3.3 流式应用状态
使用SparkStreaming处理实际实时应用业务时,针对不同业务需求,需要使用不同的函数。SparkStreaming流式计算框架,针对具体业务主要分为三类,使用不同函数进行处理:
业务一:无状态Stateless
- 使用transform和foreacRDD函数
- 比如实时增量数据ETL:实时从Kafka Topic中获取数据,经过初步转换操作,存储到Elasticsearch索引或HBase表中。
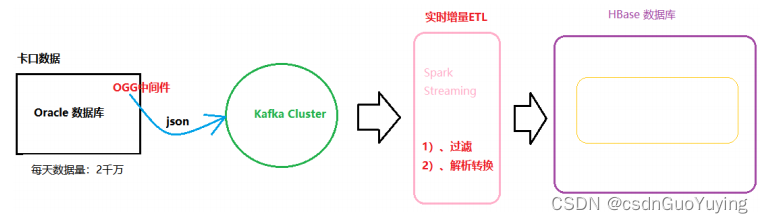
业务二:有状态State
- 双十一大屏幕所有实时累加统计数字(比如销售额和销售量等),比如销售额、网站PV、UV等等;
- 函数:updateStateByKey、mapWithState
业务三:窗口统计
- 每隔多久时间统计最近一段时间内数据,比如饿了么后台报表,每隔5分钟统计最近20分钟订单数。
- 苏宁搜索推荐时:
- 数据分析:统计搜索行为时间跨度,86%的搜索行为在5分钟内完成、90%的在10分钟内完成(从搜索开始到最后一次点击结果列表时间间隔);
- NDCG实时计算时间范围设定在15分钟,时间窗口为 15 分钟,步进 5 分钟,意味着每 5 分钟计算一次。每次计算,只对在区间[15 分钟前, 10 分钟前]发起的搜索行为进行 NDCG 计算,这样就不会造成重复计算
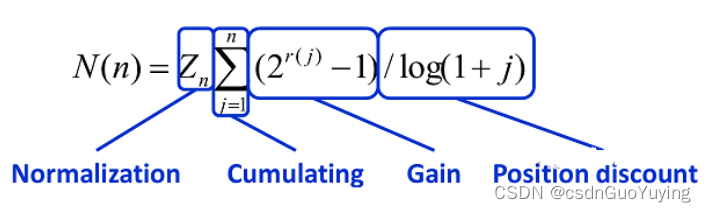
Normalized Discounted Cumulative Gain,即 NDCG,常用作搜索排序的评价指标,理想情况下排序越靠前的搜索结果,点击概率越大,即得分越高 (gain)。CG = 排序结果的得分求和, discounted 是根据排名,对每个结果得分 * 排名权重,权重 = 1/ log(1 + 排名) ,排名越靠前的权重越高。首先我们计算理想 DCG(称之为 IDCG),再根据用户点击结果, 计算真实的 DCG, NDCG = DCG / IDCG,值越接近 1, 则代表搜索结果越好。
4. 集成 Kafka
在实际项目中,无论使用Storm还是SparkStreaming与Flink,主要从Kafka实时消费数据进行处理分析,流式数据实时处理技术架构大致如下:
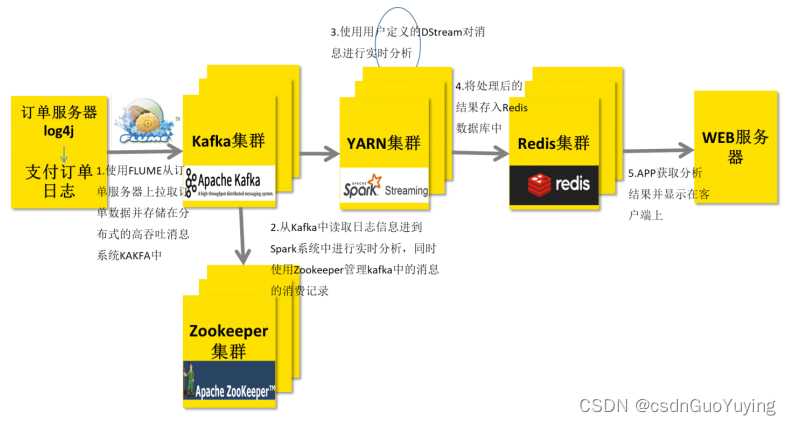
技术栈: Flume/SDK/Kafka Producer API -> KafKa —> SparkStreaming/Flink/Storm(Hadoop YARN) -> Redis -> UI
1)、阿里工具Canal:监控MySQL数据库binlog文件,将数据同步发送到Kafka Topic中
https://github.com/alibaba/canal
https://github.com/alibaba/canal/wiki/QuickStart
2)、Maxwell:实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。
http://maxwells-daemon.io/
https://github.com/zendesk/maxwell
扩展:Kafka 相关常见面试题:
1)、Kafka 集群大小(规模),Topic分区函数名及集群配置?
2)、Topic中数据如何管理?数据删除策略是什么?
3)、如何消费Kafka数据?
4)、发送数据Kafka Topic中时,如何保证数据发送成功?
4.1 整合Kafka 0.8.2
Apache Kafka: 最原始功能【消息队列】,缓冲数据,具有发布订阅功能(类似微信公众号)。
回顾 Kafka 概念
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用与大数据实时处理领域。
- 消息队列:Kafka 本质上是一个 MQ(Message Queue),使用消息队列的好处?(面试会问):
- 解耦:允许我们独立的扩展或修改队列两边的处理过程;
- 可恢复性:即使一个处理消息的进程挂掉,加入队列中的消息仍可以在系统恢复后被处理;
- 缓冲:有助于解决生产消息和消费消息的处理速度不一致的情况;
- 灵活性&峰值处理能力:不会因为突发的超负荷的请求而完全崩溃,消息队列能够使关键组件顶住突发的访问压力;
- 异步通信:消息队列允许用户把消息放入队列但不立即处理它;
- 发布/订阅模式:
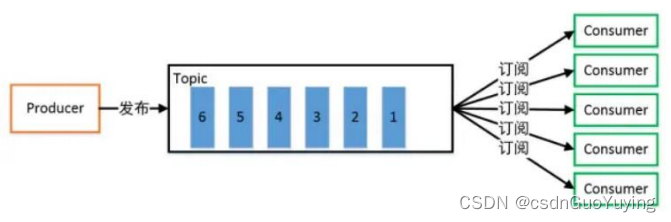
一对多,生产者将消息发布到 Topic 中,有多个消费者订阅该主题,发布到 Topic 的消息会被所有订阅者消费,被消费的数据不会立即从 Topic 清除。
Kafka 框架架构图如下所示:
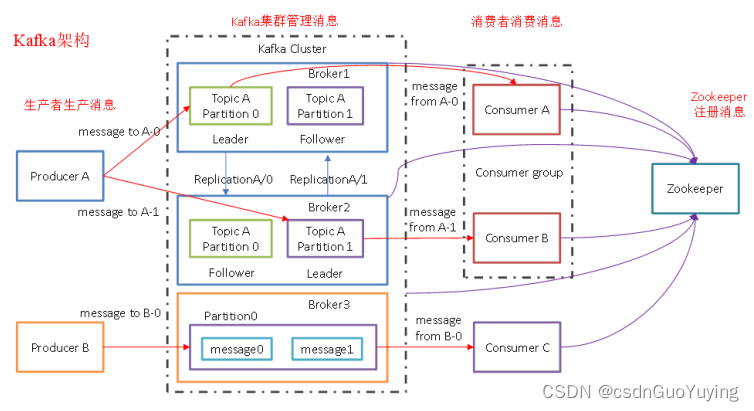
Kafka 存储的消息来自任意多被称为 Producer 生产者的进程,数据从而可以被发布到不同的Topic 主题下的不同 Partition 分区。在一个分区内,这些消息被索引并连同时间戳存储在一起。其它被称为 Consumer 消费者的进程可以从分区订阅消息。Kafka 运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群结点分布。Kafka 一些重要概念:
1)、Producer: 消息生产者,向 Kafka Broker 发消息的客户端;
2)、Consumer:消息消费者,从 Kafka Broker 取消息的客户端;
3)、Consumer Group:消费者组(CG),消费者组内每个消费者负责消费不同分区的数据,提高消费能力。一个分区只能由组内一个消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者;
4)、Broker:一台 Kafka 机器就是一个 Broker。一个集群由多个 Broker 组成。一个 Broker 可以容纳多个 Topic;
5)、Topic:可以理解为一个队列,Topic 将消息分类,生产者和消费者面向的是同一个 Topic;
6)、Partition:为了实现扩展性,提高并发能力,一个非常大的 Topic 可以分布到多个 Broker (即服务器)上,一个 Topic 可以分为多个 Partition,每个 Partition 是一个 有序的队列;
7)、Replica:副本,为实现备份的功能,保证集群中的某个节点发生故障时,该节点上的 Partition 数据不丢失,且 Kafka 仍然能够继续工作,Kafka 提供了副本机制,一个 Topic 的每个分区都有若干个副本,一个 Leader 和若干个 Follower;
8)、Leader:每个分区多个副本的“主”副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 Leader;
9)、Follower:每个分区多个副本的“从”副本,实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 还会成为新的 Leader;
10)、Offset:消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费;
11)、Zookeeper:Kafka 集群能够正常工作,需要依赖于 Zookeeper,Zookeeper 帮助 Kafka 存储和管理集群信息;