系列文章目录
第一章 ArrayList-Java八股面试(一)
第二章 HashMap-Java八股面试(二)
第三章 单例模式-Java八股面试(三)
第四章 线程池和Volatile关键字-Java八股面试(四)
提示:动态每日更新算法题,想要学习的可以关注一下
文章目录
- 系列文章目录
- 一、ConcurrentHashMap是什么?
- 1 jdk1.7
- 1. put方法
- 2. HashEntry扩容
- 3 Segment的数量和下标的计算
- 4.HashEntry的初始化
- 5.HashEntry的下标计算
- 2. jdk1.8
- 1. 扩容机制
- 2. 初始化机制(capacity和factor)
- 3. put方法
- 4. 扩容机制
- 5. 扩容时的put和get操作
- 总结和细节
- 1.JDK1.7 与 JDK1.8 中ConcurrentHashMap 的区别
- 2.ConcurrentHashMap 的并发度是什么?
- 3. ConcurrentHashMap 迭代器是强一致性还是弱一致性
- 4.ConcurrentHashMap 和 Hashtable 的效率哪个更高?为什么?
一、ConcurrentHashMap是什么?
1 jdk1.7
JDK1.7 中的 ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成,即 ConcurrentHashMap 把哈希桶数组切分成小数组(Segment ),每个小数组有 n 个 HashEntry 组成。
和普通的HashMap相比,ConcurrentHashMap其实就解决了多线程下安全的问题,其构造和HashMap相差不大,也是需要计算二次哈希值,唯一需要说明的是segment下标和小数组的问题。

Segment的数量决定了ConcurrentHashMap的并发度,因为在同一时刻只有一把锁可以访问,一旦Segment初始化之后就无法扩容,能扩容的是Segment下面的小数组。
而每个小数组则是HashEntry。
1. put方法
每一个元素先进行二次哈希值的计算,然后计算得到Segment下标,而后再进算桶下标,最后会以头插法的方式加入到链表中。

2. HashEntry扩容
一旦HashEntry下的节点个数大于HashEntry数量的3/4时就会发生扩容
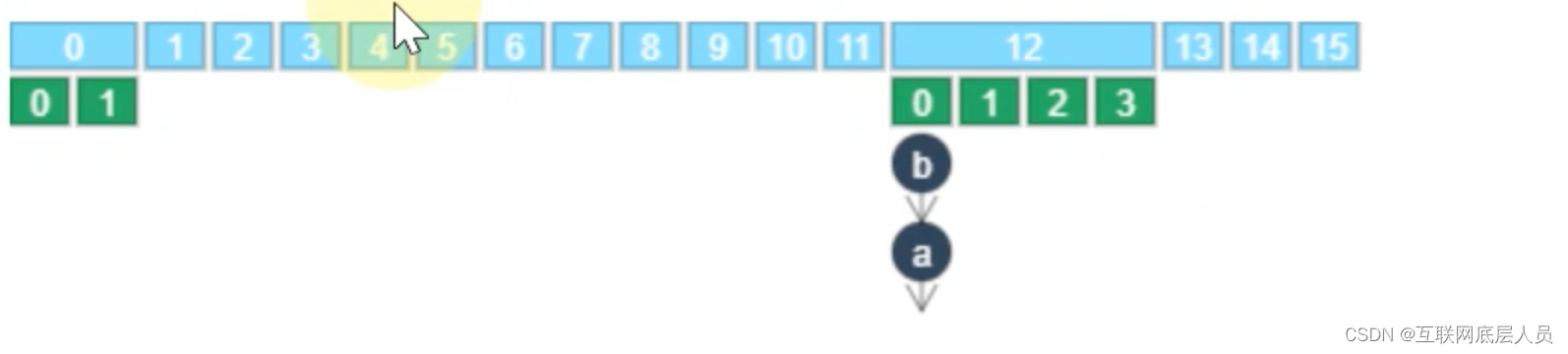
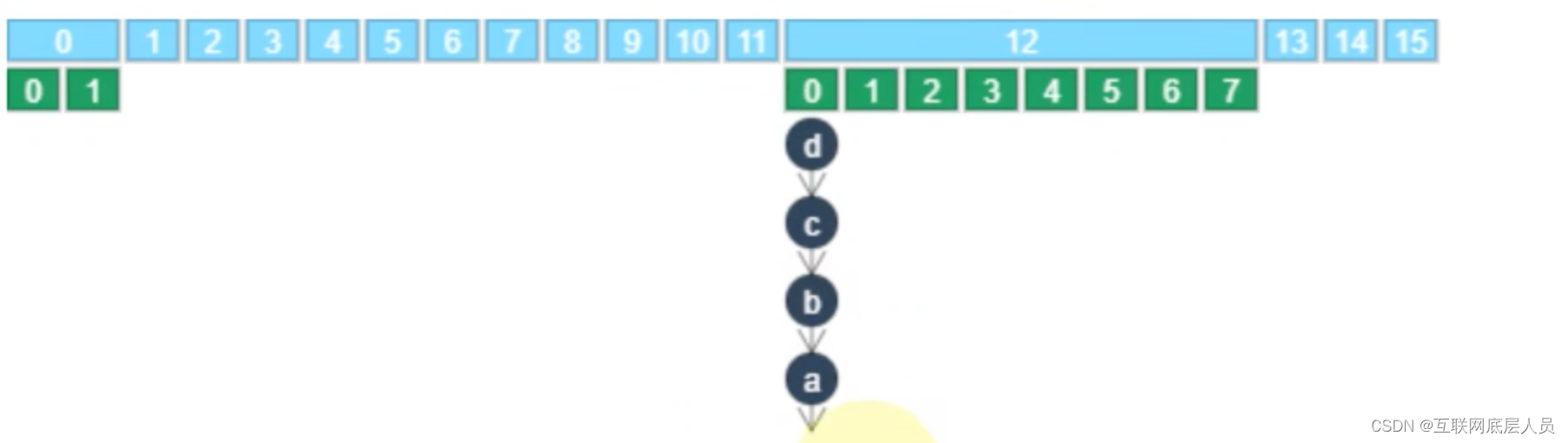
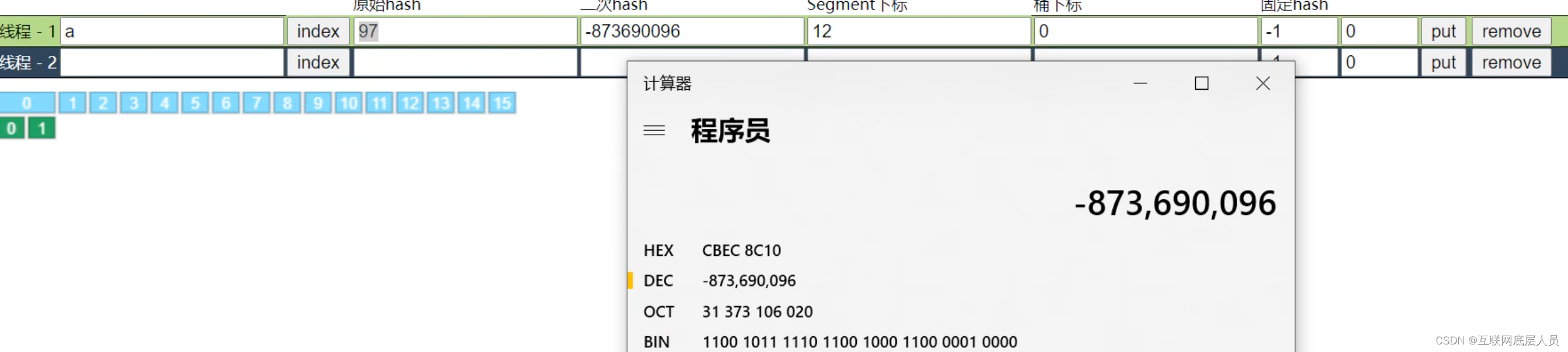
3 Segment的数量和下标的计算
