本人强烈建议在 linux环境下 学习 spark!!!
Introduction
Apache Spark是一个快速且通用的分布式计算引擎,可以在大规模数据集上进行高效的数据处理,包括数据转换、数据清洗、机器学习等。在本文中,我们将讨论如何在Windows上配置Spark开发环境,以及如何进行开发和测试等。
安装 Java 和 Spark
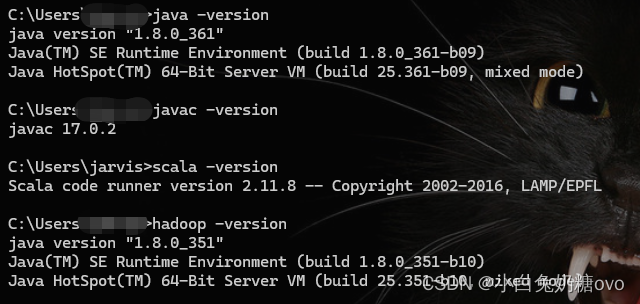
- 为了在Windows上使用Spark开发环境,你需要先安装
Java和Spark,并配置环境变量。你可以从Oracle官网下载最新版本的Java Development Kit(JDK),然后安装它。在安装完成后,你需要将Java的安装目录添加到系统环境变量中,以便Spark可以找到Java。接下来,你可以从Apache Spark官网下载适用于Windows的二进制文件,并解压到本地目录。
使用 Pyspark 或 Spark shell
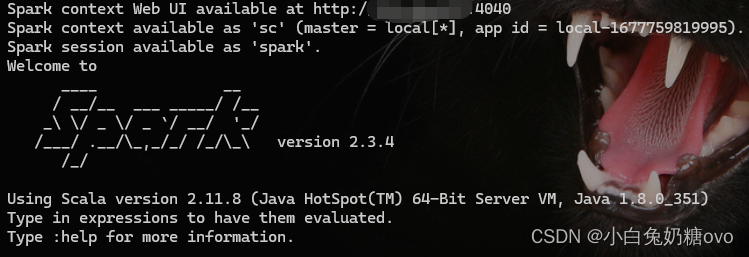
- 在下载
Spark二进制文件后,你可以使用Pyspark或Spark shell在本地或集群上进行开发。Pyspark是一个Python API,可以使开发者用Python编写Spark应用程序。Spark shell是一个交互式环境,可以允许你使用Scala、Java或Python来调试和测试Spark代码。你可以在命令行中输入“pyspark”或“spark-shell”命令来启动相应的环境。
安装 Winutils 工具
- Winutils是一个用于在
Windows上运行Hadoop的工具,它提供了一些必要的组件和环境变量,以便Spark可以在Windows上运行。你需要从Apache官网下载Winutils二进制文件,并解压到本地目录。接下来,你需要将Winutils的安装目录添加到系统环境变量中,以便Spark可以找到它。 切记:下载与自己hadoop对应的版本,并将原本hadoop/bin替换掉!
Conclusion
- 在开发和部署
Spark应用程序时,确保你了解Spark的最佳实践和安全性措施,以避免潜在的安全漏洞和性能问题。你可以使用一些第三方的库来扩展你的Spark开发环境,例如Pyrolite和SparkR。此外,你还可以考虑使用一些数据可视化工具来帮助你更好地了解和展示你的数据,例如Tableau和PowerBI等。最后,要时刻注意更新你的环境和依赖库,以保持最新的功能和性能优化。
使用集成开发环境(IDE)
- 除了使用
Pyspark或Spark shell,你还可以考虑使用一些集成开发环境(IDE)来提高开发效率,例如PyCharm或IntelliJ IDEA等。这些IDE提供了更强大的代码编辑、自动补全和调试功能,可以帮助你更快地开发和测试Spark应用程序。此外,一些IDE还提供了一些有用的插件,可以帮助你更好地管理你的项目和依赖库。

安装下列插件:


在集群上运行 Spark 应用程序
- 在使用集群时,确保你有足够的资源来支持你的开发和测试,例如足够的内存和处理器。你可以使用一些集群管理工具,例如
Apache Hadoop、Apache Mesos或者Apache YARN等来管理和分配资源。在部署Spark应用程序时,你需要将你的应用程序打包成一个jar文件,并将其提交到集群中运行。你可以使用一些工具,例如Apache Maven或SBT等来打包和管理你的应用程序。 - 如果你已经在Windows上配置了Spark开发环境,可以考虑使用sbt来打包和管理你的应用程序,而不是使用
maven打包和管理。这可以帮助你更好地管理你的依赖库和构建过程,并提高你的开发效率。另外,你还需要时刻注意更新你的环境和依赖库,以保持最新的功能和性能优化。
附上:SBT的使用教程
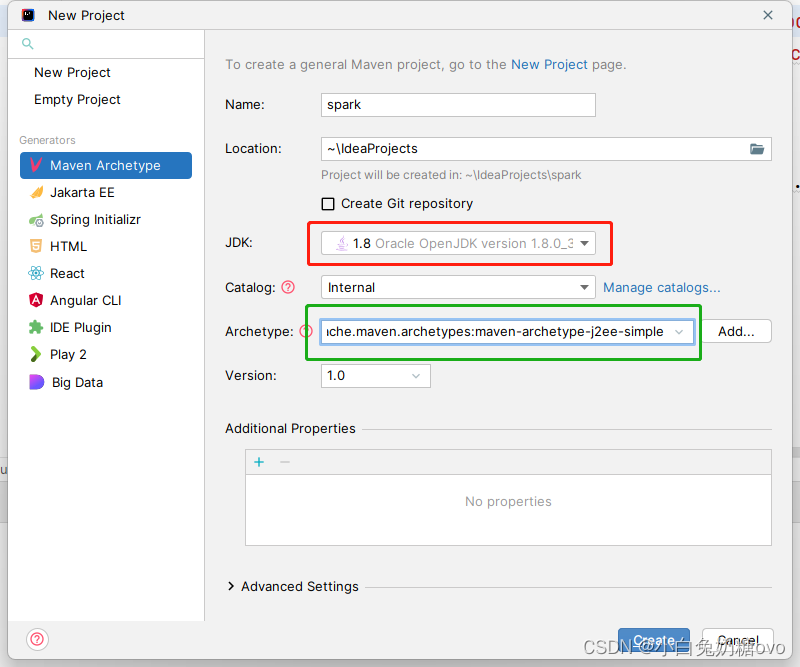
创建mvn项目:
扩展你的 Spark 开发环境
- 你可以使用一些第三方的库来扩展你的Spark开发环境,例如
