什么是下拉框推荐
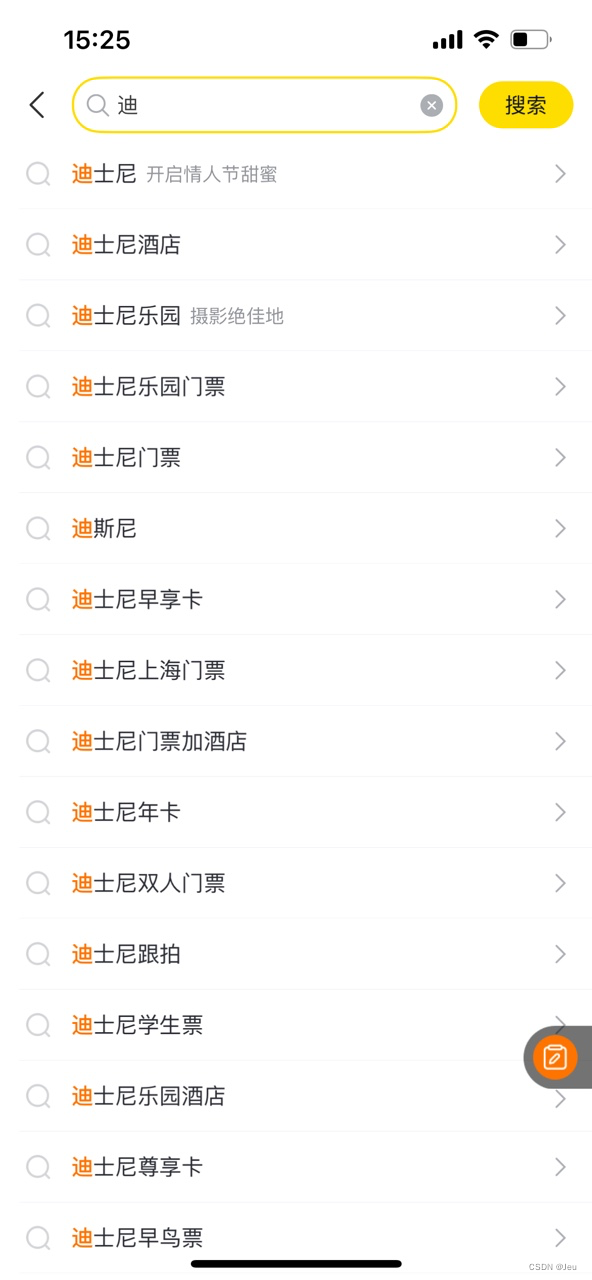
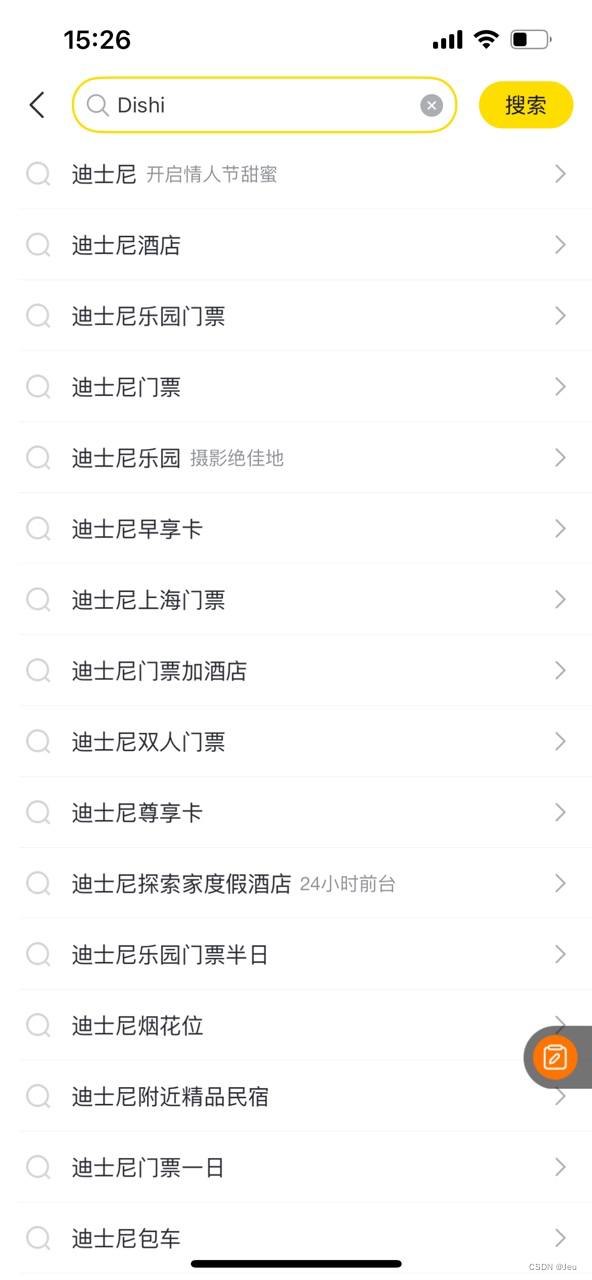
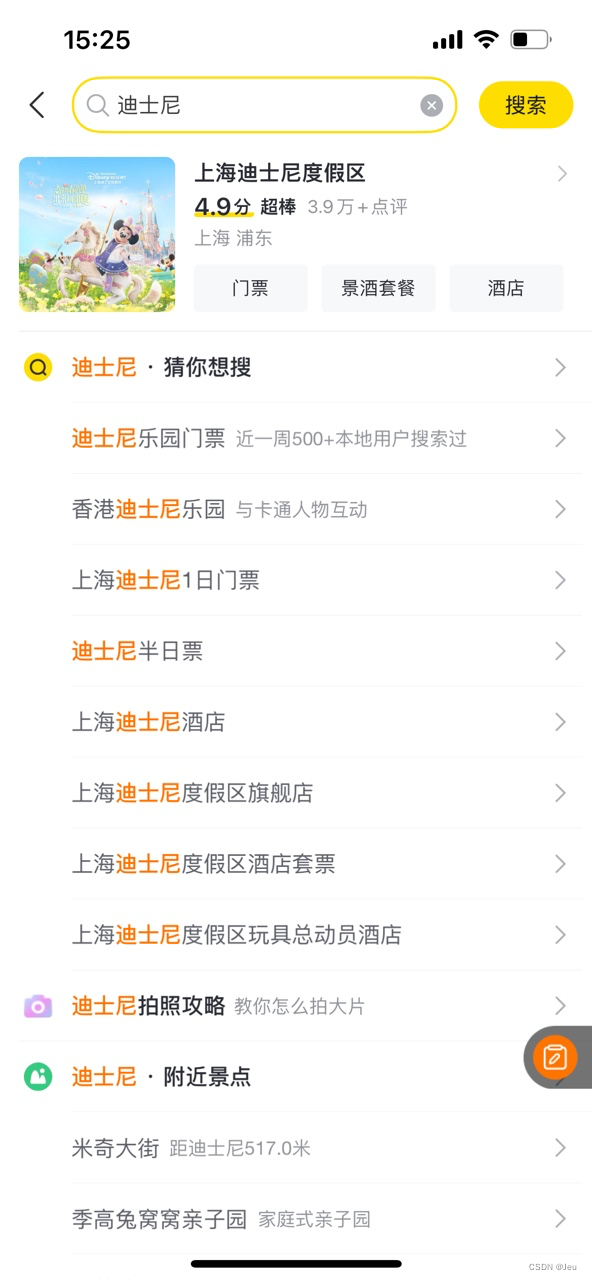
在我们使用各种app(飞猪)想要搜索我们想要的东西,假设我想要上海迪士尼的门票,那么精确的query是“上海迪士尼门票”,要打7个字,如果在你输入“上海”的时候app就推荐了query“上海迪士尼门票”,你不需要继续输入,直接点击这个query就ok;再举个例子,你不小心输入了“dishi”,app帮你自动纠错并推荐了“迪士尼门票”等query,对于用户来说,体验是不是一下就变好了,降低了我们输入的成本。
这就是下拉框推荐,也称为suggest-sug。搜索场景中,搜索list页的query大部分是从sug引导过去的,这就意味着sug推荐的query好坏对后续链路的转化有着重要影响,sug不仅要推荐用户想要的query,还要确保搜索能承接住这个query,保证有搜索结果。
如何召回
- 前缀召回-根据用户的输入前向匹配召回-上海:上海的景点、上海的酒店、上海
- 包含召回-召回的query包含用户输入-迪士尼:上海迪士尼门票、香港迪士尼乐园
- 分词包含召回-召回的query包含用户输入的分词结果,由分词的粒度决定召回效果-杭州一日游:杭州灵隐寺一日游、杭州西湖一日游