segment的数量是初始化时给的参数(clevel).
而segment的下标计算时根据如下图所示是二次哈希值的二进制编码的高4位得出12。
4.HashEntry的初始化
一旦初始化ConcurrentHashMap后,第一个HashEntry也会随之初始化,HashEntry的数量计算时:capacity/Segment(clevel),当然最小为2.第一次创建之后这个也就会作为模板,后面任意一个Segment对HashEntry初始化时都会以这个长度,而不是第一个HashEntry扩容后的长度(此时的长度)。注意这里的capacity只在这一步计算中用到,我们看到的数组长度其实是segment的长度。

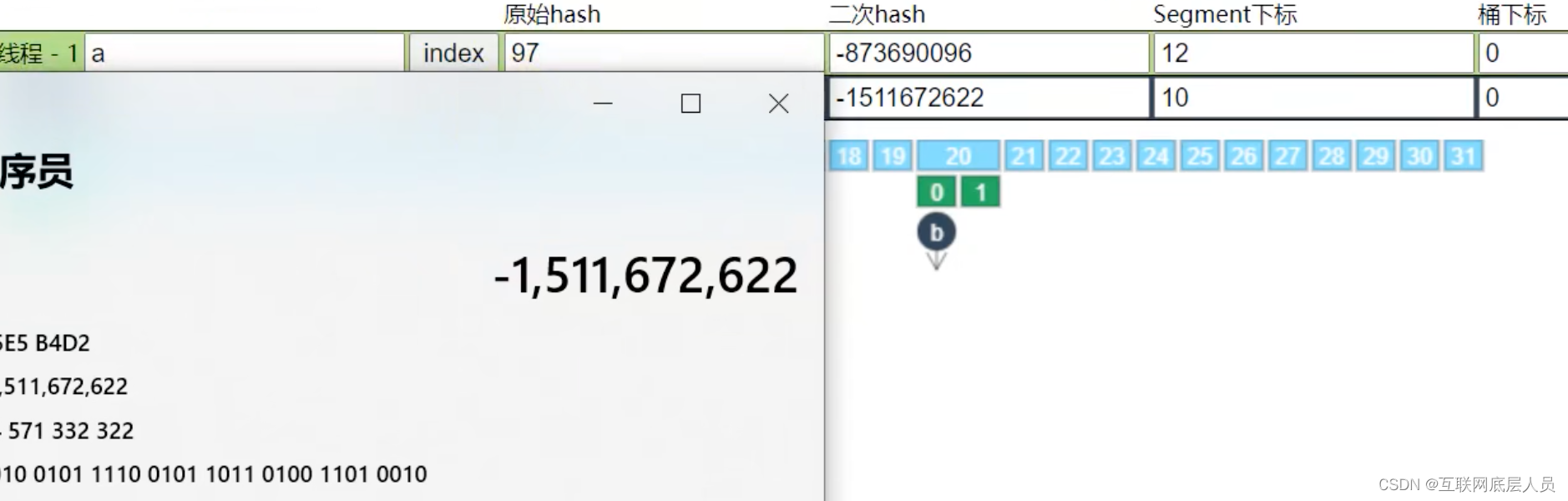
5.HashEntry的下标计算
二次哈希值的二进制编码的最低位,如下图为0,则在索引为0的地方。
2. jdk1.8
与jdk1.7不同的是没有了Segment,也没有了HashEntry,和原始的HashMap在结构上有一些类似。初始化方式为懒汉式,只有在调用时才会初始化整个ConcurrentHashMap.在数据结构上, JDK1.8 中的ConcurrentHashMap 选择了与 HashMap 相同的Node数组+链表+红黑树结构;在锁的实现上,抛弃了原有的 Segment 分段锁,采用CAS + synchronized实现更加细粒度的锁。
