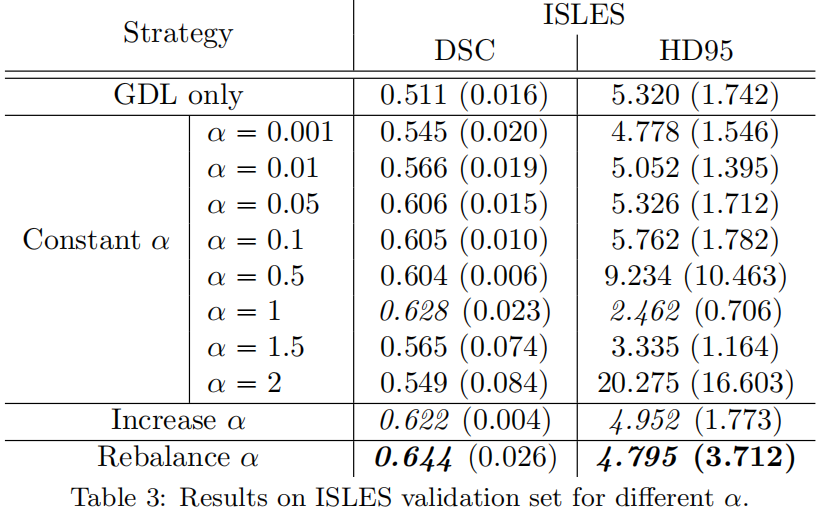
11 位运算效率更高
如果你读过 JDK 的源码,比如 ThreadLocal、HashMap 等类,你就会发现,它们的底层都用了位运算。
为什么开发 JDK 的大神们,都喜欢用位运算?
答:因为位运算的效率更高。
在 ThreadLocal 的 get、set、remove 方法中都有这样一行代码:
int i = key.threadLocalHashCode & (len-1);通过 key 的 hashCode 值,与数组的长度减 1。其中 key 就是 ThreadLocal 对象,与数组的长度减 1,相当于除以数组的长度减 1,然后取模。
这是一种 hash 算法。
接下来给大家举个例子:假设 len=16,key.threadLocalHashCode=31,
于是:int i = 31 & 15 = 15
相当于:int i = 31 % 16 = 15
计算的结果是一样的,但是使用与运算效率跟高一些。
为什么与运算效率更高?
答:因为 ThreadLocal 的初始大小是 16,每次都是按 2 倍扩容,数组的大小其实一直都是 2 的 n 次方。
这种数据有个规律就是高位是 0,低位都是 1。在做与运算时,可以不用考虑高位,因为与运算的结果必定是 0。只需考虑低位的与运算,所以效率更高。
12 巧用第三方工具类
在 Java 的庞大体系中,其实有很多不错的小工具,也就是我们平常说的轮子。
如果在我们的日常工作当中,能够将这些轮子用户,再配合一下 IDEA 的快捷键,可以极大得提升我们的开发效率。
如果你引入 com.google.guava 的 pom 文件,会获得很多好用的小工具。这里推荐一款 com.google.common.collect 包下的集合工具 Lists。
它是在太好用了,让我爱不释手。
如果你想将一个大集合分成若干个小集合。
之前我们是这样做的:
List<Integer> list = Lists.newArrayList(1, 2, 3, 4, 5);
List<List<Integer>> partitionList = Lists.newArrayList();
int size = 0;
List<Integer> dataList = Lists.newArrayList();
for(Integer data : list) {
if(size >= 2) {
dataList = Lists.newArrayList();
size = 0;
}
size++;
dataList.add(data);
}将 list 按 size=2 分成多个小集合,上面的代码看起来比较麻烦。
如果使用 Lists 的 partition 方法,可以这样写代码:
List<Integer> list = Lists.newArrayList(1, 2, 3, 4, 5);
List<List<Integer>> partitionList = Lists.partition(list, 2);
System.out.println(partitionList);执行结果:
[[1, 2], [3, 4], [5]]这个例子中,list 有 5 条数据,我将list集合按大小为 2,分成了 3 页,即变成 3 个小集合。这个是我最喜欢的方法之一,经常在项目中使用。
比如有个需求:现在有 5000 个 id,需要调用批量用户查询接口,查出用户数据。但如果你直接查 5000 个用户,单次接口响应时间可能会非常慢。如果改成分页处理,每次只查 500 个用户,异步调用 10 次接口,就不会有单次接口响应慢的问题。
13 用同步代码块代替同步方法
在某些业务场景中,为了防止多个线程并发修改某个共享数据,造成数据异常。
为了解决并发场景下,多个线程同时修改数据,造成数据不一致的情况。通常情况下,我们会加锁。
但如果锁加得不好,导致锁的粒度太粗,也会非常影响接口性能。
在 Java 中提供了 synchronized 关键字给我们的代码加锁。
通常有两种写法:在方法上加锁 和 在代码块上加锁。
先看看如何在方法上加锁:
public synchronized doSave(String fileUrl) {
mkdir();
uploadFile(fileUrl);
sendMessage(fileUrl);
}这里加锁的目的是为了防止并发的情况下,创建了相同的目录,第二次会创建失败,影响业务功能。
但这种直接在方法上加锁,锁的粒度有点粗。因为 doSave 方法中的上传文件和发消息方法,是不需要加锁的。只有创建目录方法,才需要加锁。
我们都知道文件上传操作是非常耗时的,如果将整个方法加锁,那么需要等到整个方法执行完之后才能释放锁。显然,这会导致该方法的性能很差,变得得不偿失。
这时,我们可以改成在代码块上加锁了,具体代码如下:
public void doSave(String path,String fileUrl) {
synchronized(this) {
if(!exists(path)) {
mkdir(path);
}
}
uploadFile(fileUrl);
sendMessage(fileUrl);
