GPS生产厂家在定义数据的时候都会有一定的数据类型,例如double、int、float等,我们知道它们在内存中都对应了一定的字节大小,而我在实际使用时涉及到了端序的问题(大端序高字节在前,小端序低字节在前),我用的GPS为小端序,那我抓包的时候就按照小端序抓并且定义一个指定字节大小的小端序类型,对应上原本的double、int、float等类型即可,并且不能使用字节对齐
大端序和小端序
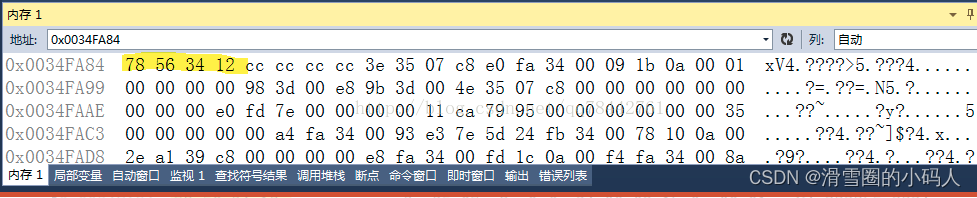
如果有一个变量:unsigned int a=0x12345678;
大端Big-Endian:高字节在前 12 34 56 78
小端Little-Endian:低字节在前 78 56 34 12
C++常见类型对应的小端序类型
| author | FJC | Bits | Bytes | range |
|---|---|---|---|---|
| little_uint8_t | unsigned char | 8 | 1 | 0-255 |
| little_int16_t | short | 16 | 2 | -32768-32767 |
| little_int32_t | int/float/long | 32 | 4 | -2147483648-2147483647 |
| little_uint64_t | unsigned long long / double | 64 | 8 | 0-18446744073709551615 |
| little_uint32_t | unsigned int /float/long | 32 | 4 | 0-4294967295 |
字节对齐
字节对齐:编译器默认对结构体进行处理。例如让宽度为2的基本数据类型位于能被2整除的地址上,让宽度为4的基本数据类型位于被4整除的地址上。因此,结构体中内容之间可能被字节填充。但是在抓包时候假设我们设置一个结构体的大小时候固定的,其中每一个成员都按照对应字节大小一个挨着一个从包中对应实际的ASCII含义,那么就不能让系统对结构体进行字节对齐。
注意:
signed:有符号的 unsigned:无符号的
aligned:对齐的 unsigned:非对齐的