机器学习笔记之狄利克雷过程——随机测度的生成过程[折棍子过程]
- 引言
- 回顾:狄利克雷过程——定义
- 随机测度的生成过程
- 从随机测度的生成过程观察标签参数 α \alpha α与随机测度离散程度之间的关系
引言
上一节使用公式推导的方式介绍了狄利克雷过程中标量参数 α \alpha α的极端取值对于生成的随机测度 G ( i ) \mathcal G^{(i)} G(i)离散程度的影响。本节从随机测度的生成角度对标量参数 α \alpha α与离散程度的关系进行描述。
回顾:狄利克雷过程——定义
已知
G
(
i
)
\mathcal G^{(i)}
G(i)服从狄利克雷过程
DP
(
α
,
H
)
\text{DP}(\alpha,\mathcal H)
DP(α,H):
G
(
i
)
∼
DP
(
α
,
H
)
\mathcal G^{(i)} \sim \text{DP}(\alpha,\mathcal H)
G(i)∼DP(α,H)
其中, G ( i ) \mathcal G^{(i)} G(i)被称作随机测度( Random Measure \text{Random Measure} Random Measure),它是从狄利克雷过程 DP ( α , H ) \text{DP}(\alpha,\mathcal H) DP(α,H)中生成的一个样本;并且它的本质是一个离散型概率分布。
假设该分布
G
(
i
)
\mathcal G^{(i)}
G(i)是一个一维随机分布,并且其内部包含
K
\mathcal K
K个离散特征:
G
(
i
)
=
(
g
1
(
i
)
,
g
2
(
i
)
,
⋯
,
g
K
(
i
)
)
T
∑
k
=
1
K
g
k
(
i
)
=
1
\mathcal G^{(i)} = (g_1^{(i)},g_2^{(i)},\cdots,g_{\mathcal K}^{(i)})^T \quad \sum_{k=1}^{\mathcal K} g_k^{(i)} = 1
G(i)=(g1(i),g2(i),⋯,gK(i))Tk=1∑Kgk(i)=1
其中
g
k
(
i
)
g_k^{(i)}
gk(i)表示
G
(
i
)
\mathcal G^{(i)}
G(i)中的第
k
k
k个特征,它的权重信息。其他权重信息对应的示例结果表示如下:
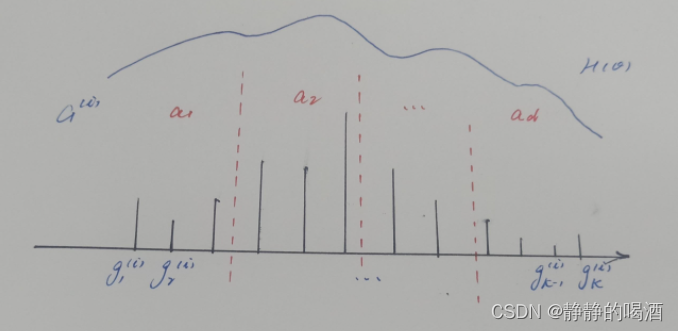
其中,图像中竖线的长度就表示特征权重信息的大小。我们将
K
\mathcal K
K个权重结果划分成
D
\mathcal D
D个区域,每个区域中可能存在若干个权重结果:
其中a d ( d = 1 , 2 , ⋯ , D ) a_d(d=1,2,\cdots,\mathcal D) ad(d=1,2,⋯,D)表示区域编号;G ( i ) ( a d ) \mathcal G^{(i)}(a_d) G(i)(ad)表示区域a d a_d ad内存在的权重结果之和。这仅是一个特征信息重组的部分,总量没有发生变化。
{ G ( i ) ( a 1 ) , G ( i ) ( a 2 ) , ⋯ , G ( i ) ( a D ) } { G ( i ) ( a d ) = ∑ g k ( i ) ∈ a d g k ( i ) ∑ d = 1 D G ( i ) ( a d ) = 1 \left\{\mathcal G^{(i)}(a_1),\mathcal G^{(i)}(a_2),\cdots,\mathcal G^{(i)}(a_{\mathcal D})\right\} \quad \begin{cases} \mathcal G^{(i)}(a_d) = \sum_{g_k^{(i)} \in a_d} g_k^{(i)} \\ \quad \\ \sum_{d=1}^{\mathcal D} \mathcal G^{(i)}(a_d) = 1 \end{cases} {G(i)(a1),G(i)(a2),⋯,G(i)(aD)}⎩ ⎨ ⎧G(i)(ad)=∑gk(i)∈adgk(i)∑d=1DG(i)(ad)=1
这意味 G ( i ) ( a d ) ( d = 1 , 2 , ⋯ , D ) \mathcal G^{(i)}(a_d)(d=1,2,\cdots,\mathcal D) G(i)(ad)(d=1,2,⋯,D)同样是随机变量。关于新的离散分布 { G ( i ) ( a 1 ) , G ( i ) ( a 2 ) , ⋯ , G ( i ) ( a D ) } \left\{\mathcal G^{(i)}(a_1),\mathcal G^{(i)}(a_2),\cdots,\mathcal G^{(i)}(a_{\mathcal D})\right\} {G(i)(a1),G(i)(a2),⋯,G(i)(aD)},它需要服从的性质是狄利克雷分布:
并且‘狄利克雷分布’内部对应参数信息是α H ( a d ) ( d = 1 , 2 , ⋯ , D ) \alpha \mathcal H(a_d)(d=1,2,\cdots,\mathcal D) αH(ad)(d=1,2,⋯,D)可以比较H ( θ ( i ) ) \mathcal H(\theta^{(i)}) H(θ(i))与H ( a d ) \mathcal H(a_d) H(ad)的意义,它们均表示基本测度,只不过a d a_d ad区域中可能包含若干个θ \theta θ.
