前言:在文章【逐步剖C】-第八章-指针进阶-上与指针初阶中我们介绍了有关指针较为全面的知识,本篇文章主要从指针和数组相关试题出发,进一步巩固对指针的学习。接下来,让我们开始吧。
一、“真假”数组名
前言:这一部分设计到有关关键字sizeof与数组名的意义的知识点,若有不熟悉的朋友可以先看看下面这几篇文章中的相关介绍:
【逐步剖C】-第三章-数组
【逐步剖C】-第四章-操作符
1. 一维数组
看下面几条语句输出的结果是什么?
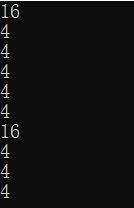
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a));
printf("%d\n",sizeof(a+0));
printf("%d\n",sizeof(*a));
printf("%d\n",sizeof(a+1));
printf("%d\n",sizeof(a[1]));
printf("%d\n",sizeof(&a));
printf("%d\n",sizeof(*&a));
printf("%d\n",sizeof(&a+1));
printf("%d\n",sizeof(&a[0]));
printf("%d\n",sizeof(&a[0]+1));
程序运行结果:
解释:
-
sizeof(a)
这里的a是数组名,其“单独”作为sizeof的操作数,代表了整个数组,故计算出的字节大小为16 -
sizeof(a+0)
这里的a是数组名,但其并不“单独”作为sizeof的操作数(因为后面还有个+0),
故此时的数组名a代表的是数组首元素的地址,是地址那么大小就是4(32位机)或8(64位机)个字节 -
sizeof(*a)
这里的a代表的是数组首元素的地址,解引用a则得到了第一个元素,类型为整型,故大小为4个字节 -
sizeof(a+1)
这里的a代表的是数组首元素的地址,+1则代表了数组第二个元素的地址,是地址那么大小就是4或8个字节 -
sizeof(a[1])
a[1]就是数组的第二个元素,类型为整型,故大小为4个字节 -
sizeof(&a)
&a是取出整个数组的地址,是地址那么大小就是4或8个字节 -
sizeof(*&a)
&a是取出整个数组的地址,再解引用就得到了整个数组,故计算出的字节大小为16
注:不在sizeof中的*&a得到的是数组首元素的地址
解释:这里可以理解为 * 与 & 相互抵消,抵消完后就只剩数组名“a”;
此时在sizeof中就相当与是“单独”作为操作数,代表了整个数组;
不在sizeof中就相当于单只有一个数组名,代表了数组首元素的地址。 -
sizeof(&a+1)
&a是整个数组的地址,&a+1跳过整个数组指向数组后边的空间,但也是一个地址,是地址那么大小就是4或8个字节
示意图参考:

-
sizeof(&a[0])
&a[0]是取出了数组第一个元素的地址,是地址那么大小就是4或8个字节 -
sizeof(&a[0]+1)
&a[0]是取出了数组第一个元素的地址,+1则代表了数组第二个元素的地址,是地址那么大小就是4或8个字节
小结:
若数组名 “单独” 作为sizeof的操作数,则此时数组名代表的是整个数组;
解引用操作*和取地址操作&可理解为“相互抵消”;
&+数组名无论是否在sizeof中都表示的是整个数组的地址;
2. 二维数组
看下面几条语句输出的结果是什么?
int a[3][4] = {0};
printf("%d\n",sizeof(a));
printf("%d\n",sizeof(a[0][0]));
printf("%d\n",sizeof(a[0]));
printf("%d\n",sizeof(a[0]+1));
printf("%d\n",sizeof(*(a[0]+1)));
printf("%d\n",sizeof(a+1));
printf("%d\n",sizeof(*(a+1)));
printf("%d\n",sizeof(&a[0]+1));
printf("%d\n",sizeof(*(&a[0]+1)));
printf("%d\n",sizeof(*a));
printf("%d\n",sizeof(a[3]));
程序运行结果:

解释:
-
sizeof(a):
数组名 “单独” 作为sizeof的操作数,a代表整个二维数组,故大小为48个字节 -
sizeof(a[0][0]))
a[0][0]代表二维数组中第一行的第一个元素,类型为整型,故大小为4个字节 -
sizeof(a[0])
a[0]代表二维数组中的第一行,相当于是第一行数组的数组名,即第一行数组的数组名“单独”作为sizeof的操作数,故代表整个第一行数组,大小为16个字节
示意图参考:

