文章目录
- 前言
- 1.理论部分
- 1.1 依存句法理论
- 1.2 依存句法分析
- 1.3 依存句法的应用
- 2. 代码实践
- 2.1 数据集
- 2.2 代码实现
- 2.3 效果查看
- 总结
前言
本文首先介绍依存句法理论,之后通过代码实现ASGCN中的依存句法图数据的构建。
1.理论部分
1.1 依存句法理论
词与词之间存在主从关系,这是一种二元不等价的关系。在句子中,如果一个词修饰另一个词,则称修饰词为从属词(dependent),被修饰的词语称为支配词(head),两者之间的语法关系称为依存关系(dependency relation)。
现代依存语法中,语言学家对依存句法提出了四个约束性公理:
- 有且只有一个词语(ROOT,虚拟根节点,简称虚根)不依存于其他词语。
- 除此之外所有单词必须依存于其他单词。
- 每个单词不能依存于多个单词。
- 如果单词A依存于B,那么位置处于A和B之间的单词C只能依存于A、B或AB之间的单词。
例子:对于句子“猴子喜欢吃香蕉”,构建其依存句法树如下图所示。

1.2 依存句法分析
- 基于图的依存句法分析:树是图的特例,依存句法树其实是完全图的一个子图。如果为完全图中的每条边是否属于句法树的可能性打分,然后就可以利用Prim之类的算法找出最大生成树作为依存句法树了。这样将整棵树的分数分解为每条边上的分数之和,然后在图上搜索最优解的方法统称为基于图的方法。
- 基于转移的依存句法分析:
我们将一颗依存句法树的构建过程表示为两个动作。如果机器学习模型能够根据句子的某些特征准确地预测这些动作,那么计算机便能够根据这些动作拼装出正确的依存句法树了。这样的拼装动作称为转移。而这类算法统称为基于转移的依存句法分析。
1.3 依存句法的应用
短语缩句、提取文本主要内容、文本分类、情感分析、意见抽取等。
2. 代码实践
2.1 数据集
使用的数据集为acl-14-short-data中的训练集,文件后缀为“.raw”,文件中部分数据如下所示,数据由上千条评论组成,每条评论中方面词被挖出单独放在第二行,空缺位置用$T$表示,每条数据的第三行为数字-1或0,亦或1,表示此方名词对应的情感为消极、积极或中性。
i agree about arafat . i mean , shit , they even gave one to $T$ ha . it should be called ‘’ the worst president ‘’ prize .
jimmy carter
-1
musicmonday $T$ - lucky do you remember this song ? it ` s awesome . i love it .
britney spears
1
2.2 代码实现
# -*- coding: utf-8 -*-
import numpy as np
import spacy
import pickle
import argparse
from spacy.tokens import Doc
class WhitespaceTokenizer(object):
def __init__(self, vocab):
self.vocab = vocab
def __call__(self, text):
words = text.split() # 句子切分为单词
# All tokens 'own' a subsequent space character in this tokenizer
spaces = [True] * len(words)
return Doc(self.vocab, words=words, spaces=spaces) # 单词恢复成句子
nlp = spacy.load('en_core_web_sm')
nlp.tokenizer = WhitespaceTokenizer(nlp.vocab) # 将单词变为doc的类
def dependency_adj_matrix(text):
# https://spacy.io/docs/usage/processing-textco
tokens = nlp(text)
words = text.split() # 句子切分为单次
matrix = np.zeros((len(words), len(words))).astype('float32') # 创建n*n的矩阵(n为句子中单词的个数)
assert len(words) == len(list(tokens)) #做出一些假设,程序运行时如果假设不成立,程序就会中断
# 构建依存矩阵
for token in tokens:
matrix[token.i][token.i] = 1
for child in token.children: # 返回依赖token的其他token
matrix[token.i][child.i] = 1
matrix[child.i][token.i] = 1
return matrix
def process(filename):
fin = open(filename, 'r', encoding='utf-8', newline='\n', errors='ignore') # 打开文件
lines = fin.readlines() # 读入数据
fin.close() # 关闭文件
idx2graph = {}
fout = open('dasgu'+'.graph', 'wb') # 创建新文件(用于存储图数据)
for i in range(0, len(lines), 3):
text_left, _, text_right = [s.strip() for s in lines[i].partition("$T$")]
aspect = lines[i + 1].strip()
adj_matrix = dependency_adj_matrix(text_left+' '+aspect+' '+text_right) # 将方面词回填到句子中
idx2graph[i] = adj_matrix # 构建每个句子的依存矩阵
pickle.dump(idx2graph, fout) # 将依存树矩阵的数据写入文件
fout.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', default=None, type=str, help='path to dataset')
opt = parser.parse_args()
process('./datasets/acl-14-short-data/train.raw')
2.3 效果查看
通过在代码的如下行出打断点调试来查看第一条数据的依赖图数据idx2graph[0]如下图所示。
idx2graph[i] = adj_matrix # 构建每个句子的依存矩阵
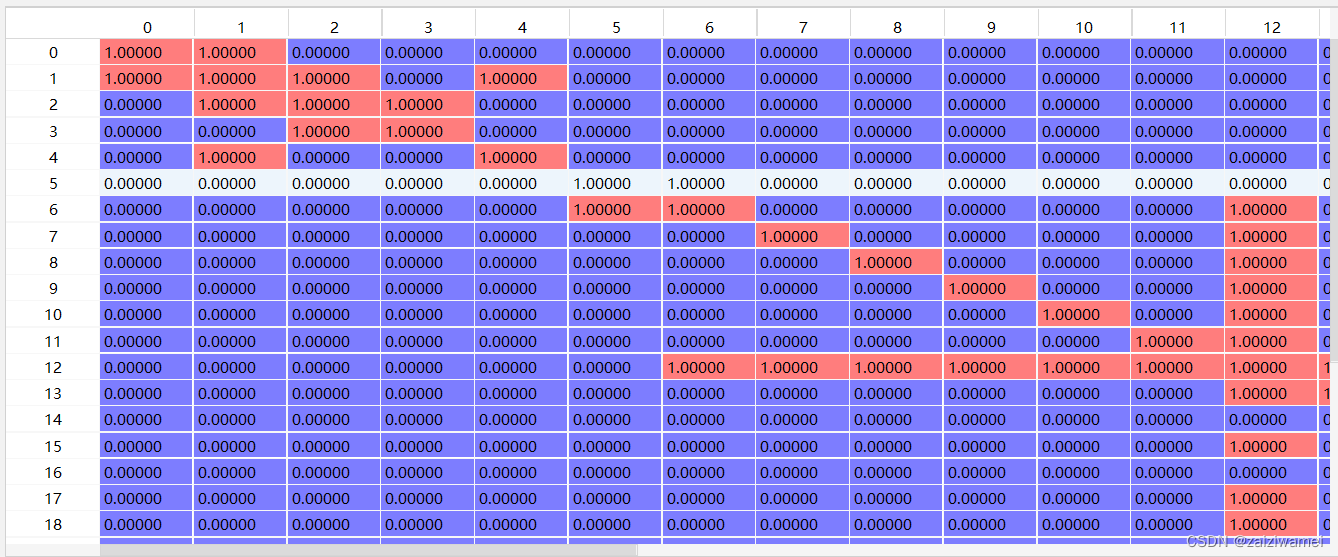
整个程序结束后在代码文件所在的目录下生成"dasgu.graph"的文件。

总结
本文简要介绍了依存句法树以依存句法图的代码构建过程。



![[ IFRS 17 ] 新准则下如何确认保险合同](https://img-blog.csdnimg.cn/bbe924c65ddd4e80ba2b954a1cd2020b.png)