原论文:Attention Is All You Need。论文地址:https://arxiv.org/abs/1706.03762.
Transformer是针对自然语言处理的,Google在2017年发表在Computation and Language,RNN模型记忆长度有限且无法并行化但是Tranformer解决了上述问题。
直接参考P导https://blog.csdn.net/qq_37541097/article/details/117691873
self-Attention
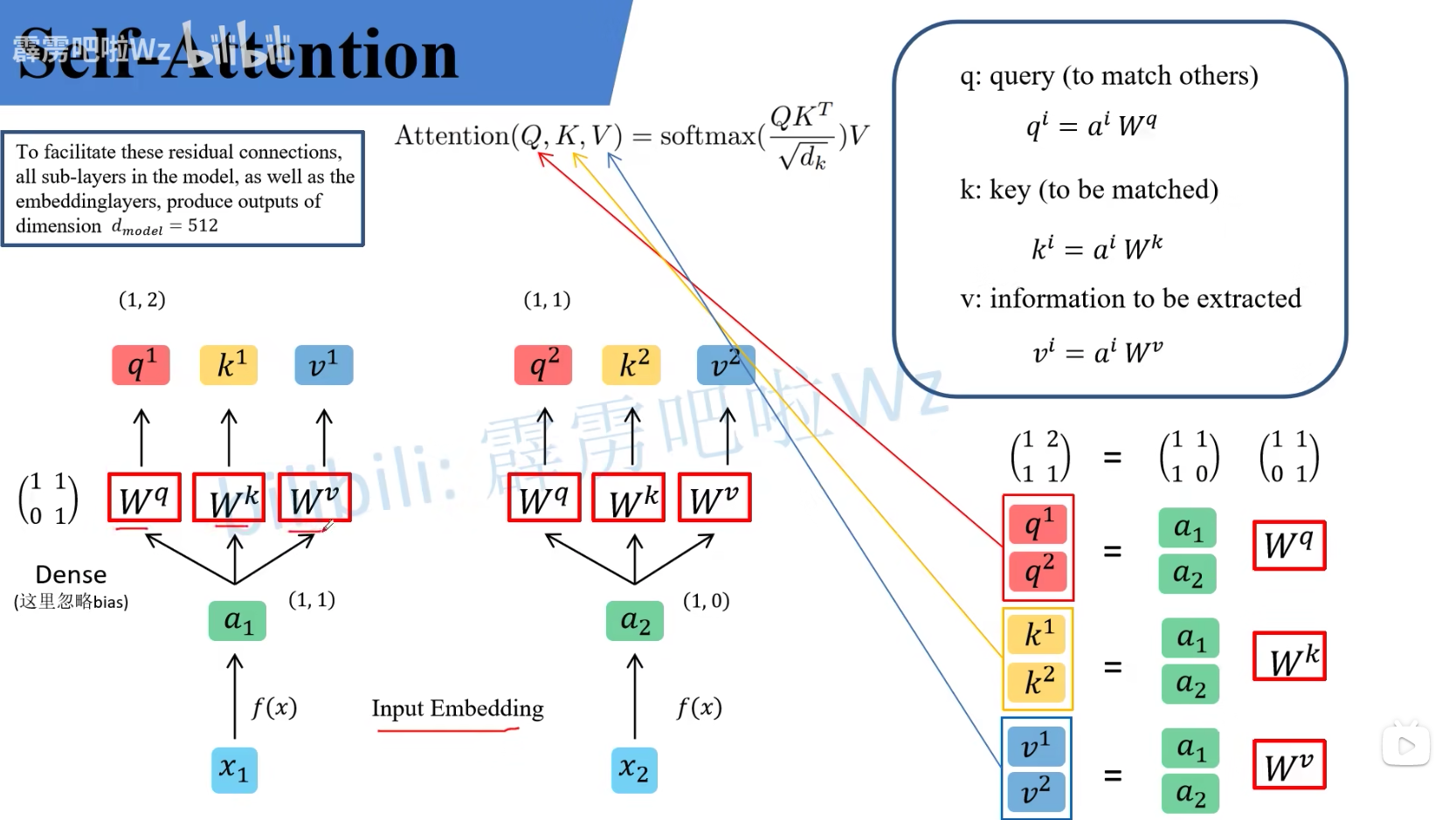
W q , W k , W v W^q, W^k, W^v Wq,Wk,Wv是全局共享的,在进行自注意力机制的时候,将每个 a i a_i ai与query,key,information矩阵相乘得到q, k , v。将得到的 q i , k i , v i q_i, k_i, v_i qi,ki,vi拼接成 Q , K , V Q, K, V Q,K,V,用QKV计算Attention。最终由输入的 a 1 , a 2 , . . . a_1, a_2, ... a1,a2,...计算得到了 b 1 , b 2 , . . . b_1, b_2, ... b1,b2,...。
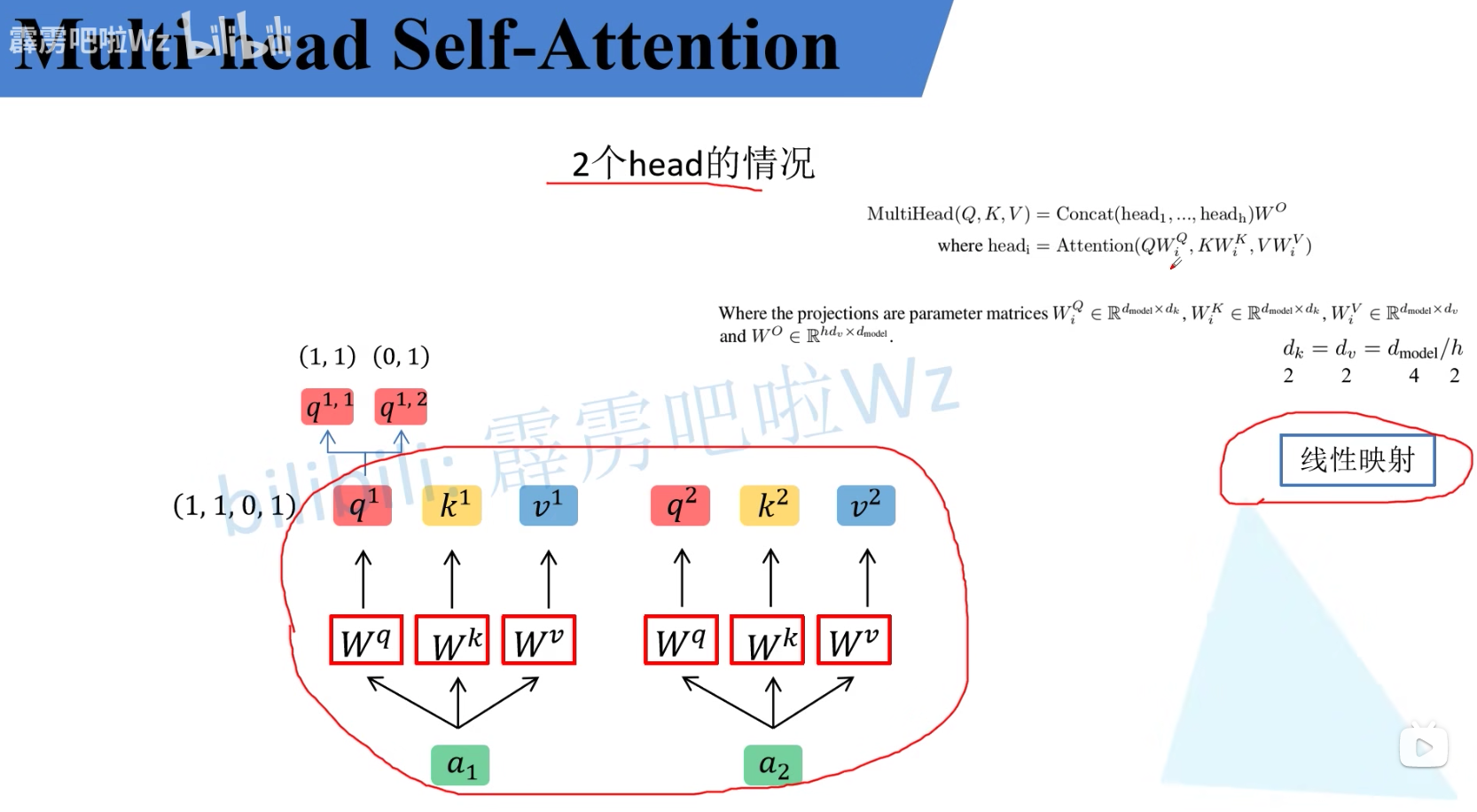
multi-head self-Attention
即有多个 W q , W k , W v W^q, W^k, W^v Wq,Wk,Wv,会将输入的a取出部分元素,分别与单个的 W q , W k , W v W^q, W^k, W^v Wq,Wk,Wv相乘后相加,再将得到的 b 1 , b 2 , . . . b_1, b_2, ... b1,b2,...进行concat拼接后通过 W W W融合。