-
sizeof(a[0]+1)
把a[0]视为数组名,a[0]不是“单独”作为sizeof的操作数,所以此时的a[0]表示的是第一行数组首元素的地址,故a[0]+1表示的是第一行数组的第二个元素的地址,故大小为4或8个字节
示意图参考:

-
sizeof(*(a[0]+1))
a[0]+1表示的是第一行数组的第二个元素的地址,故解引用得到的就是第一行数组的第二个元素,类型为整型,故大小为4个字节 -
sizeof(a+1)
a是二维数组的数组名,没有“单独”作为sizeof的操作数,故单论a而言,其代表二维数组的整个第一行的地址,+1后就代表整个第二行的地址,故大小为4或8个字节 -
sizeof(*(a+1))
a+1表示的是整个第二行的地址,故解引用得到的就是整个第二行的数组,故大小为16字节 -
sizeof(&a[0]+1)
&a[0]代表取出整个第一行一维数组的地址,+1后表示的是整个第二行数组的地址,故大小为4或8个字节 -
sizeof(*(&a[0]+1))
&a[0]+1表示整个第二行数组的地址,解引用得到整个第二行数组,故大小为16个字节 -
sizeof(*a)
a表示整个第一行的地址,解引用得到整个第一行数组,故大小为16个字节 -
sizeof(a[3])
a[3]看似发生了越界问题,其实没有。sizeof本质获取的是操作数的类型属性,对于a[3],其相当于是数组的第四行(假设存在),类型为int[4],故大小为16个字节
小结:
对于二维数组,arr[i]可视为对应第i行的一维数组的数组名;
sizeof的本质是获取操作数的值属性;
3.字符数组
看下面几条语句输出的结果是什么?
(1)
char arr[] = {'a','b','c','d','e','f'};
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr+0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr+1));
printf("%d\n", sizeof(&arr[0]+1));
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr+0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr+1));
printf("%d\n", strlen(&arr[0]+1));
对sizeof:
运行结果:

解释:
sizeof(arr)
数组名arr “单独” 作为sizeof的操作数,表示的是整个数组,故大小为6个字节sizeof(arr+0)
数组名arr没有单独作为sizeof的操作数,表示的是数组首元素的地址,故大小为4或8个字节sizeof(*arr)
数组名表示的是首元素的地址,故解引用得到的是数组第一个元素,故大小为1个字节sizeof(arr[1])
arr[1]表示数组的第二个元素,故大小为1个字节sizeof(&arr)
&arr取出的是整个数组的地址,是地址就是4或8个字节sizeof(&arr+1)
&arr表示整个数组的地址,+1跳过了整个数组,但本质还是地址,故大小为4或8字节sizeof(&arr[0]+1)
&arr[0]表示的是数组第一个元素的地址,+1表示第二个元素的地址,故大小为4或8个字节
对strlen:
这里先简单说明一下strlen函数的功能:通过统计一个字符串中在结束标志'\0'前有几个字符来计算出字符串长度,如字符串"abcdef"的长度就为6。
这里没有贴上运行结果的截图,因为个别语句是对strlen函数的错误使用,后面继续说明
说明:
strlen(arr)
arr是数组首元素的地址,计算字符串长度,本质上是找字符串的结束标志\0,数组中并没有\0,故长度为随机值strlen(arr+0)
对于函数传参来说,arr+0同arr,故长度为随机值strlen(*arr)
*arr表示数组第一个元素,而strlen函数的参数是地址,故会此时会因参数不匹配而导致发生内存访问错误,因为此时访问的是对应元素值的地址
调试截图如下,请看:

字符'a'的ASCII码值为97,转化为16进制就是61,这里相当于函数直接访问地址为0x00000061的内存空间,属于非法内存访问。strlen(arr[1])
arr[1]表示数组第二个元素,同上属于非法访问内存,程序出错。strlen(&arr)
&arr虽代表整个数组地址,但地址值与首元素是相同的(文章 【逐步剖C】-第八章-指针进阶-上中有详细讲解,感兴趣的朋友可以看看),故strlen同样从首元素的地址开始往后找'\0',故语句执行结果为随机值。strlen(&arr+1)
&arr+1,代表跳过了一整个数组即数组最后一个元素往后一个内存单元的地址,strlen从该地址开始往后找'\0',故语句执行结果为随机值
示意图参考:

strlen(&arr[0]+1)
&arr[0]+1表示数组第个二元素的地址,从此往后找'\0',故语句执行结果为随机值
示意图参考:

(2)
char arr[] = "abcdef";
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr+0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr+1));
printf("%d\n", sizeof(&arr[0]+1));
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr+0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr+1));
printf("%d\n", strlen(&arr[0]+1));
(2)与(1)相比,数组中多存储了'\0',示意图参考:

对sizeof
sizeof(arr)
数组名arr“单独”作为操作数,代表了整个数组,故大小为7个字节
往后的语句执行结果同(1),这里不再赘述啦。
对strlen
strlen(arr)
从数组首元素的位置开始往后找'\0','\0'前共有6个字符,故字符串长度为6个字节strlen(arr+0)
对于函数传参来说,arr+0同arr,故长度为6个字节strlen(*arr)
*arr表示数组第一个元素,而strlen函数的参数是地址,故会此时会因参数不匹配而导致发生内存访问错误,因为此时访问的是对应元素值的地址strlen(arr[1])
arr[1]表示数组第二个元素,同上属于非法访问内存,程序出错。strlen(&arr)
&arr虽代表整个数组地址,但地址值与首元素是相同的,故strlen同样从首元素的地址开始往后找'\0',故长度为6个字节。strlen(&arr+1)
&arr+1,代表跳过了一整个数组即数组最后一个元素往后一个内存单元的地址,strlen从该地址开始往后找'\0',故语句执行结果为随机值
参考示意图:
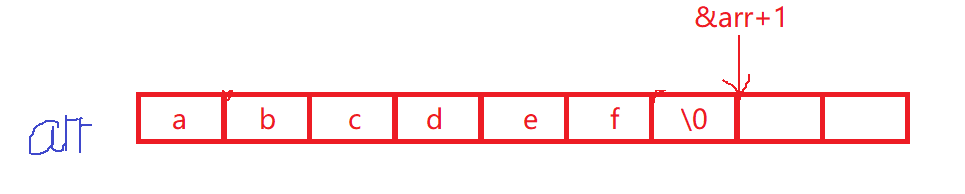
strlen(&arr[0]+1)
&arr[0]+1代表数组第二个元素的地址,即从数组第二个元素开始往后找'\0',故长度为5个字节
(3)
char *p = "abcdef";
printf("%d\n", sizeof(p));
printf("%d\n", sizeof(p+1));
printf("%d\n", sizeof(*p));
printf("%d\n", sizeof(p[0]));
printf("%d\n", sizeof(&p));
printf("%d\n", sizeof(&p+1));
printf("%d\n", sizeof(&p[0]+1));
printf("%d\n", strlen(p));
printf("%d\n", strlen(p+1));
printf("%d\n", strlen(*p));
printf("%d\n", strlen(p[0]));
printf("%d\n", strlen(&p));
printf("%d\n", strlen(&p+1));
printf("%d\n", strlen(&p[0]+1));
对sizeof
程序运行结果:

sizeof(p)
p本质上存储的是字符串首字符的地址,故大小为4或8个字节sizeof(p+1)
p+1表示字符串第二个字符的地址,故大小为4或8个字节sizeof(*p)
*p表示字符串的首字符,故大小为1个字节sizeof(p[0])
p[0]表示字符串的首字符,故大小为1个字节sizeof(&p)
&p表示字符串首字符的地址的地址,是地址大小就为4或8个字节sizeof(&p+1)
&p+1表示字符串首字符的地址的地址往后一个字符大小空间的地址,是地址大小就为4或8个字节
示意图参考:

sizeof(&p[0]+1)
表示字符串中第二个字符的地址,故大小为4或8个字节
对strlenstrlen(p)
从字符串首字符的位置开始往后找'\0','\0'之前有6个字符,故长度为6个字节strlen(p+1)
从字符串第二个字符的位置开始往后找'\0',故长度为5个字节
往后语句执行的结果同(2),这里不再赘述啦.
4. 总结:
数组名的意义:
(1)sizeof(数组名),即数组名单独作为sizeof的操作数,这里的数组名表示整个数组,计算的是整个数组的大小。
(2)&数组名,这里的数组名表示整个数组,取出的是整个数组的地址。
(3)除此之外所有的数组名都表示首元素的地址。
二、指针笔试题
数组名的意义介绍完了,接下来我们来和指针比划比划。
先声明一下这里需要用到的知识点及相关文章:
(1)所谓取地址其实取出的是第一个字节的地址(较小的地址);指针类型的意义;同类型指针相减;指针加减整数——【逐步剖C】-第五章-指针初阶
(2)数据在内存中的存储方式:大小端字节序 ——【逐步剖C】-第七章-数据的存储
(3)数组指针 ——【逐步剖C】-第八章-指针进阶-上
1. 程序的结果是什么?
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf( "%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
运行结果:

解释:
&a+1表示的是跳过整个数组后即数组最后一个元素后面的一块内存空间的地址,此时的地址类型为数组指针,即int(*)[5],故在强制转化为整型后才用指针ptr指向那块空间,因为ptr为整型指针,所以在执行 -1后指针往前走了一个整型的大小 ,即指向了数组中的元素5;
数组名a表示首元素的地址,故a+1表示第二个元素的地址,执行解引用操作就得到第二个元素。
参考示意图:

2. 假设p的值为0x100000,已知结构体Test类型的变量大小是20个字节,如下表达式的值分别为多少?
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
int main()
{
p = 0x100000;
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}
运行结果:

解释:这里主要考察指针类型在加减整数上的意义。
- 语句
printf("%p\n", p + 0x1);
这里的p为结构体指针,由已知,结构体的大小为20个字节,故在+0x1(其实也就是+1)后,指针往后走了20个字节,20转化为16进制就是14,故最终结果为00100014 - 语句
printf("%p\n", (unsigned long)p + 0x1);
把p强制转换为了无符号长整型,此时+1就是和整数一样普通的+1,故最终结果为00100001 - 语句
printf("%p\n", (unsigned int*)p + 0x1);
把p强制转换为了无符号整型指针,执行+1后,指针往后走了4个字节,故最终结果为00100004
3. 下面程序输出结果是什么?
int main()
{
int a[4] = { 1, 2, 3, 4 };
int *ptr1 = (int *)(&a + 1);
int *ptr2 = (int *)((int)a + 1);
printf( "%x,%x", ptr1[-1], *ptr2);
return 0;
}
输出结果:

解释:
- 对语句
int *ptr1 = (int *)(&a + 1)
表示的是跳过整个数组a即最后一个元素后面一块内存空间的地址,此时的地址类型为数组指针,即int(*)[4],故在强制转化为整型后才用指针ptr指向那块空间。在打印语句中的ptr1[-1]其实就等价于*(ptr-1),又因为ptr为整型指针,故在-1后往前走一个整型的大小指向了数组中元素4的位置,故最终输出的结果为4
示意图参考:

- 对语句
int *ptr2 = (int *)((int)a + 1);
我们知道a表示的是数组首元素的地址,但更准确来说是首元素的第一个字节的地址(整型有四个字节),这一点我们可以通过调试看到:

这个是整个数组的地址即内存情况,可以看到一共是16个字节,行与行之间差了4个字节,接下来我们一个字节一个字节地看:

可以看到,红色部分就是a的地址
接着,强制把其转换为整型然后+1,本质上就是让其往后加了一个字节,在上图就是从0x00cff9a8变为了0x00cff9a9,如上图蓝色部分所示。强制转换为整型后,其实就是相应地址值对应的十进制数,+1后再通过(int*)把其转换回了地址值,然后把这个地址存在了整型指针ptr2中。这里又涉及到了指针类型的另一个意义:指针类型决定了其在解引用时能访问的字节数。那么对于整型指针ptr2而言,其在解引用时就会以整型的视角从其地址开始往后访问4个字节,如下图:
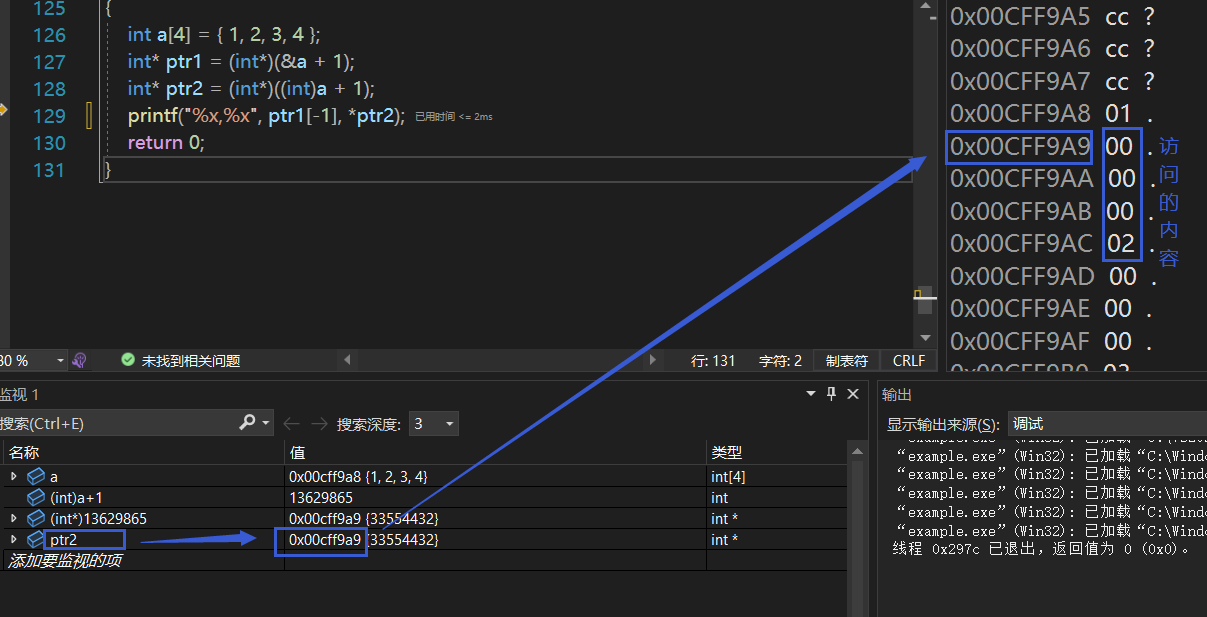
最后,因为机器是以小端字节序的方式进行数据的存储,故ptr2指针中的内容实际上是这样的:
高位---------------------低位
02 00 00 00
高地址-------------------低地址
最后以十六进制输出,那么刚好就是2000000。
4. 下面程序输出结果是什么?
#include <stdio.h>
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p;
p = a[0];
printf( "%d", p[0]);
return 0;
}
运行结果:
解释:
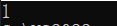
初始化列表中的其实是逗号表达式,即语句int a[3][2] = { (0, 1), (2, 3), (4, 5) };等价为int a[3][2] = { 1, 3, 5 };接着,a[0]理解为二维数组中第一行数组的数组名,代表了第一行数组中首元素的地址,该地址存在了指针变量p中,最后的p[0]就相当于*(p+0),即得到的是第一行数组的第一个元素,故最后输出结果为1。
示意图参考:

5. 下面程序输出结果是什么?
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
运行结果:

解释:
解这道题的关键在于对数组指针的理解。
- 语句
int(*p)[4];表明p是一个数组指针,其指向了一个有四个整型元素的的数组,此时p若执行+1操作,就会跳过4个整型元素的大小; - 语句
p = a;表明p指向二维数组中的第一行数组; - 最后,需要以地址与整型的形式输出
&p[4][2] - &a[4][2]的结果。那么这里我们可以先算出整数的结果,然后根据补码转换为16进制数即可(PS:若是负数,地址打印直接就是补码,不需要再转换为原码)。
这里先放上一张示意图,可能更便于理解一些:
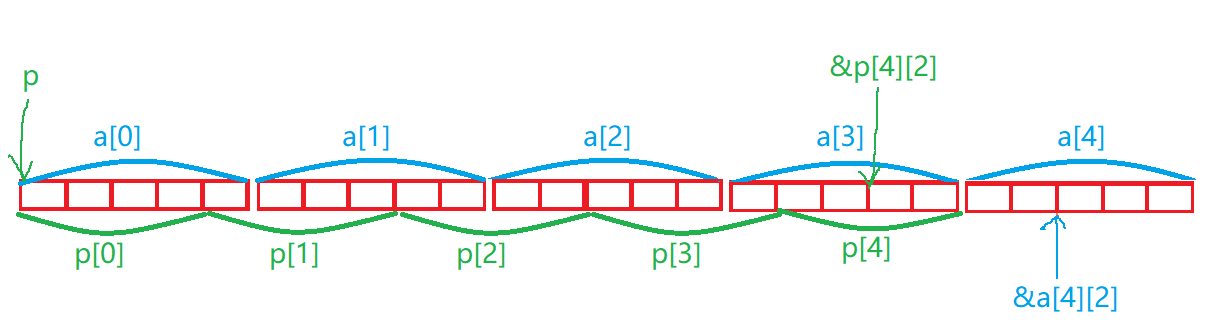
对于p[4][2],其本质上等价于*(*(p+4)+2),由于p指向二维数组中的第一行数组,所以p从第一行数组的第一个元素的位置开始向后走(第一行数组的地址与第一行数组的首元素的地址相同),最内层括号中的p+4表示p走过了4个有4个整型元素的数组也就是16个字节的大小;*(p+4)后,指针的类型 “相当于” 从int(*)[4]型变为了int*型,故再+2就是在原来的基础上再往后走了两个整型的大小,最后解引用得到对应位置上的元素;a[4][2]指的就是二维数组第四行的第二个元素。
分别对这两个元素进行取地址后作差,作差的结果若以整数的绝对值来表示,表示的就是两个地址之间的元素个数,如图中,&p[4][2]与&a[4][2]之间就有4个元素,但由于a[4][2]的地址大于p[4][2]的地址,故&p[4][2] - &a[4][2]以整数输出的最终结果就为 -4
接下来将-4转换为16进制数:
-4的原码为:
1000 0000 0000 0000 0000 0000 0000 0100
反码为:
1111 1111 1111 1111 1111 1111 1111 1011
补码为:
1111 1111 1111 1111 1111 1111 1111 1100
转换为16进制就是:
ff ff ff ff fc
6. 下面程序输出结果是什么?
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int *ptr1 = (int *)(&aa + 1);
int *ptr2 = (int *)(*(aa + 1));
printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}
运行结果:

解释:
- 对于语句
int *ptr1 = (int *)(&aa + 1);
&aa表示取出整个二维数组的地址,+1后跳过整个二维数组即指向二维数组最后一个元素后面的一块内存空间,将其强制转换为int*后存在指针ptr1中,故ptr1 - 1就让ptr1指向了元素10的位置,故解引用的结果就为10。 - 对于语句
int *ptr2 = (int *)(*(aa + 1));
aa表示的是二维数组中整个第一行数组的地址,+1后跳过整个第一行到第二行,即指向了元素6的位置,故ptr2 - 1就让ptr2指向了元素5的位置,故解引用的结果就为5。
示意图参考:

7. 下面程序输出结果是什么?
#include <stdio.h>
int main()
{
char *a[] = {"work","at","alibaba"};
char**pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}
输出结果:

解释:
示意图参考:

- a是一个字符指针数组,每个元素都是不同字符串首字符的地址;
- pa是一个二级指针,其存放的是字符指针数组中首元素的地址,故pa++就指向了字符指针数组中第二个元素的地址;故解引用得到第二个字符串的首字符的地址,故最后输出结果为at。
8. 下面程序输出结果是什么?
int main()
{
char *c[] = {"ENTER","NEW","POINT","FIRST"};
char**cp[] = {c+3,c+2,c+1,c};
char***cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *--*++cpp+3);
printf("%s\n", *cpp[-2]+3);
printf("%s\n", cpp[-1][-1]+1);
return 0;
}
输出结果:
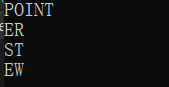
解释:
- 三条初始化语句:
一级指针数组c中有4个元素,每个元素都是对应字符串首字符的地址;
二级指针数组cp中有4个元素,每个元素都是对应一级指针数组中元素的地址;
三级指针cpp中存储的是二级指针数组中首元素的地址。
示意图参考:

-
语句
printf("%s\n", **++cpp);
++cpp后cpp指向二级字符指针数组的第二个元素,解引用得到该元素,再解引用就得到对应一级字符指针数组中的元素,也就是一级字符指针数组中的第三个元素(c+2),故输出结果为POINT
示意图参考:

-
语句
printf("%s\n", *--*++cpp+3);
在上一条语句的基础上,++cpp后cpp指向二级字符指针数组的第三个元素,解引用得到该元素后,执行--,改变了二级字符指针数组中的第三个元素(c+1),使其等于了该数组中的第四个元素(c);此时解引用就得到了对应一级字符指针数组中的字符串"ENTER"首字符的地址,+3后得到字符'E'的地址,故最后输出结果为ER
示意图参考:
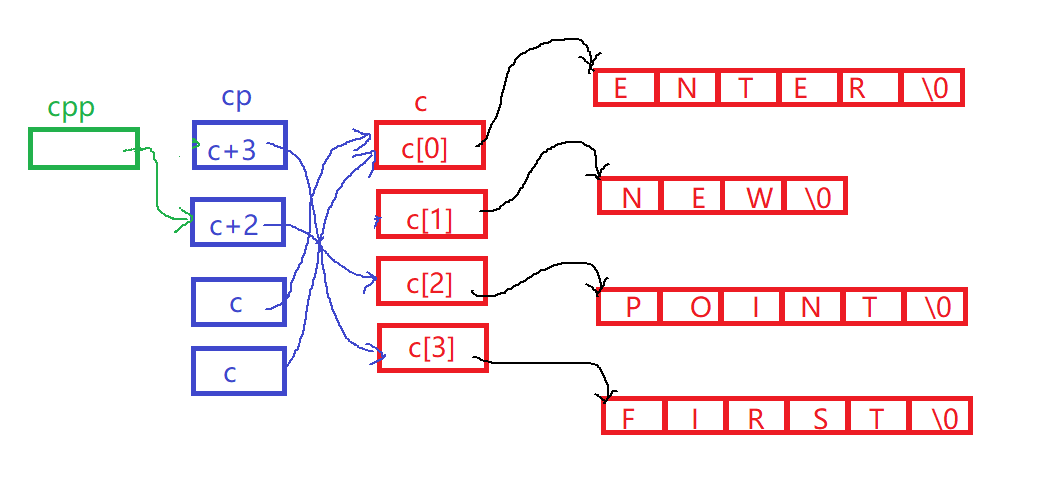
-
语句
printf("%s\n", *cpp[-2]+3);
由前面语句,cpp指向二级字符指针数组的第三个元素,又因为cpp[-2]等价于*(cpp-2),即解引用得到了二级字符指针数组的第一个元素(c+3),再解引用得到了一级字符指针数组中的字符串"FIRST"首字符的地址,+3后得到字符'S'的地址,故最后输出结果为ST -
语句
printf("%s\n", cpp[-1][-1]+1);
cpp[-1][-1]就等价于*(*(cpp - 1) - 1);*(cpp - 1)得到的是二级字符指针数组的第二个元素(c+1),然后-1得到该数组的原来第三个元素(c+2-1 = c+1),(注:虽然c+1已经不在二级指针数组cp中,但仍能通过c+1本身直接找到对应字符串,因为本质上和c有关) 解引用得到一级字符指针数组中的字符串"NEW"首字符的地址,+1后得到字符'E'的地址,故最后输出结果为EW。
本章完。
看完觉得有觉得帮助的话不妨点赞收藏鼓励一下,有疑问或看不懂的地方或有可优化的部分还恳请朋友们留个评论,多多指点,谢谢朋友们!🌹🌹🌹