将锁的级别控制在了更细粒度的哈希桶数组元素级别,也就是说只需要锁住这个链表头节点(红黑树的根节点),就不会影响其他的哈希桶数组元素的读写,大大提高了并发度。
1. 扩容机制
与1.7不同的是,当容量到达3/4时就会发生扩容,而不是超过3/4。

2. 初始化机制(capacity和factor)
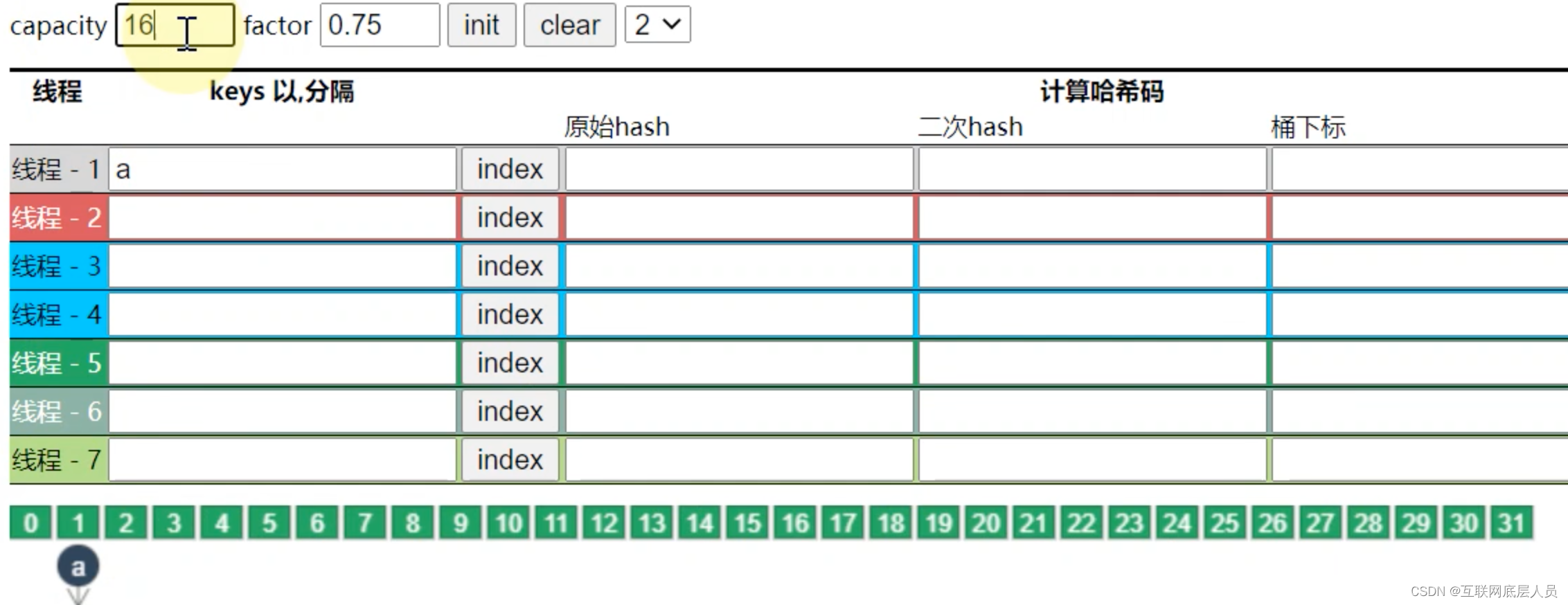
capacity的意思并不再指初始化数组的容量,而是指一开始会往ConcurrentHashMap中放几个元素。
如上图所示,放16个元素,扩容因子为3/4,假如map长度为16,那么长度在12就会扩容,因此还需要在16的基础上继续扩容成32.尽管capacity设置为16,但并不意味着必须要放16个元素,并且capacity和factor只会在第一次初始化时有效。后续就算factor设置为0.5或者其他值,都是按默认的0.75计算。
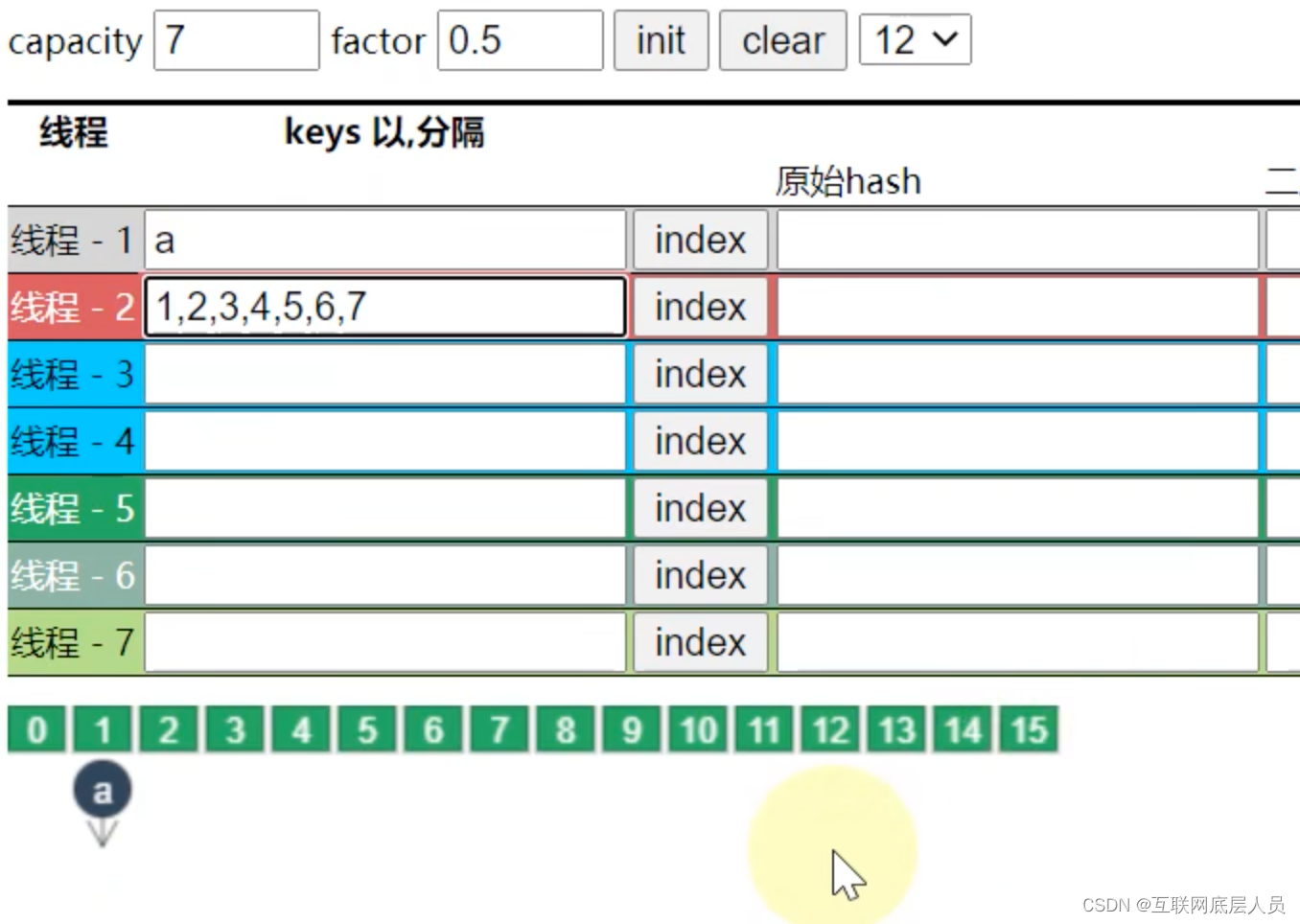
值得说明的是,ConcurrentHashMap的容量只能是2的n次方。如上所示放7个元素,那么先考虑8是否能行,因为factor为0.5,所以必须要扩容成16.
