数据库的操作
查看所有数据库:
SHOW DATABASES;(注意这里是 databases,多了个 s)
mysql 不区分大小写,所以 show databases; 是一样的。
另外,在命令行窗口操作时,可以使用上下方向键调用前面已经使用过的命令。

创建数据库:
CREATE DATABASE [IF NOT EXISTS] 数据库名 [CHARACTER SET 字符集名] [COLLATE 排序规则名];
其中 [ ] 是可选项
CHARACTER SET:指定数据库采用的字符集
COLLATE:指定数据库字符集的校验规则
例如创建学生库 student:

再次使用上面这条语句时,就会发生报错:

所以我们可以在创建数据库时加上 if not exists 避免这种情况:

加上后就变成,如果数据库 student 不存在就创建,存在则不会创建。
设置字符集:
当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则是:utf8_ general_ c。
如果系统没有 db_test 的数据库,则创建一个使用 utf8mb4 字符集的 db_test 数据库,如果有则不创建:

注意:MySQL 的 utf8 编码不是真正的 utf8,没有包含某些复杂的中文字符。MySQL 真正的 utf8 是使用 utf8mb4,建议使用 utf8mb4。
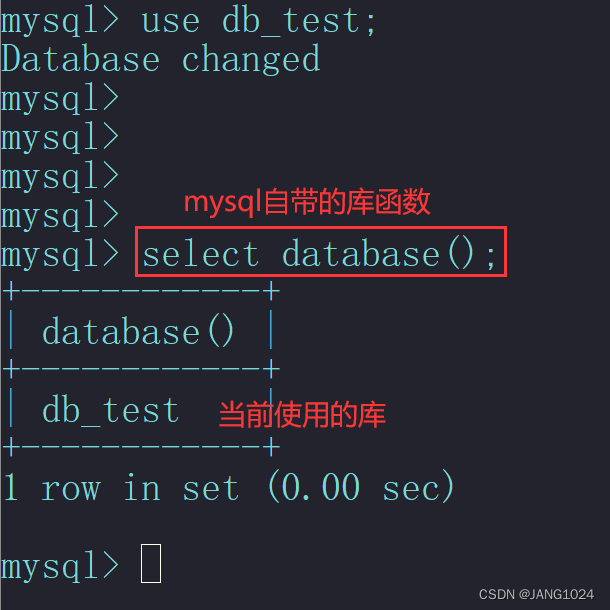
使用数据库:
USE 数据库名;
要对数据库进行后续操作,需要先选择这个数据库。

如果对数据库操作了很多语句,不知道当前使用的是哪个数据库,我们可以使用下面这条语句查看:
删除数据库:
DROP DATABASE [IF EXISTS] 数据库名;
同理,IF EXISTS 代表数据库存在就删除。
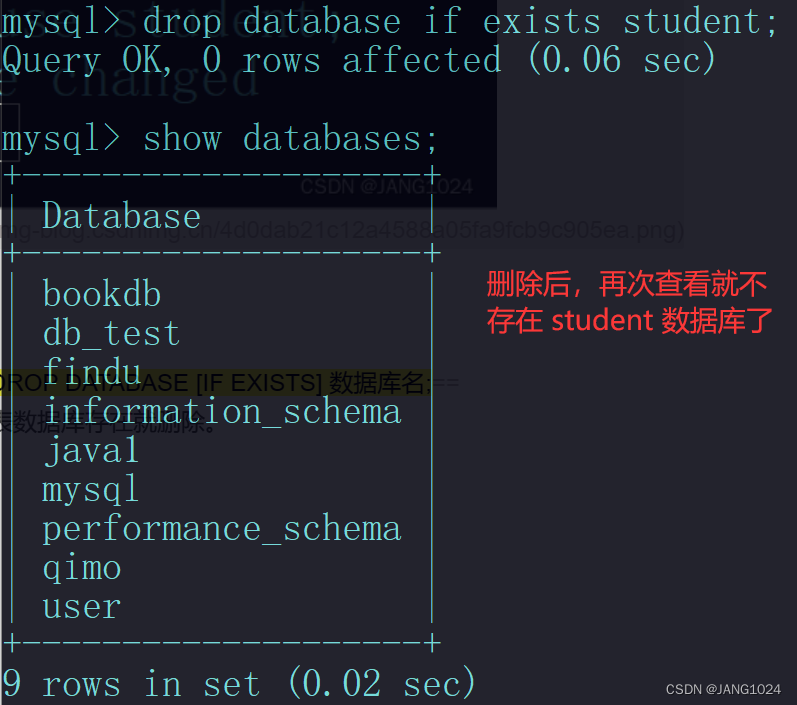
注意:这就是常说的删库跑路,危险很大,谨慎使用。
常用数据类型
在 MySQL 中,有三种主要的类型:Number(数字)、Text(文本)和 Date/Time(日期/时间)类型。
数值类型:
| 数据类型 | 大小 | 说明 | 对应java类型 |
|---|---|---|---|
| BIT[ (M) ] | M指定位数,默认为1 | 二进制数,M范围从1到64,存储数值范围从0到2^M-1 | 常用Boolean对应BIT,此时默认是1位,即只能存0和1 |
| TINYINT | 1字节 | Byte | |
| SMALLINT | 2字节 | Short | |
| INT | 4字节 | Integer | |
| BIGINT | 8字节 | Long | |
| FLOAT(M,D) | 4字节 | 单精度,M指定长度,D指定小数位数。会发生精度丢失 | Float |
| DOUBLE(M,D) | 8字节 | Double | |
| DECIMAL(M,D) | M/D最大值+2 | 双精度,M指定长度,D表示小数点位数。精确数值 | BigDecimal |
| NUMERIC(M,D) | M/D最大值+2 | 和DECIMAL一样 | BigDecimal |
文本类型:
| 数据类型 | 大小 | 说明 |
|---|---|---|
| VARCHAR (SIZE) | 0-65,535字节 | 可变长度字符串 |
| TEXT | 0-65,535字节 | 长文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| BLOB | 0-65,535字节 | 二进制形式的长文本数据 |
日期类型:
| 数据类型 | 描述 |
|---|---|
| DATE() | 日期。格式:YYYY-MM-DD 支持的范围是从 ‘1000-01-01’ 到 ‘9999-12-31’ |
| DATETIME() | 日期和时间的组合。格式:YYYY-MM-DD HH:MM:SS 支持的范围是从 ‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’ |
| TIMESTAMP() | 时间戳。格式:YYYY-MM-DD HH:MM:SS 支持的范围是从 ‘1970-01-01 00:00:01’ 到 ‘2038-01-09 03:14:07’ |
| TIME() | 时间。格式:HH:MM:SS 支持的范围是从 ‘-838:59:59’ 到 ‘838:59:59’ |
| YEAR() | 2 位或 4 位格式的年。 4 位格式所允许的值:1901 到 2155。 2 位格式所允许的值:70 到 69,表示从 1970 到 2069。 |
表的操作
查询当前数据库的所有表: SHOW TABLES;
注意:查询表以及后面对库里的表进行操作时,需要先使用该数据库(use 数据库名;)