- 字召回-分词包含召回中最细粒度分词
- 拼音前缀召回-shang:上海、上海迪士尼-尚海:上海、上海迪士尼
- 简拼召回-hz:杭州
- 中英召回-杭z:杭州、杭州的景点
- 英文前缀召回-the twin:the twin tower
- 英文分词召回-twin tower:the twin tower
- 英文包含召回-twint:the twin tower
- 模糊召回-上海迪迪士尼:上海迪士尼乐园、上海迪士尼门票
- 向量召回:基于用户输入query的向量与库中向量进行匹配并根据相似度进行排序-成本高效果一般
- 生成式模型:基于用户的输入自动补全,可以产生库中没有的query,但很难满足线上的rt要求,且易产生搜索承接不住的query。但是可以离线保存这些query,扩充候选query库,并离线检测这些query搜索是否接得住
如何排序
- 排序模型:很多wide-deep模型都可以直接用,构建的特征包括两个大类:离散特征+连续特征。
- 离散特征主要是你召回query的相关特征:sug页uctr、pctr、结果页的(30天、15天、7天、3天)uctr、pctr、l2o、用户输入与召回query直接拼接之后的uctr等。用户输入与召回query之间的包含关系:如分词包含、前缀包含等
- 连续特征主要是用户的输入和你召回的query之间的关系:用户query与召回query的拼接等
- 额外特征:模型毕竟是黑盒的,所以最终排序的分数需要额外增加一些策略特征,如对召回的酒店query计算与用户之间的距离、对3天的uctr额外增加权重等
- 根据专家经验进行排序:如用户在北京输入“杭州”,可以离线人工构建一些泛 意图query如“杭州的酒店”、“杭州的景点”、“杭州一日游”、“北京到杭州的机票”、“灵隐寺”、“杭州西湖”...到机票的query是构造的排序,目的地的景点可以根据用户历史搜索的热度进行排序
如何纠错
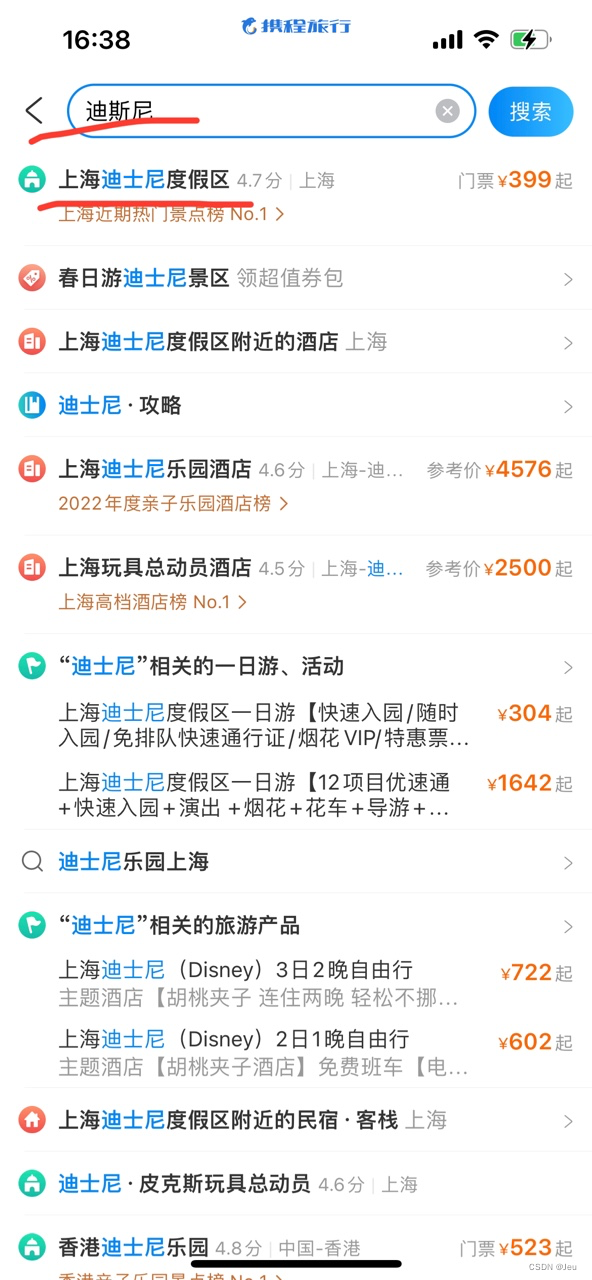
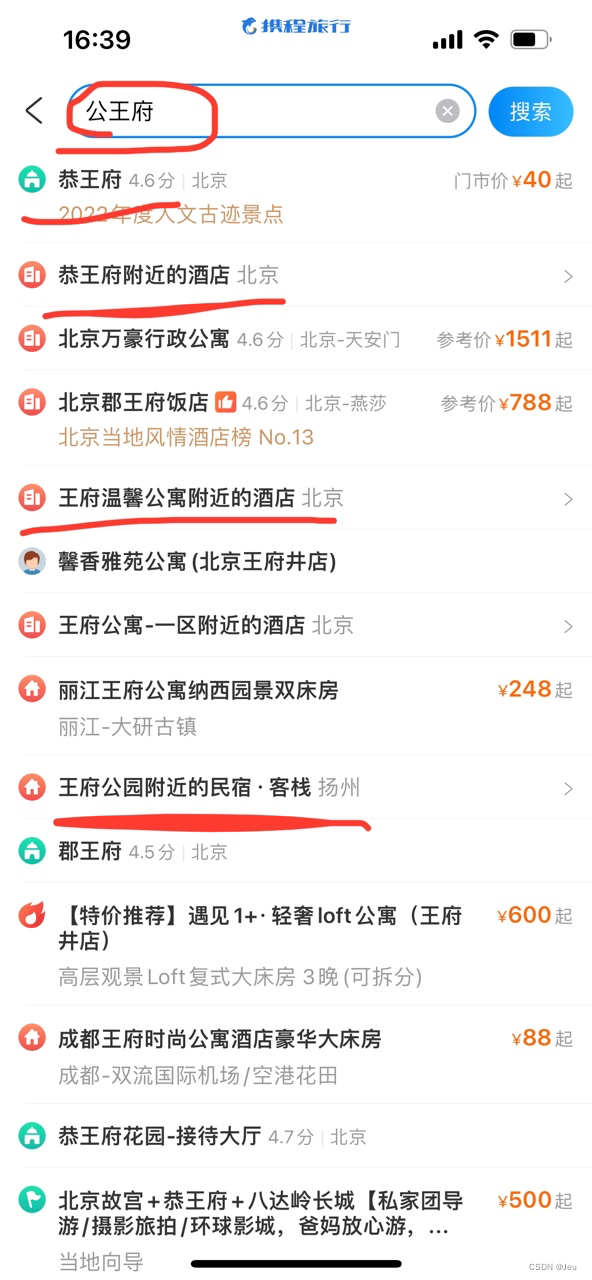
- 用户输入错误是很常见的情况,和输入法、query特征都有关系,如很多用户都会把“迪士尼”输成“迪斯尼”,把“恭王府”输成“公王府”,图1中全部使用了“迪士尼”进行了召回,图2中只有前两个query使用纠正之后的“恭王府”进行召回,其余还是用“错误”的“公王府”进行召回,如果没有纠错模型,召回的query并不是用户想搜的,用户还需要重新输入,相当于增加了用户的搜索成本,所以纠错模块是相当需要的。
