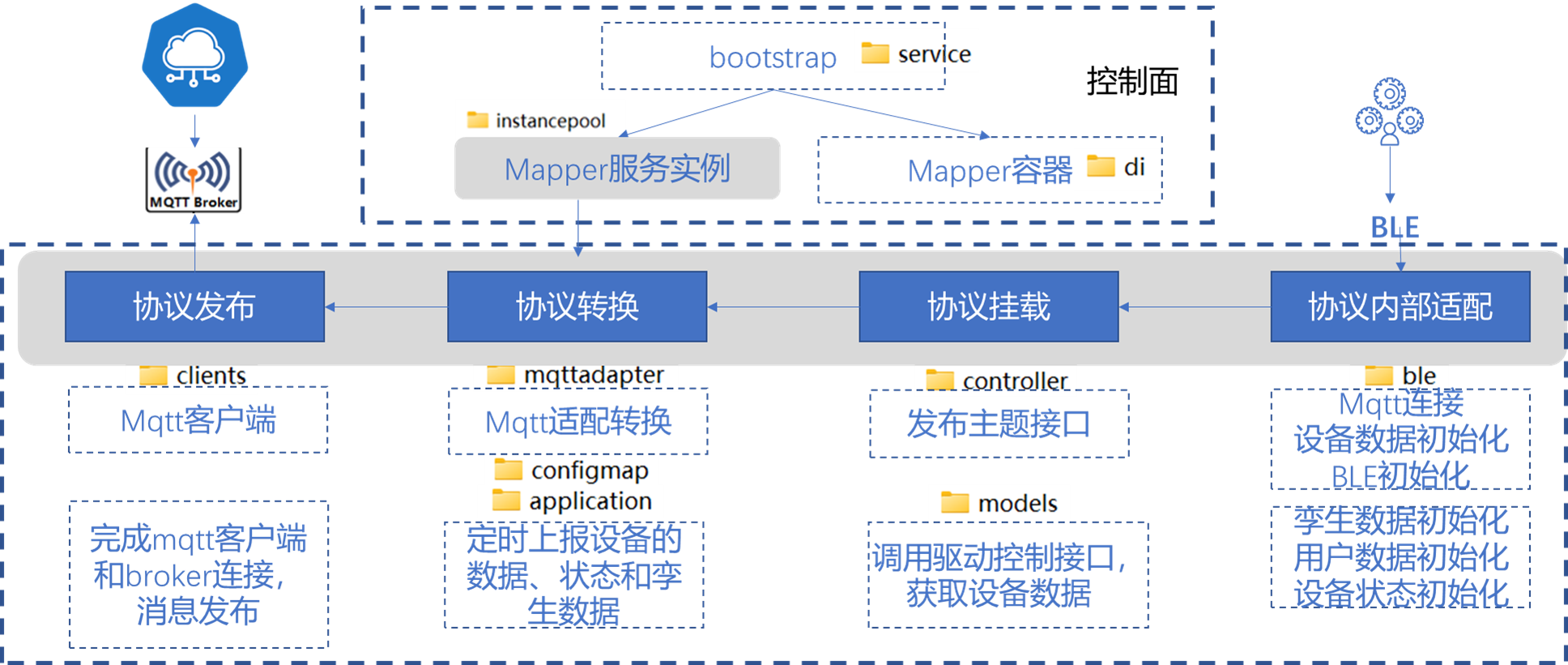
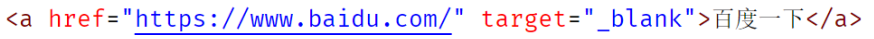关于Redis中的list类型
Redis中的list是一种先进后出、后进先出的栈结构的数据。

在使用Redis时,应该将list想像为以上图例中翻转了90度的样子,例如:
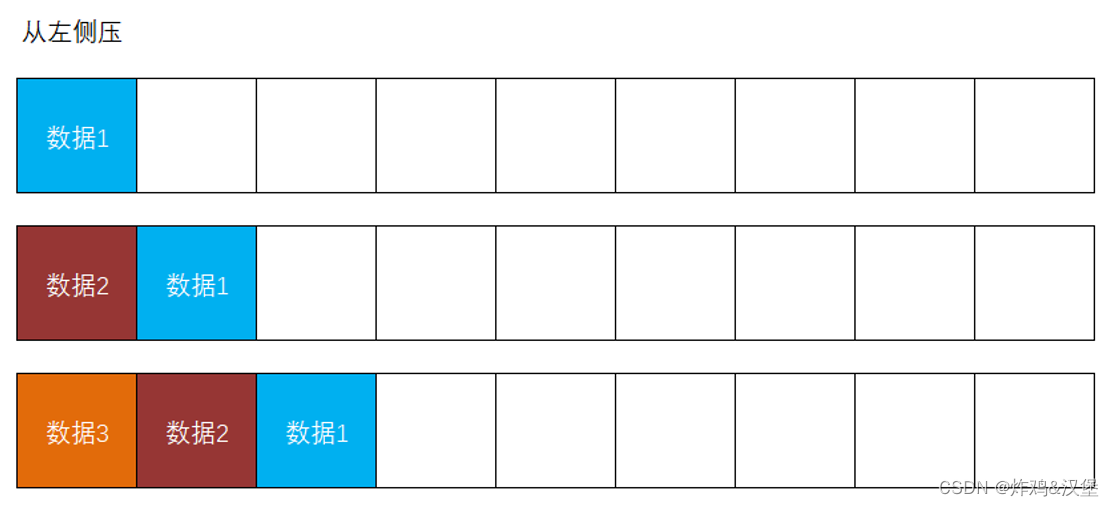
在Redis中的list数据,不仅可以从左侧压入,也可以选择从右侧压入,例如:
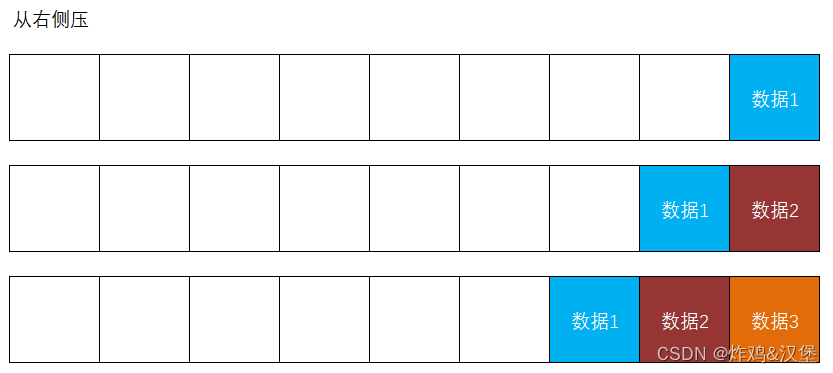
在Redis中的list数据,每个元素都有2个下标值,如下图所示:

如果需要获取list中的全部元素,通常从0开始,直至-1即可。
关于Redis中的数据的Key
根据《阿里巴巴Java开发手册》,各Key必须声明为常量,所以,应该在接口中定义Key值。
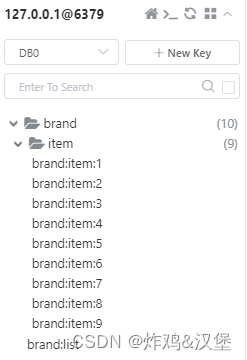
由于Redis的定位是用于缓存海量的数据,为了有效的管理各个Key,强烈建议使用多个单词组成各个Key,例如“品牌列表”的Key应该由“品牌”和“列表”这2个词对应的英语单词组成,且强烈建议各单词之间使用冒号进行分隔,在许多可视化工具中,会默认(通常可配置)使用冒号来分隔并形成文件夹的显示效果,例如:
public interface IBrandRedisRepository {
/**
* 品牌数据在缓存中的Key的前缀
*/
String BRAND_ITEM_KEY_PREFIX = "brand:item:";
/**
* 品牌列表数据在缓存中的Key
*/
String BRAND_LIST_KEY = "brand:list";
// 暂不关心其它代码
}
在Another Redis Desktop Manager中的显示效果:
缓存预热
当服务器端启动时,就读取MySQL数据库,并将相关数据写入到Redis中,使得“启动完成时,Redis中就已经存入了需要缓存的数据”,这种做法称之为“缓存预热”。
在Spring Boot中,可以自定义组件类,实现ApplicationRunner接口,此接口中有run()方法,此方法会在项目启动成功后的第一时间自动执行!
在项目的根包下创建preload.CachePreload类,用于处理缓存预热:
@Slf4j
@Component
public class CachePreload implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) throws Exception {
log.debug("开始执行CachePreload.run()");
}
}
启动项目,可以看到run()方法在启动项目之后自动执行了:

使用缓存导致的数据一致性问题
当使用缓存后,在关系型数据库(例如MySQL)中存有数据,在缓存(例如Redis)中也存在数据,这2处的数据可能是不一致的(例如修改了MySQL中的数据,但是没有同时修改Redis中的数据),那么,则存在数据一致性问题,可能需要保证这2处的数据一致!
