非精读BERT-b站有讲解视频(跟着李沐学AI)
(大佬好厉害,讲的比直接看论文容易懂得多)
写在前面
-
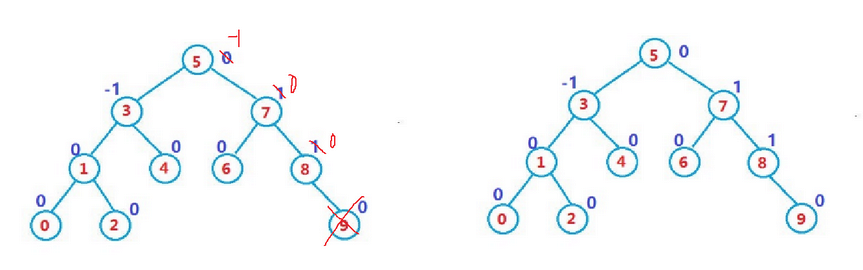
在计算MLM预训练任务的损失函数的时候,参与计算的Tokens有哪些?是全部的15%的词汇还是15%词汇中真正被Mask的那些tokens?
首先在每一个训练序列中以15%的概率随机地选中某个token位置用于预测,假如是第i个token被选中,则会被替换成以下三个token之一:
1)80%的时候是[MASK]。如,my dog is hairy——>my dog is [MASK]
2)10%的时候是随机的其他token。如,my dog is hairy——>my dog is apple
3)10%的时候是原来的token(保持不变,个人认为是作为2)所对应的负类)。如,my dog is hairy——>my dog is hairy -
在实现损失函数的时候,怎么确保没有被 Mask 的函数不参与到损失计算中去;
label_weights就像一个过滤器,将未mask的字的loss过滤掉了。(建议看源码,我没有看代码) -
BERT的三个Embedding为什么直接相加?
https://www.zhihu.com/question/374835153 -
BERT的优缺点分别是什么?
在本篇论文的结论中最大贡献是双向性
选了选双向性带来的不好是什么?做一个选择会得到一些,也会失去一些。
缺点是:与GPT(Improving Language Understanding by Generative Pre-Training)比,BERT用的是编码器,GPT用的是解码器。BERT做机器翻译、文本的摘要(生成类的任务)不好做。
但分类问题在NLP中更常见。
完整解决问题的思路:在一个很大的数据集上训练好一个很宽很深的模型,可以用在很多小的问题上,通过微调来全面提升小数据的性能(在计算机视觉领域用了很多年),模型越大,效果越好(很简单很暴力)。
BERT使用的数据量级很大( B E R T b a s e 是 1 亿, B E R T l a r g e 是 3 亿 {BERT}_{base}是1亿,{BERT}_{large}是3亿 BERTbase是1亿,BERTlarge是3亿) -
你知道有哪些针对BERT的缺点做优化的模型?
https://zhuanlan.zhihu.com/p/347846720
未看,想看可以转到这里 -
BERT怎么用在生成模型中?
不知道,咋用?
贡献:
- 我们演示了双向预训练对语言表示的重要性。与Radford等人(2018)使用单向语言模型进行预训练不同,BERT使用MLM来实现预训练的深度双向表示。这也与Peters等人(2018a)形成了对比,后者使用了独立训练的 left-to-right 和 right-to-left的LMs的浅层连接。
- 我们展示了预先训练的表征减少了对许多精心设计的任务特定架构的需求。BERT 是第一个基于微调的表征模型,它在大型句子级和标记级任务上实现了最先进的性能,优于许多特定于任务的架构。
BERT模型
由Transformer推叠而成,关于Transformer看《Attention Is All You Need》或我之前的文章。
BERT分为两个任务:
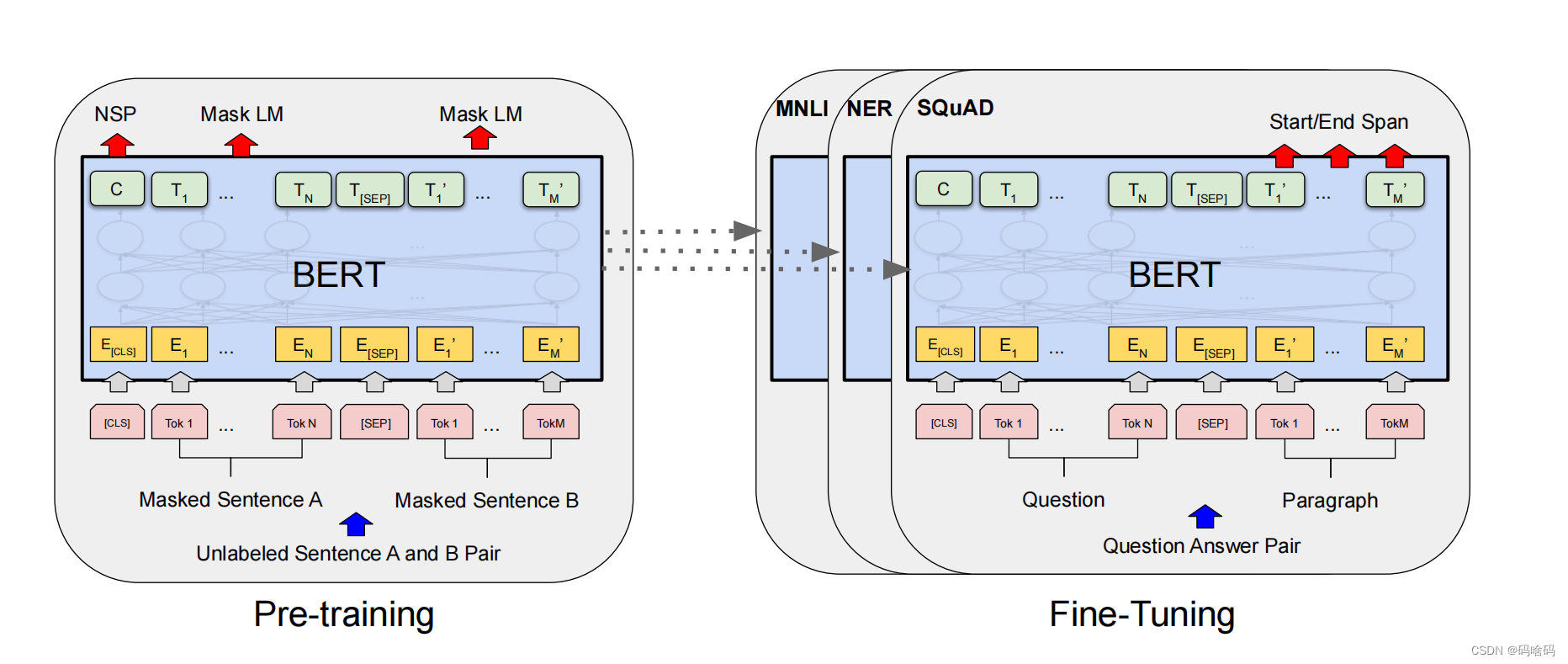
pre-traning:在预训练过程中,该模型在不同的预训练任务上对未标记的数据进行训练。
BERT使用两个无监督的任务对BERT进行预训练。这个步骤如上图的左侧所示。
-
MLM(Masked Language Model):我们简单地随机屏蔽一些百分比的输入标记,然后预测这些掩蔽标记。在我们所有的实验中,我们随机屏蔽了每个序列中15%的所有WordPiece标记。我们只预测被掩蔽的单词,而不是重建整个输入。
-
NSP(Next Sentence Prediction):一些如问答、自然语言推断等任务需要理解两个句子之间的关系,而MLM任务倾向于抽取token层次的表征,因此不能直接获取句子层次的表征。为了使模型能够有能力理解句子间的关系,BERT使用了NSP任务来预训练,简单来说就是预测两个句子是否连在一起。具体的做法是:对于每一个训练样例,我们在语料库中挑选出句子A和句子B来组成,50%的时候句子B就是句子A的下一句(标注为IsNext),剩下50%的时候句子B是语料库中的随机句子(标注为NotNext)。接下来把训练样例输入到BERT模型中,用[CLS]对应的C信息去进行二分类的预测。
fine-tuning:为了进行微调,首先使用预先训练好的参数初始化BERT模型,并使用从下游任务中获得的标记数据对所有参数进行微调。如上图右侧表示。
对于不同的下游任务,BERT结构都可能有轻微变化
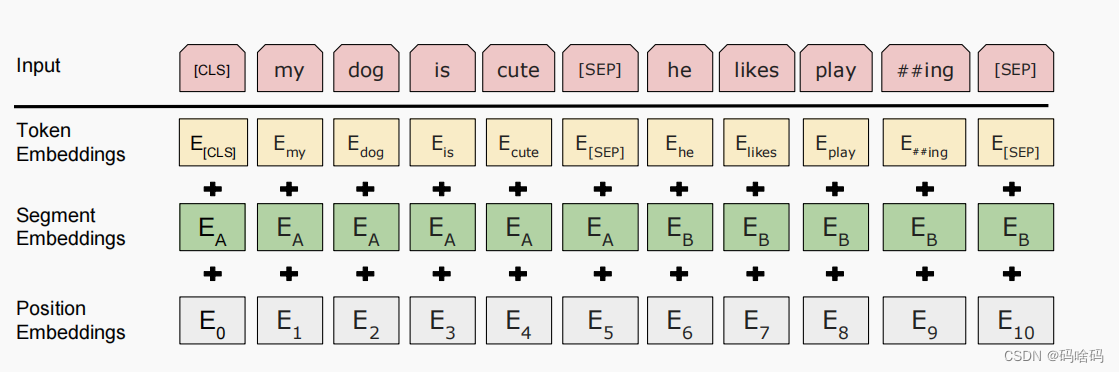
BERT的输入:
分别是对应的token,分割和位置 embeddings,三者相加。
1.2 BERT的输出
介绍完BERT的输入,实际上BERT的输出也就呼之欲出了,因为Transformer的特点就是有多少个输入就有多少个对应的输出,如下图:

BERT的输出
C为分类token([CLS])对应最后一个Transformer的输出, 则代表其他token对应最后一个Transformer的输出。对于一些token级别的任务(如,序列标注和问答任务),就把输入到额外的输出层中进行预测。对于一些句子级别的任务(如,自然语言推断和情感分类任务),就把C输入到额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
参考
知乎