- 纠错模型:相关链接-中文文本纠错调研 - nghuyong。离线构建训练集训练模型,再对用户历史输入query进行预测,筛选不同,人工校验,存入纠错库,预处理阶段对用户输入query进行修改。另一方面,专家经验也是相当重要的,可以基于用户输入的频率、点击率等输入产生一批候选待纠错query,一般这个量级不会很大,外包校验就ok。
业务结合
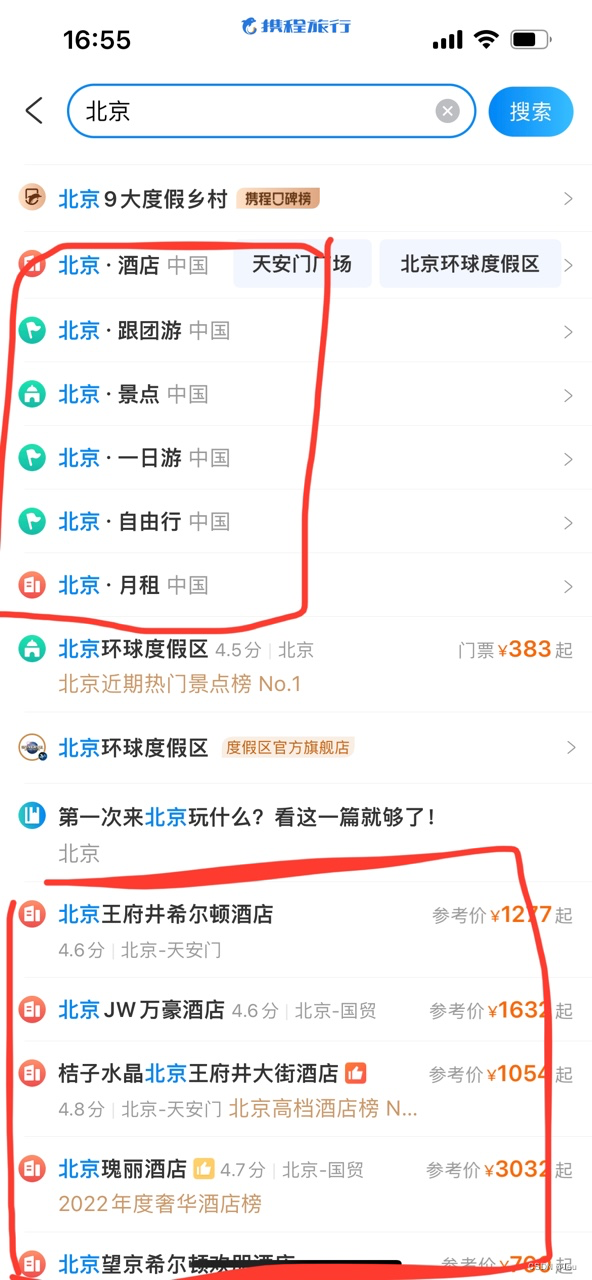
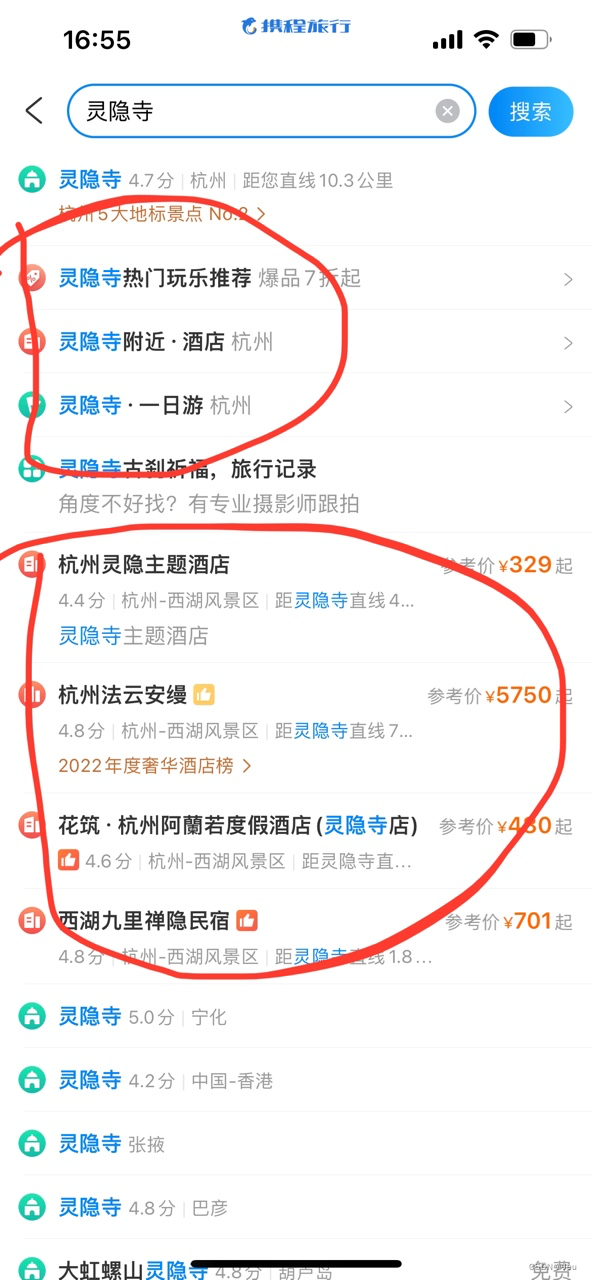
- 意图识别:构建意图库,对用户输入的query进行意图识别,并根据意图+专家经验进行不同的候选query的召回排序是很有必要的,下图,用户输入目的地意图“北京”,携程的做法是:构造一批泛意图query-目的地+酒店、景点、一日游等;目的地热门景点;北京的热门酒店。对于景点意图-poi-“灵隐寺”,做法是:poi+附近酒店、一日游;精准酒店;query普通召回。敢打赌,经过AB实验,这样搭配的策略该意图的点击率会比一般召回的点击率是高的,因为一些明确意图下,很难猜准用户的精确意图,泛化意图更能收敛,或者说用户也不知道具体自己要搜啥,那就看下大家都在搜啥。站在用户的角度,如果用户输入一个精准酒店名,该配什么样的策略?我觉得精准酒店+该精准酒店附近的酒店(给出附近酒店与精准酒店的距离,并基于距离、评分、价格等因素排序)就比较合适。
- 与工程结合,实时的定坑能力:无论在携程,还是在飞猪、美团,会有各种各样的大促活动,如随心飞,酒店打折等活动,产品运营需要对一些query进行定坑配置,如用户输入目的地“法喜寺”时,想要在坑位3配置“打卡拍照攻略”,线上能实时生效,这就需要和工程端联合开发这种能力,并把这种配置试试读取到线上
- 基于用于行为推荐:如果用户今天已经点击过某个query或者搜索过某个酒店,当再次搜索相关query时,是不是应该把用户历史行为相关的query放在前面呢?!就类似于默认页推荐吧
- 基于所有用户行为推荐:当用户搜索目的地“上海”时,在当前城市“上海迪士尼乐园”是个热度很高的query,放在前面推给用户一般是不会错的
- 异地搜索query推荐:用户在杭州输入“北京”,用户是存在交通意图的,所以“杭州到北京的机票”“杭州到北京的火车票”一般点击还挺高的
- 推荐query的丰富度:如上图所示,推一个干干的query是不是显得太单一了,可以根据不同类型的query去构建不同的标签,如POI-景点排名、景点特色;酒店-酒店标签、与用户距离等
- 确保推荐的query在结果页是有结果的或者能解析的,这就需要和搜索端进行联合,sug端利用搜索端的日志进行query的筛选
- 确保sug页的top1与结果页的top1是相同的。举个例子,用户输入“鼓楼”,sug推荐第一个是“南京鼓楼”,用户点击“搜索”进入结果页的第一个是“西安鼓楼”,这就是不统一的,会给用户错觉,所以这部分明显意图的识别sug端要和搜索端联合起来。
评价指标
- sug uctr:最直观的指标,点击算法推荐的query的用户占比。100个用户请求1000次,60个用户点击过推荐的query,uctr=60%
- sug pctr:相对准确的指标,点击算法推荐的query的pv占比。100个用户请求1000次,50次点击过推荐的query,pctr=5%。问题在于用户逐字输入“hangzhou”,相当于8次请求,及时最后点击了,pctr也只有1/8
- 用户输入的平均字长:越短表明越好
- 用户输入的平均时长:越短表明越好
- sug无结果率:用户输入query的无结果率。
- list页的无结果率:用户点击sug推荐的query之后,在list页无结果的占比
- sug ppctr:我自己命名的指标,最精确的指标,用户每一次完整输入才算一次请求,逐字输入“上海迪士尼”时相当于1次输入,而不是5次输入,这样计算是最精确的。
- list页uctr:sug引导的结果页的uctr。点击sug推荐的query之后进入list页(结果页),结果页的商品是搜索推荐的,推荐的好坏将直接影响用户的点击,但是sug推荐词的好坏也是会影响点击,所以有影响,但只是间接影响。
- list页pctr:sug引导的结果页pctr,和list页uctr的原理差不多,还是间接影响因素
- l2o:sug引导的query的下单率。更间接的因素
- list页pv来自sug的占比:sug页点击率越大,这个占比就越大
监控指标
- 上述指标的监控
- query粒度的搜索量、点击率指标:这个很重要,提升sug的uctr几乎是最重要的任务,你可以从高搜索量低点击率的query入手,对这部分query进行优化召回排序,这样也可以快读定位问题
- query type粒度的搜索量、点击率指标:比query粒度更粗一些,上面提到有意图链路召回排序利用专家经验构建的必要性,这部分指标可以让你快速发现定位基于专家经验的召回排序问题。例如发现目的地意图的点击率明显低于其他意图,那就需要对目的地意图的召回排序进行针对性优化
- query粒度下用户点击习惯指标: 用于监控用户在该输入下喜欢点击的query排序,如统计所有用户输入“北京”时的点击情况,发现用户更喜欢点“北京的酒店”、“北京环球影城”等query,“北京的酒店套餐”几乎没人点,那就可以考虑把“北京的酒店套餐”这个query替换成别的query。这部分数据还可以用于猪搜场景下的“猜你想搜”模块,很通用的用户点击行为数据。
- sug推荐用户不点的指标:用户最终输入“上海”,且点击了搜索按钮,但在输入“上”时,sug已经推荐了“上海”这个query,但用户还是没有点,这说明这部分用户的习惯是点击搜索按钮或者输入法的返回键