背景
XX 实例(一主一从)xxx 告警中每天凌晨在报 SLA 报警,该报警的意思是存在一定的主从延迟。(若在此时发生主从切换,需要长时间才可以完成切换,要追延迟来保证主从数据的一致性)
XX 实例的慢查询数量最多(执行时间超过 1s 的 SQL 会被记录),XX 应用那方每天晚上在做删除一个月前数据的任务。
分析
使用 pt-query-digest 工具分析最近一周的 mysql-slow.log:
pt-query-digest --since=148h mysql-slow.log | less结果第一部分:
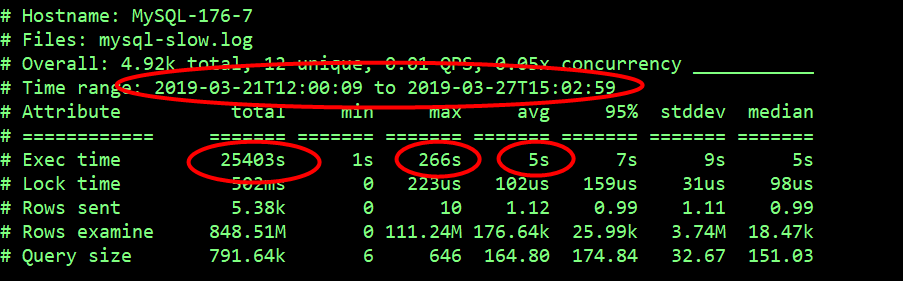
最近一个星期内,总共记录的慢查询执行花费时间为 25403s,最大的慢 SQL 执行时间为 266s,平均每个慢 SQL 执行时间 5s,平均扫描的行数为 1766 万。
结果第二部分:
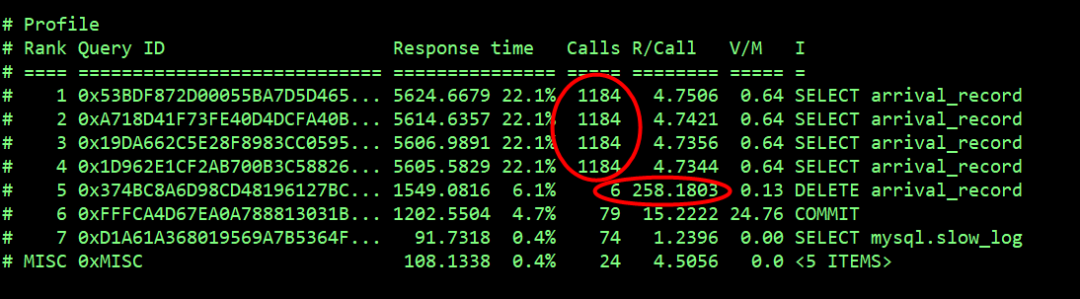
select arrival_record 操作记录的慢查询数量最多有 4 万多次,平均响应时间为 4s,delete arrival_record 记录了 6 次,平均响应时间 258s。
select xxx_record 语句
select arrival_record 慢查询语句都类似于如下所示,where 语句中的参数字段是一样的,传入的参数值不一样:
select count(*) from arrival_record where product_id=26 and receive_time between '2019-03-25 14:00:00' and '2019-03-25 15:00:00' and receive_spend_ms>=0\G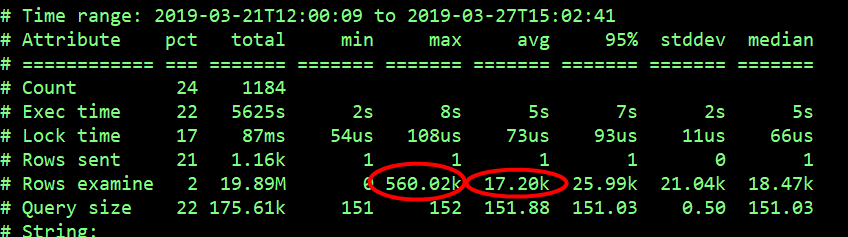
select arrival_record 语句在 MySQL 中最多扫描的行数为 5600 万、平均扫描的行数为 172 万,推断由于扫描的行数多导致的执行时间长。
查看执行计划:
explain select count(*) from arrival_record where product_id=26 and receive_time between '2019-03-25 14:00:00' and '2019-03-25 15:00:00' and receive_spend_ms>=0\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: arrival_record
partitions: NULL
type: ref
possible_keys: IXFK_arrival_record
key: IXFK_arrival_record
key_len: 8
ref: const
rows: 32261320
filtered: 3.70
Extra: Using index condition; Using where
1 row in set, 1 warning (0.00 sec)用到了索引 IXFK_arrival_record,但预计扫描的行数很多有 3000 多万行:
show index from arrival_record;
+----------------+------------+---------------------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+----------------+------------+---------------------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| arrival_record | 0 | PRIMARY | 1 | id | A | 107990720 | NULL | NULL | | BTREE | | |
| arrival_record | 1 | IXFK_arrival_record | 1 | product_id | A | 1344 | NULL | NULL | | BTREE | | |
| arrival_record | 1 | IXFK_arrival_record | 2 | station_no | A | 22161 | NULL | NULL | YES | BTREE | | |
| arrival_record | 1 | IXFK_arrival_record | 3 | sequence | A | 77233384 | NULL | NULL | | BTREE | | |
| arrival_record | 1 | IXFK_arrival_record | 4 | receive_time | A | 65854652 | NULL | NULL | YES | BTREE | | |
| arrival_record | 1 | IXFK_arrival_record | 5 | arrival_time | A | 73861904 | NULL | NULL | YES | BTREE | | |
+----------------+------------+---------------------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
show create table arrival_record;
..........
