文章目录
- 1.进程间通信基础
- 2.管道
- 2.1匿名管道
- 2.1.1匿名管道的原理
- 2.2匿名管道的特点
- 2.3匿名管道函数
- 2.3.1用例
- 2.3.2实现ps -ajx | grep bash指令
- 2.4匿名管道的特点
- 2.5管道的大小
- 2.6管道的生命周期
- 2.7进程池
- 3.命名管道FIFO
- 3.1命名管道的接口
- 3.2命名管道和匿名管道的区别
- 3.3用FIFO实现server&cilent间通信
- 4.System V进程间通信
- 5.System V共享内存
- 5.1共享内存的原理
- 5.2共享内存接口
- 5.2.1创建共享内存
- 5.2.2共享内存数据结构
- 5.2.3key的获取
- 5.2.4获取IPC资源
- 5.2.5操作共享内存
- 5.2.6挂载共享内存
- 5.2.7共享内存的使用
- 6.System V消息队列
- 6.1消息队列原理
- 6.2消息队列接口
- 6.2.1创建消息队列
- 6.2.2控制消息队列
- 6.2.3添加到消息队列
- 6.2.4消息队列接收函数
- 6.3示例
- 7.System V信号量
- 7.1信号量的数据结构
- 7.2信息量的接口
- 7.3信号量的原理
- 8.IPC资源管理
- 9.mmap共享映射区
- 9.1mmap使用实例
- 9.2mmap常见的问题
- 9.3mmap实现父子进程通信
- 9.4匿名映射
- 9.5mmap实现无血缘关系的进程通信
1.进程间通信基础
为什么需要进程间通信?
进程是一个独立的资源分配单元,不同的进程之间资源是独立的。没有关联,不能在一个进程中直接访问另一个进程的资源。
但是进程不是孤立的,不同的进程需要进行信息交互和状态的传递,因此需要进程间通信。
进程间通信简称IPC(Interprocess communication),进程间通信就是在不同进程之间传播或交换信息。
进程间通信的目的:
-
数据传输:一个进程需要将它的数据发送给另一个进程
-
资源共享:多个进程之间共享同样的资源
-
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
-
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程
希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
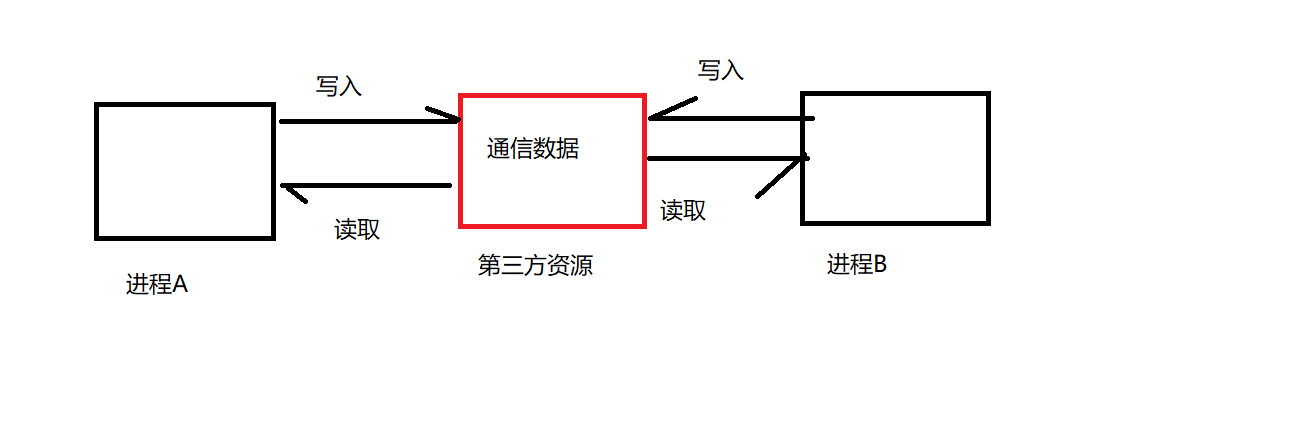
进程间通信的本质:
进程间通信的本质是:让不同的进程看到同一份资源
各个进程之间若想实现通信,需要借助第三方资源。
这些进程就可以通过向这个第三方资源写入或是读取数据,进而实现进程之间的通信,这个第三方资源实际上就是操作系统提供的一段内存区域。
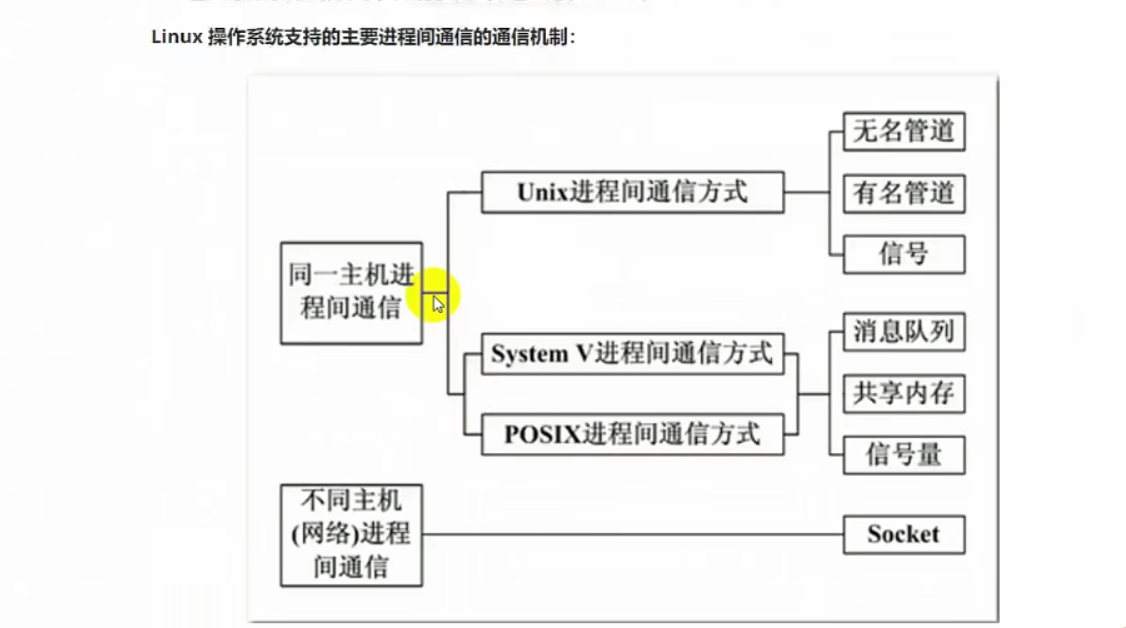
进程间通信的分类
2.管道
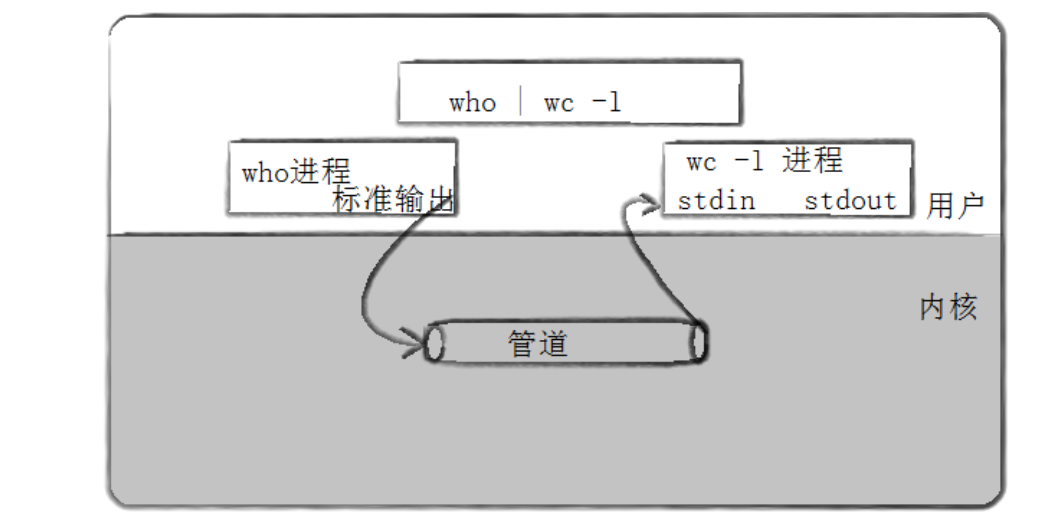
管道是Unix中最古老的进程间通信的形式 。我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”
2.1匿名管道
匿名管道用于有血缘关系的进程间通信。
2.1.1匿名管道的原理
- 子进程在创建时,会拷贝父进程的task_struct,如果父进程打开了文件,那么子进程也能够访问父进程打开的文件【子进程拷贝父进程的files_struct】
- struct file对应的是被打开的文件,struct inode对应的是磁盘文件。因此每一个struct file内部都有一个struct inode的指针用于找到对应的磁盘文件。
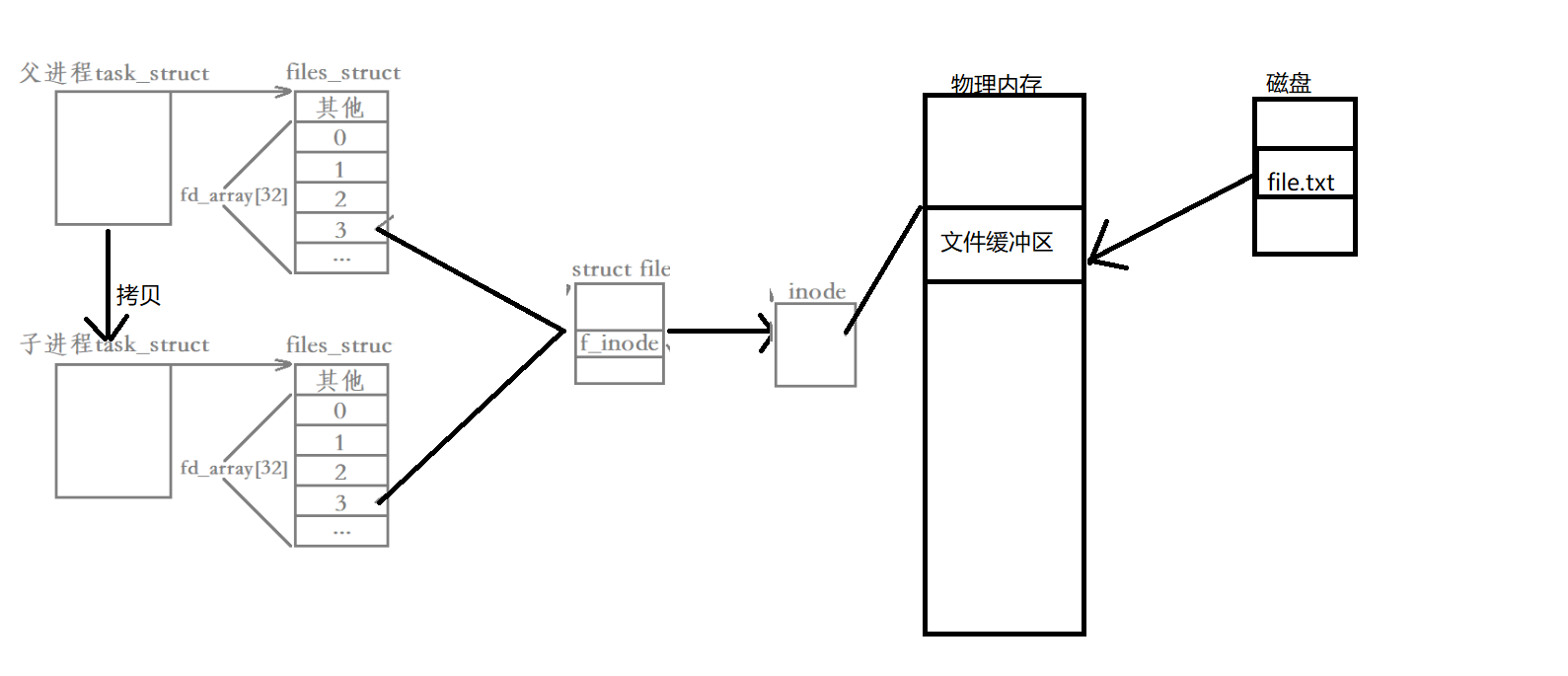
- 这里父子进程看到的同一份文件资源是由操作系统来维护的,所以当父子进程对该文件进行写入操作时,该文件缓冲区当中的数据并不会进行写时拷贝。
- 管道采用的是文件做为第三方资源;但是对于匿名管道,操作系统不会将进程间通信的数据刷新到磁盘中。因为子进程通过拷贝父进程的task_struct,可以访问父进程的文件;刷新到磁盘中,这样IO的效率会降低。也说明了,磁盘文件和内存文件不一定是一一对应的,有些文件只存在于内存中,而不会存在磁盘中。(比如这里的匿名管道)
操作系统如何判断一个文件是什么类型?
在struct inode内部有一个联合体,操作系统通过联合体判断文件的类型
union{
struct pipe_inode_info* i_pipe; //表示为管道文件
struct block_device* ibdev;
struct cdev* idev;
}
而在struct pipe_inode_info结构体中,有一个pipe_buffer的缓冲区
通过匿名管道进行进程间通信的数据,就存放在pipe_buffer缓冲区中。
2.2匿名管道的特点
- 半双工:数据只能从管道的一段写入,从另一端读出。数据在同一时刻只能有一个流向。
- 匿名管道不是普通文件,不属于某个文件系统,其只存在于内存中。
2.3匿名管道函数
#include <unistd.h>
#define _GNU_SOURCE
#include <fcntl.h>
int pipe(int pipefd[2]);
int pipe2(int pipefd[2], int flags);
参数:
pipefd[2],两个文件描述符 pipefd[0]代表读的文件描述符,pipefd[1]代表写的文件描述符
返回值:成功返回0,失败-1
底层:
pipe的底层调用了两次open函数,并将open返回的文件描述符写入到pipefd[2]数组中。
管道的创建过程
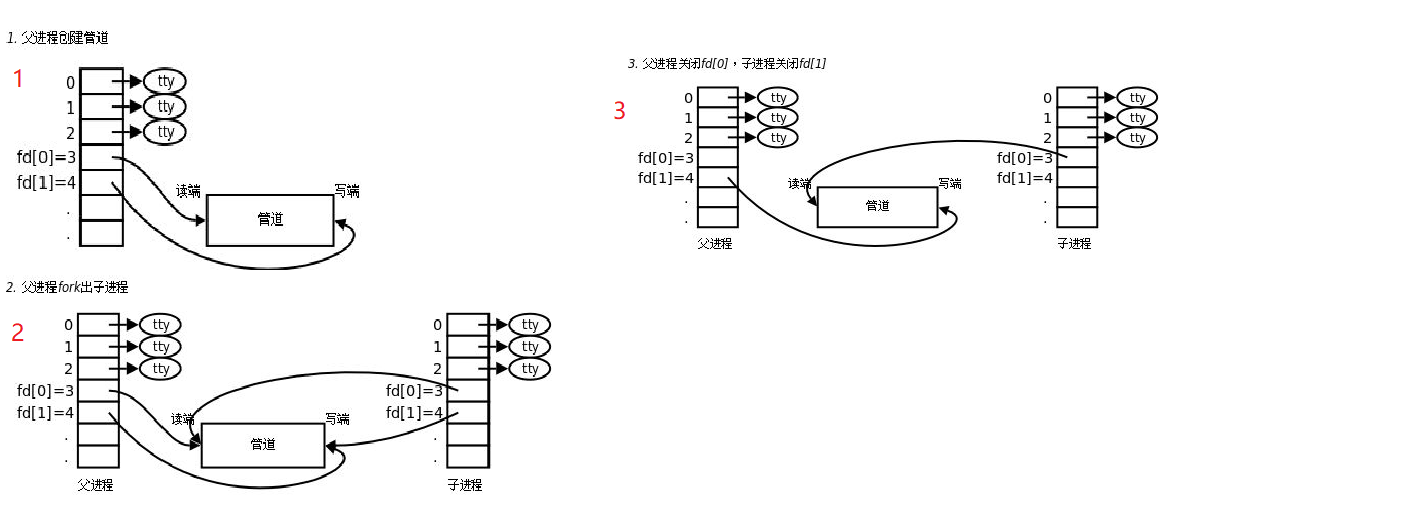
为什么父进程在创建子进程之前需要打开文件的读写端?
子进程是拷贝父进程发files_struc,父进程找到对应的文件描述符,子进程才能继承父进程的文件描述符。
为什么父子进程要关闭对应的读写?
操作系统的底层决定了,管道必须是单向通信。
2.3.1用例
实现子进程读取管道,父进程写入管道。
int main(){
int pipefd[2]={0};
if(pipe(pipefd)!=0){
cerr<<"pipe error"<<endl;
}
int pid=fork();
if(pid<0){
cerr<<"for error"<<endl;
}
else if(pid==0){//child
close(pipefd[1]);//关闭子进程的写文件
#define NUM 1024
char buf[NUM];
while (1)
{
memset(buf,0,sizeof(buf));
sleep(5);
ssize_t s=read(pipefd[0],buf,sizeof(buf)-1);
if(s>0){
buf[s]='\0';
cout<<"子进程接收到父进程的消息,内容是:"<<buf<<endl;
}
else if(s==0){
cout<<"父进程没有再写入,读取完成"<<endl;
break;
}
else{
//什么事都不做,等待有数据输入
}
}
close(pipefd[0]);
exit(0);
}
else{//parent
close(pipefd[0]); //关闭父进程的读文件描述符
const char* msg="父进程发送消息,信息编号为:";
int cnt=1;
while(1){
char sendbuff[1024];
sprintf(sendbuff,"%s %d",msg,cnt);
cnt++;
sleep(2);
write(pipefd[1],sendbuff,strlen(sendbuff));
}
close(pipefd[1]);
cout<<"父进程写入完毕:"<<endl;
//回收子进程
pid_t res=waitpid(pid,nullptr,0);
if(res>0){
cout<<"等待子进程成功"<<endl;
}
}
cout<<"fd[0]:"<<pipefd[0]<<endl;
cout<<"fd[1]:"<<pipefd[1]<<endl;
return 0;
}
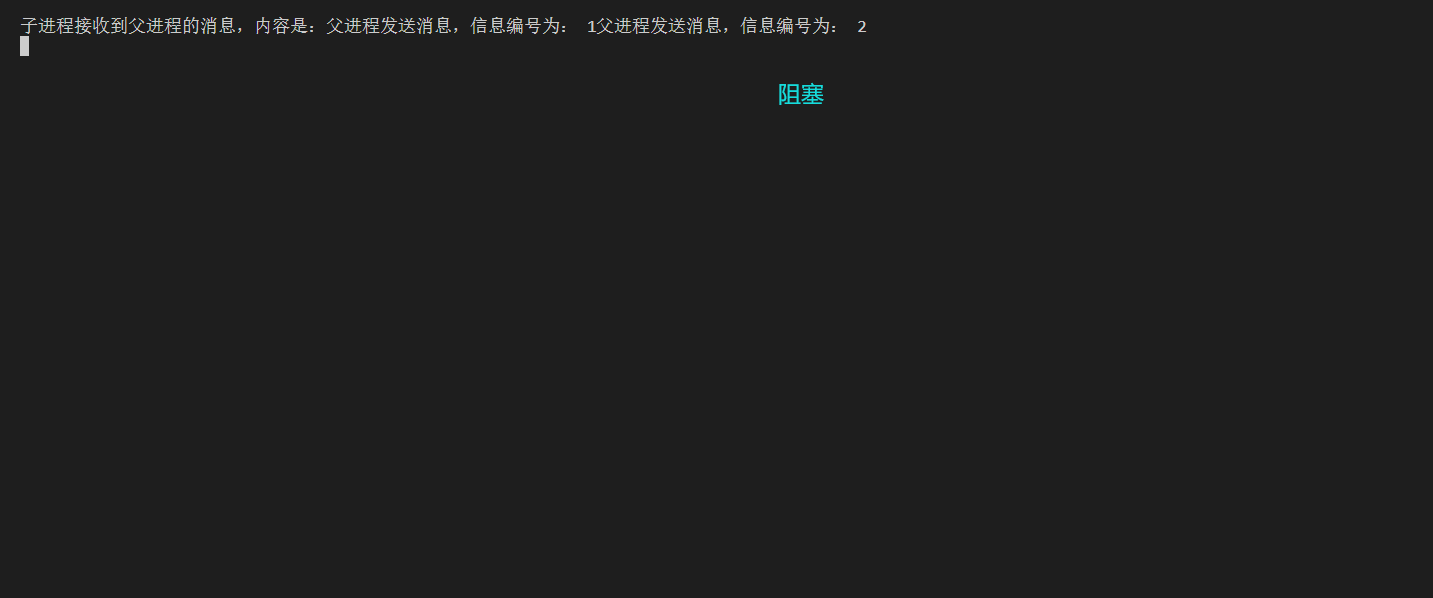
可以看到,子进程永远也不会退出。为什么?
read和write都是阻塞等待。
- 管道内部,没有数据,read就必须阻塞等待,等待有数据写入管道。
- 管道内部,如果数据写满了,write就必须阻塞等待,等待有数据被读走。

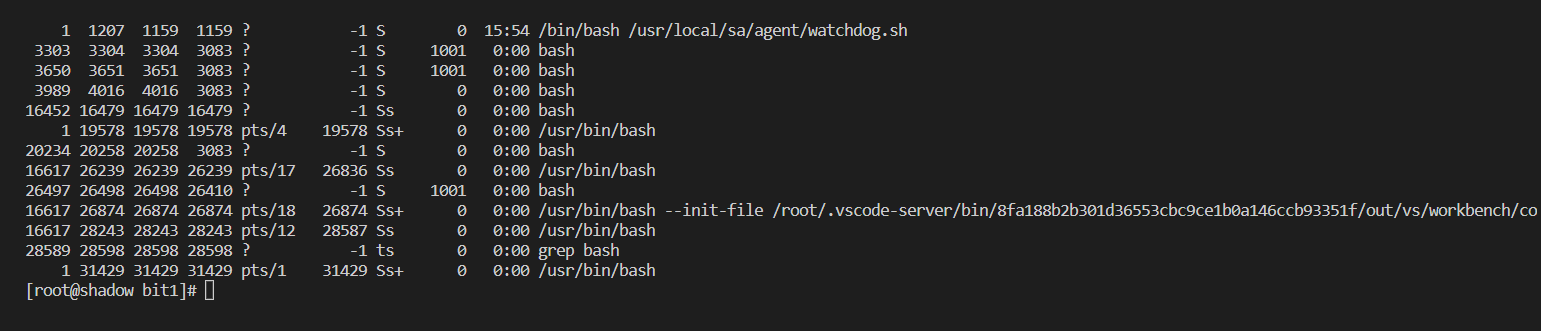
2.3.2实现ps -ajx | grep bash指令
子进程实现ps -ajx指令,父进程实现grep bash指令
int main(){
int pipefd[2]={0};
if(pipe(pipefd)!=0){
cerr<<"pipe error"<<endl;
}
//创建子进程
int pid=fork();
if(pid<0){
cerr<<"for error"<<endl;
}
if(pid==0){
//关闭读端,子进程执行ps -ajx
close(pipefd[0]);
dup2(pipefd[1],STDOUT_FILENO);
execlp("ps","ps","ajx",NULL);
}
else{
//关闭写端
close(pipefd[1]);
dup2(pipefd[0],STDIN_FILENO);
execlp("grep","grep","bash",NULL);
}
return 0;
}
2.4匿名管道的特点
1.匿名管道只能用于进行具有血缘关系的进程间通信,常用于父子进程通信。
2.管道只能单向通信(半双工通信)
3.管道自带同步和互斥机制
- **同步:**两个或两个以上的进程在运行过程中协同步调,按预定先后次序运行。比如A进程运行依赖B进程产生的数据
- **互斥:**一个公共资源同一时刻只能被一个进程使用,多个进程不能同时使用公共资源
4.管道是面向字节流
对于进程A写入管道当中的数据,进程B每次从管道读取的数据的多少是任意的,这种被称为流式服务,与之相对应的是数据报服务:
- 流式服务:先写的字符,一定是先被读取的。没有格式边界,需要用户来区分边界和数据格式。
- 数据报服务:数据有明确的分割,拿数据按报文段拿
2.5管道的大小
可以使用ulimit -a命令查看系统中创建管道文件所对应的内核缓冲区大小。

Linux下创建的管道大小可以通过下面的程序进行测试:
读端一直不读,写端一直写;当管道满了,写端就被挂起。打印写端写入的数据量。
int main(){
int fd[2]={0};
pipe(fd);
pid_t pid=fork();
if(pid==0){
close(fd[0]);//关闭读端
int cnt=0;
char a='a';
while(1){
write(fd[1],&a,1);
cnt++;
printf("cnt:%d\n",cnt);
}
}
waitpid(pid,NULL,0);
return 0;
}

2.6管道的生命周期
管道是文件。进程推出,被该进程打开的文件对应的计数器-1,如果计数器为0,那么文件关闭。对于管道而言,通信的两个进程都退出,那么管道被关闭。
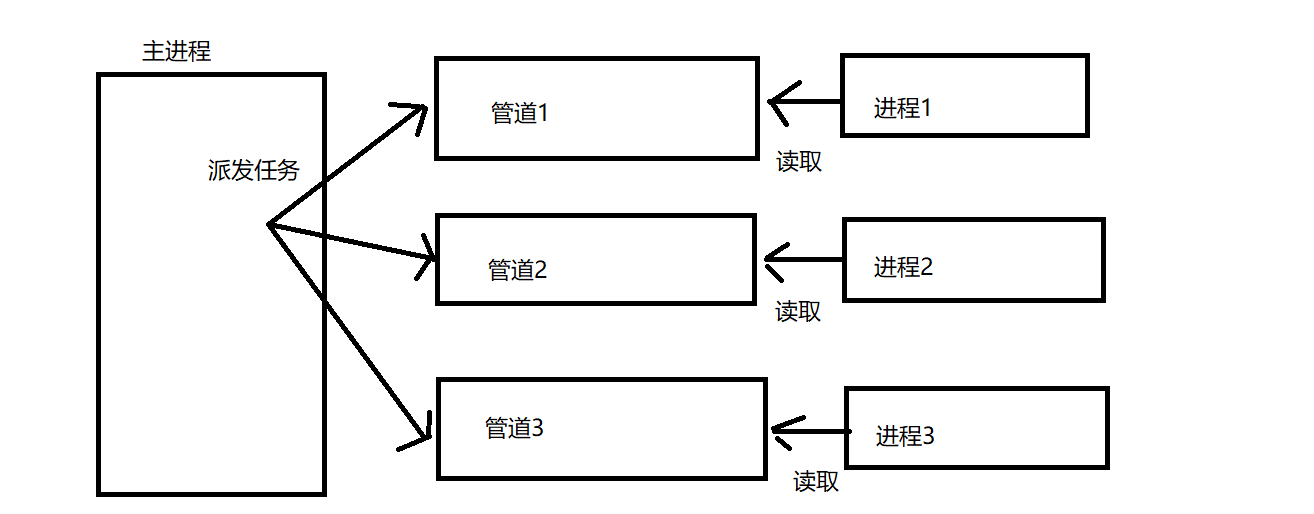
2.7进程池
主进程向每个子进程发送任务,主进程关闭每个pipe的读端,记录每个pipe的写端。
子进程收到主进程发送的指令后,执行发送的任务。
#define PROCESSNUM 10
typedef void(*functor)();
typedef pair<int32_t,int32_t>elem;
unordered_map<int32_t,string> info;
vector<functor>functors; //保存函数指针
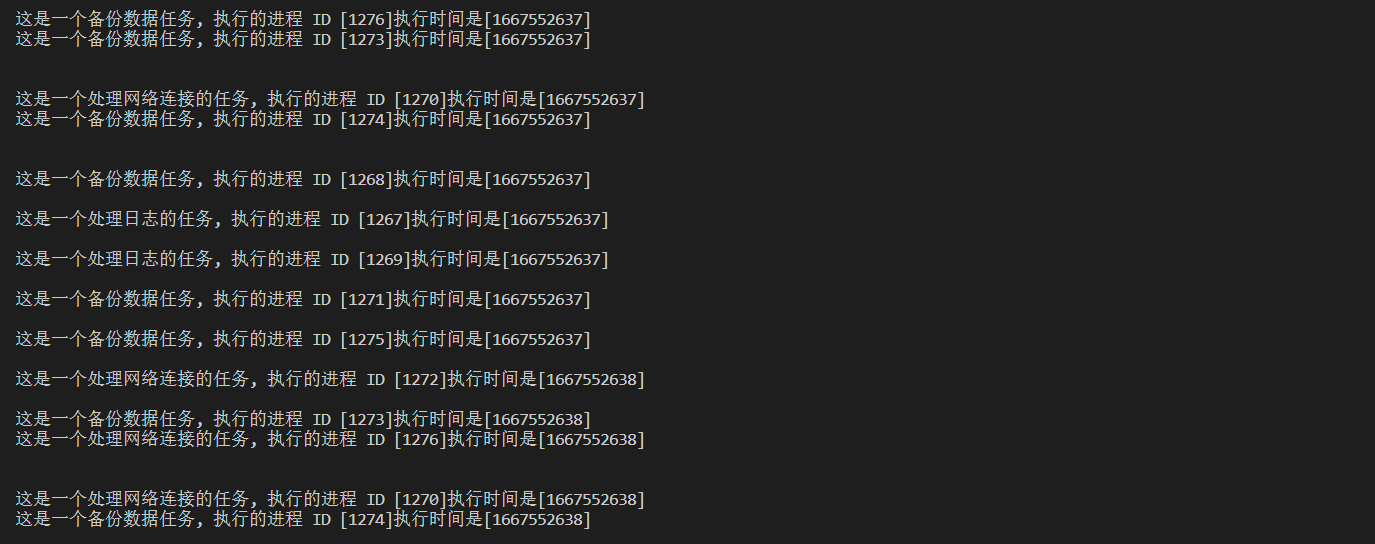
void f1()
{
cout << "这是一个处理日志的任务, 执行的进程 ID [" << getpid() << "]"
<< "执行时间是[" << time(nullptr) << "]\n" << endl;
}
void f2()
{
cout << "这是一个备份数据任务, 执行的进程 ID [" << getpid() << "]"
<< "执行时间是[" << time(nullptr) << "]\n" << endl;
}
void f3()
{
cout << "这是一个处理网络连接的任务, 执行的进程 ID [" << getpid() << "]"
<< "执行时间是[" << time(nullptr) << "]\n" << endl;
}
void londfunctor(){
info[functors.size()]="处理日志的任务";
functors.push_back(f1);
info[functors.size()]="备份数据任务";
functors.push_back(f2);
info[functors.size()]="处理网络连接的任务";
functors.push_back(f3);
}
void work(int fd){
cout<<"进程:["<<getpid()<<"]开始工作"<<endl;
while(1){
int32_t task=0;
ssize_t s=read(fd,&task,sizeof(int32_t));
if(s==0){ //如果读取完成
break;
}
assert(s==sizeof(int32_t));
//执行任务
if(task<functors.size())
{
functors[task]();
sleep(1);
}
}
cout<<"进程:["<<getpid()<<"]开始结束"<<endl;
}
void blancesendtask(const vector<elem>&assmap){ //派发方式是负载均衡的
srand((long long)time(nullptr)); //生成随机数种子
while(1){ //派发什么任务,向谁派发。
int32_t pick=rand()%assmap.size();
int32_t task=rand()%functors.size();
//指派任务,写入一个地址
write(assmap[pick].second,&task,sizeof(int32_t));
cout<<"父进程给子进程:"<<"["<<assmap[pick].first<<"]"<<"派发任务:"<<task<<endl;
}
}
int main(){
vector<elem> assmmap;
londfunctor();//加载任务
//创建进程
for(int i=0;i<PROCESSNUM;i++){
int pipefd[2]={0};
if(pipe(pipefd)!=0){
cerr<<"pipe error"<<endl;
}
//创建子进程
int pid=fork();
if(pid<0){
cerr<<"fork error"<<endl;
}
//子进程的工作是,完成父进程派发的任务。
if(pid==0){
close(pipefd[1]); //关闭子进程的写端
work(pipefd[0]);//子进程读取管道,从而执行自己的任务。
close(pipefd[0]);
exit(0);
}
else{//父进程,负责收集子进程的信息和派发任务
close(pipefd[0]); //关闭父进程的读端
elem e(pid,pipefd[1]);
assmmap.push_back(e);
}
}
cout<<"all process create successfully"<<endl;
//收集好信息后,父进程给子进程派发任务
blancesendtask(assmmap);
//回收子进程
for(int i=0;i<PROCESSNUM;i++){
int res=waitpid(assmmap[i].first,NULL,0);
if(res>0){
cout<<"等待子进程"<<assmmap[i].first<<"成功!"<<endl;
}
close(assmmap[i].second);
}
return 0;
}
3.命名管道FIFO
- 管道应用的一个限制就是只能在具有共同祖先(具有亲缘关系)的进程间通信。
- 如果我们想在不相关的进程之间交换数据,可以使用FIFO文件来做这项工作,它经常被称为命名管道。
- 命名管道是一种特殊类型的文件
注意:
- 命名管道和匿名管道一样,都是内存文件,只不过命名管道在磁盘有一个简单的映像,但这个映像的大小永远为0,因为命名管道和匿名管道都不会将通信数据刷新到磁盘当中。
- FIFO是linux基础文件类型中的一种,但FIFO文件在磁盘上没有数据块,仅仅用来标识内核中的一条通道。属于管道伪文件。
3.1命名管道的接口
创建方式
创建方式有两种:
第一种是bash命令 mkfifo 管道名字
第二种是使用库函数。:int mkfifo(const char *pathname, mode_t mode);
pathname表示管道名,mode是管道权限
$ mkfifo myfifo
$ ls -lrt
int mkfifo(const char *pathname, mode_t mode);

3.2命名管道和匿名管道的区别
- 匿名管道由pipe函数创建并打开。
- 命名管道由mkfifo函数创建,打开用open
- FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在它们创建与打开的方式相同,一但这些工作完成之后,它们具有相同的语义。
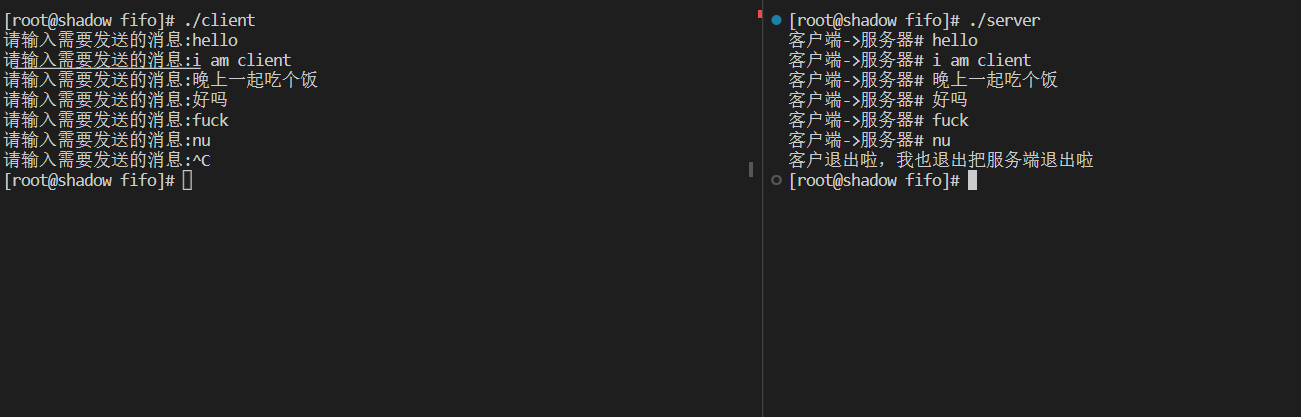
3.3用FIFO实现server&cilent间通信
实现服务端和客户端之间的通信。让服务端先运行,创建服务端和客户端通信之间通信的管道。
客户端以写的方式打开管道向管道中写入数据;服务端以读的方式打开管道,读取客户端发送的信息。
server.cpp
#include "comm.h"
#define NUM 1024
using namespace std;
int main()
{
umask(0);
if(mkfifo(IPC_PATH, 0600) != 0){
cerr << "mkfifo error" << endl;
return 1;
}
int pipefd = open(IPC_PATH, O_RDONLY);
if(pipefd < 0){
cerr << "open fifo error" << endl;
return 2;
}
//正常的通信过程
char buffer[NUM];
while(true){
ssize_t s = read(pipefd, buffer, sizeof(buffer)-1);
if(s > 0){
buffer[s] = '\0';
cout << "客户端->服务器# " << buffer << endl;
}
else if(s == 0){
cout << "客户退出啦,我也退出把";
break;
}
else{
//do nothing
cout << "read: " << strerror(errno) << endl;
break;
}
}
close(pipefd);
cout << "服务端退出啦" << endl;
unlink(IPC_PATH);
return 0;
}
client.cpp
#include"comm.h"
using namespace std;
int main(){
int pipefd=open(IPC_PATH,O_WRONLY);
if(pipefd<0){
cerr<<"open:"<<strerror(errno)<<endl;
return 1;
}
#define NUM 1024
char line[NUM];
while(1){
cout<<"请输入需要发送的消息:";
fflush(stdout);
memset(line,0,sizeof(line));
if(fgets(line,sizeof(line),stdin)!=nullptr){ //从键盘中获取数据,在输入时,我们会输入一个\n
line[strlen(line)-1]='\0';
write(pipefd,line,strlen(line));
}
else{
break;
}
}
close(pipefd);
cout<<"客户端退出:"<<endl;
return 0;
}
client.cpp中需要注意两点:
- fgets在结尾会自动添加上\0
- 在从键盘输入时,回车键也被读取到fgets中
comm.h
#pragma once
#include <iostream>
#include <cstdio>
#include <string>
#include <cstring>
#include <cerrno>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#define IPC_PATH "./myfifo"
4.System V进程间通信
管道通信本质是基于文件的,也就是说操作系统并没有为此做过多的设计工作,而system V IPC是操作系统特地设计的一种通信方式。
System V IPC提供的通信方式有以下三种
- System V共享内存
- System V消息队列
- System V信号量
System V中的共享内存和消息队列的作用是传输数据,而信号量是为了保证进程间通信的同步和互斥而设计。
5.System V共享内存
5.1共享内存的原理
进程间通信的本质是:让不同的进程看到同一份资源。
而共享内存的方式:和动态库加载到不同进程一样。**共享内存在物理内存中申请一块空间,通过不同进程的页表,映射到不同进程的共享区,这些进程就可以通过共享区的进程地址空间,访问到同一块物理内存。**达到进程间通信的目的。
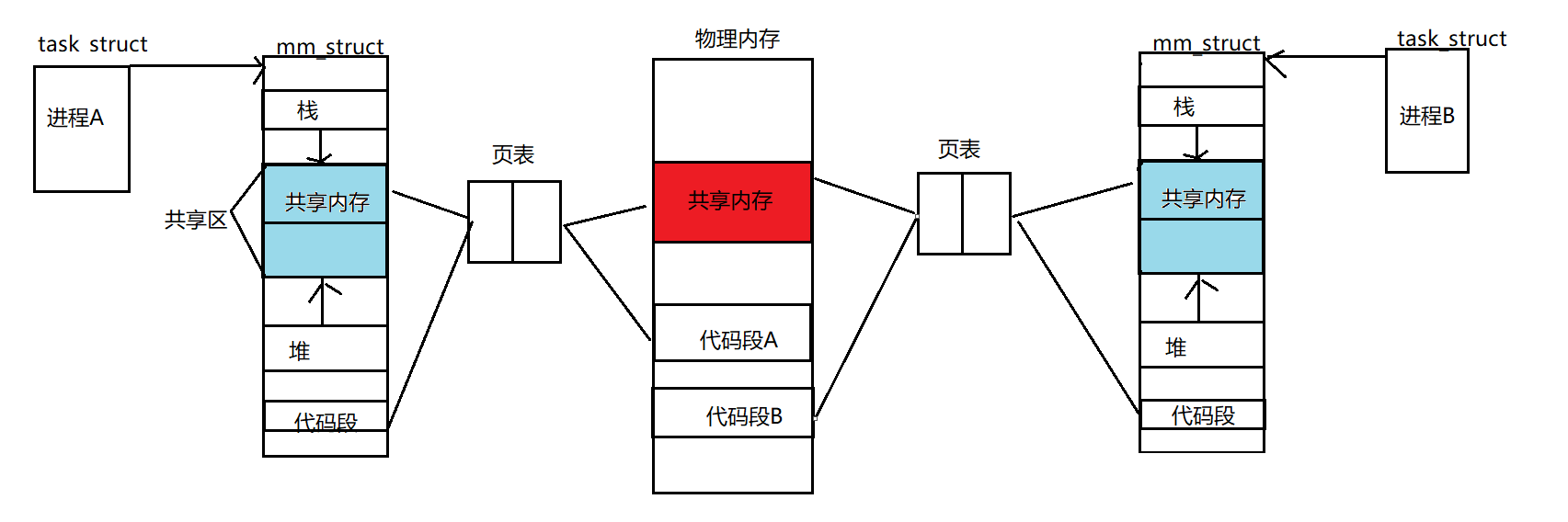
- 共享内存的创建和删除-------> OS完成
- 共享内存的关联---------------> 进程完成
5.2共享内存接口
5.2.1创建共享内存
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
参数说明:
- key:待创建共享内存在内核中的唯一标识,该值由用户提供
- size:共享内存大小,为页(4096)的整数倍
- shmlg:由九个权限标志构成,它们的用法和创建文件时使用的mode模式标志是一样的
| shmlg | 含义 |
|---|---|
| IPC_CREAT | 共享内存不存在时,创建共享内存 |
| IPC_EXCL | 共享内存存在时,报错。不单独使用,必须和IPC_CREAT配合使用。IPC_CREAT | IPC_EXCL:可以保证如果shmget调用成功,一定会得到一个全新的共享内存,否则就会出错返回。 |
返回值:
- 成功:返回一个非负整数shmid,为该共享内存段的用户层面的唯一标识码;
- 失败:返回-1
shmid和key都是标识共享内存的标识符,但是属于不同的层面。内核在管理共享内存时,使用的是key,而用户在管理共享内存时使用的是shmid。
5.2.2共享内存数据结构
在系统当中可能会有大量的进程在进行通信,因此系统当中就可能存在大量的共享内存,那么操作系统必然要对其进行管理,所以共享内存除了在内存当中真正开辟空间之外,系统一定还要为共享内存维护相关的内核数据结构。
struct shmid_ds {
struct ipc_perm shm_perm; /* operation perms */
int shm_segsz; /* size of segment (bytes) */
__kernel_time_t shm_atime; /* last attach time */
__kernel_time_t shm_dtime; /* last detach time */
__kernel_time_t shm_ctime; /* last change time */
__kernel_ipc_pid_t shm_cpid; /* pid of creator */
__kernel_ipc_pid_t shm_lpid; /* pid of last operator */
unsigned short shm_nattch; /* no. of current attaches */
unsigned short shm_unused; /* compatibility */
void *shm_unused2; /* ditto - used by DIPC */
void *shm_unused3; /* unused */
};
上面的结构体内部有一个struct ipc_perm结构体,该结构体存放了与权限相关的内容。每个共享内存的key都存放在该结构体中。
struct ipc_perm {
key_t __key; /* Key supplied to shmget(2) */
uid_t uid; /* Effective UID of owner */
gid_t gid; /* Effective GID of owner */
uid_t cuid; /* Effective UID of creator */
gid_t cgid; /* Effective GID of creator */
unsigned short mode; /* Permissions + SHM_DEST and
SHM_LOCKED flags */
unsigned short __seq; /* Sequence number */
};
用户对共享内存的管理都使用key作为标识符。
5.2.3key的获取
为什么key由用户提供?
共享内存由key作为标识符;不同的进程要看到同一块共享内存资源,则需要同一个key。如果key由进程提供,其他进程如何获得key?无法获取key,如何找到共享内存。
key_t ftok(const char *pathname, int proj_id);
该函数可以将文件路径和项目标识符转换为一个特异的数字key。在使用shmget函数获取共享内存时,这个key值会被填充进维护共享内存的数据结构当中
参数说明:
- pathname:一般传递当前路径
- proj_id:任意传递。
创建一个共享内存
ipcshmser.cpp
#include"comm.hpp"
#include"Log.hpp"
using namespace std;
#define SIZE 4096
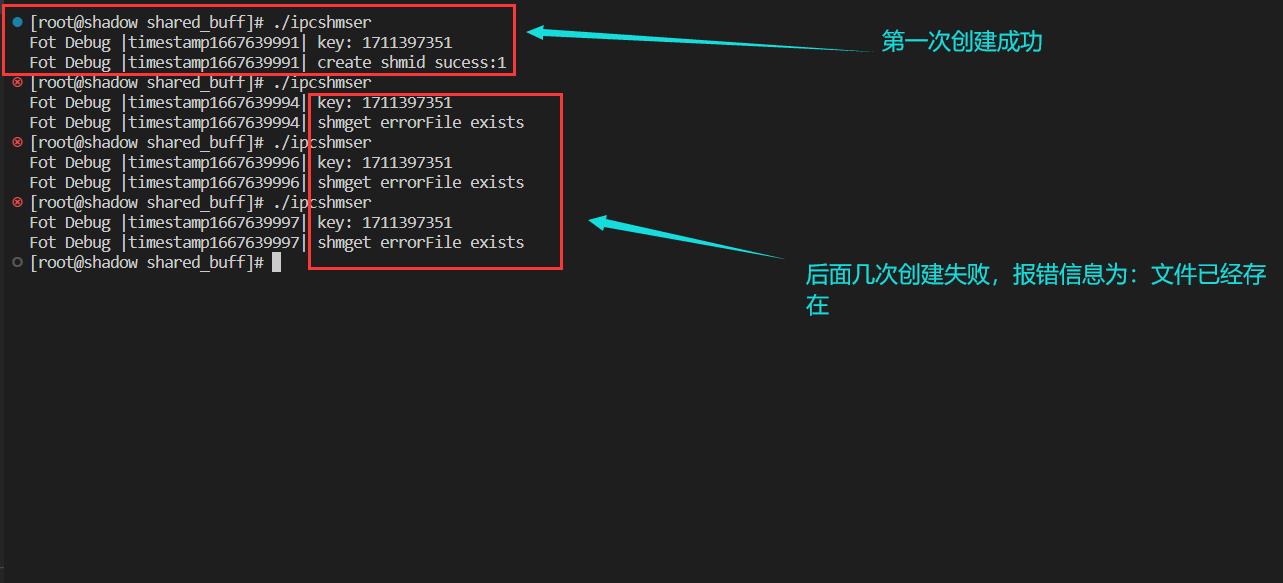
int main(){
key_t key=Creatkey();
Log()<<"key: "<<key<<std::endl;
//创建共享内存
int shmid=shmget(key,SIZE,IPC_CREAT|IPC_EXCL); //创建一个全新的共享内存
if(shmid<0){
Log()<<"shmget error"<<strerror(errno)<<std::endl;
return 2;
}
Log()<<"create shmid sucess:"<<shmid<<std::endl;
return 0;
}
comm.hpp
#define PATH_NAME "/home/west/linuxtest/bit1/shared_buff"
#define PROJ_ID 0x666
key_t Creatkey(){
key_t key=ftok(PATH_NAME,PROJ_ID);
if(key<0){
std::cerr<<"ftok error"<<std::endl;
exit(1);
}
return key;
}
Log.hpp
#include<iostream>
#include <ctime>
std::ostream& Log(){
std::cout<<"Fot Debug |"<<"timestamp"<<(uint64_t)time(NULL)<<"| ";
return std::cout;
}
执行结果:
System V下的共享内存的生命周期是随内核的,不会随进程的退出而关闭。共享内存只能被显示删除或者重启系统。
5.2.4获取IPC资源
ipcs 查找ipc资源
-m 查找共享内存资源
-s 查看信号量
-q 查看共享队列资源
ipcrm -m/-s/-q 删除ipc资源
ipcrm -shmid删除共享内存资源
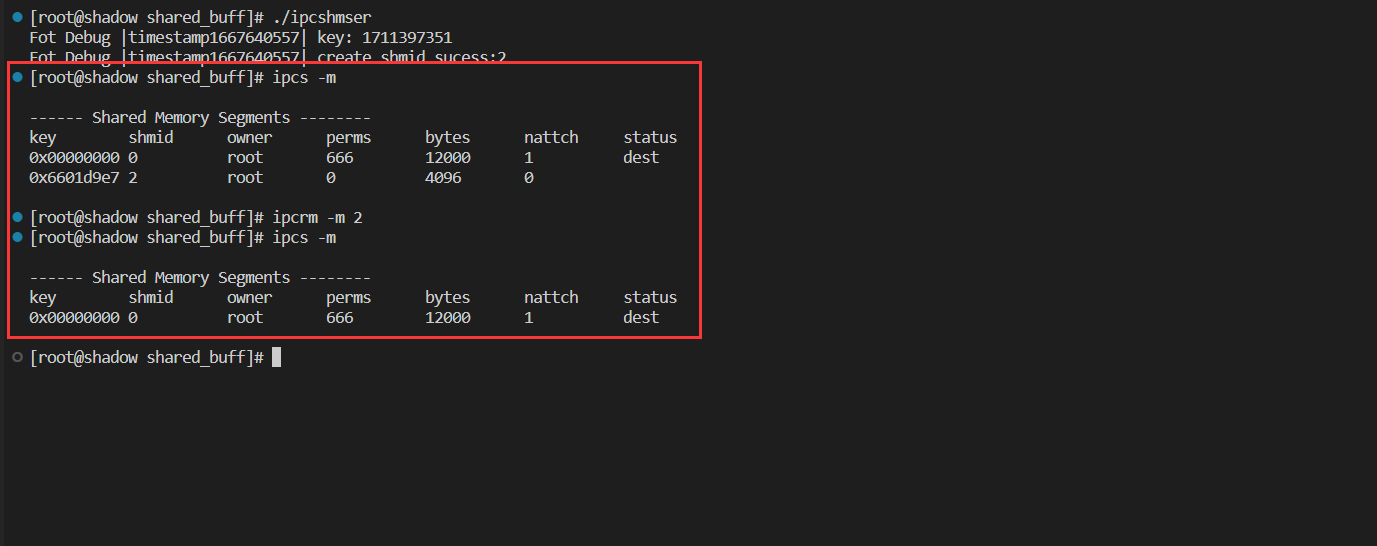
ipcs命令各参数意义:
| 标题 | 含义 |
|---|---|
| key | 系统区别各个共享内存的唯一标识 |
| shmid | 共享内存的用户层id(句柄) |
| owner | 共享内存的拥有者 |
| perms | 共享内存的权限 |
| bytes | 共享内存的大小 |
| nattch | 关联共享内存的进程数 |
| status | 共享内存的状态 |
5.2.5操作共享内存
如果每次都要使用命令行去删除共享内存,那就太麻烦了。下面的接口可以实现对共享内存的操作。
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数说明:
- shmid:需要控制的共享内存用户标识
- cmd:具体的控制动作
- buf:用户获取或者设置共享内存的数据结构。
| 选项 | 具体作用 |
|---|---|
| IPC_STAT | 获取共享内存的当前关联值,此时参数buf作为输出型参数 |
| IPC_SET | 在进程有足够权限的前提下,将共享内存的当前关联值设置为buf所指的数据结构中的值。 |
| IPC_RMID | 删除共享内存段 |
返回值:
- 成功返回0,失败返回-1
下面,我们在创建一个共享内存后,等待几秒后删除它,检测共享内存的状态。
#include"comm.hpp"
#include"Log.hpp"
using namespace std;
#define SIZE 4096
int main(){
key_t key=Creatkey();
Log()<<"key: "<<key<<std::endl;
//创建共享内存
int shmid=shmget(key,SIZE,IPC_CREAT|IPC_EXCL); //创建一个全新的共享内存
if(shmid<0){
Log()<<"shmget error"<<strerror(errno)<<std::endl;
return 2;
}
Log()<<"create shmid sucess:"<<shmid<<std::endl;
Log()<<"del shmid begin"<<"\n";
sleep(4);
int ret=shmctl(shmid,IPC_RMID,nullptr);
if(ret<0){
Log()<<"shmctl error"<<strerror(errno)<<"\n";
return 1;
}
Log()<<"del shmid end"<<"\n";
return 0;
}
监视命令
while :; do ipcs -m;echo "##########";sleep(1);done;
执行结果
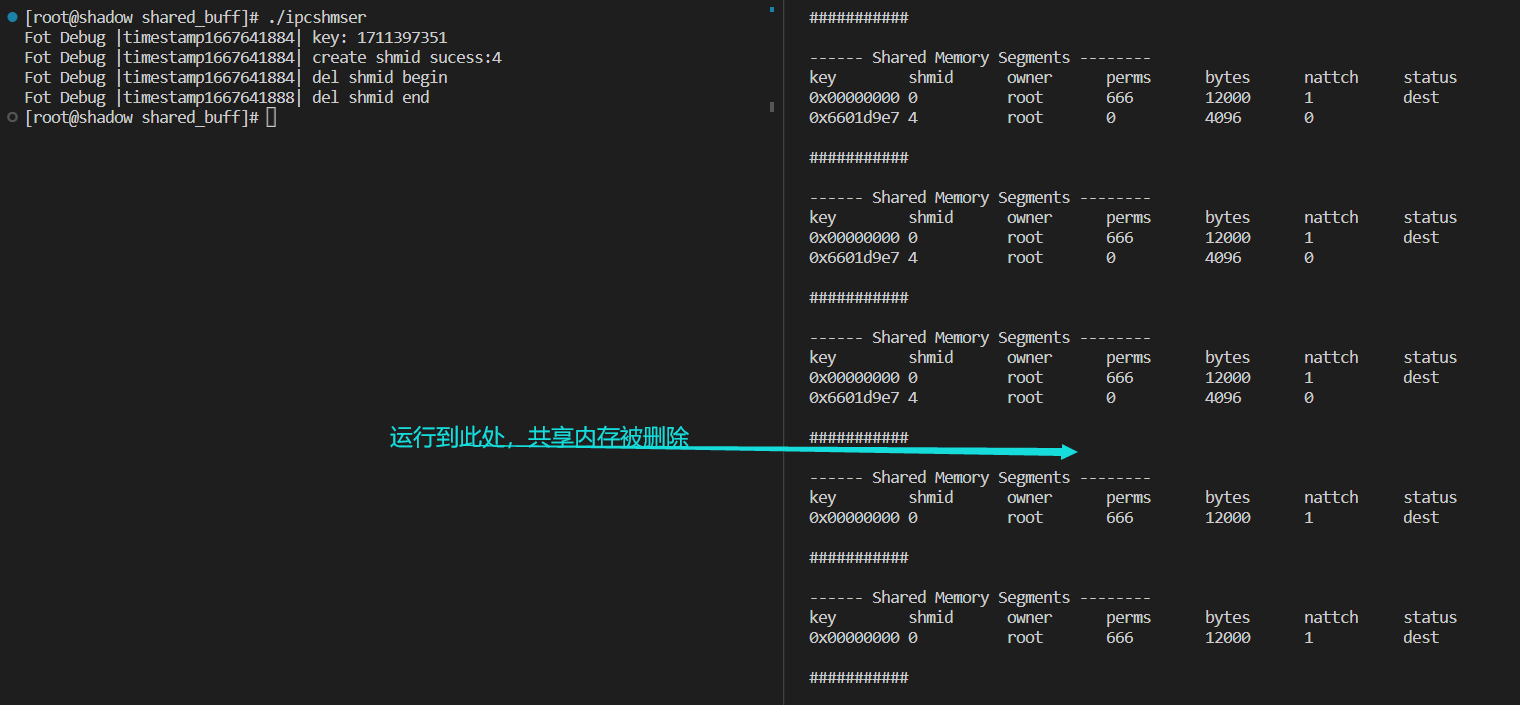
5.2.6挂载共享内存
将共享内存连接到进程地址空间我们需要用shmat函数,将共享内存从进程空间剥离需要使用shndt函数:
关联进程地址空间
void *shmat(int shmid, const void *shmaddr, int shmflg);
参数说明:
- 第一个参数shmid,表示待关联共享内存的用户级标识符。
- 第二个参数shmaddr,指定共享内存映射到进程地址空间的某一地址,通常设置为NULL,表示让内核自己决定一个合适的地址位置。
- 第三个参数shmflg,表示关联共享内存时设置的某些属性
shmlg参数:
| 选项 | 作用 |
|---|---|
| SHM_RDONLY | 关联共享内存后只进行读取操作 |
| SHM_RND | 若shmaddr不为NULL,则关联地址自动向下调整为SHMLBA的整数倍。公式:shmaddr-(shmaddr%SHMLBA) |
| 0 | 默认为读写权限 |
返回值:
- 成功:返回共享内存起始地址
- 失败:返回(void*)-1
去关联
int shmdt(const void *shmaddr);
参数说明:
- 待去关联共享内存的起始地址,即调用shmat函数时得到的起始地址。
返回值:
- 成功:返回0
- 失败:返回-1
示例
我们在创建共享内存后,先与该进程关联,5秒钟后,再去关联。
#include"comm.hpp"
#include"Log.hpp"
using namespace std;
#define SIZE 4096
int main(){
key_t key=Creatkey();
Log()<<"key: "<<key<<std::endl;
//创建共享内存
int shmid=shmget(key,SIZE,IPC_CREAT|IPC_EXCL); //创建一个全新的共享内存
if(shmid<0){
Log()<<"shmget error"<<strerror(errno)<<std::endl;
return 2;
}
Log()<<"create shmid sucess:"<<shmid<<std::endl;
char* str=(char*)shmat(shmid,nullptr,0);
sleep(5);
int res=shmdt((const void*)str);
sleep(5);
int ret=shmctl(shmid,IPC_RMID,nullptr);
if(ret<0){
Log()<<"shmctl error"<<strerror(errno)<<"\n";
return 1;
}
return 0;
}
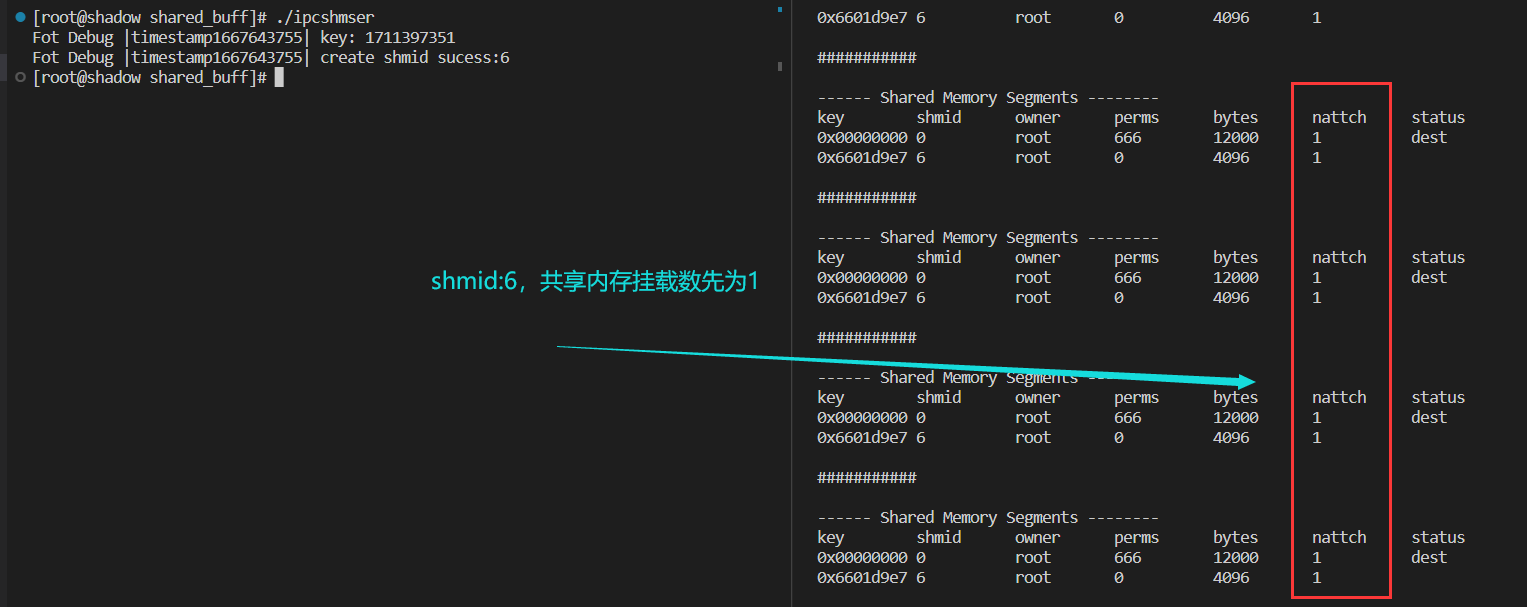
五秒后,挂载数变为0;
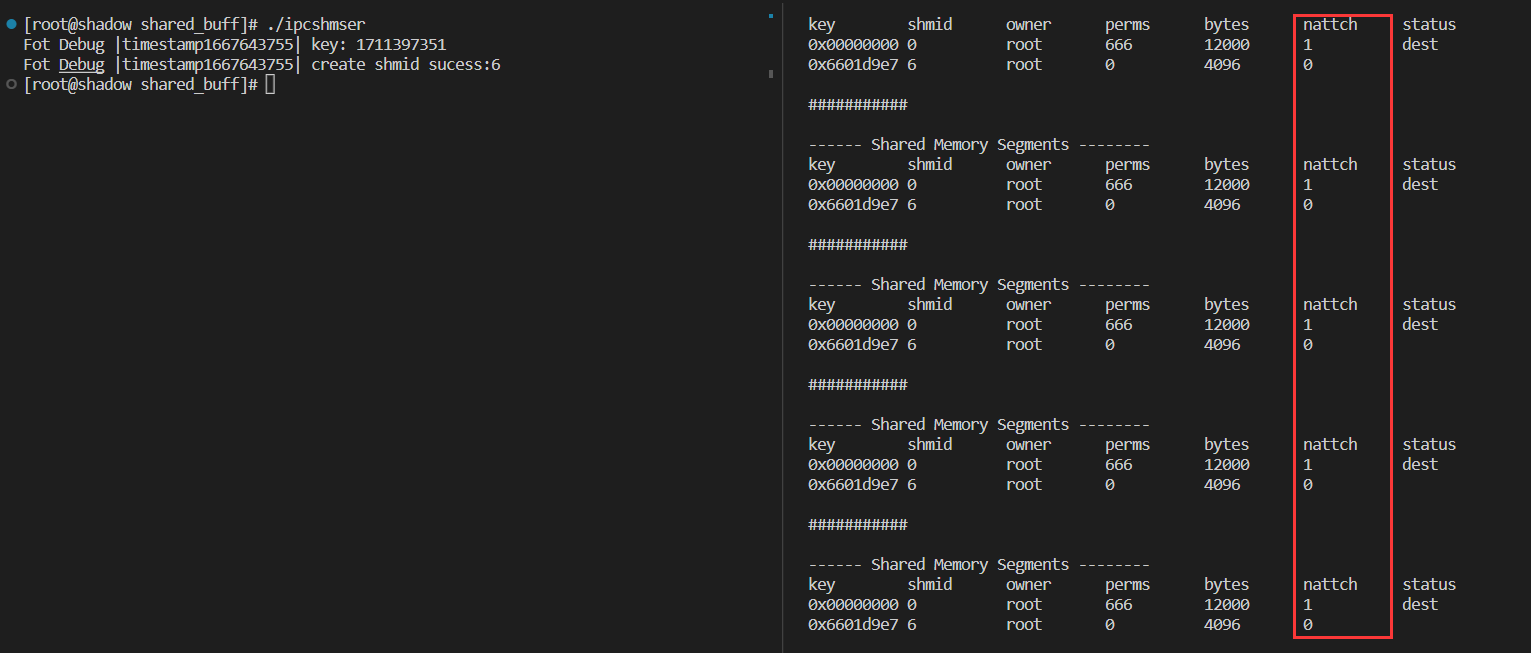
最后共享内存被删除:
5.2.7共享内存的使用
共享内存的使用:可以不使用任何系统接口,因为共享内存是映射到了我们进程地址空间的用户空间(堆栈之间的共享区),对于每一个进程,挂接到自己进程的共享内存,属于自己的堆栈空间,可以向内存一样使用。
实例
使用共享内存实现进程间通信,服务器接收到客户端发送的信号,就打印内容。
comm.hpp
#define PATH_NAME "/home/west/linuxtest/bit1/shared_buff"
#define PROJ_ID 0x666
#define FIFO_FIEL "myfifo"
key_t Creatkey(){
key_t key=ftok(PATH_NAME,PROJ_ID);
if(key<0){
std::cerr<<"ftok error"<<std::endl;
exit(1);
}
return key;
}
//创建命名管道
void CreateFifo(){
umask(0);
if(mkfifo(FIFO_FIEL,0666)<0){
Log()<<"mkfifo error"<<"\n";
exit(2);
}
}
#define READER O_RDONLY
#define WRITER O_WRONLY
//打开文件
int Open(const std::string&filename,int flags){
return open(filename.c_str(),flags);
}
//等待信号
int Wait(int fd){
uint32_t values=0;
ssize_t s=read(fd,&values,sizeof(values));
return s;
}
//发送信号
int Signal(int fd){ //发送信号,告诉接收消息
uint32_t cmd=1;
write(fd,&cmd,sizeof(cmd));
}
//关闭文件
int Close(const std::string filename,int fd){
close(fd);
unlink(filename.c_str());
}
ipcshmser.cpp
负责接收客户端发送的信号,并打印共享内存中的内容。
#include"comm.hpp"
#include"Log.hpp"
using namespace std;
#define SIZE 4096
int main(){
//打开命名管道
CreateFifo();
int fd=Open(FIFO_FIEL,READER);
assert(fd>0);
key_t key=Creatkey();
Log()<<"key: "<<key<<std::endl;
//创建共享内存
int shmid=shmget(key,SIZE,IPC_CREAT|IPC_EXCL|0666); //创建一个全新的共享内存
if(shmid<0){
Log()<<"shmget error"<<strerror(errno)<<std::endl;
return 2;
}
Log()<<"create shmid sucess:"<<shmid<<std::endl;
char* str=(char*)shmat(shmid,nullptr,0);
while (true){
//读端一直等待
if(Wait(fd)<=0) break;
printf("%s\n",str);
sleep(1);
}
int res=shmdt((const void*)str);
int ret=shmctl(shmid,IPC_RMID,nullptr);
if(ret<0){
Log()<<"shmctl error"<<strerror(errno)<<"\n";
return 1;
}
return 0;
}
ipcshmcil.cpp
客户端负责发送信号和向共享内存中写入数据
#define SIZE 4096
int main(){
int fd=Open(FIFO_FIEL,WRITER);
//创建一个相同的key值
key_t key=Creatkey();
Log()<<"key:"<<key<<"\n";
//创建共享内存
int shmid=shmget(key,SIZE,IPC_CREAT);
if(shmid<0){
Log()<<"shmget:"<<strerror(errno)<<"\n";
return 2;
}
//挂接
char* str=(char*)shmat(shmid,nullptr,0);
while(true){
printf("Please Enter# ");
fflush(stdout);
ssize_t s=read(0,str,SIZE);
if(s>0){
str[s]='\0';
}
Signal(fd);
}
//去关联
shmdt(str);
return 0;
}
Makefile
.PHTONY:all
all:ipcshmser ipcshmcli
ipcshmser:ipcshmser.cpp
g++ -o $@ $^ -std=c++11
ipcshmcli:ipcshmcli.cpp
g++ -o $@ $^ -std=c++11
.PHTONY:clean
clean:
rm -f ipcshmser ipcshmcli
6.System V消息队列
- 消息队列实际上就是在系统当中创建了一个队列,队列当中的每个成员都是一个数据块,这些数据块都由类型和信息两部分构成;
- 两个互相通信的进程通过某种方式看到同一个消息队列
- 这两个进程向对方发数据时,都在消息队列的队尾添加数据块,这两个进程获取数据块时,都在消息队列的队头取数据块。
6.1消息队列原理
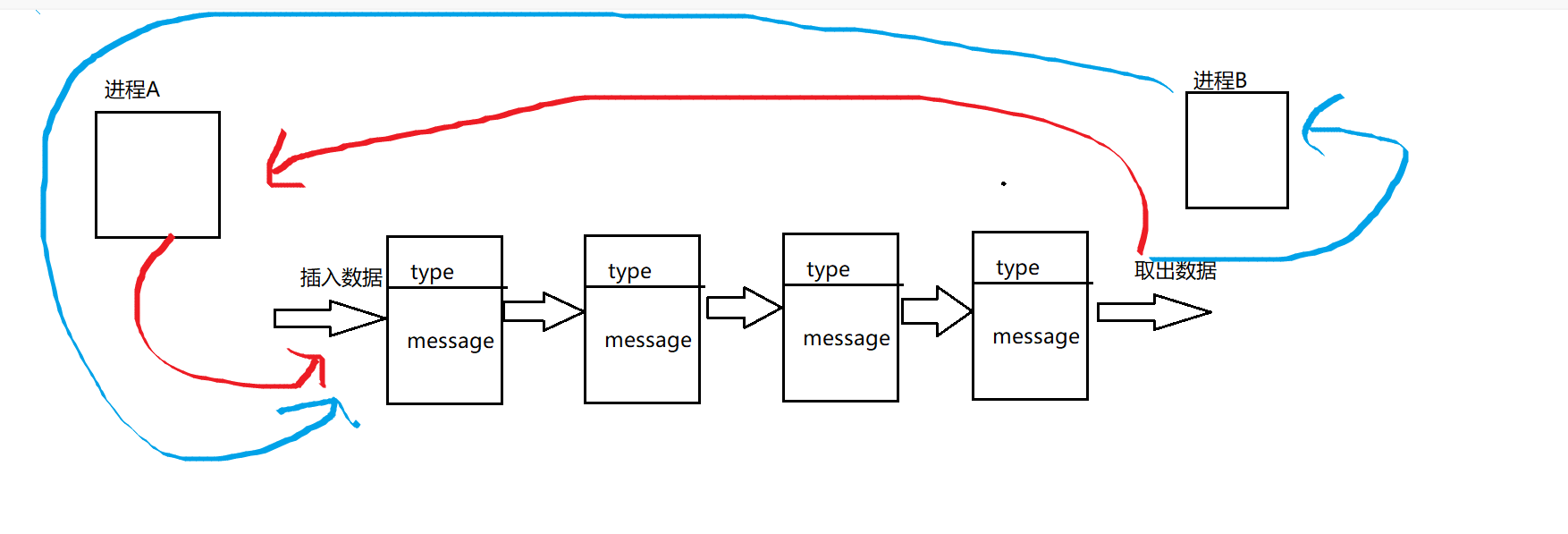
其中消息队列当中的某一个数据块是由谁发送给谁的,取决于数据块的类型。
消息队列的数据结构
struct msqid_ds {
struct ipc_perm msg_perm;
struct msg *msg_first; /* first message on queue,unused */
struct msg *msg_last; /* last message in queue,unused */
__kernel_time_t msg_stime; /* last msgsnd time */
__kernel_time_t msg_rtime; /* last msgrcv time */
__kernel_time_t msg_ctime; /* last change time */
unsigned long msg_lcbytes; /* Reuse junk fields for 32 bit */
unsigned long msg_lqbytes; /* ditto */
unsigned short msg_cbytes; /* current number of bytes on queue */
unsigned short msg_qnum; /* number of messages in queue */
unsigned short msg_qbytes; /* max number of bytes on queue */
__kernel_ipc_pid_t msg_lspid; /* pid of last msgsnd */
__kernel_ipc_pid_t msg_lrpid; /* last receive pid */
};
和共享内存一样,消息队列有一个存放权限的结构体
struct ipc_perm {
key_t __key; /* Key supplied to xxxget(2) */
uid_t uid; /* Effective UID of owner */
gid_t gid; /* Effective GID of owner */
uid_t cuid; /* Effective UID of creator */
gid_t cgid; /* Effective GID of creator */
unsigned short mode; /* Permissions */
unsigned short __seq; /* Sequence number */
};
6.2消息队列接口
6.2.1创建消息队列
msgget函数
功能:⽤用来创建和访问⼀一个消息队列
原型
int msgget(key_t key, int msgflg);
参数
key: 某个消息队列的名字
msgflg:由九个权限标志构成,它们的⽤用法和创建⽂文件时使⽤用的mode模式标志是⼀一样的
返回值:成功返回⼀一个⾮非负整数,即该消息队列的标识码;失败返回-1
和共享内存一样,key是内核级标识符,使用ftok()函数创建
6.2.2控制消息队列
功能:消息队列的控制函数
原型
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
参数
msqid: 由msgget函数返回的消息队列标识码
cmd:是将要采取的动作,(有三个可取值)
返回值:成功返回0,失败返回-1
cmd选项

6.2.3添加到消息队列
表明是谁发的消息
功能:把⼀一条消息添加到消息队列中
原型
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
参数
msgid: 由msgget函数返回的消息队列标识码
msgp:是⼀一个指针,指针指向准备发送的消息,
msgsz:是msgp指向的消息⻓长度,这个⻓长度不含保存消息类型的那个long int⻓长整型
msgflg:控制着当前消息队列满或到达系统上限时将要发⽣生的事情
msgflg=IPC_NOWAIT表⽰示队列满不等待,返回EAGAIN错误。
返回值:成功返回0;失败返回-1
注意:
1.消息结构在两⽅方⾯面受到制约:
⾸首先,它必须⼩小于系统规定的上限值;
其次,它必须以⼀一个long int⻓长整数开始,接收者函数将利⽤用这个⻓长整数确定消息的类型
2.消息结构参考形式如下:
struct msgbuf {
long mtype;
char mtext[1];
}
6.2.4消息队列接收函数
表明接收谁的消息
功能:是从⼀一个消息队列接收消息
原型
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
参数
msgid: 由msgget函数返回的消息队列标识码
msgp:是⼀一个指针,指针指向准备接收的消息,
msgsz:是msgp指向的消息⻓长度,这个⻓长度不含保存消息类型的那个long int⻓长整型
msgtype:它可以实现接收优先级的简单形式
msgflg:控制着队列中没有相应类型的消息可供接收时将要发⽣生的事
返回值:成功返回实际放到接收缓冲区⾥里去的字符个数,失败返回-1
说明:
msgtype=0返回队列第⼀一条信息
msgtype>0返回队列第⼀一条类型等于msgtype的消息
msgtype<0返回队列第⼀一条类型⼩小于等于msgtype绝对值的消息,并且是满⾜足条件的消息类型最⼩小的消息
msgflg=IPC_NOWAIT,队列没有可读消息不等待,返回ENOMSG错误。
msgflg=MSG_NOERROR,消息⼤大⼩小超过msgsz时被截断
msgtype>0且msgflg=MSG_EXCEPT,接收类型不等于msgtype的第⼀一条消息
6.3示例
消息队列实现进程间通信
comm.h
using namespace std;
#define PATHNAME "."
#define PROJ_ID 0x6666
#define SERVER_TYPE 1
#define CLIENT_TYPE 2
struct msgbbuf{
long mtype;
char mtext[1024];
};
static int commMsgQueue(int flags)
{
key_t _key = ftok(PATHNAME, PROJ_ID);
if(_key < 0)
{
cerr<<"ftok"<<endl;
return -1;
}
int msgid = msgget(_key, flags);
if(msgid < 0)
{
cerr<<"msgget"<<endl;
}
return msgid;
}
int createMsgQueue()
{
return commMsgQueue(IPC_CREAT|IPC_EXCL|0666);
}
int getMsgQueue()
{
return commMsgQueue(IPC_CREAT);
}
int destroyMsgQueue(int msgid)
{
if(msgctl(msgid, IPC_RMID, NULL)<0)
{
cerr<<"msgctl"<<endl;
return -1;
}
return 0;
}
int sendMsg(int msgid, int who, char *msg)
{
struct msgbbuf buf;
buf.mtype = who;
strcpy(buf.mtext, msg);
if(msgsnd(msgid, (void*)&buf, sizeof(buf.mtext),0)<0)
{
cerr<<"msgsnd"<<endl;
return -1;
}
return 0;
}
int recvMsg(int msgid, int recvType, char out[])
{
struct msgbbuf buf;
if(msgrcv(msgid, (void*)&buf, sizeof(buf.mtext), recvType,0) < 0)
{
cerr<<"msgrcv"<<endl;
return -1;
}
strcpy(out, buf.mtext);
return 0;
}
server.cpp
#include "comm.h"
int main()
{
int msgid = createMsgQueue();
char buf[1024];
while(1)
{
buf[0] = 0;
recvMsg(msgid, CLIENT_TYPE, buf);
printf("client# %s\n", buf);
printf("Please Enter# ");
fflush(stdout);
ssize_t s = read(0, buf, sizeof(buf));
if(s>0)
{
buf[s-1] = 0;
sendMsg(msgid, SERVER_TYPE, buf);
printf("send done, wait recv...\n");
}
}
destroyMsgQueue(msgid);
return 0;
}
client.hpp
#include "comm.h"
int main()
{
int msgid = getMsgQueue();
char buf[1024];
while(1)
{
buf[0] = 0;
printf("Please Enter# ");
fflush(stdout);
ssize_t s = read(0, buf, sizeof(buf));
if(s>0)
{
buf[s-1] = 0;
sendMsg(msgid, CLIENT_TYPE, buf);
printf("send done, wait recv...\n");
}
recvMsg(msgid, SERVER_TYPE, buf);
printf("server# %s\n", buf);
}
return 0;
}
结果展示
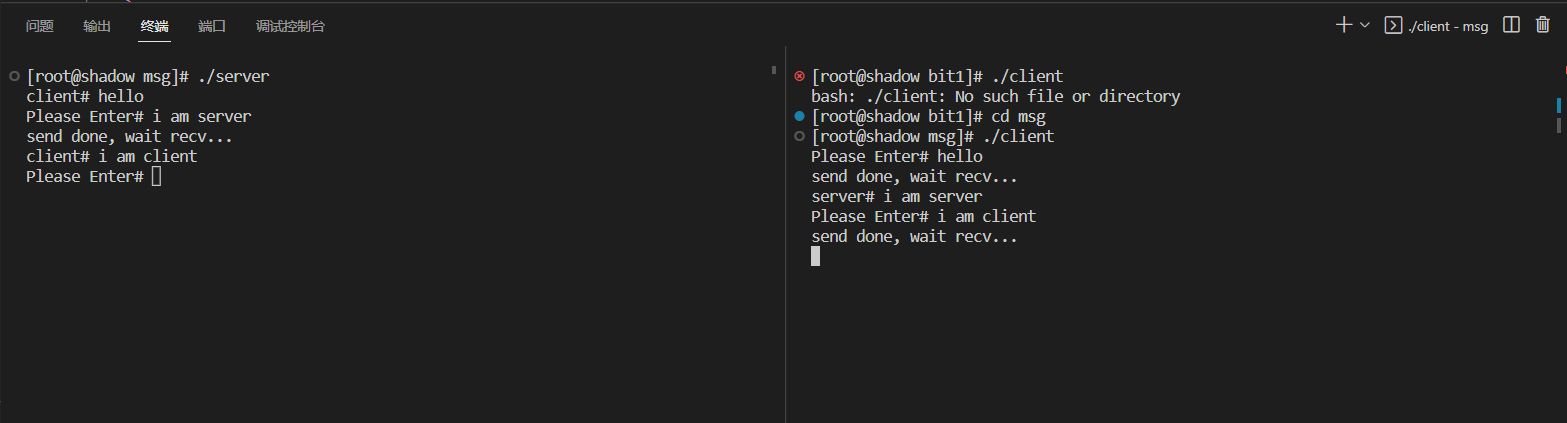
7.System V信号量
信号量的作用是保证进程间通信的同步和互斥。
下面是一些重要概念
临界资源
临界资源:被多个进程或者线程,能够同时看到的资源。
解释:如果没有对临界资源进行保护,多个进程多临界资源进行访问时,就会出现乱序。比较经典的例子是:父子进程向stdout打印是乱序的。
临界区
临界区:访问临界资源的代码段
原子性
原子性:我们把一件事,要么做完,要么不做,没有中间状态,叫做该动作是原子的。
互斥
互斥:任何时刻,都只有一个进程或者线程在访问临界资源
7.1信号量的数据结构
struct semid_ds {
struct ipc_perm sem_perm; /* permissions .. see ipc.h */
__kernel_time_t sem_otime; /* last semop time */
__kernel_time_t sem_ctime; /* last change time */
struct sem *sem_base; /* ptr to first semaphore in array */
struct sem_queue *sem_pending; /* pending operations to be processed */
struct sem_queue **sem_pending_last; /* last pending operation */
struct sem_undo *undo; /* undo requests on this array */
unsigned short sem_nsems; /* no. of semaphores in array */
};
和消息队列和共享内存一样,权限信息存放在ipc_perm结构体中
struct ipc_perm{
__kernel_key_t key;
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode;
unsigned short seq;
};
7.2信息量的接口
semget函数
功能:⽤用来创建和访问⼀一个信号量集
原型
int semget(key_t key, int nsems, int semflg);
参数
key: 信号集的名字
nsems:信号集中信号量的个数
semflg: 由九个权限标志构成,它们的⽤用法和创建⽂文件时使⽤用的mode模式标志是⼀一样的
返回值:成功返回⼀一个⾮非负整数,即该信号集的标识码;失败返回-1
shmctl函数
功能:⽤用于控制信号量集
原型
int semctl(int semid, int semnum, int cmd, ...);
参数
semid:由semget返回的信号集标识码
semnum:信号集中信号量的序号
cmd:将要采取的动作(有三个可取值)
最后⼀一个参数根据命令不同⽽而不同
返回值:成功返回0;失败返回-1

semop函数
功能:⽤用来创建和访问⼀一个信号量集
原型
int semop(int semid, struct sembuf *sops, unsigned nsops);
参数
semid:是该信号量的标识码,也就是semget函数的返回值
sops:是个指向⼀一个结构数值的指针
nsops:信号量的个数
返回值:成功返回0;失败返回-1
说明
sembuf结构体:
struct sembuf {
short sem_num;
short sem_op;
short sem_flg;
};
sem_num是信号量的编号。
sem_op是信号量⼀一次PV操作时加减的数值,⼀一般只会⽤用到两个值:
⼀一个是“-1”,也就是P操作,等待信号量变得可⽤用;
另⼀一个是“+1”,也就是我们的V操作,发出信号量已经变得可⽤用
sem_flag的两个取值是IPC_NOWAIT或SEM_UNDO
7.3信号量的原理
信号量的本质是一个计数器
信号量本质上是⼀一个计数器
struct semaphore
{
int value;
pointer_PCB queue;
}
信号量的操作是原子的。当计数器为0,表示资源被使用完,大于0表示有资源可用的个数,小于0表示等待进程的个数。
信号量的PV原语
P原语 :用于申请信号量
P(s)
{
s.value = s.value--;
if (s.value < 0)
{
该进程状态置为等待状状态
将该进程的PCB插⼊入相应的等待队列s.queue末尾
}
}
V原语 :用于释放信号量
V(s)
{
s.value = s.value++;
if (s.value < =0)
{
唤醒相应等待队列s.queue中等待的⼀一个进程
改变其状态为就绪态
并将其插⼊入就绪队列
}
}
8.IPC资源管理
从上面IPC资源的数据结构可以看出,所有的资源都有一个ipc_prem的结构体,其他资源属性不同,而ipc_prem存放的是权限相关的数据,key唯一识别一个资源。
在内核中有一个ipc_ids的结构体管理着IPC相关资源
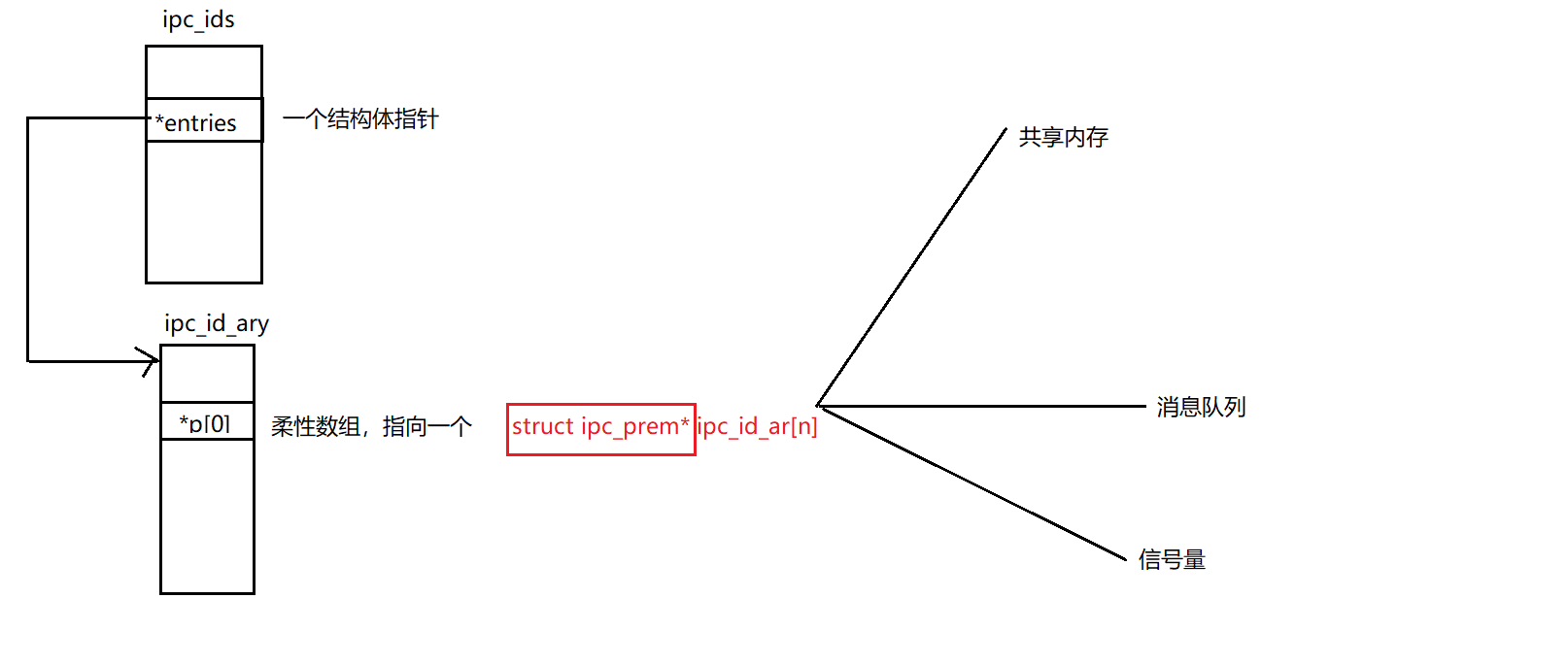
结构体指针和结构体第一个成员的指针在数值上是相等的,因此在需要具体类型时,可以强制类型转化为相应的类型即可。比如创建一个共享内存,可以强制类型转为struct shmid_ds*类型
因为所有的IPC资源第一个成员都是struct ipc_prem;所以内核只需要管理struc ipc_prem数值,就可以管理所有的IPC资源。
这也是最早的多态技术。
9.mmap共享映射区
原理图片
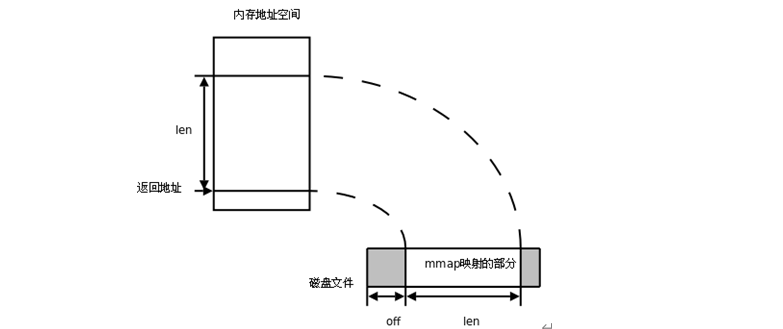
mmap是直接操作内存,是进程间通信速度最快的方式。
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,int fd, off_t offset);
/*
参数说明
addr:以前需要传递一个映射到的内存地址,现在只需传递NULL即可
length mmap映射的部分的长度。
prot:端口的权限描述
PROT_READ 可读
PROT_WRITE 可写
flags:(对内存和文件之间关系的描述)
MAP_SHARED 共享的,对内存的修改会影原文件
MAP_PRIVATE 私有的,对内存的修改不会影响原文件
fd:
文件描述符,需要用open函数打开一个文件
offset:
偏移量
返回值:
成功:返回可用的内存首地址
失败:返回信号MAP_FAILED
*/
//释放内存
int munmap(void *addr, size_t length);
/*
参数说明:
addr:需要释放内存的首地址,一般为mmap的返回值
length:释放内存的长度
返回值:
成功:0
失败:-1
*/
9.1mmap使用实例
创建book.txt文件,并在book.txt中输入xxxxxxxxxxxxx
mmaptest.c文件
int main()
{
//具有读写的的权利
int fd=open("book.txt",O_RDWR);
//映射长度为8,端口权限为可读可写,内存权限为共享,偏移量为0
char* mem=mmap(NULL,8,PROT_READ|PROT_WRITE,MAP_SHARED,fd,0);
//如果没有映射成功
if(mem==MAP_FAILED)
{
perror("mem err");
return -1;
}
strcpy(mem,"hello");
munmap(mem,8);
close(fd);
return 0;
}
编译文件
$ gcc mmaptest.c -o mmaptest
$ ./mmaptest
$ cat book.txt
输出:helloxxxxxxxxxxxxxxxxx
9.2mmap常见的问题
- 如果更改mem变量的地址,释放mummap时,mem传入失败
- 文件的偏移量,应该是是4k(4096)的整数倍。
- open文件选择O_WRONLY可以吗?不可以,内存映射的过程有读取文件的操作
- 选择MAP_SHARED的时候,,prot选择PROT_READ|PROT_WRITE,open文件应该选择可读可写O_RDWR。否则权限会发生冲突。
9.3mmap实现父子进程通信
int main()
{
//创建映射区
int fd=open("book.txt",O_RDWR);
int* mem=mmap(NULL,4,PROT_READ|PROT_WRITE,MAP_SHARED,fd,0);
if(mem==MAP_FALIED)
{
perror("mem err");
return -1;
}
//创建子进程
pid_t pid=fork();
//修改内存映射区的值
if(pid==0)
{
*mem=100;
printf("child mem: %d\n",*mem);
sleep(3);
printf("child mem: %d\n",*mem);
}
else if(pid>0)
{
sleep(1);
printf("parent mem: %d\n",*mem);
*mem=101;
printf("parent mem: %d\n",*mem);
//阻塞等待杀死子进程
wait(NULL);
}
close(fd);
return 0;
}

在上述父子进程通信中,需要打开一个文件作为通信的中介。对于空间是一种占用,所以linux文件系统有匿名映射的方式。
9.4匿名映射
使用映射区来完成文件读写操作十分方便,父子进程间通信也比较容易。但是缺点是,每次创建映射区都依赖一个文件才能完成,通常建立映射区要open一个临时文件,创建好了再unlink,close。
linux系统提供了创建匿名映射区的方法,无需依赖一个文化即可创建映射区。同样需要借助标志位参数flags来指定。使用宏MAP_ANONYMOUS (或者MAP_ANON)
//例子
int*p=mmap(NULL,size,PROT_READ|PROT_WRITE,MAP_SHARED|MAP_ANONYMOUS, -1, offset);
需注意的是,MAP_ANONYMOUS和MAP_ANON这两个宏是Linux操作系统特有的宏。在类Unix系统中如无该宏定义,可使用如下两步来完成匿名映射区的建立。
int fd=open("/dev/zero",O_RDWR);
// /dev/zero可以随意的映射 /dev/null一般错误信息重定向到改文件中
void*p=mmap(NULL,size,PROT_READ|PROT_WRITE,MMAP_SHARED,fd,0)
对于上述父子进程通信的程序,只需要修改创建映射区的部分
int* mem=mmap(NULL,4,PROT_READ|PROT_WRITE,MAP_SHARED|MAP_ANON,-1,0)

9.5mmap实现无血缘关系的进程通信
实质上mmap是内核借助文件帮我们创建了一个映射区,多个进程之间利用该映射区完成数据传递。**由于内核空间多进程共享,因此无血缘关系的进程间也可以使用mmap来完成通信。**只要设置相应的标志位参数flags即可。若想实现共享,当然应该使用MAP_SHARED了。
mmapnorelt_w.c用于修改共享内存区域的数据
typedef struct student
{
int number;
char name[20];
}student;
int main(int argc,char* argv[])
{
if(argc!=2)
{
printf("./a.out filename\n");
return -1;
}
//打开文件
int fd=open(argv[1],O_RDWR);
ftruncate(fd,sizeof(student));
int length=sizeof(student);
//创建映射区
student* stu=mmap(NULL,length,PROT_READ|PROT_WRITE,MAP_SHARED,fd,0);
if(stu==MAP_FAILED)
{
perror("stu err");
return -1;
}
//改变内存数据
int num=1;
while(1)
{
stu->number=num;
sprintf(stu->name,"stu_name%4d",num++);
sleep(1);
}
//关闭内存映射区
munmap(stu,length);
close(fd);
return 0;
}
mmapnorelt_r.c,用于读取内存映射区域的数据
typedef struct student
{
int number;
char name[20];
}student;
int main(int argc,char* argv[])
{
if(argc!=2)
{
printf("./a.out filename\n");
return -1;
}
//打开文件
int fd=open(argv[1],O_RDWR);
int length=sizeof(student);
student* stu=mmap(NULL,length,PROT_READ|PROT_WRITE,MAP_SHARED,fd,0);
if(stu==MAP_FAILED)
{
perror("stu err");
return -1;
}
while(1)
{
printf("stu->number: %d stu->name: %s\n",stu->number,stu->name);
sleep(1);
}
//关闭内存区域和文件
munmap(stu,length);
close(fd);
return 0;
}
编译文件
$ touch norelt.txt
$ gcc mmapnorelt_r.c -o mmapnorelt_r
$ gcc mmapnorelt_w.c -o mmapnorelt_w
$ ./mmaonorelt_w norelt.txt
$ ./mmaonorelt_r norelt.txt