提要
容器集群版本情况:k8s 1.20
客户端k8s client版本: 0.21
事情是这样的,运行了一年的服务,突然有一天业务反馈服务使用异常,然后初步调查结果如下
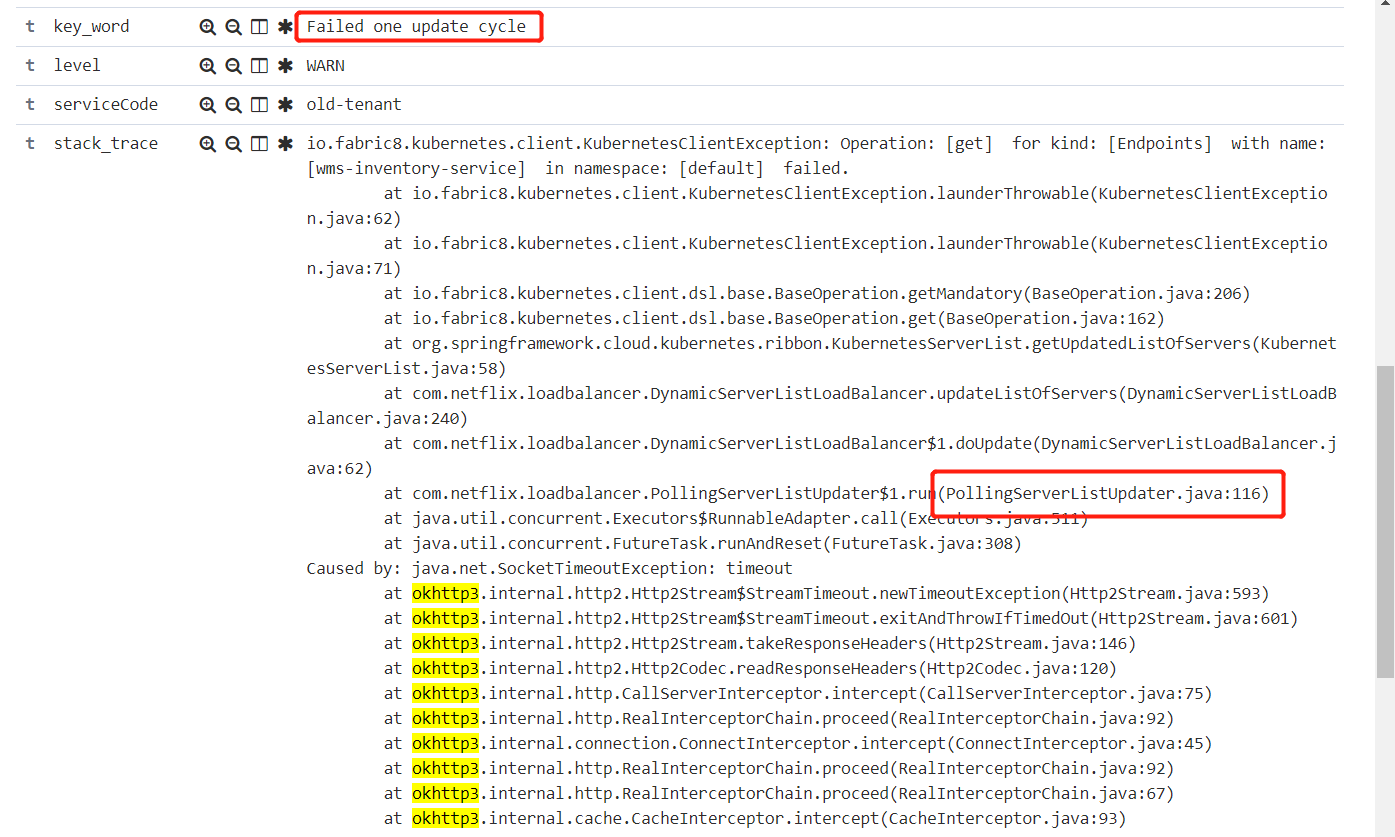
以下截图是网关异常

以下截图是客户端zull(feign)转发异常(底层都是使用ribbon)

翻译信息:
某个service的Endpoints已经更新了,但是客户端的服务发现没有更新过来,还是使用了历史的serverList 配置,配置的信息包含已经下线的pod ip,这样就导致这个调用出现问题了,最直接的异常就是 No route to host (Host unreachable)
科普一下:
Endpoints与Pod的关系是什么?
Endpoints是Kubernetes集群中的一个资源对象,存储在etcd中,用来记录一个Service对应的所有Pod的访问地址。
故障分析
一:CoreDns 排查
最开始怀疑是coredns出问题了,因为客户端使用的服务发现直接跟dns挂钩
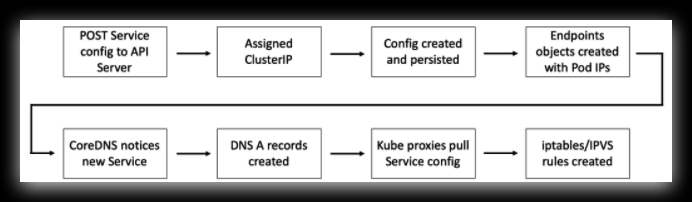
这个是注册中心流程图,最开始是apiserver -> coredns -> kube-proxy -> iptables ,然后这个serverList的更新,却不是直接跟coredns打交道的,而是跟kube-proxy。
创建新的 Service 对象时,会得到一个虚拟 IP,被称为 ClusterIP。服务名及其 ClusterIP 被自动注册到集群 DNS 中,并且会创建相关的 Endpoints 对象用于保存符合标签条件的健康 Pod 的列表,Service 对象会向列表中的 Pod 转发流量。
与此同时集群中所有节点都会配置相应的 iptables/IPVS 规则,监听目标为 ClusterIP 的流量并转发给真实的 Pod IP。
以上参考:https://ost.51cto.com/posts/17770
究竟是不是coredns出问题了呢,或者说是kube-proxy出问题了呢?!
答案是否定的!
检查容器的所有coredns的pod日志以及kube-proxy的pod日志,没有显著的异常。
另外并不是所有的客户端服务发现列表出现问题,没法同步,只是少数的应用(微服务,pod -> service)出故障了。
那,究竟是什么问题呢?!
二:客户端的服务发现排查
通过上面的分析,大概率是应用的服务发现出问题了。现在开始分析出问题应用的依赖配置
<!-- 服务发现 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-kubernetes-discovery</artifactId>
<version>0.2.1.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-kubernetes-ribbon</artifactId>
<version>0.2.1.RELEASE</version>
</dependency>纳尼?!我的乖乖,该应用的k8s服务发现的版本居然这么旧,这个跟公司推荐的版本差太远了,公司推荐的是1.1.6以上,这个版本的服务发现目前来看是没有出问题的。
直观感受是需要客户端需要升级这个服务发现的版本,但很尴尬发现,该应用绑定的spring boot版本也比较老(很老很老这种),直接升1.1.6版本,会导致一系列的版本冲突,比较恶心!
有没有其它好的办法呢?!
没办法了,需要被迫研究源代码了!
三:服务发现源代码分析
Spring Cloud Kubernetes服务注册与发现实现原理
在sck-demo项目搭建之初,我们是跟着官方提供的demo去实现服务注册和发现的,也就是在每个服务的Application类上添加一个@EnableDiscoveryClient注解。
我们并未配置Kubernetes的地址,但我们使用DiscoveryClient却能获取到服务节点。要解开这个疑惑我们需要了解Kubernetes,以及了解Spring Cloud Kubernetes Discovery的源码。
前面我们在分析Ribbon的源码时也了解到,Ribbon并非通过DiscoveryClient去获取服务提供者的。
Ribbon通过提供一个ServerList接口让使用者自己去实现来完成Ribbon的服务发现。Ribbon定时调用ServerList更新自身缓存的服务提供者列表,默认30秒更新一次。
Spring Cloud Kubernetes Ribbon的作用就是实现Ribbon的ServerList接口,从Kubernetes获取可用的服务提供者。
实际上,Spring Cloud Kubernetes Ribbon也并未使用到Spring Cloud Kubernetes Discovery提供的DiscoveryClient接口的实现来获取服务列表,而是直接调用接口从Kubernetes中获取。
正是因为如此,笔者尝试去掉@EnableDiscoveryClient注解后,以及去掉Spring Cloud Kubernetes Discovery的依赖后,项目依然能正常运作。
需要注意,Spring Cloud Kubernetes Ribbon依赖Spring Cloud Kubernetes Core,如果去掉Spring Cloud Kubernetes Discovery,可能就要自动手动添加Spring Cloud Kubernetes Core的依赖,否则服务启动失败。
Spring Cloud Kubernetes Discovery实现DiscoveryClient接口只是能够让我们通过DiscoveryClient获取服务提供者。
SpringCloud Kubernetes Discovery实现的服务注册接口也并未真正的去注册服务。
可以这么说,在Spring Cloud Kubernetes项目中,Spring Cloud Kubernetes Discovery是一个多余的存在。
如果去掉Spring Cloud Kubernetes Discovery后,我们想要获取某个服务的当前可用服务提供者怎么获取呢?
我们可以通过使用Ribbon的ServerList去获取,由Spring Cloud Kubernetes Ribbon实现。
本地使用kubectl proxy
本地使用kubectl proxy命令就会运行一个Kubernetes API代理服务。
例如:
$ kubectl proxy --port=8004Starting to serve on 127.0.0.1:8004使用kubectl proxy —port=8004开启Kubernetes API代理服务,监听请求的端口为8004。代理服务启动成功后,我们就可以使用127.0.0.1:8004访问Kubernetes的API了。
例如,获取sck-demo-provider这个服务的所有endpoints,在浏览器输入:
http://127.0.0.1:8004/api/v1/namespaces/default/endpoints/sck-demo-provider其中default为名称空间,sck-demo-provider为服务名。响应结果如下图所示。

以上参考:https://blog.51cto.com/u_15064638/2871844
四:客户端的服务发现源代码分析
好了,通用的源码已经分析完了,现在我们正式分析应用的具体依赖源码。

k8s client 0.21 依赖的 ribbon-loadbanlancer 版本是2.2.5,然后具体触发这个更新server list列表的是 PollingServerListUpdater类,
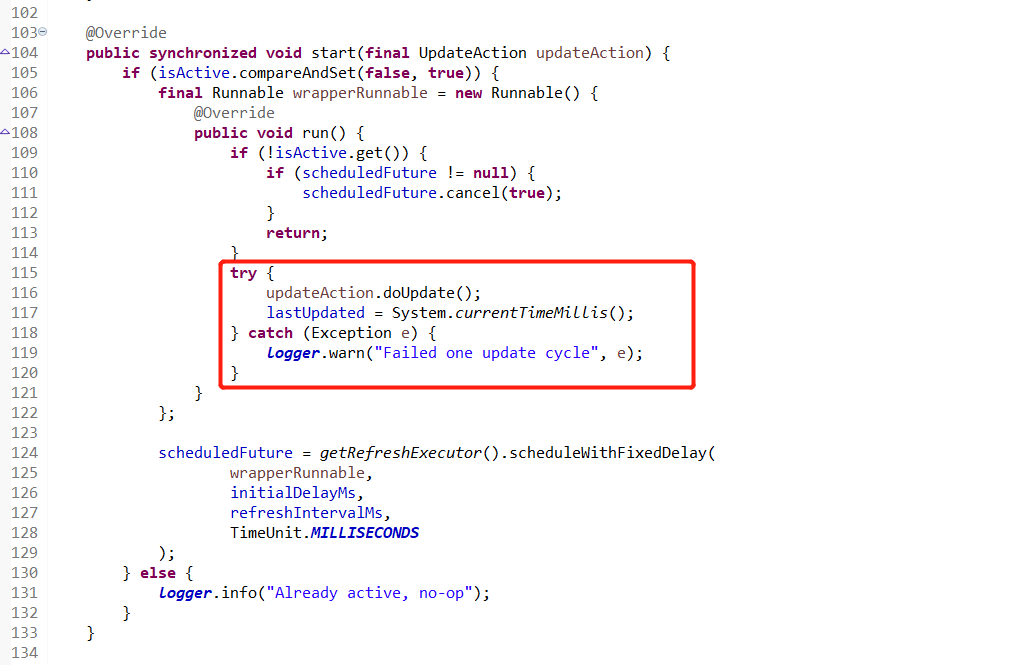
注意,ribbon这里只管调度,不管具体实现,具体实现继续看!
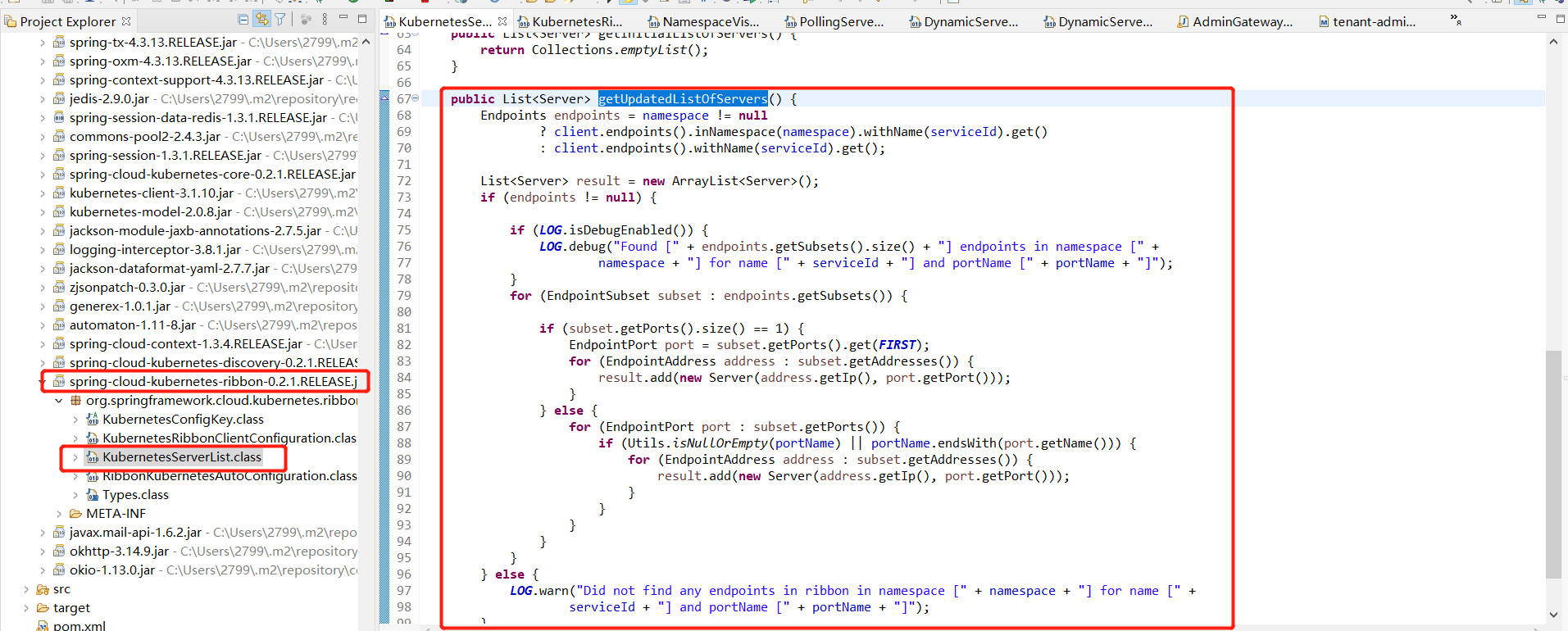
如截图所示,具体实现是k8s client服务发现的依赖包。
再接着看!
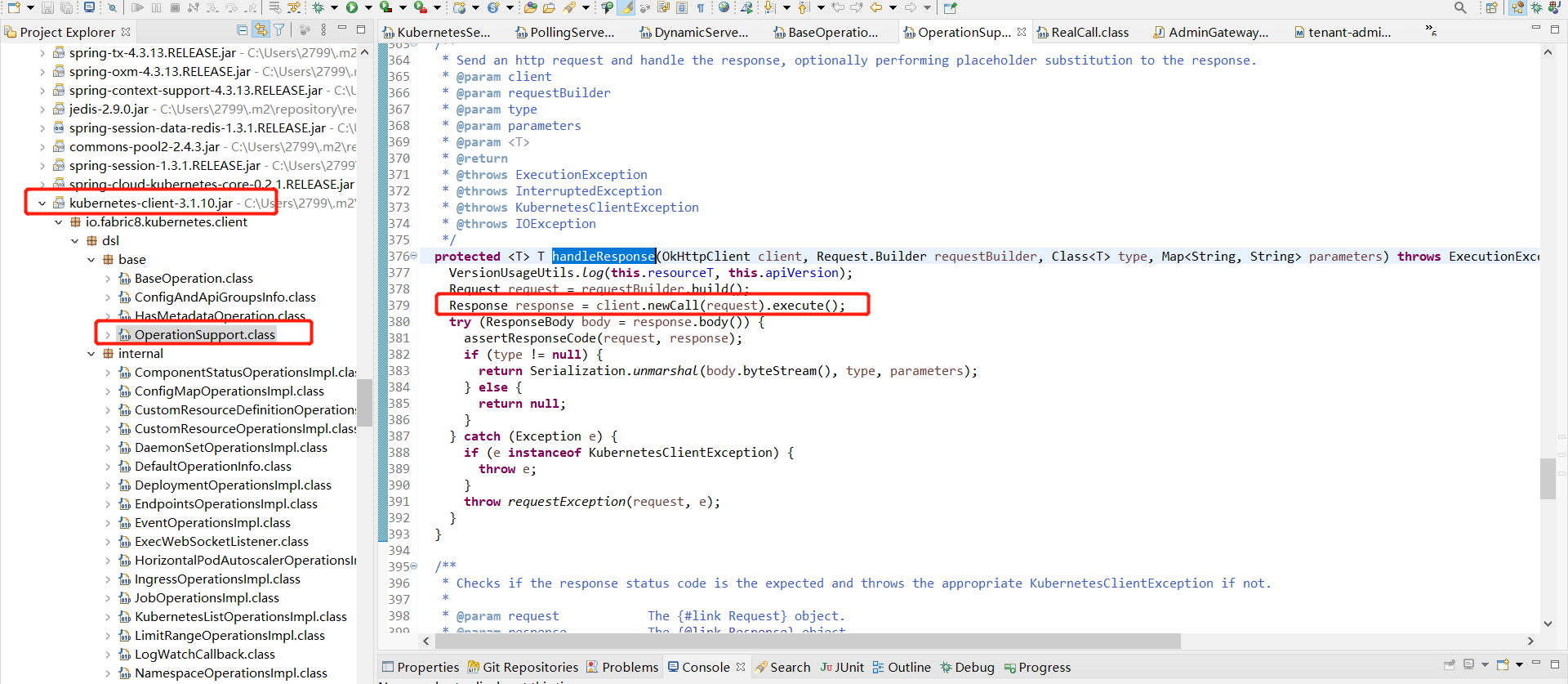
接着实现http调用的是 io.fabric8.kubernetes.client 的 client.newCall(request).execute() 方法。
再再接着看!
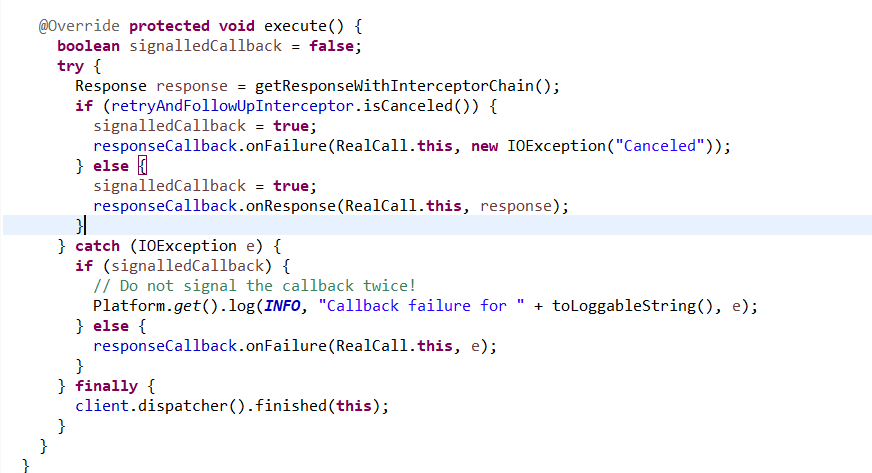
最底层实现调用的是okhttp3工具!目前k8s 服务发现对应的okhttp3依赖版本是3.8.1 版本!
本质原因找到了,是这个版本的execute出问题了,卡住了,导致ribbon的更新任务对于的线程假死了。
最后我们来看看,k8s 服务发现 1.1.6版本对应的okhttp3版本是多少。
<!-- 尝试解决更新列表卡主问题 -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>3.14.9</version>
</dependency>然后其对应的http调用执行有啥不一样
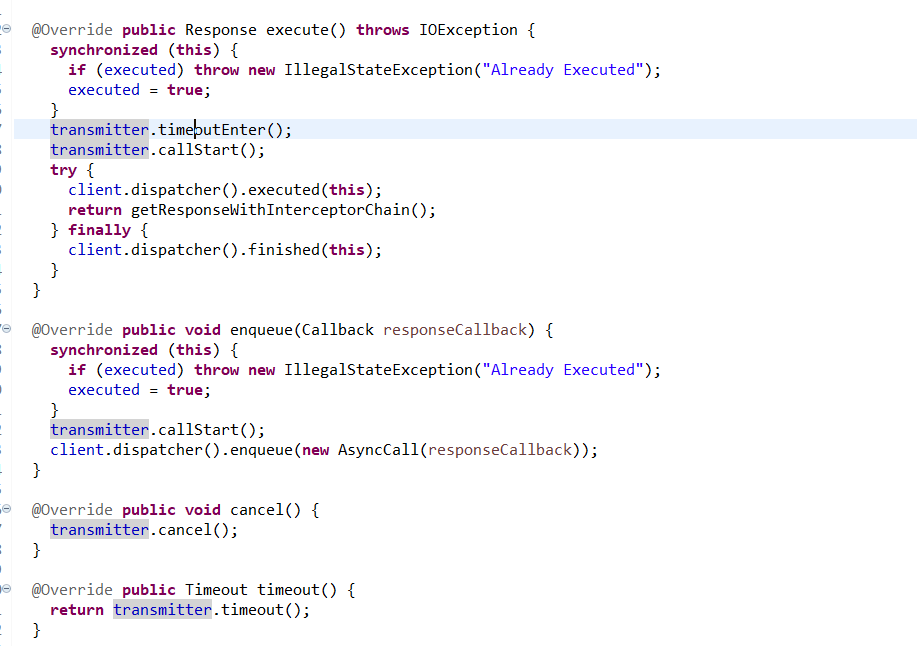
多了 transmitter.timeoutEnter() 这个调用钩子,能够有效的修复卡死bug!
查看Okhttp源码时,在Transmitter类中发现了一个AsyncTimeout对象。了解代码后得知,该类是用于做一些超时检测的操作。
/**
* This timeout uses a background thread to take action exactly when the timeout occurs. Use this to
* implement timeouts where they aren't supported natively, such as to sockets that are blocked on
* writing.
*
* <p>Subclasses should override {@link #timedOut} to take action when a timeout occurs. This method
* will be invoked by the shared watchdog thread so it should not do any long-running operations.
* Otherwise we risk starving other timeouts from being triggered.
*
* <p>Use {@link #sink} and {@link #source} to apply this timeout to a stream. The returned value
* will apply the timeout to each operation on the wrapped stream.
*
* <p>Callers should call {@link #enter} before doing work that is subject to timeouts, and {@link
* #exit} afterwards. The return value of {@link #exit} indicates whether a timeout was triggered.
* Note that the call to {@link #timedOut} is asynchronous, and may be called after {@link #exit}.
*/publicclassAsyncTimeoutextendsTimeout{这里提供了几个有用的信息:
这是一个利用统一子线程检测超时的工具,主要针对的是一些原生不支持超时检测的类。
它提供了一个timedOut()方法,作为检测到超时的回调。
内部提供的sink()和source()方法可以适配流的读写超时检测,这可以对应到网络请求的流读写,后面会讲到。
提供enter()和exit()作为开始计时和结束计时的调用。也就是说开始执行计时的起点将会在enter()发生。
详情见: https://juejin.cn/post/6962464239864774664
验证
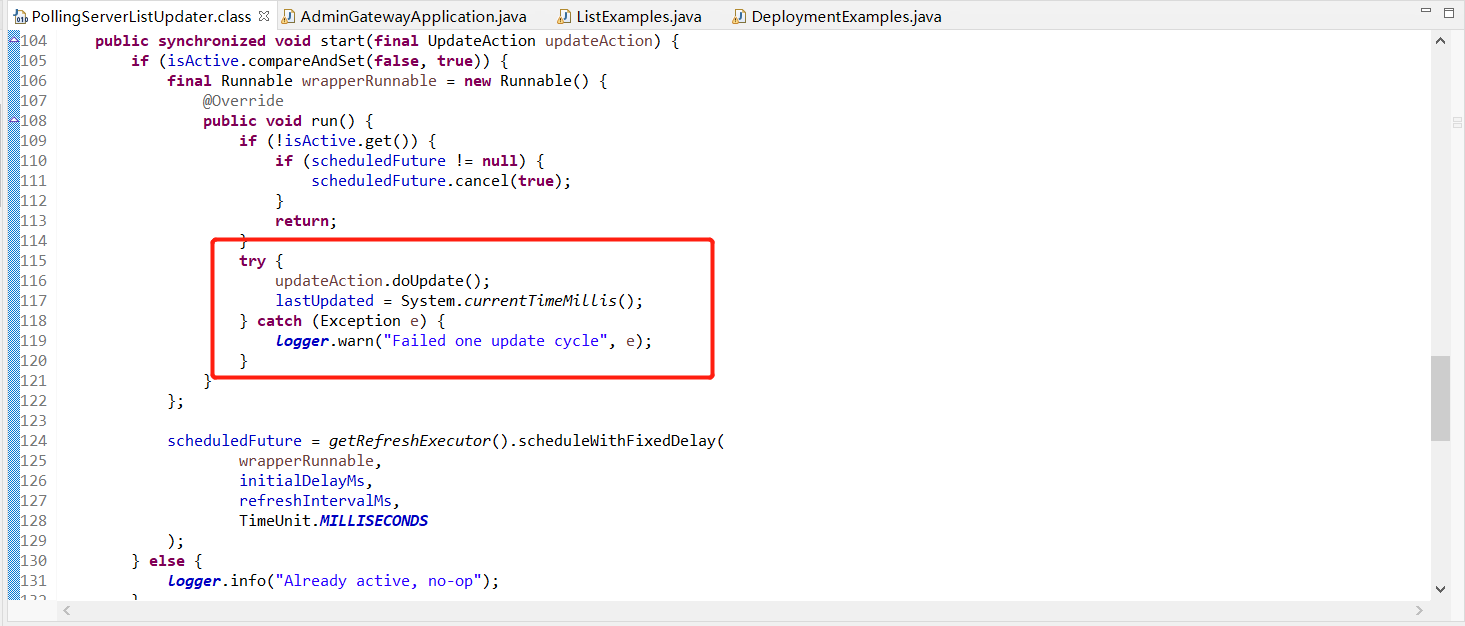
如截图所示,超时按约定被捕获了。
总结
这个服务列表更新的异常有3种处理方式
1. 在ribbon调度这块加一层线程卡死监控,如果线程长时间处理Thread.State.WAITING.name()状态的,定时强制唤醒!(感谢东平的早期方向引导)
2. 在spring-cloud-kubernetes-ribbon执行更新的地方,额外加一个监控钩子,处理方式跟上面一致。
3. 其它依赖不变的情况下,直接升级okhttp3版本,升到3.14.9以上
<!-- 尝试解决更新列表卡主问题 -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>3.14.9</version>
</dependency>