搭建大数据平台
启动流程
1、启动Nginx服务(在bdp-web-mysql服务中)
cd /usr/local/nginx/
# 启动Nginx
./sbin/nginx
# 查看端口是否存在
netstat -tunlp|grep 20001
2、启动zookeeper(在bdp-executor-realtime123)
cd /app/bdp/apache-zookeeper-3.5.8-bin/bin
# 启动
./zkServer.sh start
# 查看状态
./zkServer.sh status
3、开启实时同步微服务(在bdp-executor-realtime123)
cd /app/bdp/bdp-realtime
sh bin/start.sh
tail -200f logs/bdp-realtime.log4、启动confluent服务(在bdp-executor-realtime123)
cd /app/bdp/confluent-6.2.0
# 重载系统服务
systemctl daemon-reload
# 使用系统服务启动服务
systemctl start zookeeper
systemctl start kafka
systemctl start kafka-connect必须依次启动zookeeper、kafka、kafka-connect,可用jps命令查看服务是否启动,下面是服务名与进程名对照。启动confluent服务的命令如上,然后启动bdp-server/executor/realtime的命令如下
cd /app/bdp/bdp-server
sh bin/start.sh
tail -200f logs/bdp-server.log服务名 | 进程名 |
zookeeper | QuorumPeerMain |
kafka | Kafka |
kafka-connect | ConnectDistributed |
确保jps命令存在上面三个进程名即可,代表安装成功。
刚开始只是照着文档都配置了一遍,然后登录进去后,测试了连接数据源后就以为成功了,后面再去操作的时候都不知道怎么跑起来,这里记录一下。同时还是改一下反手关掉虚拟机的毛病,挂起就可。
平台熟悉
各个服务的作用
应用名 | 信息 |
bdp-server | 服务端:大数据平台的大脑,掌控所有的任务启停,任务调度,微服务调用,元数据操作。(最多部署两个) |
bdp-executor | 执行器:任务执行器,负责任务执行与调度。(可部署多个) |
bdp-realtime | 实时同步微服务:对实时同步组件的管理。(仅可部署一个) |
bdp-web | 前端:大数据平台的入口,用户的操作页面。 |
bdp_db | 元数据库:存放大数据平台的元数据。 |
confluent | 实时同步组件:实时同步任务、物理删除任务的运行。(可部署多个) |
这里记录这个表主要是需要了解一下各个服务的作用
大数据平台涉及到的技术
confluent组件中包含了zookeeper(微服务调用)、kafka、kafka-connect(实时同步组件)
大数据监控平台是采用Grafana、Prometheus、node-exporter实现的,可对所有服务器的硬件资源进行监控,方便运维和及时了解平台运行情况。
Grafana用来展现监控数据,各种图表
Prometheus用来收集存储监控数据
node-exporter用来采集服务器各个指标值
这里列出的技术点都是我不熟悉的或者了解不深的,后期需要系统学习一下
Linux命令收集
# 查看子网掩码
ip route show
# 查看进程
ps -ef|grep node_exporter
# 查看端口
netstat -tunlp|grep node_exporter
#查看软件商是否存在
rpm -qa|grep mariadb
# 查看CPU核数
cat /proc/cpuinfo| grep "processor"| wc -l
#查看内存大小
free -h
# 查看磁盘信息
df -h
# 关闭防火墙
systemctl stop firewalld.service
# 禁用防火墙开机自启
systemctl disable firewalld.service
# 检查防火墙状态
systemctl status firewalld.service
# 临时生效,但重启服务器后失效(禁用selinux)
setenforce 0
# 永久生效,但需要重启服务器(禁用selinux)
vim /etc/selinux/config
# 调整为disabled(禁用selinux)
SELINUX=disabled
#修改磁盘io调度
grubby --update-kernel=ALL --args="elevator=deadline"
#禁用透明页
grubby --update-kernel=ALL --args="transparent_hugepage=never"
#对象删除
cd /etc/systemd/logind.conf
# 修改配置,取消注释,调整为no,保存退出
RemoveIPC=no
# 重启服务,使修改生效
systemctl restart systemd-logind
# 修改机器名
hostnamectl set-hostname 机器名
# 修改后切换用户,查看机器名是否修改正确
su
# 修改host文件
vim /etc/hosts
# 将服务器机器名增加至hosts文件中,之后保存退出即可
192.168.181.144 bdp-server
#服务器免密
ssh-keygen -t rsa
#将公钥内容写入到authorized_keys文件中
cd ~/.ssh/
cat id_rsa.pub >> authorized_keys
#将本地公钥复制到远程服务器
ssh-copy-id -i 机器名
# 重新加载服务配置
systemctl daemon-reload
# 启动服务
systemctl start ntpd
# 服务开机自启
systemctl enable ntpd
# 查看服务状态
systemctl status ntpd
# 使用系统服务停止服务
systemctl stop zookeeper
# 解压
rpm -ivh jdk-8u241-linux-x64.rpm
tar -zxvf prometheus-2.17.2.linux-amd64.tar.gz
unzip nginx.zip
#启动bdp-server/executor/realtime
cd /app/bdp/bdp-server
sh bin/start.sh
tail -200f logs/bdp-server.log我把文档里觉得有用常用的Linux命令集合在一起,方便我后期多加熟悉和练习,少复制多敲!!!
遇到的bug
bug1
报错信息
zookeeper服务起不来
报错原因
由于电脑配置有限,只开启了五台服务器,所以把bdp-executor和bdp-realtime放在一起,共开三台虚拟机,每一台服务器配置了bdp-executor和bdp-realtime,后面zookeeper服务起不来,最后发现是confluent里面zookeeper和bdp-executor里的zookeeper冲突了
解决办法
最后解决办法是bdp-executor的zookeeper不用了,bdp-executor和bdp-realtime都用confluent里面zookeeper
bug2
报错信息
zookeeper启动后秒挂,反正就是跑步起来,检查配置文件也没有问题
报错原因
由于在配置kafka的时候broker.id=1使用的是XShell的批量修改,导致三个集群的kafka都是broker.id=1,然后我启动了,启动后报错,检查发现配置文件错误,然后又修改了配置文件,改成了正确的配置,但是由于启动了kafka,所以这些错误的配置文件就注册到了zookeeper和kafka的缓存里,
后面虽然修改成正确的配置文件 ,但是由于已经注册到了zookeeper和kafka的缓存里,导致zookeeper里的配置和后面修改后的新的配置不同,zookeeper就挂掉了
解决办法
删掉zookeeper里注册的信息和kafka的本地缓存,然后重启即可
bug3
报错信息
org.pentaho.di.core.exception.KettleException:
org.pentaho.di.core.exception.KettleDatabaseException:
Couldn't execute SQL: LOAD DATA LOCAL INFILE '/tmp/9efa05b987b846728da85793a6dc131d' INTO TABLE `temp_2aeadf472f5cc5a1` 报错原因
权限不足
解决办法
show GLOBAL VARIABLES like 'local_infile';
set GLOBAL local_infile='off';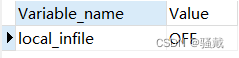
把local_infile改成off即可
bug4
报错信息
在测试批数据同步配置的时候发现运行后就卡在那里,没有继续执行,直接跳到最后断开日志,然后卡死
报错原因
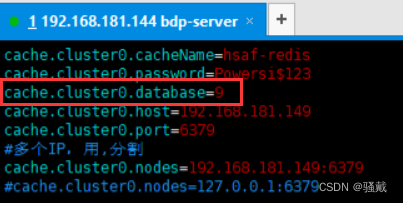
在bdp-server的conf/config/cache/cache.properties配置中,缓存配置中的下面标出的这一行配置要和bdp-executor-realtime123这三个的缓存配置要保持一致,这里我都设置为9
解决办法
把bdp-server和bdp-executor-realtime123的cache.properties中的cache.cluster0.database都改成9,保证一致即可
bug5
报错信息
在测试实时数据同步上线的时候报错,报错一大堆,上线失败
报错原因
数据库的时区和系统的时区不一致导致的
解决办法
在本地的数据库中执行set global time_zone='+8:00'来修改mysql全局时区为北京时间,也就是我们所在的东8区
bug6
报错信息
某次打开虚拟机的时候,发现输入ip a后没有en33的ip,简单来说就是ip不见了,但是之前明明存在,突然消失
报错原因
可能是隐藏或者IPADDR配置项失效
解决办法

识别所有网络接口
sudo dhclient ens33
查看ip地址
sudo ifconfig ens33
最后输入ip a即可bug7
报错信息
在bug6的操作后发现ip地址变了,不是我之前的那个ip
报错原因
linux默认是自动获取ip,所以在每次重启虚拟机的时候IP地址都会换,可能是IP地址由DHCP自动分配
解决办法
#修改配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33

修改配置文件的 BOOTPROTO为static(表示使用静态ip),然后下面追加指定的ip地址,然后使用 service network restart或者systemct restart network刷新网络,这里可能还会报错
Restarting network (via systemctl): Job for network.service failed because the control process exited with error code.
See "systemctl status network.service" and "journalctl -xe" for details. 使用systemctl status network.service命令查看错误详情
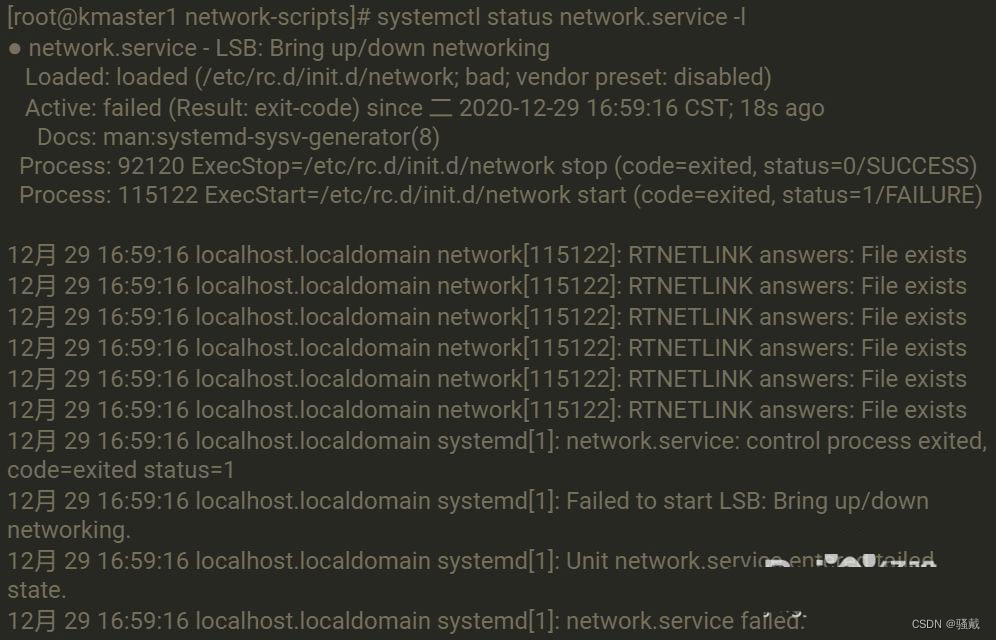
出现这种报错一般是和 NetworkManager 服务冲突导致的(network和NetworkManager一起工作时就会出现冲突),直接关闭 NetworkManger 服务就好了, service NetworkManager stop,并且禁止开机启动 systemctl disable NetworkManager(一定要记得关闭自启动,不然下次开机后又是老样子)
NetworkManager 的相关命令:
查看运行状态:systemctl status NetworkManager
启动:systemctl start NetworkManager
重启:systemctl restart NetworkManager
关闭:systemctl stop NetworkManager
查看是否开机启动:systemctl is-enabled NetworkManager
开机启动:systemctl enable NetworkManager
禁止开机启动:systemctl disable NetworkManager部署文档存在的错误
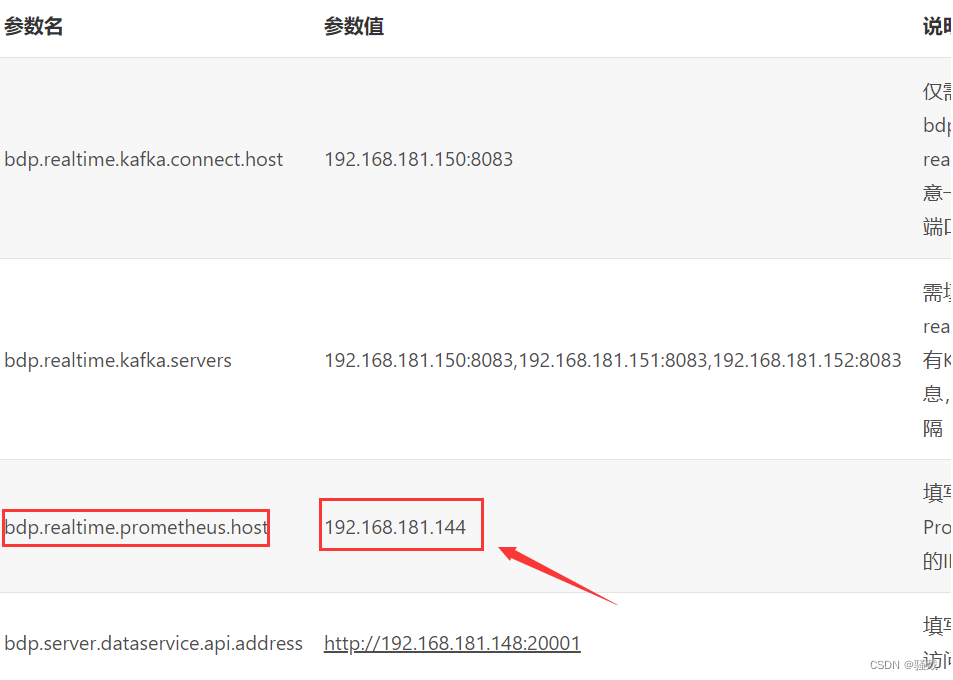
在初始化mysql的时候,需要修改表bdp_sys_para的值,如下图prometheus的参数值错了,应该是192.168.181.148(已经和峰少说过)

总结
本次搭建大数据平台,发现自己的Linux命令有很多都不熟练,然后意识到Linux对于学大数据的人来说的重要性,因为大数据集群都是搭建在Linux上,而Linux的命令是灵魂,所以多敲少复制!
在搭建的过程中,遇到了很多的bug和错误,发现自己再处理这些错误的时候第一反应就是复制到百度上一顿乱搜,这是老毛病,后面需要慢慢的培养自己遇到问题先思考-->看日志-->百度-->找峰少或者严胜救援
知道如何搭建大数据平台,了解大数据平台的组件、大数据平台的组成部分及其作用等等,更加熟悉了大数据平台的功能,意识到自己的不足之处,技术栈的缺乏,专业能力的不足,还有很大的提升空间!