Git分支的合并策略有哪些?Merge和Rebase有什么区别?关于Merge和Rebase的使用建议
- 1. 关于Git的一些基本原理
- 1.1 Git的工作流程原理
- 2. Git的分支合并方式浅析
- 2.1 分支是什么
- 2.2 分支的合并策略
- 2.2.1 Three-way-merge(三向合并原理)
- 2.2.2 Fast forward & Already Up-To-Date(退化)
- 2.2.3 Recursive
- 2.2.4 Octopus(复杂化)
- 2.3 分支的另外一种合并操作:Rebase
- 2.4 关于Merge和Rebase的一些讨论
- 2.4.1 Rebase的一些问题
- 2.4.2 其它相关场景举例
- 场景1:谨慎使用 force push
- 场景2:rebase解冲突
- 场景3:merge和rebase的提交历史差异
- 2.5 Merge和Rebase的对比以及使用建议
- 3. Git合并常用命令汇总整理
- merge
- rebase
- cherry-pick
参考:《Git 权威指南》、《Git团队协作》、快手git管理
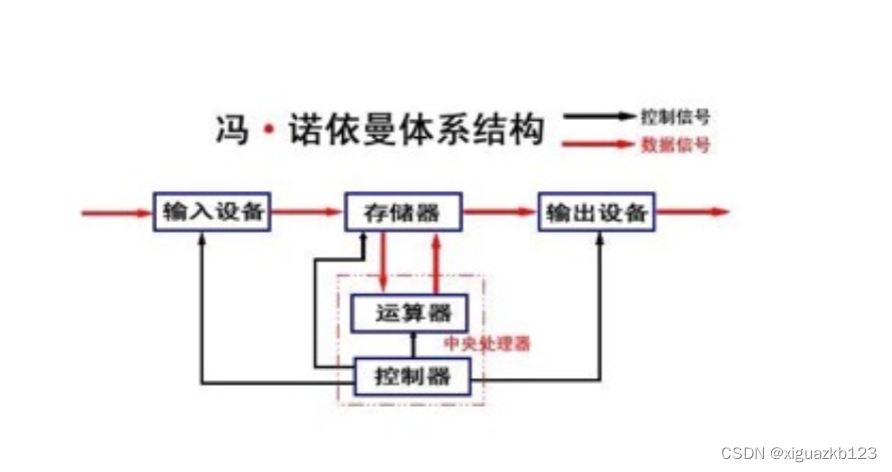
1. 关于Git的一些基本原理
1.1 Git的工作流程原理
(1)工作区域

首先来介绍介绍下Git的工作区域,分为工作区、暂存区和仓库区,每个区域的转换关系如上图所示。
-
工作区(workspace):就是我们平时本地存放项目代码的地方; -
暂存区(index/stage):用于临时存放我们的改动,事实上它只是一个文件,保存即将提交到文件列表信息; -
仓库区(Repository):就是安全存放数据的位置,里面有你提交到所有版本的数据,可分为本地仓库和远程仓库(remote),也称为版本库。
(2)文件状态

Git 中的文件可分为五种状态:
-
untrack(未追踪):未跟踪, 此文件在文件夹中, 但并没有加入到git库, 不参与版本控制。 通过git add状态变为Staged; -
unmodified(未修改):文件已经入库, 未修改, 即版本库中的文件快照内容与文件夹中完全一致。这种类型的文件有两种去处, 如果它被修改, 而变为Modified。如果使用git rm移出版本库, 则成为Untracked文件; -
modified(已修改):已修改表示修改了文件,但还没保存到数据库中; -
staged(已暂存):已暂存表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中; -
committed(已提交):已提交表示数据已经安全地保存在本地数据库中。
结合文件的五种状态和三个工作区域的对应关系,引出Git 的基本工作流程如下:
-
在工作区中修改文件A。
-
git add fileA,将更改的部分添加到暂存区。具体过程是:- 首先,它给A文件创建1个校验和添加到暂存区中。校验和可以理解为是一个文件的唯一索引,git通过
SHA-1这种哈希算法,遍历每一个文件,根据文件内容等信息,为文件创建索引,以后只要根据这个索引,我们就可以取出一个文件中的完整内容。 - 然后,git对当前的暂存区拍了一张照片,也就是我们所说的快照,并将快照放入版本库。快照里包括什么内容呢?
-
快照里包括我们刚才说的文件索引和文件完整内容(类似于key-value的结构)。同时,git采用内置的
blob对象来存储这三个文件的快照。
- 首先,它给A文件创建1个校验和添加到暂存区中。校验和可以理解为是一个文件的唯一索引,git通过
-
git commit来提交更新,找到暂存区的文件,将快照永久性存储到仓库区中。具体过程是:- 首先,git用一个内置的
tree对象,把文件的目录结构保存下来。 - 然后,git在这个tree对象上又包了一层,创建了一个
commit对象,这个commit对象也是我们说的git进行版本管理的最终对象。commit对象里包含了tree对象,还包含作者、提交评论等信息。
- 首先,git用一个内置的

