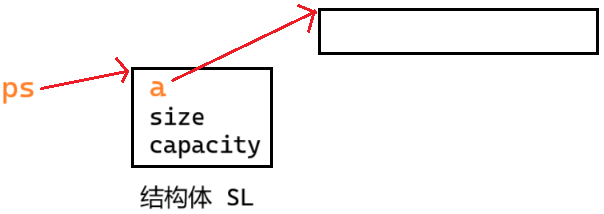
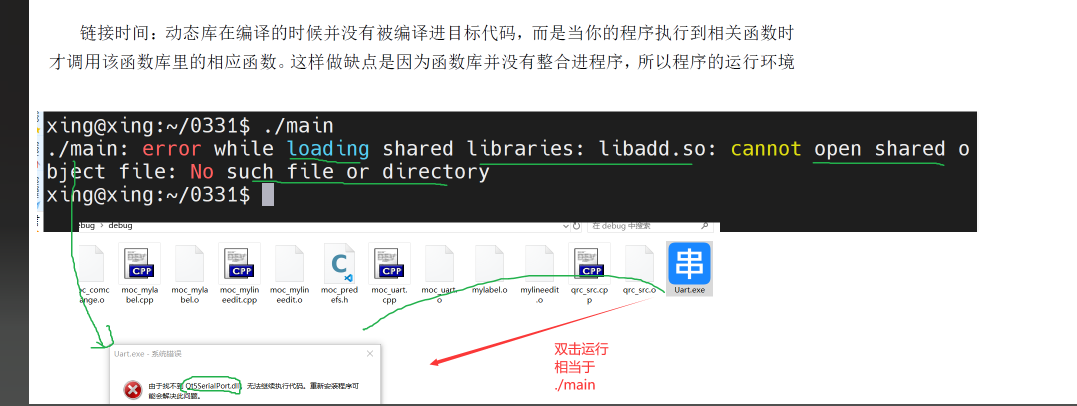
GPT的介绍
🧠 一句话总结:
字典树是一种专门用来存很多字符串的“超级前缀树”,查找某个字符串或前缀的时候,特别快!
✍️ 举个生活例子(类比):
你想做一个词典(Dictionary),里面有这些单词:
apple
app
april
bat
ball
banana
你现在想知道:
- “apple”在不在词典里? ✅
- “app”是某个单词的前缀吗?✅
- 有没有以 “ba” 开头的单词?✅
如果你把这些单词一个个拿出来比,那太慢了。
于是我们把它们塞进一个神奇的数据结构:字典树。
🌳 字典树长啥样?
我们用“树”的形式来表示字符串的每个字母(从根节点一层一层往下走):
(根)
/
a
/
p
/ \
p r
/ \
l i
/ \
e l
另一边:
b
/ \
a a
/ \
l n
/ \
l a
\
n
\
a
每个节点代表一个字母,每条路径代表一个字符串
每个节点有cnt,表示以这个节点为结尾的字符串的个数
🚀 字典树的速度怎么样?
- 普通查找(字符串在数组里)时间是:O(字符串长度 × 数组长度)
- 字典树查找时间是:O(字符串长度),和多少单词没关系!
💡 形象一点说:
- 数组/哈希表:像是一页一页翻字典
- 字典树:像是按字母顺序直接走向目标
就像 Google 搜索你输入 "ap",它能秒给你推荐 "apple"、"app store"、"april" —— 这背后可能就是字典树!
🧩 总结一张图:
"apple", "app", "april" ==> 共享前缀 "ap"
↓
Trie 就是把这些前缀共享,像搭积木一样拼起来
↓
节省空间 + 查询高效
模板
const int N = 1e5 + 10; // 最大节点数(字符串数量×平均长度)
int son[N][26]; // 每个节点的26个子节点(用下标表示)
int cnt[N]; // cnt[i] 表示以 i 号节点结尾的单词个数
int idx = 0; // 当前用到的节点编号(0 是根)
// 插入字符串
void insert(const string &s) {
int p = 0;
for (char c : s) {
int u = c - 'a';
if (!son[p][u]) son[p][u] = ++idx; // 创建新节点
p = son[p][u];
}
cnt[p]++; // 这个节点是一个完整单词的结尾
}
// 查询字典树中插入了几个s
int query(const string& s) {
int p = 0;
for (int i = 0; i < s.size(); ++i) {
int u = s[i] - 'a';
if (son[p][u] == 0) {
return 0;
}
p = son[p][u];
}
return cnt[p];
}
查询是否存在以prefix 为前缀的字符串
bool startsWith(string prefix) {
int p=0;
for(auto c:prefix){
int u=c-'a';
if(son[p][u]==0) return 0;
p=son[p][u];
}
return 1;
}