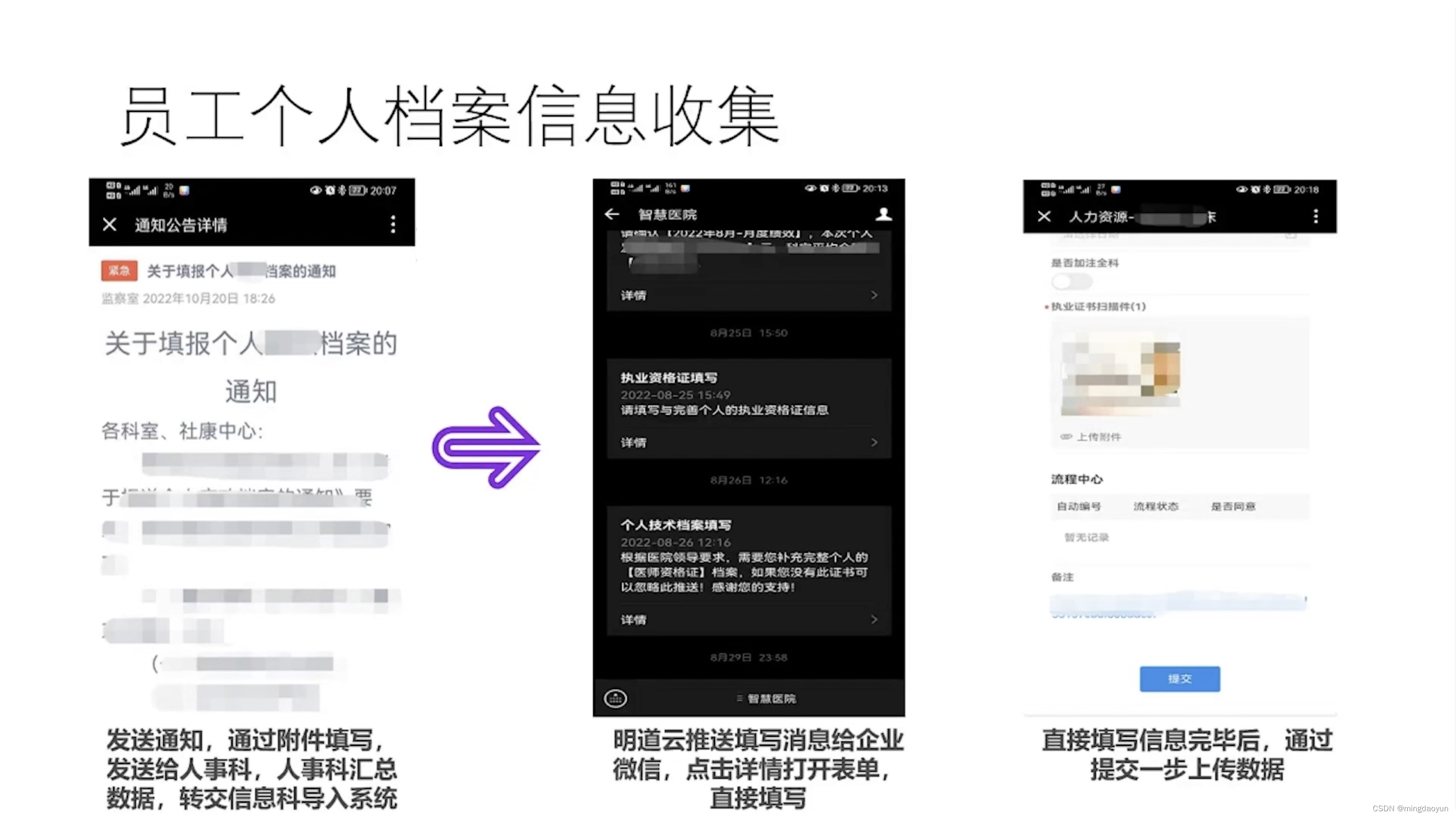
消息队列MQ
MQ的主要作用有:
异步
例子: 快递员发快递,直接到客户家效率会很低。引入菜鸟驿站后,快递员只需要把快递放到菜鸟驿站,就可以继续发其他快递去了。客户再按自己的时间安排去菜鸟驿站取快递.
作用:异步能提高系统的响应速度、吞吐量。
解耦
例子: 《Thinking in JAVA》很经典,但是都是英文,我们看不懂,所以需要编辑社,将文章翻译成其他语言,这样就可以完成英语与其他语言的交流。
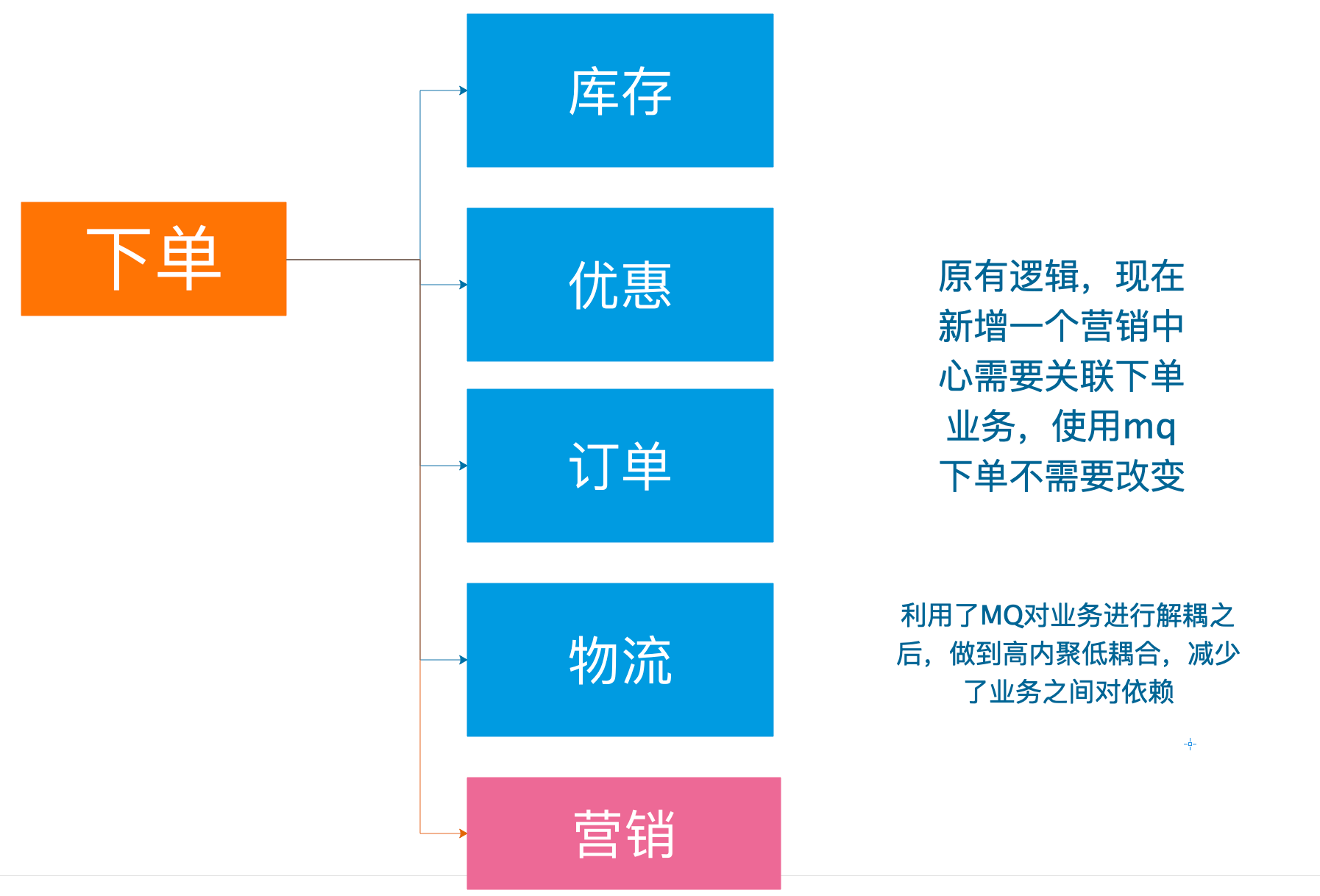
作用:
1、服务之间进行解耦,才可以减少服务之间的影响。提高系统整体的稳定性以及可扩展性。
2、另外,解耦后可以实现数据分发。生产者发送一个消息后,可以由一个或者多个消费者进行消费,并且消费者的增加或者减少对生产者没有影响。
削峰
例子: 长江每年都会涨水,但是下游出水口的速度是基本稳定的,所以会涨水。
引入三峡大坝后,可以把水储存起来,下游慢慢排水。
作用: 以稳定的系统资源应对突发的流量冲击。
MQ的缺点
上面MQ的所用也就是使用MQ的优点。但是引入MQ也是有他的缺点的:
系统可用性降低
系统引入的外部依赖增多,系统的稳定性就会变差。一旦MQ宕机,对业务会产生影响。这就需要考虑如何保证MQ的高可用。
系统复杂度提高
引入MQ后系统的复杂度会大大提高。以前服务之间可以进行同步的服务调用,引入MQ后,会变为异步调用,数据的链路就会变得更复杂。并且还会带来其他一些问题。比如:如何保证消费不会丢失?不会被重复调用?怎么保证消息的顺序性等问题。
消息一致性问题
A系统处理完业务,通过MQ发送消息给B、C系统进行后续的业务处理。如果B系统处理成功,C系统处理失败怎么办?这就需要考虑如何保证消息数据处理的一致性。
主流MQ对比
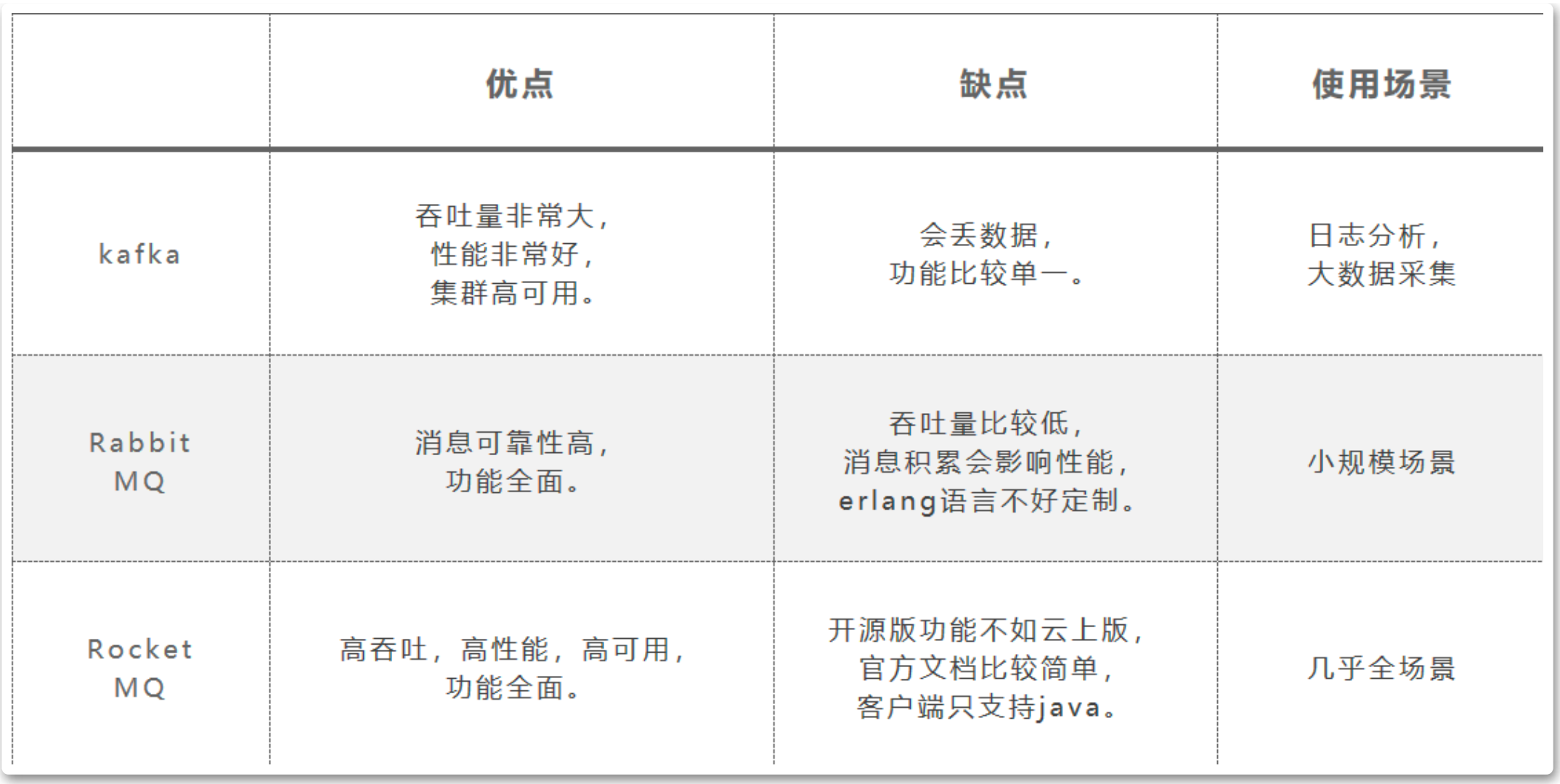
延时队列、幂等性API 开源版没有
RabbitMQ 也在针对缺点升级
RabbitMQ
class(经典)队列和Quorum(仲裁)队列对比

Quorum是基于Raft(多数确认)一致性协议实现的一种新型的分布式消息队列,他实现了持久化,多备份的FIFO队列,主要就是针对RabbitMQ的镜像模式设计的。简单理解就是quorum队列中的消息需要有集群中多半节点同意确认后,才会写入到队列中。这种队列类似于RocketMQ当中的DLedger集群。这种方式可以保证消息在集群内部不会丢失。同时,Quorum是以牺牲很多高级队列特性为代价,来进一步保证消息在分布式环境下的高可靠。
从官方这个比较图就能看到,Quorum队列大部分功能都是在Classic队列基础上做减法,比如Non-durable queues表示是非持久化的内存队列。Exclusivity表示独占队列,即表示队列只能由声明该队列的Connection连接来进行使用,包括队列创建、删除、收发消息等,并且独占队列会在声明该队列的Connection断开后自动删除。
其中有个特例就是这个Poison Message(有毒的消息)。所谓毒消息是指消息一直不能被消费者正常消费(可能是由于消费者失败或者消费逻辑有问题等),就会导致消息不断的重新入队,这样这些消息就成为了毒消息。这些读消息应该有保障机制进行标记并及时删除。Quorum队列会持续跟踪消息的失败投递尝试次数,并记录在"x-delivery-count"这样一个头部参数中。然后,就可以通过设置 Delivery limit参数来定制一个毒消息的删除策略。当消息的重复投递次数超过了Delivery limit参数阈值时,RabbitMQ就会删除这些毒消息。当然,如果配置了死信队列的话,就会进入对应的死信队列。
**Quorum队列更适合于 队列长期存在,并且对容错、数据安全方面的要求比低延迟、不持久等高级队列更能要求更严格的场景。**例如 电商系统的订单,引入MQ后,处理速度可以慢一点,但是订单不能丢失。
补充Raft协议的简单理解
将一个消息存储到一个消息的集群当中eg:3个节点,其中的两个节点确认了消息存储成功则认定自己成功了
