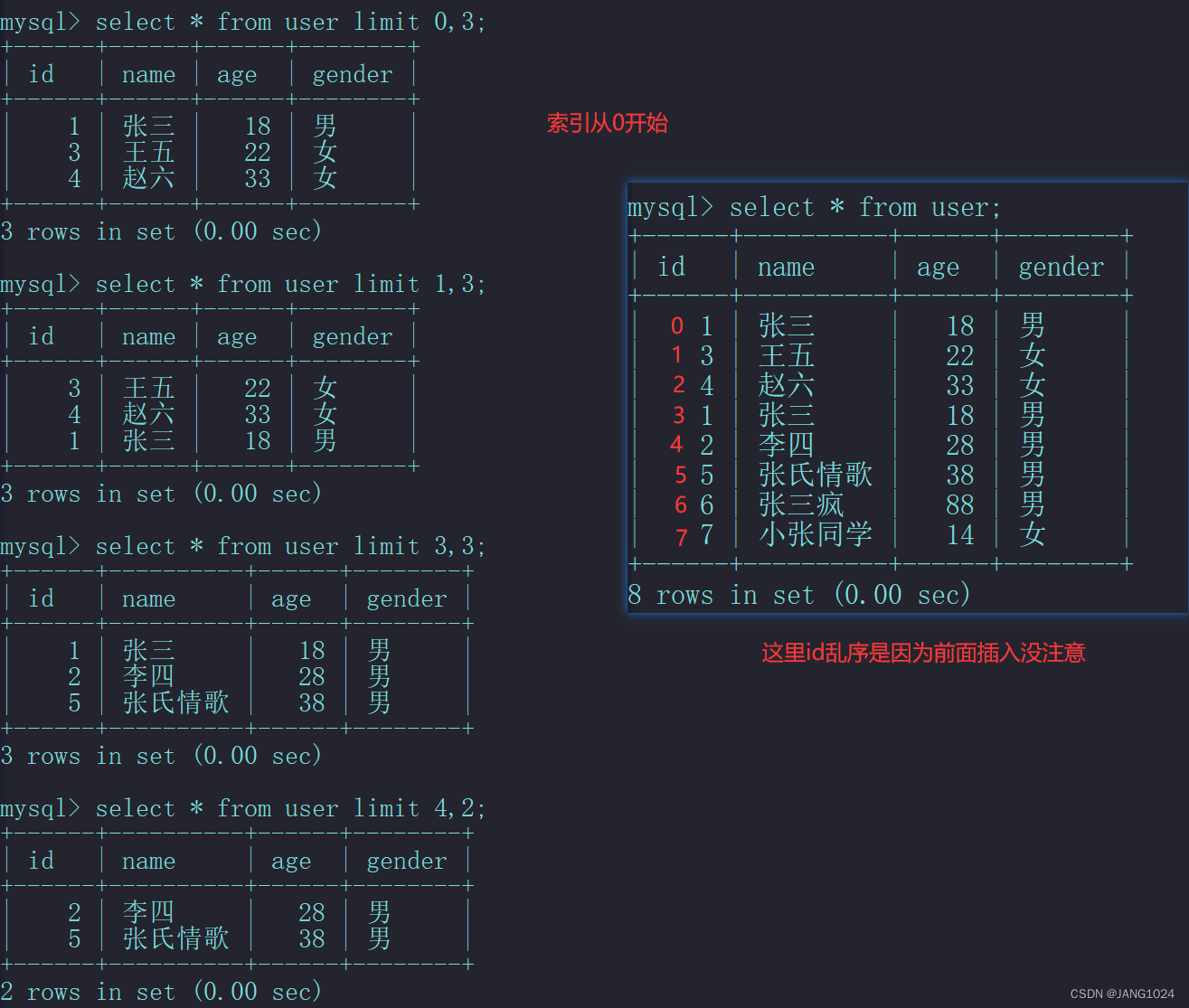
目录
- 前言
- 零碎知识点
- C++核心
- 内存分区
- 引用
- 函数
- 类和对象
- 对象的初始化和清理
- 构造函数和析构函数
- 构造函数的分类和调用
- 拷贝构造函数的调用时机
- 深拷贝与浅拷贝
- 初始化列表
- 类对象作为类的成员
- 静态成员
- C++对象模型和this指针
- 成员变量和成员函数分开存储
- this指针
- 空指针访问成员函数
- const修饰成员函数
- 友元
- 运算符重载
- 继承
- 继承中的对象模型
- 继承中的构造和析构顺序
- 继承同名处理方式
- 继承同名静态成员处理方式
- 多继承
- 菱形继承
- 多态
- 多态的低层原理
- 纯虚函数和抽象类
- 虚析构和纯虚析构
- 文件操作
- 文本文件
- 读文件
- 二进制文件写
- 5.2.1 写文件
- 读文件
前言
此学习笔记为个人学习总结,已经熟悉的知识点并没放上来,该笔记仅供参考学习使用,不具适合初学者和教程使用。
零碎知识点
常量:#define和const,常量不可以被修改
1.宏常量是字符串吗?
2.标识符区分大小写,最好见名知意。
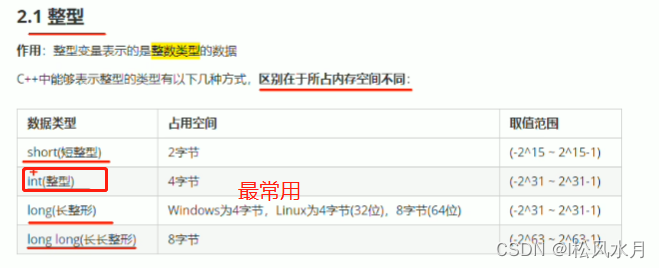
默认情况下小数当做双精度,单精度需要加f,默认输出小数时候,6位有效数(单精度和双精度都是)。
科学计数法:1e-3,1e-6
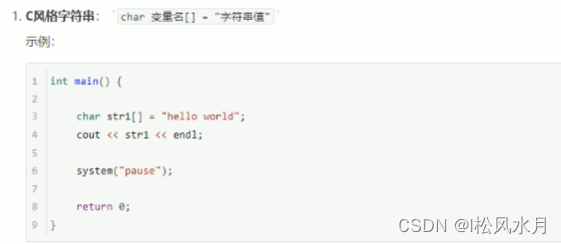
字符串:
C风格:
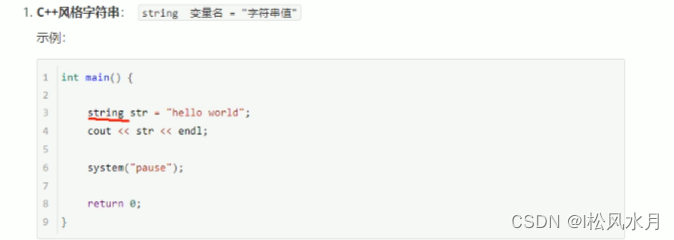
C++风格:
if有三种结构
switch的注意事项要明确
int num = rand()% 100 + 1: // rand()%100 +1生成 0+1 99 +1 随机数
//添加随机数种子 作用利用当前系统时间生成随机数,防止每次随机数都一样
srand((unsigned int)time (NULL)):
switch中只能是整型或者字符型
跳转语句 break语句:
作用: 用于跳出选择结构或者循环结构 break使用的时机:
- 出现在switch条件语句中,作用是终止case并跳出switch
- 出现在循环语句中,作用是跳出当前的循环语句
- 出现在嵌套循环中,跳出最近的内层循环语句
注意break在循环和选择中的混合使用
goto //跳转到某一句
不建议使用
goto FLAG;//直接跳转到下面的FLAG:后面的语句
cout << "3"<< endl;
cout << "4" << endl;
FLAG:
cout << "4" << endl;
system("pause") ;
数组:
维数组定义的三种方式:
1.数据类型 数组名[ 数组长度 ];
2.数据类型 数组名[ 数组长度 ] = {值1,值2 …};
3.数据类型 数组名[ ] = {值1,值2 …};
数组特点:放在一块连续的内存空间中数组中每个元素都是相同数据类型
数组长度不可以用变量来确定
一维数组名称的用途
1.可以统计整个数组在内存中的长度
2.可以获取数组在内存中的首地址
数组名是常量
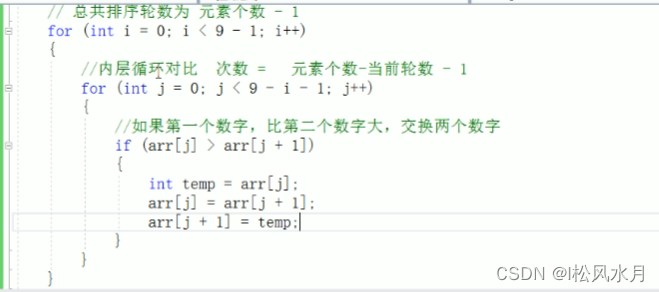
冒泡排序:
1.比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2.对每一对相邻元素做同样的工作,执行完毕后,找到第一个最大值。
3.重复以上的步骤,每次比较次数-1,直到不需要比较
二维数组:列数不可省
1.数据类型 数组名[行数][列数];
2.数据类型 数组名[行数][列数]={{数据1,数据2,数据3},{数据4,数据5,数据6}}
3.数据类型 数组名[行数][列数]={数据1,数据2,数据3,数据4,数据5,数据6}
4.数据类型 数组名[][列数]={数据1,数据2,数据3,数据4,数据5,数据6} 编译器可以自动捕捉到行数
二维数组名:
1、可以查看占用内存空间大小
2、可以查看二维数组的首地址

函数
函数的定义一般主要有5个步骤
1、返回值类型
2、函数名
3、参数列表
4、函数体语句
5、return 表达式
值传递:
形参改变不会影响实参
void不可以加返回值
四种函数形式:
1.无参无返
2.有参无返
3.无参有返
4.有参有返
函数声明:
提前告诉编译器函数存在,编译器必须提前见过,声明可以多次,但是定义只能一次。
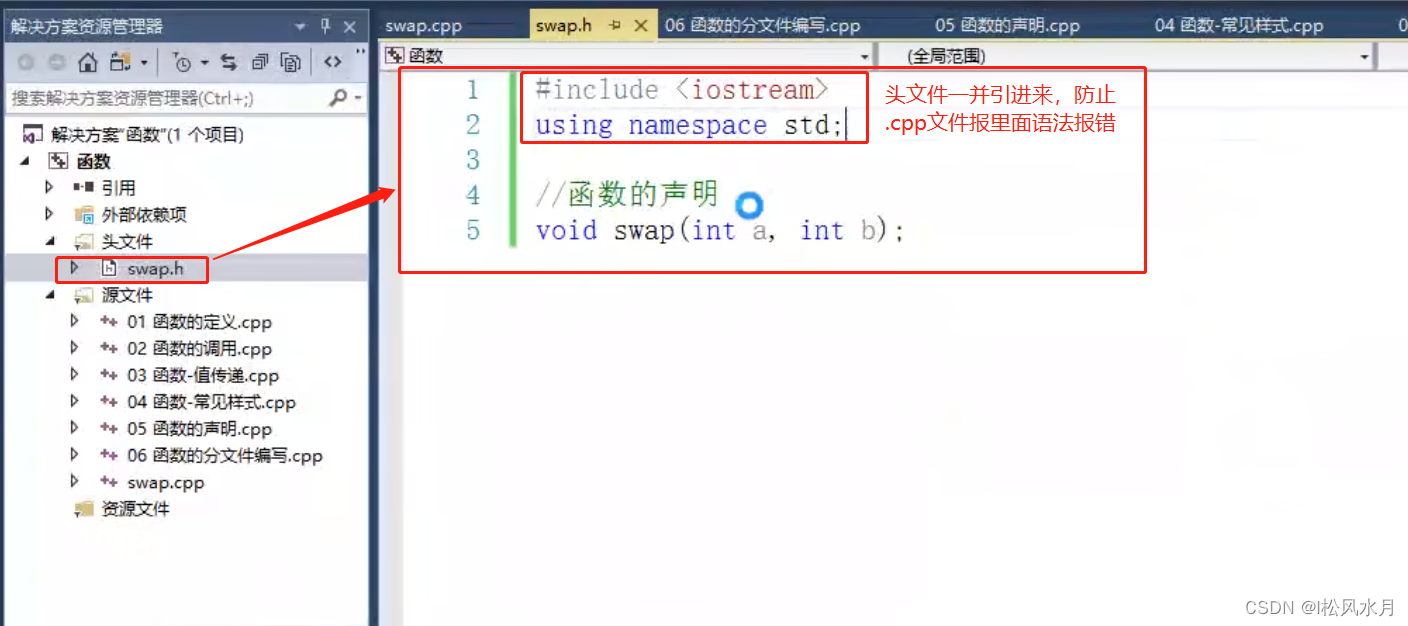
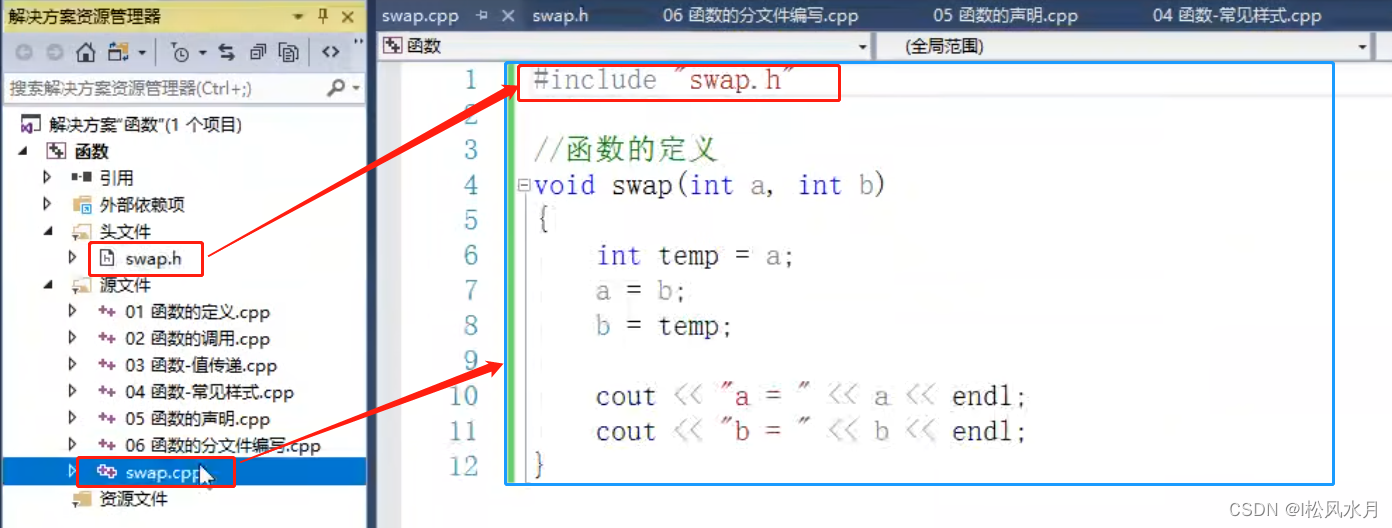
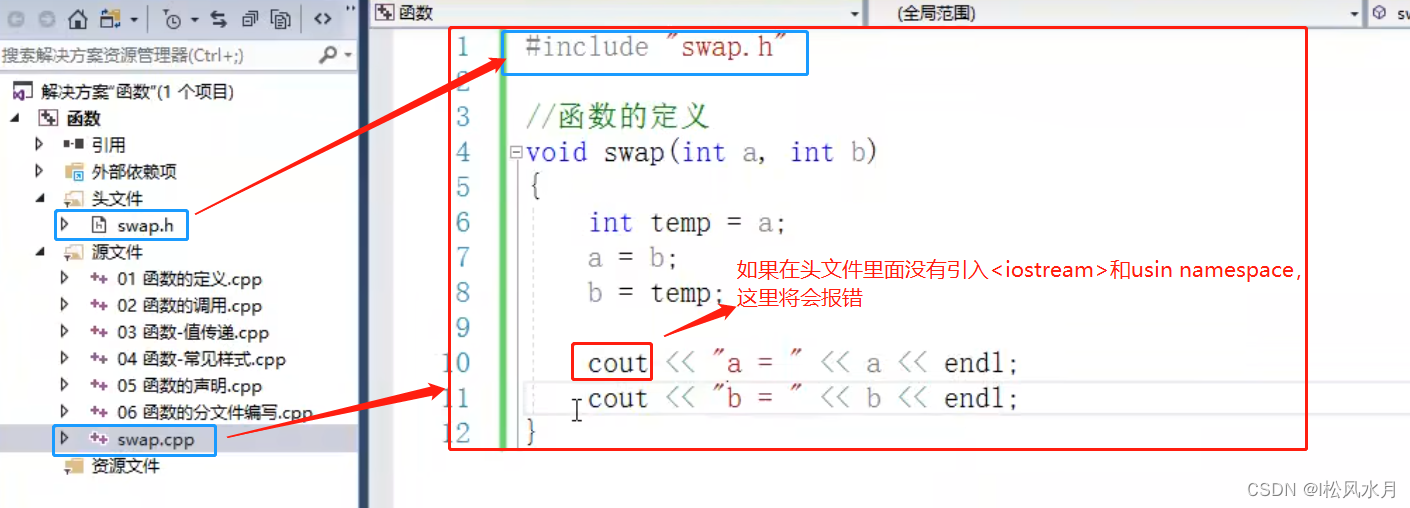
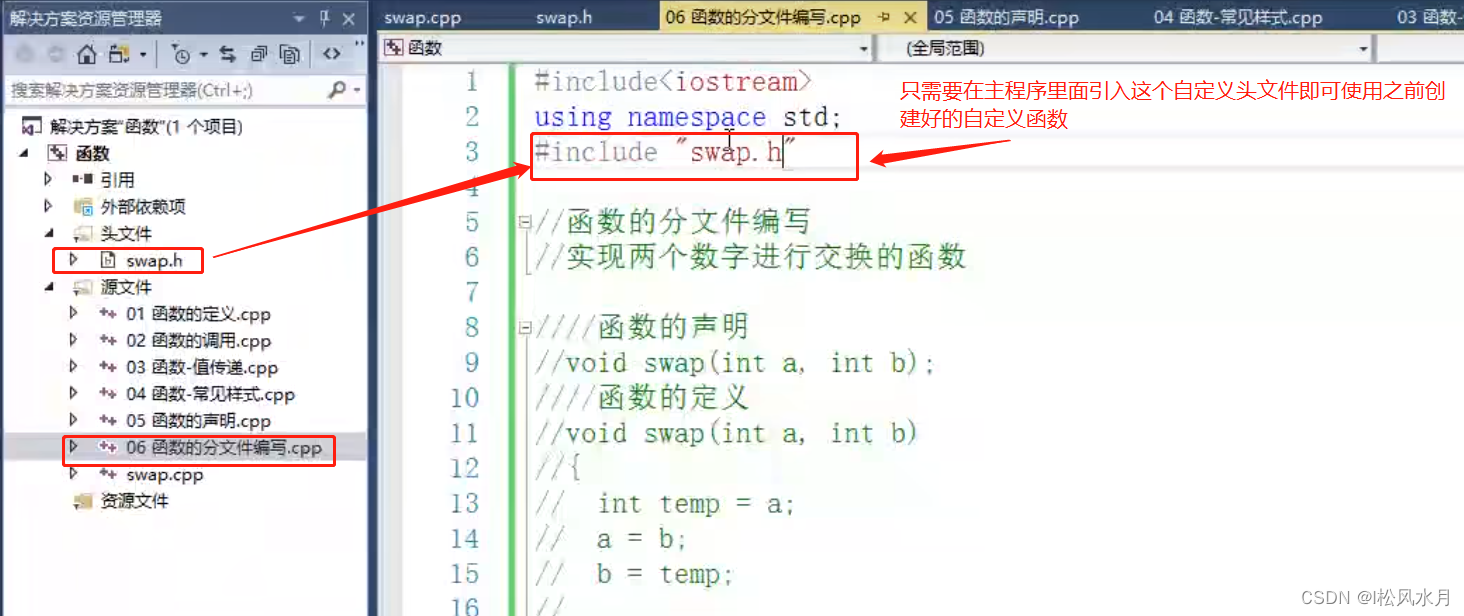
函数的分文件编写:
函数分文件编写一般有4个步骤:
1.创建后缀名为.h的头文件
2.创建后缀名为.cpp的源文件
3.在头文件中写函数的声明
4.在源文件中写函数的定义
只做了上面几步还不够,还需要在源文件里面包含一个自定义的头文件,就是自己创建的那个头文件的问价名称包含进来,这一步的目的是相当于把自定义的头文件和源文件关联起来,源文件中需要的一些声明也在头文件中写不在源文件中写了。使用的时候只需要在使用的地方的开头处再加上自己需要用的文件的头文件即可。
指针:
一般占用四个字节,在每个编译器上占用空间一样,与数据类型无关。
空指针和野指针
空指针: 指针变量指向内存编号为0的空间
用途: 初始化指针变量
注意:空指针指向的内存是不可以访问的,0-255之间的内存编号是系统占用的,因此不可以访问
//空指针
//1、空指针用于给指针变量进行初始化
int *p = NULL;
//2、空指针是不可以进行访问的
*p = 100;
空指针是不可以进行访问的,因为在内存中编号为0-255是系统占用的。
野指针:
指针变量指向非法的内存空间
int main0(
//野指针,随便让他们指向一个内存编号
//在程序中,尽量避免出现野指针
int *p = (int *)0x1100;
//访问野指针报错
cout << *p << end1;
system("pause");
return 0;
关于这部分可以参考下:C++野指针小结
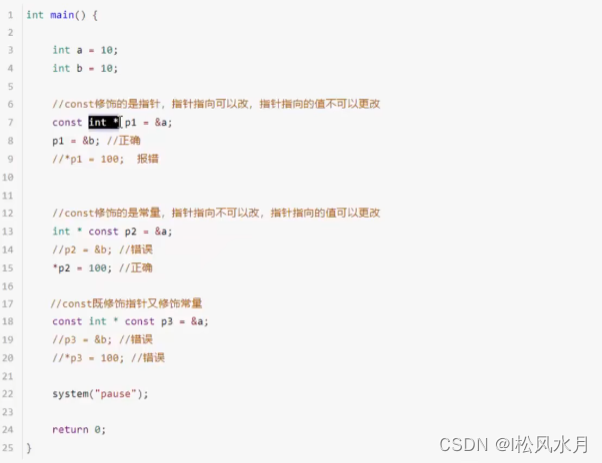
const修饰指针
const可以保证在传指针的时候值不被改变。
const修饰指针有三种情况:
1.const修饰指针 — 常量指针
2.const修饰常量 — 指针常量[
3.const即修饰指针,又修饰常量
看const后面跟的是谁?
常量指针:
const int * p = &a;
指针的指向可以改,但是指针指向的值不可以改
指针常量:
int * const p = &a;
指针的指向不可以改,但是指向的值可以改
const即修饰指针,又修饰常量:
const int * const p = &a;
指针的指向和指针指向的值都不可以改
记忆方法:
把const直接翻译成常量,"*" 翻译成指针就能清晰的区分指针常量和常量指针了,能不能改指向和指向的值,可以看const后面跟的是指针还是指 "*",跟的是谁就不能改谁,不能对谁操作。
技巧: 看const右侧紧跟着的是指针还是常量,是指针就是常量指针,是常量就是指针常量
结构体:
语法:
struct 结构体名 {结构体成员列表 };
通过结构体创建变量的方式有三种:
- struct 结构体名 变星名。
- struct 结构体名 变量名 ={成员1值 , 成员2值…}。
- 定义结构体时顺便创建变量。
注意:C++中在创建结构体变量的时候struct可以省略,在C中不可以省略。
总结:
1: 定义结构体时的关键字是struct,不可省略
2: 创建结构体变是时,关键字struct可以省略
3: 结构体变量利用操作符“.”访问成员
结构体指针:
利用操作符 ->可以通过结构体指针访问结构体属性
上面的代码有两句话忘记解释了:
system("pause")//按任意键退出系统
system("cls")//清屏
输出语句里面可以放三目运算:
switch case:
case后面如果跟的是一个复合语句要用大括号括起来。
数组删除思路:
找到要删除的标号,后面的数据整体往前移动。
C++核心
内存分区
内存分区模型:
这里非常重要,非常重要,非常重要!
C++程序在执行时,将内存大方向划分为4个区域
- 代码区: 存放函数体的二进制代码,由操作系统进行管理的。
- 全局区: 存放全局变量和静态变量以及常量
- 栈区:由编译器自动分配释放,存放函数的参数值,局部变量等。
- 堆区: 由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
内存四区意义:
不同区域存放的数据,赋予不同的生命周期,给我们更大的灵活编程
程序运行前:
在程序编译后,生成了exe可执行程序,未执行该程序前分为两个区域:代码区,全局区
代码区:
存放 CPU 执行的机器指令
代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可
代码区是只读的,使其只读的原因是防止程序意外地修改了它的指令
全局区:
全局变量和静态变量存放在此.
全局区还包含了常量区, 字符串常量和其他常量也存放在此.
该区域的数据在程序结束后由操作系统释放.
常量:
字符串常量
const修饰的,分为全局和局部