Pyrolite和SparkR。Pyrolite是一个Python库,可以让你在Python中使用Java类和对象,从而方便你与Java代码进行交互。SparkR是一个R语言的API,可以让你用R语言编写Spark应用程序。此外,你还可以使用一些数据可视化工具来帮助你更好地了解和展示你的数据,例如Tableau和PowerBI等。
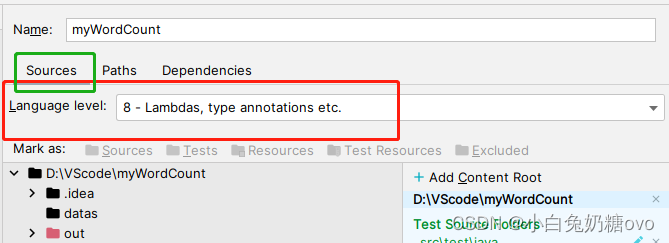
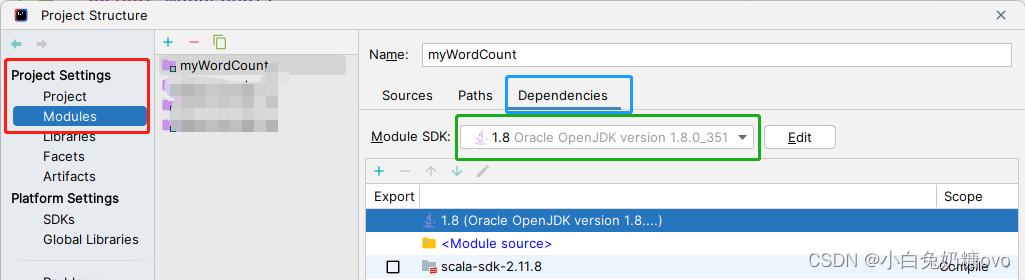
更新你的环境和依赖库
- 最后,在开发Spark应用程序时,你需要时刻注意更新你的环境和依赖库,以保持最新的功能和性能优化。你可以使用一些工具,例如Apache Maven或SBT等来管理你的依赖库,并定期更新它们。此外,你还需要定期更新你的Spark版本和相关组件,以获得最新的功能和修复潜在的漏洞。
Bugs 修复
scalac: Error: Error compiling the sbt component 'compiler-interface-2.11.8-61.0'
sbt.internal.inc.CompileFailed: Error compiling the sbt component 'compiler-interface-2.11.8-61.0'
at sbt.internal.inc.AnalyzingCompiler$.handleCompilationError$1(AnalyzingCompiler.scala:436)
at sbt.internal.inc.AnalyzingCompiler$.$anonfun$compileSources$5(AnalyzingCompiler.scala:453)
at sbt.internal.inc.AnalyzingCompiler$.$anonfun$compileSources$5$adapted(AnalyzingCompiler.scala:448)
at sbt.io.IO$.withTemporaryDirectory(IO.scala:490)
at sbt.io.IO$.withTemporaryDirectory(IO.scala:500)
at sbt.internal.inc.AnalyzingCompiler$.$anonfun$compileSources$2(AnalyzingCompiler.scala:448)
at sbt.internal.inc.AnalyzingCompiler$.$anonfun$compileSources$2$adapted(AnalyzingCompiler.scala:440)
at sbt.io.IO$.withTemporaryDirectory(IO.scala:490)
at sbt.io.IO$.withTemporaryDirectory(IO.scala:500)
at sbt.internal.inc.AnalyzingCompiler$.compileSources(AnalyzingCompiler.scala:440)
at org.jetbrains.jps.incremental.scala.local.CompilerFactoryImpl$.org$jetbrains$jps$incremental$scala$local$CompilerFactoryImpl$$getOrCompileInterfaceJar(CompilerFactoryImpl.scala:162)
at org.jetbrains.jps.incremental.scala.local.CompilerFactoryImpl.$anonfun$getScalac$1(CompilerFactoryImpl.scala:58)
at scala.Option.map(Option.scala:242)
at org.jetbrains.jps.incremental.scala.local.CompilerFactoryImpl.getScalac(CompilerFactoryImpl.scala:51)
at org.jetbrains.jps.incremental.scala.local.CompilerFactoryImpl.createCompiler(CompilerFactoryImpl.scala:20)
at org.jetbrains.jps.incremental.scala.local.CachingFactory.$anonfun$createCompiler$3(CachingFactory.scala:21)
at org.jetbrains.jps.incremental.scala.local.Cache.$anonfun$getOrUpdate$2(Cache.scala:17)
at scala.Option.getOrElse(Option.scala:201)
at org.jetbrains.jps.incremental.scala.local.Cache.getOrUpdate(Cache.scala:16)
at org.jetbrains.jps.incremental.scala.local.CachingFactory.createCompiler(CachingFactory.scala:21)
at org.jetbrains.jps.incremental.scala.local.LocalServer.doCompile(LocalServer.scala:40)
at org.jetbrains.jps.incremental.scala.local.LocalServer.compile(LocalServer.scala:27)
at org.jetbrains.jps.incremental.scala.remote.Main$.compileLogic(Main.scala:206)
at org.jetbrains.jps.incremental.scala.remote.Main$.$anonfun$handleCommand$1(Main.scala:193)
at org.jetbrains.jps.incremental.scala.remote.Main$.decorated$1(Main.scala:183)
at org.jetbrains.jps.incremental.scala.remote.Main$.handleCommand(Main.scala:190)
at org.jetbrains.jps.incremental.scala.remote.Main$.serverLogic(Main.scala:166)
at org.jetbrains.jps.incremental.scala.remote.Main$.nailMain(Main.scala:106)
at org.jetbrains.jps.incremental.scala.remote.Main.nailMain(Main.scala)
at jdk.internal.reflect.GeneratedMethodAccessor3.invoke(Unknown Source)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:568)
at com.facebook.nailgun.NGSession.runImpl(NGSession.java:312)
at com.facebook.nailgun.NGSession.run(NGSession.java:198)
解决办法:
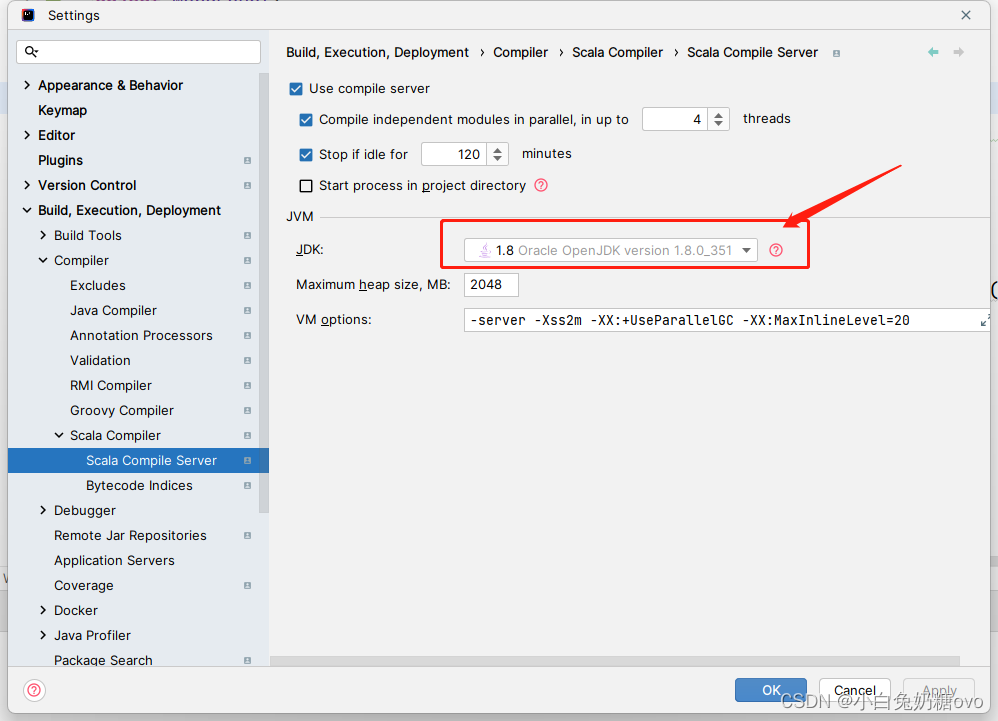
检查此处配置!
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
将SPARK_HOME/conf 目录下的 log4j.properties.template 重命名为 log4j.properties
23/03/02 18:29:33 INFO SparkContext: Created broadcast 0 from textFile at FrameDemo.scala:13