Stream 队列

Stream队列的核心是以append-only只添加的日志来记录消息,整体来说,就是消息将以append-only的方式持久化到日志文件中,然后通过调整每个消费者的消费进度offset,来实现消息的多次分发。下方有几个属性也都是来定义日志文件的大小以及保存时间。如果你熟悉Kafka或者RocketMQ,会对这种日志记录消息的方式非常熟悉。这种队列提供了RabbitMQ已有的其他队列类型不太好实现的四个特点:
1、large fan-outs 大规模分发
当想要向多个订阅者发送相同的消息时,以往的队列类型必须为每个消费者绑定一个专用的队列。如果消费者的数量很大,这就会导致性能低下。而Stream队列允许任意数量的消费者使用同一个队列的消息,从而消除绑定多个队列的需求。
2、Replay/Time-travelling 消息回溯
RabbitMQ已有的这些队列类型,在消费者处理完消息后,消息都会从队列中删除,因此,无法重新读取已经消费过的消息。而Stream队列允许用户在日志的任何一个连接点开始重新读取数据。
3、Throughput Performance 高吞吐性能
Strem队列的设计以性能为主要目标,对消息传递吞吐量的提升非常明显。
4、Large logs 大日志
RabbitMQ一直以来有一个让人诟病的地方,就是当队列中积累的消息过多时,性能下降会非常明显。但是Stream队列的设计目标就是以最小的内存开销高效地存储大量的数据。
整体上来说,RabbitMQ的Stream队列,其实有很多地方借鉴了其他MQ产品的优点,在保证消息可靠性的基础上,着力提高队列的消息吞吐量以及消息转发性能。因此,Stream也是在视图解决一个RabbitMQ一直以来,让人诟病的缺点,就是当队列中积累的消息过多时,性能下降会非常明显的问题。RabbitMQ以往更专注于企业级的内部使用,但是从这些队列功能可以看到,Rabbitmq也在向更复杂的互联网环境靠拢,未来对于RabbitMQ的了解,也需要随着版本推进,不断更新。但是,从整体功能上来讲,队列只不过是一个实现FIFO的数据结构而已,这种数据结构其实是越简单越好。而当前RabbitMQ区分出这么多种队列类型,其实极大的增加了应用层面的使用难度,应用层面必须有一些不同的机制兼容各种队列。所以,在未来版本中,RabbitMQ很可能还是会将这几种队列类型最终统一成一种类型。例如官方已经说明未来会使用Quorum队列类型替代经典队列,到那时,应用层很多工具就可以得到简化,比如不需要再设置durable和exclusive属性。虽然Quorum队列和Stream队列目前还没有合并的打算,但是在应用层面来看,他们两者是冲突的,是一种竞争关系,未来也很有可能最终统一保留成一种类型。至于未来走向如何,我们可以在后续版本拭目以待。
RabbitMQ编程模型
RabbitMQ的使用生态已经相当庞大,支持非常多的语言。而就以java而论,也已经支持非常多的扩展。我们接下来会从原生API、SpringBoot集成、SpringCloudStream集成,三个角度来详细学习RabbitMQ的编程模型。在学习编程模型时,要注意下,新推出的Stream队列,他的客户端跟另外两种队列稍有不同。
原生API
使用RabbitMQ提供的原生客户端API进行交互。先来了解下如何使用Classic和Quorum队列。至于Stream队列,目前他使用的是和这两个队列不同的客户端,所以会在后面一个章节单独讨论。
maven依赖
<dependencies>
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.9.0</version>
</dependency>
</dependencies>
基础编程模型
这些各种各样的消息模型其实都对应一个比较统一的基础编程模型。
step1首先创建连接,获取Channel
Connection connection = RabbitMQUtil.getConnection();
Channel channel = connection.createChannel();