(3)数据存储
以上我们了解到了Git的基本工作流程,那么Git是如何存储代码信息的?
我们知道,Git与其它版本控制系统不同的是,保存的不是文件的变化或者差异,而是一系列不同时刻的快照 。在进行提交操作时,Git 会保存一个提交对象(
commit object)。
知道了 Git 保存数据的方式,我们可以很自然的想到——该提交对象会包含一个指向暂存内容快照的指针。 但不仅仅是这样,该提交对象还包含了作者的姓名和邮箱、提交时输入的信息以及指向它的父对象的指针。 首次提交产生的提交对象没有父对象,普通提交操作产生的提交对象有一个父对象, 而由多个分支合并产生的提交对象有多个父对象。
那么上述提到的快照是什么呢?
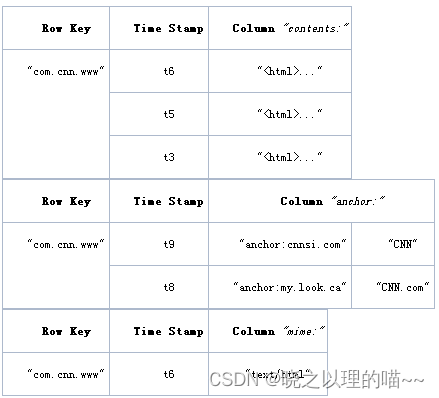
快照就是在执行git commit时,对当前暂存区的情况拍摄的一张“照片“,这个照片中涵盖的若干信息将被存放到git版本库下。若干信息指的是什么?
是文件的索引+文件的完整内容(key-value结构),文件的目录结构,和提交信息,这三者分别用git内置的blob,tree,commit对象进行存储。
blob: 在git中对应着"内容(content)", 约等于一整个文件(不包含文件名和文件mode);tree: 在git中对应着"目录(directory)", 正如每一个目录中可以存储文件或其他子目录一样, tree的每一个节点可以是一个blob, 或者另一个tree;commit: 对应着一次提交, 保存着对一个顶层树对象的引用(对应着某个路径下的一份完整的内容) , 以及提交信息(包括父commit);
我们可以通过一个目录下的文件及结构来对应得到一组git对象,下图为文件/目录与blob/tree的对应关系:

简单来说, 就是我们可以通过HEAD文件找到当前branch, 通过当前branch找到一个commit, 通过一个commit找到一个顶层目录对应的tree对象, 一个tree对象又会根据目录下的子目录和文件结构对应地指向一组tree对象和blob对象. 由此, 可以得到一个: HEAD(ref) -> branch -> commit -> tree -> tree/blob的指向图.

因此, 上面的由目录到git对象的对应关系可以被简化成:

在提交时, git会从顶部向下([He1oise 校对]还是从底部往上)观看每一个blob和tree, 然后复用那些能够复用(没有改变)的对象, 创造出一棵局部复用的树, 所谓commit就指向了这棵树.
当然, 这里我们不用去考虑说树中的一个节点为什么会有多个父节点, 因为虽然我们认为树中的节点总只有一个父节点, 但实际使用上如果我们只考虑自顶而下地观察, 我们其实只能看到这个节点是否属于某一棵树。
于是, 我们在提交过后, 获得了一个commit对象, 这个commit对象会指向其.git所在的目录为根节点的tree对象.
因此, 我们能通过一个commit对象找到一个对应的tree, 根据一个tree对象来递归地找到其子tree对象和blob对象, 因而找到当前路径下的一份完整的内容.

到这里, 我们就大概整明白了一个分支是如何对应顶层目录下的所有内容了。
更进一步地发散开, 我们已知一个commit可能有零到多个父commit, 则可以进一步了解到, 在一片commit组成的森林里, commit只是指向某一棵树的指示牌而已.
2. Git的分支合并方式浅析
2.1 分支是什么

Git 的分支,从本质上来说它仅仅是指向提交对象的可变指针。
Git 的默认分支名字是 master。 在多次提交操作之后,我们其实已经有一个指向最后那个提交对象的 master 分支。 master 分支会在每次提交时自动向前移动。下面介绍下关于Git分支的一些基本概念:
- Head指针:
- (1)指向当前所在的本地分支,我们可以看到上图中Head指向的是Master分支,说明当前是在Master分支上;
- (2)Head 指针随着提交操作自动向前移动
-
分支创建:
git branch Dev,会在当前所在的提交对象上创建一个指针。 -
分支切换:
git checkout Dev,这条命令做了两件事- (1)将Head指针移动到Dev分支上
- (2)将工作目录恢复成Dev 分支所指向的快照内容。
-
分支合并:当我们在Master和Dev分支各自提交了一次分支后,我们可以看到,提交历史已经产生了分叉,当我们想将Dev分支上的修改到Master分支上时,我们可以使用git merge来完成合并操作。
git merge可以合并一个或者多个分支到你已经检出的分支中, 然后它将当前分支指针移动到合并结果上。

2.2 分支的合并策略
我们在上一节中提到,merge操作可以将两个分支的修改整合到一起。具体来说,git会尝试通过两个分支的commit指针,分别向前追溯,找到这两个commit指针在历史上最近的一次共同提交点。Git有几种不同的方法用来寻找这个共同提交,而这些方法就是所谓的“合并策略”。默认git会帮你自动挑选合适的合并策略,也可以通过git merge -s策略名字来强指定使用的策略类型。下面我们来介绍一下最常见的几种合并策略:Fast-foward,Recursice,Octopus 等。
2.2.1 Three-way-merge(三向合并原理)
在正式介绍git的合并策略之前,我们可以先来看下这种几种策略共同会遵循的一个原理:三向合并原理(Three Way Merge),举例一个场景:假设有两个同学在各自的分支上对同一个文件进行修改,如下图:

这个时候我们需要合并两个分支成一个分支,如果我们只对这两个文件进行对比,那么在代码合并时,只知道这两个文件在第20行有差异,却不知道应该采纳谁的版本。
如果我知道这个文件的原件“base”,那么通过和“原件”代码的对比就能推算出应该采用谁的版本:

图示可以看出,B中的代码和Base一样,说明B中并没有对这行代码做修改,而A中的代码和Base不一样,说明A在Base的基础上对这行代码做了修改,那么A和B合并应该采用A中的内容。
当然还有一种情况是三个文件的代码都不相同,这就需要我们自己手动去解决冲突了:

从上面的例子可以看出采用Tree-Way-Merge(也称为三向合并)原理来合并代码有个重要前提是可以找到两份代码的“原件”,而git因为记录了文件的提交历史,再通过自身的合并策略就可以找到两个commit的公共commit是哪个,从而通过比对代码来进行合并。
2.2.2 Fast forward & Already Up-To-Date(退化)

Fast foward是最简单的一种合并策略,如图将feature分支合并到dev分支上,git只需要将dev分支的指向最后一个commit节点上。
Fast forward是git在合并两个没有分叉的分支时的默认行为,如果你想禁用掉这种行为,明确拥有一次合并的commit记录,可以使用git merge --no-ff命令来禁用掉。
2.2.3 Recursive
Recursive是git中最重要也是最常用的合并策略,简单概述为:通过算法寻找两个分支的最近公共祖先节点,再将找到的公共祖先节点作为base节点使用三向合并的策略来进行合并。
举个例子:圆圈里的字母为当前commit中的内容,当我们要合并C2,C3两个节点时,先找到他们的公共祖先节点C1,接着和节点C1的内容进行对比,因为C1的内容是A,所以C3并没有修改内容,而C2将内容改成B,所以最后的合并结果C4的内容也是B。

但是可能有更复杂的情况,出现几个分支相互交叉的情况(Criss-Cross现象),如下图所示,当我们在寻找最近公共祖先时,可以找到两个节点:节点C2和节点C3,根据不同公共祖先,可以分为两种情况:

(1)节点C3作为base节点
通过三向合并策略合并(base节点的内容是A,两个待合并分支节点的内容是B和C)我们是无法得出应该使用哪个节点内容的,需要自己手动解决冲突。
(2)节点C2作为base节点
通过三向合并策略合并(base节点的内容是B,两个待合并分支节点的内容是B和C)可以得出应该使用C来作为最终结果。

通过上述分析,我们可以得知正确的合并结果应该是C,那么git要如何保证自己能找到正确的base节点,尽可能的减少代码的合并冲突呢?
实际上git在合并时,如果查找发现满足条件的祖先节点不唯一,那么git会首先合并满足条件的祖先节点们,将合并完的结果作为一个虚拟的base节点来参与接下来的合并。
如上图所示:git会首先合并节点C2和节点C3,找到他们的公共祖先节点C1,在通过三项合并策略得到一个虚拟的节点C23,内容是B,再将节点C23作为base节点,和节点C5,节点C6合并,比较完后得出最终版本的内容应该是C。
2.2.4 Octopus(复杂化)
Octopus 策略可以让我们优雅的合并多个分支。
前面我们介绍的策略都是针对两个分支的,如果现在有多个分支需要合并,使用Recursive策略进行两两合并会产生大量的合并记录:每合并其中两个分支就会产生一个新的记录,过多的合并提交出现在提交历史里会成为一种“杂音“,对提交历史造成不必要的”污染“。
Octopus在合并多个分支时只会生成一个合并记录,这也是git合并多个分支的默认策略。如下图:在dev分支下执行git merge feature1 feature2。

2.3 分支的另外一种合并操作:Rebase
(1)场景举例
我们举一个实际应用的例子来引出Rebase操作,设想两种场景:
-
多人共用一个分支开发,且本地分支落后远程分支,需更新
-
一个分支单人开发,且当前研发分支落后于主干分支,需更新

其实,上述两种情况都可抽象为上图所示,由第一种情况来举例,
假如有多人在同一个分支上开发,C1、C2为远端分支的提交,C3、C4为我们在本地仓库的提交还没有推送到远端,如果这个时候另外一个同学将他的提交记录C5推送到了远端,这时,我们再想把我们的本地的提交推送到远端时,就需求有一个更新远程仓库并且合并本地分支的操作,目的是将其它同学提交记录也保留下来。那么如何更新呢?
有两种办法:
git pullgit pull --rebase
我们可以先来看下这两种操作所带来的结果:

其中,左图为git pull的操作后的提交历史,我们可以看到在本地分支多了一次合并记录C6,这是由于git pull 等同于 git fetch + git merge操作,先从远端拉取分支,接着再执行合并操作(如有冲突需解除冲突),因此增加了一次提交记录C6;
右图为执行git pull --rebase操作,可以看到我们本地的提交直接变基到了C5后面,而且没有增加提交记录,呈现出一条直线,这是因为git pull --rebase这个操作其实可以拆分为fetch+rebase操作,先从远端同步分支,接着再执行rebase操作。
所以说这两个命令其实差别是在拉取分支后是执行了merge操作,还是rebase操作。
(2)Rebase原理
我们可以看到,经过merge更新操作远程此时也变成了非直线形式,且有多了一次merge记录,而rebase更新操作此时变成了一条直线形式,且没有增加提交记录。目前可以总结下,rebase有以下特点:
-
rebase之后会改变提交历史记录,分支不再岔开,而是变成了一条直线;
-
rebase 之后如果有冲突,解冲突时需把每次的commit都解一遍;
-
rebase之后没有保留merge记录,意味着没有保存这步的操作,而git的意义不就是保存记录吗?

为什么采用rebase方式来完成合并操作会有merge有这么多的不同呢?
其实所谓的变基(rebase), 指的就是将提交到某一分支的所有修改在另一分支上再应用一次, 也就是想修改移动到另一个分支上. 看上去就好像是其base commit发生了变化。我们可以从git源码上得知,rebase就是调用了多次merge。
我们可以从一个例子上直观表示一下rebase每一步都做了什么,如下图所示:在feature上rebase dev时,git会以dev分支对应的commit节点作为起点,将feature上commit节点”变基“至dev commit的后面,并且会创建全新的commit节点来替代之前commit,实际上rebase操作可以拆分成一系列的merge操作,
现在我们看一下rebase的过程中git所做的事情:
首先我们需要以C1作为base节点,C2和C4进行合并生成新的C5,然后再将C5的parent指向C4。C3到C6转变进行了同样的步骤。
因为相比较之前的commit,新的commit的parent变了,对应的hash值自然也变了。
因此我们在rebase的时候,当前分支有几个commit记录那么git就需要进行合并几次。
如果当前分支比较”干净“,只有一个commit记录的话,那么你rebase需要解的冲突其实和merge是一样的,区别就是rebase不会单独生成一个新的commit来记录这次合并。

2.4 关于Merge和Rebase的一些讨论
2.4.1 Rebase的一些问题
Rebase会修改历史记录
大家可能都看过git文档(pro-git)里的经典戒律: Do not rebase commits that exist outside your repository and that people may have based work on. 如果在你的repo外, 有人基于你的某些commit在开发, 那么你就不应该对这些commit做rebase.
文档里说得很严重, 如果你不遵守这条准则, 或者说是戒律, 你会被人民仇恨, 会被亲友唾弃。之所以整这么严重, 是因为rebase操作的实质是丢弃一些既有的提交, 然后相应地新建一系列变更内容相同但不一样的commit对象。
如果这个提交在rebase前被推到了远端共享, 而且其他人也在基于它做开发, 那么当他们试图提交的时候, 就得做所谓的remerge了。不论是merge还是rebase, 合并行为都会发生, 并导致有端点(commit)被提交. 只不过在rebase中, 合并发生在被依次应用每个差量, 伴随着在一个分支中创建来自另一个分支的变更的线性历史而完成. 而普通的三路合并则仅仅修改端点本身。
Rebase可能会导致一系列错误的提交
rebase除了修改历史记录之外, 还有更深远的效果: rebase会导致一系列新的提交. 虽然这些提交组合起来, 最后会达到相同的最终状态, 但中间的提交有新的SHA-1, 基于新的初始状态, 代表不同的差异。
因此, 相较于merge, rebase的典型问题是: 它事实上被视为"将源分支上的所有修改逐项地应用到目标分支上“, 就之前提到的: " 两种整合方法在分支的最终结果上文件内容与结构上毫无区别”, 但也仅此而已——这些因为逐项应用产生的新提交对应的版本在现实里从来没有存在过, 没有人真正生产了这些提交, 也没有人能证明它们是可行的。

我们看一个例子:在commit2中定义了一个函数, 接受数字或字符串类型. 在commit4中调用了这个函数, 传入了一个数字. 紧接着由于函数func维护的同学通知说从commit3以后不兼容数字形式了, 需要依赖方做修改(page/page2).
因此, 在commit5中, 我们添加上了对类型的修正. 这个时候去rebase代码, 将commit4和commit5迁移成commit4’和commit5’, 这个时候, commit5’是完全正确且安全的, 但是如果我们commit5里有错误, 希望回退到commit4’去, 问题就大条了. 因为commit4’事实上没有任何人测试过, 也不是开发者特意上传的内容. 而且可以看见, 在这个例子里, 是完全通不过类型系统的检查的。

2.4.2 其它相关场景举例
我们曾经在团队内部做了一个关于merge和rebase合理使用的调查问卷, 有一个建议是希望能够从二者的原理出发, case by case来分析场景和规避途径,下面列出了一些同事们在实际开发中遇到的一些问题场景:
场景1:谨慎使用 force push
首先来分享下团队内部曾经在git上踩过的坑:

如上图所示,A同学和B同学共用一个研发分支,B同学已经提交了两次commit并推送到了远端。
之后,A同学也已经开发完成,我们可以看到A同学的本地仓库分支已经落后于远端,理应先从远端更新分支,再推送到远端。
但是A同学没有这么做,如下图所示,而是直接force push了上去,就导致了下面这种情况,B同学的C3、C4提交记录被“丢弃”掉了。

此时的补救的方法可以是:B同学更新远端分支(git pull 或 git pull --rebase),再提交上去,提交历史变为下图:

那么应该如何避免这个问题呢:
-
提交代码时谨慎使用force push,建议使用
push(原因:如果我们使用push推送时,本地分支落后远端时会有提示) -
正确提交方法:先更新本地分支,再推送到远端。我们如何更新本地分支:两种方法
merge或rebase,下面是两种命令更新后的分支示意图

我们可以看到,采用merge更新的方式,多了一条合并记录C6,而rebase则是直接把记录从C5变更到了C4’提交的后面且没有多一次的提交记录。

场景2:rebase解冲突
我们知道,在采用rebase方式更新代码时,如果有冲突,解冲突时需把每次的commit都解一遍。
我们设想这样一种场景,feature分支上共有三次提交,我们在解决冲突1和冲突2时如果包含了第三次提交的全部变动内容,我们在推代码后会神奇的发现C5记录不见了,这是因为rebase合并的实质是丢弃掉原有的提交,而另创建与原提交记录“相似”的提交,通过上述方式解冲突后,新的C5’已经没有任何新的改动,所以C5会被“丢弃掉”。