创建表:
格式:
CREATE TABLE 表名(
字段1 字段1类型 [COMMENT 字段1注释],
字段2 字段2类型 [COMMENT 字段2注释],
字段3 字段3类型 [COMMENT 字段3注释],
………………
字段n 字段n类型 [COMMENT 字段n注释]
)[COMMENT 表注释]
注意: […] 为可选参数,最后一个字段后面没有逗号。
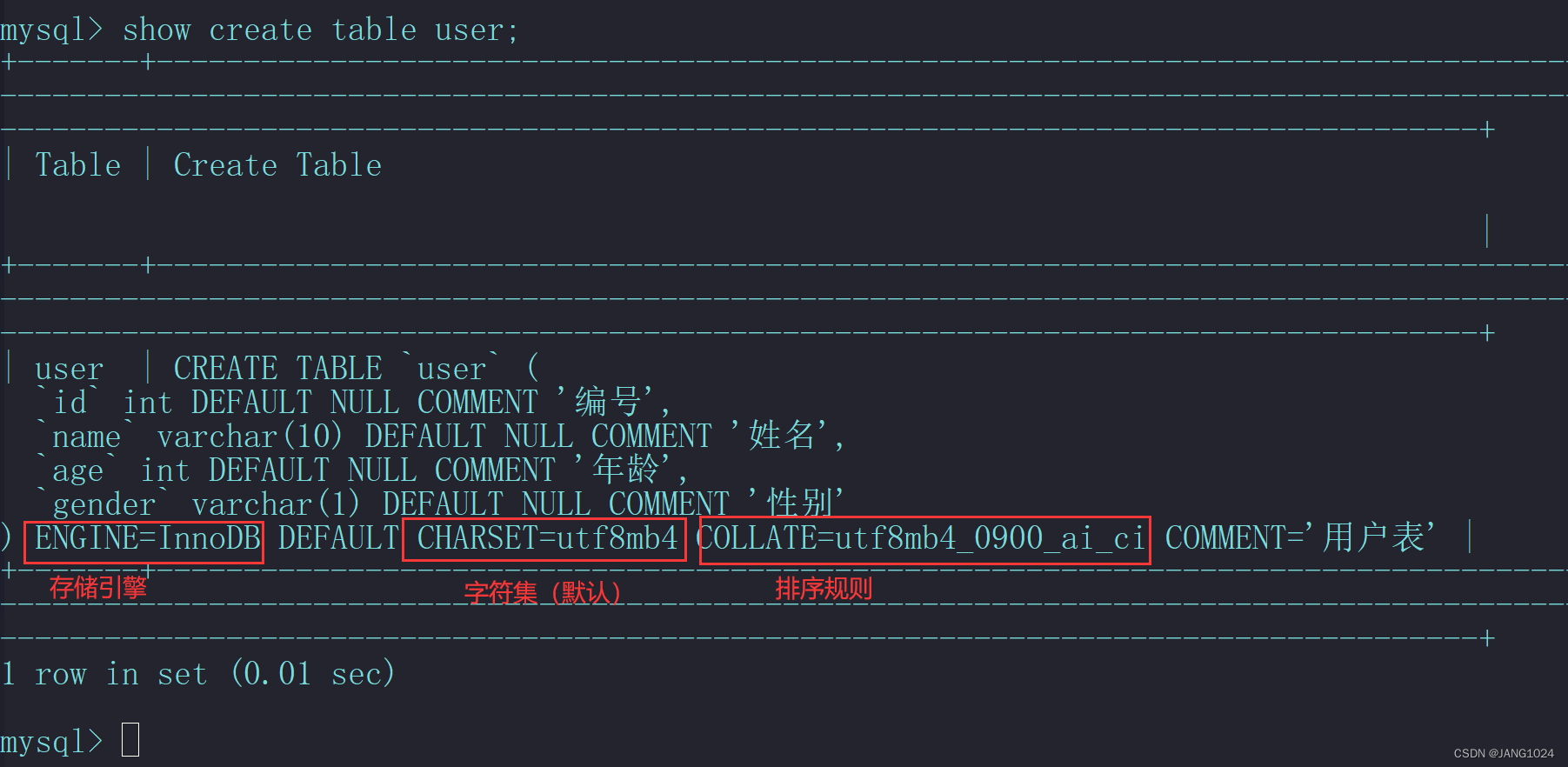
例如创建下面这张 user 表:

查看表结构: desc 表名;

查询指定表的建表语句: show create table 表名;
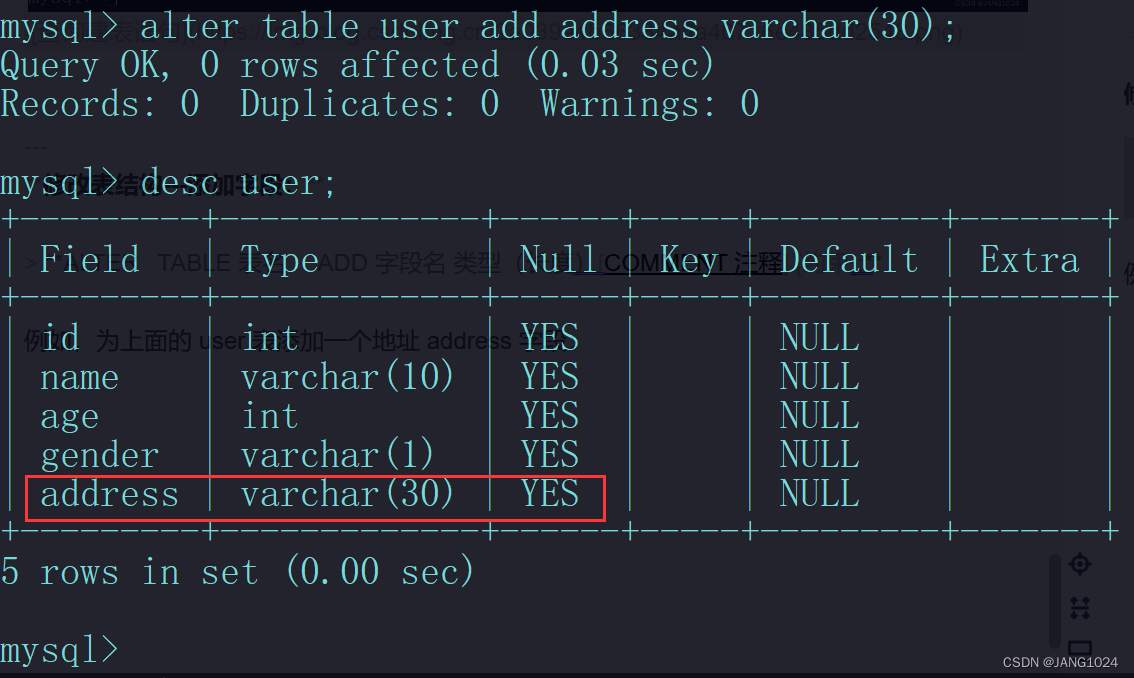
表操作—添加字段:
ALTER TABLE 表名 ADD 字段名 类型(长度)[COMMENT 注释] [约束];
例如,为上面的 user 表添加一个地址 address 字段:
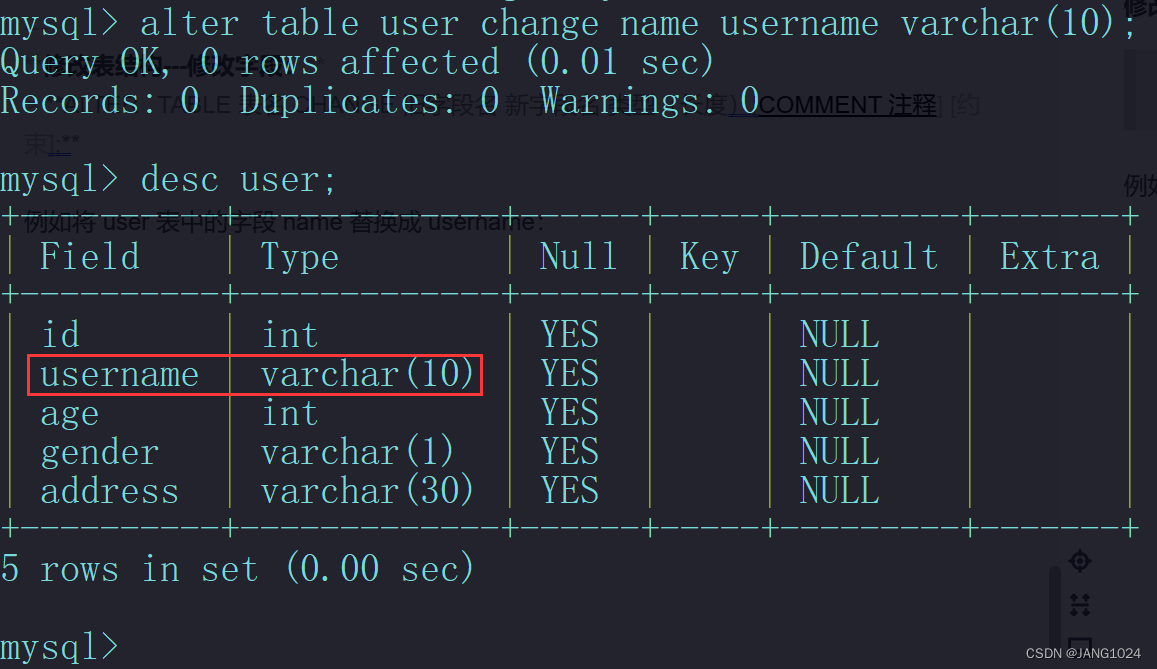
表操作—修改字段:
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度)[COMMENT 注释] [约束];
例如将 user 表中的字段 name 替换成 username:
表操作—删除字段:
ALTER TABLE 表名 DROP 字段名;
例如,将 user 表中的 address 字段删除:

表操作—修改表名:
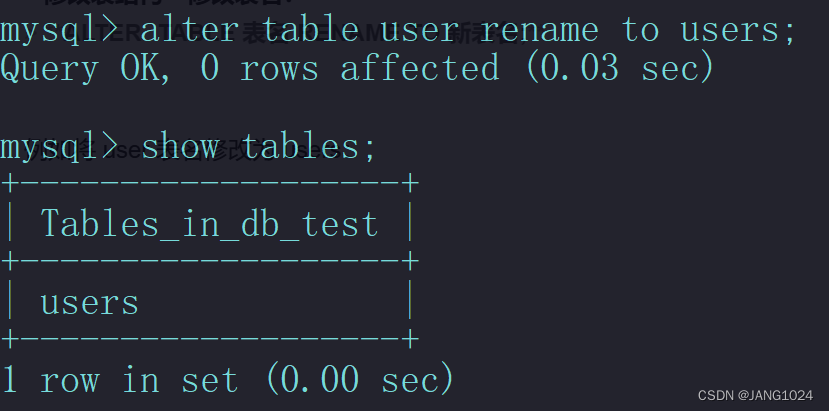
ALTER TABLE 表名 RENAME TO 新表名;
例如将 user 表名修改为 users:
表操作—删除表:
DROP TABLE [IE EXISTS] 表名;
和删库一个道理,表和表里的数据都会被删除。
还有另外一种,删除指定表,并重新创建该表:
TRUNCATE TABLE 表名;
相当于清空表里的数据,留下表结构。
数据操纵语言
添加数据:
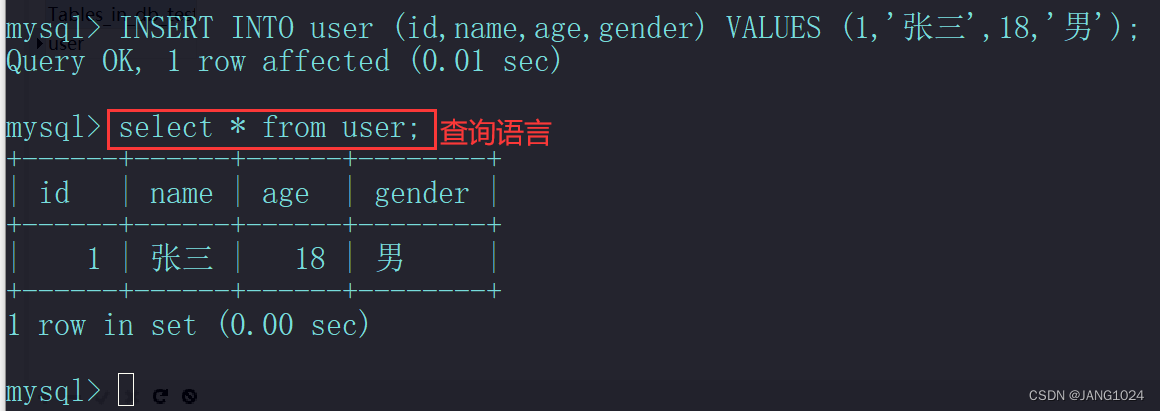
- 给指定字段添加数据:
INSERT INTO 表名 (字段1, 字段2, ……) VALUES (值1, 值2, ……);
- 给全部字段添加数据:
INSERT INTO 表名 VALUES (值1, 值2, ……);