3. put方法
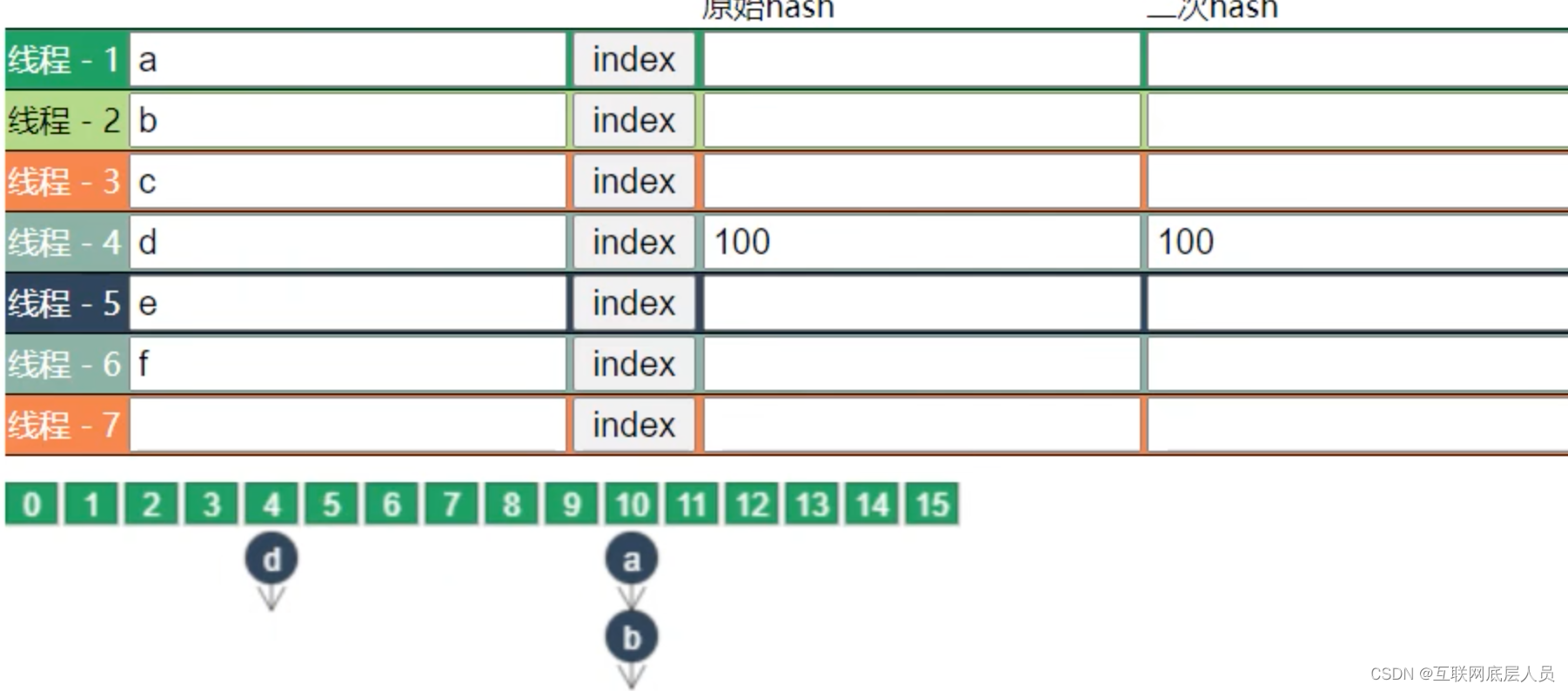
根据二次哈希值先定位到数组索引处,然后占锁,再进行put。数组的大小决定了
ConcurrentHashMap的并发度,也就是说不同索引的Node互不干扰,d的put和ab的put互不影响。但是a和b的put需要占锁释放锁的步骤。
4. 扩容机制