23/03/02 18:29:34 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:278)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:300)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:293)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:76)
at org.apache.hadoop.mapred.FileInputFormat.setInputPaths(FileInputFormat.java:362)
at <br>org.apache.spark.SparkContext$$anonfun$hadoopFile$1$$anonfun$33.apply(SparkContext.scala:1015)
at org.apache.spark.SparkContext$$anonfun$hadoopFile$1$$anonfun$33.apply(SparkContext.scala:1015)
at <br>org.apache.spark.rdd.HadoopRDD$$anonfun$getJobConf$6.apply(HadoopRDD.scala:176)
at <br>org.apache.spark.rdd.HadoopRDD$$anonfun$getJobConf$6.apply(HadoopRDD.scala:176)<br>
at scala.Option.map(Option.scala:145)<br>
at org.apache.spark.rdd.HadoopRDD.getJobConf(HadoopRDD.scala:176)<br>
at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:195)<br>
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)<br>
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)<br>
at scala.Option.getOrElse(Option.scala:120)<br>
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)<br>
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)<br>
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)<br>
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)<br>
at scala.Option.getOrElse(Option.scala:120)<br>
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)<br>
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1929)<br>
at org.apache.spark.rdd.RDD.count(RDD.scala:1143)<br>
at com.org.SparkDF.FrameDemo$.main(FrameDemo.scala:14)<br>
at com.org.SparkDF.FrameDemo.main(FrameDemo.scala)<br>
以编程方式设置 HADOOP_HOME 环境变量:
System.setProperty(“hadoop.home.dir”, “full path to the folder with winutils”);
总结
- 在本文中,我们讨论了如何在
Windows上配置Spark开发环境,并介绍了如何使用Pyspark或Spark shell进行开发和测试。此外,我们还讨论了如何使用集成开发环境(IDE)和扩展你的Spark开发环境。最后,我们提醒你时刻注意更新你的环境和依赖库,以保持最新的功能和性能优化。如果你正在学习Spark开发,希望这篇文章能够帮助你更好地开始你的Spark开发之旅。