step2声明queue队列
一旦创建不能修改
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
queue–队列的名称
durable–如果我们声明持久队列(队列将在服务器重新启动后继续存在)
exclusive–如果我们宣布独占队列(仅限于此连接),则为true
autoDelete–如果是声明自动删除队列(服务器将在不再使用时删除它)参数,则为true–队列的其他财产(构造参数)
返回:一个声明确认方法,用于指示队列已成功声明Throws:IOException–如果遇到错误,
请参阅:AMQP.queue.Declare,AMQP.queue.DeclareOk
/**
* Declare a queue
* @see com.rabbitmq.client.AMQP.Queue.Declare
* @see com.rabbitmq.client.AMQP.Queue.DeclareOk
* @param queue the name of the queue
queue–队列的名称
* @param durable true if we are declaring a durable queue (the queue will survive a server restart)
durable–如果我们声明持久队列(队列将在服务器重新启动后继续存在)
* @param exclusive true if we are declaring an exclusive queue (restricted to this connection)
exclusive–如果我们宣布独占队列(仅限于此连接),则为true
* @param autoDelete true if we are declaring an autodelete queue (server will delete it when no longer in use) 如果是声明自动删除队列(服务器将在不再使用时删除它)
* @param arguments other properties (construction arguments) for the queue
arguments–队列的其他财产(构造参数)用于声明quorum等队列
* @return a declaration-confirm method to indicate the queue was successfully declared
返回:一个声明确认方法,用于指示队列已成功声明
* @throws java.io.IOException if an error is encountered
Throws:IOException–如果遇到错误,
*/
Queue.DeclareOk queueDeclare(String queue, boolean durable, boolean exclusive, boolean autoDelete,
Map<String, Object> arguments) throws IOException;
//quorum
Map<String,Object> params = new HashMap<>();
params.put("x-queue-type","quorum");
//声明Quorum队列的方式就是添加一个x-queue-type参数,指定为quorum。默认是classic
channel.queueDeclare(QUEUE_NAME, true, false, false, params);
//注意:1、对于Quorum类型,durable参数就必须是true了,设置成false的话,会报错。同样,exclusive参数必须设置为false
//stream
Map<String,Object> params = new HashMap<>();
params.put("x-queue-type","stream");
params.put("x-max-length-bytes", 20_000_000_000L); // maximum stream size: 20 GB
params.put("x-stream-max-segment-size-bytes", 100_000_000); // size of segment files: 100 MB
channel.queueDeclare(QUEUE_NAME, true, false, false, params);
//注意:1、同样,durable参数必须是true,exclusive必须是false。 --你应该会想到,对于这两种队列,这两个参数就是多余的了,未来可以直接删除。
//2、x-max-length-bytes 表示日志文件的最大字节数。x-stream-maxsegment-size-bytes 每一个日志文件的最大大小。这两个是可选参数,通常为了防止stream日志无限制累计,都会配合stream队列一起声明。
声明的队列,如果服务端没有,那么会自动创建。但是如果服务端有了这个队列,那么声明的队列属性必须和服务端的队列属性一致才行。
step3Producer根据应用场景发送消息到queue
channel.basicPublish("", QUEUE_NAME, builder.build(), message.getBytes("UTF-8"));
/**
* Publish a message.
*
* Publishing to a non-existent exchange will result in a channel-level
* protocol exception, which closes the channel.
* 发布到不存在的交换机将导致通道级协议异常,从而关闭通道
* Invocations of <code>Channel#basicPublish</code> will eventually block if a
如果资源驱动警报生效,则ChannelbasicPublish的调用最终将被阻止。
* <a href="https://www.rabbitmq.com/alarms.html">resource-driven alarm</a> is in effect.
*
* @see com.rabbitmq.client.AMQP.Basic.Publish
* @see <a href="https://www.rabbitmq.com/alarms.html">Resource-driven alarms</a>
* @param exchange the exchange to publish the message to exchange–将消息发布到的exchange
* @param routingKey the routing key routingKey的交换–路由密钥属性
* @param props other properties for the message - routing headers etc
* @param body the message body
* @throws java.io.IOException if an error is encountered
*/
void basicPublish(String exchange, String routingKey, BasicProperties props, byte[] body) throws IOException;
step4Consumer消费消息
定义消费者,消费消息进行处理,并向RabbitMQ进行消息确认。确认了之后就表明这个消息已经消费完了,否则RabbitMQ还会继续让别的消费者实例来处理主要收集了两种消费方式
1、被动消费模式,
Consumer等待rabbitMQ 服务器将message推送过来再消费。一般是启一个一直挂起的线程来等待。
/**
* Start a non-nolocal, non-exclusive consumer, with
* a server-generated consumerTag.
* @param queue the name of the queue
* @param autoAck true if the server should consider messages
* acknowledged once delivered; false if the server should expect
不应答消息一直在
* explicit acknowledgements
* @param callback an interface to the consumer object
回掉函数处理业务
* @return the consumerTag generated by the server
* @throws java.io.IOException if an error is encountered
* @see com.rabbitmq.client.AMQP.Basic.Consume
* @see com.rabbitmq.client.AMQP.Basic.ConsumeOk
* @see #basicConsume(String, boolean, String, boolean, boolean, Map, Consumer)
*/
String basicConsume(String queue, boolean autoAck, Consumer callback) throws IOException;
不会停止回挂起等待消息
2.主动消费模式
**。**Comsumer主动到rabbitMQ服务器上去获取指定的messge进行消费。
/**
* Retrieve a message from a queue using {@link com.rabbitmq.client.AMQP.Basic.Get}
* @see com.rabbitmq.client.AMQP.Basic.Get
* @see com.rabbitmq.client.AMQP.Basic.GetOk
* @see com.rabbitmq.client.AMQP.Basic.GetEmpty
* @param queue the name of the queue
* @param autoAck true if the server should consider messages
* acknowledged once delivered; false if the server should expect
* explicit acknowledgements
* @return a {@link GetResponse} containing the retrieved message data
* @throws java.io.IOException if an error is encountered
*/
GetResponse basicGet(String queue, boolean autoAck) throws IOException;
GetResponse response2 = channel.basicGet(QUEUE_NAME, false);
拉取消息之后会停止
Stream队列消费 在当前版本下,消费Stream队列时,需要注意三板斧的设置。
step5、完成以后关闭连接,释放资源
channel.close();
connection.close();
官网的消息场景


1.Hello World
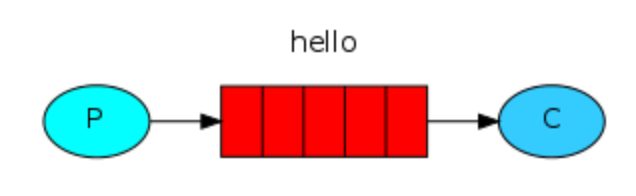
最直接的方式,P端发送一个消息到一个指定的queue,中间不需要任何exchange规则。C端按queue方式进行消费。
关键代码:(其实关键的区别也就是几个声明上的不同。)
channel.queueDeclare(QUEUE_NAME,false,false,false,null);
channel.basicPublish(“”, QUEUE_NAME, null, message.getBytes(“UTF-8”));
Product:
channel.queueDeclare(QUEUE_NAME,false,false,false,null); channel.basicPublish("", QUEUE_NAME, null, message.getBytes("UTF-8"));
Comsumer:
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
2. Work queues 工作序列
这就是kafka同一groupId的消息分发模式
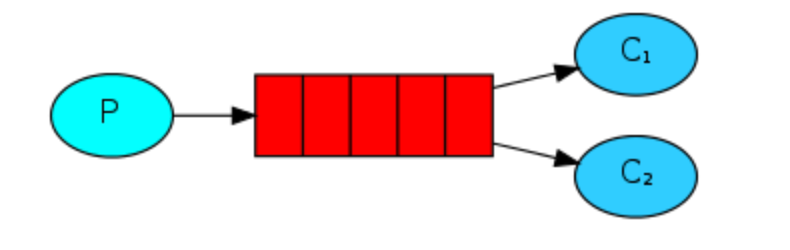
Producer消息发送给queue,服务器根据负载方案决定把消息发给一个指定的Consumer处理。
工作任务模式,领导部署一个任务,由下面的一个员工来处理。
Product:
channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);
//任务一般是 不能因为消息中间件的服务而被耽误的,所以durable设置成了true,这样,即使rabbitMQ服务断了,这个消息也不会消失
channel.basicPublish("", TASK_QUEUE_NAME,MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8"));123
Comsumer:
channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null); channel.basicQos(1); channel.basicConsume(TASK_QUEUE_NAME, false, consumer);123
这个模式应该是最常用的模式,也是官网讨论比较详细的一种模式,所以官网上也对这种模式做了重点讲述。