场景3:merge和rebase的提交历史差异

我们可以直观看到,经过rebase更新操作提交历史变成了一条直线形式,而经过merge更新操作远程的提交历史为非直线形式,且因为更新(而不是合并)多了一次merge记录。但是rebase也有很多缺点:
-
rebase 之后 如果有冲突 解冲突时需把每次的commit都解一遍。
-
rebase之后没有保留merge记录,意味着没有保存这步的操作,而git的意义不就是保存记录吗?
但是如果我们换一种思路考虑,我们在本地分支中使用 rebase 来更新,是为了让我们的本地提交记录更加清晰可读。(当然, rebase 不只用来合并 master 的改动,还可以在协同开发时 rebase 队友的改动)而主分支中使用 merge 来把 feature 分支的改动合并进来,是为了保留分支信息。
那么如何合适的使用rebase和merge呢?
-
假如全使用 merge 就会导致提交历史繁复交叉,错综复杂。
-
如果全使用 rebase 就会让你的commits history变成一条光秃秃的直线。
因此,一个好的commits history,应该是这样的,有合并记录且分支不交错:
* e2e6451 (HEAD -> master) feture-c finished
|\
| * 516fc18 C.2
| * 09112f5 C.1
|/
* c6667ab feture-a finished
|\
| * e64c4b6 A.2
| * 6058323 A.1
|/
* 2b24281 feture-b finished
而不应该是这样的,分支交错,看起来很混乱:
* 9f0c13b (HEAD -> master) feture-c finished
|\
| * 55be61c C.2
| * e18b5c5 merge master
| |\
| |/
|/|
* | ee549c2 feture-a finished
|\ \
| * | 51f2126 A.3
| * | 72118e2 merge master
| |\ \
| |/ /
|/| |
* | | 6cb16a0 feture-b finished
|\ \ \
| * | | 7b27b77 B.3
| * | | 3aac8a2 B.2
| * | | 2259a21 B.1
|/ / /
| * | 785fab7 A.2
| * | 2b2b664 A.1
|/ /
| * bf9e77f C.1
|/
* 188abf9 init
也不应该是这样的,完全呈一条直线,没有任何的合并记录:
* b8902ed (HEAD -> master) C.2
* a4d4e33 C.1
* 7e63b80 A.3
* 760224c A.2
* 84b2500 A.1
* cb4c4cb B.3
* 2ea8f0d B.2
* df97f39 B.1
* 838f514 init
2.5 Merge和Rebase的对比以及使用建议
我们通过上述例子得知,rebase和 merge 不是二选一的关系,要协同使用。
当开发只属于自己的分支时尽量使用rebase,减少无用的commit合到主分支里,多人合作时尽量使用merge,一方面减少冲突,另一个方面也让每个人的提交有迹可循。按照上述思路来说,我们按照如下规则可以合理使用rebase和merge操作:
-
如果我们只注重于更新操作时,rebase操作可能会更好些,因为没必要多生成一个除了开发外的merge记录,也可以让我们的本地提交记录清晰可读。
-
当我们要把研发分支合入到主干时,我们更注重的是合并的操作,保留合并的记录,这个时候用merge会好些。

3. Git合并常用命令汇总整理
假设当前在feature分支,公共开发分支为feature,示意图如下:

merge
# feature分支与dev分支合并
git merge dev
# 禁用自动提交
git merge --no-commit dev
# 禁用快进合并(保留merge记录)
git merge --no-ff dev
# 将dev分支的commit压缩成一个再合并
git merge --squash dev
# 指定合并策略(如ours、subtree,默认为recursive和octopus)
git merge -s <strategy> dev
# 显示详细的合并结果信息
git merge -v dev
# 显示合并的进度信息(不显示--no-progress)
git merge -progress dev
# 创建合并节点时的提交信息
git merge -m "" dev
# 合并冲突
git merge --continue
# 抛弃当前合并冲突的处理过程并尝试重建合并前的状态
git merge --abort
rebase
# 将feature分支变基到dev分支上
git rebase dev
# 交互式修改或合并commit记录,详细使用可见https://www.jianshu.com/p/4a8f4af4e803
git rebase -i [startpoint] [endpoint]
# 拉取远程分支后采用rebase方式合并代码
git pull --rebase
# 合并冲突
git rebase --continue
# 将feature分支从feature0分支变基到到master
git rebase --onto master feature0
# 放弃此次rebase
git rebase --abort
cherry-pick
# 把其他分支的某一个commit合入到当前分支
git cherry-pick <commit id>
# 合并中有冲突,解决完后需要执行下面命令
git cherry-pick --continue