paper:A Gift From Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning
code:https://github.com/HobbitLong/RepDistiller/blob/master/distiller_zoo/FSP.py
背景
深度神经网络DNN逐层生成特征。更高层的特征更接近于任务的有用特征。如果我们把DNN的输入看作问题,把输出看作答案,我们就可以把DNN中间生成的特征看作是求解过程中的中间结果。根据这一想法,FitNets可以让学生网络简单地模拟教师网络的中间结果。然而在DNN中,有许多方法或途径来解决从输入生成输出的问题。因此,模拟教师网络生成的特征对学生网络来说是一个硬约束hard constraint。就人而言,老师解释问题的解决过程,学生学习解决问题的流程。当输入特定的问题时,学生网络不一定需要学习中间输出,但当遇到特定类型的问题时,学生网络可以学习这一类问题的通用解决方法。因此作者认为,对于知识蒸馏中的教师网络,演示问题的解决过程比演示中间结果具有更好的泛化性。
本文的创新点
本文将神经网络中层与层之间的信息流动定义为需要蒸馏的知识,并通过计算两个特征层之间的内积来得到这种知识。当将这种层之间的流动作为知识传递给学生网络时,作者通过实验得到了三个结论:
从教师网络学习这种蒸馏知识的学生网络比原始网络的优化(收敛)速度快得多。
学习这种蒸馏知识的学生网络比原始网络的性能更好。
即使教师网络是在一个不同的任务或数据集上训练得到的,学生网络也可以从教师网络中学习到这种知识,并且比从头训练的效果更好。
下图是本文提出的知识蒸馏方法的概念图
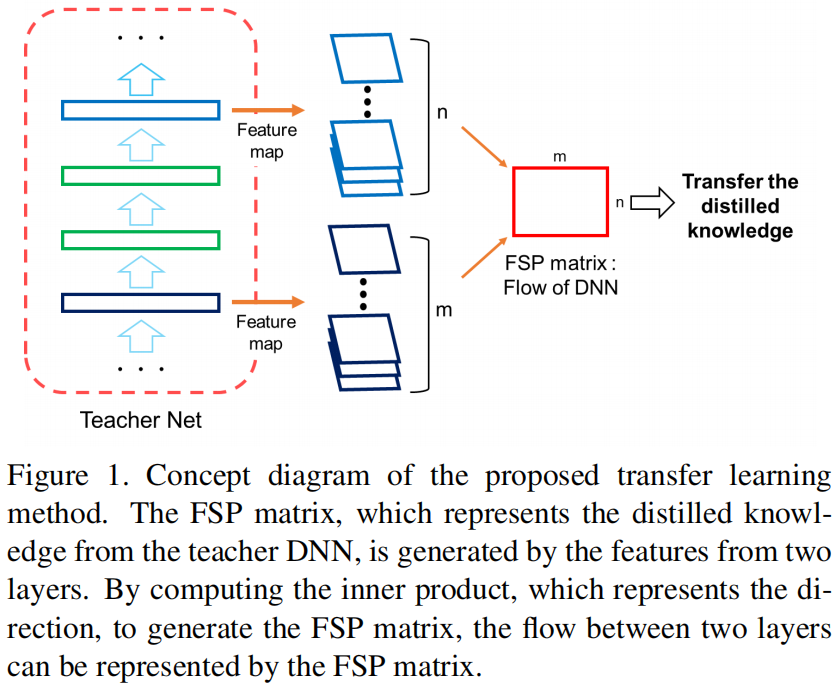
本文的贡献如下:
提出了一种知识蒸馏的新方法。
这种知识对于快速优化非常有用。
利用所提出的蒸馏知识定义网络的初始权重可以提高小模型的性能。
即使学生网络接受了与教师网络不同的训练任务,所提出的蒸馏知识也能提高学生网络的表现。
方法介绍
作者设计了网络中两个相邻层之间的FSP(flow of solution procedure)矩阵来表示问题的求解过程,对于挑选的层1输出的feature map表示为 \(F^{1}\in \mathbb{R}^{h\times w\times m}\),其中 \(h,w,m\) 分别表示特征图的高、宽、通道数。层2表示为 \(F^{2}\in \mathbb{R}^{h\times w\times n}\),则FSP矩阵 \(G\in \mathbb{R}^{m\times n}\) 可通过下式求得
