官方教程:https://huggingface.co/docs/transformers/training
准备数据集(基于datasets库)
train.json 数据格式:
{"source":"你是谁?", "target":"我是恁爹"}
{"source":"你多大了?", "target":"我五百岁了哦!"}
{"source": "我想吃火锅。", "target": "好的,我帮您找附近的火锅店。"}
{"source": "明天天气如何?", "target": "明天有雨,记得带伞。"}
加载数据集:
from datasets import load_dataset
data_files = {"train": "train.json", "validation": "validation.json"}
dataset = load_dataset('./data', data_files=data_files)
Tokenize 数据集:
def tokenize_function(example):
encoded = tokenizer(example["source"], truncation=True, padding="max_length", max_length=128)
# seq2seq模型需:with tokenizer.as_target_tokenizer():
encoded["labels"] = tokenizer(example["target"], truncation=True, padding="max_length", max_length=128)["input_ids"]
return encoded
# batched=True 可批量处理数据
tokenized_dataset = dataset.map(encode_data, batched=True)
print(tokenized_dataset.column_names)
{‘train’: [‘source’, ‘target’, ‘input_ids’, ‘attention_mask’, ‘labels’], ‘validation’: [‘source’, ‘target’, ‘input_ids’, ‘attention_mask’, ‘labels’]}
字段更名(仅供学习):
tokenized_dataset = tokenized_dataset.rename_column("source","sources")
tokenized_dataset
DatasetDict({
train: Dataset({
features: [‘sources’, ‘target’, ‘input_ids’, ‘attention_mask’, ‘labels’],
num_rows: 28
})
validation: Dataset({
features: [‘sources’, ‘target’, ‘input_ids’, ‘attention_mask’, ‘labels’],
num_rows: 28
})
})
移除某列(仅供学习):
tokenized_dataset = tokenized_dataset.remove_columns(["sources","target"])
tokenized_dataset
DatasetDict({
train: Dataset({
features: [‘input_ids’, ‘attention_mask’, ‘labels’],
num_rows: 28
})
validation: Dataset({
features: [‘input_ids’, ‘attention_mask’, ‘labels’],
num_rows: 28
})
})
随机打乱并取子集(仅供学习):
small_train_dataset = tokenized_dataset["train"].shuffle(seed=42).select(range(3))
small_eval_dataset = tokenized_dataset["validation"].shuffle(seed=42).select(range(3))