}这样改造之后,锁的粒度一下子变小了,只有并发创建目录功能才加了锁。而创建目录是一个非常快的操作,即使加锁对接口的性能影响也不大。
最重要的是,其他的上传文件和发送消息功能,任然可以并发执行。
14 不用的数据及时清理
在 Java 中保证线程安全的技术有很多,可以使用 synchroized、Lock 等关键字给代码块加锁。
但是它们有个共同的特点,就是加锁会对代码的性能有一定的损耗。
其实,在jdk中还提供了另外一种思想即用空间换时间。
没错,使用 ThreadLocal 类就是对这种思想的一种具体体现。
ThreadLocal 为每个使用变量的线程提供了一个独立的变量副本,这样每一个线程都能独立地改变自己的副本,而不会影响其它线程所对应的副本。
ThreadLocal 的用法大致是这样的:
1) 先创建一个 CurrentUser 类,其中包含了 ThreadLocal 的逻辑。
public class CurrentUser {
private static final ThreadLocal<UserInfo> THREA_LOCAL = new ThreadLocal();
public static void set(UserInfo userInfo) {
THREA_LOCAL.set(userInfo);
}
public static UserInfo get() {
THREA_LOCAL.get();
}
public static void remove() {
THREA_LOCAL.remove();
}
}2) 在业务代码中调用 CurrentUser 类。
public void doSamething(UserDto userDto) {
UserInfo userInfo = convert(userDto);
CurrentUser.set(userInfo);
...
//业务代码
UserInfo userInfo = CurrentUser.get();
...
}在业务代码的第一行,将 userInfo 对象设置到 CurrentUser,这样在业务代码中,就能通过 CurrentUser.get() 获取到刚刚设置的 userInfo 对象。特别是对业务代码调用层级比较深的情况,这种用法非常有用,可以减少很多不必要传参。
但在高并发的场景下,这段代码有问题,只往 ThreadLocal 存数据,数据用完之后并没有及时清理。
ThreadLocal 即使使用了 WeakReference(弱引用)也可能会存在内存泄露问题,因为 entry 对象中只把 key(即 threadLocal 对象)置成了弱引用,但是 value 值没有。
那么,如何解决这个问题呢?
public void doSamething(UserDto userDto) {
UserInfo userInfo = convert(userDto);
try{
CurrentUser.set(userInfo);
...
//业务代码
UserInfo userInfo = CurrentUser.get();
...
} finally {
CurrentUser.remove();
}
}需要在 finally 代码块中,调用 remove 方法清理没用的数据。
15 用 equals 方法比较是否相等
不知道你在项目中有没有见过,有些同事对 Integer 类型的两个参数使用==号比较是否相等?
反正我见过的,那么这种用法对吗?
我的回答是看具体场景,不能说一定对,或不对。
有些状态字段,比如 orderStatus有:-1(未下单)、0(已下单),1(已支付),2(已完成)、3(取消)、5种状态。
这时如果用 == 判断是否相等:
Integer orderStatus1 = new Integer(1);
Integer orderStatus2 = new Integer(1);
System.out.println(orderStatus1 == orderStatus2);返回结果会是 true 吗?
答案:是 false。
有些同学可能会反驳,Integer 中不是有范围是 -128 ~ 127 的缓存吗?
为什么是 false?
先看看 Integer 的构造方法:
public Integer(int value) {
this.value = value;
}它其实并没有用到缓存。那么缓存是在哪里用的?
答案在 valueOf 方法中:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high) {
return IntegerCache.cache[i + (-IntegerCache.low)];
}
return new Integer(i);
}如果上面的判断改成这样:
String orderStatus1 = new String("1");
String orderStatus2 = new String("1");
System.out.println(Integer.valueOf(orderStatus1) == Integer.valueOf(orderStatus2));返回结果会是 true 吗?
答案:还真是 true。
我们要养成良好编码习惯,尽量少用 == 判断两个 Integer 类型数据是否相等,只有在上述非常特殊的场景下才相等。
而应该改成使用 equals 方法判断:
Integer orderStatus1 = new Integer(1);
Integer orderStatus2 = new Integer(1);
System.out.println(orderStatus1.equals(orderStatus2));运行结果为 true。
16 避免创建大集合
很多时候,我们在日常开发中,需要创建集合。比如为了性能考虑,从数据库查询某张表的所有数据,一次性加载到内存的某个集合中,然后做业务逻辑处理。
例如:
List<User> userList = userMapper.getAllUser();
for(User user:userList) {
doSamething();
}从数据库一次性查询出所有用户,然后在循环中,对每个用户进行业务逻辑处理。
如果用户表的数据量非常多时,这样 userList 集合会很大,可能直接导致内存不足,而使整个应用挂掉。
针对这种情况,必须做分页处理。
例如:
private static final int PAGE_SIZE = 500;
int currentPage = 1;
RequestPage page = new RequestPage();
page.setPageNo(currentPage);
page.setPageSize(PAGE_SIZE);
Page<User> pageUser = userMapper.search(page);
while(pageUser.getPageCount() >= currentPage) {
for(User user:pageUser.getData()) {
doSamething();
}
page.setPageNo(++currentPage);
pageUser = userMapper.search(page);
}通过上面的分页改造之后,每次从数据库中只查询 500 条记录,保存到 userList 集合中,这样 userList 不会占用太多的内存。
这里特别说明一下,如果你查询的表中的数据量本来就很少,一次性保存到内存中,也不会占用太多内存,这种情况也可以不做分页处理。
此外,还有中特殊的情况,即表中的记录数并算不多,但每一条记录,都有很多字段,单条记录就占用很多内存空间,这时也需要做分页处理,不然也会有问题。
整体的原则是要尽量避免创建大集合,导致内存不足的问题,但是具体多大才算大集合。目前没有一个唯一的衡量标准,需要结合实际的业务场景进行单独分析。
17 状态用枚举
在我们建的表中,有很多状态字段,比如订单状态、禁用状态、删除状态等。
每种状态都有多个值,代表不同的含义。
比如订单状态有:
-
1:表示下单
-
2:表示支付
-
3:表示完成
-
4:表示撤销
如果没有使用枚举,一般是这样做的:
public static final int ORDER_STATUS_CREATE = 1;
public static final int ORDER_STATUS_PAY = 2;
public static final int ORDER_STATUS_DONE = 3;
public static final int ORDER_STATUS_CANCEL = 4;
public static final String ORDER_STATUS_CREATE_MESSAGE = "下单";
public static final String ORDER_STATUS_PAY = "下单";
public static final String ORDER_STATUS_DONE = "下单";
public static final String ORDER_STATUS_CANCEL = "下单";需要定义很多静态常量,包含不同的状态和状态的描述。
使用枚举定义之后,代码如下:
public enum OrderStatusEnum {
CREATE(1, "下单"),
PAY(2, "支付"),
DONE(3, "完成"),
CANCEL(4, "撤销");
private int code;
private String message;
OrderStatusEnum(int code, String message) {
this.code = code;
this.message = message;
}
public int getCode() {
return this.code;
}
public String getMessage() {
return this.message;
}
public static OrderStatusEnum getOrderStatusEnum(int code) {
return Arrays.stream(OrderStatusEnum.values()).filter(x -> x.code == code).findFirst().orElse(null);
}
}使用枚举改造之后,职责更单一了。
而且使用枚举的好处是:
-
代码的可读性变强了,不同的状态,有不同的枚举进行统一管理和维护。
-
枚举是天然单例的,可以直接使用 == 号进行比较。
-
code 和 message 可以成对出现,比较容易相关转换。
-
枚举可以消除 if...else 过多问题。
18 把固定值定义成静态常量
不知道你在实际的项目开发中,有没有使用过固定值?
例如:
if(user.getId() < 1000L) {
doSamething();
}或者:
if(Objects.isNull(user)) {
throw new BusinessException("该用户不存在");
}其中 1000L 和该用户不存在是固定值,每次都是一样的。
既然是固定值,我们为什么不把它们定义成静态常量呢?
这样语义上更直观,方便统一管理和维护,更方便代码复用。
代码优化为:
private static final int DEFAULT_USER_ID = 1000L;
...
if(user.getId() < DEFAULT_USER_ID) {
doSamething();
}或者:
private static final String NOT_FOUND_MESSAGE = "该用户不存在";
...
if(Objects.isNull(user)) {
throw new BusinessException(NOT_FOUND_MESSAGE);
}使用 static final 关键字修饰静态常量,static 表示静态的意思,即类变量,而 final 表示不允许修改。
两个关键字加在一起,告诉 Java 虚拟机这种变量,在内存中只有一份,在全局上是唯一的,不能修改,也就是静态常量。
19. 避免大事务
很多小伙伴在使用 Spring 框架开发项目时,为了方便,喜欢使用 @Transactional 注解提供事务功能。
没错,使用 @Transactional 注解这种声明式事务的方式提供事务功能,确实能少写很多代码,提升开发效率。
但也容易造成大事务,引发其他的问题。
下面用一张图看看大事务引发的问题。

从图中能够看出,大事务问题可能会造成接口超时,对接口的性能有直接的影响。
我们该如何优化大事务呢?
-
少用 @Transactional 注解
-
将查询 (select) 方法放到事务外
-
事务中避免远程调用
-
事务中避免一次性处理太多数据
-
有些功能可以非事务执行
-
有些功能可以异步处理
20 消除过长的 if...else
我们在写代码的时候,if...else 的判断条件是必不可少的。不同的判断条件,走的代码逻辑通常会不一样。
废话不多说,先看看下面的代码。
public interface IPay {
void pay();
}
@Service
public class AliaPay implements IPay {
@Override
public void pay() {
System.out.println("===发起支付宝支付===");
}
}
@Service
public class WeixinPay implements IPay {
@Override
public void pay() {
System.out.println("===发起微信支付===");
}
}
@Service
public class JingDongPay implements IPay {
@Override
public void pay() {
System.out.println("===发起京东支付===");
}
}
@Service
public class PayService {
@Autowired
private AliaPay aliaPay;
@Autowired
private WeixinPay weixinPay;
@Autowired
private JingDongPay jingDongPay;
public void toPay(String code) {
if ("alia".equals(code)) {
aliaPay.pay();
} elseif ("weixin".equals(code)) {
weixinPay.pay();
} elseif ("jingdong".equals(code)) {
jingDongPay.pay();
} else {
System.out.println("找不到支付方式");
}
}
}PayService 类的 toPay 方法主要是为了发起支付,根据不同的 code,决定调用用不同的支付类(比如 aliaPay)的 pay 方法进行支付。
这段代码有什么问题呢?也许有些人就是这么干的。
试想一下,如果支付方式越来越多,比如又加了百度支付、美团支付、银联支付等等,就需要改 toPay 方法的代码,增加新的 else...if 判断,判断多了就会导致逻辑越来越多?
很明显,这里违法了设计模式六大原则的:开闭原则和单一职责原则。
开闭原则:对扩展开放,对修改关闭。就是说增加新功能要尽量少改动已有代码。
单一职责原则:顾名思义,要求逻辑尽量单一,不要太复杂,便于复用。
那么,如何优化 if...else 判断呢?
答:使用策略模式+工厂模式。
策略模式定义了一组算法,把它们一个个封装起来, 并且使它们可相互替换。工厂模式用于封装和管理对象的创建,是一种创建型模式。
public interface IPay {
void pay();
}
@Service
public class AliaPay implements IPay {
@PostConstruct
public void init() {
PayStrategyFactory.register("aliaPay", this);
}
@Override
public void pay() {
System.out.println("===发起支付宝支付===");
}
}
@Service
public class WeixinPay implements IPay {
@PostConstruct
public void init() {
PayStrategyFactory.register("weixinPay", this);
}
@Override
public void pay() {
System.out.println("===发起微信支付===");
}
}
@Service
public class JingDongPay implements IPay {
@PostConstruct
public void init() {
PayStrategyFactory.register("jingDongPay", this);
}
@Override
public void pay() {
System.out.println("===发起京东支付===");
}
}
public class PayStrategyFactory {
private static Map<String, IPay> PAY_REGISTERS = new HashMap<>();
public static void register(String code, IPay iPay) {
if (null != code && !"".equals(code)) {
PAY_REGISTERS.put(code, iPay);
}
}
public static IPay get(String code) {
return PAY_REGISTERS.get(code);
}
}
@Service
public class PayService3 {
public void toPay(String code) {
PayStrategyFactory.get(code).pay();
}
}这段代码的关键是 PayStrategyFactory 类,它是一个策略工厂,里面定义了一个全局的 map,在所有 IPay 的实现类中注册当前实例到 map 中,然后在调用的地方通过 PayStrategyFactory 类根据 code 从 map 获取支付类实例即可。
如果加了一个新的支付方式,只需新加一个类实现 IPay 接口,定义 init 方法,并且重写 pay 方法即可,其他代码基本上可以不用动。
当然,消除又臭又长的 if...else 判断,还有很多方法,比如使用注解、动态拼接类名称、模板方法、枚举等等。