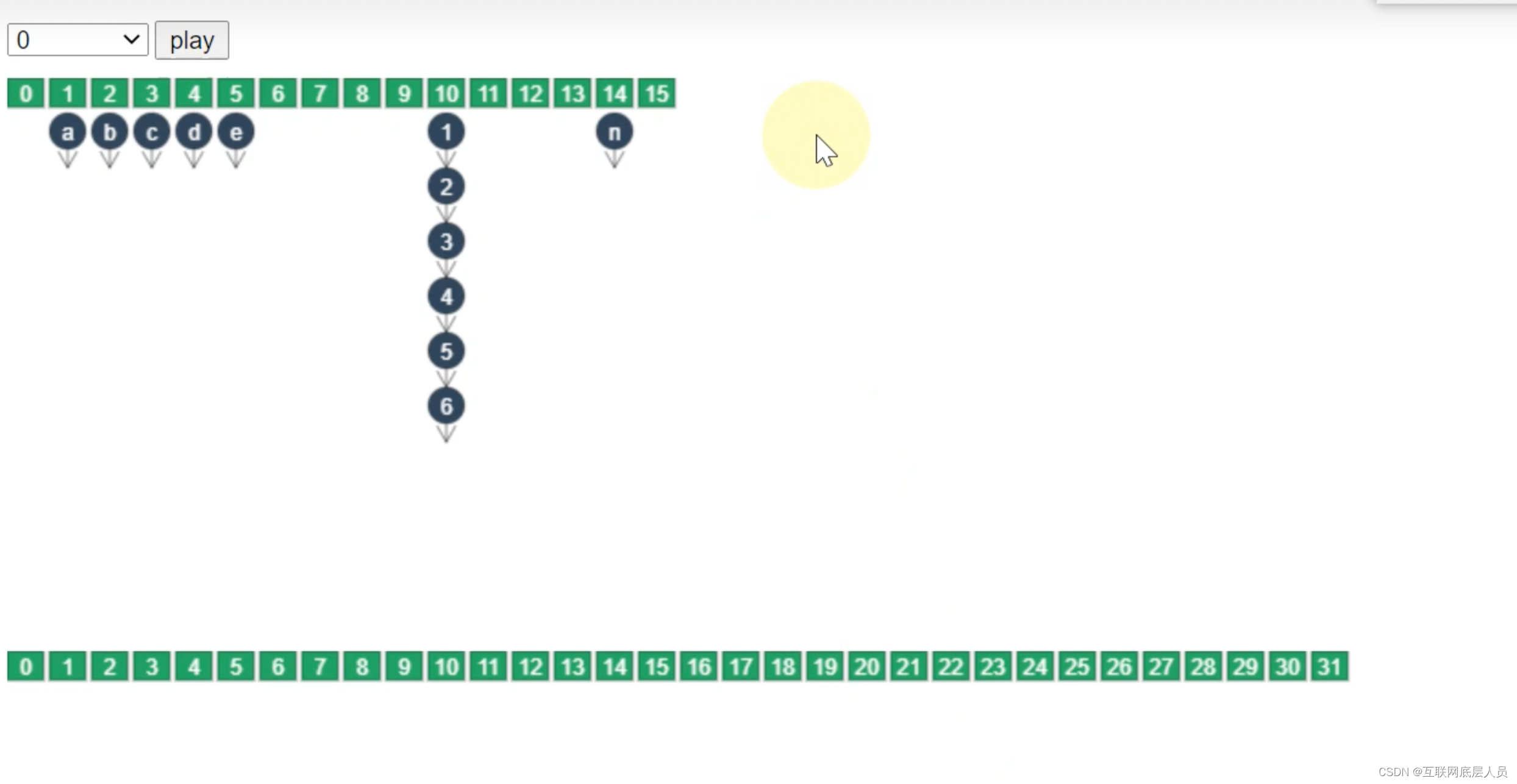
假设n为临界节点,也就是put了n之后就会扩容,与数组方式相同,新建一个容量为2倍的新数组,然后进行数据迁移。
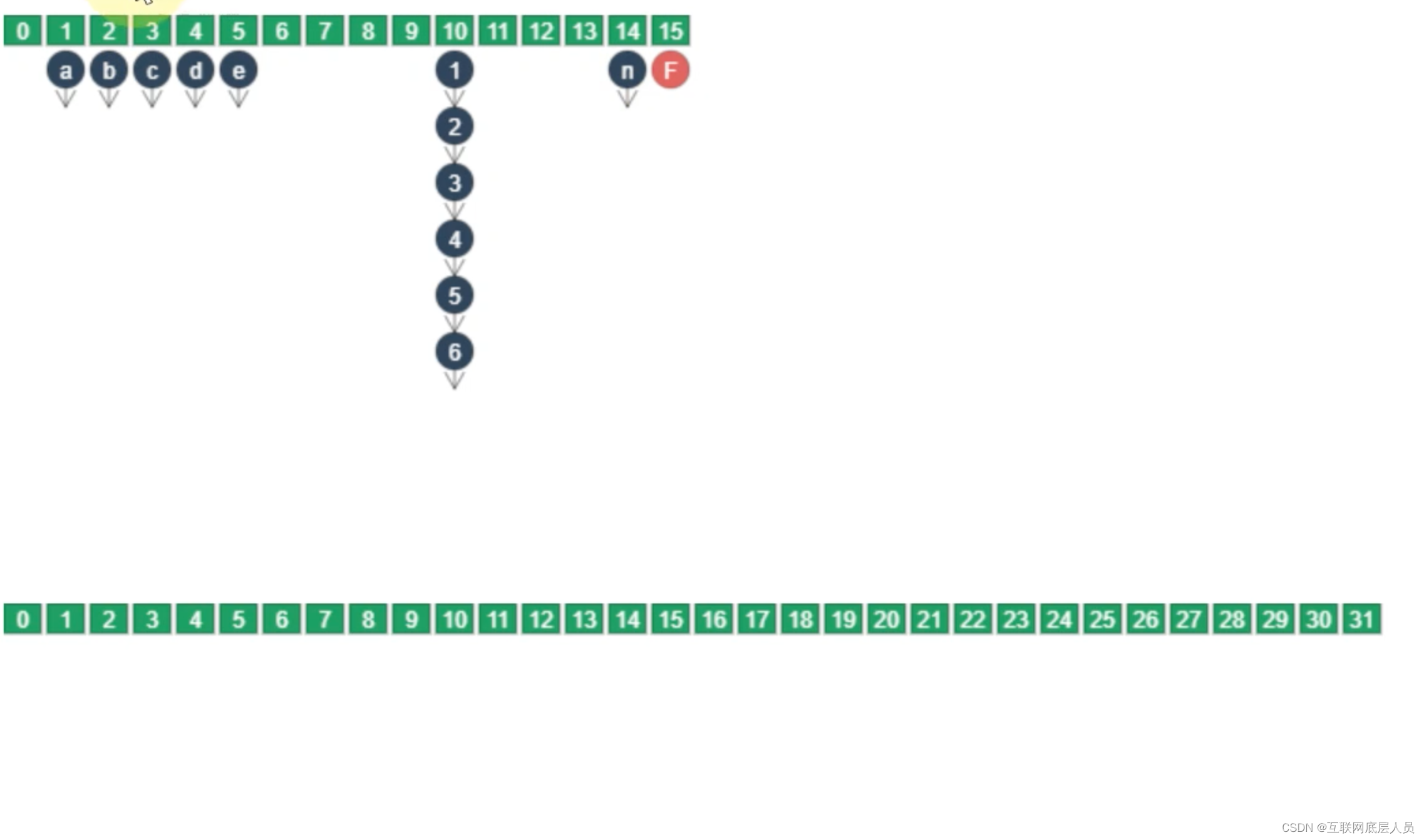
迁移顺序是从后往前进行迁移,每次迁移一个索引的链表或者红黑树。一旦该索引处完成迁移,就会变成Forwarding Node 认为是已完成的Node。