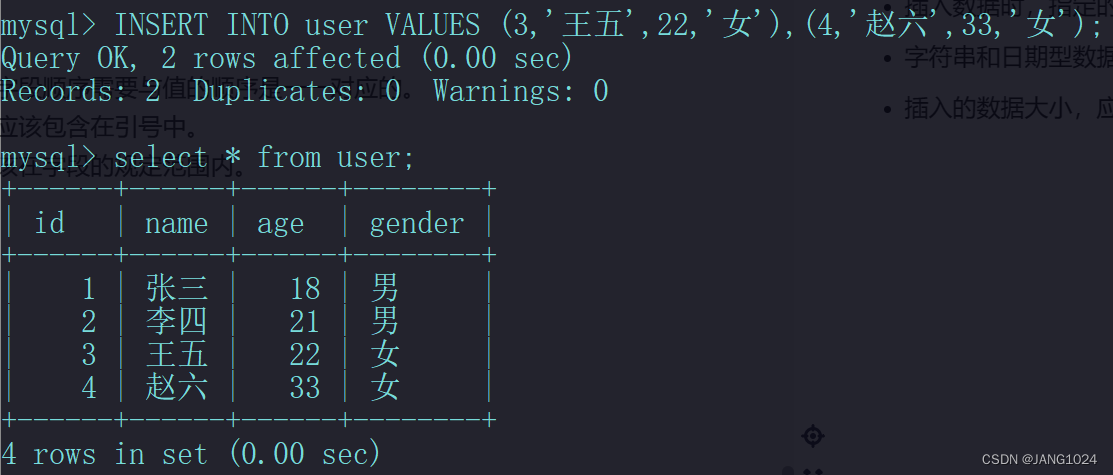
- 批量添加数据:
INSERT INTO 表名 (字段1, 字段2, ……) VALUES (值1, 值2, ……), (值1, 值2, ……), (值1, 值2, ……);
INSERT INTO 表名 VALUES (值1, 值2, ……), (值1, 值2, ……), (值1, 值2, ……);
注意:
- 插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
- 字符串和日期型数据应该包含在引号中。
- 插入的数据大小,应该在字段的规定范围内。
修改数据:
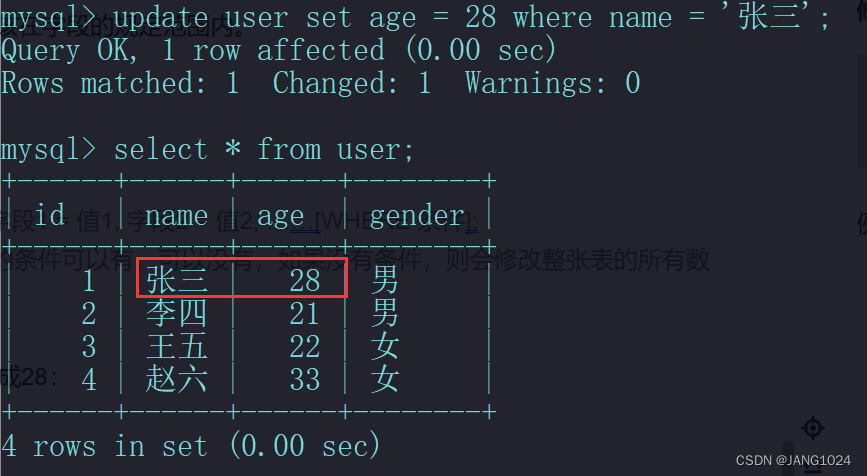
UPDATE 表名 SET 字段1 = 值1, 字段2 = 值2, ……[WHERE 条件];
注意: 修改语句的条件可以有,可以没有,如果没有条件,则会修改整张表的所有数据。
例如,把张三的年龄修改成28:
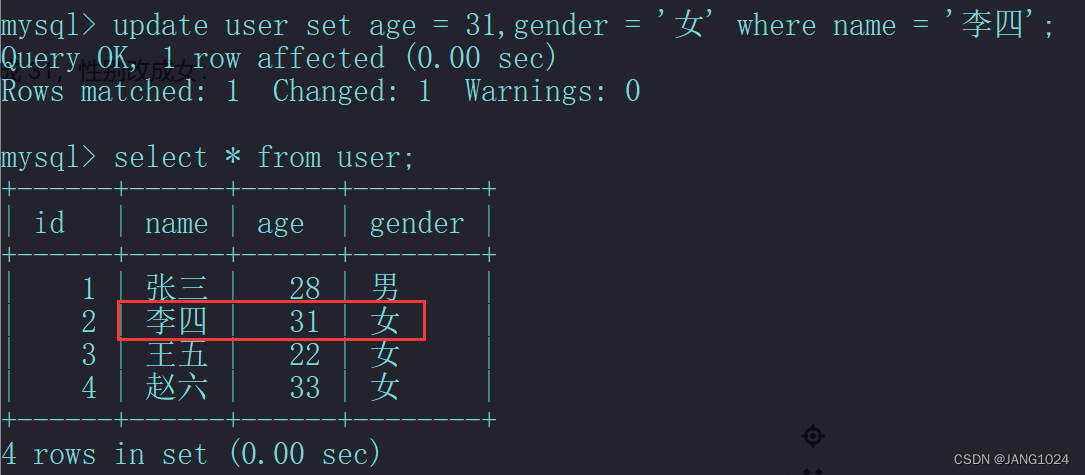
例如,把李四的年龄改成 31,性别改成女:
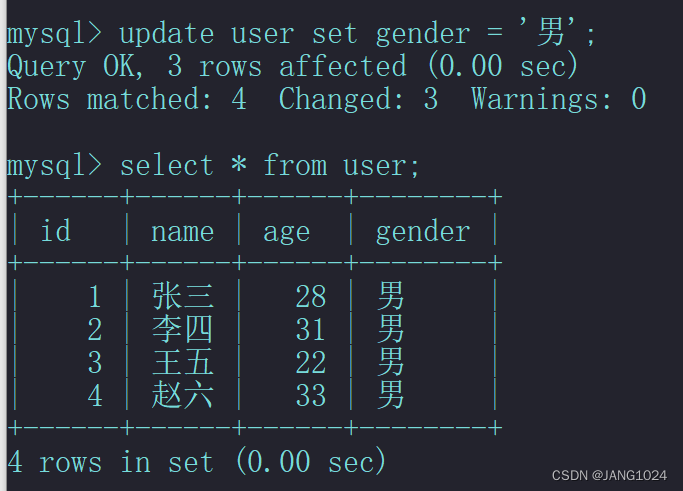
例如,把 user 表中的性别全改成男:
删除数据:
DELETE FROM 表名 [WHERE 条件];
delete 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
delete 语句不能删除某一个字段的值(可使用 update)。
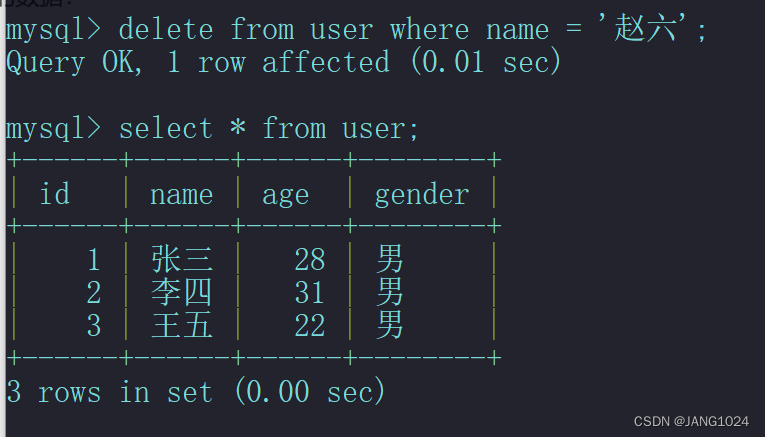
例如,删除名叫 赵六 的数据:
例如,删除所有数据:

数据查询语言
基础查询:
查询指定字段:select 字段1, 字段2…… from 表名;
例如,查询 name, gender 字段:

查询所有字段:select * from 表名;
在实际开发中,不建议使用 * 通配符,一是效率不高,二是上面指定字段的直观。
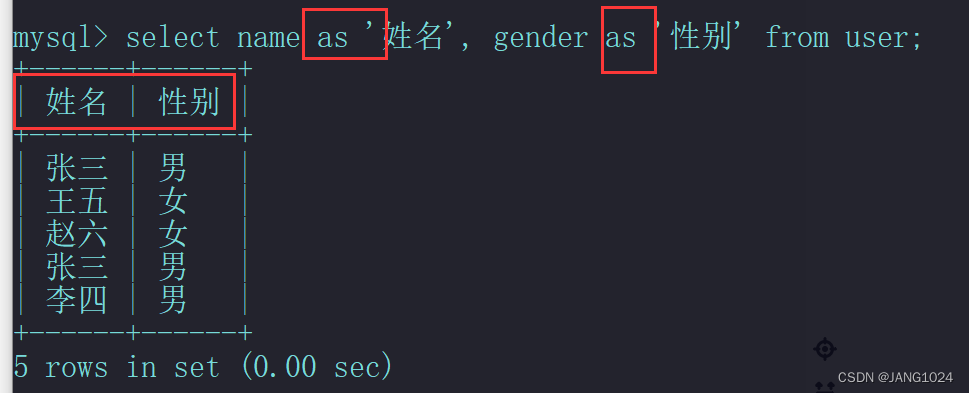
在查询的语句中,我们可以给字段添加别名,使用 AS 关键字,例如:
在上面的查询结果中,发现有两条重复记录,我们可以使用 distinct 关键字去掉这些重复的数据(只是结果不显示,并不是把表里的数据删除):

条件查询:
SELECT 字段列表 FROM 表名 WHERE 条件列表;
条件:
| 比较运算符 | 功能 | 逻辑运算符 | 功能 |
|---|---|---|---|
| > | 大于 | AND 或 && | 并且(多个条件同时成立) |
| >= | 大于等于 | OR 或 || | 或者(多个条件任意一个成立) |
| < | 小于 | NOT 或 ! | 非,不是 |
| <= | 小于等于 | ||
| = | 等于 | ||
| <> 或 != | 不等于 | ||
| BETWEEN…AND… | 在某个区间内,包含两端 | ||
| IN(…) | 在 in 之后列表中的值 | ||
| LIKE 占位符 | 模糊匹配(_ 匹配单个字符,%匹配任意个字符) | ||
| IS NULL | 是 NULL,同样还有 IS NOT NULL |
例如,查询年龄大于等于 22 的信息:

例如,查询年龄在 18 到 28 之间的用户信息:

例如,查询年龄为 18 ,22 ,28 其中的用户信息:
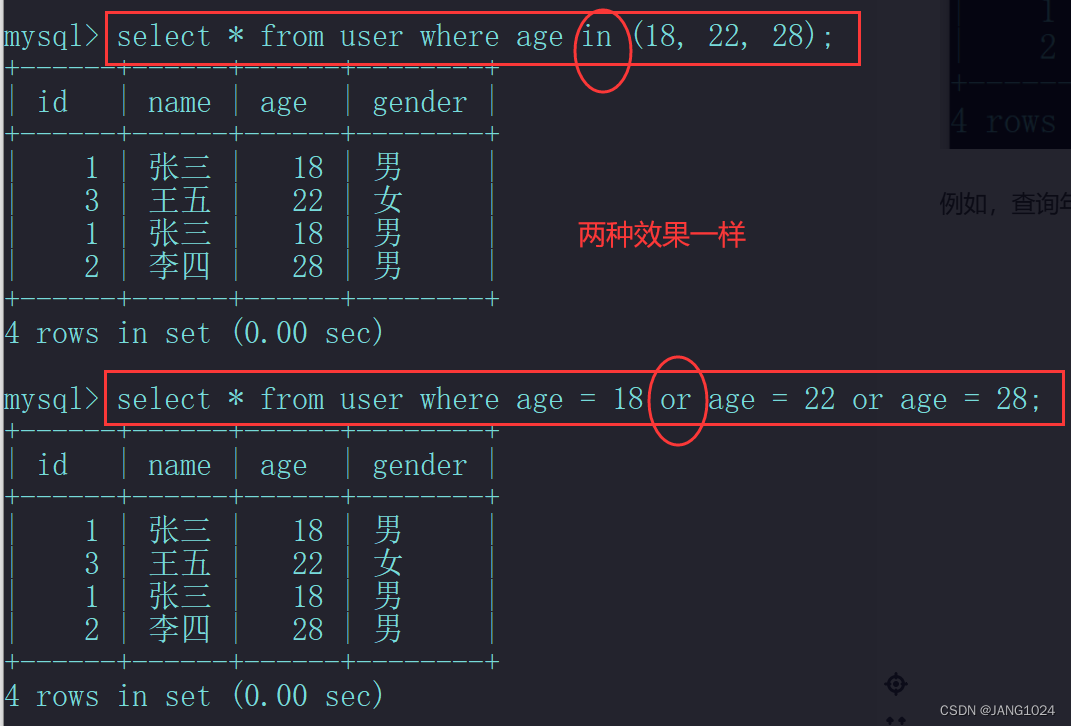
例如,查询张开头的用户信息:

例如,查询名字中包含张字的用户信息:

% 代表0个和多个字符,_ 代表一个字符,同理查询第二个字为张的名字就可以使用 like “_张%”。
在讲解分组查询前,先看一下聚合函数:
聚合函数就是将一列数据作为一个整体,进行纵向计算。
注意: null 值不参与计算。
常见聚合函数:
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
语法:
SELECT 聚合函数(字段列表)FROM 表名;
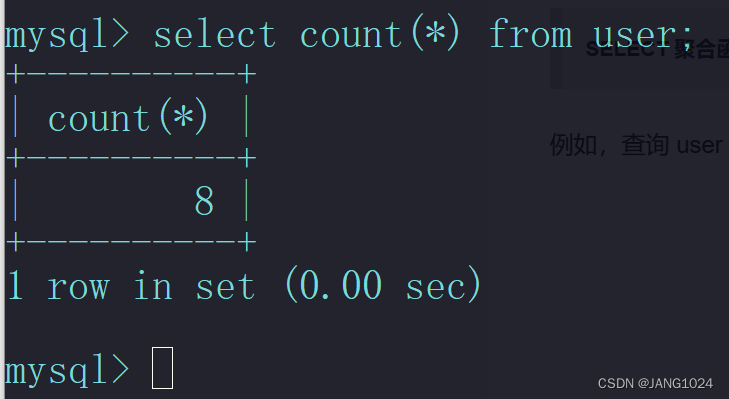
例如,查询 user 表有多少用户:
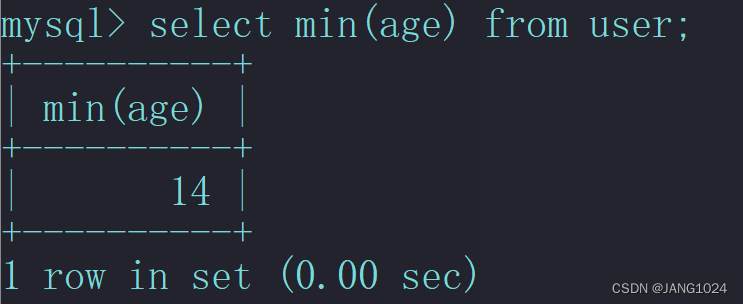
例如,查询年龄最小的用户:
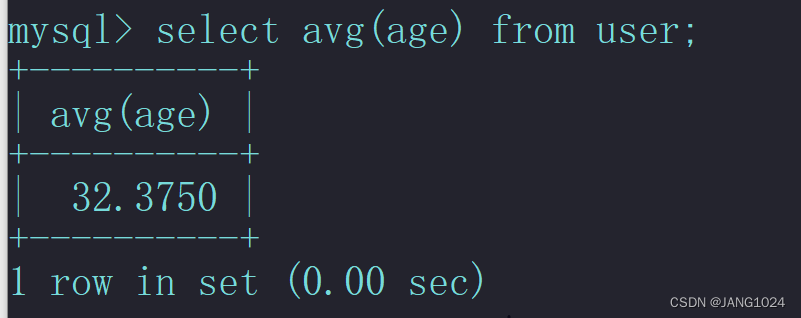
例如,统计 user 表的平均年龄:
分组查询:
格式:
SELECT 字段列表 FROM 表名 [WHERE 条件] GROUP BY 分组字段名 [HAVING 分组后过滤条件];
注意:where 与 having 区别
执行时机不同: where 是分组之前进行过滤,不满足 where 条件,不参与分组;而 having 是分组之后对结果进行过滤。
判断条件不同: where 不能对聚合函数进行判断,而 having 可以。
例如,根据性别分组,统计男用户和女用户的数量:

例如,根据性别分组,计算男用户和女用户的平均年龄:

例如,查询年龄小于 40 的用户,并根据性别分组,返回男用户或女用户 数量大于 3 :

排序查询:
SELECT 字段列表 FROM 表名 ORDER BY 字段 1 排序方式 1, 字段2 排序方式 2 …;
排序方式:
ASC:升序(默认)
DESC:降序
注意:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。
例如,根据年龄排序:
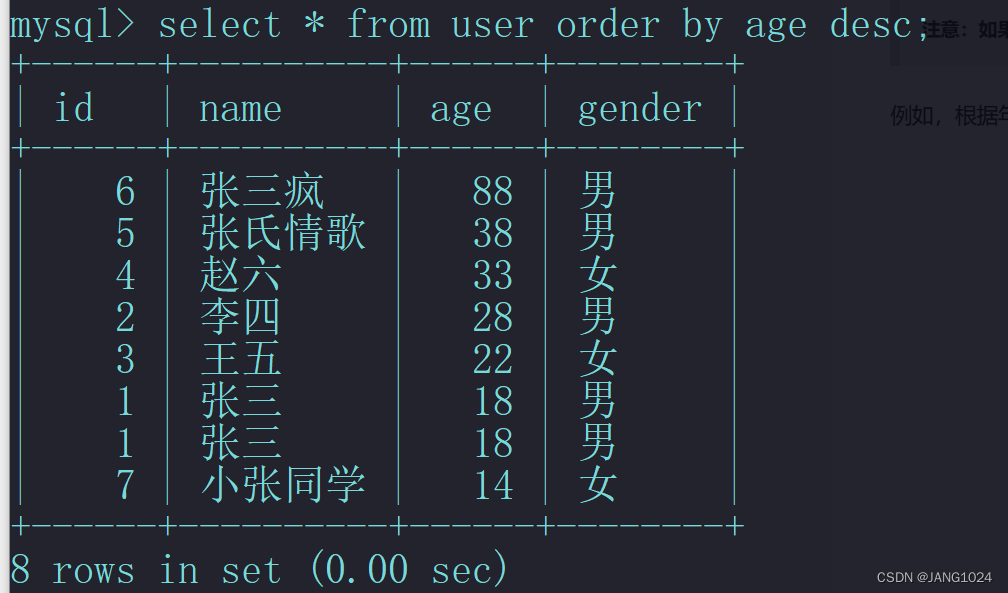
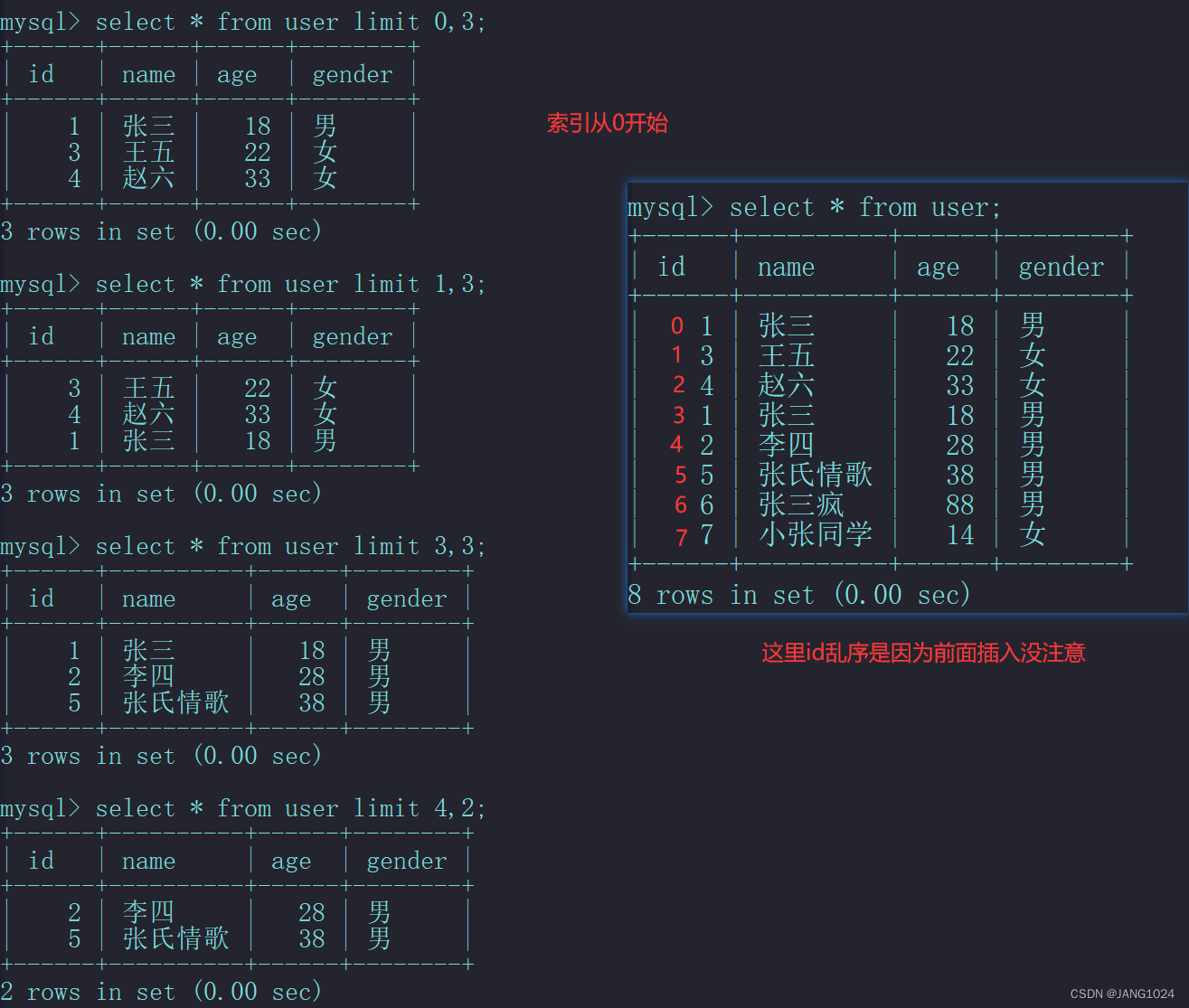
分页查询:
SELECT 字段列表 FROM 表名 LIMIT 起始索引,查询记录数;
例如: