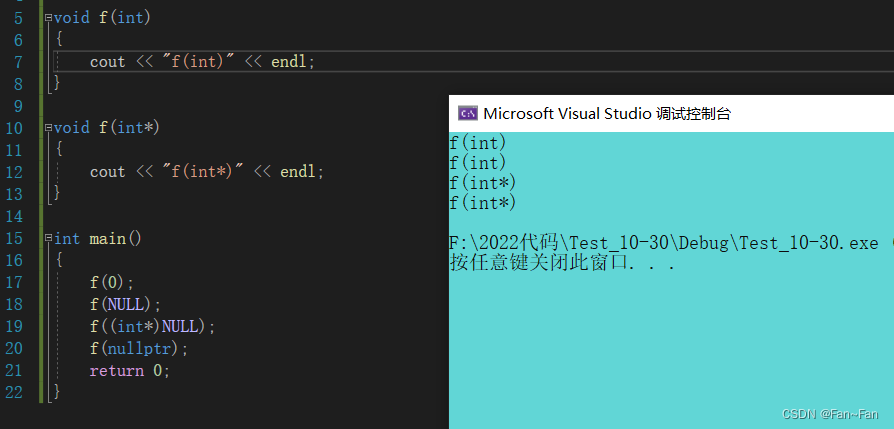
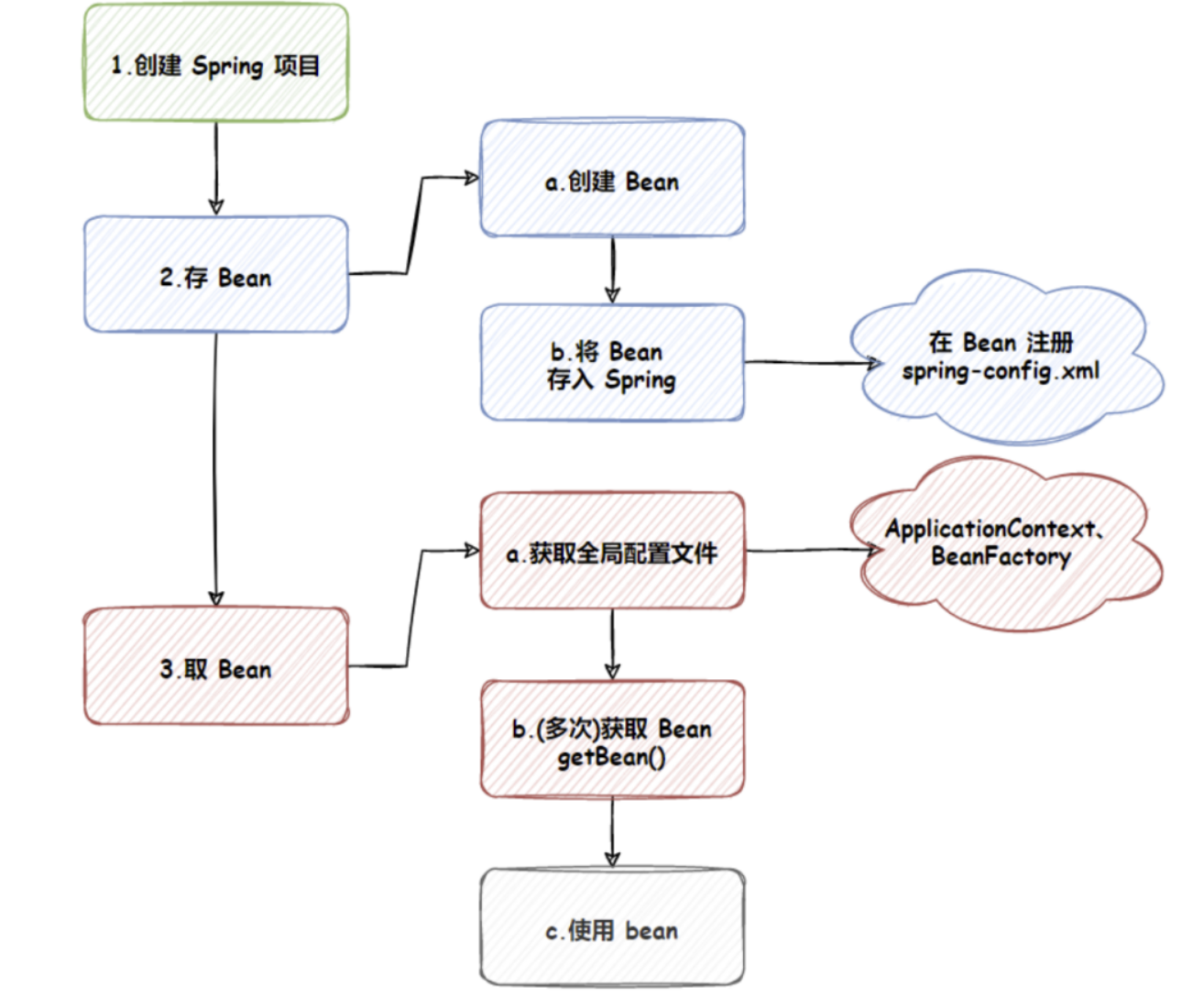
一、深度学习的经典算法
- two-stage(两阶段):RCNN
- one-stage(一阶段):YOLO,SSD(这个好像很牛)
one-stage: 将图片输入到CNN里,经过特征提取,输出4个值,得到框的x1,y1,x2,y2,即为一个回归任务。即一个CNN网络提取特征做一个回归任务,中间不需要加任何的额外的补充。
two-stage: 多加了一个网络,叫做区域建议网络RPN,多了一些预选框,先经过预选,再得到最终结果。结果会更好一点。
优缺点:
- one-stage:
- 速度快,适合做实时检测任务(视频)
- 效果不太好
- 明确任务:速度快,要做视频检测任务
- 自己选择特征提取网络,简单复杂自己决定
- two-stage:
- 速度慢,5FPS
- 效果好

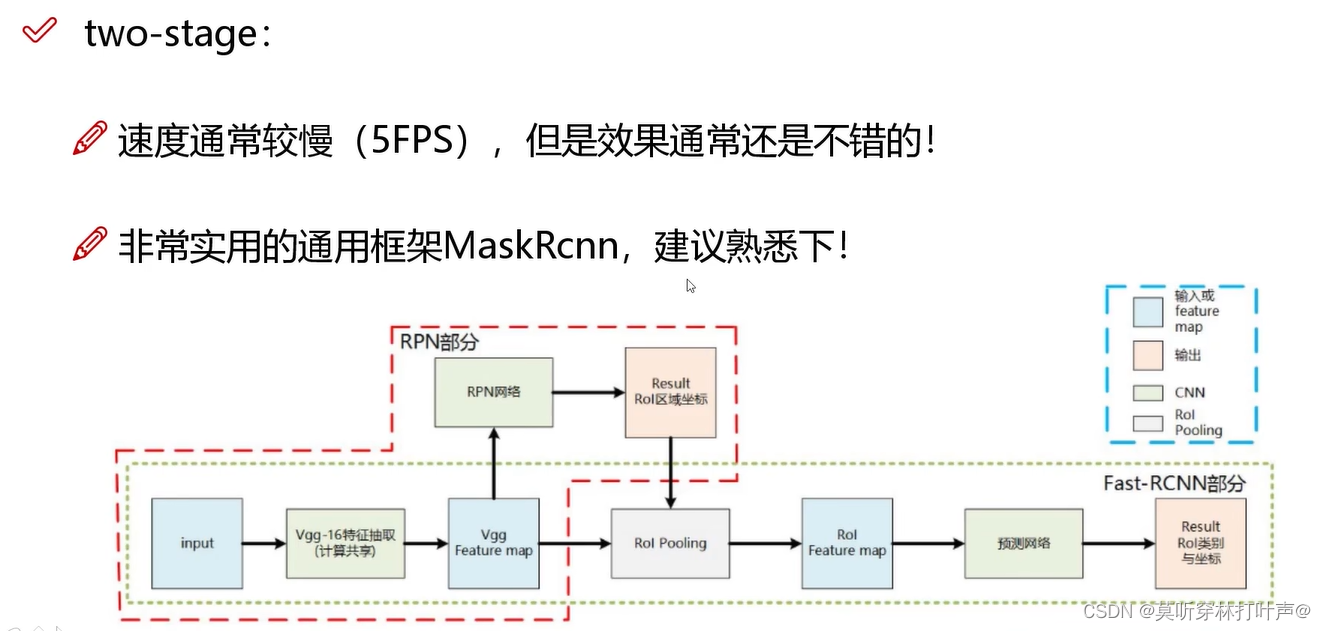
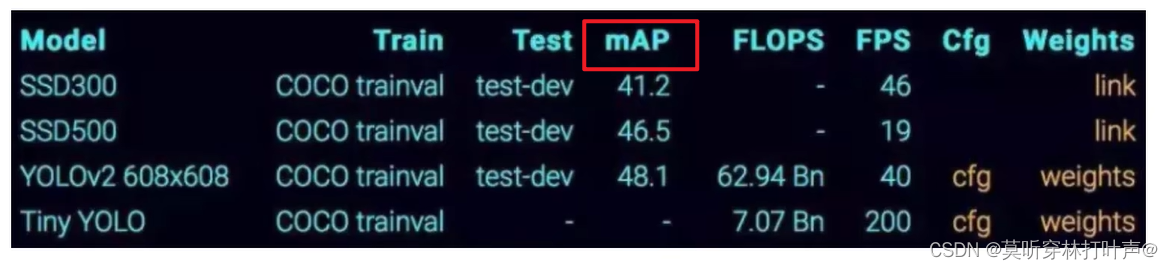
目标检测的衡量指标:
- FPS:快OR慢
- mAP:衡量指标,越大越好,越接近1越好
二、目标检测用的衡量指标
YOLO系列一直在改进,改进有两个点:
- MAP值更高
- 速度更快

MAP值
map指标:综合衡量检测效果,单看精度和recall不行。
IOU:是Ground truth真实值和Prediction预测值交集和并集的一个比值。越高越好,代表越重合
精度:希望真实值和预测值越吻合越好。
recall:希望把真实值都检测到了。
精度和召回率

在目标检测中,精度和召回率代表什么?