arrival_spend_ms bigint(20) DEFAULT NULL,
total_spend_ms bigint(20) DEFAULT NULL,
PRIMARY KEY (id),
KEY IXFK_arrival_record (product_id,station_no,sequence,receive_time,arrival_time) USING BTREE,
CONSTRAINT FK_arrival_record_product FOREIGN KEY (product_id) REFERENCES product (id) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=614538979 DEFAULT CHARSET=utf8 COLLATE=utf8_bin |①该表总记录数约 1 亿多条,表上只有一个复合索引,product_id 字段基数很小,选择性不好。
②传入的过滤条件:
where product_id=26 and receive_time between '2019-03-25 14:00:00' and '2019-03-25 15:00:00' and receive_spend_ms>=0
没有 station_nu 字段,使用不到复合索引 IXFK_arrival_record 的 product_id,station_no,sequence,receive_time 这几个字段。
③根据最左前缀原则,select arrival_record 只用到了复合索引 IXFK_arrival_record 的第一个字段 product_id,而该字段选择性很差,导致扫描的行数很多,执行时间长。
④receive_time 字段的基数大,选择性好,可对该字段单独建立索引,select arrival_record sql 就会使用到该索引。
现在已经知道了在慢查询中记录的 select arrival_record where 语句传入的参数字段有 product_id,receive_time,receive_spend_ms,还想知道对该表的访问有没有通过其他字段来过滤了
神器 tcpdump 出场的时候到了,使用 tcpdump 抓包一段时间对该表的 select 语句:
tcpdump -i bond0 -s 0 -l -w - dst port 3316 | strings | grep select | egrep -i 'arrival_record' >/tmp/select_arri.log获取 select 语句中 from 后面的 where 条件语句:
IFS_OLD=$IFS
IFS=$'\n'
for i in `cat /tmp/select_arri.log `;do echo ${i#*'from'}; done | less
IFS=$IFS_OLD
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=17 and arrivalrec0_.station_no='56742'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=22 and arrivalrec0_.station_no='S7100'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=24 and arrivalrec0_.station_no='V4631'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=22 and arrivalrec0_.station_no='S9466'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=24 and arrivalrec0_.station_no='V4205'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=24 and arrivalrec0_.station_no='V4105'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=24 and arrivalrec0_.station_no='V4506'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=24 and arrivalrec0_.station_no='V4617'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=22 and arrivalrec0_.station_no='S8356'
arrival_record arrivalrec0_ where arrivalrec0_.sequence='2019-03-27 08:40' and arrivalrec0_.product_id=22 and arrivalrec0_.station_no='S8356'select 该表 where 条件中有 product_id,station_no,sequence 字段,可以使用到复合索引 IXFK_arrival_record 的前三个字段。
综上所示,优化方法为:
删除复合索引 IXFK_arrival_record
建立复合索引 idx_sequence_station_no_product_id
建立单独索引 indx_receive_time
