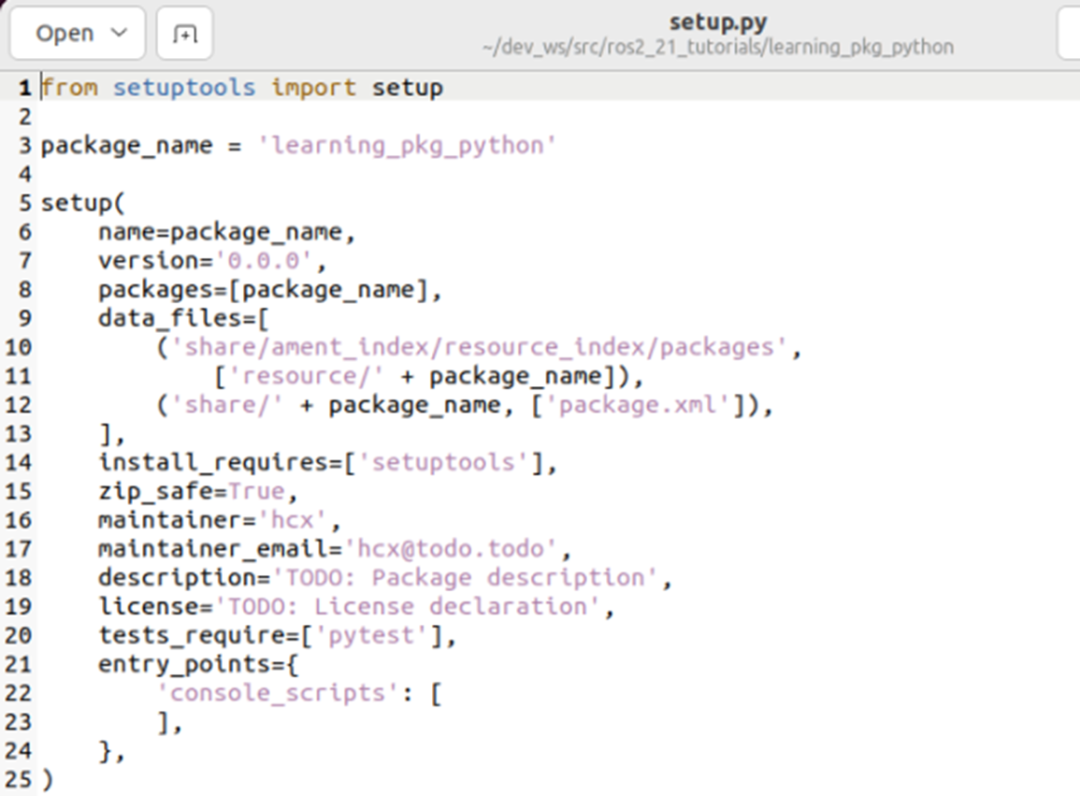
深度学习 Day26——利用Pytorch实现天气识别
文章目录
- 深度学习 Day26——利用Pytorch实现天气识别
- 一、前言
- 二、我的环境
- 三、前期工作
- 1、导入依赖项和设置GPU
- 2、导入数据
- 3、划分数据集
- 四、构建CNN网络
- 五、训练模型
- 1、设置超参数
- 2、编写训练函数
- 3、编写测试函数
- 4、正式训练
- 六、结果可视化
- 七、模型识别
一、前言
🍨 本文为🔗365天深度学习训练营 中的学习记录博客
🍦 参考文章:Pytorch实战 | 第P3周:彩色图片识别:天气识别
🍖 原作者:K同学啊|接辅导、项目定制

刚经过了期末考试周,然后最近也比较忙,时间还是很紧凑,需要更加高效才行,废话不多说,我们开始本周的深度学习之旅。
本期博客我们将使用谷歌旗下的colab机器学习云平台,这也是我经常使用的平台,感觉很不错,感兴趣的朋友可以去试试(需要魔法才能访问)机器的配置我就放在下面了。
二、我的环境

三、前期工作
1、导入依赖项和设置GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torchvision import transforms, datasets
import os,PIL,pathlib
torch是PyTorch的核心库torch.nn是神经网络模块,包括定义各种神经网络层和激活函数torchvision.transforms包含了各种图像处理工具torchvision.datasets包含了一些常用的数据集,如CIFAR10、MNIST等os是Python中的一个操作系统接口模块,可以处理文件和目录PIL(Python Imaging Library)是Python的一个图像处理库pathlib是Python 3中新添加的一个面向对象的文件路径库,可以方便地处理文件和目录路径。
然后判断当前设备是否支持CUDA(即GPU加速),如果支持则使用CUDA,否则使用CPU。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device(type='cuda')
2、导入数据
定义数据所在文件夹的路径,将数据所在文件夹的路径转换为pathlib.Path对象,方便后续处理,然后获取数据文件夹中所有文件的路径,使用glob(‘*’)可以匹配文件夹中的所有文件,最后将数据文件夹中的所有类别名称提取出来,存储在classeNames列表中。这里使用了列表解析式,遍历data_paths中的每个文件路径,将其转换为字符串类型并使用split()方法将其按照“/”分隔,然后取得分隔后的第9个元素(从0开始计数),即类别名称。最后将类别名称存储在classeNames列表中。
import random
data_dir = '/content/drive/Othercomputers/我的笔记本电脑/深度学习/data/weather_photos/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split('/')[8] for path in data_paths]
classeNames
['cloudy', 'rain', 'shine', 'sunrise']
然后我们定义数据集所在的总文件夹路径,定义数据集的数据转换方式,将Resize()函数用于将输入图片resize成统一尺寸,ToTensor()函数用于将PIL Image或numpy.ndarray转换为tensor,并将像素值归一化到[0,1]之间,Normalize()函数用于将tensor标准化处理,转换为标准正太分布(高斯分布),从而使模型更容易收敛。其中mean和std分别表示从数据集中随机抽样计算得到的均值和标准差。使用datasets.ImageFolder()函数创建数据集,total_datadir表示数据集所在的总文件夹路径,transform参数表示使用train_transforms数据转换方式对数据进行转换。最终得到的total_data为一个ImageFolder对象,包含了数据集中的所有图片和标签信息。
total_datadir = '/content/drive/Othercomputers/我的笔记本电脑/深度学习/data/weather_photos/'
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
total_data
Dataset ImageFolder
Number of datapoints: 1125
Root location: /content/drive/Othercomputers/我的笔记本电脑/深度学习/data/weather_photos/
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
3、划分数据集
然后我们将导入的数据进行划分数据集,计算训练集大小,将数据集总数的80%作为训练集大小。计算测试集大小,将数据集总数减去训练集大小得到测试集大小。最后使用torch.utils.data.random_split()函数将数据集分为训练集和测试集,total_data表示需要被分割的数据集,[train_size, test_size]表示分割后训练集和测试集的大小,train_dataset和test_dataset分别表示分割后的训练集和测试集。该函数可以随机地将数据集划分为训练集和测试集,比较适用于小数据集。
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
打印训练集和测试集的尺寸。
train_size,test_size
(900, 225)
然后我们设置每次训练时输入的数据批次大小,这里设置为32,即每次输入32张图片进行训练。然后使用torch.utils.data.DataLoader()函数创建训练集的数据加载器train_dl。其中train_dataset表示需要加载的数据集,batch_size表示每次输入的数据批次大小,shuffle=True表示打乱数据集顺序,num_workers=1表示使用一个进程来加载数据。最后使用torch.utils.data.DataLoader()函数创建测试集的数据加载器test_dl。其中test_dataset表示需要加载的数据集,batch_size表示每次输入的数据批次大小,shuffle=True表示打乱数据集顺序,num_workers=1表示使用一个进程来加载数据。注意到这里使用了和训练集相同的batch_size大小和相同的shuffle选项来保证训练和测试时的一致性。
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_workers=1)
使用test_dl数据加载器遍历测试集的数据,每次加载一个批次的数据,其中X表示图片数据,y表示图片标签。打印当前批次的图片数据X的形状,其中N表示批次大小,C表示通道数,H表示图片的高度,W表示图片的宽度。最后打印当前批次的标签数据y的形状和数据类型dtype。
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
Shape of X [N, C, H, W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
四、构建CNN网络
我们定义一个名为"Network_bn"的神经网络模型,继承自nn.Module类。该模型包括多个卷积层和批标准化层以及全连接层,最终输出分类的预测值。在这个模型中,激活函数使用了ReLU函数。同时,还定义了一个forward()函数来定义数据如何通过该神经网络进行前向传播。最后,将该模型移动到GPU上进行运算,并打印出使用的设备(CPU或GPU)。最后一行代码返回创建的模型。
import torch.nn.functional as F
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
"""
nn.Conv2d()函数:
第一个参数(in_channels)是输入的channel数量
第二个参数(out_channels)是输出的channel数量
第三个参数(kernel_size)是卷积核大小
第四个参数(stride)是步长,默认为1
第五个参数(padding)是填充大小,默认为0
"""
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.pool2 = nn.MaxPool2d(2,2)
self.conv6 = nn.Conv2d(in_channels=24, out_channels=48, kernel_size=5, stride=1, padding=0)
self.bn6 = nn.BatchNorm2d(48)
self.conv7 = nn.Conv2d(in_channels=48, out_channels=48, kernel_size=5, stride=1, padding=0)
self.bn7 = nn.BatchNorm2d(48)
self.pool3 = nn.MaxPool2d(2,2)
self.fc1 = nn.Linear(48*21*21, len(classeNames))
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = F.relu(self.bn6(self.conv6(x)))
x = F.relu(self.bn7(self.conv7(x)))
x = self.pool(x)
x = x.view(-1, 48*21*21)
x = self.fc1(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = Network_bn().to(device)
model
Using cuda device
Network_bn(
(conv1): Conv2d(3, 12, kernel_size=(5, 5), stride=(1, 1))
(bn1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1))
(bn2): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv4): Conv2d(12, 24, kernel_size=(5, 5), stride=(1, 1))
(bn4): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv5): Conv2d(24, 24, kernel_size=(5, 5), stride=(1, 1))
(bn5): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv6): Conv2d(24, 48, kernel_size=(5, 5), stride=(1, 1))
(bn6): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv7): Conv2d(48, 48, kernel_size=(5, 5), stride=(1, 1))
(bn7): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=21168, out_features=4, bias=True)
)
这个模型我在K老师的基础上添加了两层卷积层和两层池化层。
然后我们再使用上期博客提到的网络结构可视化库torchviz来将我们上面的网络结构画出来。
import torchviz
model = Network_bn()
torchviz.make_dot(model(torch.randn(1, 3, 224, 224)), params=dict(model.named_parameters()))

图片比较模糊,见谅。
五、训练模型
1、设置超参数
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
nn.CrossEntropyLoss()是交叉熵损失函数,用于计算模型输出和目标值之间的差异。在分类问题中,交叉熵损失函数常常被使用。
learn_rate = 1e-4定义了学习率,用于控制模型参数更新的速度。学习率越大,模型参数更新的幅度就越大,训练速度也会加快。但是,如果学习率过大,模型可能会发散,导致训练失败。
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)定义了优化器,这里使用了随机梯度下降(SGD)优化器。优化器的作用是根据损失函数的梯度信息来更新模型参数,使得模型能够更好地拟合训练数据。model.parameters()表示需要更新的参数集合,lr=learn_rate表示学习率为learn_rate。
2、编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
在上面函数中:
size变量存储训练数据集的大小,这里是60000张图片。num_batches变量存储批处理数据的数量,即将整个数据集分成的批次数量,这里是1875个(每个批次的大小为32)。train_loss和train_acc变量分别用于记录训练损失和正确率,它们的初始值为0。- 循环遍历数据加载器
dataloader,在每一次循环中,将图像和标签数据加载到设备中(如果GPU可用)。 pred变量包含通过模型处理后的输出结果,loss变量包含通过计算pred与真实标签值y之间差异得到的损失值。optimizer.zero_grad()调用将梯度属性清零。loss.backward()根据损失反向传播,计算梯度值。optimizer.step()在每次循环迭代中自动更新模型参数。train_acc变量记录每个批次中正确分类的数量。train_loss变量存储每个批次中的损失值。- 计算训练集的平均正确率和平均损失,并将其返回作为训练循环的输出。
3、编写测试函数
测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器。
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0 # 初始化测试损失和正确率
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader: # 获取测试图片及其标签
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs) # 网络输出
loss = loss_fn(target_pred, target) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
test_loss += loss.item() # 累加测试损失
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item() # 累加测试正确率
test_acc /= size # 计算平均测试正确率
test_loss /= num_batches # 计算平均测试损失
return test_acc, test_loss
4、正式训练
接下来我们将设置训练参数和正式训练,并在最后训练结果保存下来方便后续调用模型。
# 设置训练的轮数为50次
epochs = 50
# 初始化存储训练集正确率、训练损失、测试集正确率、测试集损失的列表
train_loss = []
train_acc = []
test_loss = []
test_acc = []
# 开始训练循环
for epoch in range(epochs):
# 训练模式下进行训练
model.train()
# 计算当前轮的训练集正确率和训练损失
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
# 测试模式下进行测试
model.eval()
# 计算当前轮的测试集正确率和测试损失
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
# 将当前轮的正确率和损失添加到对应的列表中
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 打印当前轮的正确率和损失
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
saveFile = os.path.join('epoch'+str(epochs)+'.pkl')
torch.save(model.state_dict(), saveFile)
因为我调整过网络结构所以在K老师的基础上我增加了训练轮数,具体训练结果如下:
Epoch: 1, Train_acc:51.7%, Train_loss:1.146, Test_acc:49.3%,Test_loss:1.187
Epoch: 2, Train_acc:71.1%, Train_loss:0.878, Test_acc:72.9%,Test_loss:0.788
Epoch: 3, Train_acc:76.7%, Train_loss:0.755, Test_acc:72.9%,Test_loss:0.741
Epoch: 4, Train_acc:80.6%, Train_loss:0.655, Test_acc:79.1%,Test_loss:0.607
Epoch: 5, Train_acc:83.2%, Train_loss:0.576, Test_acc:82.2%,Test_loss:0.651
Epoch: 6, Train_acc:83.4%, Train_loss:0.533, Test_acc:80.9%,Test_loss:0.577
Epoch: 7, Train_acc:84.9%, Train_loss:0.496, Test_acc:82.7%,Test_loss:0.532
Epoch: 8, Train_acc:86.4%, Train_loss:0.449, Test_acc:83.1%,Test_loss:0.440
Epoch: 9, Train_acc:85.6%, Train_loss:0.468, Test_acc:83.1%,Test_loss:0.490
Epoch:10, Train_acc:85.6%, Train_loss:0.451, Test_acc:83.6%,Test_loss:0.426
Epoch:11, Train_acc:87.7%, Train_loss:0.406, Test_acc:85.8%,Test_loss:0.391
Epoch:12, Train_acc:87.9%, Train_loss:0.402, Test_acc:84.0%,Test_loss:0.362
Epoch:13, Train_acc:88.3%, Train_loss:0.384, Test_acc:84.4%,Test_loss:0.397
Epoch:14, Train_acc:90.3%, Train_loss:0.390, Test_acc:85.3%,Test_loss:0.380
Epoch:15, Train_acc:90.2%, Train_loss:0.338, Test_acc:87.1%,Test_loss:0.351
Epoch:16, Train_acc:89.1%, Train_loss:0.334, Test_acc:86.2%,Test_loss:0.323
Epoch:17, Train_acc:90.2%, Train_loss:0.319, Test_acc:85.3%,Test_loss:0.319
Epoch:18, Train_acc:90.0%, Train_loss:0.302, Test_acc:85.8%,Test_loss:0.319
Epoch:19, Train_acc:90.8%, Train_loss:0.316, Test_acc:86.7%,Test_loss:0.300
Epoch:20, Train_acc:90.7%, Train_loss:0.301, Test_acc:86.2%,Test_loss:0.288
Epoch:21, Train_acc:90.8%, Train_loss:0.311, Test_acc:86.2%,Test_loss:0.348
Epoch:22, Train_acc:90.3%, Train_loss:0.303, Test_acc:88.4%,Test_loss:0.287
Epoch:23, Train_acc:91.4%, Train_loss:0.280, Test_acc:87.6%,Test_loss:0.405
Epoch:24, Train_acc:91.6%, Train_loss:0.294, Test_acc:88.0%,Test_loss:0.271
Epoch:25, Train_acc:92.1%, Train_loss:0.239, Test_acc:86.7%,Test_loss:0.338
Epoch:26, Train_acc:92.6%, Train_loss:0.256, Test_acc:86.2%,Test_loss:0.731
Epoch:27, Train_acc:91.6%, Train_loss:0.272, Test_acc:83.6%,Test_loss:0.387
Epoch:28, Train_acc:91.4%, Train_loss:0.251, Test_acc:88.0%,Test_loss:0.262
Epoch:29, Train_acc:92.9%, Train_loss:0.244, Test_acc:88.4%,Test_loss:0.249
Epoch:30, Train_acc:92.7%, Train_loss:0.240, Test_acc:88.4%,Test_loss:0.247
Epoch:31, Train_acc:93.7%, Train_loss:0.223, Test_acc:87.6%,Test_loss:0.278
Epoch:32, Train_acc:93.9%, Train_loss:0.230, Test_acc:88.9%,Test_loss:0.287
Epoch:33, Train_acc:93.1%, Train_loss:0.227, Test_acc:88.9%,Test_loss:0.370
Epoch:34, Train_acc:94.1%, Train_loss:0.186, Test_acc:88.9%,Test_loss:0.238
Epoch:35, Train_acc:93.4%, Train_loss:0.219, Test_acc:87.6%,Test_loss:0.436
Epoch:36, Train_acc:93.9%, Train_loss:0.223, Test_acc:88.0%,Test_loss:0.268
Epoch:37, Train_acc:94.7%, Train_loss:0.194, Test_acc:87.6%,Test_loss:0.261
Epoch:38, Train_acc:92.8%, Train_loss:0.220, Test_acc:88.9%,Test_loss:0.216
Epoch:39, Train_acc:94.9%, Train_loss:0.202, Test_acc:88.4%,Test_loss:0.249
Epoch:40, Train_acc:95.7%, Train_loss:0.169, Test_acc:88.0%,Test_loss:0.233
Epoch:41, Train_acc:95.2%, Train_loss:0.180, Test_acc:89.8%,Test_loss:0.225
Epoch:42, Train_acc:95.6%, Train_loss:0.203, Test_acc:88.4%,Test_loss:0.227
Epoch:43, Train_acc:95.2%, Train_loss:0.184, Test_acc:88.4%,Test_loss:0.238
Epoch:44, Train_acc:96.1%, Train_loss:0.163, Test_acc:89.8%,Test_loss:0.225
Epoch:45, Train_acc:94.7%, Train_loss:0.188, Test_acc:91.6%,Test_loss:0.237
Epoch:46, Train_acc:94.9%, Train_loss:0.175, Test_acc:90.2%,Test_loss:0.252
Epoch:47, Train_acc:95.0%, Train_loss:0.209, Test_acc:89.8%,Test_loss:0.314
Epoch:48, Train_acc:95.7%, Train_loss:0.170, Test_acc:90.7%,Test_loss:0.219
Epoch:49, Train_acc:96.6%, Train_loss:0.143, Test_acc:90.2%,Test_loss:0.198
Epoch:50, Train_acc:95.8%, Train_loss:0.168, Test_acc:90.2%,Test_loss:0.200
Done
可以看见最后可以达到96%左右,还不错,但是我感觉还可以提高,另外我想说的是,一开始直接使用K老师的模型进行训练有一次结果达到了97%,可能是偶然,因为再接下来的时候重复训练之后就达不到97%了。
六、结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

七、模型识别
接下来我们将进行拔高操作,我们将调用我们训练过的模型预测本地的一张图片。
我们将需要被预测的照片进行各种操作,下面是需要被预测的图片:

然后我们开始处理图片并进行预测。
import torchvision
import PIL
classeNames = ['cloudy', 'rain', 'shine', 'sunrise']
num_classes = len(classeNames)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Network_bn()
model.load_state_dict(torch.load('/content/epoch50.pkl'))
model.eval()
mg_path = '/content/shine.jpg'
img = Image.open(img_path)
train_transforms = torchvision.transforms.Compose([
# 将输入图片resize成统一尺寸
torchvision.transforms.Resize([224, 224]),
# 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
torchvision.transforms.ToTensor(),
# 标准化处理转换为标准正太分布(高斯分布),使模型更容易收敛
torchvision.transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img = train_transforms(img)
img = torch.reshape(img, (1, 3, 224, 224))
output = model(img)
_, indices = torch.max(output, 1)
percentage = torch.nn.functional.softmax(output, dim=1)[0] * 100
perc = percentage[int(indices)].item()
result = classeNames[indices]
print('预测的天气为:{}, 预测的准确率为:{}'.format(result, perc))
这段代码的作用是利用预先训练好的深度神经网络模型(在这里是Network_bn()),对一张本地图片进行分类预测,并输出预测结果和其对应的概率。下面是具体的代码含义:
classeNames:定义了分类的类别名称,即要预测图片的分类可能属于哪些类别。num_classes:统计了分类的类别数量。device:定义了使用的设备类型,如果GPU可用就使用GPU。model:创建了一个Network_bn()模型的实例。model.load_state_dict():加载之前训练好的模型参数。model.eval():将模型设置为评估模式,使其不会更新参数。mg_path:定义了本地要预测的图片路径。img:使用PIL库打开了img_path路径下的图片,并进行了一系列的数据预处理(resize、ToTensor、Normalize)。output:利用预处理后的图片输入模型进行预测,得到一个输出结果。torch.max():返回输出结果中最大值及其下标。torch.nn.functional.softmax():对输出结果进行softmax处理,即将输出结果归一化为概率分布。percentage:计算输出结果中最大值对应的概率。perc:取最大值对应概率的数值。result:输出结果的标签。print():输出预测结果和其对应的概率。
最后预测的结果是:
预测的天气为:shine, 预测的准确率为:81.39346313476562
可以看出预测结果正确,而且准确率也还不错,证明模型还不错,大家还可以在我的基础上继续调整模型的网络结构或者改变其他的参数进行测试。