- 精度:希望预测的框和真实的框越接近越好
- 召回率:希望没检测到的框越少越好(漏检)
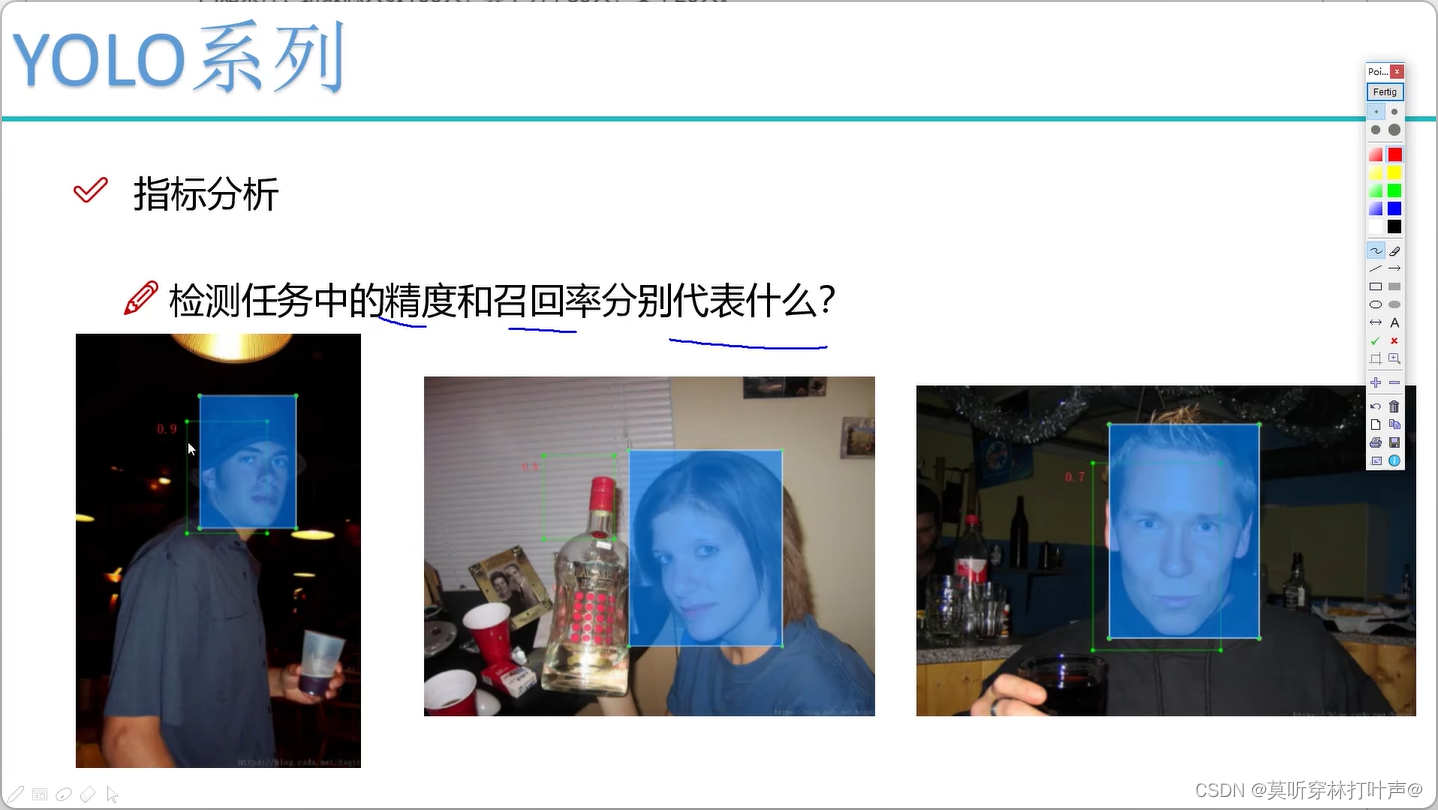
- 置信度:在预测时,会有很多重叠的框,每个框上都有一个值。需要指定一个阈值,低于阈值的框会被舍弃掉。
- 设置阈值为0.9
设置阈值为0.9,计算下面三张图的Precision和recall。
0.9的时候,只有第一张图预测的框保留下来了,TP为真正类(是人脸,并且检测到了),即为1;FP为假正类(预测错了,错误的把背景判断成人脸了),为0;FN为假负类(预测错了,把人脸预测成背景了,漏检了!),为2。
Precision=1/1
Recall=1/3

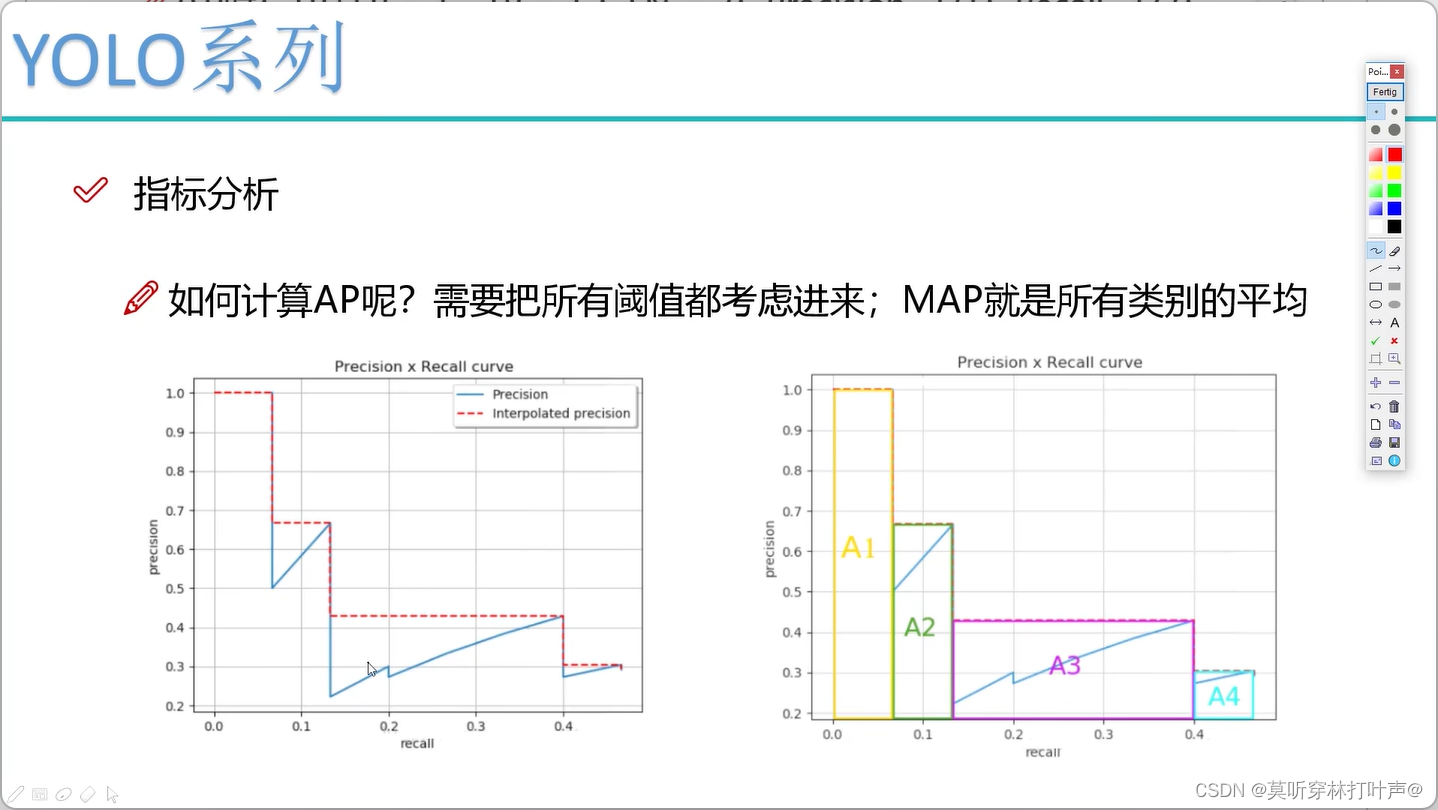
- 然后计算每个阈值的精度和召回率,比如计算0-1之间的的P和R
- 构建一个P-R图,横轴为召回率,纵轴为精度
- 把所有的阈值都考虑进来,MAP值即为,将这张图画出来,下方所围成的这张图的面积,取最大值下方的面积。面积代表MAP值是多少,希望MAP值越大越好,越接近1越好。