delete xxx_record 语句
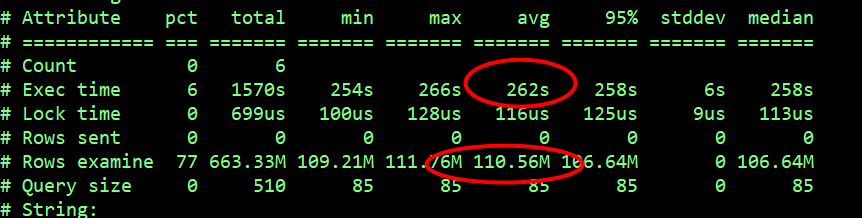
该 delete 操作平均扫描行数为 1.1 亿行,平均执行时间是 262s。
delete 语句如下所示,每次记录的慢查询传入的参数值不一样:
delete from arrival_record where receive_time < STR_TO_DATE('2019-02-23', '%Y-%m-%d')\G执行计划:
explain select * from arrival_record where receive_time < STR_TO_DATE('2019-02-23', '%Y-%m-%d')\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: arrival_record
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 109501508
filtered: 33.33
Extra: Using where
1 row in set, 1 warning (0.00 sec)该 delete 语句没有使用索引(没有合适的索引可用),走的全表扫描,导致执行时间长。
优化方法也是:建立单独索引 indx_receive_time(receive_time)。
测试
拷贝 arrival_record 表到测试实例上进行删除重新索引操作。
XX 实例 arrival_record 表信息:
du -sh /datas/mysql/data/3316/cq_new_cimiss/arrival_record*
12K /datas/mysql/data/3316/cq_new_cimiss/arrival_record.frm
48G /datas/mysql/data/3316/cq_new_cimiss/arrival_record.ibd
select count() from cq_new_cimiss.arrival_record;
+-----------+
| count() |
+-----------+
| 112294946 |
+-----------+
1亿多记录数
SELECT
table_name,
CONCAT(FORMAT(SUM(data_length) / 1024 / 1024,2),'M') AS dbdata_size,
CONCAT(FORMAT(SUM(index_length) / 1024 / 1024,2),'M') AS dbindex_size,
CONCAT(FORMAT(SUM(data_length + index_length) / 1024 / 1024 / 1024,2),'G') AS table_size(G),
AVG_ROW_LENGTH,table_rows,update_time
FROM
information_schema.tables
WHERE table_schema = 'cq_new_cimiss' and table_name='arrival_record';
+----------------+-------------+--------------+------------+----------------+------------+---------------------+
| table_name | dbdata_size | dbindex_size | table_size(G) | AVG_ROW_LENGTH | table_rows | update_time |
+----------------+-------------+--------------+------------+----------------+------------+---------------------+
| arrival_record | 18,268.02M | 13,868.05M | 31.38G | 175 | 109155053 | 2019-03-26 12:40:17 |
+----------------+-------------+--------------+------------+----------------+------------+---------------------+磁盘占用空间 48G,MySQL 中该表大小为 31G,存在 17G 左右的碎片,大多由于删除操作造成的。(记录被删除了,空间没有回收)
备份还原该表到新的实例中,删除原来的复合索引,重新添加索引进行测试。
mydumper 并行压缩备份:
user=root
passwd=xxxx
socket=/datas/mysql/data/3316/mysqld.sock
db=cq_new_cimiss
table_name=arrival_record
backupdir=/datas/dump_$table_name
mkdir -p $backupdir
nohup echo `date +%T` && mydumper -u $user -p $passwd -S $socket -B $db -c -T $table_name -o $backupdir -t 32 -r 2000000 && echo `date +%T` &并行压缩备份所花时间(52s)和占用空间(1.2G,实际该表占用磁盘空间为 48G,mydumper 并行压缩备份压缩比相当高):
Started dump at: 2019-03-26 12:46:04
........
Finished dump at: 2019-03-26 12:46:56
du -sh /datas/dump_arrival_record/
1.2G /datas/dump_arrival_record/拷贝 dump 数据到测试节点:
scp -rp /datas/dump_arrival_record root@10.230.124.19:/datas多线程导入数据:
time myloader -u root -S /datas/mysql/data/3308/mysqld.sock -P 3308 -p root -B test -d /datas/dump_arrival_record -t 32
real 126m42.885s
user 1m4.543s
sys 0m4.267s逻辑导入该表后磁盘占用空间:
du -h -d 1 /datas/mysql/data/3308/test/arrival_record.*
12K /datas/mysql/data/3308/test/arrival_record.frm
30G /datas/mysql/data/3308/test/arrival_record.ibd
没有碎片,和mysql的该表的大小一致
cp -rp /datas/mysql/data/3308 /datas分别使用 online DDL 和 pt-osc 工具来做删除重建索引操作。
先删除外键,不删除外键,无法删除复合索引,外键列属于复合索引中第一列:
nohup bash /tmp/ddl_index.sh &
2019-04-04-10:41:39 begin stop mysqld_3308
2019-04-04-10:41:41 begin rm -rf datadir and cp -rp datadir_bak
2019-04-04-10:46:53 start mysqld_3308
2019-04-04-10:46:59 online ddl begin
2019-04-04-11:20:34 onlie ddl stop
2019-04-04-11:20:34 begin stop mysqld_3308
2019-04-04-11:20:36 begin rm -rf datadir and cp -rp datadir_bak
2019-04-04-11:22:48 start mysqld_3308
2019-04-04-11:22:53 pt-osc begin
2019-04-04-12:19:15 pt-osc stoponline DDL 花费时间为 34 分钟,pt-osc 花费时间为 57 分钟,使用 onlne DDL 时间约为 pt-osc 工具时间的一半。
做 DDL 参考:
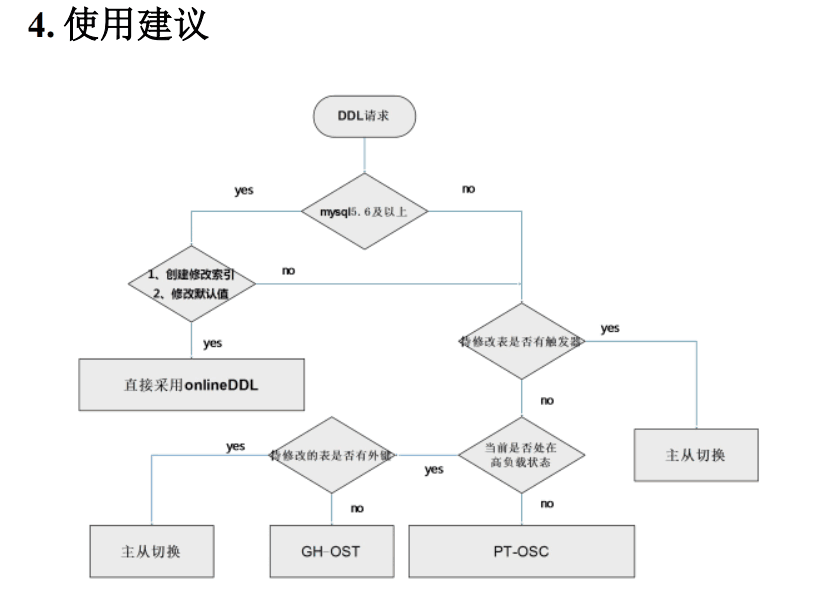
实施
由于是一主一从实例,应用是连接的 vip,删除重建索引采用 online DDL 来做。
停止主从复制后,先在从实例上做(不记录 binlog),主从切换,再在新切换的从实例上做(不记录 binlog):
function red_echo () {
local what="$*"
echo -e "$(date +%F-%T) ${what}"
}
function check_las_comm(){
if [ "$1" != "0" ];then
red_echo "$2"
echo "exit 1"
exit 1
fi
}
red_echo "stop slave"
mysql -uroot -p$passwd --socket=/datas/mysql/data/${port}/mysqld.sock -e"stop slave"
check_las_comm "$?" "stop slave failed"
red_echo "online ddl begin"
mysql -uroot -p$passwd --socket=/datas/mysql/data/${port}/mysqld.sock -e"set sql_log_bin=0;select now() as ddl_start;ALTER TABLE $db_.\`${table_name}\` DROP FOREIGN KEY FK_arrival_record_product,drop index IXFK_arrival_record,add index idx_product_id_sequence_station_no(product_id,sequence,station_no),add index idx_receive_time(receive_time);select now() as ddl_stop" >>${log_file} 2>& 1
red_echo "onlie ddl stop"
red_echo "add foreign key"
mysql -uroot -p$passwd --socket=/datas/mysql/data/${port}/mysqld.sock -e"set sql_log_bin=0;ALTER TABLE $db_.${table_name} ADD CONSTRAINT _FK_${table_name}_product FOREIGN KEY (product_id) REFERENCES cq_new_cimiss.product (id) ON DELETE NO ACTION ON UPDATE NO ACTION;" >>${log_file} 2>& 1
check_las_comm "$?" "add foreign key error"
red_echo "add foreign key stop"
red_echo "start slave"
mysql -uroot -p$passwd --socket=/datas/mysql/data/${port}/mysqld.sock -e"start slave"
check_las_comm "$?" "start slave failed"执行时间:
2019-04-08-11:17:36 stop slave
mysql: [Warning] Using a password on the command line interface can be insecure.
ddl_start
2019-04-08 11:17:36
ddl_stop
2019-04-08 11:45:13
2019-04-08-11:45:13 onlie ddl stop
2019-04-08-11:45:13 add foreign key
mysql: [Warning] Using a password on the command line interface can be insecure.
2019-04-08-12:33:48 add foreign key stop
2019-04-08-12:33:48 start slave删除重建索引花费时间为 28 分钟,添加外键约束时间为 48 分钟。
再次查看 delete 和 select 语句的执行计划:
explain select count(*) from arrival_record where receive_time < STR_TO_DATE('2019-03-10', '%Y-%m-%d')\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: arrival_record
partitions: NULL
type: range
possible_keys: idx_receive_time
key: idx_receive_time
key_len: 6
ref: NULL
rows: 7540948
filtered: 100.00
Extra: Using where; Using index
explain select count(*) from arrival_record where product_id=26 and receive_time between '2019-03-25 14:00:00' and '2019-03-25 15:00:00' and receive_spend_ms>=0\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: arrival_record
partitions: NULL
type: range
possible_keys: idx_product_id_sequence_station_no,idx_receive_time
key: idx_receive_time
key_len: 6
ref: NULL
rows: 291448
filtered: 16.66
Extra: Using index condition; Using where都使用到了 idx_receive_time 索引,扫描的行数大大降低。
索引优化后
delete 还是花费了 77s 时间:
delete from arrival_record where receive_time < STR_TO_DATE('2019-03-10', '%Y-%m-%d')\G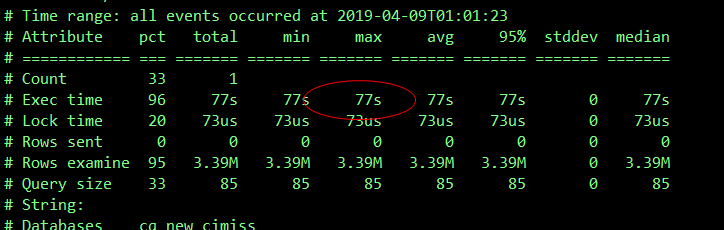
delete 语句通过 receive_time 的索引删除 300 多万的记录花费 77s 时间。
delete 大表优化为小批量删除
应用端已优化成每次删除 10 分钟的数据(每次执行时间 1s 左右),xxx 中没在出现 SLA(主从延迟告警):
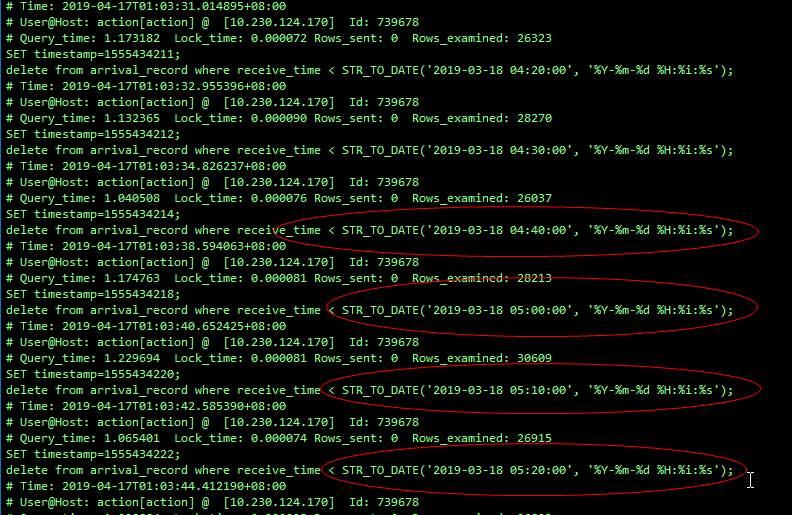
另一个方法是通过主键的顺序每次删除 20000 条记录:
#得到满足时间条件的最大主键ID
#通过按照主键的顺序去 顺序扫描小批量删除数据
#先执行一次以下语句
SELECT MAX(id) INTO @need_delete_max_id FROM `arrival_record` WHERE receive_time<'2019-03-01' ;
DELETE FROM arrival_record WHERE id<@need_delete_max_id LIMIT 20000;
select ROW_COUNT(); #返回20000
#执行小批量delete后会返回row_count(), 删除的行数
#程序判断返回的row_count()是否为0,不为0执行以下循环,为0退出循环,删除操作完成
DELETE FROM arrival_record WHERE id<@need_delete_max_id LIMIT 20000;
select ROW_COUNT();
#程序睡眠0.5s总结
表数据量太大时,除了关注访问该表的响应时间外,还要关注对该表的维护成本(如做 DDL 表更时间太长,delete 历史数据)。
对大表进行 DDL 操作时,要考虑表的实际情况(如对该表的并发表,是否有外键)来选择合适的 DDL 变更方式。
对大数据量表进行 delete,用小批量删除的方式,减少对主实例的压力和主从延迟。