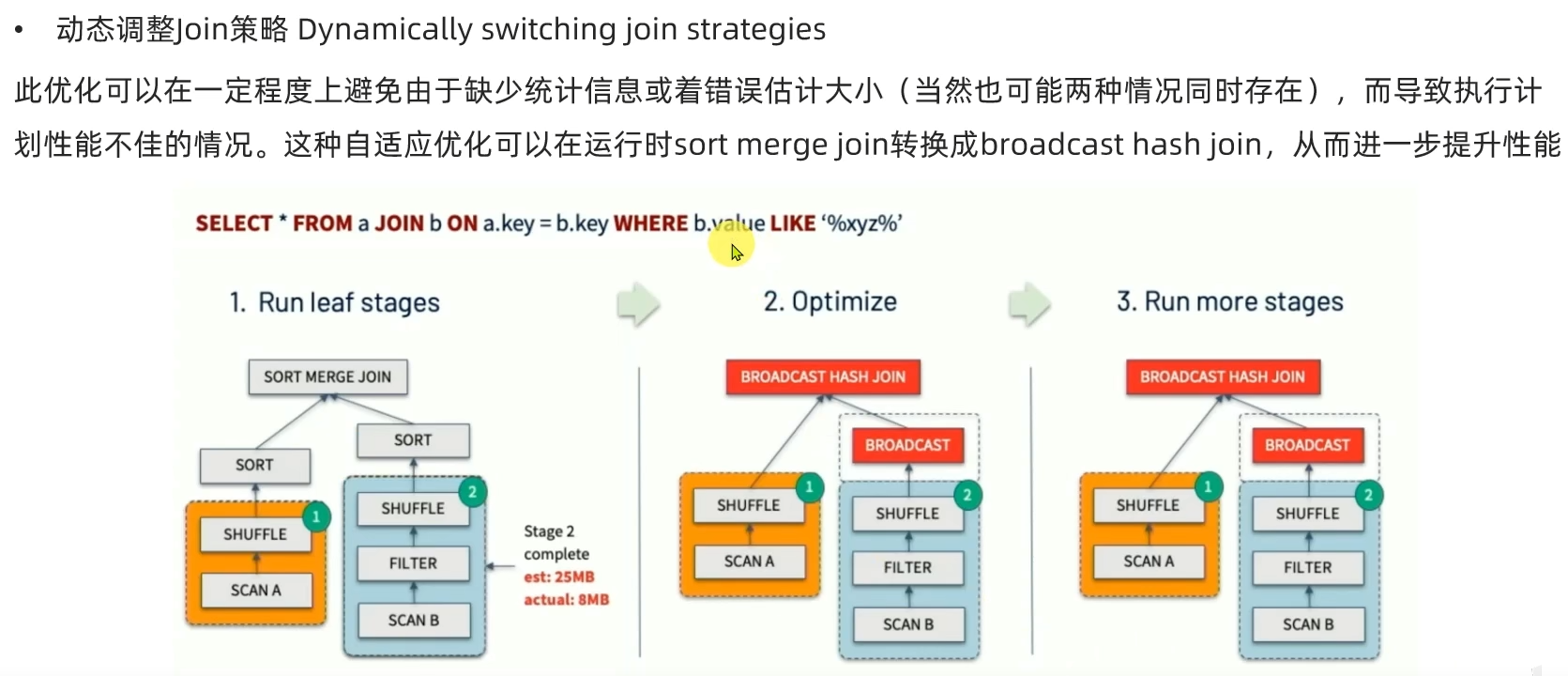
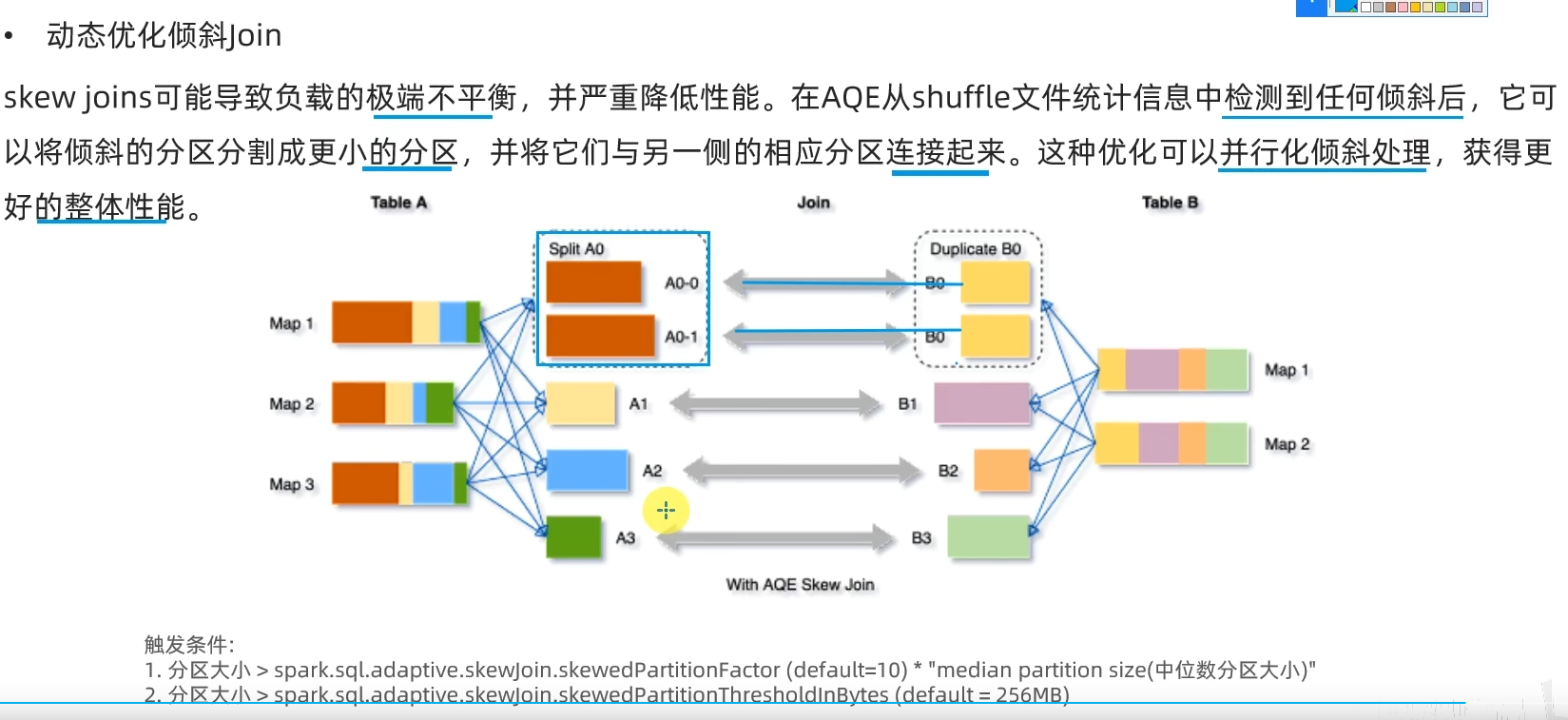