{ G ( i ) ( a 1 ) , G ( i ) ( a 2 ) , ⋯ , G ( i ) ( a D ) } ∼ Dir [ α H ( a 1 ) , α H ( a 2 ) , ⋯ , α H ( a D ) ] \left\{\mathcal G^{(i)}(a_1),\mathcal G^{(i)}(a_2),\cdots,\mathcal G^{(i)}(a_{\mathcal D})\right\} \sim \text{Dir} \left[\alpha \mathcal H(a_1),\alpha \mathcal H(a_2),\cdots,\alpha \mathcal H(a_{\mathcal D})\right] {G(i)(a1),G(i)(a2),⋯,G(i)(aD)}∼Dir[αH(a1),αH(a2),⋯,αH(aD)]
随机测度的生成过程
现在已经知道了狄利克雷过程的定义,那么随机测度
G
(
i
)
\mathcal G^{(i)}
G(i)要如何生成呢?自然是采样(
Sampling
\text{Sampling}
Sampling)。在蒙特卡洛方法介绍中提到了关于从分布中生成的方式。如拒绝采样(
Rejection Sampling
\text{Rejection Sampling}
Rejection Sampling):
M
⋅
Q
(
x
)
≥
P
(
x
)
\mathcal M \cdot \mathcal Q(x) \geq \mathcal P(x)
M⋅Q(x)≥P(x)
重要性采样(
Importance Sampling
\text{Importance Sampling}
Importance Sampling)等等:
E
P
(
x
)
[
f
(
x
)
]
≈
1
N
∑
i
=
1
N
[
f
(
x
(
i
)
)
⋅
P
(
x
(
i
)
)
Q
(
x
(
i
)
)
]
\mathbb E_{\mathcal P(x)} [f(x)] \approx \frac{1}{N} \sum_{i=1}^N \left[f(x^{(i)}) \cdot \frac{\mathcal P(x^{(i)})}{\mathcal Q(x^{(i)})}\right]
EP(x)[f(x)]≈N1i=1∑N[f(x(i))⋅Q(x(i))P(x(i))]
但这些采样方式仅针对于单个样本。
经过上面的介绍, G ( i ) \mathcal G^{(i)} G(i)并不是一个简单样本,而是一个完整分布。在极大似然估计与最大后验概率估计中介绍过,概率分布是一个客观的存在,它可以源源不断地产生样本。
如何去采出一个存在无穷样本的分布?我们直接从样本的权重信息进行采样,构造一个过程。这个过程也被称作折棍子过程( Stick-breaking \text{Stick-breaking} Stick-breaking):
-
已知关于参数 θ = { θ ( i ) } i = 1 N \theta = \{\theta^{(i)}\}_{i=1}^N θ={θ(i)}i=1N的基本测度 H ( θ ) \mathcal H(\theta) H(θ)。首先从 H ( θ ) \mathcal H(\theta) H(θ)中随机采样出一个样本 θ ( i ) \theta^{(i)} θ(i):
θ ( k ) ∼ H ( θ ) \theta^{(k)} \sim \mathcal H(\theta) θ(k)∼H(θ) -
下一步,我们需要采样它的权重信息:
在θ ( k ) \theta^{(k)} θ(k)被确定后,它就已经是随机离散测度G ( i ) \mathcal G^{(i)} G(i)中的一个随机变量了,按照理论来说,这种随机变量是无穷无尽的,因为我们从H ( θ ) \mathcal H(\theta) H(θ)中源源不断的产生样本。随着样本θ ( k ) \theta^{(k)} θ(k)的增多,G ( i ) \mathcal G^{(i)} G(i)的离散程度越低,最终会成为连续分布。为了保证G ( i ) \mathcal G^{(i)} G(i)是离散分布,关于θ ( k ) \theta^{(k)} θ(k)权重的分配是至关重要的。通过观察发现,θ ( k ) \theta^{(k)} θ(k)的生成仅与基本测度H ( θ ) \mathcal H(\theta) H(θ)相关,和标量参数α \alpha α无关。
-
假定 θ ( k ) \theta^{(k)} θ(k)对应的权重为 π ( k ) \pi^{(k)} π(k),该值服从 Beta \text{Beta} Beta分布:
关于Beta \text{Beta} Beta分布,该分布中的样本值域均为( 0 , 1 ] (0,1] (0,1],并且关于Beta(a,b) \text{Beta(a,b)} Beta(a,b)分布的期望(该分布的位置)与参数a , b a,b a,b之间的关系为:E [ x ] = a a + b \mathbb E[x] = \frac{a}{a + b} E[x]=a+ba.