small_train_dataset
Dataset({
features: [‘input_ids’, ‘attention_mask’, ‘labels’],
num_rows: 3
})
DataLoader 定义(data_collator)
类似 torch.utils.data.DataLoader 的collate_fn,用来处理训练集、验证集。官方提供了下面这些 Collator:
上一小节 tokenize_function 函数的作用是将原始数据集中的每个样本编码为模型可接受的输入格式,包括对输入和标签的分词、截断和填充等操作,最终返回一个包含 input_ids 和 labels 的字典。它主要用于 dataset.map 函数中对数据集进行转换。
DataCollatorForLanguageModeling 类的作用是将一批样本组合成一个训练用的 mini-batch,它会将每个样本的 input_ids 合并成一个大的矩阵,每个样本的 attention_mask 合并成一个大的矩阵,每个样本的 labels 合并成一个大的向量。它还会计算出训练时需要用到的特殊的 mask 矩阵,用于在训练时计算 loss。在使用 Trainer 训练模型时,DataCollatorForLanguageModeling 类需要传入到 Trainer 的 data_collator 参数中,它会在每个训练步骤中将训练数据组合成 mini-batch,并且计算 loss 和其他统计信息。
模型训练(基于 Trainer)
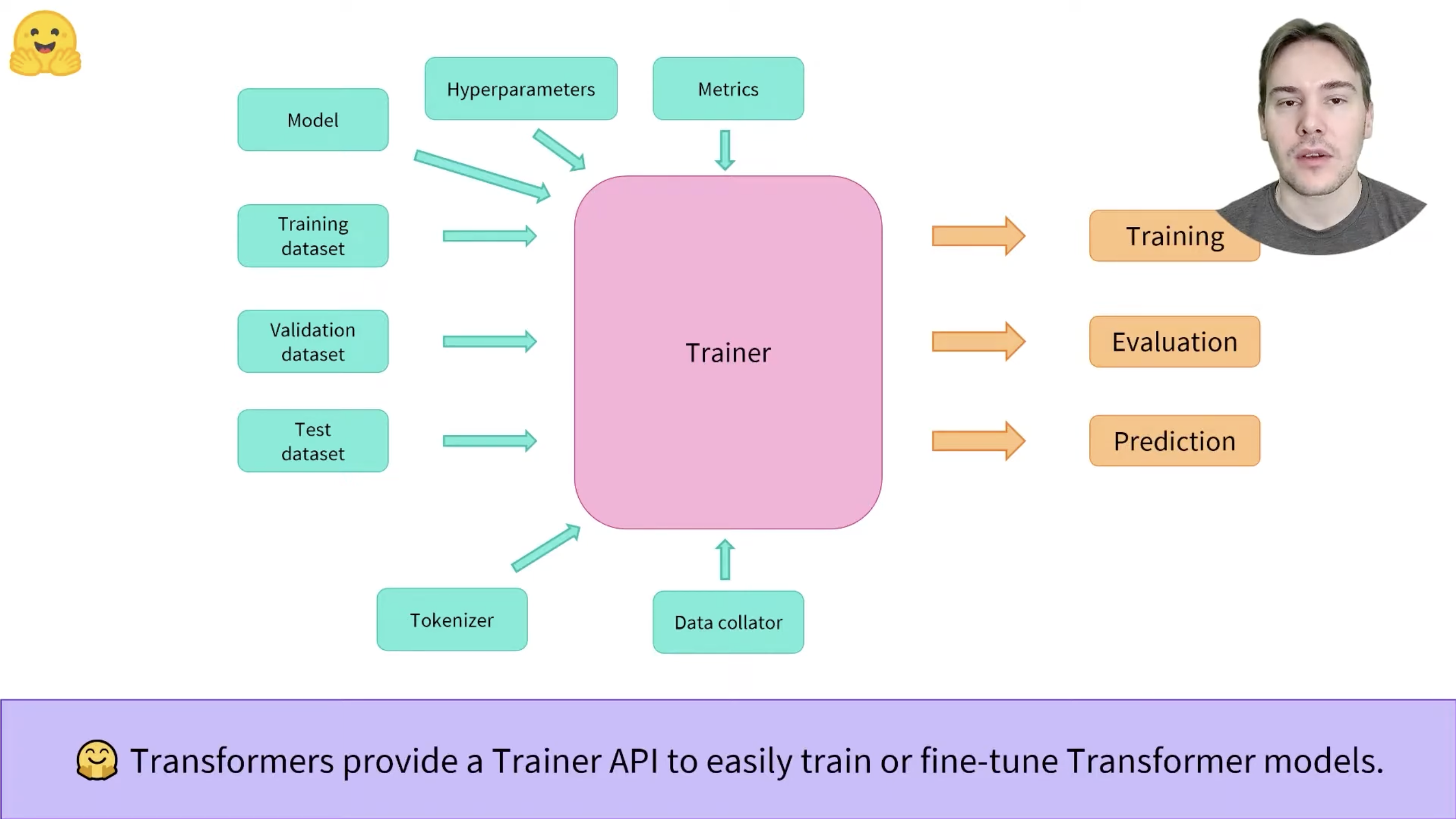
通过 TrainingArguments 设置超参:
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir='./results/train_xxxx', # 保存模型和日志的目录
num_train_epochs=10, # 训练轮数
per_device_train_batch_size=4, # 训练时每个 GPU 上的 batch size