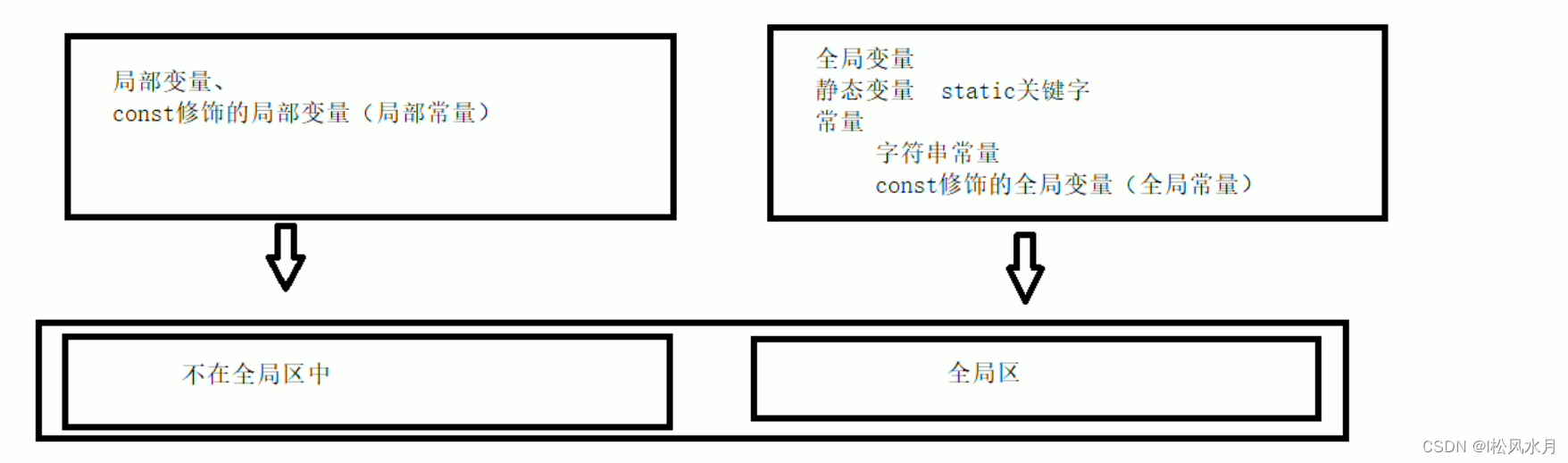
总结:
C++中在程序运行前分为全局区和代码区
代码区特点是共享和只读
全局区中存放全局变量、静态变量、常量
常量区中存放 const修饰的全局常量 和字符串常量,const修饰的局部变量不是放在全局区的。宏常量并不会被分配到堆区或全局区,它们只是在预处理阶段被替换为其定义的常量值。因此,宏常量只存在于代码中,不会在程序运行时被分配内存空间。
程序运行后:
栈区:
由编译器自动分配释放,存放函数的参数值,局部变量等
注意: 不要返回局部变量的地址,栈区开辟的数据由编译器自动释放,如下示例:
int* func()
{
int a = 10;//局部变量 存放在栈区,栈区的数据在函数执行完后自动释放
return &a; //返回局部变量的地址
}
int main() {
//接受func函数的返回值
int *p = func();
cout << *p << endl; //第一次可以打印正确的数字,是因为编译器做了一次保留,只做一次保留;
cout << *p << endl; //第二次这个数据就不再保留了,此时相当于野指针
system(pause");
return 0;
}
堆区:
由程序员分配释放,若程序员不释放,程序结束时由操作系统回收
在C++中主要利用new在堆区开辟内存
int *func()
{
//利用new关键字 可以将数据开辟到堆区
//指针本质上也是局部变量,放在栈上,指针保存的数据是放在堆区
int *p = new int(10); //返回的也是地址
return p;
}
int main() {
//在堆区开辟数据
int *p = func();
cout << *p << endl;
//只要不手动释放,在程序退出前可以一直输出
cout << *p << endl;
cout << *p << endl;
cout << *p << endl;
system(pause");
return 0;
}
new操作符 :
C++中利用new操作符在堆区开辟数据 堆区开辟的数据,由程序员手动开辟,手动释放,释放利用操作符
delete
语法:new 数据类型,返回的是指针
利用new创建的数据,会返回该教据对应的类型的指针
void test010()
{
int * p = func();
cout << *p <<endl;
cout << *p <<endl;
cout << *p <<endl;
//堆区的数据 由程序员管理开辟,程序员管理释放
//如果想释放堆区的数据,利用关键字 delete
delete p; //释放p指向的内容
//报错,读取访问权限冲突,此时再访问就是野指针
cout << *p <<endl;
}
在堆区开辟数组:
void test02(){
//创建10整型数据的数组,在堆区
int * arr = new int[10]: //10代表数组有10个元素
}
//释放堆区数组
//释放数组的时候 要加[]才可以
delete[] arr;
引用
引用
给变量取别名,同一个存储空间,一个变,另一个也变化。
引用基本语法:
数据类型 &别名 = 原名
注意:
- 引用必须初始化 ,上来就要告诉编译器是谁的别名
- 引用在初始化后,不可以改变,只能是一个变量的别名,从一而终
int a = 10;
//1、引用必须初始化//int &b; 错误,必须要初始化
int &b = a;
//2、引用在初始化后,不可以改变
int c = 20;
//赋值操作,而不是更改引用,相当于把c的值赋给了a和b,a和b完全等价,最终a,b,c三个值都是20.
b = c;
引用为函数的参数:
作用: 函数传参时,可以利用引用的技术让形参修饰实参
优点: 可以简化指针修改实参
注意:
当使用引用作为函数参数时,形参和实参共享同一个内存空间。 也就是说,实参的值直接被传递给形参,并且在函数中对形参的修改会直接反映到实参上。
总结:
通过引用参数产生的效果同按地址传递是一样的。引用的语法更清楚简单。
引用作为函数的返回值:
引用是可以作为函数的返回值存在的。
注意:
1.不要返回局部变量引用
2.函数调用作为左值
//返回局部变量引用,会引起意想不到的错误,相当于野指针
int& test01() {
int a = 10; //局部变量
return a;
}
//返回静态变量引用
int& test02() {
static int a = 20; //静态变量,存放在全局区,程序运行完才释放
return a;
}
int main() {
//不能返回局部变量的引用
int& ref = test01();
//第一册正确
cout << "ref = " << ref << endl;
//第二次错误,因为a的内存已释放
cout << "ref = " << ref << endl;
//如果函数做左值,那么必须返回引用
int& ref2 = test02();
//下面两句都能正常输出
cout << "ref2 = " << ref2 << endl;
cout << "ref2 = " << ref2 << endl;
//如果函数的返回值是引用,这个函数的调用可以作为左值
test02() = 1000;
cout << "ref2 = " << ref2 << endl;
cout << "ref2 = " << ref2 << endl;
system("pause");
return 0;
}
再解释下上面的代码:

引用的本质:
引用的本质在c++内部实现是一个指针常量
C++推荐用引用技术,因为语法方便,引用本质是指针常量,但是所有的指针操作编译器都帮我们做了
//发现是引用,转换为 int* const ref = &a;
void func(int& ref){
ref = 100; // ref是引用,转换为*ref = 100
}
int main(){
int a = 10;
//自动转换为 int* const ref = &a; 指针常量是指针指向不可改,也说明为什么引用不可更改
int& ref = a;
ref = 20; //内部发现ref是引用,自动帮我们转换为: *ref = 20;
cout << "a:" << a << endl;
cout << "ref:" << ref << endl;
func(a);
return 0;
}
上面例子中,内部发现ref是引用,自动帮我们转换为: *ref = 20的格式
常量引用:
修饰形参防止误操作,C++规范写法中能用const修饰的尽量使用const修饰。
引用必须引用一块合法的内存空间:
int a = 10:
int & ref = 10;//引用必须引一块合法的内存空间(栈区或者堆区的数据),这里会报错,因为10是放在常量区的
//引用使用的场景,通常用来修饰形参
void showValue(const int& v) {
//v += 10;
cout << v << endl;
}
int main() {
//int& ref = 10; 引用本身需要一个合法的内存空间,因此这行错误
/*加入const就可以了,编译器将代码修改为:int temp = 10; const int& ref = temp;创建了一个临时变量就可以引用了,
其实这里引用的是个中间变量,我们找不到他的原名,原名是编译器起的,我们只能通过别名操作。*/
const int& ref = 10; //加入const之后变为只读,不可修改
//ref = 100; //加入const后不可以修改变量
cout << ref << endl;
//函数中利用常量引用防止误操作修改实参
int a = 10;
showValue(a);
system("pause");
return 0;
}
函数
函数的默认参数:
如果传入了数据就用自己的,如果没传就用默认的。
如果某个位置已经有了默认参数,那么从这个位置开始后面必须都有默认参数,即默认参数必须放后面。
如果函数的声明有了默认参数,那么函数的 实现就不能有默认参数,或者说声明和实现只能有一个有默认参数。
函数的占位参数:
语法: 返回值类型 函数名 (数据类型){}
传参的时候占位符也必须填补参数。占位参数也可以有默认参数,后面会用到。
//函数占位参数 ,占位参数也可以有默认参数
void func(int a, int) {
cout << "this is func" << endl;
}
int main() {
func(10,10); //占位参数必须填补,否者报错
system("pause");
return 0;
}
函数重载:
函数名可以相同。
重载条件:三个条件同时满足,核心就是参数要不一样
- 同一个作用域下,即你要调用的函数来自同一个地方
- 函数名称相同
- 函数参数类型不同 或者个数不同或者 顺序不同
注意:
函数的返回值不可以作为重载的条件。
//函数重载需要函数都在同一个作用域下
void func()
{
cout << "func 的调用!" << endl;
}
void func(int a)
{
cout << "func (int a) 的调用!" << endl;
}
void func(double a)
{
cout << "func (double a)的调用!" << endl;
}
void func(int a ,double b)
{
cout << "func (int a ,double b) 的调用!" << endl;
}
void func(double a ,int b)
{
cout << "func (double a ,int b)的调用!" << endl;
}
//函数返回值不可以作为函数重载条件
//int func(double a, int b)
//{
// cout << "func (double a ,int b)的调用!" << endl;
//}
int main() {
func();
func(10);
func(3.14);
func(10,3.14);
func(3.14 , 10);
system("pause");
return 0;
}
函数重载的注意事项:
- 引用可以作为重载条件
- 函数重载碰到函数默认参数
//函数重载注意事项
//1、引用作为重载条件
void func(int &a)
{
cout << "func (int &a) 调用 " << endl;
}
void func(const int &a)
{
cout << "func (const int &a) 调用 " << endl;
}
//2、函数重载碰到函数默认参数
void func2(int a, int b = 10)
{
cout << "func2(int a, int b = 10) 调用" << endl;
}
void func2(int a)
{
cout << "func2(int a) 调用" << endl;
}
int main() {
int a = 10;
func(a); //调用无const
func(10);//调用有const,并且int& a = 10也不合法,但是const int& a = 10,相当于创建了一个临时的变量
//func2(10); //碰到默认参数产生歧义,不知道调用哪个了,需要避免这种情况。有函数重载的时候尽量不要使用默认参数。这里传两个参数可以。
system("pause");
return 0;
}
函数重载的核心:调佣函数的 时候不能出现歧义。
类和对象
C++中最最重要的内容,面向对象:封装,继承,多态。下面我们从封装开始介绍。
封装:
封装是C++面向对象三大特性之一
封装的意义:
- 将属性和行为作为一个整体,表现生活中的事物
- 将属性和行为加以权限控制
封装意义一:
在设计类的时候,属性和行为写在一起,表现事物
语法: class 类名{ 访问权限: 属性 / 行为 };
看一个简单的类的例子:设计一个圆类,求圆的周长
//圆周率
const double PI = 3.14;
//1、封装的意义
//将属性和行为作为一个整体,用来表现生活中的事物
//封装一个圆类,求圆的周长
//class代表设计一个类,后面跟着的是类名
class Circle
{
public: //访问权限 公共的权限
//属性
int m_r;//半径
//行为
//获取到圆的周长
double calculateZC()
{
//2 * pi * r
//获取圆的周长
return 2 * PI * m_r;
}
};
int main() {
//通过圆类,创建圆的对象
// c1就是一个具体的圆
Circle c1;
c1.m_r = 10; //给圆对象的半径 进行赋值操作
//2 * pi * 10 = = 62.8
cout << "圆的周长为: " << c1.calculateZC() << endl;
system("pause");
return 0;
}
设计一个学生类,属性有姓名和学号,可以给姓名和学号赋值,可以显示学生的姓名和学号。
//学生类
class Student {
public:
void setName(string name) {
m_name = name;
}
void setID(int id) {
m_id = id;
}
void showStudent() {
cout << "name:" << m_name << " ID:" << m_id << endl;
}
public:
string m_name;
int m_id;
};
int main() {
Student stu;
stu.setName("德玛西亚");
stu.setID(250);
stu.showStudent();
system("pause");
return 0;
}
类和对象的访问权限:包含函数和变量
1. public 公共权限 成员 类内可以访问 类外可以访问 一般用来对外接口
2. protected 保护权限 成员 类内可以访问 类外不可以访问 继承的时候儿子可以访问父类中的保护内容
3. private 私有权限 成员 类内可以访问 类外不可以访问 继承的时候儿子不可以访问父类中的私有内容
下面看个例子:
//三种权限
//公共权限 public 类内可以访问 类外可以访问
//保护权限 protected 类内可以访问 类外不可以访问
//私有权限 private 类内可以访问 类外不可以访问
class Person
{
//姓名 公共权限
public:
string m_Name;
//汽车 保护权限
protected:
string m_Car;
//银行卡密码 私有权限
private:
int m_Password;
public:
void func()
{
m_Name = "张三";
m_Car = "拖拉机";
m_Password = 123456;
}
};
int main() {
Person p;
p.m_Name = "李四";
//p.m_Car = "奔驰"; //保护权限类外访问不到
//p.m_Password = 123; //私有权限类外访问不到
system("pause");
return 0;
}
struct和class的区别:
从类的定义方式上可以看出,struct和class的定义方式很像。
在C++中 struct和class唯一的区别就在于 默认的访问权限不同
区别:
- struct 默认权限为公共,成员如果不加权限修饰符,默认为public
- class 默认权限为私有,成员如果不加权限修饰符,默认为private
class C1
{
int m_A; //默认是私有权限
};
struct C2
{
int m_A; //默认是公共权限
};
int main() {
C1 c1;
c1.m_A = 10; //错误,访问权限是私有
C2 c2;
c2.m_A = 10; //正确,访问权限是公共
system("pause");
return 0;
}
通过上面的例子也能看出来,
将成员属性设置为私有:工程中一般都要这么做,类的优点就是私有性。
优点1:将所有成员属性设置为私有,可以自己控制读写权限
优点2:对于写权限,我们可以检测数据的有效性
class Person {
public:
//姓名设置可读可写
void setName(string name) {
m_Name = name;
}
string getName()
{
return m_Name;
}
//设置年龄
void setAge(int age) {
if (age < 0 || age > 150) {
cout << "请输入正确的年龄!" << endl;
return;
}
m_Age = age;
}
//获取年龄
int getAge() {
return m_Age;
}
//爱人设置为只写
void setLover(string lover) {
m_Lover = lover;
}
private:
string m_Name; //可读可写 姓名
int m_Age; //只读 年龄
string m_Lover; //只写 爱人
};
int main() {
Person p;
//姓名设置
p.setName("张三");
cout << "姓名: " << p.getName() << endl;
//年龄设置
p.setAge(50);
cout << "年龄: " << p.getAge() << endl;
//爱人设置
p.setLover("xh");
//cout << "爱人: " << p.m_Lover << endl; //只写属性,不可以读取
system("pause");
return 0;
}
在类中可以让另一个类作为成员,看下面的例子。
#include<iostream>
using namespace std;
//点和圆的关系
// 点类
class Point
{
public:
//设置x坐标
void setX(int x)
{
m_X = x;
}
//获取x坐标
int getX()
{
return m_X;
}
//设置Y坐标
void setY(int y)
{
m_Y = y;
}
//获取Y坐标
int getY()
{
return m_Y;
}
private:
int m_X;
int m_Y;
};
//圆类
class Circle
{
private:
int m_R;
Point m_Center;
public:
//设置半径
void setR(int r)
{
m_R = r;
}
//获取半径
int getR()
{
return m_R;
}
//设置圆心
void setCenter(Point center)
{
m_Center = center;
}
//获取圆心
Point getCenter()
{
return m_Center;
}
};
//判断点和圆的关系
void isInCircle(Circle& c, Point& p)
{
//计算两点之间距离平方
int distance =
(c.getCenter().getX() - p.getX()) * (c.getCenter().getX() - p.getX()) +
(c.getCenter().getY() - p.getY()) * (c.getCenter().getY() - p.getY());
//计算半径平方
int rDistance = c.getR() * c.getR();
//判断关系
if (distance == rDistance)
{
cout << "点在圆上" << endl;
}
else if (distance > rDistance)
{
cout << "点在圆外" << endl;
}
else
{
cout << "点在圆内" << endl;
}
}
int main() {
//创建圆
Circle c;
c.setR(10);
Point center;
center.setX(10);
center.setY(10);
c.setCenter(center);
//创建点
Point p;
p.setX(10);
p.setY(10);
//判断关系
isInCircle(c, p);
system("pause");
return 0;
}
上面的代码是不是看看这很乱,没有一点层次,很不利与工程开发。下面我们按文件类型给他整理一下。
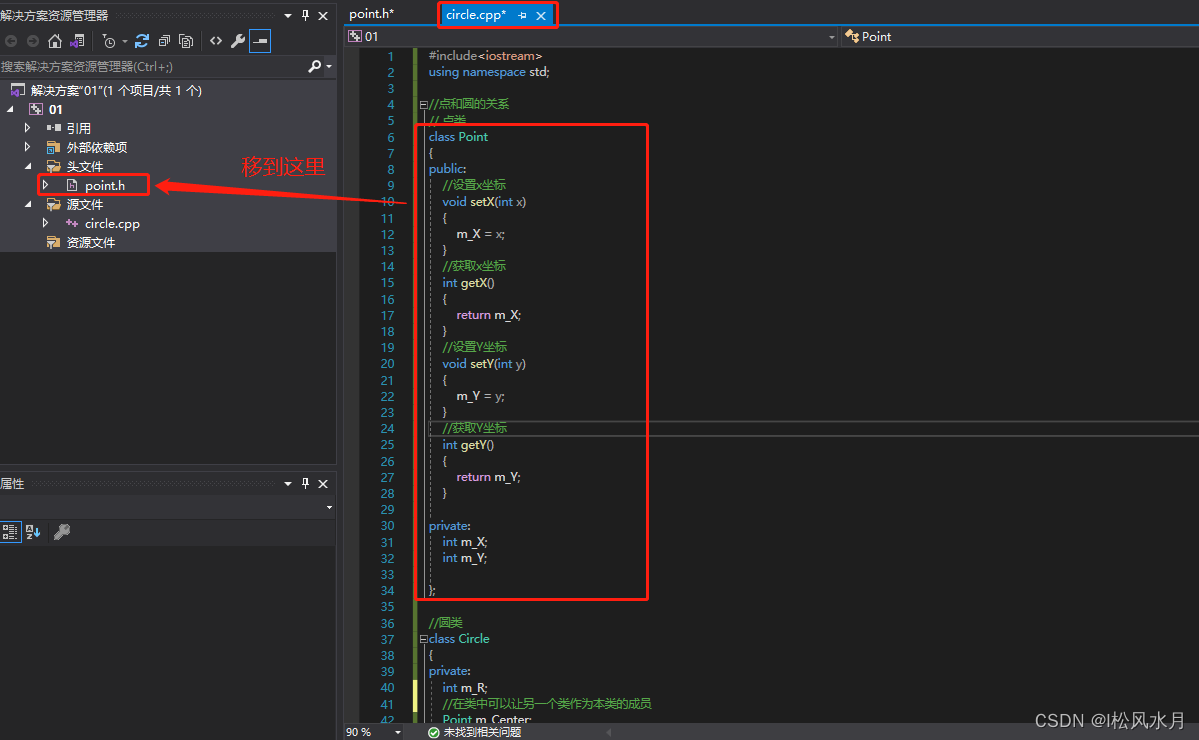
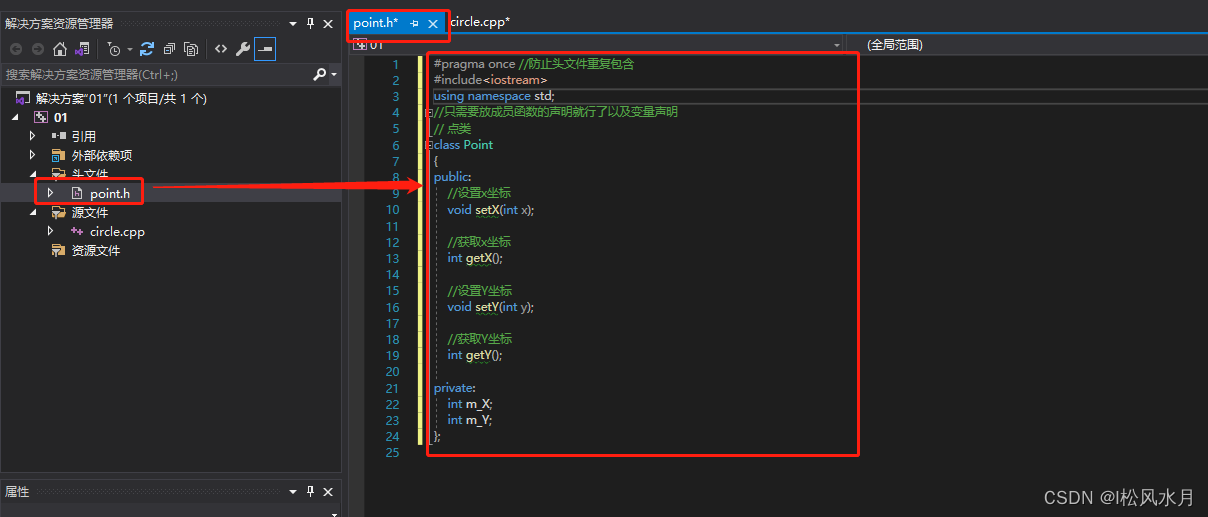
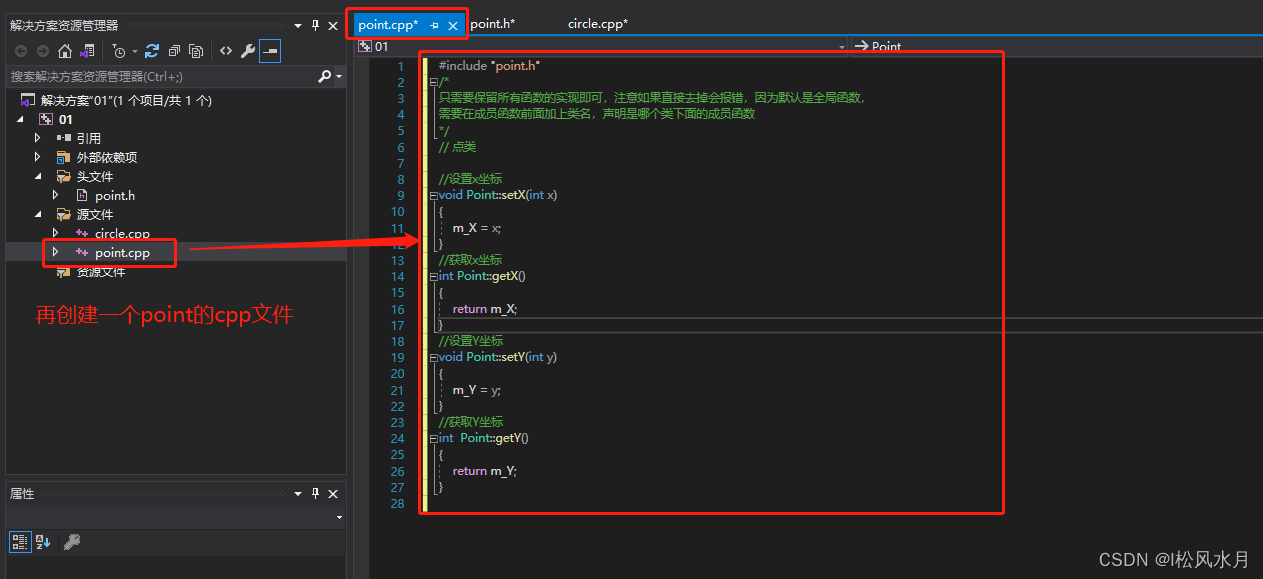
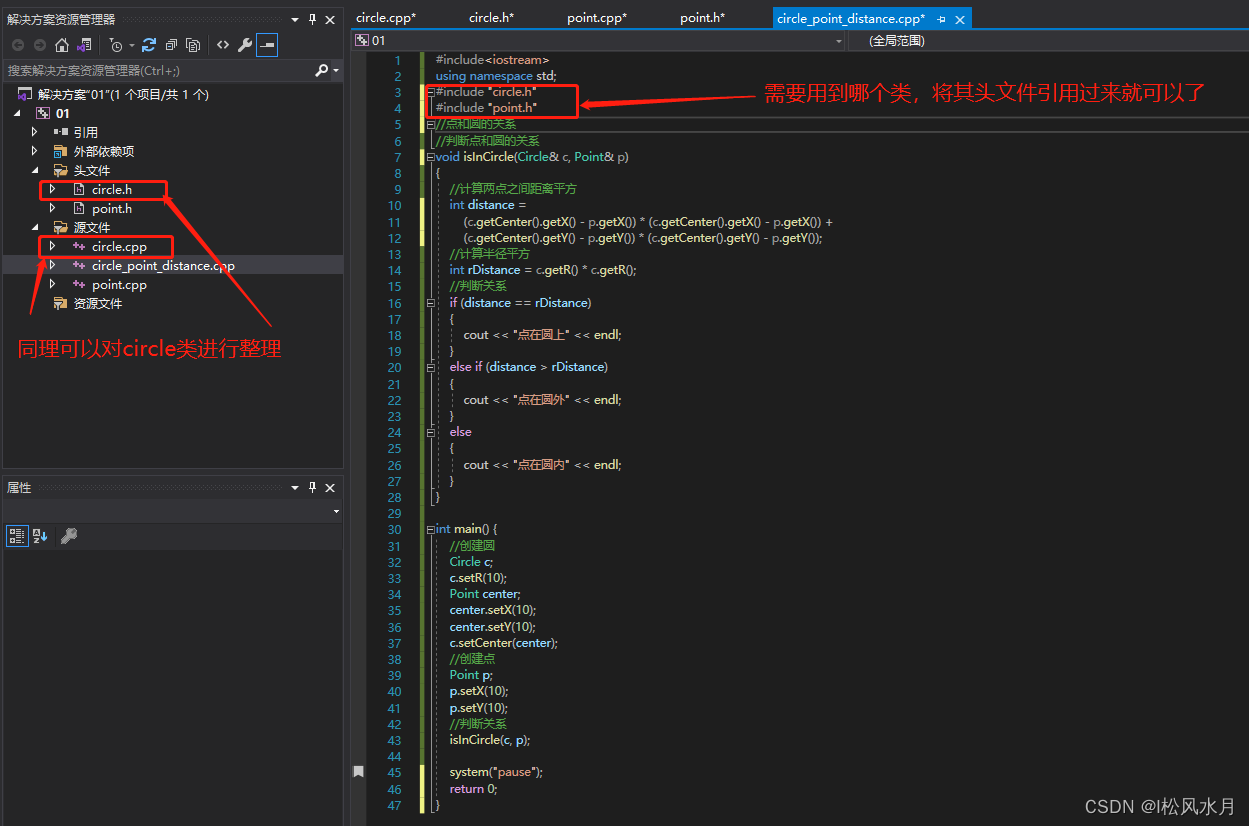
上面整理完之后代码是不是看着简洁多了。
对象的初始化和清理
构造函数和析构函数
对象的初始化和清理也是两个非常重要的安全问题
一个对象或者变量没有初始状态,对其使用后果是未知
同样的使用完一个对象或变量,没有及时清理,也会造成一定的安全问题
c++利用了构造函数和析构函数解决上述问题,这两个函数将会被编译器自动调用,完成对象初始化和清理工作。
对象的初始化和清理工作是编译器强制要我们做的事情,因此如果我们不提供构造和析构,编译器会提供
编译器提供的构造函数和析构函数是空实现。
- 构造函数:主要作用在于创建对象时为对象的成员属性赋值,构造函数由编译器自动调用,无须手动调用。
- 析构函数:主要作用在于对象销毁前系统自动调用,执行一些清理工作。
构造函数语法:类名(){}
- 构造函数,没有返回值也不写
void - 函数名称与类名相同
- 构造函数可以有参数,因此可以发生重载
- 程序在调用对象时候会自动调用构造,无须手动调用,而且只会调用一次
析构函数语法: ~类名(){}
- 析构函数,没有返回值也不写
void - 函数名称与类名相同,在名称前加上符号
~ - 析构函数不可以有参数,因此不可以发生重载
- 程序在对象销毁前会自动调用析构,无须手动调用,而且只会调用一次
核心:一个负责初始化,一个负责销毁。
class Person
{
public:
//构造函数
Person()
{
//如果自己不写,系统默认为空,这里什么都不写
cout << "Person的构造函数调用" << endl;
}
//析构函数
~Person()
{
//如果自己不写,系统默认为空,这里什么都不写
cout << "Person的析构函数调用" << endl;
}
};
//构造和析构都是必须有的实现,如果我们自己不提供,编译器会提供一个空实现的构造和析构
void test01()
{
Person p; //在栈上的数据,test01执行完毕后释放对象。如果把创建对象放到main函数中,要等程序运行完才释放,即对象销毁后才释放
}
int main() {
test01();
system("pause");
return 0;
}
构造函数的分类和调用
两种分类方式:
- 按参数分为: 有参构造和无参(默认)构造
- 按类型分为: 普通构造和拷贝构造
三种调用方式:
- 括号法
- 显示法
- 隐式转换法
//1、构造函数分类
// 按照参数分类分为 有参和无参构造 无参又称为默认构造函数
// 按照类型分类分为 普通构造和拷贝构造
class Person {
public:
//无参(默认)构造函数
Person() {
cout << "无参构造函数!" << endl;
}
//有参构造函数
Person(int a) {
age = a;
cout << "有参构造函数!" << endl;
}
//拷贝构造函数,拷贝构造顾名思义拷贝一份类对象,但是又不能改变本体,拷贝的同时按照引用的方式传值
Person(const Person& p) {
//将传入的人身上的所有属性,拷贝到我身上
age = p.age;
cout << "拷贝构造函数!" << endl;
}
//析构函数
~Person() {
cout << "析构函数!" << endl;
}
public:
int age;
};
//2、构造函数的调用
//调用无参构造函数
void test01() {
Person p; //调用无参构造函数
}
//调用有参的构造函数
void test02() {
//2.1 括号法,常用,推荐使用
Person p1; //默认构造函数
Person p11(10);//有参构造函数
Person p12(p1);//拷贝构造函数,传对象
//注意1:调用无参构造函数不能加括号,如果加了编译器认为这是一个函数声明,不认为是创建对象
//Person p2();
//2.2 显式法
Person p2; //默认构造函数
Person p21 = Person(10); //有参构造函数,可以理解成Person p21(10)
Person p22 = Person(p2); //拷贝构造函数,可以理解成Person p22(p2)
//Person(10)单独写就是匿名对象,当前行结束之后,马上析构,即这个对象调用完,下面的函数还没执行就已经销毁了
//不要用拷贝构造函数初始化匿名对象:Person(p2),会提示Person p2重定义,因为此时编译器会认为 Person p2;上面已经有一个了
//2.3 隐式转换法
Person p4 = 10; // Person p4 = Person(10); 有参构造函数
Person p5 = p4; // Person p5 = Person(p4); 拷贝构造函数
//注意2:不能利用 拷贝构造函数 初始化匿名对象 编译器认为是对象声明
//Person p5(p4);
}
int main() {
test01();
//test02();
system("pause");
return 0;
}
拷贝构造函数的调用时机
三种时机:
- 使用一个已经创建完毕的对象来初始化一个新对象
- 值传递的方式给函数参数传值
- 以值方式返回局部对象
class Person {
public:
//默认(无参)构造
Person() {
cout << "无参构造函数!" << endl;
mAge = 0;
}
//有参构造
Person(int age) {
cout << "有参构造函数!" << endl;
mAge = age;
}
//拷贝构造,将传过来的对象的数据全部拷贝一份
Person(const Person& p) {
cout << "拷贝构造函数!" << endl;
mAge = p.mAge;
}
//析构函数在释放内存之前调用
~Person() {
cout << "析构函数!" << endl;
}
public:
int mAge;
};
//拷贝函数调用时机
//1. 使用一个已经创建完毕的对象来初始化一个新对象
void test01() {
Person man(100); //p对象已经创建完毕
Person newman(man); //调用拷贝构造函数
Person newman2 = man; //拷贝构造
//Person newman3;
//newman3 = man; //不是调用拷贝构造函数,赋值操作
}
//2. 值传递的方式给函数参数传值
//相当于Person p1 = p;
void doWork(Person p1) {}
void test02() {
Person p; //无参构造函数
//这里会调用拷贝构造函数,实参传给形参的时候会调用拷贝构造,但是doWork里面的p不会改变 这里定义的p,因为拷贝的是临时的副本,不一个内存空间
doWork(p);
}
//3. 以值方式返回局部对象,局部对象有个特点,函数执行完立即释放
Person doWork2()
{
Person p1;
cout << (int *)&p1 << endl;
//以值的方式返回,这里返回的并不是p1本身,而是根据p1来创建一个新的对象再返回
return p1;
}
void test03()
{
//函数执行完会调用析构函数
Person p = doWork2();
cout << (int *)&p << endl;
}
int main() {
//test01();
//test02();
test03(); //执行完之后会有两个拷贝构造和两个析构函数打印出来。这里的析构函数要等程序运行完才会执行
system("pause");
return 0;
}
构造函数的调用规则:
默认情况下,只要写了一个类,c++编译器至少给一个类添加3个函数
1.默认构造函数(无参,函数体为空)
2.默认析构函数(无参,函数体为空)
3.默认拷贝构造函数,对属性进行值拷贝,即使自己没写,编译器也会自己写。
如下面的代码,即使没有写拷贝构造函数,那么在执行Person p2(p1);这句话的时候在类中也会自动的创建拷贝构造函数把p1的属性赋值给p2,编译器会做一个属性拷贝
void test01()
{
Person p1(18);
//如果不写拷贝构造,编译器会自动添加拷贝构造,并且做浅拷贝操作
Person p2(p1);
cout << "p2的年龄为: " << p2.age << endl;
}
- 类中如果写了有参构造函数,没写默认 (无参)构造函数,编译器也不会提供无参默认构造函数了,如果调用默认构造函数将会报错,但是如果没写拷贝构造,依然会提供拷贝构造函数,上面已经举了例子。即自己写了有参构造之后,编译器不在提供默认构造。
- 类中如果只写了拷贝构造函数,没写默认构造函数和有参构造函数,那么编译器也不再提供,如果再调用默认构造函数和有参构造函数的时候就会报错。即写了拷贝构造之后,另外另个也不在提供了。
对上面的问题看个例子:
class Person {
public:
//无参(默认)构造函数
Person() {
cout << "无参构造函数!" << endl;
}
//有参构造函数
Person(int a) {
age = a;
cout << "有参构造函数!" << endl;
}
//拷贝构造函数
Person(const Person& p) {
age = p.age;
cout << "拷贝构造函数!" << endl;
}
//析构函数
~Person() {
cout << "析构函数!" << endl;
}
public:
int age;
};
void test01()
{
Person p1(18);
//如果不写拷贝构造,编译器会自动添加拷贝构造,并且做浅拷贝操作
Person p2(p1);
cout << "p2的年龄为: " << p2.age << endl;
}
void test02()
{
//如果用户提供有参构造,编译器不会提供默认构造,会提供拷贝构造
Person p1; //此时如果用户自己没有提供默认构造,会出错
Person p2(10); //用户提供的有参
Person p3(p2); //此时如果用户没有提供拷贝构造,编译器会提供
//如果用户提供拷贝构造,编译器不会提供其他构造函数
Person p4; //此时如果用户自己没有提供默认构造,会出错
Person p5(10); //此时如果用户自己没有提供有参,会出错
Person p6(p5); //用户自己提供拷贝构造
}
int main() {
test01();
system("pause");
return 0;
}
深拷贝与浅拷贝
这个知识点非常重要,面试的时候经常会问的。
- 浅拷贝:编译器中简单的赋值拷贝操作
- 深拷贝:在堆区重新申请空间,进行拷贝操作
class Person {
public:
//无参(默认)构造函数
Person() {
cout << "无参构造函数!" << endl;
}
//有参构造函数
Person(int age ,int height) {
cout << "有参构造函数!" << endl;
m_age = age;
m_height = new int(height);
}
//拷贝构造函数
/*
Person(const Person& p) {
cout << "拷贝构造函数!" << endl;
//如果不利用深拷贝在堆区创建新内存,会导致浅拷贝带来的重复释放堆区问题
m_age = p.m_age;
m_height = new int(*p.m_height);
}
*/
//析构函数
~Person() {
//析构函数通常用来释放堆区中的数据
cout << "析构函数!" << endl;
if (m_height != NULL)
{
delete m_height;
}
}
public:
int m_age;
//创建一个指针为了上面把身高放在堆区。
int* m_height;
};
void test01()
{
Person p1(18, 180);
Person p2(p1);
cout << "p1的年龄: " << p1.m_age << " 身高: " << *p1.m_height << endl;
cout << "p2的年龄: " << p2.m_age << " 身高: " << *p2.m_height << endl;
}
int main() {
test01();
system("pause");
return 0;
}
运行上面的代码会发现出现如下运行结果:
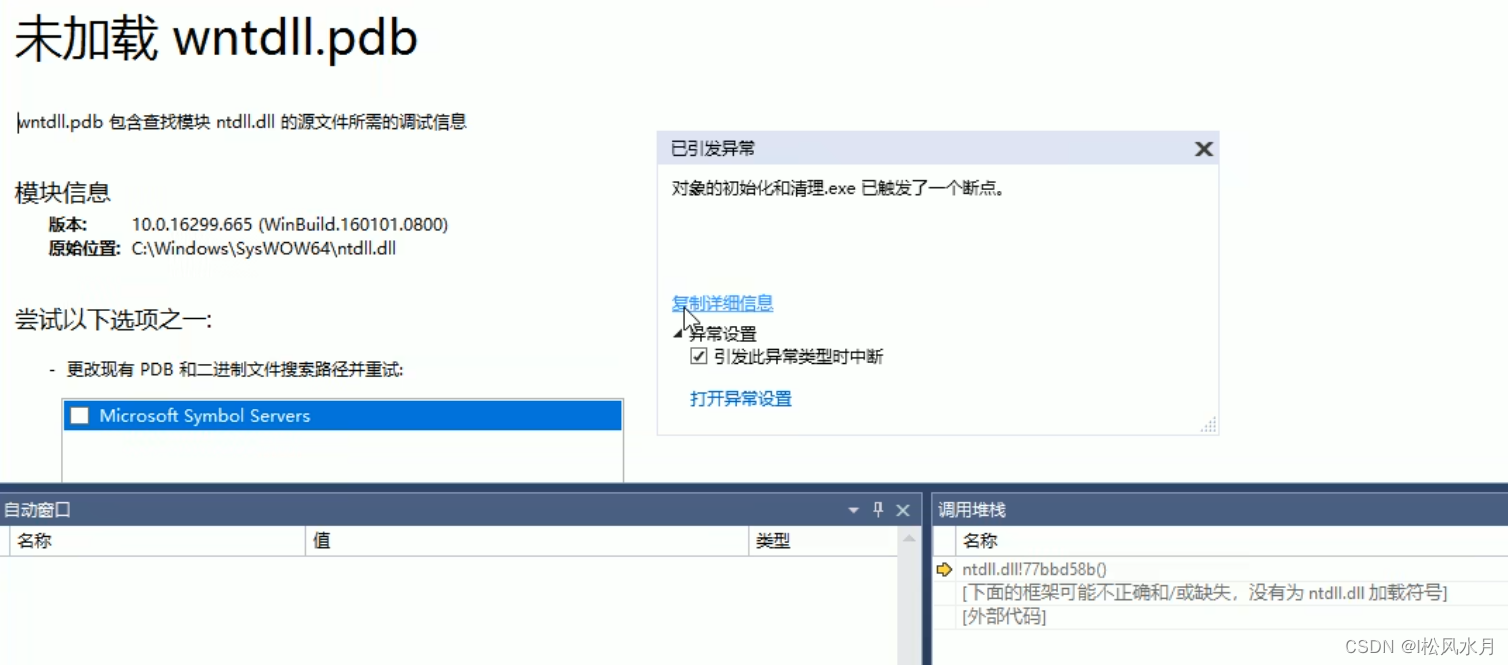
我们来看下为什么会报这个错误:
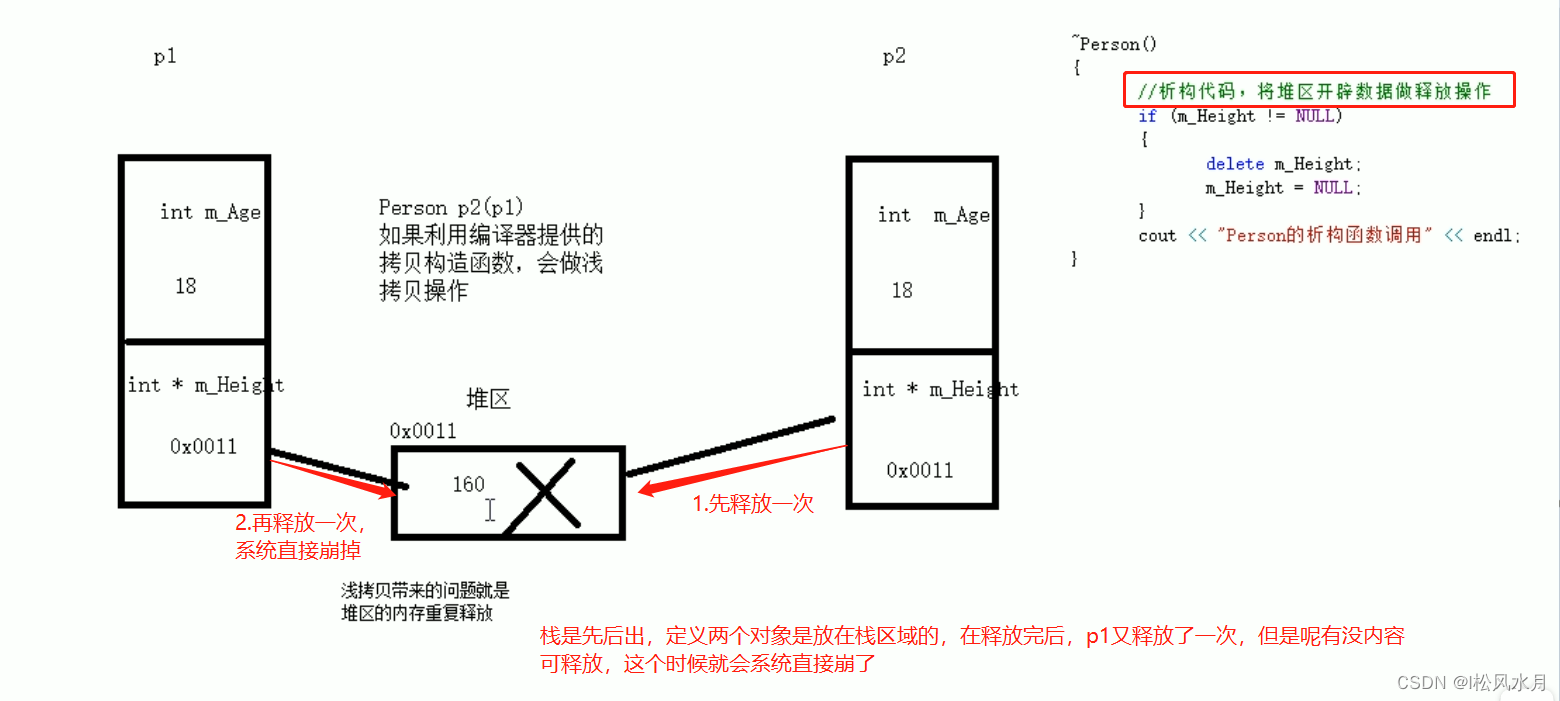
上面代码之所以出现问题就是因为身高这个地方出现了问题,他是在堆区开辟的,在创建p1的时候会把堆区里面存放的身高的地址拷贝到p1下面,在创建对象p2的时候会默认把p1中的数据拷贝到p2中,也就是拷贝了堆区里面的数据到p2。程序运行完之后要执行析构函数释放p1和p2,但是呢p1和p2是放在栈上面的,先释放p2中的数据,再释放p1中的数据,这时候就造成了堆区中的数据重复释放,就产生了冲突。问题产生的原因是因为拷贝构造函数的浅拷贝引起的?怎么解决呢?利用深考别可以解决这一问题。把上面/**/注释取消即可解决,自己实现拷贝构造函数,解决浅拷贝带来的问题,不使用系统默认的构造拷贝。

如上图中的代码,自己重新开辟一个堆区用来存放拷贝的数据。
总结:
如果属性有在堆区开辟的,一定要自己提供拷贝构造函数,防止浅拷贝带来的问题
初始化列表
C++提供了初始化列表语法,用来初始化属性。在工程中我们推荐这种写法。注意冒号的位置。
语法:构造函数():属性1(值1),属性2(值2)... {}
class Person {
public:
传统方式初始化,通常我们都是使用这种有参构造初始化,但是不推荐
//Person(int a, int b, int c) {
// m_A = a;
// m_B = b;
// m_C = c;
//}
//初始化列表方式初始化,工程中推荐用法,这样也可以在构造函数里面写一下其他的语法,这里一定注意冒号的位置
Person(int a, int b, int c) :m_A(a), m_B(b), m_C(c) //相当于m_A = a, m_B = b, m_C = c
{
}
void PrintPerson() {
cout << "mA:" << m_A << endl;
cout << "mB:" << m_B << endl;
cout << "mC:" << m_C << endl;
}
private:
int m_A;
int m_B;
int m_C;
};
int main() {
Person p(1, 2, 3);
p.PrintPerson();
system("pause");
return 0;
}
类对象作为类的成员
C++类中的成员可以是另一个类的对象,我们称该成员为 对象成员。
class Phone
{
public:
Phone(string name)
{
m_PhoneName = name;
cout << "Phone构造" << endl;
}
~Phone()
{
cout << "Phone析构" << endl;
}
string m_PhoneName;
};
class Person
{
public:
//初始化列表可以告诉编译器调用哪一个构造函数
/*Phone是一个类,这里给pName传过来的是个字符串,但是没有报错是因为什么呢?因为这里相当于隐士转换法
Phone m_Pname = pName。这里就展示了类对象也可以用初始化列表的方式赋初值。*/
Person(string name, string pName) :m_Name(name), m_Phone(pName)
{
cout << "Person构造" << endl;
}
~Person()
{
cout << "Person析构" << endl;
}
void playGame()
{
cout << m_Name << " 使用" << m_Phone.m_PhoneName << " 牌手机! " << endl;
}
string m_Name;
Phone m_Phone;
};
void test01()
{
//当类中成员是其他类对象时,我们称该成员为 对象成员
//构造的顺序是 :先调用对象成员的构造,再调用本类构造
//析构顺序与构造相反
Person p("张三" , "苹果X");
p.playGame();
}
int main() {
test01();
system("pause");
return 0;
}
静态成员
静态成员分为:
- 静态成员变量
- 所有对象共享同一份数据
- 在编译阶段分配内存,程序还没运行之前就已经分配内存了,在全局区
- 类内声明,类外初始化
- 静态成员函数
- 所有对象共享同一个函数
- 静态成员函数只能访问静态成员变量
先看下静态成员变量:
class Person
{
public:
//静态成员变量特点:
//1 在编译阶段分配内存
//2 所有对象共享同一份数据
//3 类内声明,类外初始化,必须要做的,否则没法访问
static int m_A; //静态成员变量
};
//类外初始化,注意初始化的时候作用域
int Person::m_A = 10;
void test01()
{
//静态成员变量两种访问方式
//1、通过对象
Person p1;
p1.m_A = 100;
cout << "p1.m_A = " << p1.m_A << endl;
Person p2;
p2.m_A = 200;
cout << "p1.m_A = " << p1.m_A << endl; //共享同一份数据,输出100
cout << "p2.m_A = " << p2.m_A << endl;//输出200
}
int main() {
test01();
system("pause");
return 0;
}
上面的类内声明,类外初始化指的就是需要在类里面定义,类外赋值,但是要注意声明空间在哪个类下面。

看下完整代码,注意注释部分:
class Person
{
public:
static int m_A; //静态成员变量
//静态成员变量特点:
//1 在编译阶段分配内存
//2 类内声明,类外初始化
//3 所有对象共享同一份数据
private:
static int m_B; //静态成员变量也是有访问权限的,外部无法访问
};
int Person::m_A = 10;
int Person::m_B = 10;
void test01()
{
//静态成员变量不属于某个对象,所有对象都共享同一份数据
//静态成员变量两种访问方式
//1、通过对象,其实这里创不创建对象没任何意义,因为静态成员本身不属于任何对象
Person p1;
p1.m_A = 100;
cout << "p1.m_A = " << p1.m_A << endl;
Person p2;
p2.m_A = 200;
cout << "p1.m_A = " << p1.m_A << endl; //共享同一份数据
cout << "p2.m_A = " << p2.m_A << endl;
//2、通过类名,因为静态成员本身不属于任何对象
cout << "m_A = " << Person::m_A << endl;
//cout << "m_B = " << Person::m_B << endl; //私有权限访问不到
}
int main() {
test01();
system("pause");
return 0;
}
再来看下静态成员函数:
- 程序共享一个函数
- 静态成员函数只能访问静态成员变量

为什么静态成员函数不给访问非静态成员属性呢?因为静态成员函数的数据在内存中只有一份,上面的m_B不是非静态成员变量,必须通过对象来访问,当我们调用上面的静态函数的时候,函数体的内部不知道改变的是哪一个对象下面的m_B。比如说创建了两个对象p1,p2,p1要调用上面的静态成员函数,函数里面有个m_B=200,在静态函数体内,m_B并不知道p1要给他改成200,虽然p1在调用这个静态成员函数,但是在这个函数体内并没有体现出来这是p1的成员,同理p2也一样。而m_A可以是因为他不属于任何一个对象。
静态成员函数也是有访问权限的。
class Person
{
public:
//静态成员函数特点:
//1 程序共享一个函数
//2 静态成员函数只能访问静态成员变量
static void func()
{
cout << "func调用" << endl;
m_A = 100;
//m_B = 100; //错误,不可以访问非静态成员变量
}
static int m_A; //静态成员变量
int m_B; //
private:
//静态成员函数也是有访问权限的,类外无法访问
static void func2()
{
cout << "func2调用" << endl;
}
};
int Person::m_A = 10;
void test01()
{
//静态成员变量两种访问方式
//1、通过对象,没特殊意义,因为函数不属于任何对象
Person p1;
p1.func();
//2、通过类名,因为函数不属于任何对象,可以直接通过类名访问
Person::func();
//Person::func2(); //类外访问不到私有权限静态成员函数
}
int main() {
test01();
system("pause");
return 0;
}
C++对象模型和this指针
成员变量和成员函数分开存储
- 在C++中,类内的成员变量和成员函数分开存储
- 只有非静态成员变量才属于类的对象上,像静态成员变量,静态成员函数都不属于某一个对象,非静态成员函数也不属于类对象上面,非静态成员函数也是只有一份,和静态成员变量分开存储,即函数不属于类对象上面。
class Person {
public:
Person() {
mA = 0;
}
//非静态成员变量占对象空间
int mA;
//静态成员变量不占对象空间
static int mB;
//函数也不占对象空间,所有函数共享一个函数实例
void func() {
cout << "mA:" << this->mA << endl;
}
//静态成员函数也不占对象空间
static void sfunc() {
}
};
int main() {
//一个空对象的占员工内存空间是1个字节,即C++编译器会为每个空对象分配一个字节空间,是为了区分空对象的占内存的位置
//每个空对象也应该有一个独一无二的内存地址
cout << sizeof(Person) << endl;
system("pause");
return 0;
}
单独的一个对象里面没有任何成员的时候编译器会为其开辟一个字节的空间。里面有非静态成员变量的时候对象占用成员变量的字节数,即按照成员变量分配内存,这个非静态成员变量属于类的对象上。如果类里面有非静态成员变量,那么非静态成员变量不属于类对象上,类对象也就不会为其开辟内存。如果类里面有非静态成员函数时,他也不属于类对象上,也不会为其开辟内存。如果类里面有静态成员函数时,他也不属于类对象上,也不会为其开辟内存。以上要说的就是成员变量和成员函数是分开存储的。

归根结底,只有非静态成员变量属于类对象上。
this指针
刚才我们说了在类对象里面定义的有些成员不属于类对象的,那么我们在创建不同的对象的时候怎么区分哪个对象在使用呢?
我们知道在C++中成员变量和成员函数是分开存储的,每一个非静态成员函数只会诞生一份函数实例,也就是说多个同类型的对象会共用一块代码
那么问题是:这一块代码是如何区分那个对象调用自己的呢?
c++通过提供特殊的对象指针,this指针,解决上述问题。this指针指向被调用的成员函数所属的对象,谁调用指向谁。
this指针是隐含每一个非静态成员函数内的一种指针
this指针不需要定义,直接使用即可
this指针的用途:
- 当形参和成员变量同名时,可用this指针来区分。解决名称冲突
- 在类的非静态成员函数中返回对象本身,可使用return *this。返回对象本身
我们先看下名称冲突的示例:
class Person
{
public:
/*
这里在编译的时候会不会出现错误,但是最终的程序输出结果不是10,这里想做的是把传过来的值赋值给成员变量age,
但是呢成员变量和age同名,出现了名称冲突。规范写法应该是区分开来,成员属性前面加个m,即m_age,表示成员属性,
即下面的/**/注释部分写法。或者通过this指针去解决。
*/
Person(int age)
{
age = age;
}
int age;
/*
Person(int age)
{
m_age = age;
}
int m_age;*/
};
void test01()
{
Person p1(10);
cout << "p1.age = " << p1.age << endl;
}
int main() {
test01();
system("pause");
return 0;
}

第二种解决方法:通过this解决。
class Person
{
public:
Person(int age)
{
//1、当形参和成员变量同名时,可用this指针来区分
//this指针指向被调用成员函数所属的对象,此时的this就相当于p1.
this->age = age;
}
int age;
};
void test01()
{
Person p1(10);
cout << "p1.age = " << p1.age << endl;
}
int main() {
test01();
system("pause");
return 0;
}
下面再看下返回对象本身用*this:
class Person
{
public:
Person(int age)
{
//1、当形参和成员变量同名时,可用this指针来区分
this->age = age;
}
/*注意,这里返回的是引用,返回的还是对象本身,如果这里返回的不是引用直接Person而不是Person&,即直接返回值,那么下面的代码
p2.PersonAddPerson(p1).PersonAddPerson(p1).PersonAddPerson(p1);输出结果还是20。为什么呢?因为如果这里返回的是值的
话,在调用完p2.PersonAddPerson(p1)第一次之后p2的年龄加了10岁,这里没问题,但是呢这里返回的已经不是p2的本体了,而是按照本
体创建了一个新的数据调用了拷贝构造函数,我们知道在拷贝构造函数调用构造函数时,用值的方式返回会复制一份新的数据出来,相当于这
里的person已经和自身的不一样了。即每次返回的都是一个新的东西,跟原来已经不一样了。*/
Person& PersonAddPerson(Person p)
{
this->age += p.age;
//返回对象本身
//this指向对象本身,而*this指向的是p2这个对象本体
return *this;
}
int age;
};
void test01()
{
Person p1(10);
cout << "p1.age = " << p1.age << endl;
Person p2(10);
p2.PersonAddPerson(p1).PersonAddPerson(p1).PersonAddPerson(p1);
cout << "p2.age = " << p2.age << endl;
}
int main() {
test01();
system("pause");
return 0;
}

函数返回值和返回引用的区别:用值的 方式返回会复制一份新的数据,而引用返回的是本身
空指针访问成员函数
C++中空指针也是可以调用成员函数的,但是也要注意有没有用到this指针
如果用到this指针,需要加以判断保证代码的健壮性
//空指针访问成员函数
class Person {
public:
void ShowClassName() {
cout << "我是Person类!" << endl;
}
void ShowPerson() {
//加上这句话,防止下面空指针代码出错
if (this == NULL) {
return;
}
//其实这里的mAge默认的是this->mAge,而传入的指针是NULL,不指向任何东西,这里会报错。
cout << mAge << endl;
}
public:
int mAge;
};
void test01()
{
//空指针,没有指向任何确切的对象
Person * p = NULL;
p->ShowClassName(); //空指针,可以调用成员函数,单独调用这行代码是不会出错的
//调用这行代码会出错
p->ShowPerson(); //但是如果成员函数中用到了this指针,就不可以了
}
int main() {
test01();
system("pause");
return 0;
}
上面的代码可以看出空指针是可以访问类成员的,但是使用的时候要注意。
const修饰成员函数
常函数:
- 成员函数后加const后我们称为这个函数为常函数
- 常函数内不可以修改成员属性
- 成员属性声明时加关键字mutable后,在常函数中依然可以修改
常对象:
- 声明对象前加const称该对象为常对象
- 常对象只能调用常函数
先来看下常函数,这个地方有点绕,看下面的代码和注释:
class Person {
public:
//this指针的本质是一个指针常量,指针的指向不可修改
//如果想让指针指向的值也不可以修改,需要声明常函数
//在成员函数后面加const,修饰的是this指向,让指针指向的值也不可以修改
void ShowPerson() const
{
//this = NULL; //this指针是不能修改指针的指向 Person* const this;
/*
但是this指针指向的对象的数据是可以修改的,这里的前提是没加上void ShowPerson() const 中的const加了也不能修改,
如果不加const呢,在这里的this指针就相当于Person * const this,指向不可修改,但是指向的值可以修改,
如果加了const呢,就相当于const Person * const this,即指向不能改,指向的内容也不能改,
那么这个const加载哪合适呢,编译器想来想去还是加载函数后面吧,于是就有了void ShowPerson() const 与
const Person * const this完全等价。
*/
this->mA = 100;
//const修饰成员函数,表示指针指向的内存空间的数据不能修改,除了mutable修饰的变量
//变量前面加了mutable,表示可以修改
//this->m_B = 100;
}
public:
int m_A;
mutable int m_B; //可修改 可变的,即使在常函数中也可以修改
};
//const修饰函数
void test01() {
Person p;
//当利用p去调用成员函数ShowPerson()的时候,类中的this就指向这个p。
p.ShowPerson();
cout << person.m_A << endl;
p.showPerson();
}
int main() {
test01();
system("pause");
return 0;
}
上面的代码可以看出this指针的本质是一个指针常量,指针的指向不可修改。
我们再来看下const修饰常对象:
class Person {
public:
Person() {
m_A = 0;
m_B = 0;
}
//this指针的本质是一个指针常量,指针的指向不可修改
//如果想让指针指向的值也不可以修改,需要声明常函数
void ShowPerson() const {
//const Type* const pointer;
//this = NULL; //不能修改指针的指向 Person* const this;
//this->mA = 100; //但是this指针指向的对象的数据是可以修改的
//const修饰成员函数,表示指针指向的内存空间的数据不能修改,除了mutable修饰的变量
this->m_B = 100;
}
void MyFunc() {
//mA = 10000;
}
public:
int m_A;
mutable int m_B; //可修改 可变的
};
//const修饰对象 常对象
void test01() {
const Person person; //常量对象,不允许修改指针指向的值,对象的属性不允许修改
cout << person.m_A << endl;
//person.mA = 100; //常对象不能修改成员变量的值,但是可以访问
person.m_B = 100; //但是常对象可以修改mutable修饰成员变量
//常对象访问成员函数
person.MyFunc(); //常对象能调用const的函数,不能调用普通成员函数,因为普通成员函数可以修改成员变量
}
int main() {
test01();
system("pause");
return 0;
}
常函数内不可修改成员属性,原因是常函数他那个const修饰的是this指针,this指针本身是个指针常量,所以加个cosnt之后连指针指向的值都不可以修改了。如果人此昂修改可以加mutable。
友元
在程序里,有些私有属性 也想让类外特殊的一些函数或者类进行访问,就需要用到友元的技术。友元就是声明一些特殊的函数或者一些特殊的类来作为另一个类的好朋友访问这一类的私有成员。
友元的关键字为 friend
友元的三种实现方式:
- 全局函数做友元
- 类做友元
- 成员函数做友元
全局函数做友元:
class Building
{
//告诉编译器 goodGay全局函数 是 Building类的好朋友,就可以访问类中的私有内容了
friend void goodGay(Building * building);
public:
Building()
{
this->m_SittingRoom = "客厅";
this->m_BedRoom = "卧室";
}
public:
string m_SittingRoom; //客厅
private:
string m_BedRoom; //卧室
};
//全局函数
void goodGay(Building * building)
{
cout << "好基友正在访问: " << building->m_SittingRoom << endl;
//上面类里面如果没有friend void goodGay(Building * building)这个声明就会报错,无法访问私有属性。
cout << "好基友正在访问: " << building->m_BedRoom << endl;
}
void test01()
{
Building b;
goodGay(&b);
}
int main(){
test01();
system("pause");
return 0;
}
上面可以看到只要把全局函数放到类里面前面加上friend,就可以访问类中的私有属性了
类做友元:
友元的目的就是让一个类可以访问另一个类中的私有成员。
class Building; //为了防止下面写Building类的时候报错
class goodGay
{
public:
//函数具体内容写在外面,这样代码看着更简洁
goodGay();
void visit();
private:
Building *building;
};
class Building
{
//告诉编译器 goodGay类是Building类的好朋友,可以访问到Building类中私有内容
friend class goodGay;
public:
Building();
public:
string m_SittingRoom; //客厅
private:
string m_BedRoom;//卧室
};
//在类外声明构造函数,注意加上作用于,哪个类下面的。下面使用了this指针,如果使用初始化列表的方式就不能使用this指针了
Building::Building()
{
this->m_SittingRoom = "客厅";
this->m_BedRoom = "卧室";
}
//类外声明构造函数,注意哪个类下面的
goodGay::goodGay()
{
building = new Building;
}
//类外声明成员函数,注意哪个类下面的
void goodGay::visit()
{
cout << "好基友正在访问" << building->m_SittingRoom << endl;
cout << "好基友正在访问" << building->m_BedRoom << endl;
}
void test01()
{
goodGay gg;
gg.visit();
}
int main(){
test01();
system("pause");
return 0;
}
上面有个隐含的注意事项,关于构造函数初始化的时候能不能使用this可以参考下这两篇博文:
- 关于在cpp类构造函数中使用this指针
- C++构造函数初始化列表中不能使用this指针
成员函数做友元:
class Building;
class goodGay
{
public:
goodGay();
void visit(); //只让visit函数作为Building的好朋友,可以发访问Building中私有内容
void visit2();
private:
Building *building;
};
class Building
{
//告诉编译器 goodGay类中的visit成员函数 是Building好朋友,可以访问私有内容
friend void goodGay::visit();
public:
Building();
public:
string m_SittingRoom; //客厅
private:
string m_BedRoom;//卧室
};
Building::Building()
{
this->m_SittingRoom = "客厅";
this->m_BedRoom = "卧室";
}
goodGay::goodGay()
{
building = new Building;
}
void goodGay::visit()
{
cout << "好基友正在访问" << building->m_SittingRoom << endl;
cout << "好基友正在访问" << building->m_BedRoom << endl;
}
void goodGay::visit2()
{
cout << "好基友正在访问" << building->m_SittingRoom << endl;
//cout << "好基友正在访问" << building->m_BedRoom << endl;
}
void test01()
{
goodGay gg;
gg.visit();
}
int main(){
test01();
system("pause");
return 0;
}
运算符重载
加号运算符重载:
运算符重载概念:对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型。比如,如果我想让;两个人相加,两个人相加是什么意思?看下面的图例:想实现两个对象相加,我们创建了一个Person AddPerson成员/全局函数,但是呢,每个人起的名字不一样,于是编译器给起了一个通用的名称operator+,使用编译器起的函数名可以简化调用方式,直接使用+。需要注意得是如果通过全局函数实现重载的话需要传入两个变量。

看个例子:

上面报错了怎么办呢?需要用重载解决。
class Person {
public:
Person(int a, int b)
{
this->m_A = a;
this->m_B = b;
}
//成员函数实现 + 号运算符重载
Person operator+(const Person& p)
{
//创建一个临时的Person变量
Person temp;
temp.m_A = this->m_A + p.m_A;
temp.m_B = this->m_B + p.m_B;
return temp;
}
public:
int m_A;
int m_B;
};
//全局函数实现 + 号运算符重载
//Person operator+(const Person& p1, const Person& p2) {
// Person temp(0, 0);
// temp.m_A = p1.m_A + p2.m_A;
// temp.m_B = p1.m_B + p2.m_B;
// return temp;
//}
//运算符重载 可以发生函数重载 ,实现一个对象加一个整数
Person operator+(const Person& p2, int val)
{
Person temp;
temp.m_A = p2.m_A + val;
temp.m_B = p2.m_B + val;
return temp;
}
void test() {
Person p1(10, 10);
Person p2(20, 20);
//成员函数方式
//成员函数的本质调用方法:Person p3 = p1.operator+.(p2);
//简化方法
Person p3 = p2 + p1; //相当于 p2.operaor+(p1)
cout << "mA:" << p3.m_A << " mB:" << p3.m_B << endl;
//全局函数重载的本质调用:Person p3 = operator+(p1,p2)
Person p4 = p3 + 10; //相当于 Person p4 = operator+(p3,10)
cout << "mA:" << p4.m_A << " mB:" << p4.m_B << endl;
//运算符重载也可以发生函数重载
Person p4 = p3+10;
}
int main() {
test();
system("pause");
return 0;
}
总结1:对于内置的数据类型的表达式的的运算符是不可能改变的。比如两个整型1+1=2,不能让其变成1-1=0。
总结2:不要滥用运算符重载,比如明明是operator+,执行的是相加操作,但是代码写的功能是相减。
左移运算符:
<<重载可以输出自定义内容,比如想直接输出类名输出里面的成员变量,正常是做不到的,但是可以通过重载做到。

class Person {
friend ostream& operator<<(ostream& out, Person& p);
public:
Person(int a, int b)
{
this->m_A = a;
this->m_B = b;
}
//成员函数 实现不了 p << cout 不是我们想要的效果:
/*如果这里参数写的是Person& p,最后调用的时候变成p.operator<<(p),我们只有一个对象,这里需要两个对象,
肯定不行,方便理解也可以这样人为,这个写法可以简化为p<<p,这根本不是我们要的结果。
那如果传cout呢(cout也是对象,可以传),最后调用的时候变成p.operator<<(cout),
简化版本为p<<cout,也不是我们想要的结果*/
//void operator<<(Person& p){
//}
private:
int m_A;
int m_B;
};
//只能全局函数实现左移重载
/*
ostream(输出流)对象,全局只能有一个,必须用引用方式传过来。注意这里的返回类型ostream。重载的核心operator<<。
这里还要注意到友元,私有类型。这里返回ostream才可以无限使用<<输出,不然只能使用一次。
这里的使用的是引用,cout是别名,可以换成其他的名字。这里关于cout可以是别名仍有疑问,待更近一步研究(第二遍的理解:cout在可以理解成内部定义好的关键词,只有一个,全局成员函数只是通过引用的方式接受他而已,所以想气什么名字起什么名字)。
*/
ostream& operator<<(ostream& cout, Person& p) {
cout << "a:" << p.m_A << " b:" << p.m_B;
return cout;
}
void test() {
Person p1(10, 20);
cout << p1 << "hello world" << endl; //链式编程
}
int main() {
test();
system("pause");
return 0;
}
总结:重载左移运算符配合友元可以实现输出自定义数据类型。重载不能通过成员函数实现。
递增运算符的重载:
作用: 通过重载递增运算符,实现自己的整型数据

class MyInteger {
friend ostream& operator<<(ostream& out, MyInteger myint);
public:
MyInteger() {
m_Num = 0;
}
//前置++,注意这里返回的是引用而不是值,如果返回值的话只能执行一次++,不可以连续多个++,如++(++a)仍然只做一次++。
MyInteger& operator++() {
//先++
m_Num++;
//再返回
return *this;
}
//后置++,这里不能返回引用,如果返回的是引用相当于返回的是局部对象的引用,局部对象这里运行完立即释放,后面在操作就是非法的,这里有个占位参数int,只能写int,可以区分前置和后置,不然重载错误
MyInteger operator++(int) {
//先记录
MyInteger temp = *this; //记录当前本身的值,然后让本身的值加1
//后递增
m_Num++;
return temp;
}
private:
int m_Num;
};
ostream& operator<<(ostream& out, MyInteger myint) {
out << myint.m_Num;
return out;
}
//前置++ 先++ 再返回
void test01() {
MyInteger myInt;
cout << ++myInt << endl;
cout << myInt << endl;
}
//后置++ 先返回 再++
void test02() {
MyInteger myInt;
cout << myInt++ << endl;
cout << myInt << endl;
}
int main() {
test01();
//test02();
system("pause");
return 0;
}
总结: 前置递增返回引用,后置递增返回值
赋值运算符重载:
C++编译器实际上至少给一个类一共就添加4个函数
- 默认构造函数(无参,函数体为空)
- 默认析构函数(无参,函数体为空)
- 默认拷贝构造函数,对属性进行值拷贝
- 赋值运算符
operator=, 对属性进行值拷贝
class Person
{
public:
Person(int age)
{
//将年龄数据开辟到堆区
m_Age = new int(age);
}
//重载赋值运算符
Person& operator=(Person &p)
{
//先判断是否释放干净
if (m_Age != NULL)
{
delete m_Age;
m_Age = NULL;
}
//编译器提供的代码是浅拷贝,析构函数释放的时候会报错。在上面的拷贝构造函数中的浅拷贝已经解释过了。
//m_Age = p.m_Age;
//提供深拷贝 解决浅拷贝的问题
m_Age = new int(*p.m_Age);
//返回自身,自由返回自身才能多次赋值
return *this;
}
~Person()
{
if (m_Age != NULL)
{
delete m_Age;
m_Age = NULL;
}
}
//年龄的指针
int *m_Age;
};
void test01()
{
Person p1(18);
Person p2(20);
Person p3(30);
//p2 = p1; //赋值操作,将p1的所有数据赋值给p2,此时p1和p2中的堆中的数据指向同一个位置,如果析构函数中使用的是浅拷贝将会报错,内存释放两次。
p3 = p2 = p1;
cout << "p1的年龄为:" << *p1.m_Age << endl;
cout << "p2的年龄为:" << *p2.m_Age << endl;
cout << "p3的年龄为:" << *p3.m_Age << endl;
}
int main() {
test01();
//int a = 10;
//int b = 20;
//int c = 30;
//链式操作,我们的重载也应该要满足这个条件
//c = b = a;
//cout << "a = " << a << endl;
//cout << "b = " << b << endl;
//cout << "c = " << c << endl;
system("pause");
return 0;
}
如果类中有属性指向堆区,做赋值操作时也会出现深浅拷贝问题
关系运算符重载:
作用:重载关系运算符,可以让两个自定义类型对象进行对比操作
class Person
{
public:
Person(string name, int age)
{
this->m_Name = name;
this->m_Age = age;
};
bool operator==(Person & p)
{
if (this->m_Name == p.m_Name && this->m_Age == p.m_Age)
{
return true;
}
else
{
return false;
}
}
bool operator!=(Person & p)
{
if (this->m_Name == p.m_Name && this->m_Age == p.m_Age)
{
return false;
}
else
{
return true;
}
}
string m_Name;
int m_Age;
};
void test01()
{
//int a = 0;
//int b = 0;
Person a("孙悟空", 18);
Person b("孙悟空", 18);
if (a == b)
{
cout << "a和b相等" << endl;
}
else
{
cout << "a和b不相等" << endl;
}
if (a != b)
{
cout << "a和b不相等" << endl;
}
else
{
cout << "a和b相等" << endl;
}
}
int main() {
test01();
system("pause");
return 0;
}
函数调用运算符重载:
- 函数调用运算符 () 也可以重载
- 由于重载后使用的方式非常像函数的调用,因此称为仿函数
- 仿函数没有固定写法,非常灵活
class MyPrint
{
public:
void operator()(string text)
{
cout << text << endl;
}
};
void test01()
{
//重载的()操作符 也称为仿函数
MyPrint myFunc;
myFunc("hello world");
}
class MyAdd
{
public:
int operator()(int v1, int v2)
{
return v1 + v2;
}
};
void test02()
{
MyAdd add;
int ret = add(10, 10);
cout << "ret = " << ret << endl;
/*匿名对象调用MyAdd()代替add,执行完立即释放。匿名函数对象MyAdd(),首先他是个匿名对象,
然后他又重载了(),所以我们叫它仿函数,所以又叫匿名函数对象。*/
cout << "MyAdd()(100,100) = " << MyAdd()(100, 100) << endl;
}
int main() {
test01();
test02();
system("pause");
return 0;
}
继承
有些类与类之间存在特殊的关系,例如我们看到很多网站中,都有公共的头部,公共的底部,甚至公共的左侧列表,只有中心内容不同,接下来我们分别利用普通写法和继承的写法来实现计Java,C++和Python教程网页中的内容,看一下继承存在的意义以及好处。
普通实现:
//Java页面
class Java
{
public:
void header()
{
cout << "首页、公开课、登录、注册...(公共头部)" << endl;
}
void footer()
{
cout << "帮助中心、交流合作、站内地图...(公共底部)" << endl;
}
void left()
{
cout << "Java,Python,C++...(公共分类列表)" << endl;
}
void content()
{
cout << "JAVA学科视频" << endl;
}
};
//Python页面
class Python
{
public:
void header()
{
cout << "首页、公开课、登录、注册...(公共头部)" << endl;
}
void footer()
{
cout << "帮助中心、交流合作、站内地图...(公共底部)" << endl;
}
void left()
{
cout << "Java,Python,C++...(公共分类列表)" << endl;
}
void content()
{
cout << "Python学科视频" << endl;
}
};
//C++页面
class CPP
{
public:
void header()
{
cout << "首页、公开课、登录、注册...(公共头部)" << endl;
}
void footer()
{
cout << "帮助中心、交流合作、站内地图...(公共底部)" << endl;
}
void left()
{
cout << "Java,Python,C++...(公共分类列表)" << endl;
}
void content()
{
cout << "C++学科视频" << endl;
}
};
void test01()
{
//Java页面
cout << "Java下载视频页面如下: " << endl;
Java ja;
ja.header();
ja.footer();
ja.left();
ja.content();
cout << "--------------------" << endl;
//Python页面
cout << "Python下载视频页面如下: " << endl;
Python py;
py.header();
py.footer();
py.left();
py.content();
cout << "--------------------" << endl;
//C++页面
cout << "C++下载视频页面如下: " << endl;
CPP cp;
cp.header();
cp.footer();
cp.left();
cp.content();
}
int main() {
test01();
system("pause");
return 0;
}
可以看到,上面很多代码都是重复的
再来看下继承的用法:
//公共页面
class BasePage
{
public:
void header()
{
cout << "首页、公开课、登录、注册...(公共头部)" << endl;
}
void footer()
{
cout << "帮助中心、交流合作、站内地图...(公共底部)" << endl;
}
void left()
{
cout << "Java,Python,C++...(公共分类列表)" << endl;
}
};
//Java页面
class Java : public BasePage
{
public:
void content()
{
cout << "JAVA学科视频" << endl;
}
};
//Python页面
class Python : public BasePage
{
public:
void content()
{
cout << "Python学科视频" << endl;
}
};
//C++页面
class CPP : public BasePage
{
public:
void content()
{
cout << "C++学科视频" << endl;
}
};
void test01()
{
//Java页面
cout << "Java下载视频页面如下: " << endl;
Java ja;
ja.header();
ja.footer();
ja.left();
ja.content();
cout << "--------------------" << endl;
//Python页面
cout << "Python下载视频页面如下: " << endl;
Python py;
py.header();
py.footer();
py.left();
py.content();
cout << "--------------------" << endl;
//C++页面
cout << "C++下载视频页面如下: " << endl;
CPP cp;
cp.header();
cp.footer();
cp.left();
cp.content();
}
int main() {
test01();
system("pause");
return 0;
}
可以看到,继承的方法能够极大的减少代码的重复。
总结:
继承的好处:可以减少重复的代码
class A : public B;
A 类称为子类 或 派生类
B 类称为父类 或 基类
派生类中的成员,包含两大部分:
一类是从基类继承过来的,一类是自己增加的成员。
从基类继承过过来的表现其共性,而新增的成员体现了其个性。
继承方式:
继承的语法:class 子类 : 继承方式 父类
继承方式一共有三种:
- 公共继承
- 保护继承
- 私有继承
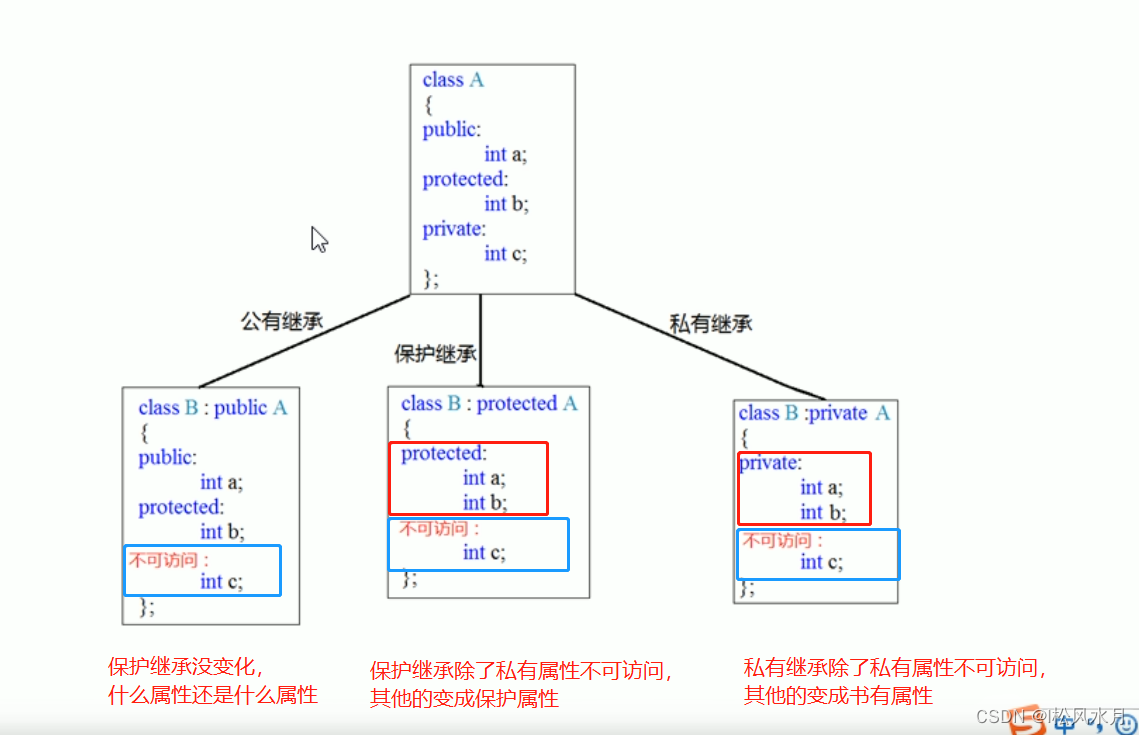
上图中最左侧应该是公共继承
我们来看下下面三个例子:
class Base1
{
public:
int m_A;
protected:
int m_B;
private:
int m_C;
};
//公共继承
class Son1 :public Base1
{
public:
void func()
{
m_A; //可访问父类中的 public权限成员
m_B; //可访问父类中的 protected权限,到子类中仍然是保护权限,只有类内能访问,类外不能访问
//m_C; //不可访问,父类中私有权限成员不可访问
}
};
//创建一个测试函数
void myClass()
{
Son1 s1;
s1.m_A; //其他类只能访问到公共权限
//s1.m_B; 报错,m_B到了子类Son1中变成了保护权限,类外不能访问保护权限
}
//保护继承
class Base2
{
public:
int m_A;
protected:
int m_B;
private:
int m_C;
};
class Son2:protected Base2
{
public:
void func()
{
m_A; //父类中的公共成员,到子类中变成了保护权限
m_B; //父类中的保护成员,到子类中变成了保护权限
//父类中的私有成员,不可访问
//m_C; //不可访问
}
};
void myClass2()
{
Son2 s;
//报错,m_A到了子类Son2中变成了保护权限,类外不能访问保护权限
//s.m_A; //不可访问
}
//私有继承
class Base3
{
public:
int m_A;
protected:
int m_B;
private:
int m_C;
};
class Son3:private Base3
{
public:
void func()
{
m_A; //父类中的公共成员到子类中变成了私有成员
m_B; //父类中的保护成员到子类中变成了私有成员
//m_C; //不可访问
}
};
class GrandSon3 :public Son3
{
public:
void func()
{
//Son3是私有继承,所以即使孙子以公共的方式继承父类Son3的属性在GrandSon3中都无法访问到,会直接报错
//m_A;
//m_B;
//m_C;
}
};
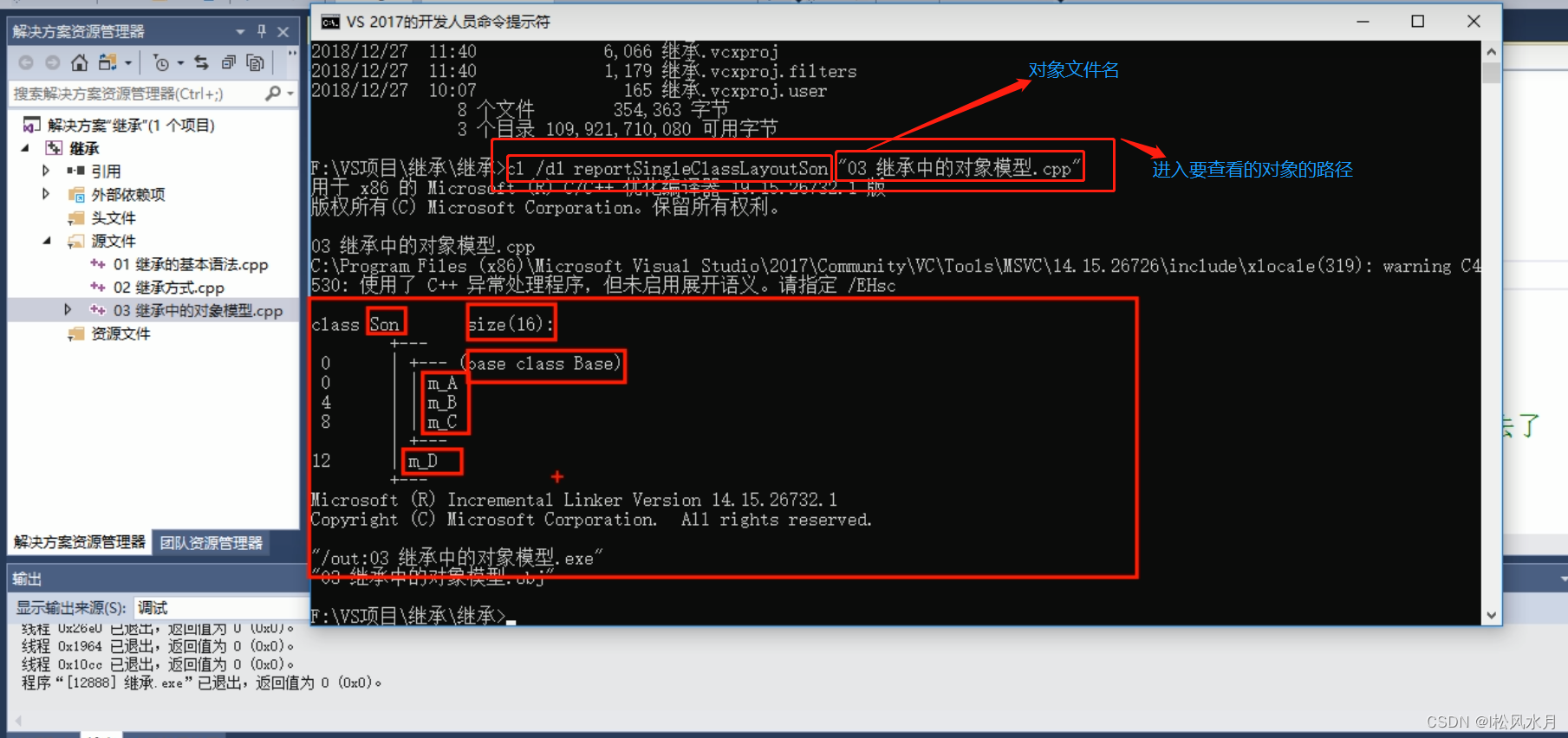
继承中的对象模型
在父类中所有的非静态成员属性都会被继承下去,但是父类中的私有成员属性是被编译器给隐藏了,因此无法访问,但是确实是被继承下去了。
class Base
{
public:
int m_A;
protected:
int m_B;
private:
int m_C; //私有成员只是被隐藏了,但是还是会继承下去
};
//公共继承
class Son :public Base
{
public:
int m_D;
};
void test01()
{
//输出结果是12,父类中的所有非静态成员都别继承下去。父类中的私有属性是被编译器给隐藏了,因此访问不到,但是确实是被继承下去了。
cout << "sizeof Son = " << sizeof(Son) << endl;
}
int main() {
test01();
system("pause");
return 0;
}
用开发人员命令提示工具也可以看到继承了哪些属性。具体步骤如下:

继承中的构造和析构顺序
class Base
{
public:
Base()
{
cout << "Base构造函数!" << endl;
}
~Base()
{
cout << "Base析构函数!" << endl;
}
};
class Son : public Base
{
public:
Son()
{
cout << "Son构造函数!" << endl;
}
~Son()
{
cout << "Son析构函数!" << endl;
}
};
void test01()
{
//继承中 先调用父类构造函数,再调用子类构造函数,析构顺序与构造相反
Son s;
}
int main() {
test01();
system("pause");
return 0;
}

子类中如果有继承,在创建子类对象的时候,由于做了继承的操作,所以子类肯定会父类的属性和成员拿到手,也会创建父类对象,因此会在创建父类对象的同时调用父类对象。
总结:继承中 先调用父类构造函数,再调用子类构造函数,析构顺序与构造相反
继承同名处理方式
class Base {
public:
Base()
{
m_A = 100;
}
void func()
{
cout << "Base - func()调用" << endl;
}
void func(int a)
{
cout << "Base - func(int a)调用" << endl;
}
public:
int m_A;
};
class Son : public Base {
public:
Son()
{
m_A = 200;
}
//当子类与父类拥有同名的成员函数,子类会隐藏父类中所有版本的同名成员函数
//如果想访问父类中被隐藏的同名成员函数,需要加父类的作用域
void func()
{
cout << "Son - func()调用" << endl;
}
public:
int m_A;
};
void test01()
{
Son s;
//直接访问就是自己类下面的
cout << "Son下的m_A = " << s.m_A << endl;
//如果想要访问父类中的同名成员,需要加上作用域
cout << "Base下的m_A = " << s.Base::m_A << endl;
s.func();
s.Base::func();
/* 如果子类中出现和父类中的同名成员函数,子类中的同名成员函数会隐藏掉父类中所有的同名成员函数即所有的重载函数都被隐藏了。
只要同名不管是否重载都被隐藏
如果想访问到父类中的隐藏的同名成员函数,需要加作用域。
*/
s.Base::func(10);
}
int main() {
test01();
system("pause");
return EXIT_SUCCESS;
}
- 子类对象可以直接访问到子类中同名成员
- 子类对象加作用域可以访问到父类同名成员
- 当子类与父类拥有同名的成员函数,子类会隐藏父类中同名成员函数,加作用域可以访问到父类中同名函数
继承同名静态成员处理方式
先回顾下前面讲的静态成员变量的特点:所有对象共享同一份数据,编译阶段就分配内存,类内声明类外初始化
静态成员函数的特点:只能访问静态成员变量,不能访问非静态成员变量,也是所有对象共享一份数据
问题:继承中同名的静态成员在子类对象上如何进行访问?
静态成员和非静态成员出现同名,处理方式一致
- 访问子类同名成员 直接访问即可
- 访问父类同名成员 需要加作用域
class Base {
public:
static void func()
{
cout << "Base - static void func()" << endl;
}
static void func(int a)
{
cout << "Base - static void func(int a)" << endl;
}
static int m_A;
};
int Base::m_A = 100;
class Son : public Base {
public:
static void func()
{
cout << "Son - static void func()" << endl;
}
static int m_A;
};
int Son::m_A = 200;
//同名成员属性
void test01()
{
//通过对象访问
cout << "通过对象访问: " << endl;
Son s;
cout << "Son 下 m_A = " << s.m_A << endl;
cout << "Base 下 m_A = " << s.Base::m_A << endl;
//通过类名访问
cout << "通过类名访问: " << endl;
cout << "Son 下 m_A = " << Son::m_A << endl;
//通过子类对象访问父类的静态成员数据,第一个::表示通过类名的方式访问,第二个::表示表示访问父类作用域下的
cout << "Base 下 m_A = " << Son::Base::m_A << endl;
}
//同名成员函数
void test02()
{
//通过对象访问
cout << "通过对象访问: " << endl;
Son s;
s.func();
s.Base::func();
cout << "通过类名访问: " << endl;
Son::func();
//通过类名访问父类中的func()。
Son::Base::func();
//出现同名,子类会隐藏掉父类中所有同名成员函数,需要加作作用域访问
Son::Base::func(100);
}
int main() {
//test01();
test02();
system("pause");
return 0;
}
总结:同名静态成员处理方式和非静态处理方式一样,只不过有两种访问的方式(通过对象 和 通过类名),区分下雨非静态的只能通过对象访问
多继承
C++允许一个类继承多个类
语法: class 子类 :继承方式 父类1 , 继承方式 父类2...
多继承可能会引发父类中有同名成员出现,需要加作用域区分
C++实际开发中不建议用多继承
class Base1 {
public:
Base1()
{
m_A = 100;
}
public:
int m_A;
};
class Base2 {
public:
Base2()
{
m_A = 200; //开始是m_B 不会出问题,但是改为mA就会出现不明确
}
public:
int m_A;
};
//语法:class 子类:继承方式 父类1 ,继承方式 父类2
class Son : public Base2, public Base1
{
public:
Son()
{
m_C = 300;
m_D = 400;
}
public:
int m_C;
int m_D;
};
//多继承容易产生成员同名的情况
//通过使用类名作用域可以区分调用哪一个基类的成员
void test01()
{
Son s;
//输出16,两个父类里面都继承了
cout << "sizeof Son = " << sizeof(s) << endl;
//当父类中出现同名的时候,使用的时候需要加作用域,所以一般不建议使用多继承
cout << s.Base1::m_A << endl;
cout << s.Base2::m_A << endl;
}
int main() {
test01();
system("pause");
return 0;
}
菱形继承
菱形继承概念:
两个派生类继承同一个基类 ,又有某个类同时继承者两个派生类 ,这种继承被称为菱形继承,或者钻石继承
看个示例:
- 羊继承了动物的数据,驼同样继承了动物的数据,当草泥马使用数据时,因为羊和驼继承的数据相同,这时候就会产生二义性。
- 草泥马继承自动物的数据继承了两份,其实我们应该清楚,这份数据我们只需要一份就可以。
class Animal
{
public:
int m_Age;
};
//继承前加virtual关键字后,变为虚继承
//此时公共的父类Animal称为虚基类
class Sheep : virtual public Animal {};
class Tuo : virtual public Animal {};
class SheepTuo : public Sheep, public Tuo {};
void test01()
{
SheepTuo st;
st.Sheep::m_Age = 100;//这里有个注意的地方,::的优先级高于.的优先级,这里注意一下,不然有时候这样写代码看着很迷惑
st.Tuo::m_Age = 200;
//当菱形继承时,两个父类具有相同的数据,需要加作用域区分
cout << "st.Sheep::m_Age = " << st.Sheep::m_Age << endl;
cout << "st.Tuo::m_Age = " << st.Tuo::m_Age << endl;
//这份数据我们知道 只要有一份就可以,菱形继承导致数据有两份,资源浪费。那么这里输出的应该是18还是28呢?怎么解决这个问题?利用虚继承可以解决菱形继承的问题,继承之前 加上关键字 virtual 变为虚继承。这个时候的输出为200,包括上面的输出也变为了200。当我们发生虚继承之后只保留最后一次的,也就是只能有一份数据。
cout << "st.m_Age = " << st.m_Age << endl;
}
int main() {
test01();
system("pause");
return 0;
}
用开发人员命令提示工具看一下。
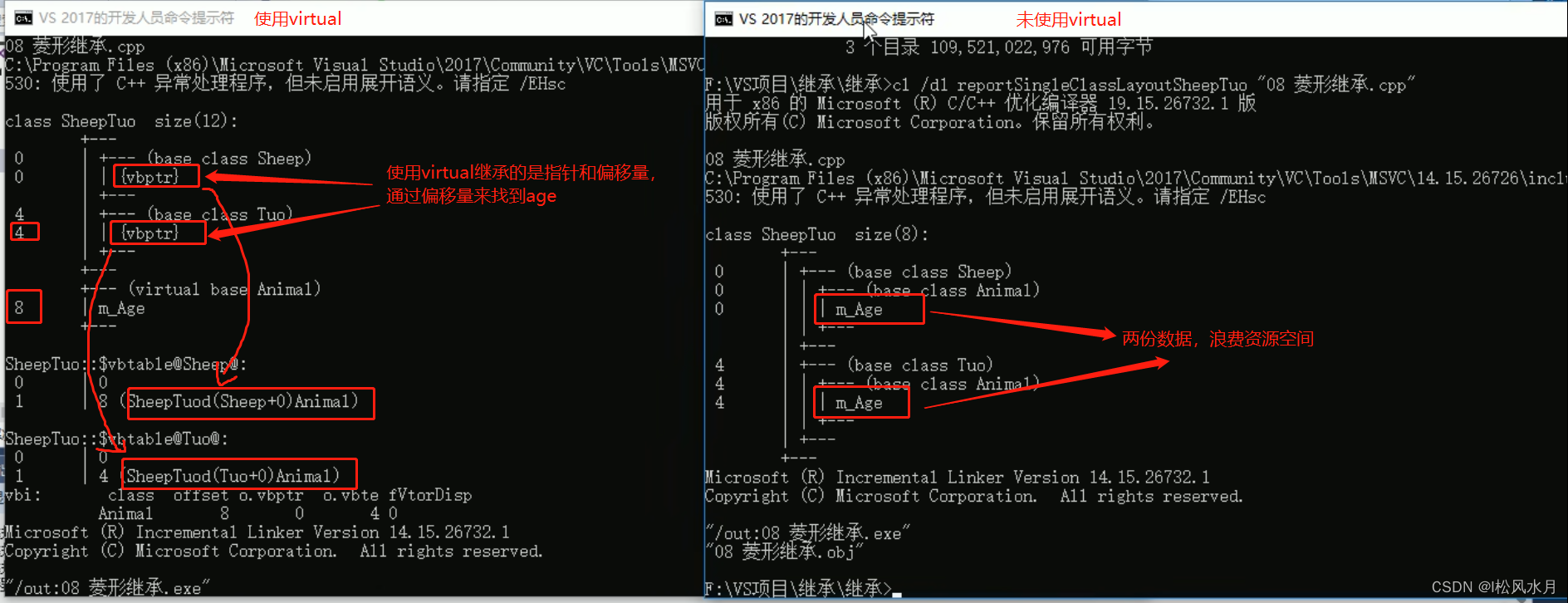
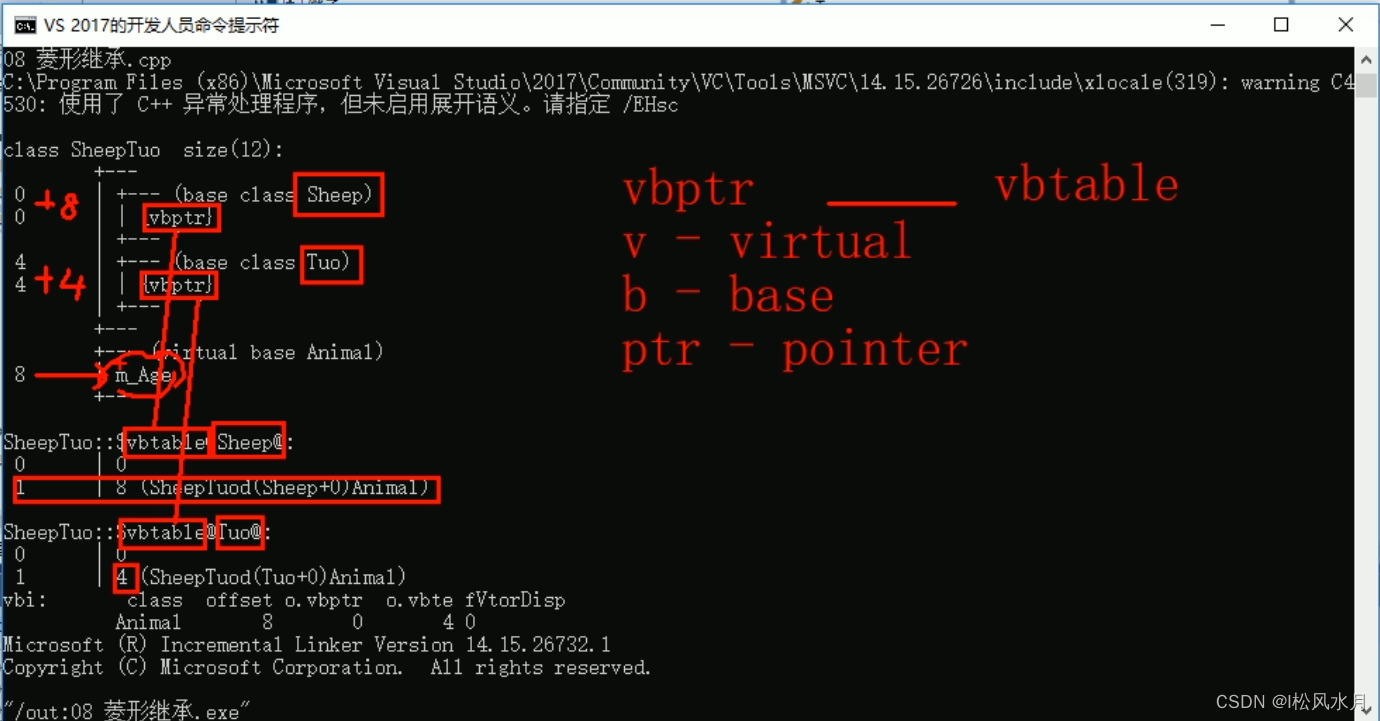
上图中的vbptr是虚基类指针,会指向vbtable(虚基类表)
总结:
- 菱形继承带来的主要问题是子类继承两份相同的数据,导致资源浪费以及毫无意义
- 利用虚继承可以解决菱形继承问题
- 不建议使用
多态
多态是C++面向对象三大特性之一
多态分为两类:
- 静态多态:函数重载和运算符重载属于静态多态,复用函数名
- 动态多态: 派生类和虚函数实现运行时多态,通常我们指的多态都是动态多态
静态多态和动态多态区别:
- 静态多态的函数地址早绑定 - 编译阶段确定函数地址
- 动态多态的函数地址晚绑定 - 运行阶段确定函数地址
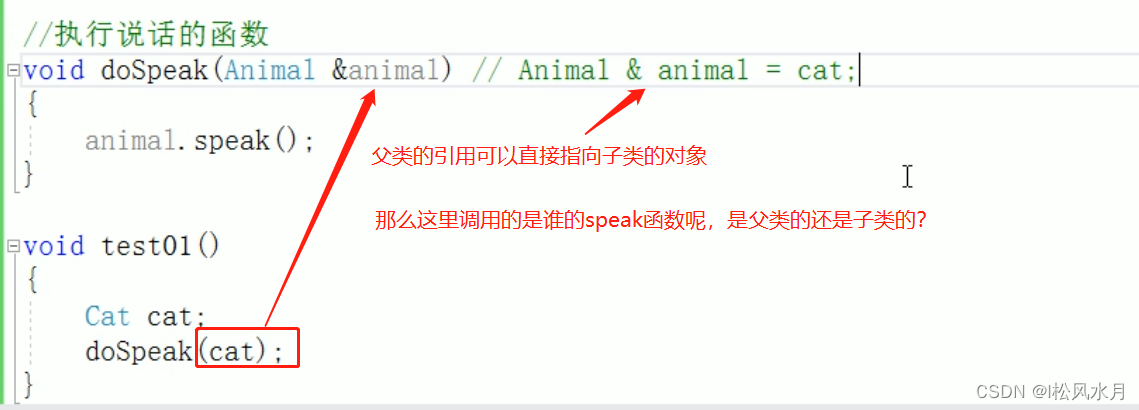
在C++中,允许父子之间的类型转换,不需要做强制类型转换,父类的指针或者引用可以直接指向子类的对象。
上面的代码输出是的动物在说话,因为现在我们函数的地址属于地址早绑定,传入的对象已经跟Animal的地址绑定了,在编译阶段就已经确定了函数的地址。如果想执行让猫说话,那么这个函数地址就不能提前绑定,需要在运行阶段进行绑定,地址晚绑定。怎么做呢?就是在父类的函数前面加上virtual,加上这个virtual之后下面子类再实现与父类同名的函数之后就可以实现地址晚绑定。
多态满足条件:
1、有继承关系
2、子类重写父类中的虚函数,virtual关键字可写可不写
多态使用:
父类指针或引用指向子类对象
看下面的例子:
class Animal
{
public:
//Speak函数就是虚函数
//函数前面加上virtual关键字,变成虚函数,那么编译器在编译的时候就不能确定函数调用了。
virtual void speak()
{
cout << "动物在说话" << endl;
}
};
class Cat :public Animal
{
public:
void speak()
{
cout << "小猫在说话" << endl;
}
};
class Dog :public Animal
{
public:
void speak()
{
cout << "小狗在说话" << endl;
}
};
//我们希望传入什么对象,那么就调用什么对象的函数
//如果函数地址在编译阶段就能确定,那么静态联编
//如果函数地址在运行阶段才能确定,就是动态联编
void DoSpeak(Animal & animal)
{
animal.speak();
}
//
//动态多态满足条件:
//1、有继承关系
//2、子类重写父类中的虚函数,virtual关键字可写可不写
//多态使用:
//父类指针或引用指向子类对象
void test01()
{
Cat cat;
DoSpeak(cat);
Dog dog;
DoSpeak(dog);
}
int main() {
test01();
system("pause");
return 0;
}
动态多态满足条件:
1、有继承关系
2、子类重写父类中的虚函数,virtual关键字可写可不写
多态使用:
父类指针或引用指向子类对象
多态的低层原理
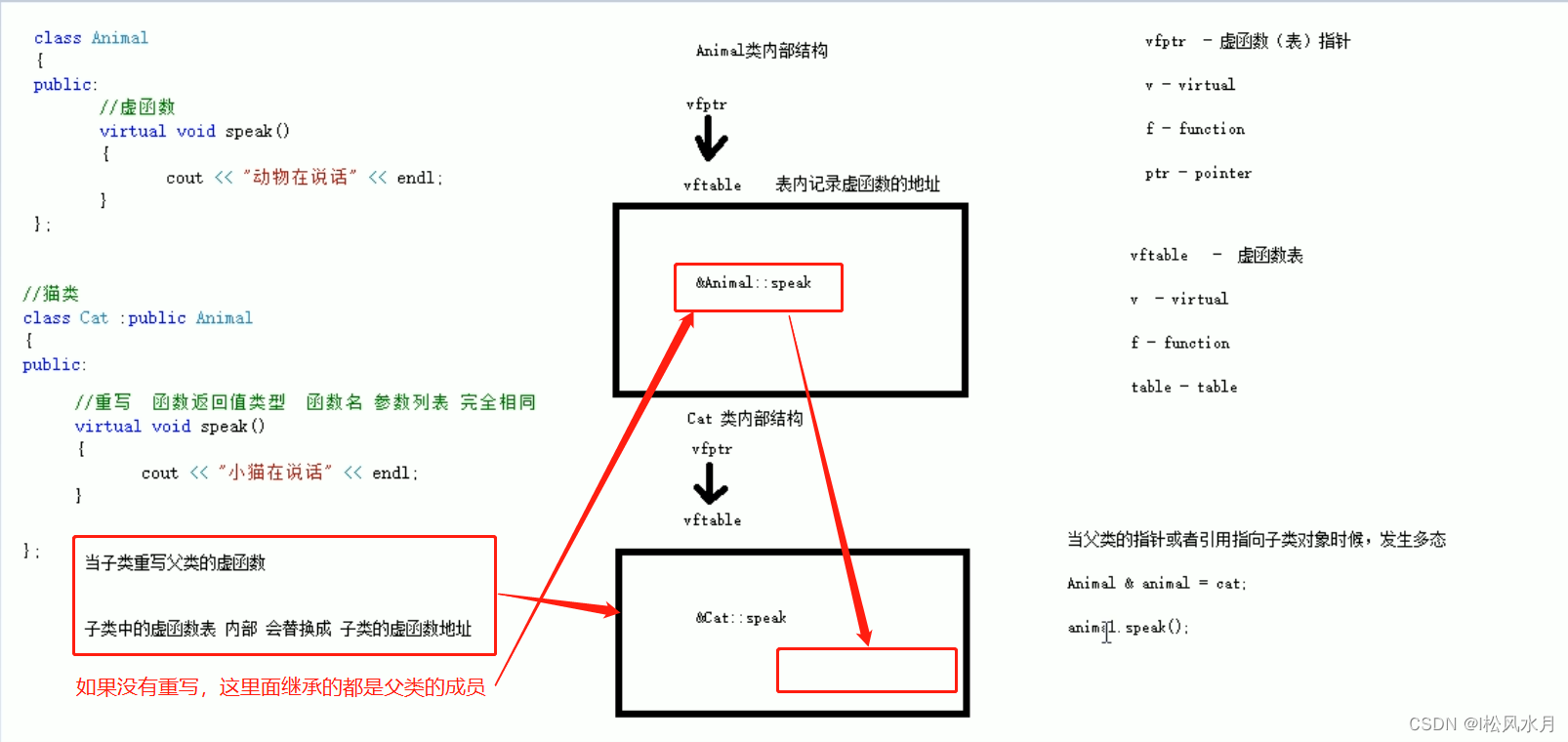
上图的核心是虚函数表,子类中的虚函数表内部会替换成子类的函数地址。父类里面有虚函数表指针,指向父类中的虚函数,当子类重新写父类中的函数的时候,父类对象的引用或者指针指向子类就发生了多态,此时指针就指向了子类。
多态的优点:
- 代码组织结构清晰
- 可读性强
- 利于前期和后期的扩展以及维护
我们来看个案例实现计算器:
//普通实现
class Calculator {
public:
int getResult(string oper)
{
if (oper == "+") {
return m_Num1 + m_Num2;
}
else if (oper == "-") {
return m_Num1 - m_Num2;
}
else if (oper == "*") {
return m_Num1 * m_Num2;
}
//如果要提供新的运算,需要修改源码
}
public:
int m_Num1;
int m_Num2;
};
void test01()
{
//普通实现测试
Calculator c;
c.m_Num1 = 10;
c.m_Num2 = 10;
cout << c.m_Num1 << " + " << c.m_Num2 << " = " << c.getResult("+") << endl;
cout << c.m_Num1 << " - " << c.m_Num2 << " = " << c.getResult("-") << endl;
cout << c.m_Num1 << " * " << c.m_Num2 << " = " << c.getResult("*") << endl;
}
//多态实现
//抽象计算器类
//多态优点:代码组织结构清晰,可读性强,利于前期和后期的扩展以及维护
class AbstractCalculator
{
public :
virtual int getResult()
{
return 0;
}
int m_Num1;
int m_Num2;
};
//加法计算器
class AddCalculator :public AbstractCalculator
{
public:
int getResult()
{
return m_Num1 + m_Num2;
}
};
//减法计算器
class SubCalculator :public AbstractCalculator
{
public:
int getResult()
{
return m_Num1 - m_Num2;
}
};
//乘法计算器
class MulCalculator :public AbstractCalculator
{
public:
int getResult()
{
return m_Num1 * m_Num2;
}
};
void test02()
{
//创建加法计算器
AbstractCalculator *abc = new AddCalculator;
abc->m_Num1 = 10;
abc->m_Num2 = 10;
cout << abc->m_Num1 << " + " << abc->m_Num2 << " = " << abc->getResult() << endl;
delete abc; //用完了记得销毁
//创建减法计算器
abc = new SubCalculator;
abc->m_Num1 = 10;
abc->m_Num2 = 10;
cout << abc->m_Num1 << " - " << abc->m_Num2 << " = " << abc->getResult() << endl;
delete abc;
//创建乘法计算器
abc = new MulCalculator;
abc->m_Num1 = 10;
abc->m_Num2 = 10;
cout << abc->m_Num1 << " * " << abc->m_Num2 << " = " << abc->getResult() << endl;
delete abc;
}
int main() {
//test01();
test02();
system("pause");
return 0;
}
总结:C++开发提倡利用多态设计程序架构,因为多态优点很多
纯虚函数和抽象类
在多态中,通常父类中虚函数的实现是毫无意义的,主要都是调用子类重写的内容,因此可以将虚函数改为纯虚函数。当父类有意义时就不需要写纯虚函数。
纯虚函数语法:virtual 返回值类型 函数名 (参数列表)= 0 ;
当类中有了纯虚函数,这个类也称为抽象类
抽象类主要用于实现接口和多态,只能用于指针或引用的形式,即可以创建指向抽象类的指针或引用。
抽象类特点:
- 无法实例化对象
- 子类必须重写抽象类中的纯虚函数,否则也属于抽象类
class Base
{
public:
//纯虚函数
//类中只要有一个纯虚函数就称为抽象类
//抽象类无法实例化对象
//子类必须重写父类中的纯虚函数,否则也属于抽象类,无法实例化对象
virtual void func() = 0; //纯虚函数,前面必须加virtual才可以等于0
};
class Son :public Base
{
public:
//子类必须重写父类中的纯虚函数,否则也属于抽象类,无法实例化对象
virtual void func()
{
cout << "func调用" << endl;
};
};
void test01()
{
Base * base = NULL;
// Base b;// 错误,抽象类无法实例化对象
//base = new Base; // 错误,抽象类无法实例化对象。无论栈还是堆方式都不可以
base = new Son;
base->func();
delete base;//记得销毁
}
int main() {
test01();
system("pause");
return 0;
}
多态的技术:
父类的指针用来引用或者指向子类的对象
我们再来看个例子,制作不同的饮品。
//抽象制作饮品
class AbstractDrinking {
public:
//烧水
virtual void Boil() = 0;
//冲泡
virtual void Brew() = 0;
//倒入杯中
virtual void PourInCup() = 0;
//加入辅料
virtual void PutSomething() = 0;
//规定流程
void MakeDrink() {
Boil();
Brew();
PourInCup();
PutSomething();
}
};
//制作咖啡
class Coffee : public AbstractDrinking {
public:
//烧水
virtual void Boil() {
cout << "煮农夫山泉!" << endl;
}
//冲泡
virtual void Brew() {
cout << "冲泡咖啡!" << endl;
}
//倒入杯中
virtual void PourInCup() {
cout << "将咖啡倒入杯中!" << endl;
}
//加入辅料
virtual void PutSomething() {
cout << "加入牛奶!" << endl;
}
};
//制作茶水
class Tea : public AbstractDrinking {
public:
//烧水
virtual void Boil() {
cout << "煮自来水!" << endl;
}
//冲泡
virtual void Brew() {
cout << "冲泡茶叶!" << endl;
}
//倒入杯中
virtual void PourInCup() {
cout << "将茶水倒入杯中!" << endl;
}
//加入辅料
virtual void PutSomething() {
cout << "加入枸杞!" << endl;
}
};
//业务函数
void DoWork(AbstractDrinking* drink) {
drink->MakeDrink();
delete drink;
}
void test01() {
DoWork(new Coffee);
cout << "--------------" << endl;
DoWork(new Tea);
}
int main() {
test01();
system("pause");
return 0;
}
多态的核心,通过父类指针或者引用指向之类对象,从子类中寻找重写的函数
虚析构和纯虚析构
下面我们来介绍下虚析构和纯虚析构,为什么要知道这个呢?我们知道在多态使用的时候是父类的指针或者引用用来指向子类对象,但是呢父类的指针是无法释放子类中的析构代码,那么子类中的数据开辟到堆区了,那么父类指针在delete的时候就无法释放子类的数据,就会造成内存泄露
多态使用时,如果子类中有属性开辟到堆区,那么父类指针在释放时无法调用到子类的析构代码
解决方式:将父类中的析构函数改为虚析构或者纯虚析构
虚析构和纯虚析构共性:
- 可以解决父类指针释放子类对象
- 都需要有具体的函数实现
虚析构和纯虚析构区别:
- 如果代码中有
纯虚析构,该类属于抽象类,无法实例化对象
虚析构语法:
virtual ~类名(){}
纯虚析构语法:
virtual ~类名() = 0;
类名::~类名(){}
class Animal {
public:
Animal()
{
cout << "Animal 构造函数调用!" << endl;
}
virtual void Speak() = 0;
//析构函数加上virtual关键字,变成虚析构函数
//virtual ~Animal()
//{
// cout << "Animal虚析构函数调用!" << endl;
//}
/*纯虚析构,利用纯虚析构和虚析构都可以解决,只能用一个。纯虚析构里面也要写上代码实现,不然直接写这句话报错,
类外写上代码实现。区分跟纯虚函数的区别,纯虚函数可以直接写等于0*/
//有了纯虚析构 之后 ,这个类也属于抽象类,无法实例化对象
virtual ~Animal() = 0;
};
//如果这里不使用虚析构,将无法释放子类中的堆区数据
Animal::~Animal()
{
cout << "Animal 纯虚析构函数调用!" << endl;
}
//和包含普通纯虚函数的类一样,包含了纯虚析构函数的类也是一个抽象类。不能够被实例化。
class Cat : public Animal {
public:
Cat(string name)
{
cout << "Cat构造函数调用!" << endl;
m_Name = new string(name);
}
virtual void Speak()
{
cout << *m_Name << "小猫在说话!" << endl;
}
~Cat()
{
cout << "Cat析构函数调用!" << endl;
if (this->m_Name != NULL) {
delete m_Name;
m_Name = NULL;
}
}
public:
string *m_Name;
};
void test01()
{
Animal *animal = new Cat("Tom");
animal->Speak();
//父类指针在析构时候 不会调用子类中析构函数,导致子类如果有堆区属性,出现内存泄漏
//怎么解决?把基类改成一个虚析构函数
//虚析构函数就是用来解决通过父类指针释放子类对象,是因为在运行时,会根据对象的实际类型调用相应的析构函数。这样就可以确保子类对象被正确地销毁,避免了内存泄漏和其他异常问题。
delete animal;
}
int main() {
test01();
system("pause");
return 0;
}
总结:
- 虚析构或纯虚析构就是用来解决通过父类指针释放子类对象,两个都可以,区别就在于写了纯虚析构之后这个类属于抽象类。
- 如果子类中没有堆区数据,可以不写为虚析构或纯虚析构
- 拥有纯虚析构函数的类也属于抽象类
- 虚析构和纯虚析构都必须有具体的函数实现。
- 父类中有了纯虚析构在也是抽象类,无法实例化对象。
文件操作
程序运行时产生的数据都属于临时数据,程序一旦运行结束都会被释放。
C++对文件的操作也是基于面向对象的操作
通过文件可以将数据持久化
C++中对文件操作需要包含头文件 < fstream >
文件类型分为两种:
- 文本文件 - 文件以文本的ASCII码形式存储在计算机中
- 二进制文件 - 文件以文本的二进制形式存储在计算机中,用户一般不能直接读懂它们
操作文件的三大类:
- ofstream:写操作
- ifstream: 读操作
- fstream : 读写操作
文本文件
写文件步骤如下:
- 包含头文件
#include <fstream>- 创建流对象
ofstream ofs;- 打开文件
ofs.open(“文件路径”,打开方式);- 写数据
ofs << “写入的数据”;- 关闭文件
ofs.close();
文件打开方式:
| 打开方式 | 解释 |
|---|---|
| ios::in | 为读文件而打开文件 |
| ios::out | 为写文件而打开文件 |
| ios::ate | 初始位置:文件尾 |
| ios::app | 追加方式写文件 |
| ios::trunc | 如果文件存在先删除,再创建 |
| ios::binary | 二进制方式 |
注意: 文件打开方式可以配合使用,利用|操作符
例如:用二进制方式写文件 ios::binary | ios:: out
#include <fstream>
void test01()
{
ofstream ofs;
ofs.open("test.txt", ios::out);
ofs << "姓名:张三" << endl;
ofs << "性别:男" << endl;
ofs << "年龄:18" << endl;
ofs.close();
}
int main() {
test01();
system("pause");
return 0;
}
上面的程序运行完会在程序所在位置生成一个txt文档
总结:
- 文件操作必须包含头文件 fstream
- 读文件可以利用 ofstream ,或者fstream类
- 打开文件时候需要指定操作文件的路径,以及打开方式
- 利用<<可以向文件中写数据
- 操作完毕,要关闭文件
读文件
读文件与写文件步骤相似,但是读取方式相对于比较多
读文件步骤如下:
- 包含头文件
#include <fstream>- 创建流对象
ifstream ifs;- 打开文件并判断文件是否打开成功
ifs.open(“文件路径”,打开方式);- 读数据
四种方式读取- 关闭文件
ifs.close();
#include <fstream>
#include <string>
void test01()
{
ifstream ifs;
ifs.open("test.txt", ios::in);
if (!ifs.is_open())
{
cout << "文件打开失败" << endl;
return;
}
//第一种方式
//char buf[1024] = { 0 };
//while (ifs >> buf)
//{
// cout << buf << endl;
//}
//第二种
//char buf[1024] = { 0 };
//while (ifs.getline(buf,sizeof(buf)))
//{
// cout << buf << endl;
//}
//第三种
//string buf;
//while (getline(ifs, buf))
//{
// cout << buf << endl;
//}
char c;
while ((c = ifs.get()) != EOF)
{
cout << c;
}
ifs.close();
}
int main() {
test01();
system("pause");
return 0;
}
二进制文件写
以二进制的方式对文件进行读写操作
打开方式要指定为 ios::binary
5.2.1 写文件
二进制方式写文件主要利用流对象调用成员函数write
函数原型 :ostream& write(const char * buffer,int len);
参数解释:字符指针buffer指向内存中一段存储空间。len是读写的字节数
#include <fstream>
#include <string>
class Person
{
public:
char m_Name[64];
int m_Age;
};
//二进制文件 写文件
void test01()
{
//1、包含头文件
//2、创建输出流对象
ofstream ofs("person.txt", ios::out | ios::binary);
//3、打开文件
//ofs.open("person.txt", ios::out | ios::binary);
Person p = {"张三" , 18};
//4、写文件
ofs.write((const char *)&p, sizeof(p));
//5、关闭文件
ofs.close();
}
int main() {
test01();
system("pause");
return 0;
}
- 文件输入流对象 可以通过read函数,以二进制方式读数据
读文件
二进制方式读文件主要利用流对象调用成员函数read
函数原型:istream& read(char *buffer,int len);
参数解释:字符指针buffer指向内存中一段存储空间。len是读写的字节数
#include <fstream>
#include <string>
class Person
{
public:
char m_Name[64];
int m_Age;
};
void test01()
{
ifstream ifs("person.txt", ios::in | ios::binary);
if (!ifs.is_open())
{
cout << "文件打开失败" << endl;
}
Person p;
ifs.read((char *)&p, sizeof(p));
cout << "姓名: " << p.m_Name << " 年龄: " << p.m_Age << endl;
}
int main() {
test01();
system("pause");
return 0;
}