π ( k ) = β 1 ∼ Beta ( 1 , α ) \pi^{(k)} = \beta_1 \sim \text{Beta}(1,\alpha) π(k)=β1∼Beta(1,α) -
此时, θ ( k ) \theta^{(k)} θ(k)对应权重 π ( k ) \pi^{(k)} π(k)已经采样完成。继续采集后续的样本。再次从 H ( θ ) \mathcal H(\theta) H(θ)中采出一个样本 θ ( j ) \theta^{(j)} θ(j),继续计算它的权重信息:
和第一个样本θ ( k ) \theta^{(k)} θ(k)不同的是,它需要从除去π ( k ) \pi^{(k)} π(k)后的剩余权重中获取相应的权重.很明显,就像‘折棍子’一样,如果将( 0 , 1 ] (0,1] (0,1]视作完整的棍子,那么每次迭代过程中,每折掉一段,就将剩余的长度到下次迭代时,再进行折断。
{ θ ( j ) ∼ H ( θ ) β 2 ∼ Beta ( 1 , α ) π ( j ) = ( 1 − π ( k ) ) ⋅ β 2 \begin{cases} \theta^{(j)} \sim \mathcal H(\theta) \\ \beta_2 \sim \text{Beta}(1,\alpha) \\ \pi^{(j)} = (1 - \pi^{(k)}) \cdot \beta_2 \end{cases} ⎩ ⎨ ⎧θ(j)∼H(θ)β2∼Beta(1,α)π(j)=(1−π(k))⋅β2
-
以此类推,直到权重全部被分配出去,此时的概率分布就完成了,此时就生成了一个随机测度 G ( i ) \mathcal G^{(i)} G(i)。
从上述的过程可以发现,虽然都是从Beta ( 1 , α ) \text{Beta}(1,\alpha) Beta(1,α)中随机结果,但是随着‘棍子’的长度缩短,对应的权值结果是‘递减’的。越往后迭代产生的权重,对于整个分布的影响越小。
从随机测度的生成过程观察标签参数 α \alpha α与随机测度离散程度之间的关系
关于从
Beta
(
1
,
α
)
\text{Beta}(1,\alpha)
Beta(1,α)分布中产生的权值结果
β
\beta
β,它的期望表示如下:
E
[
x
]
=
1
1
+
α
\mathbb E[x] = \frac{1}{1 + \alpha}
E[x]=1+α1
而期望在
Beta
\text{Beta}
Beta分布表示 被采样概率最高的样本位置,实际它就是确定了
Beta
\text{Beta}
Beta分布的位置。
- 如果 α = 0 \alpha = 0 α=0时,对应的期望结果 E [ x ] = 1 \mathbb E[x] = 1 E[x]=1,这意味着第一次采样的时候就将所有的权重全部分配给第一个样本;剩余的样本没有任何权重;
- 相反,当 α = ∞ \alpha = \infty α=∞时,对应的期望结果 E [ x ] → 0 \mathbb E[x] \to 0 E[x]→0,这意味着每一次采样仅能获取无限接近于 0 0 0的权重,也就是说,即便采集了无穷个样本,也无法将权重消耗完,那么此时的分布 G ( i ) \mathcal G^{(i)} G(i)就是基本测度 H \mathcal H H。
相关参考:
徐亦达机器学习:Dirichlet-Process-part 3




![[Java·算法·困难]LeetCode25. K 个一组翻转链表](https://img-blog.csdnimg.cn/d8afa9d66cf8463d88277e112a2488b4.png)