per_device_eval_batch_size=4, # 验证时每个 GPU 上的 batch size
warmup_steps=50, # 学习率 warmup 步数
learning_rate=2e-5, # 初始学习率
logging_dir='./logs', # 日志保存目录
logging_steps=50, # 每隔多少步打印一次训练日志
evaluation_strategy='epoch', # 在哪些时间步骤上评估性能:'no', 'steps', 'epoch'
save_total_limit=3, # 保存的模型数量上限
save_strategy='epoch', # 模型保存策略,'steps':每隔多少步保存一次,'epoch':每个epoch保存一次
gradient_accumulation_steps=2, # 每多少个 batch 合并为一个,等于期望的 batch size / per_device_train_batch_size
)
通过 Trainer 加载训练器
from transformers import Trainer
# 定义 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
data_collator=data_collator,
tokenizer=tokenizer
)
# 开始训练
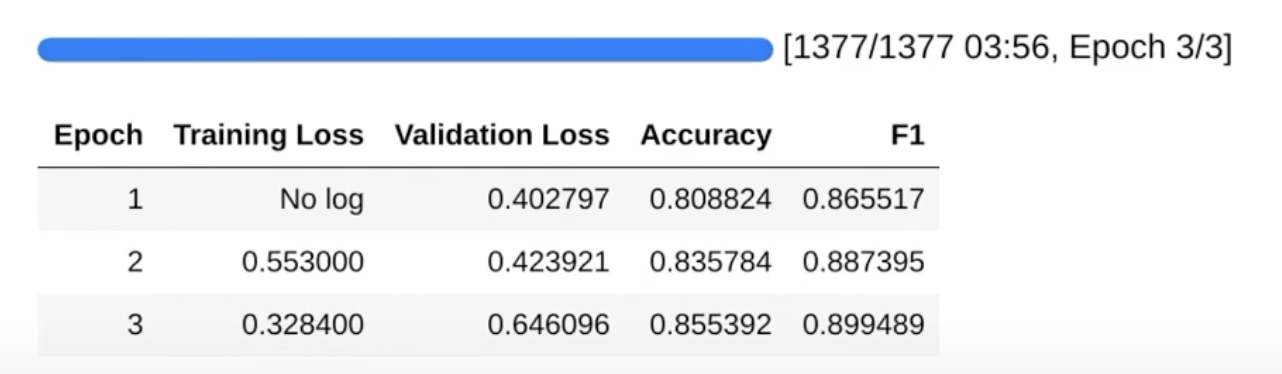
trainer.train()
但上面只能根据验证集的 loss 评估,如果需要针对任务设置指标,则参考如下:
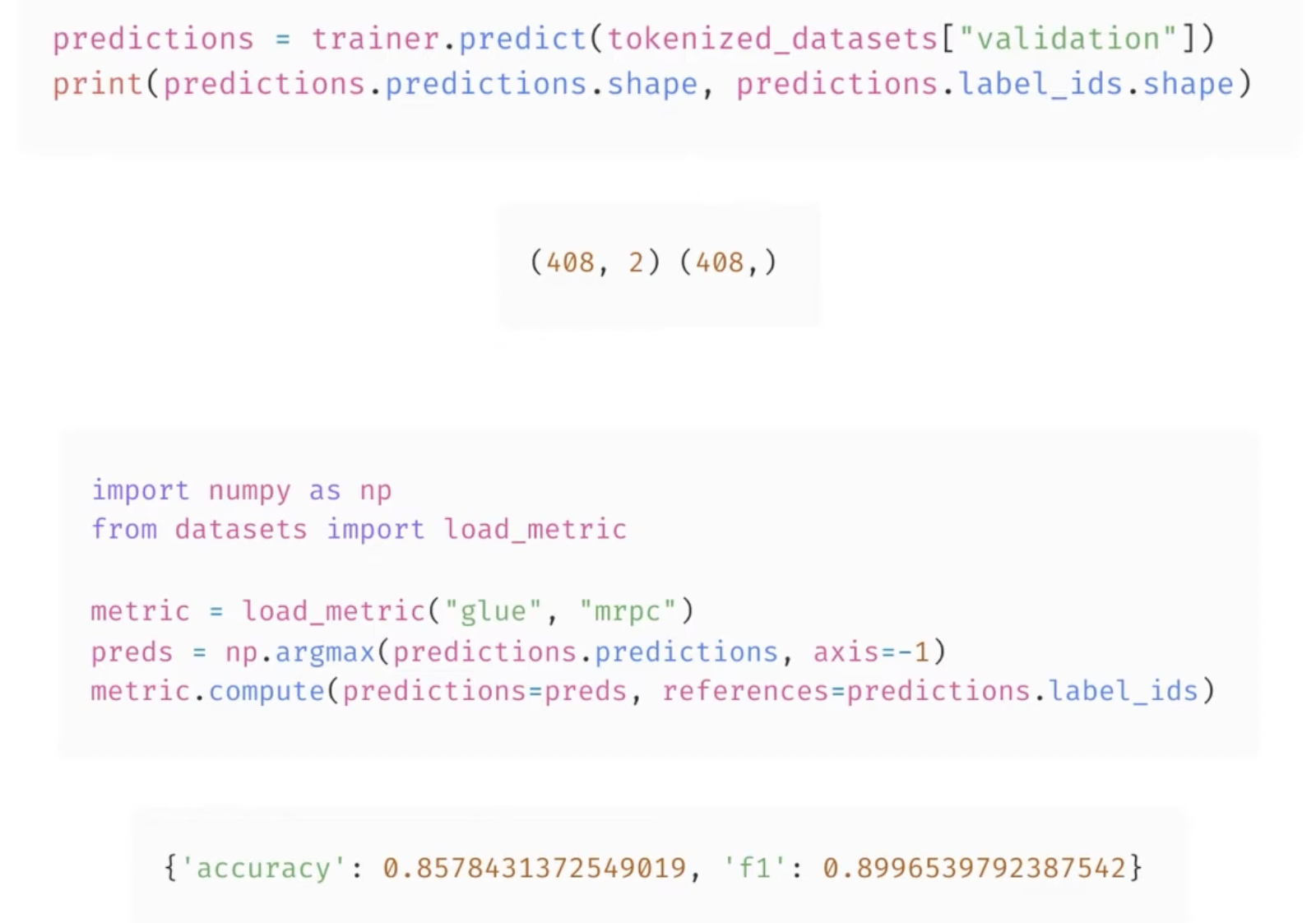
因此,需要定义一个 compute_metrics 方法,用于计算任务指标(可以用 evaluate 库),并传给 Trainer。
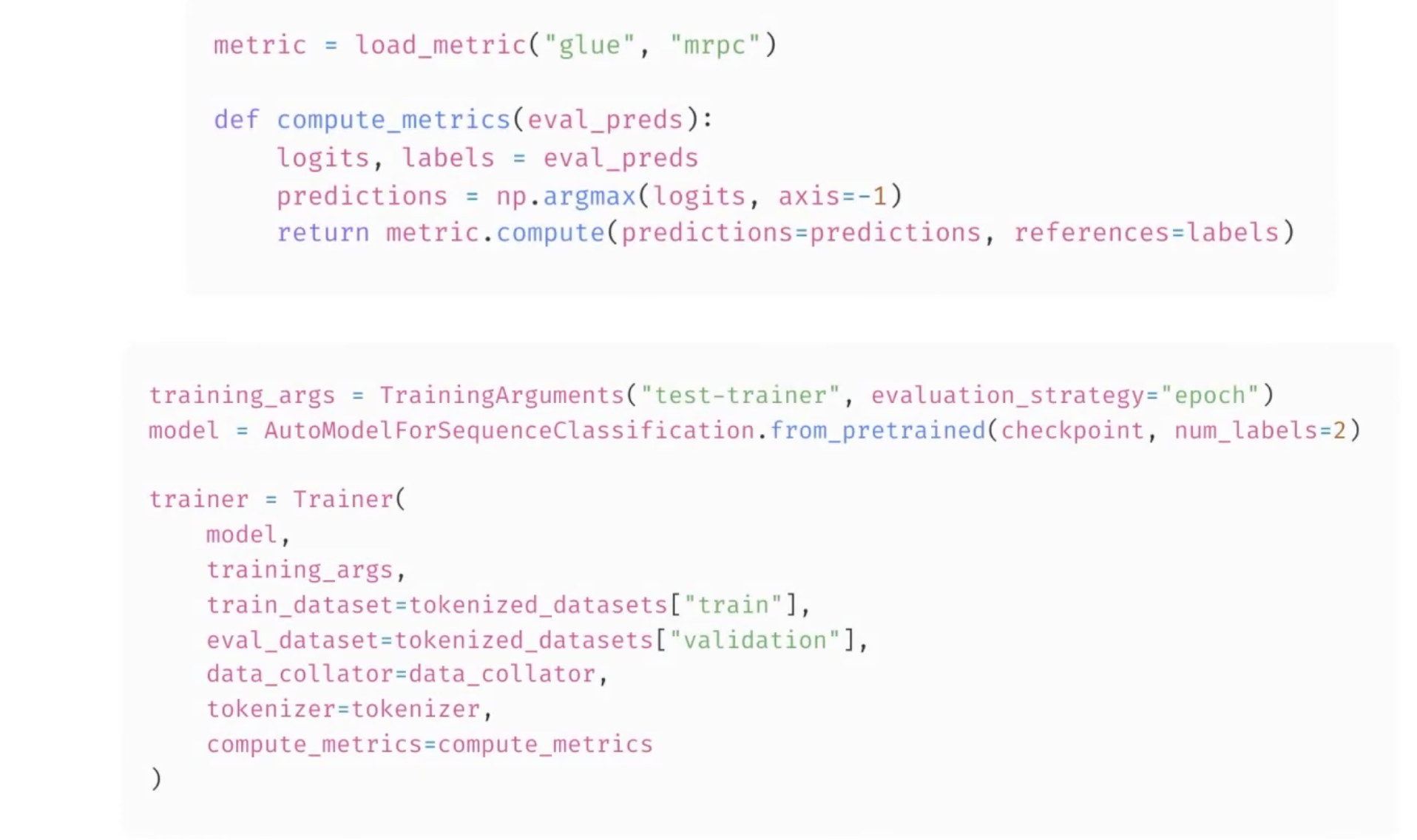
这样,训练时就会输出 compute_metrics 中自定义的指标了: