RDD
RDD 是构建 Spark 分布式内存计算引擎的基石,如 :DAG/调度系统都衍生自 RDD
- RDD 是对分布式数据集的抽象,囊括所有内存/磁盘的分布式数据实体
RDD/数组差异
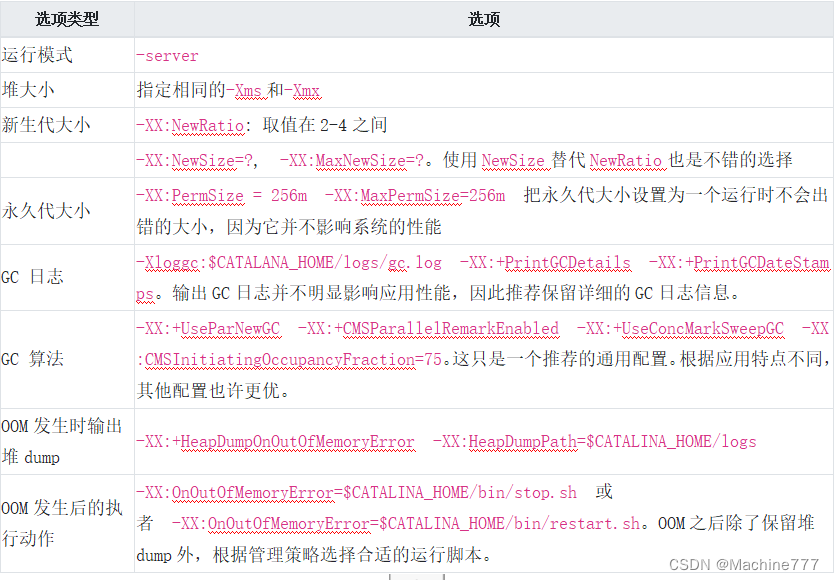
| 对比项 | 数组 | RDD |
|---|---|---|
| 概念 | 数据结构实体 | 数据模型抽象 |
| 数据跨度 | 单机进程内 | 跨进程,跨计算节点 |
| 数据构成 | 数组元素 | 数据分片(Partitions) |
| 数据定位 | 数组下标,索引 | 数据分片索引 |
RDD属性
RDD 的 4 大属性:
| 属性名 | 成员变量 | 属性含义 | RDD特性 | 刻画方向 |
|---|---|---|---|---|
| partitions | 变量 | RDD的切片实体 | 分布式 | 横向 |
| partitioner | 方法 | 切分 RDD规则 | ||
| dependencies | 变量 | RDD 依赖父RDD | 容错性 | 纵向 |
| compute | 方法 | 生成 RDD 接口 |
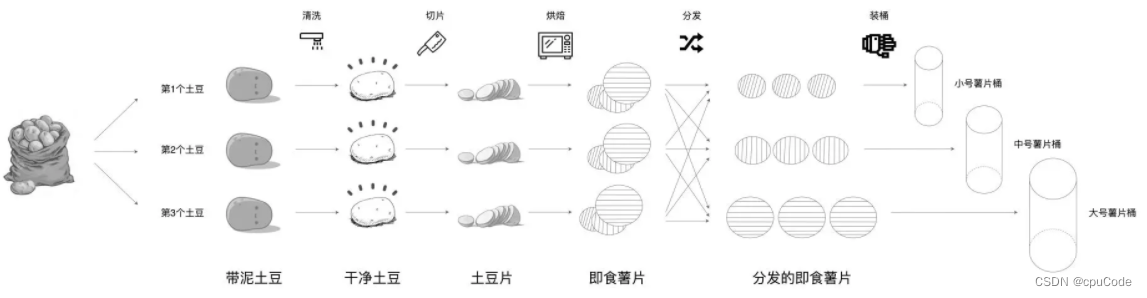
薯片的加工流程 :
- 不同的食材形态 - RDD 概念
- 同一种食材形态在不同流水线上的具体实物 - partitions
- 食材按照什么规则被分配到哪条流水线 - partitioner
- 每一种食材形态都会依赖上一种形态,依赖关系 - dependencies
- 不同环节的加工方法 - compute
dependencies/compute :

编程模型
高阶函数(Higher-order Functions):本身是函数,参数是函数、返回值是函数的函数
- map、filter、flatMap、reduceByKey 这些算子都是高阶函数,都用在 RDD 上、用来 RDD 之间的转换
- RDD 到 RDD 的转换,就是数据形态上的转换(Transformations)
RDD 的编程模型有两种算子:
- Transformations 类算子:定描述数据形态的转换过程
- Actions 类算子:将计算结果收集起来、物化到磁盘
Spark 运行时的两个计算环节:
- 基于不同数据形态之间的转换,构建计算流图(DAG,Directed Acyclic Graph)
- 通过 Actions 类算子,以回溯的方式去触发执行这个计算流图
延迟计算(Lazy Evaluation):
- 用 Transformations 算子,不会执行计算,只有调用 Actions 算子时,才会执行
运行流程 :