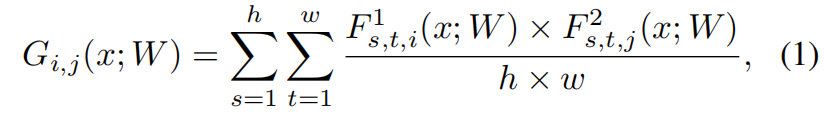
其中 \(x\) 表示输入图片,\(W\) 表示网络权重参数。
对于残差网络,网络在一些位置的spatial size发生变化,我们选择教师网络和学生网络对应位置具有相同spatial size的特征图来生成FSP matrix,下图是一个示例
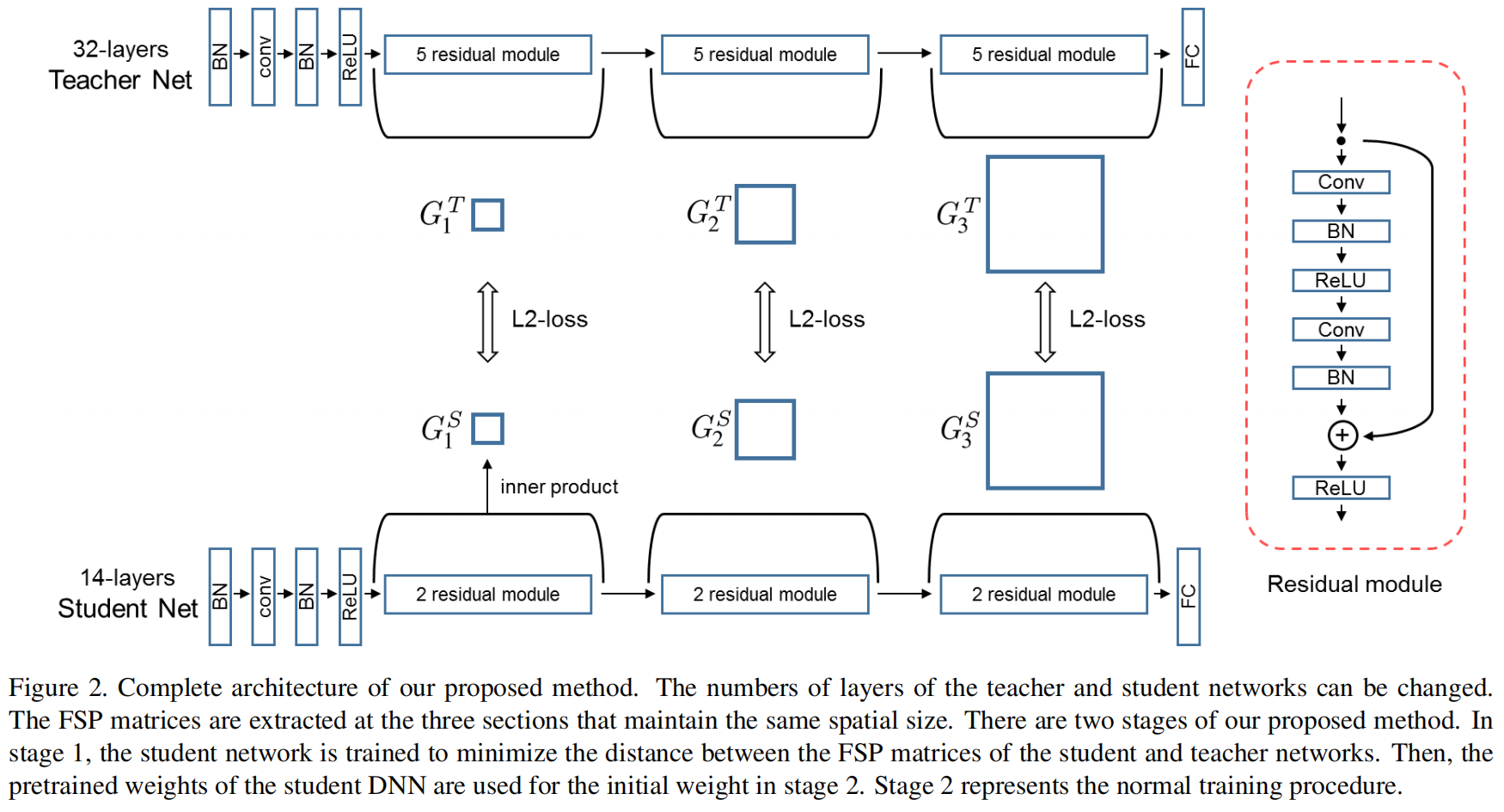
计算教师网络和学生网络对应FSP矩阵的L2损失,完整是损失函数如下
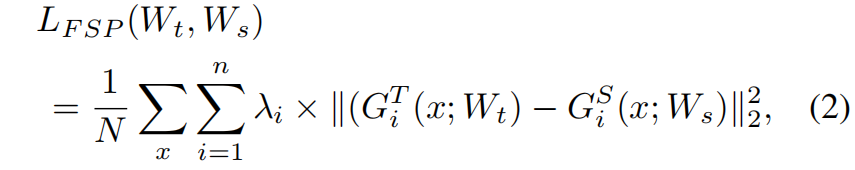
其中 \(\lambda_{i}\) 表示每一对FSP矩阵损失的权重,文中设定所有层计算的FSP之间的损失权重相等。\(N\) 表示所有的采样点。
代码解析
forward函数的输入g_s和g_t分别表示学生网络和教师网络中所有用来计算FSP矩阵的层,在compute_fsp中每一层都与相邻层计算fsp矩阵,注意这里的相邻并不是说在原始网络中这两层的相邻的。这里相邻层之间计算fsp矩阵需要保证spatial size相等,如果不相等通过自适应平均池化使之相等。
from __future__ import print_function
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
class FSP(nn.Module):
"""A Gift from Knowledge Distillation:
Fast Optimization, Network Minimization and Transfer Learning"""
def __init__(self, s_shapes, t_shapes):
super(FSP, self).__init__()
assert len(s_shapes) == len(t_shapes), 'unequal length of feat list'
s_c = [s[1] for s in s_shapes]
t_c = [t[1] for t in t_shapes]
if np.any(np.asarray(s_c) != np.asarray(t_c)):
raise ValueError('num of channels not equal (error in FSP)')
def forward(self, g_s, g_t):
# [(64,32,32,32),(64,64,32,32),(64,128,16,16),(64,256,8,8)]
# [(64,32,32,32),(64,64,32,32),(64,128,16,16),(64,256,8,8)]
s_fsp = self.compute_fsp(g_s)
t_fsp = self.compute_fsp(g_t)
loss_group = [self.compute_loss(s, t) for s, t in zip(s_fsp, t_fsp)]
return loss_group
@staticmethod
def compute_loss(s, t):
return (s - t).pow(2).mean()
@staticmethod
def compute_fsp(g):
fsp_list = []
for i in range(len(g) - 1):
bot, top = g[i], g[i + 1] # (64,32,32,32),(64,64,32,32)
b_H, t_H = bot.shape[2], top.shape[2]
if b_H > t_H:
bot = F.adaptive_avg_pool2d(bot, (t_H, t_H))
elif b_H < t_H:
top = F.adaptive_avg_pool2d(top, (b_H, b_H))
else:
pass
bot = bot.unsqueeze(1) # (64,1,32,32,32)
top = top.unsqueeze(2) # (64,64,1,32,32)
bot = bot.view(bot.shape[0], bot.shape[1], bot.shape[2], -1) # (64,1,32,1024)
top = top.view(top.shape[0], top.shape[1], top.shape[2], -1) # (64,64,1,1024)
fsp = (bot * top).mean(-1) # (64,64,32,1024)->(64,64,32)
fsp_list.append(fsp)
return fsp_list