---- 首先。Consumer端的autoAck字段设置的是false,这表示consumer在接收到消息后不会自动反馈服务器已消费了message,而要改在对message处理完成了之后,再调用channel.basicAck来通知服务器已经消费了该message.这样即使Consumer在执行message过程中出问题了,也不会造成message被忽略,因为没有ack的message会被服务器重新进行投递。但是,这其中也要注意一个很常见的BUG,就是如果所有的consumer都忘记调用basicAck()了,就会造成message被不停的分发,也就造成不断的消耗系统资源。这也就是 Poison Message(毒消息)。
----- 其次,官方特意提到的message的持久性。关键的message不能因为服务出现问题而被忽略。还要注意,官方特意提到,所有的queue是不能被多次定义的。如果一个queue在开始时被声明为durable,那在后面再次声明这个queue时,即使声明为 not durable,那这个queue的结果也还是durable的。
----- 然后,是中间件最为关键的分发方式。这里,RabbitMQ默认是采用的fairdispatch,也叫round-robin模式,就是把消息轮询,在所有consumer中轮流发送。这种方式,没有考虑消息处理的复杂度以及consumer的处理能力。而他们改进后的方案,是consumer可以向服务器声明一个prefetchCount,我把他叫做预处理能力值。channel.basicQos(prefetchCount);表示当前这个consumer可以同时处理几个message。这样服务器在进行消息发送前,会检查这个consumer当前正在处理中的message(message已经发送,但是未收到consumer的basicAck)有几个,如果超过了这个consumer节点的能力值,就不再往这个consumer发布。这种模式,官方也指出还是有问题的,消息有可能全部阻塞,所有consumer节点都超过了能力值,那消息就阻塞在服务器上,这时需要自己及时发现这个问题,采取措施,比如增加consumer节点或者其他策略
----- 另外 官网上没有深入提到的,就是还是没有考虑到message处理的复杂程度。有的message处理可能很简单,有的可能很复杂,现在还是将所有message的处理程度当成一样的。还是有缺陷的,但是目前也只看到dubbo里对单个服务有权重值的概念,涉及到了这个问题。
3:Publish/Subscribe 订阅 发布 机制
type为fanout 的exchange:
就是将生产消息的步骤和将消息转发的步骤进行解开耦,也就是把preducer与Consumer进行进一步的解耦。producer只负责发送消息,至于消息进入哪个queue,由exchange来分配。如上图,就是把producer发送的消息,交由exchange同时发送到两个queue里,然后由不同的Consumer去进行消费
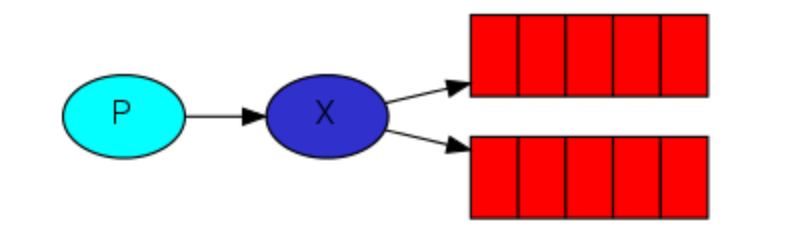
Product:
channel.exchangeDeclare(EXCHANGE_NAME, "fanout"); channel.basicPublish(EXCHANGE_NAME, "", null, message.getBytes("UTF-8"));12
Comsumer(receiver): //将消费的目标队列绑定到exchange上。
channel.exchangeDeclare(EXCHANGE_NAME, "fanout");
String queueName = channel.queueDeclare().getQueue(); channel.queueBind(queueName, EXCHANGE_NAME, "");123
关键处就是type为”fanout” 的exchange,这种类型的exchange只负责往所有已绑定的队列上发送消息。
4:Routing 基于内容的路由
type为”direct” 的exchange
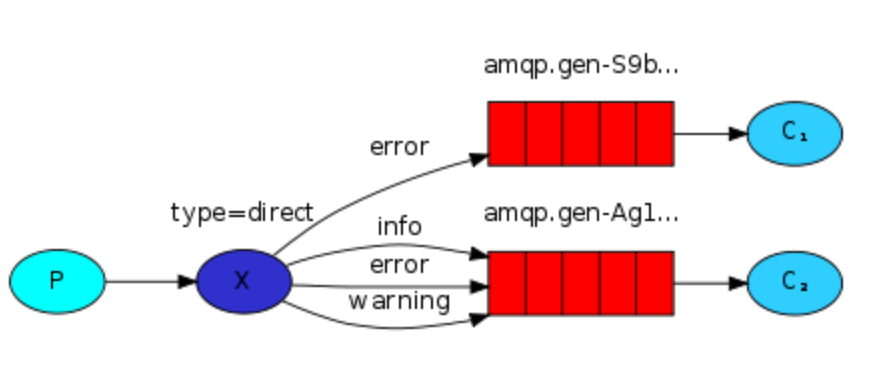
这种模式一看图就清晰了。 在上一章 exchange 往所有队列发送消息的基础上,增加一个路由配置,指定exchange如何将不同类别的消息分发到不同的queue上。
Producer:
channel.exchangeDeclare(EXCHANGE_NAME, "direct");
channel.basicPublish(EXCHANGE_NAME, routingKey, null, message.getBytes("UTF- 8"));12
Receiver:
channel.exchangeDeclare(EXCHANGE_NAME, "direct");
channel.queueBind(queueName, EXCHANGE_NAME, routingKey1);
channel.queueBind(queueName, EXCHANGE_NAME, routingKey2);
channel.basicConsume(queueName, true, consumer);1234
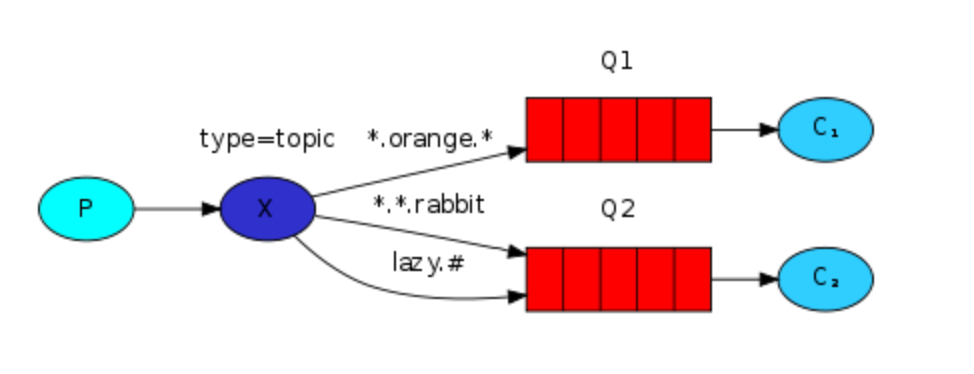
5:Topics 话题
type为"topic" 的exchange
这个模式也就在上一个模式的基础上,对routingKey进行了模糊匹配单词之间用,隔开,* 代表一个具体的单词。# 代表0个或多个单词。
Producer:
channel.exchangeDeclare(EXCHANGE_NAME, "topic");
channel.basicPublish(EXCHANGE_NAME, routingKey, null, message.getBytes("UTF- 8"));12
Receiver:
channel.exchangeDeclare(EXCHANGE_NAME, "topic");
channel.queueBind(queueName, EXCHANGE_NAME, routingKey1);
channel.queueBind(queueName, EXCHANGE_NAME, routingKey2);
channel.basicConsume(queueName, true, consumer);1234
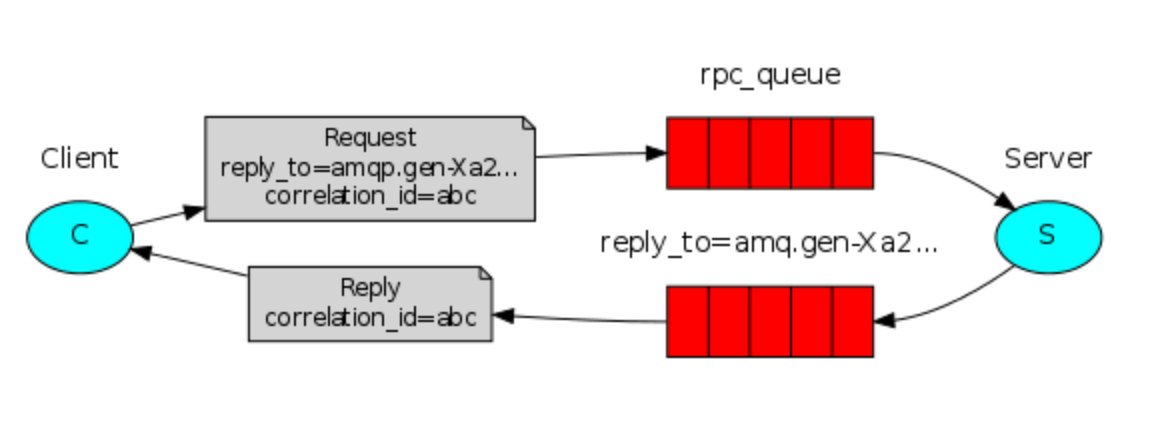
6:RPC 远程调用(不推荐使用有更好的选择)
远程调用是同步阻塞的调用远程服务并获取结果。RPC远程调用机制其实并不是消息中间件的处理强项。毕竟消息队列机制很大程度上来说就是为了缓冲同步RPC调用造成的瞬间高峰。而RabbitMQ的同步调用示例,看着也确实怪怪的。并且,RPC远程调用的场景,也有太多可替代的技术会比用消息中间件处理得更优雅,更流畅。
7:Publisher Confirms 发送者消息确认
如果了解了这个机制就会发现,这个消息确认机制就是跟RocketMQ的事务消息机制差不多的。而对于这个机制,RocketMQ的支持明显更优雅
RabbitMQ的消息可靠性是非常高的,但是他以往的机制都是保证消息发送到了MQ之后,可以推送到消费者消费,不会丢失消息。但是发送者发送消息是否成功是没有保证的。我们可以回顾下,发送者发送消息的基础API:Producer.basicPublish方法是没有返回值的,也就是说,一次发送消息是否成功,应用是不知道的,这在业务上就容易造成消息丢失。而这个模块就是通过给发送者提供一些确认机制,来保证这个消息发送的过程是成功的。
发送者确认模式默认是不开启的,所以如果需要开启发送者确认模式,需要手动在channel中进行声明。
channel.confirmSelect();
在官网的示例中,重点解释了三种策略:
1、发布单条消息
即发布一条消息就确认一条消息。核心代码:
for (int i = 0; i < MESSAGE_COUNT; i++) {
String body = String.valueOf(i);
channel.basicPublish("", queue, null, body.getBytes());
channel.waitForConfirmsOrDie(5_000);
}
channel.waitForConfirmsOrDie(5_000);这个方法就会在channel端等待RabbitMQ给出一个响应,用来表明这个消息已经正确发送到了RabbitMQ服务端。但是要注意,这个方法会同步阻塞channel,在等待确认期间,channel将不能再继续发送消息,也就是说会明显降低集群的发送速度即吞吐量。
官方说明了,其实channel底层是异步工作的,会将channel阻塞住,然后异步等待服务端发送一个确认消息,才解除阻塞。但是我们在使用时,可以把他当作一个同步工具来看待。然后如果到了超时时间,还没有收到服务端的确认机制,那就会抛出异常。然后通常处理这个异常的方式是记录错误日志或者尝试重发消息,但是尝试重发时一定要注意不要使程序陷入死循环
2、发送批量消息
之前单条确认的机制会对系统的吞吐量造成很大的影响,所以稍微中和一点的方式就是发送一批消息后,再一起确认。
int batchSize = 100;
int outstandingMessageCount = 0;
long start = System.nanoTime();
for (int i = 0; i < MESSAGE_COUNT; i++) {
String body = String.valueOf(i);
ch.basicPublish("", queue, null, body.getBytes());
outstandingMessageCount++;
if (outstandingMessageCount == batchSize) {
ch.waitForConfirmsOrDie(5_000); outstandingMessageCount = 0;
}
}
if (outstandingMessageCount > 0) {
ch.waitForConfirmsOrDie(5_000);
}
这种方式可以稍微缓解下发送者确认模式对吞吐量的影响。但是也有个固有的问题就是,当确认出现异常时,发送者只能知道是这一批消息出问题了, 而无法确认具体是哪一条消息出了问题。所以接下来就需要增加一个机制能够具体对每一条发送出错的消息进行处理。
3、异步确认消息
RabbitMQ 事务的简化版本
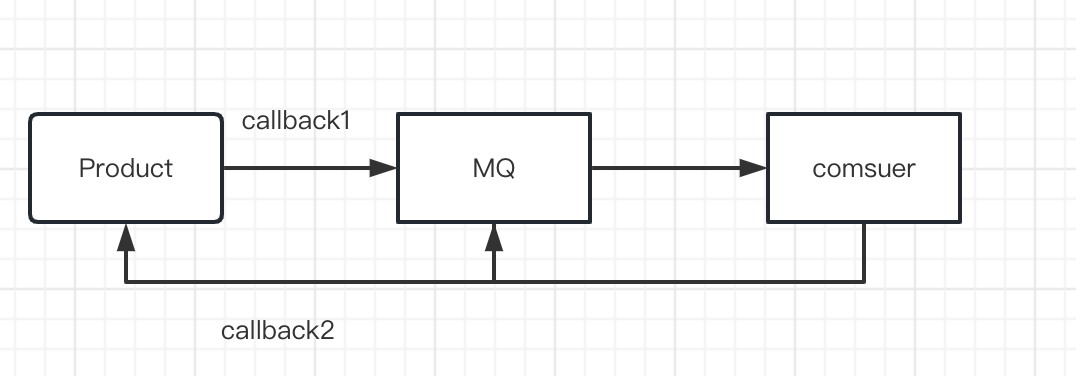
实现的方式也比较简单,Producer在channel中注册监听器来对消息进行确认。
channel.addConfirmListener(ConfirmCallback var1, ConfirmCallback var2);
按说监听只要注册一个就可以了,那为什么这里要注册两个呢?如果对照下RocketMQ的事务消息机制,这就很容易理解了。发送者在发送完消息后,就会执行第一个监听器callback1,然后等服务端发过来的反馈后,再执行第二个监听器callback2。
然后关于这个ConfirmCallback,这是个监听器接口,里面只有一个方法:
voidhandle(long sequenceNumber, boolean multiple) throws IOException;
这方法中的两个参数,
sequenceNumer:这个是一个唯一的序列号,代表一个唯一的消息。在RabbitMQ中,他的消息体只是一个二进制数组,并不像RocketMQ一样有一个封装的对象,所以默认消息是没有序列号的。而RabbitMQ提供了一个方法
int sequenceNumber = channel.getNextPublishSeqNo());
来生成一个全局递增的序列号。然后应用程序需要自己来将这个序列号与消息对应起来。没错!是的!需要客户端自己去做对应!
multiple:这个是一个Boolean型的参数。如果是true,就表示这一次只确认了当前一条消息。如果是false,就表示RabbitMQ这一次确认了一批消息,在sequenceNumber之前的所有消息都已经确认完成了。
对比下RocketMQ的事务消息机制,有没有觉得很熟悉,但是又很别扭?当然,考虑到这个对于RabbitMQ来说还是个新鲜玩意,所以有理由相信这个机制在未来会越来越完善。
package com.rabbitmq.reliable;
import com.rabbitmq.client.*;
import com.roy.rabbitmq.RabbitMQUtil;
import java.time.Duration;
import java.util.UUID;
import java.util.concurrent.ConcurrentNavigableMap;
import java.util.concurrent.ConcurrentSkipListMap;
import java.util.function.BooleanSupplier;
public class PublishConfirm {
static final int MESSAGE_COUNT = 50000;
static Connection createConnection() throws Exception {
ConnectionFactory cf = new ConnectionFactory();
cf.setHost("localhost");
cf.setUsername("guest");
cf.setPassword("guest");
return cf.newConnection();
// return RabbitMQUtil.getConnection();
}
public static void main(String[] args) throws Exception {
// publishMessagesIndividually();
// publishMessagesInBatch();
handlePublishConfirmsAsynchronously();
}
//发布单条消息
static void publishMessagesIndividually() throws Exception {
try (Connection connection = createConnection()) {
Channel ch = connection.createChannel();
String queue = UUID.randomUUID().toString();
ch.queueDeclare(queue, false, false, true, null);
//启用消费者确认
ch.confirmSelect();
long start = System.nanoTime();
for (int i = 0; i < MESSAGE_COUNT; i++) {
String body = String.valueOf(i);
ch.basicPublish("", queue, null, body.getBytes());
ch.waitForConfirmsOrDie(5_000);
}
long end = System.nanoTime();
System.out.format("Published %,d messages individually in %,d ms%n", MESSAGE_COUNT, Duration.ofNanos(end - start).toMillis());
}
}
//发布多条消息批量确认
static void publishMessagesInBatch() throws Exception {
try (Connection connection = createConnection()) {
Channel ch = connection.createChannel();
String queue = UUID.randomUUID().toString();
ch.queueDeclare(queue, false, false, true, null);
//开启生产者确认
ch.confirmSelect();
int batchSize = 100;
int outstandingMessageCount = 0;
long start = System.nanoTime();
for (int i = 0; i < MESSAGE_COUNT; i++) {
String body = String.valueOf(i);
ch.basicPublish("", queue, null, body.getBytes());
outstandingMessageCount++;
if (outstandingMessageCount == batchSize) {
ch.waitForConfirmsOrDie(5_000);
outstandingMessageCount = 0;
System.out.println("outstandingMessageCount:" + i);
}
}
if (outstandingMessageCount > 0) {
ch.waitForConfirmsOrDie(5_000);
}
long end = System.nanoTime();
System.out.format("Published %,d messages in batch in %,d ms%n", MESSAGE_COUNT, Duration.ofNanos(end - start).toMillis());
}
}
//异步确认消息
static void handlePublishConfirmsAsynchronously() throws Exception {
try (Connection connection = createConnection()) {
Channel ch = connection.createChannel();
String queue = UUID.randomUUID().toString();
ch.queueDeclare(queue, false, false, true, null);
//开启生产者确认
ch.confirmSelect();
ConcurrentNavigableMap<Long, String> outstandingConfirms = new ConcurrentSkipListMap<>();
ConfirmCallback cleanOutstandingConfirms = (sequenceNumber, multiple) -> {
if (multiple) {
ConcurrentNavigableMap<Long, String> confirmed = outstandingConfirms.headMap(
sequenceNumber, true
);
confirmed.clear();
} else {
outstandingConfirms.remove(sequenceNumber);
}
};
//异步确认(回掉函数1,回掉函数2)
ch.addConfirmListener(cleanOutstandingConfirms, (sequenceNumber, multiple) -> {
String body = outstandingConfirms.get(sequenceNumber);
System.err.format(
"Message with body %s has been nack-ed. Sequence number: %d, multiple: %b%n",
body, sequenceNumber, multiple
);
cleanOutstandingConfirms.handle(sequenceNumber, multiple);
});
long start = System.nanoTime();
for (int i = 0; i < MESSAGE_COUNT; i++) {
String body = String.valueOf(i);
outstandingConfirms.put(ch.getNextPublishSeqNo(), body);
ch.basicPublish("", queue, null, body.getBytes());
System.out.println(ch.getNextPublishSeqNo());
}
if (!waitUntil(Duration.ofSeconds(60), () -> outstandingConfirms.isEmpty())) {
throw new IllegalStateException("All messages could not be confirmed in 60 seconds");
}
long end = System.nanoTime();
System.out.format("Published %,d messages and handled confirms asynchronously in %,d ms%n", MESSAGE_COUNT, Duration.ofNanos(end - start).toMillis());
}
}
static boolean waitUntil(Duration timeout, BooleanSupplier condition) throws InterruptedException {
int waited = 0;
while (!condition.getAsBoolean() && waited < timeout.toMillis()) {
Thread.sleep(100L);
waited = +100;
}
return condition.getAsBoolean();
}
}