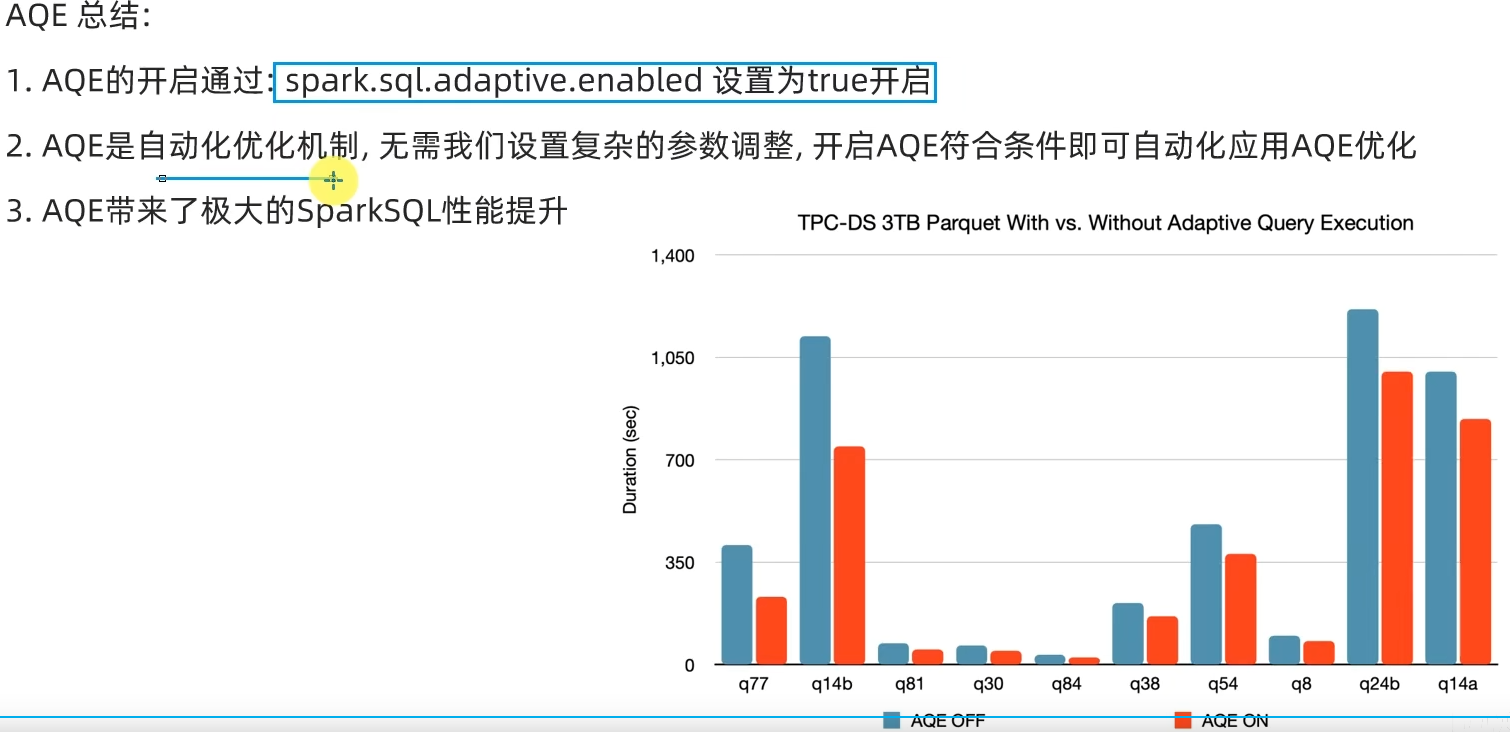
AQE总结
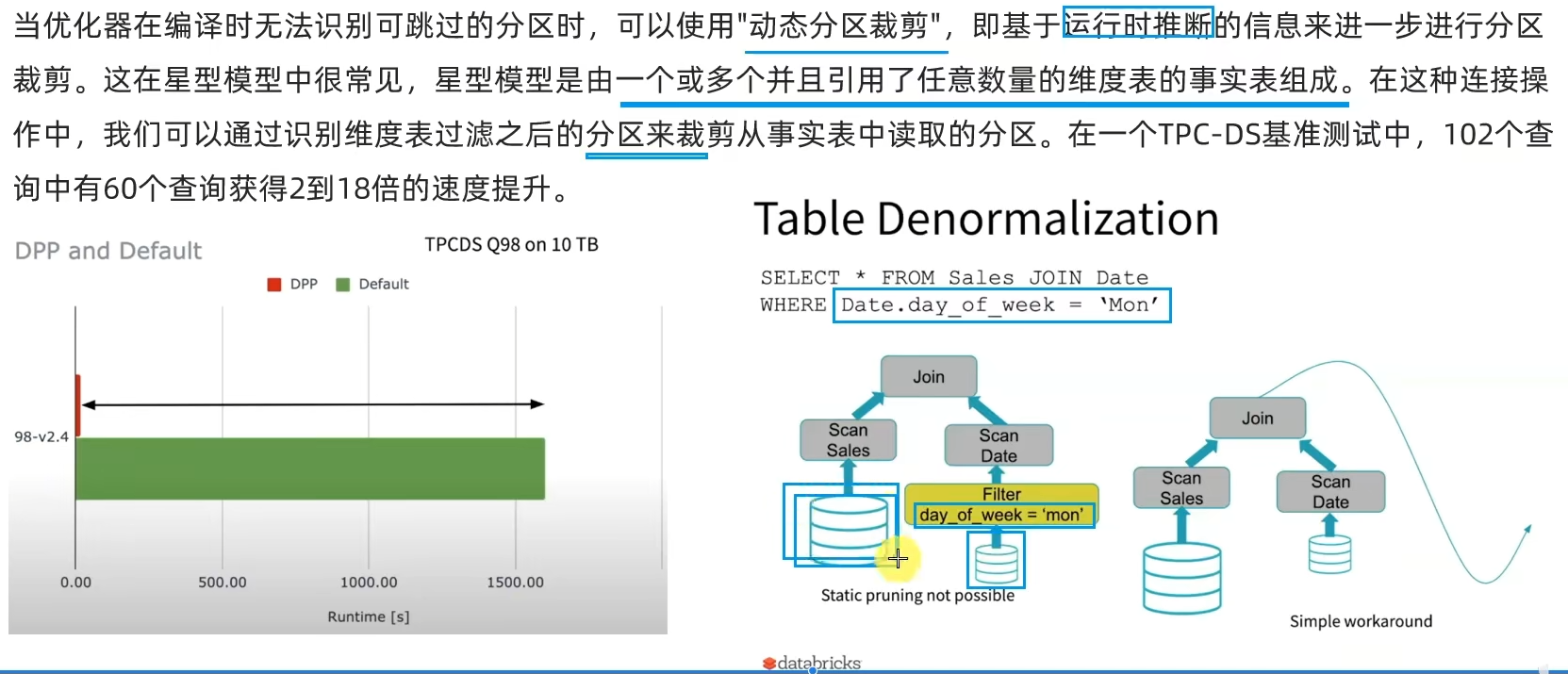
2.3 Dynamic Partition Pruning动态分区裁剪(SparkSQL)
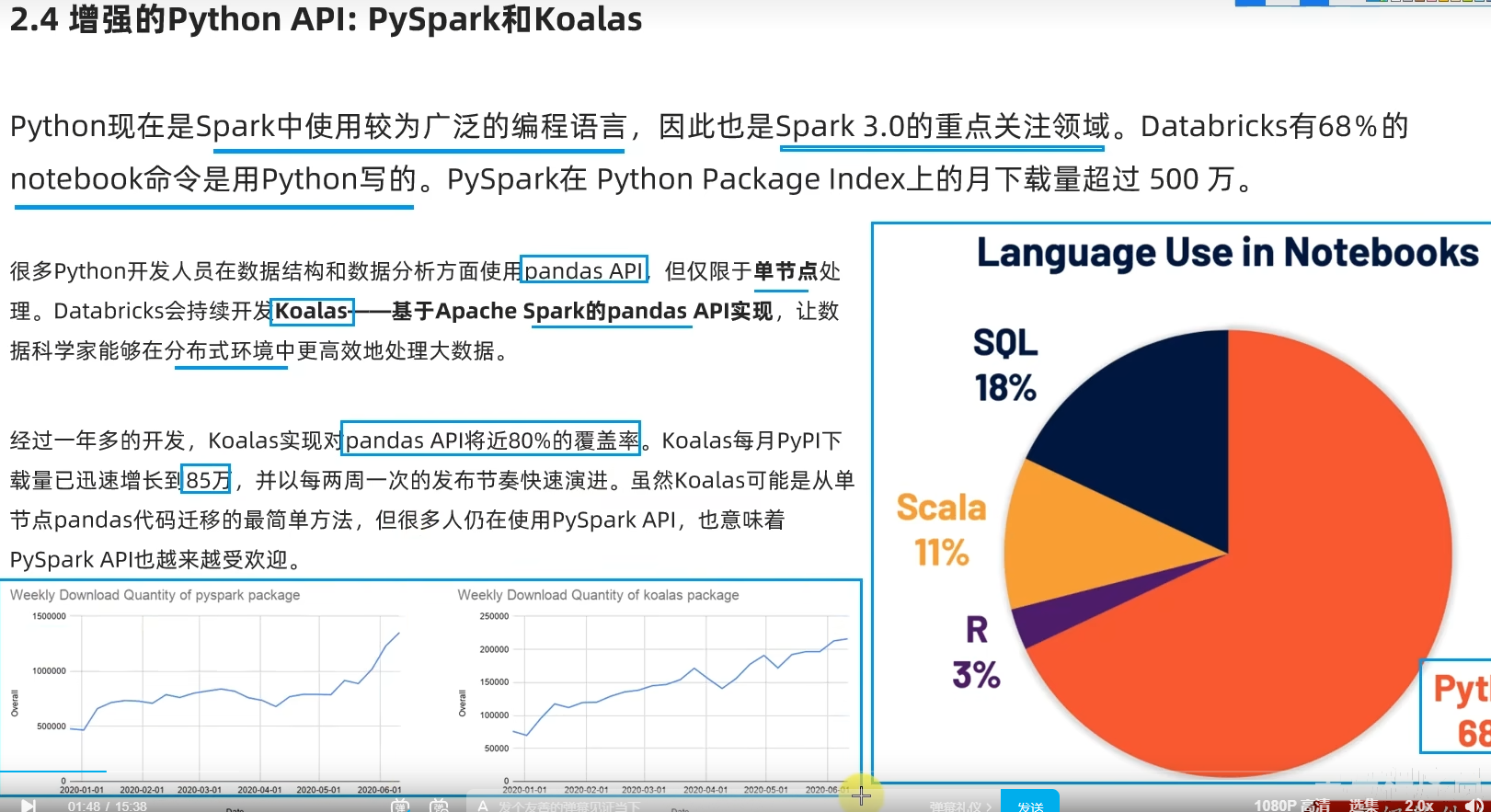
2.4 增强的Python API:PySpark和Koalas
2.5 Koalas入门演示-Koalas DataFrame构建
略