**注意:**如果需要保持数据一致,当数据发生变化,向MySQL或Redis中写入数据时,还必须向Redis或MySQL中也写入数据,即2个数据库必须同时写入!同时写入也会带来许多问题,例如,消耗服务器端的资源,事务相关问题。
**注意:**并不是所有数据都必须时刻保持一致!例如:热门话题的阅读量。
**注意:**通常,绝大部分数据只需要在某段时间内保持数据一致即可,并不需要时刻保持一致性。某些特殊场景中的重要数据才需要始终保持数据的一致性!
计划任务
计划任务:周期性的,在满足某条件(例如到了某个时间点)执行某个任务。
在Spring Boot中,要执行计划任务,首先,需要在配置类上使用@EnableScheduling注解开启计划任务。
在项目的根包下创建config.ScheduleConfiguration类,以开启计划任务:
package cn.tedu.csmall.product.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableScheduling;
/**
* 计划任务配置类
*
* @author java@tedu.cn
* @version 0.0.1
*/
@Slf4j
@Configuration
@EnableScheduling
public class ScheduleConfiguration {
public ScheduleConfiguration() {
log.debug("创建配置类对象:ScheduleConfiguration");
}
}
然后,自定义组件类,作为计划任务类,然后,在类中自定义计划任务方法,并在方法上通过@Scheduled注解配置计划任务参数。
在项目的根包下创建schedule.CacheSchedule类,在类上添加@Component注解,在类中定义方法作为计划任务方法:
@Slf4j
@Component
public class CacheSchedule {
@Autowired
private IBrandService brandService;
public CacheSchedule() {
log.debug("创建计划任务类对象:CacheSchedule");
}
// fixedRate:执行计划任务的间隔时间,以毫秒为单位
@Scheduled(fixedRate = 5000)
public void xxxxx() {
log.debug("开始执行计划任务……");
// brandService.rebuildCache();
}
}
关于Mybatis中的#{}和${}这2种格式的占位符
以AdminMapper.xml中的getStandardById()对应的查询为例:
<select id="getStandardById" resultMap="StandardResultMap">
SELECT
<include refid="StandardQueryFields"/>
FROM
ams_admin
WHERE
id=#{id}
</select>
以上占位符使用#{id}或${id}最终的执行结果是完全相同的!
而getLoginInfoByUsername()对应的查询:
<select id="getLoginInfoByUsername" resultMap="LoginInfoResultMap">
SELECT
<include refid="LoginInfoQueryFields"/>
FROM
ams_admin
LEFT JOIN ams_admin_role ON ams_admin.id=ams_admin_role.admin_id
LEFT JOIN ams_role_permission ON ams_admin_role.role_id=ams_role_permission.role_id
LEFT JOIN ams_permission ON ams_role_permission.permission_id=ams_permission.id
WHERE
username=#{username}
</select>
以上配置中,使用#{username}可以正常查询,如果换成${username}则会出现异常:
Cause: java.sql.SQLSyntaxErrorException: Unknown column 'root' in 'where clause'
提示:以上错误信息中的root是测试执行时传入的参数。
当使用${username}作为占位符时,需要使用一对单引号将${username}框住,即:
where username='${username}'
或者,传入的字符串需要使用单引号框,例如:
@Test
void getLoginInfoByUsername() {
String username = "'root'"; // 使用一对单引号框住字符串值
Object queryResult = mapper.getLoginInfoByUsername(username);
log.debug("根据用户名【{}】查询数据详情完成,查询结果:{}", username, queryResult);
}
出现这样的问题,原因在于:在SQL语句中,除了关键字(例如SELECT)、数值、布尔值、标点符号以外的内容,除非是在特定语法格式中表现的(例如数据表名称可能出现的位置就非常固定),否则,其它所有未被单引号框住的,都会被视为“字段名”!
或者说,在SQL语句中,所有值都应该使用一对单引号框住,否则,就会被当成字段名,但是,由于字段名不可能是纯数字,而布尔值的true和false都是关键字,不可能被误认为字段名,所以,数值和布尔值可以不添加一对单引号!
在使用#{}格式的占位符时,无论是哪种类型的值,都不必考虑添加一对单引号的问题,是因为使用#{}格式的占位符时,SQL语句会被“预编译”的机制进行处理,而编译与执行的流程顺序是:词法分析、语义分析、编译、执行,在“预编译”的机制中,是会先编译,再将值代入到编译中执行!例如以下代码:
select * from user where username=?
在编译时,并不确定在where条件中username的值是多少,但是,即便不知道具体值,也不影响词法分析、语义分析!当经过编译后,以上语句中的?部分肯定只能是某个值,不可能是字段名,所以,在使用了“预编译”的机制中,传入的值不必考虑数据类型的问题,也就是说,即使传入字符串值,此值也不需要使用一对单引号框住。
基于以上特性,使用“预编译”的机制,也完全不存在“SQL注入”的风险!
在使用${}格式的占位符时,是先将值入代入到SQL语句中,再进行编译、执行,所以,非数值、非布尔值必须添加一对单引号,同时,存在SQL注入的风险!