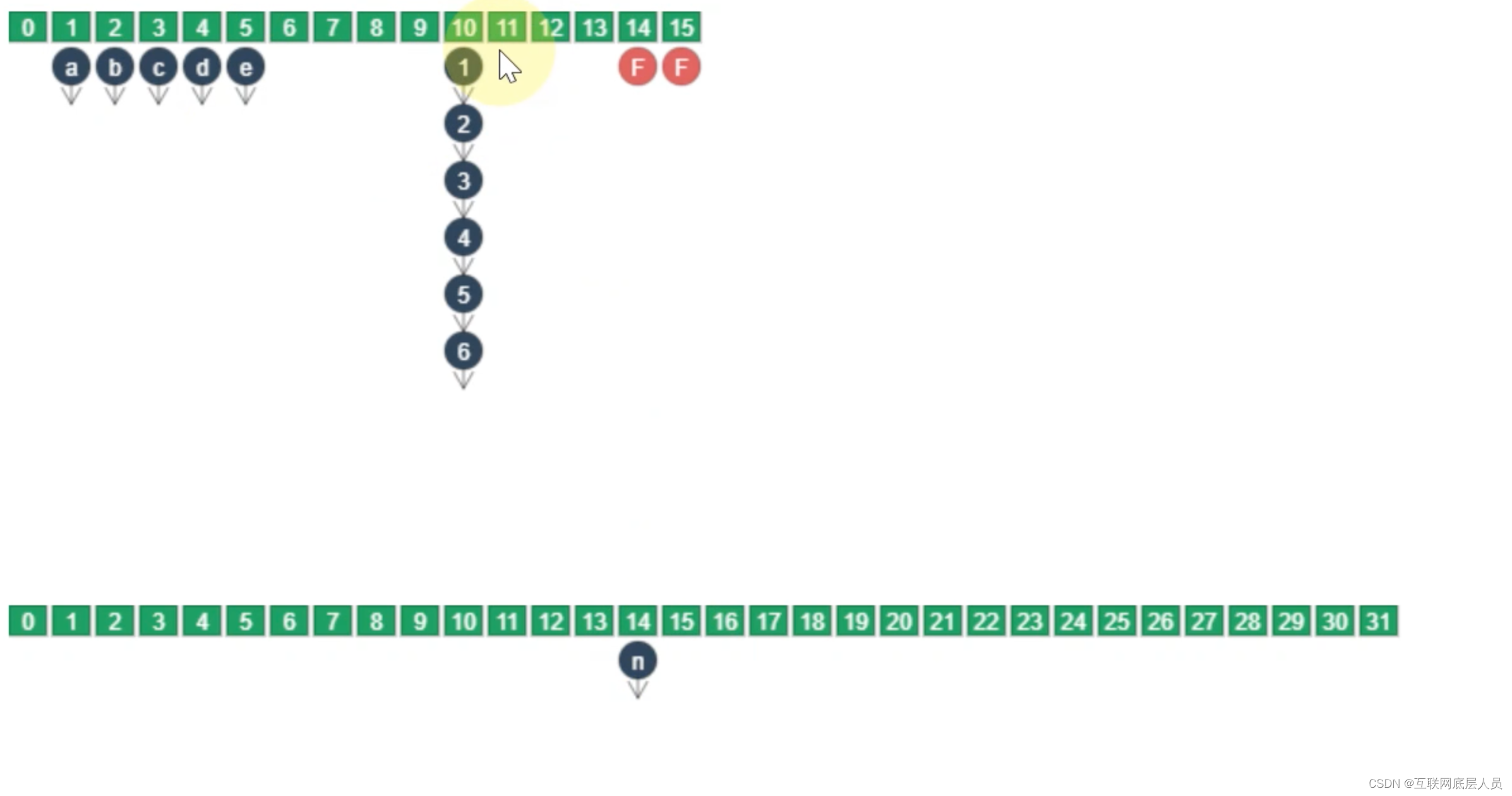
在迁移过程中,需要重新计算二次哈希值,一般情况下会重新创建新的节点,并将该节点插入新的数组中。
在这里为什么需要重新创建新的节点需要说明一下,如上图1这个节点的next指针为2,一旦哈希值重新计算之后,在新的数组中,它的next不一定是2.
当然也有一种情况可以直接引用,不需要再创建节点的情况就是,比如说456三个节点,在新的数组中仍然是该顺序情况,那么就不需要新创建节点。
5. 扩容时的put和get操作
- get的索引在forwarding node之前
那么正常get,并不会影响。
2.get的索引已经变成forwarding
那么直接去新数组中取得get
3.get的索引正在迁移
由上所述,因为扩容之后的节点的next指针可能会变化,所以该线程会等待该索引完成迁移查询新的节点。
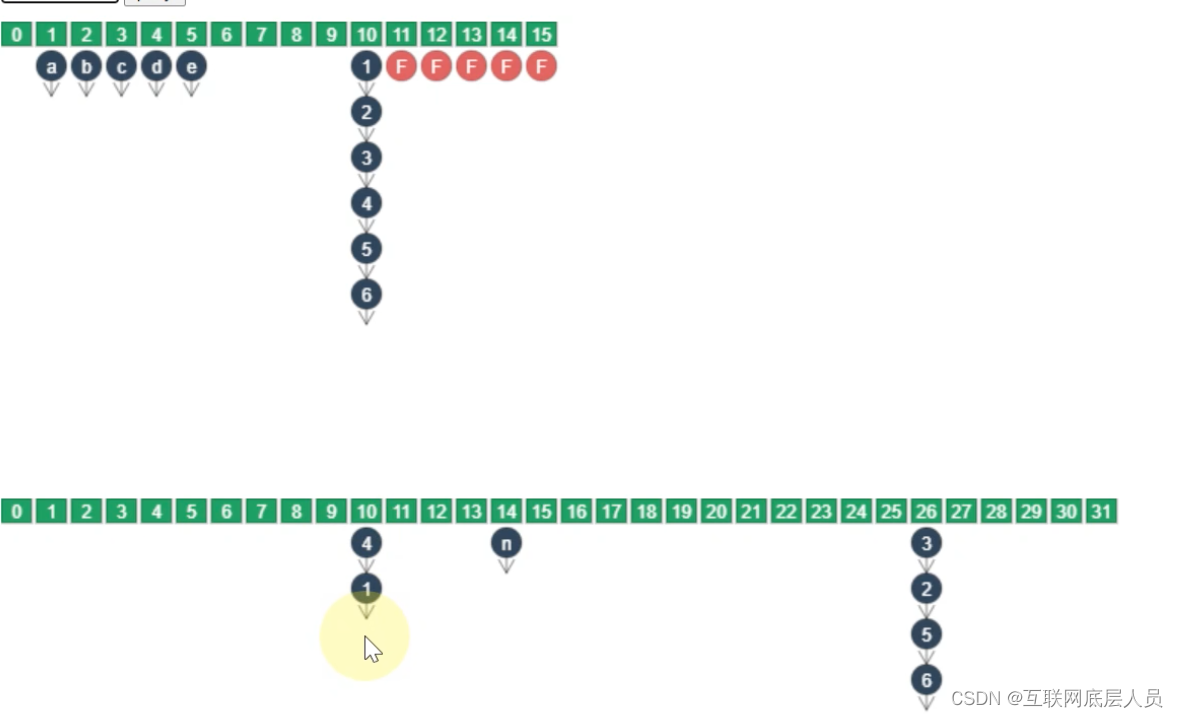
- put的索引在forwarding node之前
同样,正常的并发执行。
2.put的索引已经变成forwarding node
线程会阻塞并帮助前面的node一起进行迁移,因为新的节点只有在所有旧的节点都完成迁移之后才能进行put,这时线程就会帮助前面未完成的索引一起进行迁移。
3.put的索引正在迁移
只能阻塞。
总结和细节
1.JDK1.7 与 JDK1.8 中ConcurrentHashMap 的区别
数据结构:取消了 Segment 分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
保证线程安全机制:JDK1.7 采用 Segment 的分段锁机制实现线程安全,其中 Segment 继承自 ReentrantLock 。JDK1.8 采用CAS+synchronized保证线程安全。
锁的粒度:JDK1.7 是对需要进行数据操作的 Segment 加锁,JDK1.8 调整为对每个数组元素加锁(Node)。
链表转化为红黑树:定位节点的 hash 算法简化会带来弊端,hash 冲突加剧,因此在链表节点数量大于 8(且数据总量大于等于 64)时,会将链表转化为红黑树进行存储。
查询时间复杂度:从 JDK1.7的遍历链表O(n), JDK1.8 变成遍历红黑树O(logN)。
2.ConcurrentHashMap 的并发度是什么?
并发度可以理解为程序运行时能够同时更新 ConccurentHashMap且不产生锁竞争的最大线程数。在JDK1.7中,实际上就是ConcurrentHashMap中的分段锁个数,即Segment[]的数组长度,默认是16,这个值可以在构造函数中设置。
在JDK1.8中,已经摒弃了Segment的概念,选择了Node数组+链表+红黑树结构,并发度大小依赖于数组的大小。
3. ConcurrentHashMap 迭代器是强一致性还是弱一致性
与 HashMap 迭代器是强一致性不同,ConcurrentHashMap 迭代器是弱一致性。
ConcurrentHashMap 的迭代器创建后,就会按照哈希表结构遍历每个元素,但在遍历过程中,内部元素可能会发生变化,如果变化发生在已遍历过的部分,迭代器就不会反映出来,而如果变化发生在未遍历过的部分,迭代器就会发现并反映出来,这就是弱一致性。
4.ConcurrentHashMap 和 Hashtable 的效率哪个更高?为什么?
ConcurrentHashMap 的效率要高于 Hashtable,因为 Hashtable 给整个哈希表加了一把大锁从而实现线程安全。而ConcurrentHashMap 的锁粒度更低,在 JDK1.7 中采用分段锁实现线程安全,在 JDK1.8 中采用CAS+synchronized实现线程安全。