xgboost算法数学原理
1、求预测值
y
^
i
=
ϕ
(
x
i
)
=
∑
k
=
1
K
f
k
(
x
i
)
,
f
k
∈
F
,
(1)
\hat{y}_i=\phi\left(\mathbf{x}_i\right)=\sum_{k=1}^K f_k\left(\mathbf{x}_i\right), \quad f_k \in \mathcal{F},\tag{1}
y^i=ϕ(xi)=k=1∑Kfk(xi),fk∈F,(1)
F
=
{
f
(
x
)
=
w
q
(
x
)
}
(
q
:
R
m
→
T
,
w
∈
R
T
)
\mathcal{F}=\left\{f(\mathbf{x})=w_{q(\mathbf{x})}\right\}\left(q: \mathbb{R}^m \rightarrow T, w \in \mathbb{R}^T\right)
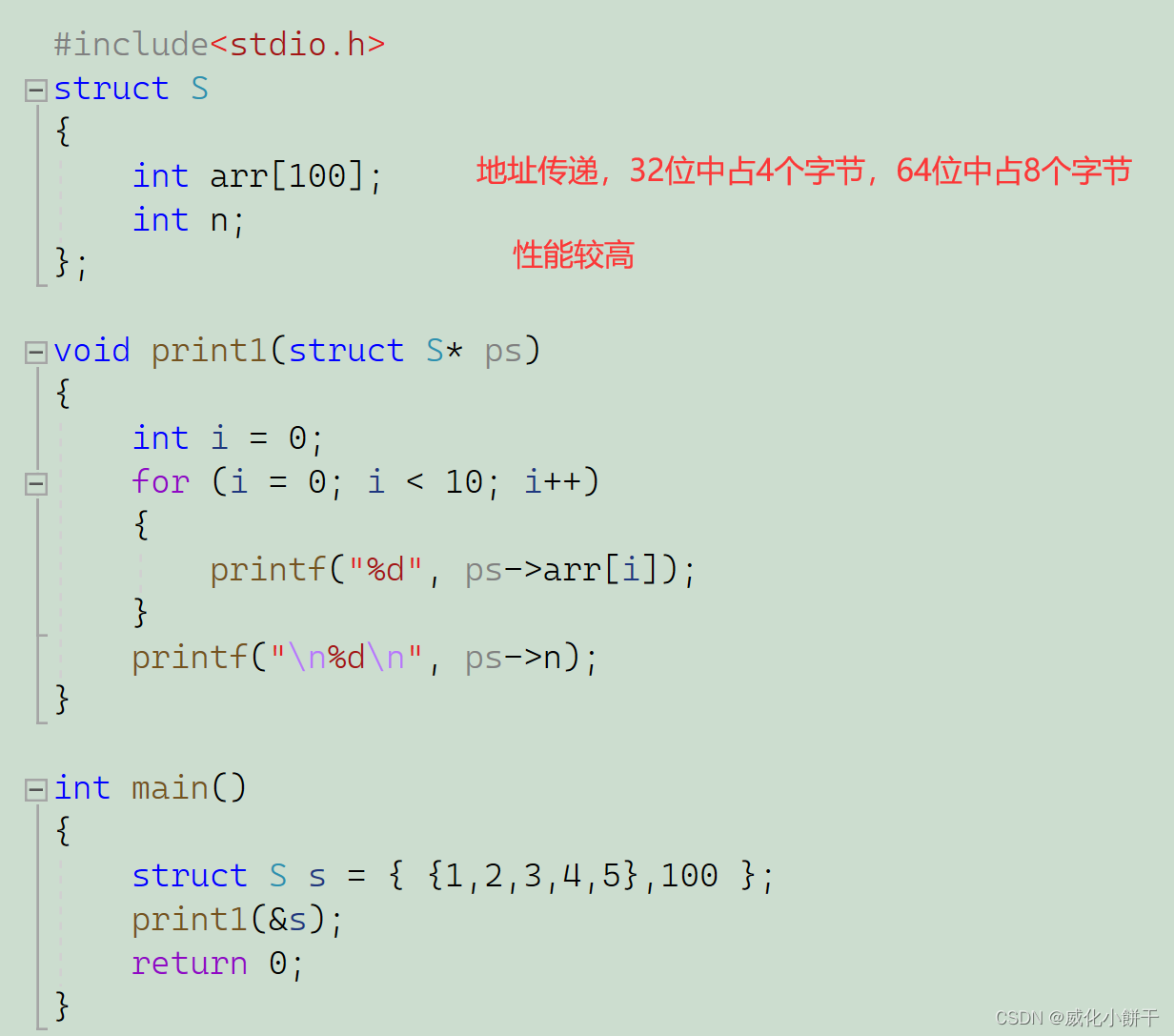
F={f(x)=wq(x)}(q:Rm→T,w∈RT):递归树的的空间;
q q q:每棵树的结构,映射一个样本到一个叶子节点index;
T : T: T:叶子的数目; f k f_k fk对于一个独立的树结构 q q q和叶子权重 w w w。
w i w_i wi:在 i − t h i-th i−th叶子节点的分数;(与决策树不同,递归树在每个叶子节点上包含一个连续分数)。
示例图:(注:图中的人指的是一个个样本)
结合上面的公式理解就是对于样本 i i i的预测值等于 K K K棵递归树样本落在的叶子节点对应的分数的和;

2、计算带正则项的损失
L
(
ϕ
)
=
∑
i
l
(
y
^
i
,
y
i
)
+
∑
k
Ω
(
f
k
)
where
Ω
(
f
)
=
γ
T
+
1
2
λ
∥
w
∥
2
(2)
\begin{aligned} & \mathcal{L}(\phi)=\sum_i l\left(\hat{y}_i, y_i\right)+\sum_k \Omega\left(f_k\right) \\ & \text { where } \Omega(f)=\gamma T+\frac{1}{2} \lambda\|w\|^2 \end{aligned}\tag{2}
L(ϕ)=i∑l(y^i,yi)+k∑Ω(fk) where Ω(f)=γT+21λ∥w∥2(2)
l
l
l:衡量预测值
y
i
^
\hat{y_i}
yi^和目标值
y
i
y_i
yi差别的可微的凸函数;
Ω \Omega Ω:模型复杂度的惩罚项;用于平滑最终的学习权重避免过拟合。正则化的目标函数倾向于选择一个更简单、可预测的函数(递归树模型);传统的梯度提升树没有用正则化项,RGF用到。
3、梯度树集成(Gradient Tree Boosting)
从对全部递归树的损失,利用贪心和近似,推导到一棵树的损失
为什么用(3)式作为目标函数而不是(2)式?
将(1)和(2)合并:
L
(
ϕ
)
=
∑
i
l
(
∑
k
=
1
K
f
k
(
x
i
)
,
y
i
)
+
∑
k
Ω
(
f
k
)
where
Ω
(
f
)
=
γ
T
+
1
2
λ
∥
w
∥
2
(2)
\begin{aligned} & \mathcal{L}(\phi)=\sum_i l\left(\sum_{k=1}^K f_k\left(\mathbf{x}_i\right), y_i\right)+\sum_k \Omega\left(f_k\right) \\ & \text { where } \Omega(f)=\gamma T+\frac{1}{2} \lambda\|w\|^2 \end{aligned}\tag{2}
L(ϕ)=i∑l(k=1∑Kfk(xi),yi)+k∑Ω(fk) where Ω(f)=γT+21λ∥w∥2(2)
可以看到(2)式不能进行优化,不能优化的原因是
K
K
K棵树的话,就有
K
K
K个
f
(
x
)
f(x)
f(x),在优化理论中,相当于多变量优化,是一个极其难以优化的问题。所以使用(3)式这种贪婪的方式,每一次只优化一棵树。
L
(
t
)
=
∑
i
=
1
n
l
(
y
i
,
y
^
i
(
t
−
1
)
+
f
t
(
x
i
)
)
+
Ω
(
f
t
)
(3)
\mathcal{L}^{(t)}=\sum_{i=1}^n l\left(y_i, \hat{y}_i^{(t-1)}+f_t\left(\mathbf{x}_i\right)\right)+\Omega\left(f_t\right)\tag{3}
L(t)=i=1∑nl(yi,y^i(t−1)+ft(xi))+Ω(ft)(3)
y
i
^
t
\hat{y_i}^{t}
yi^t:第
i
i
i个样本实例在第
t
t
t次迭代的预测值;
注:二阶泰勒公式:
f
(
x
+
Δ
x
)
≈
f
(
x
)
+
f
′
(
x
)
⋅
Δ
x
+
1
2
f
′
′
(
x
)
⋅
Δ
x
2
f(x+\Delta x)\approx f(x)+f'(x)\cdot\Delta x+\dfrac{1}{2}f''(x)\cdot\Delta x^2
f(x+Δx)≈f(x)+f′(x)⋅Δx+21f′′(x)⋅Δx2
但是(3)式还是不容易优化,需要进行二阶近似:
L
(
t
)
≃
∑
i
=
1
n
[
l
(
y
i
,
y
^
(
t
−
1
)
)
+
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
2
(
x
i
)
]
+
Ω
(
f
t
)
(4)
\mathcal{L}^{(t)} \simeq \sum_{i=1}^n\left[l\left(y_i, \hat{y}^{(t-1)}\right)+g_i f_t\left(\mathbf{x}_i\right)+\frac{1}{2} h_i f_t^2\left(\mathbf{x}_i\right)\right]+\Omega\left(f_t\right)\tag{4}
L(t)≃i=1∑n[l(yi,y^(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)(4)
g
i
g_i
gi:
g
i
=
∂
y
^
(
t
−
1
)
l
(
y
i
,
y
^
(
t
−
1
)
)
g_i=\partial_{\hat{y}^{(t-1)}} l\left(y_i, \hat{y}^{(t-1)}\right)
gi=∂y^(t−1)l(yi,y^(t−1))
h i h_i hi: h i = ∂ y ^ ( t − 1 ) 2 l ( y i , y ^ ( t − 1 ) ) h_i=\partial_{\hat{y}^{(t-1)}}^2 l\left(y_i, \hat{y}^{(t-1)}\right) hi=∂y^(t−1)2l(yi,y^(t−1))
进一步去掉常数项,得到损失函数:(常数项不影响损失函数,因为常数项不影响最小化损失函数问题,只会影响损失函数的结果的量级)
L
~
(
t
)
=
∑
i
=
1
n
[
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
2
(
x
i
)
]
+
Ω
(
f
t
)
(5)
\tilde{\mathcal{L}}^{(t)}=\sum_{i=1}^n\left[g_i f_t\left(\mathbf{x}_i\right)+\frac{1}{2} h_i f_t^2\left(\mathbf{x}_i\right)\right]+\Omega\left(f_t\right)\tag{5}
L~(t)=i=1∑n[gift(xi)+21hift2(xi)]+Ω(ft)(5)
按照叶子节点进行样本的集合划分:
L
~
(
t
)
=
∑
i
=
1
n
[
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
2
(
x
i
)
]
+
γ
T
+
1
2
λ
∑
j
=
1
T
w
j
2
=
∑
j
=
1
T
[
(
∑
i
∈
I
j
g
i
)
w
j
+
1
2
(
∑
i
∈
I
j
h
i
+
λ
)
w
j
2
]
+
γ
T
(6)
\begin{aligned} \tilde{\mathcal{L}}^{(t)} & =\sum_{i=1}^n\left[g_i f_t\left(\mathbf{x}_i\right)+\frac{1}{2} h_i f_t^2\left(\mathbf{x}_i\right)\right]+\gamma T+\frac{1}{2} \lambda \sum_{j=1}^T w_j^2 \\ & =\sum_{j=1}^T\left[\left(\sum_{i \in I_j} g_i\right) w_j+\frac{1}{2}\left(\sum_{i \in I_j} h_i+\lambda\right) w_j^2\right]+\gamma T \end{aligned}\tag{6}
L~(t)=i=1∑n[gift(xi)+21hift2(xi)]+γT+21λj=1∑Twj2=j=1∑T
i∈Ij∑gi
wj+21
i∈Ij∑hi+λ
wj2
+γT(6)
I
j
=
{
i
∣
q
(
x
i
)
=
j
}
I_j=\{i|q(\mathbf{x}_i)=j\}
Ij={i∣q(xi)=j}:叶子节点
j
j
j的样本集合;
然后对
w
w
w求导数,令其==0,得到:
w
j
∗
=
−
∑
i
∈
I
j
g
i
∑
i
∈
I
j
h
i
+
λ
,
(7)
w_j^*=-\dfrac{\sum_{i\in I_j}g_i}{\sum_{i\in I_j}h_i+\lambda},\tag{7}
wj∗=−∑i∈Ijhi+λ∑i∈Ijgi,(7)
计算对应的优化值:
L
~
(
t
)
(
q
)
=
−
1
2
∑
j
=
1
T
(
∑
i
∈
I
j
g
i
)
2
∑
i
∈
I
j
h
i
+
λ
+
γ
T
.
(8)
\tilde{\mathcal{L}}^{(t)}(q)=-\dfrac{1}{2}\sum\limits_{j=1}^{T}\dfrac{\left(\sum_{i\in I_j}g_i\right)^2}{\sum_{i\in I_j}h_i+\lambda}+\gamma T.\tag{8}
L~(t)(q)=−21j=1∑T∑i∈Ijhi+λ(∑i∈Ijgi)2+γT.(8)
式(8)可以作为像决策树里面的纯度、信息熵一样的划分函数,得到树的划分分数。如图

通常应该计算单个叶子节点和添加左右节点的贪婪算法来评估是不是增加分支,而不能直接计算(8),如下:
L
s
p
l
i
t
=
1
2
[
(
∑
i
∈
I
L
g
i
)
2
∑
i
∈
I
L
h
i
+
λ
+
(
∑
i
∈
I
R
g
i
)
2
∑
i
∈
I
R
h
i
+
λ
−
(
∑
i
∈
I
g
i
)
2
∑
i
∈
I
h
i
+
λ
]
−
γ
(9)
\mathcal{L}_{split}=\dfrac{1}{2}\left[\dfrac{(\sum_{i\in I_L}g_i)^2}{\sum_{i\in I_L}h_i+\lambda}+\dfrac{(\sum_{i\in I_R}g_i)^2}{\sum_{i\in I_R}h_i+\lambda}-\dfrac{(\sum_{i\in I}g_i)^2}{\sum_{i\in I}h_i+\lambda}\right]-\gamma\tag{9}
Lsplit=21[∑i∈ILhi+λ(∑i∈ILgi)2+∑i∈IRhi+λ(∑i∈IRgi)2−∑i∈Ihi+λ(∑i∈Igi)2]−γ(9)
R}h_i+\lambda}-\dfrac{(\sum_{i\in I}g_i)^2}{\sum_{i\in I}h_i+\lambda}\right]-\gamma\tag{9}
$$